
Linux что такое gawk
Обновлено: 29.06.2024
AWK назван в честь фамилии его авторов: Альфред Ахо, Питер Вайнбергером и Брайан Керниган. AWK очень полезный язык сценариев для обработки текста. Этот язык выполняется в интерпретаторе. Это позволяет пользователю обрабатывать некоторые входные, определять переменные, использовать логические операторы, строки и числовые функции, извлечения данных и создания отформатированных отчетов. Синтаксис AWK очень близок с языку C и является прямым предшественником Perl. Все сценарии AWK могут быть преобразованы в сценарии Perl с использованием утилиты A2P.
Для чего нужен awk?
В защиту awk
Да, у awk отнюдь не замечательное имя. Но это замечательный язык. Awk создан для обработки текста и создания отчетов, но у него много хорошо проработанных функций, дающих возможность серьезного программирования. При этом, в отличие от некоторых других языков, синтаксис awk привычен и заимствует лучшее из таких языков, как C, python и bash (хотя формально awk был создан до python и bash). Awk — один из тех языков, которые, будучи один раз выучены, становятся ключевой частью стратегического арсенала программиста.
Базовые концепции
Предпосылки
Интерпретатор AWK является стандартным инструментом, найденным на каждом дистрибутиве Linux. Пакет gawk содержит версию AWK с открытым исходным кодом, и в зависимости от дистрибутива Linux он может быть установлен из исходного файла или с помощью пакетов gawk или mawk, включенных в конкретный дистрибутив Linux.
Как работает awk?
На самом деле awk – это изначально язык программирования, предназначенный для обработки текста/данных. Поскольку, как уже отмечалось, в Linux-системах основной средой для взаимодействия между пользователем и машиной является текст, то обработка достаточно больших его объёмов вручную способна была парализовать на некоторое время процесс выполнения основной работы. Требовался инструмент для обеспечения автоматической обработки данных и позволяющий использовать эту возможность «на лету», т. е. прямо при работе в командной оболочке. Лучшим средством для достижения этой цели является использование специализированного языка программирования и регулярных выражений, которое реализовано в виде одноимённой утилиты — команды awk.
Справедливо заметить, что awk – это прежде всего Си-подобный язык программирования, но для удобства понимания, под awk принято понимать утилиту или команду. Разработчиками языка AWK являются Alfred V. Aho, Peter J. Weinberger и Brian W. Kernighan, по сокращённым инициалам которых язык и получил своё название. Создан язык в 1977 году. Кстати, на основе AWK когда-то был создан язык Perl, который и по сей день является одним из самых мощных языков для высокопроизводительной обработки данных.
В качестве исходных данных awk принимает на вход строку и после её обработки в зависимости от конкретных опций выдаёт результат. Исходные данные могут поступать из файла или из вывода другой команды/программы. Самым распространённым случаем использования awk является выборка определённых столбцов из результата вывода других команд, например:
В результате вывод будет примерно таким:
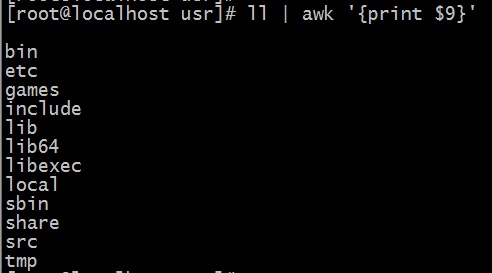
Следует напомнить, что по-умолчанию вывод команды ll выглядит следующим образом:
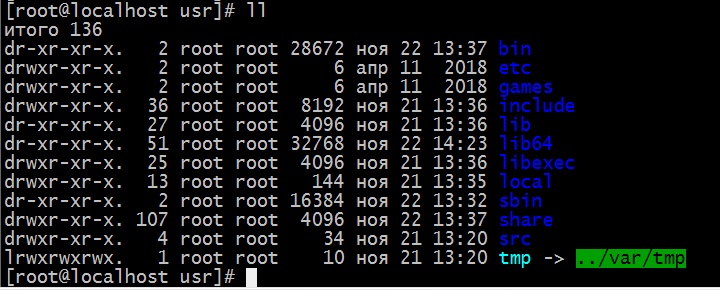
Как видно, команда awk помогла вывести только отдельный столбец из общего вывода ll – с именами каталогов и файлов.
Конечно, для решения подобных задач существует утилита grep, но awk гораздо быстрее и производительнее для обработки больших и сложных массивов данных.
Установка
Войдите на сервер через SSH с правами суперпользователя
Для того, чтобы установить утилиту командной строки AWK на CentOS/Fedora или на любую другую на основе RPM распределения Linux, выполните следующую команду:
yum install gawk
В Ubuntu/Debian, вам нужно вызвать эту команду, чтобы установить Gawk:
apt-get install gawk
Примеры команды AWK
Простые команды awk могут быть легко запущены из командной строки, а для более сложных задач должны быть записаны в виде сценариев awk в файл. Ниже перечислены некоторые полезные примеры команд awk и исполняемых скриптов.
Вы можете использовать команду AWK для печати только определенных столбцов из поля ввода. Например, с помощью команды приведенной ниже вы можете узнать список IP-адресов, которые подключены к серверу:
Это очень полезно, если вы расследуете, находиться ли ваш сервер под атакой DoS или DDoS.
В следующем примере мы используем AWK для поиска конкретного шаблона в определенных столбцах и делаем какое-то действие, на основе результата:
exim -bpr | grep frozen | awk | xargs exim -Mrm
AWK часто используется для выполнения полезной и практической обработки и манипуляции текста. Например, мы можем использовать AWK для удаления дубликатов в текстовом файле без сортировки:
Следующая команда напечатает пять случайных чисел от 0 до 999:
Используйте следующую команду, чтобы подсчитать количество строк в файле с именем «sample_file»:
Следующая команда выведет все строки в файле «sample_file», которые содержат строки, начинающиеся с ‘ A ‘ или ‘a’, за которыми следует ‘ re’:
Вы можете использовать команду AWK для более сложных операций. Если ваш веб-сайт работает довольно медленно, вы можете использовать следующую команду, чтобы проверить, есть ли какая-то проблема с диском I/O (и/или сети, в некоторых редких случаях):
IOWAIT означает, как долго процессы блокируются занятые вводом/выводом, в основном дискового хранения или, возможно, сети. STEAL означает, как долго процессы блокируются удачей CPU Time slice на сервере. Выше iowait на время процессора пользователя (=USER + NICE + SYSTEM) показывает занят ввода / вывода, выше украсть просматривается показывает занят CPU.
Следующий сценарий использует простую команду awk, которая выполняет поиск во входном файле ‘/etc/passwd ‘ и предоставляет вывод с именем пользователя, за которым следует дата и время последнего входа:
Сделайте скрипт исполняемым:
chmod 755 login-check
Вы должны состоянии увидеть учетные записи пользователей, доступных на сервере, а затем по дате и времени последнего входа в систему каждого пользователя.
Первый шаг в awk
Давайте начнем и попробуем поэкспериментировать с awk, чтобы увидеть, как он работает. В командной строке введем следующую команду:
В результате должно быть показано содержимое файла /etc/passwd. Теперь — объяснение того, что делал awk. Вызывая awk, мы указали /etc/passwd в качестве входного файла. Когда мы запустили awk, он обработал команду print для каждой строки в /etc/passwd по порядку. Весь вывод отправлен в stdout, и мы получили результат, идентичный результату команды cat /etc/passwd. Теперь объясним блок < print >. В awk фигурные скобки используются для группирования блоков текста, как в C. В нашем блоке текста есть лишь одна команда print. В awk команда print без дополнительных параметров печатает все содержимое текущей строки.
Вот еще один пример программы на awk, которая делает то же самое:
В awk переменная $0 представляет всю текущую строку, поэтому print и print $0 делают в точности одно и то же. Если угодно, можно создать программу на awk, которая будет выводить данные, совершенно не связанные с входными данными. Вот пример:
Если запустить этот скрипт, он заполнит экран словами «ура». 🙂
Множественные поля
Awk хорошо подходит для обработки текста, разбитого на множество логических полей, и дает возможность без усилий обращаться к каждому отдельному полю из awk-скрипта. Следующий скрипт распечатает список всех учетных записей в системе:
Вот фрагмент из вывода на экран этого скрипта:
Как видим, awk выводит первое и третье поля файла /etc/passwd, которые представляют собой соответственно поля имени пользователя и uid. При этом, хотя скрипт и работает, он не совершенен — нет пробелов между двумя выходными полями! Те, кто привык программировать в bash или python, возможно ожидали, что команда print $1 $3 вставит пробел между этими двумя полями. Однако когда в программе на awk две строки оказываются рядом друг с другом, awk сцепляет их без добавления между ними пробела. Следующая команда вставит пробел между полями:
В результате получаем такой вывод:
Использование awk в Linux
Да, использование фигурных скобок немного непривычно, но это только в первое время. Вы уже догадались как напечатать второе, третье, четвертое, или другие поля? Правильно это $2, $3, $4 соответственно.
Иногда необходимо представить данные в определенном формате, например, выбрать несколько слов. AWK легко справляется с группировкой нескольких полей и даже позволяет включать статические данные:
Но разделитель не обязательно заключать в кавычки. Следующий вывод аналогичен предыдущему:
Иногда нужно обработать данные с неизвестным количеством полей. Если вам нужно выбрать последнее поле можно воспользоваться переменной $NF. Вот так вы можете вывести последнее поле:
Также вы можете использовать переменную $NF для получения предпоследнего поля:
Или поля с середины:
Все это можно сделать с помощью таких утилит как sed, cut и grep но это будет намного сложнее.
Как я рассказывал выше, awk обрабатывает одну строку за раз, вот этому подтверждение:
А вот пример фильтрации с помощью условия, выведем только строку, в которой содержится текст one:
А вот пример использования операций с переменными:
Это означает что мы должны выполнять следующий блок кода для каждой строки. Это можно использовать, например, для подсчета количества переданных данных по запросам из журнала веб-сервера.
Представьте себе, у нас есть журнал доступа, который выглядит так:
Мы можем подсчитать, что количество переданных байт, это десятое поле. Дальше идёт User-Agent пользователя и он нам не интересен:
Вот так можно подсчитать количество байт:
Это только несколько примеров показывающих использование awk в Linux , освоив awk один раз в получите очень мощный и полезный инструмент на всю жизнь.
Синтаксис команды awk
С помощью действия можно выполнять преобразования с обрабатываемой строкой. Об этом мы поговорим позже, а сейчас давайте рассмотрим опции утилиты:
Это далеко не все опции awk, однако их вам будет достаточно на первое время. Теперь перечислим несколько функций-действий, которые вы можете использовать:
Функций намного больше, но чтобы не загромождать статью я привел только те, которые мы будем использовать сегодня, а также ещё несколько для чтобы вы могли оценить масштаб возможностей утилиты.
В функциях-действиях можно использовать различные переменные и операторы, вот несколько из них:
Кроме этих переменных, есть и другие, а также можно объявлять свои.
Условиепозволяет обрабатывать только те строки, в которых содержатся нужные нам данные, его можно использовать в качестве фильтра, как grep. А ещё условие позволяет выполнять определенные блоки кода awk для начала и конца файла, для этого вместо регулярного выражения используйте директивы BEGIN (начало) и END (конец). Там ещё есть очень много всего, но на сегодня пожалуй достаточно. Теперь давайте перейдем к примерам.
5. Заключение
Как вы можете видеть, с помощью awk вы можете выполнять большое количество операций по обработке текста и множество других полезных вещей. Мы не вдавались в более сложные предметы, такие как предопределенные функции awk, но мы показали достаточно (как мы надеемся), чтобы вы запомнили, каким мощным инструментом является awk.
Команда gawk в Linux используется для сканирования шаблонов и языка обработки. Команда awk не требует компиляции и позволяет пользователю использовать переменные, числовые функции, строковые функции и логические операторы. Это утилита, которая позволяет программистам писать крошечные и эффективные программы в форме операторов, определяющих текстовые шаблоны, которые нужно искать, в текстовом документе и действиях, которые необходимо предпринять, когда в строке найдено совпадение.
Команда gawk может быть использована для:
- Сканирует файл построчно.
- Разбивает каждую строку ввода на поля.
- Сравнивает входную строку / поля с шаблоном.
- Выполняет действие (я) на согласованных линиях.
- Преобразование файлов данных.
- Создание отформатированных отчетов.
- Форматировать выходные строки.
- Арифметические и строковые операции.
- Условные и петли.
Синтаксис:
Некоторые важные параметры:
- -f progfile, –file = progfile: считывать исходный код программы AWK из файла program-file, а не из первого аргумента командной строки. Можно использовать несколько опций -f (или -file).
- -F fs, –field-separator = fs: в качестве разделителя входных полей используется FS (значение предопределенной переменной FS).
- -v var = val, –assign = var = val: присвоить значение val переменной var до начала выполнения программы.
Примеры:
-
-F: в качестве разделителя поля ввода используется FS (значение предопределенной переменной FS).


Некоторые встроенные переменные:
- NR: Текущий счетчик количества строк ввода.
- NF: Он ведет подсчет количества полей в текущей входной записи.
- FS: содержит символ разделителя полей, который используется для разделения полей в строке ввода.
- RS: хранит символ разделителя текущей записи.
- OFS: хранит разделитель выходных полей, который разделяет поля, когда Awk печатает их.
- ORS: хранит разделитель выходных записей, который разделяет выходные строки, когда Awk печатает их.
Примеры:



Пример дополнительных команд с примерами:
-
Рассмотрим следующий образец текстового файла в качестве входного файла для всех случаев ниже.
Чтобы создать текстовый файл:




В приведенном выше примере, $ 2 представляет Monile №. поле.




Замечания:
- Чтобы проверить страницу руководства команды gawk, используйте следующую команду:
- Чтобы проверить страницу справки команды gawk, используйте следующую команду:
В отличие от большинства других процедурных языков программирования, awk управляется данными, что означает, что вы определяете набор действий, выполняемых с вводимым текстом. Он принимает входные данные, преобразует их и отправляет результат на стандартный вывод.
В этой статье рассматриваются основы языка программирования awk. Знание основ awk значительно улучшит вашу способность манипулировать текстовыми файлами в командной строке.
Как работает awk
Записи и поля
Записи состоят из полей, разделенных разделителем полей. По умолчанию поля разделяются пробелом, включая один или несколько символов табуляции, пробела и новой строки.
Вот визуальное представление, показывающее, как ссылаться на записи и поля:
Программа awk
Чтобы обработать текст с помощью awk , вы пишете программу, которая сообщает команде, что делать. Программа состоит из ряда правил и пользовательских функций. Каждое правило содержит одну пару шаблон и действие. Правила разделяются новой строкой или точкой с запятой ( ; ). Обычно awk-программа выглядит так:
Когда awk обрабатывает данные, если шаблон соответствует записи, он выполняет указанное действие с этой записью. Если у правила нет шаблона, все записи (строки) совпадают.
Действие awk заключено в фигурные скобки ( <> ) и состоит из операторов. Каждый оператор определяет операцию, которую нужно выполнить. В действии может быть несколько операторов, разделенных новой строкой или точкой с запятой ( ; ). Если правило не имеет действия, по умолчанию выполняется печать всей записи.
Awk поддерживает различные типы операторов, включая выражения, условные операторы, операторы ввода, вывода и т. Д. Наиболее распространенные операторы awk:
Выполнение программ awk
Программа awk может быть запущена несколькими способами. Если программа короткая и простая, ее можно передать непосредственно интерпретатору awk из командной строки:
Если программа большая и сложная, лучше всего поместить ее в файл и использовать параметр -f для передачи файла команде awk :
В приведенных ниже примерах мы будем использовать файл с именем «team.txt», который выглядит примерно так:
Шаблоны AWK
Шаблоны в awk определяют, следует ли выполнять соответствующее действие.
Awk поддерживает различные типы шаблонов, включая регулярное выражение, выражение отношения, диапазон и шаблоны специальных выражений.
Если у правила нет шаблона, сопоставляется каждая входная запись. Вот пример правила, содержащего только действие:
Программа распечатает третье поле каждой записи:
Шаблоны регулярных выражений
Шаблон может быть любым типом расширенного регулярного выражения. Вот пример, который печатает первое поле, если запись начинается с двух или более цифр:
Шаблоны реляционных выражений
Шаблоны реляционных выражений обычно используются для сопоставления содержимого определенного поля или переменной.
По умолчанию шаблоны регулярных выражений сопоставляются с записями. Чтобы сопоставить регулярное выражение с полем, укажите поле и используйте оператор сравнения «содержать» (
Например, чтобы напечатать первое поле каждой записи, второе поле которой содержит «ia», вы должны ввести:
Чтобы сопоставить поля, которые не содержат заданного шаблона, используйте оператор !
Вы можете сравнивать строки или числа для таких отношений, как, больше, меньше, равно и т. Д. Следующая команда печатает первое поле всех записей, третье поле которых больше 50:
Шаблоны диапазонов
Шаблоны диапазонов состоят из двух шаблонов, разделенных запятой:
Все записи, начинающиеся с записи, соответствующей первому шаблону, до совпадения с записью, соответствующей второму шаблону.
Вот пример, который напечатает первое поле всех записей, начиная с записи, включая «Raptors», до записи, включающей «Celtics»:
Шаблоны также могут быть выражениями отношений. Приведенная ниже команда распечатает все записи, начиная с той, четвертое поле которой равно 32, до той, четвертое поле которой равно 33:
Шаблоны диапазона нельзя комбинировать с другими выражениями шаблона.
Специальные шаблоны выражения
Awk включает следующие специальные паттерны:
Шаблон BEGIN обычно используется для установки переменных, а шаблон END для обработки данных из записей, таких как вычисления.
В следующем примере печатается «Начать обработку.», Затем печатается третье поле каждой записи и, наконец, «Завершить обработку».
Если программа имеет только шаблон BEGIN , действия выполняются, а ввод не обрабатывается. Если в программе есть только шаблон END , ввод обрабатывается перед выполнением действий правила.
Версия awk для Gnu также включает еще два специальных шаблона BEGINFILE и ENDFILE , которые позволяют выполнять действия при обработке файлов.
Комбинирование узоров
Awk позволяет комбинировать два или более шаблонов, используя логический оператор И ( && ) и логический оператор ИЛИ ( || ).
Вот пример, в котором оператор && используется для печати первого поля той записи, у которой третье поле больше 50, а четвертое поле меньше 30:
Встроенные переменные
Awk имеет ряд встроенных переменных, которые содержат полезную информацию и позволяют управлять обработкой программы. Ниже приведены некоторые из наиболее распространенных встроенных переменных:
Вот пример, показывающий, как напечатать имя файла и количество строк (записей):
Переменные в AWK могут быть установлены в любой строке программы. Чтобы определить переменную для всей программы, поместите ее в шаблон BEGIN .
Изменение поля и разделителя записей
Например, чтобы установить разделитель полей . вы бы использовали:
Разделитель полей также может содержать более одного символа:
При запуске однострочных команд awk в командной строке вы также можете использовать параметр -F для изменения разделителя полей:
По умолчанию разделителем записей является символ новой строки, который можно изменить с помощью переменной RS .
Вот пример, показывающий, как изменить разделитель записей на . :
Действия при отсутствии нагрузки
Действия awk заключаются в фигурные скобки ( <> ) и выполняются при совпадении с шаблоном. Действие может иметь ноль или более утверждений. Несколько операторов выполняются в том порядке, в котором они появляются, и должны быть разделены новой строкой или точкой с запятой ( ; ).
В awk поддерживается несколько типов операторов действий:
- Выражения, такие как присваивание переменных, арифметические операторы, операторы увеличения и уменьшения.
- Управляющие операторы, используемые для управления потоком программы ( if , for , while , switch и т. Д.)
- Операторы вывода, такие как print и printf .
- Составные утверждения, чтобы сгруппировать другие утверждения.
- Операторы ввода, чтобы управлять обработкой ввода.
- Операторы удаления для удаления элементов массива.
Оператор print вероятно, является наиболее часто используемым оператором awk. Он печатает форматированный вывод текста, записей, полей и переменных.
При печати нескольких элементов их нужно разделять запятыми. Вот пример:
Печатные материалы разделяются одиночными пробелами:
Если вы не используете запятые, между элементами не будет пробелов:
Печатные элементы объединены:
Когда print используется без аргументов, по умолчанию используется print $0 . Текущая запись будет напечатана.
Чтобы напечатать собственный текст, вы должны заключить текст в двойные кавычки:
Вы также можете печатать специальные символы, такие как новая строка:
Оператор printf дает вам больше контроля над форматом вывода. Вот пример вставки номеров строк:
printf не создает новую строку после каждой записи, поэтому мы используем n :
Следующая команда вычисляет сумму значений, хранящихся в третьем поле в каждой строке:
Вот еще один пример, показывающий, как использовать выражения и управляющие операторы для печати квадратов чисел от 1 до 5:
Однострочные команды, подобные приведенной выше, труднее понять и поддерживать. При написании более длинных программ следует создать отдельный программный файл:
Запустите программу, передав имя файла интерпретатору awk :
Вы также можете запустить программу awk как исполняемый файл, используя директиву shebang и установив интерпретатор awk :
Теперь вы можете запустить программу, введя:
Использование переменных оболочки в программах AWK
Выводы
Эта статья едва затрагивает поверхность языка программирования awk. Чтобы узнать больше об awk, ознакомьтесь с официальной документацией Gawk .
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Текст это сердце Unix. Философия "все есть файл" полностью пронизывает всю систему и разработанные для нее инструменты. Вот почему работа с текстом является одним из обязательных навыков не только системного администратора, но и обычного пользователя Linux, который хочет поглубже разобраться в этой операционной системе.
Команда awk - один из самых мощных инструментов для обработки и фильтрации текста, доступный даже для людей никак не связных с программированием. Это не просто утилита, а целый язык разработанный для обработки и извлечения данных. В этой статье мы разберемся как пользоваться awk.
Синтаксис команды awk
Сначала надо понять как работает утилита. Она читает документ по одной строке за раз, выполняет указанные вами действия и выводит результат на стандартный вывод. Одна из самых частых задач, для которых используется awk - это выборка одной из колонок. Все параметры awk находятся в кавычках, а действие, которое надо выполнить - в фигурных скобках. Вот основной её синтаксис:
$ awk опции ' условие < действие >'
$ awk опции ' условие < действие >условие < действие >'
С помощью действия можно выполнять преобразования с обрабатываемой строкой. Об этом мы поговорим позже, а сейчас давайте рассмотрим опции утилиты:
- -F, --field-separator - разделитель полей, используется для разбиения текста на колонки;
- -f, --file - прочитать данные не из стандартного вывода, а из файла;
- -v, --assign - присвоить значение переменной, например foo=bar;
- -b, --characters-as-bytes - считать все символы однобайтовыми;
- -d, --dump-variables - вывести значения всех переменных awk по умолчанию;
- -D, --debug - режим отладки, позволяет вводить команды интерактивно с клавиатуры;
- -e, --source - выполнить указанный код на языке awk;
- -o, --pretty-print - вывести результат работы программы в файл;
- -V, --version - вывести версию утилиты.
Это далеко не все опции awk, однако их вам будет достаточно на первое время. Теперь перечислим несколько функций-действий , которые вы можете использовать:
- print(строка) - вывод чего либо в стандартный поток вывода;
- printf(строка) - форматированный вывод в стандартный поток вывода;
- system(команда) - выполняет команду в системе;
- length(строка) - возвращает длину строки;
- substr(строка, старт, количество) - обрезает строку и возвращает результат;
- tolower(строка) - переводит строку в нижний регистр;
- toupper(строка) - переводить строку в верхний регистр.
Функций намного больше, но чтобы не загромождать статью я привел только те, которые мы будем использовать сегодня, а также ещё несколько для чтобы вы могли оценить масштаб возможностей утилиты.
В функциях-действиях можно использовать различные переменные и операторы, вот несколько из них:
- FNR - номер обрабатываемой строки в файле;
- FS - разделитель полей;
- NF - количество колонок в данной строке;
- NR - общее количество строк в обрабатываемом тексте;
- RS - разделитель строк, по умолчанию символ новой строки;
- $ - ссылка на колонку по номеру.
Кроме этих переменных, есть и другие, а также можно объявлять свои.
Условие позволяет обрабатывать только те строки, в которых содержатся нужные нам данные, его можно использовать в качестве фильтра, как grep. А ещё условие позволяет выполнять определенные блоки кода awk для начала и конца файла, для этого вместо регулярного выражения используйте директивы BEGIN (начало) и END (конец). Там ещё есть очень много всего, но на сегодня пожалуй достаточно. Теперь давайте перейдем к примерам.
Использование awk в Linux
Простейшая и часто востребованная задача - выборка полей из стандартного вывода. Вы не найдете более подходящего инструмента для решения этой задачи, чем awk. По умолчанию awk разделяет поля пробелами. Если вы хотите напечатать первое поле, вам нужно просто использовать функцию print и передать ей параметр $1, если функция одна, то скобки можно опустить:
echo 'one two three four' | awk ''
Да, использование фигурных скобок немного непривычно, но это только в первое время. Вы уже догадались как напечатать второе, третье, четвертое, или другие поля? Правильно это $2, $3, $4 соответственно.
echo 'one two three four' | awk ''
Иногда необходимо представить данные в определенном формате, например, выбрать несколько слов. AWK легко справляется с группировкой нескольких полей и даже позволяет включать статические данные:
echo 'one two three four' | awk ''
Если поля разделены не пробелами, а другим разделителем, просто укажите в параметре -F нужный разделитель в кавычках, например ":" :
echo 'one mississippi:two mississippi:three mississippi:four mississippi' | awk -F":" ''
Но разделитель не обязательно заключать в кавычки. Следующий вывод аналогичен предыдущему:
echo 'one mississippi:two mississippi:three mississippi:four mississippi' | awk -F: ''
Иногда нужно обработать данные с неизвестным количеством полей. Если вам нужно выбрать последнее поле можно воспользоваться переменной $NF. Вот так вы можете вывести последнее поле:
echo 'one two three four' | awk ''
Также вы можете использовать переменную $NF для получения предпоследнего поля:
echo 'one two three four' | awk ''
Или поля с середины:
echo 'one two three four five' | awk ''
Все это можно сделать с помощью таких утилит как sed, cut и grep но это будет намного сложнее.
Как я рассказывал выше, awk обрабатывает одну строку за раз, вот этому подтверждение:
echo -e 'one 1\n two 2' | awk ''
А вот пример фильтрации с помощью условия, выведем только строку, в которой содержится текст one:
echo -e 'one 1\n two 2' | awk '/one/ '
А вот пример использования операций с переменными:
echo -e 'one 1\n two 2' | awk ' END '
Это означает что мы должны выполнять следующий блок кода для каждой строки. Это можно использовать, например, для подсчета количества переданных данных по запросам из журнала веб-сервера.
Представьте себе, у нас есть журнал доступа, который выглядит так:
Мы можем подсчитать, что количество переданных байт, это десятое поле. Дальше идёт User-Agent пользователя и он нам не интересен:
cat /var/log/apache2/access.log | awk ''
Вот так можно подсчитать количество байт:
Это только несколько примеров показывающих использование awk в Linux , освоив awk один раз в получите очень мощный и полезный инструмент на всю жизнь.
Читайте также: