
Linux создать большой файл
Обновлено: 06.07.2024
Философия Linux гласит - всё в системе есть файл. Мы ежедневно работаем с файлами, и программы, которые мы выполняем, - тоже файлы. В разных случаях нам может понадобиться создать в системе файлы определённого типа. Если вам интересно, какие типы файлов в Linux можно создать, смотрите отдельную статью.
Конечно, всё очень просто делается с помощью мышки и файлового менеджера. Но если вы дружите с клавиатурой, создать файл через терминал Linux намного быстрее и, как вы увидите, эффективнее. В терминале вы можете не только создавать пустые файлы, но и создавать файл с уже готовым содержимым, файлы определённого размера, и с нужными метаданными.
Как всё это делать, вы узнаете из этой статьи. Мы рассмотрим все доступные средства создания файлов в терминале Linux. Поехали!
1. Редактор nano
Самый распространённый способ создать текстовый файл в Linux - это использовать консольные текстовые редакторы. Например nano. После ввода команды открывается редактор, и вы прописываете нужный текст, например:

2. Редактор Vi
Тот же принцип, но программа намного серьёзнее:

Если вы в первый раз столкнулись с vim, то предупрежу - это необычный редактор. Здесь есть два режима: режим вставки и командный. Переключаться между ними можно с помощью кнопки Esc. Для выхода из редактора в командном режиме наберите :q, для сохранения файла - :w. Вообще, Vim - очень полезный инструмент. Чтобы узнать побольше о его возможностях и выучить основы, выполните: vimtutor.
Понятное дело, в этом пункте можно говорить и о других редакторах, в том числе и с графическим интерфейсом. Но мы их опустим и перейдём к другим командам создания файла в Linux.
3. Оператор перенаправления >
Это, наверное, самая короткая команда для создания файла в Linux:

Оператор оболочки для перенаправления вывода позволяет записать вывод любой команды в новый файл. Например, можно подсчитать md5 сумму и создать текстовый файл в Linux с результатом выполнения.

Это рождает ещё несколько способов создания файла в Linux, например, выведем строку в файл с помощью команды echo:
echo "Это строка" > файл.txt

Этот способ часто используется для создания конфигурационных файлов в Linux, так сказать, на лету. Но заметьте, что sudo здесь работать не будет. С правами суперпользователя выполниться echo, а запись файла уже будет выполнять оболочка с правами пользователя, и вы всё равно получите ошибку Access Denied.
Ещё тем же способом можно сделать примитивный текстовый редактор для создания файла. Утилита cat без параметров принимает стандартный ввод, используем это:

После выполнения команды можете вводить любые символы, которые нужно записать в файл, для сохранения нажмите Ctrl+D.
А ещё есть утилита printf, и здесь она тоже поддерживает форматирование вывода:
printf "Это %d текстовая строка\n" 1 > файл

Этот способ создать файл в Linux используется довольно часто.
4. Оператор перенаправления вывода >>
Также можно не только перезаписывать файл, а дописывать в него данные, с помощью перенаправления оператора >>. Если файла не существует, будет создан новый, а если существует, то строка запишется в конец.
echo "Это текстовая строка" > файл.txt
$ echo "Это вторая текстовая строка" >> файл.txt

5. Оператор перенаправления 2>

Если команда не выдает ошибок, файл будет пустым.
6. Оператор перенаправления и head
С помощью команды head можно выбрать определённый объем данных, чтобы создать текстовый файл большого размера. Данные можно брать, например, с /dev/urandom. Для примера создадим файл размером 100 мегабайт:
base64 /dev/urandom | head -c 100M > файл
7. Команда cp
Команда cp используется для копирования файлов в Linux. Но с её помощью можно и создать файл. Например, чтобы создать пустой файл, можно просто скопировать /dev/null:
cp /dev/null файл
8. touch
Вот мы и подобрались к непосредственному созданию файлов через терминал, для этого в Linux есть специальная утилита touch. Она позволяет создать пустой файл в Linux, при этом указывать дату создания, права доступа и другие метаданные.
Чтобы создать пустой файл Linux, просто наберите:

Можно создать несколько пустых файлов сразу:
touch файл1 файл2
Опция -t позволяет установить дату создания. Дата указывается опцией -t в формате YYMMDDHHMM.SS. Если не указать, будет установлена текущая дата. Пример:
touch -t 201601081830.14 файл
Можно использовать дату создания другого файла:
touch -r шаблон файл
Также можно установить дату последней модификации, с помощью опции -m:
touch -m -t 201601081830.14 файл
Или дату последнего доступа:
touch -a -t 201601081830.14 файл
Чтобы посмотреть, действительно ли задаётся информация, которую вы указали, используйте команду stat:

9. Утилита dd
Это утилита для копирования данных из одного файла в другой. Иногда необходимо создать файл определённого размера в Linux, тогда можно просто создать его на основе /dev/zero или /dev/random, вот так:
dd if=/dev/zero of=

Параметр if указывает, откуда брать данные, а of - куда записывать, count - необходимый размер. Ещё можно указать размер блока для записи с помощью bs, чем больше размер блока, тем быстрее будет выполняться копирование.
Создание специальных файлов в Linux
В Linux, кроме выше рассмотренных обычных текстовых и бинарных файлов, существуют ещё и специальные файлы. Это файлы сокетов и туннелей. Их нельзя создать обычными программами, но для этого существуют специальные утилиты, смотрите подробнее в статье, ссылку на которую я дал вверху.
Выводы
Это были все возможные команды для создания файла в Linux. Если вы знаете другие, которые следовало бы добавить в статью - поделитесь в комментариях.
Как быстро создать большой файл в системе Linux ( Red Hat Linux )?
dd выполнит эту работу, но чтение /dev/zero и запись на диск могут занять много времени, когда вам нужен файл размером в несколько сотен гигабайт для тестирования . Если вам нужно делать это несколько раз, время действительно увеличивается.
Меня не волнует содержимое файла, я просто хочу, чтобы он был создан быстро. Как это может быть сделано?
Использование разреженного файла не будет работать для этого. Мне нужно, чтобы файл был выделен на диске.
Ext4 обладает гораздо лучшей производительностью размещения файлов, поскольку целые блоки размером до 100 МБ могут быть выделены одновременно. Люди, кажется, грубо игнорируют «разреженный файл не будет работать с этим», с их усечением и dd ищет ниже. Вы должны были определить, что вы имели в виду под «для тестирования». Тестирование скорости записи вашего жесткого диска? Тестирование о чем df сообщит? Тестирование приложения, которое делает что-то конкретное. Ответ зависит от того, что вы хотите проверить. Как бы то ни было, я немного опоздал - теперь я вижу, что с момента вашего вопроса прошло много лет :-) На всякий случай, если вы ищете способ смоделировать полный раздел, как я, посмотрите не дальше, чем / dev / full Возможно ли, что dd уже использует это внутренне? Если я выполню 'dd if = / dev / zero of = zerofile bs = 1G count = 1' на ядре 3.0.0, запись завершится через 2 секунды, при скорости записи данных более 500 мегабайт в секунду. Это явно невозможно на 2,5-Это общий вопрос, особенно в современной среде виртуальных сред. К сожалению, ответ не так прост, как можно предположить.
dd - очевидный первый выбор, но dd по сути является копией, и это заставляет вас записывать каждый блок данных (таким образом, инициализируя содержимое файла) . И эта инициализация занимает столько времени ввода-вывода. (Хотите, чтобы это заняло еще больше времени? Используйте / dev / random вместо / dev / zero ! Тогда вы будете использовать процессор, а также время ввода-вывода!) В конце концов, dd - плохой выбор (хотя по сути по умолчанию используется ВМ "создать" GUI). Например:
truncate - это другой выбор - и, вероятно, самый быстрый . Но это потому, что он создает «разреженный файл». По сути, разреженный файл - это раздел диска, который содержит много одинаковых данных, и лежащая в основе файловая система «обманывает», на самом деле не сохраняя все данные, а просто «делая вид», что все это есть. Таким образом, когда вы используете усечение для создания 20 ГБ диска для вашей виртуальной машины, файловая система фактически не выделяет 20 ГБ, но обманывает и говорит, что там есть 20 ГБ нулей, хотя всего одна дорожка на диске может фактически (действительно) использоваться. Например:
fallocate является окончательным - и лучший - выбор для использования с выделением диска VM, потому что она по существу «резервы» (или «выделяет» все пространства вы ищете, но это не мешает писать что - либо так,. когда вы используете Fallocate для создания виртуального дискового пространства объемом 20 ГБ, вы действительно получаете файл размером 20 ГБ (а не «разреженный файл»), и вам не нужно будет ничего записывать в него - это означает, что практически все может быть в там - вроде как новый диск!) Например:
Создайте тестовый файл размером 1000 МБ, все содержимое файла равно 0 (поскольку он читается из / dev / zero, / dev / zero является источником 0). Но это фактическая запись на жесткий диск, скорость генерации файла зависит от скорости чтения и записи жесткого диска, если вы хотите сгенерировать очень большие файлы, скорость будет очень низкой.
В определенном сценарии мы хотим, чтобы файловая система только думала, что здесь очень большой файл, но не записывала его на жесткий диск. Вы можете использоватьseek
1) count = 0 означает 0 операций чтения и записи, а размер сгенерированного файла равен 0M
2) count = 50 означает 50 операций чтения и записи, а размер сгенерированного файла указан как 50M
Отображаемый размер файла, созданного в это время в файловой системе, составляет 100000 МБ, но на самом деле он не занимает блок, поэтому скорость создания эквивалентна скорости памяти.
- если (входной файл) представляет входной файл / каталог, если если не указан, входные данные будут считываться из стандартного ввода по умолчанию
- of (выходной файл) представляет выходной файл / каталог, если of не указано, по умолчанию будет выводиться стандартный вывод по умолчанию.
- bs представляет размер блока, читаемый каждый раз
- count: количество прочитанных блоков
bs * count = Размер файла - / dev / zero - это специальное символьное устройство, предоставляемое Linux. Его особенностью является то, что файл можно читать бесконечно, и результатом каждого чтения является двоичный 0.
- seek: пропустить часть выходного файла указанного размера без фактического написания
2. Команда усечения
Уменьшите или увеличьте файл до указанного размера.
Параметр -s, а именно размер (размер)
1) Если указанный файл не существует, он будет создан.
2) Если указанный файл превышает указанный размер, лишние данные будут потеряны.
3) Если указанный файл меньше указанного размера, используйте 0 для компенсации.
будь осторожен:
Этот тип файла называется "дырочным файлом", и его часть на самом деле не существует на жестком диске.
du (использование диска): по умолчанию отображается фактическое использование диска.
3. Команда fallocate
Команда fallocate может предварительно выделить физическое пространство для файлов.
-l следует за размером пробела, единицей измерения по умолчанию является байт. За ним также могут следовать k, m, g, t, p, e, чтобы указать единицы измерения, соответствующие KB, MB, GB, TB, PB, EB.
Интеллектуальная рекомендация
совместный запрос mysql с тремя таблицами (таблица сотрудников, таблица отделов, таблица зарплат)
1. Краткое изложение проблемы: (внизу есть инструкция по созданию таблицы, копирование можно непосредственно практиковать с помощью (mysql)) Найдите отделы, в которых есть хотя бы один сотрудник. Отоб.

[Загрузчик классов обучения JVM] Третий день пользовательского контента, связанного с загрузчиком классов

IP, сеанс и cookie
В этой статье пойдет речь о разреженных файлах. Расскажем об их недостатках и достоинствах, какие файловые системы поддерживают такие файлы. А также, как создавать или преобразовать их из обычных. Статья для новичков.

Разреженные – это специальные файлы, которые с большей эффективностью используют файловую систему, они не позволяют ФС занимать свободное дисковое пространство носителя, когда разделы не заполнены. То есть, «пустое место» будет задействовано только при необходимости. Пустая информация в виде нулей, будет хранится в блоке метаданных ФС. Поэтому, разреженные файлы изначально занимают меньший объем носителя, чем их реальный объем.
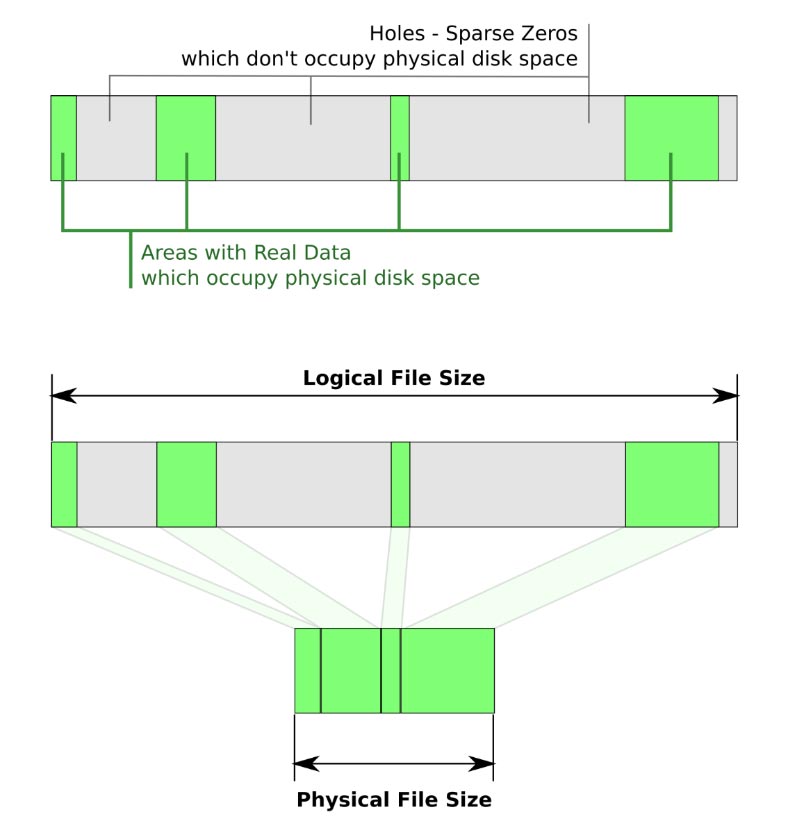
Этот тип поддерживает большинство файловый систем: BTRFS, NILFS, ZFS, NTFS, ext2, ext3, ext4, XFS, JFS, ReiserFS, Reiser4, UFS, Rock Ridge, UDF, ReFS, APFS, F2FS.
Все эти ФС полностью поддерживают такой тип, но в тоже время не предоставляют прямой доступ к их функциям по средством своего стандартного интерфейса. Управлять их свойствами можно только через команды командной строки.
Разница между сжатием и разреженными файлами
Все файловые системы, которые я назвал выше, также поддерживают стандартную функцию сжатия. Оба этих инструмента дают преимущество в виде экономии места на диске, но достигают этой цели по-разному. Основным недостатком использования сжатия является то, что это может снизить производительность системы при выполнении операции чтения\ записи. Так как будут использоваться дополнительные ресурсы для распаковки или сжатия данных. Но некоторые программные продукты не поддерживают сжатие.
Преимущества и недостатки
Самым большим преимуществом разреженных файлов является то, что пользователь может создавать файлы большого размера, которые занимают очень мало места для хранения. Пространство для хранения выделяется автоматически по мере записи на него данных. Разреженные файлы большого объема создаются за относительно короткое время, поскольку файловой системе не требуется предварительно выделять дисковое пространство для записи нулей.
Преимущества ограничены лишь приложениями, которые их поддерживают. Если у программы нет возможности распознавать или использовать их, то она сохранит их в исходном – несжатом состоянии, что не даст никаких преимуществ. Также с ними нужно быть осторожными, поскольку разреженный файл размером всего несколько мегабайт может внезапно увеличиться до нескольких гигабайт, когда неподдерживающие приложения скопируют его в место назначения.
Еще один из недостатков — это то, что нельзя скопировать или создать такой файл, если его номинальный размер превышает доступный объем свободного пространства (или ограничения размера квоты, налагаемые на учетные записи пользователей). Например, если исходный размер (со всеми нулевыми байтами) составляет 500 МБ, а для учетной записи пользователя, используемой для его создания, существует предел квоты в 400 МБ. Это приведет к ошибке даже если фактическое дисковое пространство, занимаемое им, составляет всего 50 МБ на диске.
Что касается накопителей, на которых хранятся такие данные, то они также подвержены фрагментации, поскольку файловая система будет записывать данные в разреженные файлы по мере необходимости. Со временем это может привести к снижению производительности. Кроме того, некоторые утилиты для управления дисками могут неточно отображать объем доступного свободного места. Когда файловая система почти заполнена, это может привести к неожиданным результатам. Например, могут возникать ошибки «переполнения диска», когда данные копируются поверх существующей части, которая была помечена как разреженная.
Создаем разреженный файл в Windows
Для этого в ОС Windows будем использовать командную строку. В поиске пишем cmd и запускаем ее от имени администратора.
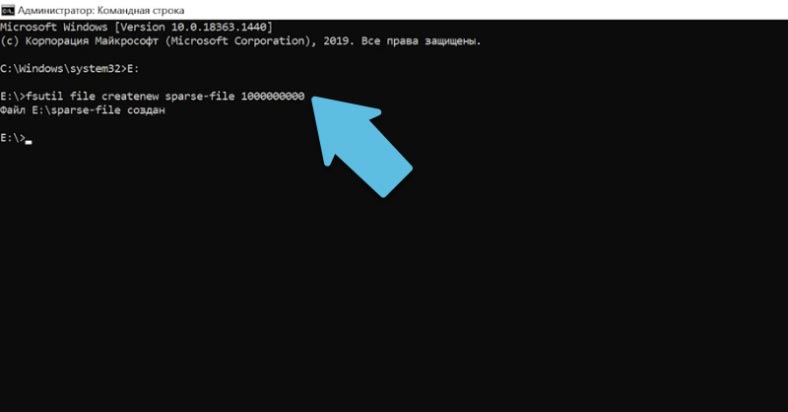
В Windows для управления такими данными используют программу fsutil (утилита файловой системы). При выполнении create, по умолчанию файл создается самый обычный. Переходим в папку где нужно его создать и вводим:
fsutil file createnew sparse-file 1000000000
Где sparse-file – имя, а в конце указан его размер в байтах.
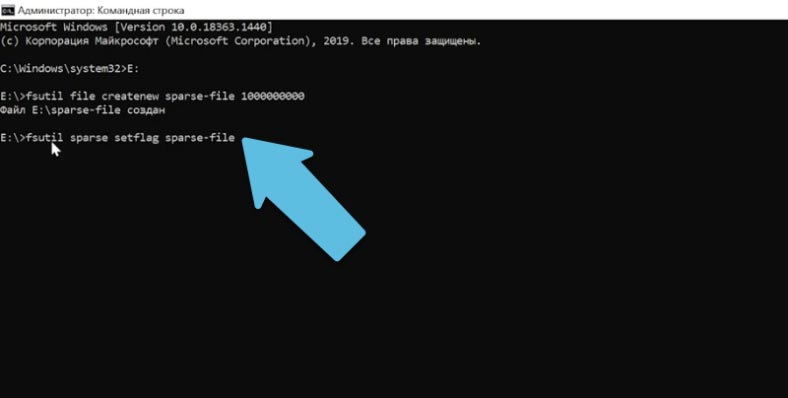
Чтобы присвоить файлу значение «разреженный» вводим:
fsutil sparse setflag sparse-file
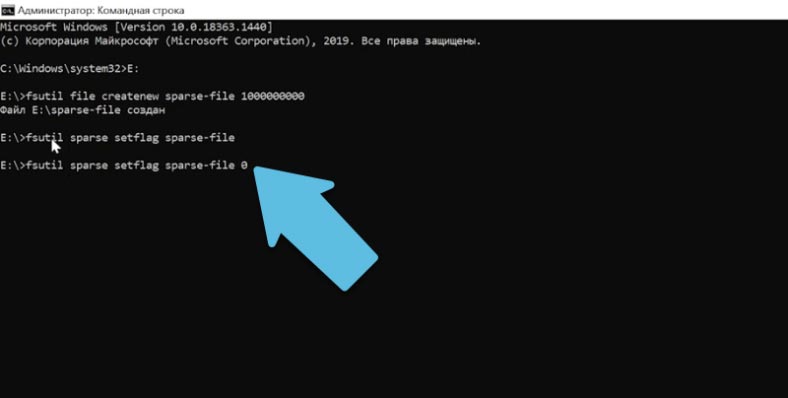
Для удаления этого флага выполняется следующая команда:
fsutil sparse setflag sparse-file 0
И чтобы снова присвоить атрибут:
fsutil sparse setflag sparse-file
fsutil sparse queryflag sparse-file
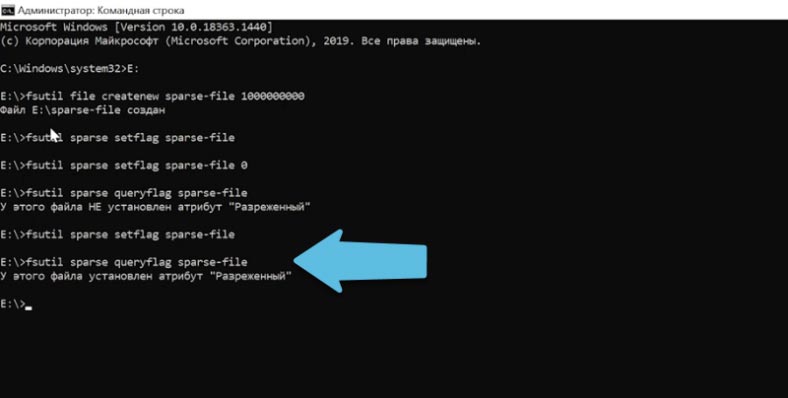
Сам по себе атрибут ещё не приводит к экономии дискового пространства. Для этого нужно разметить пустую область, которая будет освобождена внутри.
Для пометки пустой области введите:
fsutil sparse setrange sparse-file 0 1000000000
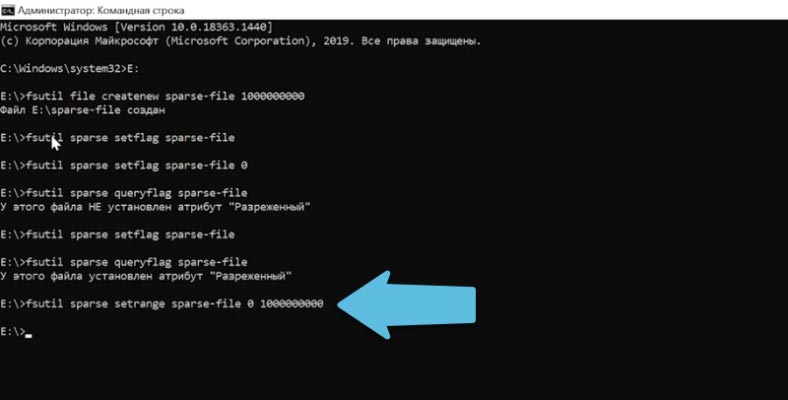
В конце указывается смещение и длина, они задаются в байтах. В моем случае от нуля до 1Гб.
Для установки полностью разреженного файла указываем полный объем. Если нужно можно расширить файл указав здесь большее значение.
Для того чтобы убедиться, что файлу присвоен данный атрибут выполним layout
fsutil file layout sparse-file
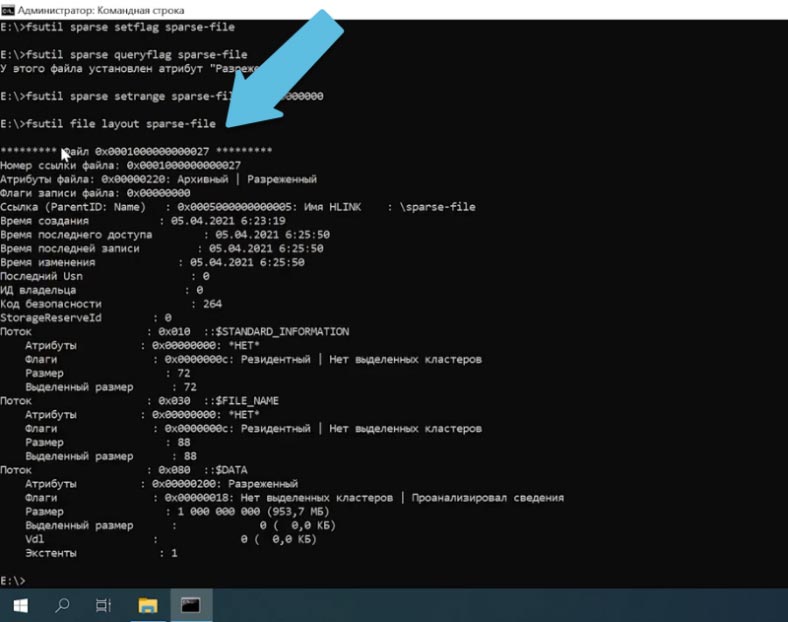
Такой Атрибут можно задать любому файлу. Просто выполнив эту команду с его именем и задать нужный вам размер.
В свойствах созданного ранее файла можно увидеть, что при размере в 1Гб. файл занимает на диске 0 байт.
Данный набор команд подходит для всех файловых систем Windows, которые поддерживают данный тип данных (NTFS, ReFS и т.д.).
Как создать разреженный файл в Linux
В Linux процесс создания таких типов данных немного проще, поскольку существует несколько команд для их создания. Этот набор подойдет для всех файловых систем Linux.
Здесь можно использовать команду dd, либо truncate.
Первая команда имеет следующий вид:
dd if=/dev/zero of=file-sparse bs=1 count=0 seek=2G
Где file-sparse – имя, и в конце указан его размер, можно задать в байтах, мегабайтах и т.д.
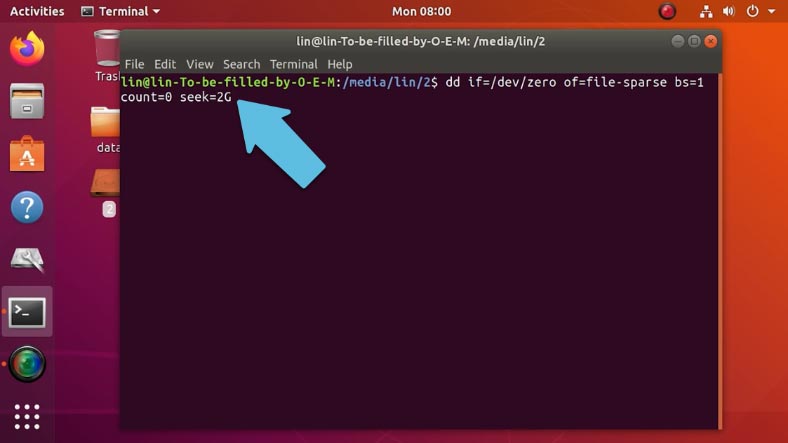
Вторая команда проще, она имеет такой вид:
truncate -s2G file-sparse
Где значение s – указывает размер, после которого идет имя.
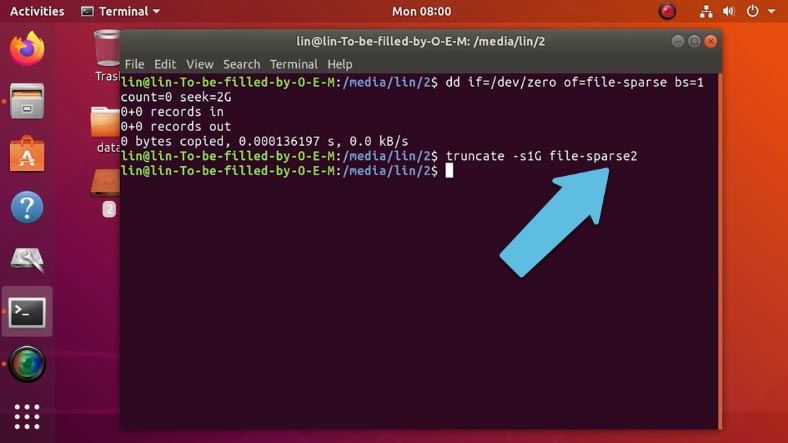
По сравнению с Windows, в Linux при создании такого файла одной из команд, он будет «разреженным» по умолчанию.
Для преобразования обычного в разреженный, есть отдельная команда:
cp --sparse=always ./025.jpg ./0251.jpg
Где 025.jpg – первое имя обычного.
0251.jpg – и второе имя разреженного.
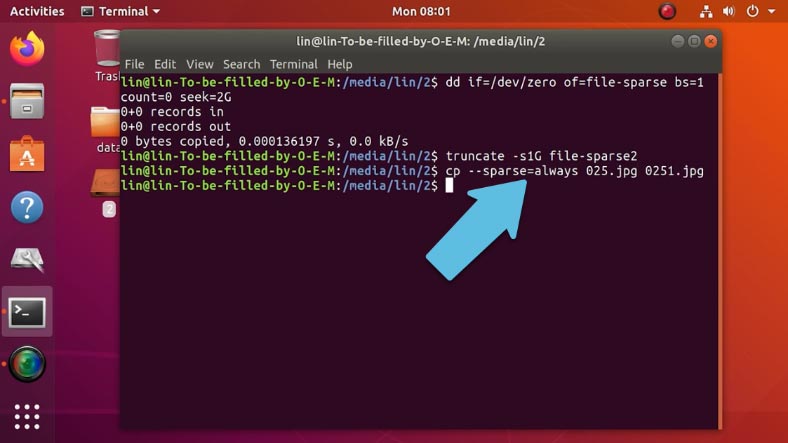
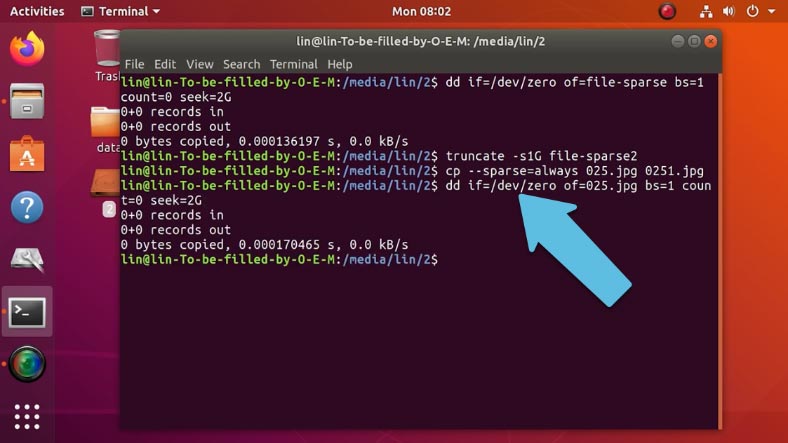
Как увеличить
Если вам нужно увеличить уже существующий файл воспользуйтесь первой командой, здесь замените имя и укажите нужный размер.
dd if=/dev/zero of=025.jpg bs=1 count=0 seek=2G
Это увеличит его размер до 2 Гб.
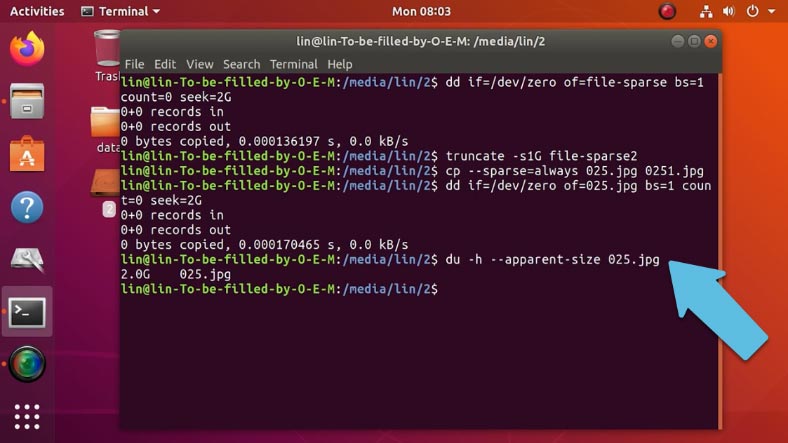
Для проверки размера выполним такую команду:
du -h --apparent-size 025.jpg
Разреженные файлы в ApFS
По сути, данный набор команд подходит и для файловой системы apple – ApFS, так как Linux и MacOS используют в своей основе архитектуру ядра Unix, они обе предоставляют доступ к Unix-командам и оболочке Bash.
Запустите терминал и выполните любую из команд, которую я использовал в Linux.
В MacOS Catalina работает только первая команда, и размер нужно указывать в байтах, иначе в результате команда выведет ошибку.
sudo dd if=/dev/zero of=sparse_APFS bs=1 count=0 seek=1000000000
Файловая система ApFS при соблюдении определенных условий создает разреженные файлы по умолчанию, поэтому для увеличения любого файла можно использовать команду:
dd if=/dev/zero of=187.jpg bs=1 count=0 seek=500000000
Зададим размер, к примеру, 500Мб, в MacOS размер нужно указывать в байтах.
В свойствах можно увидеть, что его размер увеличился до 500 Mb.
Заключение
Перед использованием этого функционала в любых ОС вам крайне важно узнать все их преимущества и недостатки. Знание этих особенностей гарантировано позволит вам избежать потенциальных проблем в будущем.
Полную версию статьи со всеми дополнительными видео уроками смотрите в источнике. А также зайдите на наш Youtube канал, там собраны более 400 обучающих видео.
Читайте также: