
Количество страниц в pdf linux
Обновлено: 02.07.2024
В сегодняшней заметке я покажу, как исходный PDF документ разбить на страницы каждая, из которых, будет представлена PDF страницей. Нам понадобится консольная утилита, не раз применяемая в моих заметках – это pdftk.
И так у нас есть система:
Description: Ubuntu 10.10
Для наших целей я создал в домашней каталоге папку и назвал её “pdf_on_output_pdf”, перейдем в неё:
В нём лежит PDF’ый документ (а именно купленный журнал Linux Format, выпуск – 154.pdf).
Теперь установим в нашу систему пакет pdftk из репозитариев Ubuntu 10.10 :
“в моем случае устанавливает такое большое число пакетов, у вас же может быть либо больше, либо меньше”
/pdf_on_output_pdf$ sudo apt-get install pdftk
Building dependency tree
The following packages were automatically installed and are no longer required:
esound-common libesd0 libaudiofile0 esound-clients libaudio2
The following extra packages will be installed:
ca-certificates-java default-jre default-jre-headless gcj-4.4-base
gcj-4.4-jre-lib icedtea-6-jre-cacao java-common libaccess-bridge-java
libaccess-bridge-java-jni libbcmail-java libbcmail-java-gcj libbcprov-java
libgcj-bc libgcj-common libgcj10 libgif4 libgnuinet-java libgnujaf-java
libgnumail-java libitext-java libitext-java-gcj openjdk-6-jre
openjdk-6-jre-headless openjdk-6-jre-lib ttf-dejavu-extra tzdata tzdata-java
equivs java-virtual-machine libbcmail-java-doc libbcprov-java-gcj
libbcprov-java-doc libgcj10-dbg libgcj10-awt libgnumail-java-doc
icedtea6-plugin sun-java6-fonts ttf-sazanami-gothic ttf-kochi-gothic
ttf-sazanami-mincho ttf-kochi-mincho ttf-telugu-fonts ttf-oriya-fonts
The following NEW packages will be installed:
ca-certificates-java default-jre default-jre-headless gcj-4.4-base
gcj-4.4-jre-lib icedtea-6-jre-cacao java-common libaccess-bridge-java
libaccess-bridge-java-jni libbcmail-java libbcmail-java-gcj libbcprov-java
libgcj-bc libgcj-common libgcj10 libgif4 libgnuinet-java libgnujaf-java
libgnumail-java libitext-java libitext-java-gcj openjdk-6-jre
openjdk-6-jre-headless openjdk-6-jre-lib pdftk ttf-dejavu-extra tzdata-java
The following packages will be upgraded:
1 upgraded, 27 newly installed, 0 to remove and 375 not upgraded.
Need to get 66.4MB of archives.
After this operation, 166MB of additional disk space will be used.
Do you want to continue [Y/n]? y – соглашаемся.
Теперь отобразим информацию по нашему PDF документу :
/pdf_on_output_pdf$ pdfinfo 154.pdf
Creator: Adobe InDesign CS3 (5.0)
Producer: Adobe PDF Library 8.0
CreationDate: Mon Jan 30 23:51:23 2012 – дата подготовки документа
ModDate: Fri Mar 2 13:08:57 2012
Pages: 116 – Количество страниц в документе
Encrypted: no – Документ не зашифрован
Page size: 595.276 x 841.89 pts (A4) – Формат страниц
File size: 29301782 bytes – Размер документа в байтах
Либо вот через такую строчку:
116 – Количество страниц в PDF документе.
Вытащим из PDF документа, определённые страницы (к примеру, 5’ую) и сохраним их в PDF :
/pdf_on_output_pdf$ pdftk 154.pdf cat 5 output 5.pdf
, если нужно указать диапазон извлекаемых страниц ( c 5’ую по 10’ую) :
/pdf_on_output_pdf$ pdftk 154.pdf cat 5-10 output 5.pdf
, если нужно извлечь все страницы каждая в отдельный pdf документ:
/pdf_on_output_pdf$ pdftk 154.pdf burst

В итоге мы получили файл содержащий метаинформацию по исходному PDF документу и каждую страницу представленную в формате PDF. Что нам собственно и требовалось. На этом всё, удачи.
Используйте прокси ((заблокировано роскомнадзором, используйте vpn или proxy)) при использовании Telegram клиента:
Поблагодари автора и новые статьи
будут появляться чаще :)
Карта МКБ: 4432-7300-2472-8059
Большое спасибо тем кто благодарит автора за практические заметки небольшими пожертвованиями. С уважением, Олло Александр aka ekzorchik.
Я много часов искал быстрый и простой, но в основном точный способ узнать количество страниц в документе PDF. Поскольку я работаю в компании по полиграфической печати и репродукции, которая много работает с PDF-файлами, необходимо точно знать количество страниц в документе, прежде чем они будут обработаны. PDF-документы поступают от многих разных клиентов, поэтому они не создаются в одном приложении и / или не используют один и тот же метод сжатия.
Использование FPDI (библиотека PHP)
FPDI прост в использовании и установке (просто извлеките файлы и вызовите сценарий PHP), НО многие методы сжатия не поддерживаются FPDI. Затем он возвращает ошибку:
Ошибка FPDF: в этом документе (test_1.pdf), вероятно, используется метод сжатия, который не поддерживается бесплатным анализатором, поставляемым с FPDI.
Открытие потока и поиск с регулярным выражением:
Это открывает файл PDF в потоке и ищет какую-то строку, содержащую количество страниц или что-то подобное.
- /\/Count\s+(\d+)/ (ищет /Count <number> ) не работает, потому что только несколько документов содержат параметр /Count внутри, поэтому в большинстве случаев он ничего не возвращает. Источник.
- /\/Page\W*(\d+)/ (ищет /Page<number> ) не получает количество страниц, в основном содержит некоторые другие данные. Источник.
- /\/N\s+(\d+)/ (ищет /N <number> ) тоже не работает, поскольку документы могут содержать несколько значений /N ; большинство, если не все, не содержат количество страниц. Источник.
Итак, что же работает надежно и точно?
Простой исполняемый файл командной строки с именем: pdfinfo .
Его можно загрузить для Linux и Windows. Вы загружаете сжатый файл, содержащий несколько небольших программ, связанных с PDF. Извлеките его куда-нибудь.
Один из этих файлов - pdfinfo (или pdfinfo.exe для Windows). Пример данных, возвращаемых при их запуске в PDF-документе:
Я не видел PDF-документа, в котором он возвращал бы ложное количество страниц (пока). Это также очень быстро, даже с большими документами размером 200+ МБ время отклика составляет всего несколько секунд или меньше.
Здесь, в PHP, есть простой способ извлечь количество страниц из вывода:
Конечно, этот инструмент командной строки можно использовать на других языках, которые могут анализировать вывод внешней программы, но я использую его в PHP.
Я знаю, что это не чистый PHP , но внешние программы способом лучше обрабатывают PDF (как видно из вопроса).
Я надеюсь, что это может помочь людям, потому что я потратил много времени, пытаясь найти решение этой проблемы, и я видел много вопросов о количестве страниц PDF, в которых я не нашел ответа, который искал. Поэтому я задал этот вопрос и сам на него ответил.
Пакет R pdftools и функция pdf_info() предоставляет информацию о количестве страниц в pdf.
Вот командный сценарий Windows с использованием gsscript, который сообщает номер страницы файла PDF.
Вот функция R , которая сообщает номер страницы файла PDF с помощью команды pdfinfo .
Я создал класс-оболочку для pdfinfo на случай, если он кому-то будет полезен, на основе ответа Ричарда @
Поскольку вы не против использовать утилиты командной строки, вы можете использовать cpdf (Microsoft Windows / Linux /Mac OS X). Чтобы узнать количество страниц в одном PDF:
Если у вас есть доступ к оболочке, самым простым (но не применимым в 100% PDF-файлов) подходом было бы использование grep .
Это должно вернуть только количество страниц:
- -m 1 необходимо, так как некоторые файлы могут иметь более одного совпадения с шаблоном регулярного выражения (необходимо заменить его расширением решения регулярного выражения только для совпадения)
- -a необходимо для обработки двоичного файла как текста
- -o , чтобы показать только совпадение
- -P для использования регулярного выражения Perl
Объяснение регулярного выражения:
- начальный "разделитель": (?<=\/N ) ретроспективный просмотр /N (nb. пробел здесь не отображается)
- фактический результат: \d+ любое количество цифр
- окончание "разделителя": (?=\/) просмотр вперед /
Примечание: если в каком-то случае совпадение не найдено, можно с уверенностью предположить, что существует только 1 страница.
Кажется, это работает очень хорошо, без необходимости в специальных пакетах или выводе команды синтаксического анализа.
Вот простой пример, чтобы получить количество страниц в PDF с помощью PHP.
Если вы не можете установить какие-либо дополнительные пакеты, вы можете использовать этот простой однострочник:
Вы можете использовать qpdf , как показано ниже. Если файл имя_файла.pdf содержит 100 страниц,
Проще всего использовать ImageMagick .
Вот пример кода
В противном случае вы также можете использовать библиотеки PDF , такие как MPDF или TCPDF для PHP
Многие знают о формате Portable Document Format, благодаря которому мы видим на различных платформах документ так как его задумал автор. Чаще всего нам нужно просто прочесть какое-либо руководство в формате PDF и в Linux есть масса программ для просмотра. А что если нужно не только прочесть pdf файл?
что такое пдф?
Это прежде всего формат документа (Portable Document Format (PDF)), который был придуман фирмой Adobe Systems. Формат пдф был задуман как межплатформенный открытый формат электронных документов, что означает для пользователя избавление от массы проблем. Если вы видите документ в формате pdf на экране вашего устройства, то точно так же он будет выглядеть при печати. Вас не будут волновать размер полей, наличие шрифтов в системе и т.д. На практике, всё не так радужно, но, в целом, документы пдф вызывают меньше проблем, чем остальные. Не даром, формат пдф стал стандартом распространения различных справочных руководств. Считается хорошим тоном отправлять документы в формате pdf вашим адресатам, если не подразумевается дальнейшая правка. Формат пдф включает в себя механизм электронных подписей для защиты и проверки подлинности документов, что позволяет легко убедиться в авторстве документа.
pdfgrep. Поиск в pdf.
Если вы хоть раз использовали мощную утилиту grep, то вам сразу будет ясна работа pdfgrep. Отличие только одно. Grep оперирует строками, а PdfGrep страницами. PdfGrep умеет использовать мощь регулярных выражений, обходить рекурсивно каталоги при поиске, подсвечивать найденное.
comparepdf. Сравнение файлов pdf.
Вам стоит знать, что comparepdf не выводит вам в каком-либо виде различающиеся части. Утилита заточена под вызовы из программ для диагностирования самого факта различия или идентичности в pdf. Если вам необходим инструмент визуального сравнения документов, то переходите к Diffpdf.
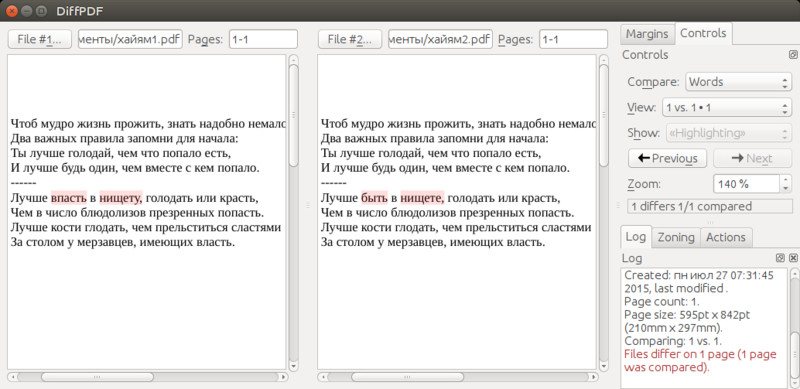
Diffpdf.
DiffPDF используется для сравнения двух файлов формата PDF. По умолчанию в каждой паре страниц сравнивается текст, но можно сравнить и внешний вид. Например, изменение вставленной диаграммы или стиля абзаца. Кроме того, можно сравнить определённые страницы или страницы в определённых диапазонах. Например, если в первой версии файла формата PDF имеются страницы от 1 до 12, а во второй - от 1 до 13 (вставлена дополнительная страница 4), эти версии можно сравнить, страницы первой версии файла указав в диапазоне 1-12, а страницы второй — в диапазонах 1-3 и 5-13. Таким образом, DiffPDF выполнит сравнение страниц в следующих парах: (1,1), (2, 2), (3, 3), (4, 5), (5, 6) и далее до (12, 13).
Картинки в pdf.
Если у вас есть серия изображений типа pic_*.jpg, то преобразовать в pdf можно командой ls -v | tr '\n' ' ' | sed 's/$/\ result.pdf/' | xargs convert Причём pic_10.jpg будет после pic_9.jpg, а не после pic_1.jpg, благодаря ключу -v.
PDF Toolkit (pdftk).
Если PDF документ - это "электронная бумага", то pdftk - это степлер, дырокол, сшиватель в одном флаконе. pdftk, словно швейцарский нож, умеет:
Из PDF в текст. Конвертер PDF.
Вызов pdftotext document.pdf document.txt позволит вам извлечь текст из pdf. Можно сразу вывести текст в простой html или xml. Если текст в pdf есть на фиксированных позициях, то есть возможность указать координаты и текст будет извлечён именно оттуда. Вызывая pdftotext document.pdf - | grep НужнаяСтрока , можно сымитировать работу pdfgrep.
Из PDF вытащить картинки.
Вызов pdfimages -j document.pdf images/ приведёт к тому, что в подкаталоге images/ будут находиться извлечённые файлы в формате PBM для монохромных изображений и PPM для цветных. Опции -png, -tiff, -j, -jp2 и -jbig2 сохранят соответственно в форматах PNG, TIFF, JPEG, JPEG2000 и JBIG2.
Из CHM в PDF.
Если хотите преобразовать свою коллекцию различных руководств в формате Microsoft Compiled HTML Help в Portable Document Format, то в этом поможет утилита командной строки chm2pdf. chm2pdf поддерживает пакетный режим, опции безопасности PDF, защиту паролем и режимы сжатия.
PDF Split and Merge (pdfsam).
Нельзя не отметить java программу PDF Split and Merge (pdfsam), которая в графическом режиме позволит сделать массу вышеописанного.
PDFSaM идёт в двух версиях, обе свободны. Базовая доступна в пакетах для Debian, Ubuntu и Arch Linux. Расширенная версия обладает всем функционалом, но доступна на официальном сайте лишь в виде исходного кода, хотя учитывая язык java, проблем с запуском программы быть не должно.
Мне необходимо посчитать количество страниц в PDF-файлах (в данной дирректории и во всех вложениях) и количество этих PDF-файлов. Количество PDF-файлов - любое, количество вложенных папок - любое.
Рабочий код для подсчета количества PDF-файлов:
А вот с подсчетом количества страниц в PDF-файлах проблема. Почитал интернет - много всего говорится, но код так и не нашел. Может у кого-то есть готовый код для CMD/BAT?
Нашел код на др языках программирования, может кто-то сможет переписать эти варианты на CMD/BAT?
Вот что смог найти в интернете
Вариант 1: взял здесь:
%PDF-1.5
%вгПУ
109199 0 obj <</Linearized 1/L 9142108/O 109203/E 52524/N 1236/T 9126252/H [ 2754 12723]>>
endobj
Где $pdf_filename - путь к файлу
и здесь же указали измененный вариант кода:
__________________Помощь в написании контрольных, курсовых и дипломных работ здесь
Подсчет количества страниц в PDF файлах в каталоге: проблема с файлами с паролем
Привет)) Мне нужна программа, считающая кол-во страниц в PDF файлах в каталоге. Но у меня загвоздка.
Как получить количество страниц в документе PDF
kak iz biblioteka pdf reader (Axdpdf) shitat countpage in.vbnet
Как посчитать и записать количество строк в разных файлах
Доброго времени суток. Подскажите пожалуйста. Есть задача: список файлов (причем не эксель, а.
Как посчитать количество страниц?
Здравствуйте. Есть гостевая. Как сделать так что бы на каждой странице было по 5 записей и.
по одному файлу (жестко указанному файлу) считает классно, а как сделать, чтобы он посчитал страницы во всех PDF-файлах в данной папке и во вложенных? Количество PDF-файлов рандомное.
Решение
чтобы он посчитал страницы во всех PDF-файлах в данной папке alpap, огромное спасибо, все круто работает, считает во всех вложениях. se_arts,ограничил вывод, не знаю стало ли шустрее, например у меня по всему диску С:
Старт поиск: 8:53:41,87
Стoп поиск: 8:54:12,23
Старт запись: 8:54:12,23
Всего страниц во всех файлах PDF диска C: - 608
Стоп запись: 8:54:12,23
Измененный код (в принципе изменения только в строке 4, добавлено find "NumberOfPages")
быстрее, конечно, работать в папке, без ключа /s в dir /a-d/b/s, а еще быстрее использовать для поиска и перебора файлов pdf не cmd, например PowerShell или js, да все кроме cmd.
По времени подсчета: очень долго открывает файлы большого объема - 90-200МБ, даже файлов 5-6 может считать около минуты. Продолжаю тестить.
Читайте также: