
Linux убрать лишние пробелы
Обновлено: 02.07.2024
Обрабатывая информацию, собирая ее из разных источников, например с сайта поставщика, мы часто сталкиваемся с тем, что нам надо ее привести в достойный вид, удалив лишние пробелы.
Удаление пробелов в начале или конце строки.
Стандартные функция trim( string $str [, string $character_mask = " \t\n\r\0\x0B" ]) удаляет все возможные пробелы в начале или в конце строки, так же эта функция может удалять те символы, которые вам не нужны, например точку или запятую:
Так же есть 2 функции, ltrim и rtrim, которые работают так же как и trim, за исключением того , что ltrim удаляет символы в начале строки, а rtrim в конце.
Удаление лишних пробелов в самом тексте.
Иногда нужно удалить лишние пробелы, а иногда и табы, в самом тексте, например: «Купив телефон сегодня вы получите самый лучший подарок». В этом тексте после каждого слова стоит более 1 пробела, Попробуем заменить лишние через регулярное выражение:
В данном случае \s говорит что надо заменить все пробелы, а + включая табы на 1 пробел. Если вы считаете, что регулярные выражения зло, то можно использовать:
Удаление «не удаляемых» пробелов.
Возможно вы столкнулись с такой проблемой, что ни одно из средств перечисленных выше не удаляет пробелы. Для начала рассмотрите внимательно текст, желательно в исходном коде, потому что текст « Купив телефон сегодня вы получите самый лучший подарок» может оказаться таким: « Купив телефон сегодня вы получите самый лучший подарок». Для начала надо заменить   и просто на пробелы:
А потом, применить один из способов, о котором я писал выше.
Хорошо, это мы сделали, но у нас остались лишние пробелы, которые не удаляются стандартными методами. Вероятнее всего это NO-BREAK SPACE, в таблице utf-8 символов он идет как c2 a0.

Для начала попробуйте перевести ваш текст в HEX:
и поищите там: c2a0, как видно на скриншоте, у меня аж 2 таких пробела
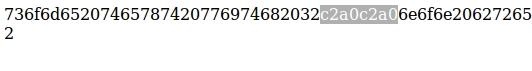
Удаление через регулярное выражение:
Удаление без регулярного выражения:
переводим наш текс в HEX, заменяем NO-BREAK SPACE на обычный пробел, переводим обратно в обычный текст, после этого можно сделать замену пробелов и чистку.
Возможно у вас есть свой способ, может более практичный, как исправлять "не удаляемые" пробелы, то поделитесь в комментариях.
Сортирует содержимое файла, часто используется как промежуточный фильтр в конвейерах. Эта команда сортирует поток текста в порядке убывания или возрастания, в зависимости от заданных опций. Ключ -m используется для сортировки и объединения входных файлов. В странице info перечислено большое количество возможных вариантов ключей. См. Пример 10-9, Пример 10-10 и Пример A-9.
Топологическая сортировка, считывает пары строк, разделенных пробельными символами, и выполняет сортировку, в зависимости от заданного шаблона.
Удаляет повторяющиеся строки из отсортированного файла. Эту команду часто можно встретить в конвейере с командой sort.
Ключ -c выводит количество повторяющихся строк.
Команда sort INPUTFILE | uniq -c | sort -nr выводит статистику встречаемости строк в файле INPUTFILE (ключ -nr, в команде sort, означает сортировку в порядке убывания). Этот шаблон может с успехом использоваться при анализе файлов системного журнала, словарей и везде, где необходимо проанализировать лексическую структуру документа.
Пример 12-8. Частота встречаемости отдельных слов
Команда expand преобразует символы табуляции в пробелы. Часто используется в конвейерной обработке текста.
Команда unexpand преобразует пробелы в символы табуляции. Т.е. она является обратной по отношению к команде expand.
Предназначена для извлечения отдельных полей из текстовых файлов. Напоминает команду print $N в awk, но более ограничена в своих возможностях. В простейших случаях может быть неплохой заменой awk в сценариях. Особую значимость, для команды cut, представляют ключи -d (разделитель полей) и -f (номер(а) поля(ей)).
Использование команды cut для получения списка смонтированных файловых систем:
Использование команды cut для получения версии ОС и ядра:
Использование команды cut при разборе текстового файла:
Используется для объединения нескольких файлов в один многоколоночный файл.
Может рассматриваться как команда, родственная команде paste. Эта мощная утилита позволяет объединять два файла по общему полю, что представляет собой упрощенную версию реляционной базы данных.
Команда join оперирует только двумя файлами и объедияет только те строки, которые имеют общее поле (обычно числовое), результат объединения выводится на stdout. Объединяемые файлы должны быть отсортированы по ключевому полю.
На выходе ключевое поле встречается только один раз.
Выводит начальные строки из файла на stdout (по-умолчанию -- 10 строк, но это число можно задать иным). Эта команда имеет ряд интересных ключей.
Пример 12-9. Какие из файлов являются сценариями?
Пример 12-10. Генератор 10-значных случайных чисел
Выводит последние строки из файла на stdout (по-умолчанию -- 10 строк). Обычно используется для мониторинга системных журналов. Ключ -f, позволяет вести непрерывное наблюдение за добавляемыми строками в файл.
Пример 12-11. Мониторинг системного журнала с помощью tail
Многоцелевая поисковая утилита, использующая регулярные выражения. Изначально это была команда в древнем строчном редакторе ed, g/re/p, что означает -- global - regular expression - print .
Поиск участков текста в файле(ах), соответствующих шаблону pattern, где pattern может быть как обычной строкой, так и регулярным выражением.
Если файл(ы) для поиска не задан, то команда grep работает как фильтр для устройства stdout, например в конвейере.
-i -- выполняется поиск без учета регистра символов.
-w -- поиск совпадений целого слова.
-l -- вывод только имен файлов, в которых найдены участки, совпадающие с заданным образцом/шаблоном, без вывода совпадающих строк.
-r -- (рекурсивный поиск) поиск выполняется в текущем каталоге и всех вложенных подкаталогах.
The -n option lists the matching lines, together with line numbers.
-v (или --invert-match) -- выводит только строки, не содержащие совпадений.
-c ( --count) -- выводит количество совпадений без вывода самих совпадений.
Если grep вызывается для поиска по группе файлов, то вывод будет содержать указание на имена файлов, в которых найдены совпадения.
Для того, чтобы заставить grep выводить имя файла, когда поиск производится по одному-единственному файлу, достаточно указать устройство /dev/null в качестве второго файла.
Если совпадение было найдено, то grep возвращает код завершения -- 0, это может оказаться полезным при выполнении поиска в условных операторах ( в таких случаях особый интерес может представлять ключ -q, который подавляет вывод).
Пример 29-6 -- пример поиска заданного образца в системном журнале, с помощью grep.
Пример 12-12. Сценарий-эмулятор "grep"
egrep -- то же самое, что и grep -E. Эта команда использует несколько отличающийся, расширенный набор регулярных выражений, что позволяет выполнять поиск более гибко.
fgrep -- то же самое, что и grep -F. Эта команда выполняет поиск строк символов (не регулярных выражений), что несколько увеличивает скорость поиска.
Утилита agrep имеет более широкие возможности поиска приблизительных совпадений. Образец поиска может отличаться от найденной строки на указанное число символов.
Для поиска по сжатым файлам следует использовать утилиты zgrep, zegrep или zfgrep. Они с успехом могут использоваться и для не сжатых файлов, но в этом случае они уступают в скорости обычным grep, egrep и fgrep. Они очень удобны при выполнении поиска по смешенному набору файлов -- когда одни файлы сжаты, а другие нет.
Для поиска по bzip-файлам используйте bzgrep.
Команда look очень похожа на grep, и предназначена для поиска по "словарям" -- отсортированным файлам. По-умолчанию, поиск выполняется в файле /usr/dict/words, но может быть указан и другой словарь.
Пример 12-13. Поиск слов в словаре
Скриптовые языки, специально разработанные для анализа текстовых данных.
Неинтерактивный "потоковый редактор" . Широко используется в сценариях на языке командной оболочки.
Утилита контекстного поиска и преобразования текста, замечательный инструмент для извлечения и/или обработки полей (колонок) в структурированных текстовых файлах. Синтаксис awk напоминает язык C.
wc -- "word count" , счетчик слов в файле или в потоке:
wc -w подсчитывает только слова.
wc -l подсчитывает только строки.
wc -c подсчитывает только символы.
wc -L возвращает длину наибольшей строки.
Подсчет количества .txt -файлов в текущем каталоге с помощью wc:
Подсчет общего размера файлов, чьи имена начинаются с символов, в диапазоне d - h
От переводчика: в случае, если у вас локаль отлична от "C", то вышеприведенная команда может не дать результата, поскольку wc вернет не слово "total", в конце вывода, а "итого". Тогда можно попробовать несколько измененный вариант:
Использование wc для подсчета количества вхождений слова "Linux" в основной исходный файл с текстом этого руководства.
Отдельные команды располагают функциональностью wc в виде своих ключей.
Замена одних символов на другие.
В отдельных случаях символы необходимо заключать в кавычки и/или квадратные скобки. Кавычки предотвращают интерпретацию специальных символов командной оболочкой. Квадратные скобки должны заключаться в кавычки.
Ключ -d удаляет символы из заданного диапазона.
Ключ --squeeze-repeats ( -s) удалит все повторяющиеся последовательности символов. Может использоваться для удаления лишних пробельных символов.
Ключ -c "complement" заменит символы в соответствии с шаблоном. Этот ключ воздействует только на те символы, которые НЕ соответствуют заданному шаблону.
Обратите внимание: команда tr корректно распознает символьные классы POSIX. [1]
Пример 12-14. toupper: Преобразование символов в верхний регистр.
Пример 12-15. lowercase: Изменение имен всех файлов в текущем каталоге в нижний регистр.
Пример 12-16. du: Преобразование текстового файла из формата DOS в формат UNIX.
Пример 12-17. rot13: Сверхслабое шифрование по алгоритму rot13.
Пример 12-18. Более "сложный" шифр
Различные версии tr
Выравнивает текст по ширине, разрывая, если это необходимо, слова. Особый интерес представляет ключ -s, который производит перенос строк по пробелам, стараясь не разрывать слова. (см. Пример 12-19 и Пример A-2).
Очень простая утилита форматирования текста, чаще всего используемая как фильтр в конвейерах для того, чтобы выполнить "перенос" длинных строк текста.
Пример 12-19. Отформатированный список файлов.
Эта утилита с обманчивым названием удаляет из входного потока символы обратной подачи бумаги (код ESC 7). Она так же пытается заменить пробелы на табуляции. Основная область применения утилиты col -- фильтрация вывода отдельных утилит обработки текста, таких как groff и tbl.
Форматирование по столбцам. Эта утилита преобразует текст, например какой либо список, в табличное, более "удобочитаемое" , представление, вставляя символы табуляции по мере необходимости.
Пример 12-20. Пример форматирования списка файлов в каталоге
Утилита удаления колонок. Удаляет колонки (столбцы) сиволов из файла и выводит результат на stdout. colrm 2 4 <filename -- удалит символы со 2-го по 4-й включительно, в каждой строке в файле filename.
Если файл содержит символы табуляции или непечатаемые символы, то результат может получиться самым неожиданным. В таких случаях, как правило, утилиту colrm, в конвейере, окружают командами expand и unexpand.
Нумерует строки в файле. nl filename -- выведет файл filename на stdout, и в начале каждой строки вставит ее порядковый номер, счет начинается с первой непустой строки. Если файл не указывается, то принимается ввод со stdin.
Вывод команды nl очень напоминает cat -n, однако, по-умолчанию nl не нумерует пустые строки.
Пример 12-21. nl: Самонумерующийся сценарий.
Подготовка файла к печати. Утилита производит разбивку файла на страницы, приводя его в вид пригодный для печати или для вывода на экран. Разнообразные ключи позволяют выполнять различные манипуляции над строками и колонками, соединять строки, устанавливать поля, нумеровать строки, добавлять колонтитулы и многое, многое другое. Утилита pr соединяет в себе функциональность таких команд, как nl, paste, fold, column и expand.
pr -o 5 --width=65 fileZZZ | more -- выдаст хорошо оформленное и разбитое на страницы содержимое файла fileZZZ.
Хочу особо отметить ключ -d, который выводит строки с двойным интервалом (тот же эффект, что и sed -G).
Утилита преобразования текста из одной кодировки в другую. В основном используется для нужд локализации.
Может рассматриваться как разновилность утилиты iconv, описанной выше. Универсальная утилита для преобразования текстовой информации в различные кодировки.
TeX и Postscript -- языки разметки текста, используемые для подготовки текста к печати или выводу на экран.
TeX -- это сложная система подготовки к печати, разработанная Дональдом Кнутом (Donald Knuth). Эту утилиту удобнее использовать внутри сценария, чем в командной строке, поскольку в сценарии проще один раз записать все необходимые параметры, передаваемые утилите, для получения необходимого результата.
Ghostscript ( gs) -- это GPL-версия интерпретатора Postscript.
groff -- это еще один язык разметки текста и форматированного вывода. Является расширенной GNU-версией пакета roff/troff в UNIX-системах.
tbl -- утилита обработки таблиц, должна рассматриваться как составная часть groff, так как ее задачей является преобразование таблиц в команды groff.
eqn -- утилита преобразования математических выражений в команды groff.
lex -- утилита лексического разбора текста. В Linux-системах заменена на свободно распространяемую утилиту flex.
yacc -- утилита для создания синтаксических анализаторов, на основе набора грамматик, задаваемых разработчиком. В Linux-системах, эта утилита заменена на свободно распространяемую утилиту bison.
Примечания
Это верно только для GNU-версии команды tr, поведение этой команды, в коммерческих UNIX-системах, может несколько отличаться.
Работа со строками в bash осуществляется при помощи встроенных в оболочку команд.
Термины
- Консольные окружения — интерфейсы, в которых работа выполняется в текстовом режиме.
- Интерфейс — механизм взаимодействия пользователя с аппаратной частью компьютера.
- Оператор — элемент, задающий законченное действие над каким-либо объектом операционной системы (файлом, папкой, текстовой строкой и т. д.).
- Текстовые массивы данных — совокупность строк, записанных в переменную или файл.
- Переменная — поименованная область памяти, позволяющая осуществлять запись и чтение данных, которые в нее записываются. Она может принимать любые значения: числовые, строковые и т. д.
- Потоковый текстовый редактор — программа, поддерживающая потоковую обработку текстовой информации в консольном режиме.
- Регулярные выражения — формальный язык поиска части кода или фрагмента текста (в том числе строки) для дальнейших манипуляций над найденными объектами.
- Bash-скрипты — файл с набором инструкций для выполнения каких-либо манипуляций над строкой, текстом или другими объектами операционной системы.
Сравнение строковых переменных
Для выполнения операций сопоставления 2 строк (str1 и str2) в ОС на основе UNIX применяются операторы сравнения.
Основные операторы сравнения
- Равенство « = »: оператор возвращает значение «истина» («TRUE»), если количество символов в строке соответствует количеству во второй.
- Сравнение строк на эквивалентность « == »: возвращается «TRUE», если первая строка эквивалентна второй ( дом == дом ).
- Неравенство «str1 != str2»: «TRUE», если одна строковая переменная не равна другой по количеству символов.
- Неэквивалентность «str1 !== str2»: «TRUE», если одна строковая переменная не равна другой по смысловому значению ( дерево !== огонь ).
- Первая строка больше второй «str1 > str2»: «TRUE», когда str1 больше str2 по алфавитному порядку. Например, « дерево > огонь » , поскольку литера «д» находится ближе к алфавитному ряду, чем «о».
- Первая строка меньше второй «str1 < str2»: «TRUE», когда str1 меньше str2 по алфавитному порядку. Например, « огонь < дерево », поскольку «о» находится дальше к началу алфавитного ряда, чем «д».
- Длина строки равна 0 « -z str2»: при выполнении этого условия возвращается «TRUE».
- Длина строки отлична от нулевого значения « -n str2»: «TRUE», если условие выполняется.
Пример скрипта для сравнения двух строковых переменных

Создание тестового файла
Обработка строк не является единственной особенностью консольных окружений Ubuntu. В них можно обрабатывать текстовые массивы данных.
- Для практического изучения команд, с помощью которых выполняется работа с текстом в интерпретаторе bash, необходимо создать текстовый файл txt .
- После этого нужно наполнить его произвольным текстом, разделив его на строки. Новая строка не должна сливаться с другими элементами.
- Далее нужно перейти в директорию, в которой находится файл, и запустить терминал с помощью сочетания клавиш — Ctrl+Alt+T.
Основы работы с grep
Поиск строки в файле операционной системы Linux Ubuntu осуществляется посредством специальной утилиты — grep . Она позволяет также отфильтровать вывод информации в консоли. Например, вывести все ошибки из log-файла утилиты ps или найти PID определенного процесса в ее отчете.
Команда grep работает с шаблонами и регулярными выражениями. Кроме того, она применяется с другими командами интерпретатора bash.
Синтаксис команды
Для работы с утилитой grep необходимо придерживаться определенного синтаксиса
- grep [options] pattern [file_name1 file_name2 file_nameN] (где «options» — дополнительные параметры для указания настроек поиска и вывода результата; «pattern» — шаблон, представляющий строку поиска или регулярное выражение, по которым будет осуществляться поиск; «file_name1 file_name2 file_nameN» — имя одного или нескольких файлов, в которых производится поиск).
- instruction | grep [options] pattern (где «instruction» — команда интерпретатора bash, «options» — дополнительные параметры для указания настроек поиска и вывода результата, «pattern» — шаблон, представляющий строку поиска или регулярное выражение, по которым будет производиться поиск).

Основные опции
Практическое применение grep
Поиск подстроки в строке

В окне терминала выводятся все строки, содержащие подстроку. Найденные совпадения подсвечиваются другим цветом.
- С учетом регистра:
- Без учета регистра:
Вывод нескольких строк
- Строка с вхождением и две после нее:
- Строка с вхождением и три до нее:
- Строка, содержащая вхождение, и одну до и после нее:
Чтение строки из файла с использованием регулярных выражений
Регулярные выражения расширяют возможности поиска и позволяют выполнить разбор строки на отдельные элементы. Они активируются при помощи ключа -e.
Чтобы вывести первый символ строки, нужно воспользоваться конструкцией
Если воспользоваться числовыми интервалами, то можно вывести все строки, в которых встречаются числа:
Рекурсивный режим поиска
- Чтобы найти строку или слово в нескольких файлах, расположенных в одной папке, нужно использовать рекурсивный режим поиска:
- Если нет необходимости выводить имена файлов, содержащих искомую строку, то можно воспользоваться ключом-параметром деактивации отображения имен:
Точное вхождение
При поиске союза «и» grep будет выводить все строки, в которых он содержится. Чтобы этого избежать, требуется использовать специальный ключ « w »:
Поиск нескольких слов
Утилита «w» позволяет искать не только одно слово, но и несколько одновременно
Количество строк в файле
При помощи grep можно определить число вхождений строки или подстроки в текстовом файле и вывести ее номер.
![]()
- Число вхождений:
- Номера строк с совпадениями:
Инверсия
Если в тексте требуется найти определенные строки, которые не содержат какого-либо слова или подстроки, то рекомендуется использовать инверсионный режим поиска.
Вывод только имени файла
Чтобы не выводить все строки с совпадением, а вывести только имя файла, нужно воспользоваться конструкцией:
Использование sed
Потоковый текстовый редактор « sed » встроен в bash Linux Ubuntu. Он использует построчное чтение, а также позволяет выполнить фильтрацию и преобразование текста.
Синтаксис
Для работы с потоковым текстовым редактором sed используется следующий синтаксис:
sed [options] instructions [file_name] (где «options» — ключи-опции для указания метода обработки текста, «instructions» — команда, совершаемая над найденным фрагментом текста, «file_name» — имя файла, над которым совершаются действия).

Для вывода всех опций потокового текстового редактора нужно воспользоваться командой:
Распространенные конструкции с sed
Замена слова
Например, если требуется заменить строку в файле или слово с «команды» на «инструкции». Для этого нужно воспользоваться следующими конструкциями:
Редактирование файла
Чтобы записать строку в файл, нужно указать параметр замены одной строки на другую, воспользовавшись ключом — -i :
После выполнения команды произойдет замена слова «команды» на «инструкции» с последующим сохранением файла.
Удаление строк из файла
- Удалить первую строку из файла:
- Удалить строку из файла, содержащую слово«окне»:
Нумерация строк
Строки в файле будут пронумерованы следующим образом: первая строка — 1, вторая — 2 и т. д.

Следует обратить внимание, что нумерация начинается не с «0», как в языках программирования.
Удаление всех чисел из текста
Замена символов
Чтобы заменить набор символов, нужно воспользоваться инструкцией, содержащей команду « y »:
Обработка указанной строки
Утилита производит манипуляции не только с текстом, но и со строкой, указанной в правиле шаблона (3 строка):
Работа с диапазоном строк
Для выполнения замены только в 3 и 4 строках нужно использовать конструкцию:
Если аргумент какой-либо команды содержит пробелы (или знаки табуляции) то Bash интерпретирует их как множественные аргументы. Вот, например, команда echo:
Но ошибкой будет считать, что команда такая "умная", что в точности воспроизводит введенный текст. Это не так:
На самом деле команда интерпретирует любое количество пробелов (и знаков табуляции) как один пробел; а пробел как разделитель между аргументами. Так как по умолчанию команда echo печатает стандартный вывод в одну строку, то и результат будет одинаковым с любым количеством пробелов.
Другие команды по умолчанию печатают свой вывод обработки каждого аргумента с новой строки, например команда printf:
Тут уж сразу видно, что команда обрабатывала не фразу, а каждое слово как отдельный аргумент.
Как же заставить команду включить пробелы (и знаки табуляции) в свой стандартный вывод? Тут возможны два пути:
1. Маскировка при помощи обратного слэша (\). По-английски называется Escaping, а управляющие символы, начинающиеся с обратного слэша, Escapе-символами (само слово "escapе" переводится как исчезать, скрываться). Вот пример маскировки пробела:
Механизм такой маскировки прост: при помощи специального символа, обратного слэша, мы лишили пробела его значения как разделителя между аргументами, и теперь он интерпретируется Bash только как часть текста.
2. Закавычивание. Если заключить аргумент в кавычки, двойные или одинарные, то он всегда будет интерпретирован в качестве единого выражения. Например:
Такой же механизм работает и с командами, принимающими имена файлов в качестве аргумента. Имена файлов ведь тоже могут содержать пробелы; для примера создадим файл по имени text file и попытаемся просмотреть его при помощи команды cat:
А интересно, справится ли с этой задачей автозавершение?
Автозавершение выбрало вариант маскировки. Это не удивительно, ведь маскировать приходится не только пробелы, но и управляющие символы, с которыми кавычки не справятся.
Пока мы рассматривали только пробелы внутри аргумента команды. Лишние же пробелы перед командой, между командой и опциями, между опцией и аргументом, как правило, игноририруются. Если только иное поведение специально не оговорено в синтаксисе команды.
И, наконец, пробел, поставленный вместо аргумента многих команд, заставляет их принимать стандартный ввод. Например:
Читайте также: