
Linux количество одинаковых строк
Обновлено: 04.07.2024
Здесь представлен фрагмент будущей книги «Основные инструменты и практики для начинающего разработчика программного обеспечения» Бальтазара Рубероля и Этьена Броду. Книга должна помочь образованию подрастающего поколения разработчиков. Она охватит такие темы, как освоение консоли, настройка и эффективная работа в командной оболочке, управление версиями кода с помощью git , основы SQL, инструменты вроде Make , jq и регулярные выражения, основы сетевого взаимодействия, а также лучшие практики разработки программного обеспечения и совместной работы. В настоящее время авторы упорно работают над этим проектом и приглашают всех поучаствовать в списке рассылки.
Одна из причин, которые делают командную оболочку бесценным инструментом, — это большое количество команд обработки текста и возможность легко объединять их в конвейер, создавая сложные шаблоны обработки. Эти команды делают тривиальными многие задачи по анализу текста и данных, преобразованию данных между разными форматами, по фильтрации строк и т. д.
При работе с текстовыми данными главный принцип заключается в том, чтобы разбить любую сложную проблему на множество более мелких — и решить каждую из них с помощью специализированного инструмента.
Заставьте каждую программу хорошо выполнять одну функцию — «Основы философии Unix»
Примеры из этой главы на первый взгляд могут показаться немного надуманными, но это сделано специально. Каждый из инструментов разработан для решения одной небольшой задачи. Однако в сочетании они становятся чрезвычайно мощными.
Мы рассмотрим некоторые из наиболее распространенных и полезных команд обработки текста в командной оболочке и продемонстрируем реальные рабочие процессы, соединяющие их вместе. Я предлагаю взглянуть на маны этих команд, чтобы увидеть всю широту возможностей в вашем распоряжении.
Файл CSV с примерами доступен в онлайне. Можете скачать его для проверки материала.
Команда cat используется для составления списка из одного или нескольких файлов и отображения их содержимого на экране.
head выводит первые n строк в файле. Это может быть очень полезно для того, чтобы заглянуть в файл неизвестной структуры и формата, не заваливая всю консоль кучей текста.
Если -n не указано, head выводит первые десять строк указанного файла или входящего потока.
tail — аналог head , только он выводит последние n строк в файле.
Если хотите вывести все строки, расположенном после n-й строки (включая её), можете использовать аргумент -n +n .
В нашем файле 43 строки, поэтому tail -n +42 выводит только 42-ю и 43-ю строки из него.
Если параметр -n не указан, tail выведет последние десять строк в указанном файле или входном потоке.
tail -f или tail --follow отображают последние строки в файле и каждую новую строку по мере записи в файл. Это очень полезно для просмотра активности в реальном времени, например, что записывается в логи веб-сервера и т. д.
wc (word count) выводит количество символов ( -c ), слов ( -w ) или строк ( -l ) в указанном файле или потоке.
По умолчанию отображается всё вышеперечисленное.
Если текстовые данные передаются по конвейеру или перенаправлены в stdin , то отображается только счётчик.
grep — это швейцарский нож фильтрации строк по заданному шаблону.
Например, можем найти все вхождения слова mutex в файле.
grep может обрабатывать либо файлы, указанные в качестве аргументов, либо поток текста, переданный на его stdin . Таким образом, мы можем сцеплять несколько команд grep для дальнейшей фильтрации текста. В следующем примере мы фильтруем строки в нашем файле metadata.csv , чтобы найти строки, содержащие и mutex, и OS.
Рассмотрим некоторые опции grep и их поведение.
grep -v выполняет инвертное сопоставление: фильтрует строки, которые не соответствуют шаблону аргументов.
grep -i выполняет сопоставление без учёта регистра. В следующем примере grep -i os находит как OS, так и os.
grep -l выводит список файлов, содержащих совпадение.
Команда grep -c подсчитывает, сколько раз найден образец.
grep -r рекурсивно ищет файлы в текущем рабочем каталоге и всех его подкаталогах.
grep -w показывает только совпадающие целиком слова.
cut извлекает часть файла (или, как обычно, входного потока). Команда определяет разделитель полей (который разделяет столбцы) с помощью опции -d , а порядковые номера столбцов для извлечения с помощью опции -f .
Например, следующая команда извлекает первый столбец из последних пяти строк нашего CSV-файла.
Поскольку мы имеем дело с CSV, то столбцы разделяются запятой, а за извлечение первого столбца отвечает опция -f 1 .
Можно выбрать и первый, и второй столбцы, используя опцию -f 1,2 .
paste объединяет вместе два разных файла в один многоколоночный файл.
По умолчанию paste использует разделитель табуляции, но его можно изменить с помощью параметра -d .
Ещё один распространённый способ использования paste — объединение всех строк в потоке или файле с помощью заданного разделителя, используя комбинацию аргументов -s и -d .
Если в качестве входного файла указан параметр - , то вместо него будет считываться stdin .
Команда sort , собственно, сортирует данные (в указанном файле или входном потоке).
sort -r выполняет обратную сортировку.
sort -n сортирует поля по их арифметическому значению.
uniq обнаруживает и отфильтровывает соседние одинаковые строки в указанном файле или входном потоке.
Поскольку uniq отфильтровывает только соседние строки, в наших данных могут ещё остаться дубликаты. Чтобы отфильтровать все одинаковые строки из файла, нужно сначала отсортировать его содержимое.
uniq -c в начале каждой строки вставляет количество её вхождений.
uniq -u отображает только уникальные строки.
Примечание. uniq особенно полезен в сочетании с сортировкой, поскольку конвейер | sort | uniq позволяет удалить все дублирующиеся строки в файле или потоке.
awk — это чуть больше, чем просто инструмент обработки текста: на самом деле у него целый язык программирования. В чём awk действительно хорош — так это в разбиении файлов на столбцы, и делает это с особенным блеском, когда в файлах перемешаны пробелы и табы.
Как видим, столбцы разделены либо пробелами, либо табуляциями, и не всегда одинаковым количеством пробелов. cut здесь бесполезен, потому что работает только с одним символом-разделителем. Но awk легко разберётся с таким файлом.
awk '< print $n >' выводит n-й столбец в тексте.
Хотя awk способен на гораздо большее, выдача колонок составляет, наверное, 99% вариантов использования в моём личном случае.
tr расшифровывается как translate. Эта команда заменяет одни символы на другие. Она работает либо с символами, либо с классами символов, такими как строчные, печатные, пробелы, буквенно-цифровые и т. д.
На стандартных входных данных tr <char1> <char2> заменяет все вхождения <char1> на <char2>.
tr может переводить классы символов с помощью нотации [:class:] . Полный список доступных классов описан на справочной странице tr , но некоторые продемонстрируем здесь.
[:space:] представляет все типы пробелов, от простого пробела до табуляции или символа новой строки.
Все символы, похожие на пробелы, переведены в запятую. Обратите внимание, что символ % в конце выдачи означает отсутствие завершающей новой строки. Действительно, этот символ тоже переведён в запятую.
[:lower:] представляет все строчные символы, а [:upper:] — все прописные. Таким образом, преобразование между ними становится тривиальным.
tr -c SET1 SET2 преобразует любой символ, не входящий в набор SET1, в символы набора SET2. В следующем примере все символы, кроме указанных гласных, заменяются пробелами.
tr -d удаляет указанные символы, а не заменяет их. Это эквивалент tr <char> '' .
tr также может заменить диапазоны символов, например, все буквы между a и e или все числа между 1 и 8, используя нотацию s-e , где s — начальный символ, а e — конечный.
Команда tr -s string1 сжимает все множественные вхождения символов в string1 в одно-единственное. Одним из наиболее полезных применений tr -s является замена нескольких последовательных пробелов одним.
Команда fold сворачивает все входные строки до заданной ширины. Например, может быть полезно убедиться, что текст помещается на дисплеях небольшого размера. Так, fold -w n укладывает строки по ширине n символов.
Команда fold -s будет разбивать строки только на символах пробела. Её можно объединить с предыдущей, чтобы ограничить строким заданным количеством символом.
sed — это неинтерактивный потоковый редактор, который используется для преобразования текста во входном потоке строка за строкой. В качестве входных данных используется или файл, или stdin , а на выходе тоже или файл, или stdout .
Команды редактора могут включать один или несколько адресов, функцию и параметры. Таким образом, команды выглядят следующим образом:
Хотя sed выполняет множество функций, мы рассмотрим только замену текста как один из самых распространённых вариантов использования.
Замена текста
Команда замены sed выглядит следующим образом:
Пример: замена первого экземпляра слова в каждой строке в файле:
Мы видим, что в первой строчке заменяется только первый экземпляр hello . Чтобы заменить все вхождения hello во всех строках, можно использовать опцию g (означает global).
sed позволяет использовать любые разделители, кроме / , что особенно улучшает читаемость, если в самих аргументах команды есть слэши.
Адрес говорит редактору, в какой строке или диапазоне строк выполнять подстановку.
Адрес 1 указывает заменять hello на Hey I just met you в первой строке. Можем указать диапазон адресов в нотации <start>,<end> , где <end> может быть либо номером строки, либо $ , то есть последней строкой в файле.
По умолчанию sed выдаёт результат в свой stdout , но может отредактировать и оригинальный файл с опцией -i .
Примечание. В Linux достаточно только -i . Но в macOS поведение команды немного отличается, поэтому сразу после -i нужно добавить '' .
Фильтрация CSV с помощью grep и awk
В этом примере grep в файле metadata.csv сначала фильтрует строки, содержащие слово gauge , затем те, у которых query в четвёртой колонке, и выводит название метрики (1-я колонка) с соответствующим значением per_unit_name (5-я колонка).
Вывод адреса IPv4, связанного с сетевым интерфейсом
Команда ifconfig <interface name> выводит сведения по указанному сетевому интерфейсу. Например:
Затем запускаем grep для inet , что выдаст две строки соответствия.
Затем с помощью grep -v исключаем строку с ipv6 .
Наконец, с помощью awk запрашиваем второй столбец в этой строке: это IPv4-адрес, связанный с нашим сетевым интерфейсом en0 .
Примечание. Мне предложили заменить grep inet | grep -v inet6 такой надёжной командой awk :
Она короче и конкретно нацелена на IPv4 с условием $1 == "inet" .
Извлечение значения из файла конфигурации
В файле конфигурации git текущего пользователя ищем значение editor = , обрезаем знак = , извлекаем второй столбец и удаляем все пробелы вокруг.
Извлечение IP-адресов из файла журнала
Давайте разберем, что делает этот конвейер. Во-первых, как выглядит строка в журнале.
Затем awk '< print $12 >' извлекает из строки IP-адрес.
Команда sed 's@/@@' удаляет начальный слэш.
Примечание. Как мы уже видели ранее, в sed можно использовать любой разделитель. Хотя обычно в качестве разделителя используется / , здесь мы заменяем именно этот символ, что слегка ухудшит читаемость выражения подстановки.
sort | uniq -c сортирует IP-адреса в лексикографическом порядке, а затем удаляет дубликаты, добавляя перед IP-адресами количество вхождений каждого.
sort -rn | head -n 10 сортирует строки по количеству вхождений, численно и в обратном порядке, чтобы главные нарушители выводились в первую очередь, из которых отображаются 10 строк. Последняя команда awk < print $2 >извлекает сами IP-адреса.
Переименование функции в исходном файле
Представим, что мы работаем над проектом и хотели бы переименовать недачно названную функцию (или класс, переменную и т. д.) в исходном файле. Можно сделать это с помощью команды sed -i , которая выполняет замену прямо в оригинальном файле.
Примечание. На macOS вместо sed -i используйте sed -i '' .
Однако мы переименовали функцию только в оригинальном файле. Это сломает импорт bool_from_str в любом другом файле, поскольку эта функция больше не определена. Нужно найти способ переименовать bool_from_str повсюду в нашем проекте. Такого можно добиться с помощью команд grep , sed , а также циклов for или с помощью xargs .
Чтобы заменить в нашем проекте все вхождения bool_from_str , сначала нужно рекурсивно найти их с помощью grep -r .
Поскольку нас интересуют только файлы c совпадениями, также необходимо использовать опцию -l/--files-with-matches :
Затем можем использовать команду xargs для осуществления действий с каждой строки выходных данных (то есть всех файлов, содержащих строку bool_from_str ).
Опция -n 1 указывает, что каждая строка в выходных данных должна выполнить отдельную команду sed .
Затем выполняются следующие команды:
Если команда, которую вы вызываете с помощью xargs (в нашем случае sed ), поддерживает несколько аргументов, то следует отбросить аргумент -n 1 для производительности.
Эта команда затем исполнит
Примечание. Из синопсиса sed на ман-странице видно, что команда может принять несколько аргументов.
Действительно, как мы видели в предыдущей главе, file . означает, что принимаются несколько аргументов, представляющих собой имена файлов.
Мы видим, что произведены замены для всех вхождений bool_from_str .
Как это часто бывает, существует несколько способов достижения одного и того же результата. Вместо xargs мы могли бы использовать циклы for , чтобы перебирать строки по списку и выполнять действие над каждым элементом. У этих циклов такой синтаксис:
Если обернуть нашу команду grep в $() , то оболочка выполнит её в подоболочке, результат чего затем будет повторён в цикле for .
Эта команда выполнит
Синтаксис циклов for кажется мне более чётким, чем у xargs , однако последняя может выполнять команды параллельно, используя параметры -P n , где n — максимальное количество параллельных команд, выполняемых одновременно, что может дать выигрыш в производительности.
Все эти инструменты открывают целый мир возможностей, так как позволяют извлекать и преобразовывать данные, создавая целые конвейеры из команд, которые, возможно, никогда не предназначались для совместной работы. Каждая из них выполняет относительно небольшую функцию (сортировка sort , объединение cat , фильтры grep , редактирование sed , вырезание cut и т. д.).
Любую задачу, включающую текст, можно свести к конвейеру более мелких задач, каждая из которых выполняет простое действие и передаёт свои выходные данные в следующую задачу.
Например, если нам хочется узнать, сколько уникальных IP-адресов в файле журнала, и чтобы эти IP-адреса всегда появлялись в одном и том же столбце, то можно запустить следующую последовательность команд:
- grep строк, которые соответствуют шаблону строк с IP-адресами
- найти столбец с IP-адресом, извлечь его с помощью awk
- отсортировать список IP-адресов с помощью sort
- устранить смежные дубликаты с помощью uniq
- подсчитать количество строк (то есть уникальных IP-адресов) с помощью wc -l
Примеры в этой статье были надуманными, но я предлагаю вам прочитать удивительную статью «Инструменты командной строки могут быть в 235 раз быстрее, чем ваш кластер Hadoop», чтобы получить представление о том, насколько полезны и мощны эти команды на самом деле и какие реальные проблемы они могут решить.
- Подсчитайте количество файлов и каталогов, расположенных в вашем домашнем каталоге.
- Отобразите содержимое файла только прописными буквами.
- Подсчитайте, сколько раз встречалось каждое слово в файле.
- Подсчитайте количество гласных в файле. Отсортируйте результат от наиболее распространённой до наименее распространённой буквы.
Если интересно поучаствовать в проекте, подписывайтесь на список рассылки!
Команда uniq предназначена для поиска одинаковых строк в массивах текста. При этом с найденными совпадениями пользователь может совершать множество действий — например, удалять их из вывода либо наоборот, выводить только их.
Работа команды осуществляется как с текстовыми файлами (в том числе, записями скриптов), так и с текстом, напечатанным в командной строке терминала.
Синтаксис uniq
Запись команды осуществляется следующим образом:
$ uniq опции файл_источник файл_для_записи
Файл источник указывает откуда надо читать данные, а файл для записи - куда писать результат. Но их указывать не обязательно. В примерах мы будем набирать текст, который нуждается в редактировании, прямо в командную строку терминала, воспользовавшись ещё одной командой — echo, и применив к ней опцию -e. Это будет выглядеть так:
echo -e [текст, слова в котором разделены управляющей последовательностью\\n] | uniq
Эта управляющая последовательность нужна, чтобы указать утилите, что каждое слово выводится в новой строке. Если указано только название файла источника, результат выполнения команды появится прямо в окне терминала. А при наличии выходного файла текст будет напечатан в теле документа.
Опции uniq
У команды uniq есть такие основные опции:
- -u (--unique) — выводит исключительно те строки, у которых нет повторов.
- -d (--repeated) — если какая-либо строка повторяется несколько раз, она будет выведена лишь единожды.
- -D — выводит только повторяющиеся строки.
- --all-repeated[=МЕТОД] — то же самое, что и -D, но при использовании этой опции между группами из одинаковых строк при выводе будет отображаться пустая строка. [=МЕТОД] может иметь одно из трех значений — none (применяется по умолчанию), separate или prepend.
- --group[=МЕТОД] — выводит весь текст, при этом разделяя группы строк пустой строкой. [=МЕТОД] имеет значения separate (по умолчанию), prepend, append и both, среди которых нужно выбрать одно.
Вместе с основными опциями могут применяться дополнительные. Они нужны для более тонких настроек работы команды:
- -f (--skip-fields=N) — будет проведено сравнение полей, начиная с номера, который следует после указанного вместо буквы N. Поля — это слова, хотя, называть их словами в прямом смысле слова нельзя, ведь словом команда считает любую последовательность символов, отделенную от других последовательностей пробелом либо табуляцией.
- -i (--ignore-case) — при сравнении не будет иметь значение регистр, в котором напечатаны символы (строчные и заглавные буквы).
- -s (--skip-chars=N) — работает по аналогии с -f, однако, игнорирует определенное количество символов, а не строк.
- -c (--count) — в начале каждой строки выводит число, которое обозначает количество повторов.
- -z (--zero-terminated) — вместо символа новой строки при выводе будет использован разделитель строк NULL.
- -w (--check-chars=N) — указание на то, что нужно сравнивать только первые N символов в строках.
Примеры использования uniq
Прежде всего следует отметить главную особенность команды uniq — она сравнивает только строки, которые находятся рядом. То есть, если две строки, состоящие из одинакового набора символов, идут подряд, то они будут обнаружены, а если между ними расположена строка с отличающимся набором символов — то не будут поэтому перед сравнением желательно отсортировать строки с помощью sort. Без задействования файлов uniq работает так:
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq

После команды uniq можно использовать её опции. Вот пример вывода, где не просто удалены повторы, но и указано количество одинаковых строк:
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq -c

Теперь применим команду к тексту, который находится в файле.
uniq --all-repeated=prepend text-example.txt

Как можно заметить, глядя на снимок экрана, команда вывела в качестве повторяющихся только вторую и третью группу строк.

Причина этого — незаметный глазу символ пробела, который стоит в конце одной из строк первой группы. Нужно быть предельно внимательным при использовании uniq, чтобы получить качественный результат.
Используемая опция --all-repeated=prepend выполнила свою работу — добавила пустые строки в начало, в конец и между группами строк. Теперь попробуем сравнить только первые 5 символов в каждой строке.
echo -e небо исполосовано молниями\\nоблака на небе\\nоблака разогнал ветер\\nоблака закрыли солнце\\nсолнце светит ярко\\nзвезды кажутся огромными | uniq -w5

Как видно на скриншоте, повторяющиеся строки, которые начинались словом «облака», были удалены. Осталась только первая из них. Вывод только уникальных строк с использованием опции -u выглядит так:
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq -u

Чтобы проигнорировать определенное количество символов в начале одинаковых строк, воспользуемся опцией --skip-chars. В данном случае команда пропустит слово «облака», сравнив слова «перистые» и «белые».
echo -e небо\\nоблака перистые\\nоблака перистые\\nоблака белые\\nсолнце\\nзвезды | uniq --skip-chars=6

А вот наглядная демонстрация отличий при использовании опции --group с разными значениями. both добавило пустые строки как перед текстом, так и после него, а также между группами строк.
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq --group=both
Тогда как append не добавило пустую строку перед текстом:
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq --group=append

Выводы
Команда uniq linux пригодится тем, кто часто и много работает с массивами текста, не имея возможности вычитывать их самостоятельно. Следует заметить, что не все версии uniq работают исправно, поэтому иногда результат выдачи может отличаться от ожидаемого.
Свои вопросы относительно использования команды, а также замечания и пожелания оставляйте в комментариях.
Нет похожих записей
Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна.
Этичный хакинг и тестирование на проникновение, информационная безопасность
Стандартный вывод и стандартный ввод. Перенаправление вывода
Для командной строки существует такое понятие как «стандартный вывод». Стандартным является вывод в консоль. Например, команда
выводит в консоль список файлов:
- сохранить в файл;
- передать другой программе;
- безвозвратно уничтожить без вывода и сохранения куда-либо.
Для сохранения в файл используется символ >
После этого символа нужно указать имя файла. Например:
При этом на экран ничего не вывелось. Но если проверить файлы, то можно увидеть новый с именем files.txt.
cat – для отображения содержимого файлов
Главной функцией cat является «склеивание» нескольких файлов. После неё можно указать название нескольких файлов, и она последовательно их выведет. Если вы указали название только одного файла, то будет отображён только он. Для показа только что созданного файла:
wc – для подсчёта строк, слов и байт
Программа wc считает, сколько ей передали строк, сколько слов и сколько байт.
После команды wc нужно указать имя файла, например:
Будет выведено что-то вроде:
- 11 – количество строк в файле
- 93 – количество слов в файле
- 619 – количество байт в файле
Если вы хотите, чтобы вывод ограничился количеством строк, то используйте ключ -l:
Там вы увидите, что если файл не задан, то читается стандартный вывод. Мы уже выяснили, что стандартный вывод – это то, что другие программы выводят в консоль. Если мы хотим передать вывод одной программы в другую, то используется символ |. Например:
Если программа принимает от другой программы вывод через символ |, то это называется стандартным вводом.
Мы также можем использовать различные опции, как с первой, так и со второй командой:
Можно воспользоваться стандартным выводом команды cat:
grep – вывод строк, соответствующих шаблону
Общий вид использования команды:
Означает искать в файле files.txt строки, соответствующие шаблону «txt».

Команда grep также поддерживает стандартный ввод:
Поиск по шаблону осуществляется с учётом регистра. Т.е. txt, Txt и TXT – это три разных шаблона и если вы указали txt, то строка, содержащая TXT будет считаться неподходящей. Для поиска без учёта регистра используется опция -i.
Чтобы было интереснее, скачайте или создайте текстовый файл. Если у вас нет своего файла, то скачайте словарик:
Примечание: wget и bunzip2 – это также команды Linux. Первая используется для получения файлов по сети, вторая для распаковки архивов. Пока мы не будем останавливаться на них подробно.
Итак, в результате работы этих двух команд мы скачали и распаковали текстовый файл. В текущей рабочей директории у нас присутствует файл rockyou.txt.
Поищем в этом файле строки, содержащие, например, шаблон «russia», чтобы поиск осуществлялся без учёта регистра, добавим ключ -i:
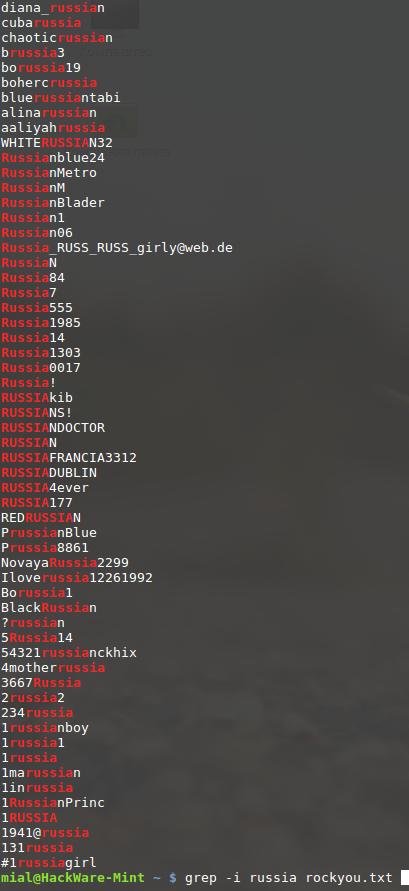
Как мы помним, команда grep может работать со стандартным вводом. Поэтому следующая команда абсолютно аналогична:
Будет найдено довольно много совпадений. А сколько именно? Легко:

Если вы немного запутались, поясню. Команда cat считывает файл rockyou.txt и выводит его в стандартный вывод, по стандартному вводу (символ |) стандартный вывод передаётся команде grep, которая без учёта регистра (-i) ищет все строки, содержащие слово russia, найденные строки по стандартному вводу (символ |) передаются команде wc, которая считает их количество, при этом считается только количество строк, а количество слов и количество байт не отображается (-l).
uniq – сообщает о повторяющихся строках или удаляет их
Команда uniq удаляет одинаковые строки или показывает их. Но она «видит» одинаковые строки только если они являются смежными (следуют друг за другом). Т.е. перед применением команды uniq, записи в файле нужно отсортировать. Для этого применяется команда sort.
Давайте начнём с того, что посчитаем общее количество строк в файле rockyou.txt. Для этого мы выведем его содержимое в стандартный вывод командой cat, а затем применим команду wc:
Теперь перед тем, как посчитать количество строк, мы их отсортируем (команда sort) и удалим одинаковые (команда uniq). Обе эти команды умеют работать со стандартным вводом (а также и с файлами). Далее показан пример при работе со стандартным вводом:

Как можно заметить, в файле rockyou.txt имеется почти три тысячи абсолютно одинаковых строк.
Задание для самостоятельной работы: посмотрите справку по командам uniq, sort и wc и удалите дубликаты из файла rockyou.txt без использования стандартного ввода. А затем посчитайте количество уникальный записей также без использования стандартного ввода.
У команды uniq имется ключ -d, который позволяет просмотреть одинаковые строки. Но вначале очистим словарь от нечитаемых символов:
iconv -f utf-8 -t utf-8 -c
Подробности о проблеме, которую решает предыдущая команда, вы найдёте в статье «Как из текстового файла найти и удалить символы, отличные от UTF-8».
А теперь выведем список дублирующихся строк:
Различия между > и |
Оба символа: > и | используются для перенаправления стандартного вывода. Но символ > отправляет данные в файл, а символ | (его ещё называют «труба») отправляет их другой программе. Если сделать так:
То этой командой вы пытаетесь переписать бинарный (исполнимый) файл программы sort тем, что выдаст cat. Если вы обычный пользователь, то система не позволит вам испортить файл программы. Но если вы работаете под учётной записью администратора, то таким образом вы навредите системе, результат будет совершенно другим от ожидаемого вами.
Если вы хотите очистить файл rockyou.txt от дублей и сохранить результат в новый файл, то нужно сделать так:
Здесь cleaned_rockyou.txt – это название нового файла без дублей.
less – для просмотра содержимого больших файлов
Вы могли обратить внимание, что когда мы вывели результаты поиска командой:
то вывод получил достаточно большим и пришлось прокручивать окно консоли вверх.
Что делать, если нужно просмотреть большой вывод или очень объёмный текстовый файл? Команда
в этом случае абсолютно бы не помогла, она только переполнит окно консоли, и вы даже не сможете просмотреть самые верхние строки файла.
Для таких случаев имеется команда less. Она может работать и с файлами и со стандартным вводом. Для просмотра файла:
Вы можете прокручивать большие файлы вверх и вниз.
Вы можете вводить команды для поиска и навигации по файлу:
| Команда | Действие |
|---|---|
| Page Up или b | Прокрутка назад на одну страницу |
| Page Down или пробел | Прокрутка вперёд на одну страницу |
| Стрелка вверх (↑) | Прокрутка вверх на одну строку |
| Стрелка вниз (↓) | Прокрутка вниз на одну строку |
| G | Перейти к концу файла |
| 1G или g | Перейти к началу файла |
| /символы | Поиск вперёд по файлу введённых символов |
| n | Поиск следующего вхождения предыдущего поиска |
| h | Показать справку |
| q | Выйти из less |
Для выхода из команды less используйте клавишу q.
head — Вывод только начала текстового файла
Команда head выводит только начало текстового файла. По умолчанию будет выведено первые 10 строк, например, чтобы вывести начало файла ZTE F2.txt:
Если вам нужно оставить только определённое число строк, то используйте опцию -n, после которой укажите желаемое число строк, например, чтобы вывести только одну первую строку файла:
Чтобы вывести первые 100 строк:
tail — Вывод только конца текстового файла
Эта команда похожа на head, но выводит конец файла.
По умолчанию выводятся последние 10 строк, но вы можете изменить их количество опцией -n:
Ввод имён файлов в Linux
Консоль поддерживает drag-and-drop, т.е. вы можете перетащить и бросить в консоль файл, после этого в консоли появится полный путь до файла.
Также используйте клавишу TAB для автодополнения имени файла и пути до него.
Будьте внимательны с файлами, у которых присутствуют в имени пробелы. Например, если вы хотите переименовать файл files.txt в файл new file.txt, то следующая команда завершиться шибкой:
Чтобы избежать ошибку, нужно:
- взять путь до файла, содержащий пробелы, в кавычки;
- экранировать пробел;
- вместо пробела использовать знак нижнего подчёркивания (_), который по общепринятому соглашению символизирует пробел.
Т.е. все следующие команды являются верными. Имя файла в кавычках:
Замена пробела на знак нижнего подчёркивания:
В Linux можно создавать файлы с именами, невозможными в Windows, например, в именах можно использовать слеши, двоеточие, нулевой байт и т.д. Будьте внимательны с такими файлами – в Windows вы не сможете их ни открыть, ни переименовать, ни удалить.
Связанные статьи:
факультете информационной безопасности от GeekBrains? Комплексная годовая программа практического обучения с охватом всех основных тем, а также с дополнительными курсами в подарок. По итогам обучения выдаётся свидетельство установленного образца и сертификат. По этой ссылке специальная скидка на любые факультеты и курсы!
Рекомендуется Вам:
2 комментария to Азы работы в командной строке Linux (часть 3)

Приветствую! Важное наблюдение. Дело в том, что файл rockyou.txt имеет несколько строк с неверными, с точки зрения UTF-8 символами, из-за которых команда uniq с опцией -d терпит неудачу.
Очистим словарь от нечитаемых символов:
Подробности о проблеме, которую решает предыдущая команда, вы найдёте в статье «Как из текстового файла найти и удалить символы, отличные от UTF-8».
А теперь можно вывести список дубликатов (в новом правильном файле):
Ваши действия (пересохранение файла) приводили к тому, что редактор сам удалял неправильные символы и после этого uniq -d начинала работать как надо.
Мне нужно подсчитать кол-во совпадений второго поля и найти строки в которых кол-во совпадений n меньше заданного N в скрипте (в данном случае 5) и использовать второе поле из этих строк в качестве переменной $var_surname для дальнейших действий.
на выходе нужно получить
Буду благодарен любым подсказкам.
1. идешь while-ом по строке 2. пишешь функцию, подсчета совпадений 3. на каждой итерации, бери фамилию. разделитель двоеточие передавай в функцию поиска из пункта 2 (awk -F ':' '') 3. функция поиска делает поиск (cat input | grep -i -c surname) и делает append в массив, хеш-мап нет, поэтому добавляй, в одну строку, потом при сортировке распарсишь, вида: surname:count 4. пишешь функцию сортировку 5. после идешь for-ом по массиву surname:count, передаешь на каждой итерации строку в функцию сортировки 6. в функции сортировки: сплит по ':', и сравниваешь count по условию, если удовлетворяет, принтуешь или что тебе там нужно.
Вырезаешь второе поле man cut или man grep . Сортируешь man sort . Считаешь каждое входение man uniq . Получаешь список «кол-во фамилия». Дальше сам

Как говорит тут один аноним, сразу видно пятизвёздочного. Ну накой awk -F ':' '' если уже есть while? Это делается while IFS=: read name surname; С чего это нету map-а? Тут явно напрашивается ассоциативный массив. Ну и так далее.
vodz ★★★★★ ( 21.07.19 16:05:23 )Последнее исправление: vodz 21.07.19 16:06:00 (всего исправлений: 1)
Спасибо, очень помог) Простое и доступное для меня решение.
cat unionfile | cut -d":" -f2 | sort | uniq -c > output
sed -i 's/^ *//' output
awk -F '[()]' '$1 < $N' output
и потом чтение строки в переменные
Возможно для больших объемов данных не пойдет и есть решения изящнее и производительнее, но для моего случая и это сработает.
Раз тут идет звездная война, а ТС, как я понимаю, ничего не понимает, то если дать почти готовое решение, это ничего не изменить в балансе темных и светлых сил. ``` cut -d: -f2 | sort | uniq -c ``` И вообще, причем тут баш, сед, авк и другие. Задача именно на понимание.
Ну ты понял, что я ошибся на счет теба. Успехов.
Возможно для больших объемов данных не пойдет и есть решения изящнее и производительнее, но для моего случая и это сработает.
Это точно будет попроизводительнее перелопачивания на баш.
и потом чтение строки в переменные
Что ты хочешь здесь сделать?
найти строки в которых кол-во совпадений n меньше заданного N в скрипте
отсортируй дальше по количеству вхождений (по первому полю), и отбрось начало (или конец) до нужного числа N (например sed’ом). Будет тебе список фамилий удовлетворяющих условию, практически без использования баша.
Хорошо, если так можно сделать в bash, сходу и без лишних телодвижений. Я не в курсе и выдал сходу, по памяти.
Здесь sed-ом сначала удаляю пробелы вначале строки, потом с помощью awk по оставляю только строки где количество совпадений меньше заданного (значение в первом поле < N).
По идее можно и без седа, только я не знаю как понять какой номер поля там получается. Там идет 6 или 7 пробелов сначала.
Потом считываю из строк(и) переменные n и var_surname
Мне количество совпадений важно обязательно считать в переменную т.к. я потом произвожу с ней математическое действие.
Мне количество совпадений важно обязательно считать в переменную т.к. я потом произвожу с ней математическое действие. Где ты производишь мат. действия? Если в баше, то читай сразу в баш и фильтруй там.
Мне количество совпадений важно обязательно считать в переменную т.к. я потом произвожу с ней математическое действие.
Где ты производишь мат. действия? Если в баше, то читай сразу в баш и фильтруй там.
vodz ★★★★★ ( 21.07.19 17:34:39 )Мне количество совпадений важно обязательно считать в переменную т.к. я потом произвожу с ней математическое действие.
Последнее исправление: vodz 21.07.19 17:36:33 (всего исправлений: 1)
Спасибо) Протестировал данное решение тоже, все работает.
Только вот выдает строки с совпадениями n не только те, которые меньше заданного значения, но и которые равны этому значению.
Для простых обработок текста есть специальный язык.
Только вот выдает строки с совпадениями n не только те, …
Ясно, пациент полный ноль в баше.
Раз мы для тебя стараемся, сделай для нас что-нибудь. Например, какая самая популярная фамилия?
Только вот выдает строки с совпадениями n не только те, которые меньше заданного значения, но и которые равны этому значению.
Потому там и 4, а не 5. Но если вам для зачёта надо, то поменяйте le, на lt.
Спасибо за пример, познавательно.
Правда отдельной программой не очень удобно, т.к. этот кусочек обработки является частью более глобального скрипта и хочется все в одном файле уместить.
Не, я не сдаю зачеты, я для своих задач пишу и учусь)
Думаю разобрался бы, выше был пример с -t вместо -e и читал я ранее, что -e это equal, но в любом случае спасибо за поправку.
И вообще всем отписавшимся - спасибо большое за то что подсказали как можно решить задачу разными способами. Добра вам всем. Хорошо, что есть такие отзывчивые люди, которым не лень кому-то менее опытному подсказать)
p.s. ну не полный ноль, скрипты пишу какие-то для себя, повышаю сложность. Но вот с массивами очень плотно пока не работал, знакомлюсь как раз.

На будущее - прочитай Advanced Bash Scripting Guide. Он есть и на русском(правда устаревший перевод), но тебе хватит. Оттуда и будет понятна в чём разница между -lt и -le и где можно обойтись встроенными средствами bash(если переносимость на другие шеллы не планируется), а где надо подключать внешние программы.
Ну а потом - только практика. И чтение чужого кода, да.
Правда отдельной программой не очень удобно
хочется все в одном файле уместить.
ну это так себе хотелка. Не зря индустрия больше полусотни лет разбивает программы на осмысленные части. Но пока твой скрипт не слишком велик программу на awk можно внедрить прямо в него
legolegs ★★★★★ ( 21.07.19 20:40:57 )Последнее исправление: legolegs 21.07.19 20:42:11 (всего исправлений: 1)
А вот не соглашусь. Сравните свой код и мой чуть выше. Есть разница? Казалось бы в принципе почти одно и тоже и даже может awk тут будет и быстрее. Но, это пока вам не понадобится потом работать с полученными переменными, особенно если надо будет обрабатывать чуть ли весь ассоциативный массив гораздо дальше, чем можно поместить в этот внедренный код в сложный скрипт.

Но, это пока вам не понадобится потом работать с полученными переменными
Объявление запрошенных ТСом переменных в рамках этого скрипта, думаю, излишне (либо мало данных). Что будет, если попадется 2 фамилии с n<5?
В остальном - что в случае с awk'ом, что в случае с башем полученные пары можно обрабатывать одинаково; как было уже выше предложено:
YAR ★★★★★ ( 21.07.19 23:40:04 )Последнее исправление: YAR 21.07.19 23:44:10 (всего исправлений: 2)
Что будет, если попадется 2 фамилии с n<5?
Так и я об этом. Что? Может тогда понадобятся имена? Номера строк в исходном файле? И главное, смысл тогда в awk, если результат из пайпа? Где удобство и скорость?
смысл тогда в awk
Где удобство и скорость?
По удобству - пусть каждый под задачу выбирает удобный для себя вариант. По скорости - awk будет быстрее на больших объемах данных.
Если у ТСа задача все равно подразумевает использование баша (некие математические операции с переменными - и да, а зачем тут баш?) - это не повод решать все исключительно средствами баша, благо подзадачи можно реализовать различными средствами.
По скорости - awk будет быстрее на больших объемах данных.
Да с чего бы это было б сильно заметно? Оба языка, что bash, что awk работают примерно одинаково - парсят текст, создают дерево разбора и его интерпретируют. Я знаю, что там внутри и даже правил и то и другое. У awk есть хорошее преимущество, когда надо обрабатывать входные строки через regex-ы. Когда же у нас задача разбить входные строки на два поля, то применение awk как правило только доказывает непрофессионализм пишущего.
vodz ★★★★★ ( 22.07.19 00:17:16 )Последнее исправление: vodz 22.07.19 00:17:54 (всего исправлений: 1)
Да с чего бы это было б сильно заметно?
Страдаю какой-то херней вместо приготовления ужина
Дык. Аж целых 2 минуты жевало, а с первого коммента - уже более 2 часов. Если вам жалко 2 минут на 121Мб, то перепишите на C. Не удивлюсь, что bash тормозит на генерации ассоциативного индекса.
На всякий случай, напоминаю, что я никогда не говорил, что bash на этой задаче может быть быстрее. Я говорил, что если вам понадобится потом эти данные, то встраивание другого интерпретатора в скрипт неудобно и будет скорее всего медленнее. Ну в самом деле, вот пусть у вас 100M будет по 4 имен у фамилий и только одно 5. Ну прогоните через пайп и while read.
Да с чего бы это было б сильно заметно?
я никогда не говорил, что bash на этой задаче может быть быстрее.
Чем что? 2 последовательных цикла на bash по 3 минуты будут быстрее, чем 0.7 секунды на mawk + 3 минуты на bash? Ну ок.
Дальше можно было не писать:
YAR ★★★★★ ( 22.07.19 02:24:59 )Когда же у нас задача разбить входные строки на два поля, то применение awk как правило только доказывает непрофессионализм пишущего
Последнее исправление: YAR 22.07.19 02:29:53 (всего исправлений: 2)
Как вы предсказуемы. На реальных данных, когда вообще имеет смысл пользоваться скриптами, разница в долях секунд не заметна.
А вот это уже подлог. Я вам предлагал обработать задачу awk, а потом закачать весь массив через read. Собственно данных уже достаточно, чтобы увидеть, что будет медленнее.
А вот как это сделать в контексте вашего примера никак не разберусь. Подключать еще один массив?
Так как в bash нет многомерных массивов, а их ручная эмуляция весьма кривая как по виду кода так и по скорости, то новые массивы обычно наилучшее решение. Если б не одно но, которое у вас: ассоциативный массив у вас не сохраняет порядок следования входным данным и придётся решать задачу конкретно по ситуации, может даже вначале заполнять данными обычные, а потом отдельно высчитывать с ассоциативными.
Ты занимаешься не тем делом. Ты пытаешься работать с базой данных на скриптовом языке, который задуман как запускалка других программ. У тебя ничего хорошего не получится, как хорошо бы ты не знал этот скриптовый язык для запуска программ. И при этом ты не знаешь этот скриптовый язык.
Это лишь кусочек большого скрипта с ветвлениями и циклами. Мне нужно запускать один файл и чтобы он выполнял всю работу на серверах, принимал разные решения в зависимости от вводных данных, ошибок, которые меняются после каждого последующего запуска. Поэтому я решил, что будет удобнее записывать данные в простые файлы. И при повторном запуске считывать данные с них и выполнять те или иные действия.
Если подключать БД, то вероятно одним скриптом я уже не справлюсь?
Примерно в этом ключе и думал.
Либо с полученной переменной потом в цикле считать все строки, которые ее содержат.
Не надо строить массивы в баше при обработке реальных данных, ты столкнешься с тем, что у баш нет эффективных по скорости и по потреблению памяти структур данных для работы с такими объемами данными.
Поэтому используй баш как запускалку подходящих для этого программ. Не надо считать математику в баш.
Если ты прям не хочешь использовать для этого спец инструменты, хочешь копаться в текстовых файлах, то
Все промежуточные файлы можно скоратить направив через пайпы следующей команде.
Чувствствуешь, что во всем этом практически не используется баш, тупое использование спец-инструментов, и все это есть закат солнца вручную - имитация субд.
Читайте также: