
Linux выполнить команду для каждой строки
Обновлено: 07.07.2024
Например, прямо сейчас я использую следующее, чтобы изменить пару файлов, чьи пути Unix я написал в файл:
Есть ли более элегантный, безопасный способ?
Это потому, что есть не только 1 ответ.
- shell расширение командной строки
- xargs специальный инструмент
- while read с некоторыми замечаниями
- while read -u с использованием выделенного fd для интерактивной обработки (пример)
Что касается запроса OP: запуск chmod для всех целей, перечисленных в файле, xargs является указанным инструментом. Но для некоторых других приложений небольшое количество файлов и т.д.
Читать весь файл как аргумент командной строки.
Если ваш файл не слишком большой и все файлы имеют правильные имена (без пробелов и других специальных символов, таких как кавычки), вы можете использовать расширение командной строки shell . Просто:
Для небольшого количества файлов (строк) эта команда является более легкой.
xargs - правильный инструмент
Для большего количества файлов или почти для любого количества строк во входном файле.
Для многих инструментов binutils, таких как chown , chmod , rm , cp -t .
Если у вас есть специальные символы и/или много строк в file.txt .
если ваша команда должна быть выполнена ровно 1 раз по записи:
Это не нужно для этого примера, поскольку chmod принимает несколько файлов в качестве аргумента, но это соответствует названию вопроса.
В некоторых особых случаях вы можете даже определить местоположение аргумента файла в командах, сгенерированных xargs :
Тест с seq 1 5 в качестве ввода
Где командование выполняется один раз в строке.
while read и варианты.
Как предполагает OP, cat file.txt | while read in; do chmod 755 "$in"; done будет работать, но есть 2 проблемы:
cat | - бесполезная вилка, и
| while . ;done станет недоработкой, и после ;done среда исчезнет.
Так что это может быть лучше написано:
Вас могут предупредить о флагах $IFS и read :
В некоторых случаях вам может понадобиться использовать
Для избежания проблем с чужими именами файлов. И, может быть, если у вас возникнут проблемы с UTF-8 :
Пока вы используете STDIN для чтения file.txt , ваш сценарий не может быть интерактивным (вы больше не можете использовать STDIN ).
while read -u , используя выделенный fd .
Синтаксис: while read . ;done <file.txt перенаправит STDIN в file.txt . Это означает, что вы не сможете иметь дело с процессом, пока он не закончится.
Если вы планируете создать интерактивный инструмент, вам следует избегать использования STDIN и использовать какой-либо альтернативный дескриптор файла.
Дескрипторы файла констант: 0 для STDIN, 1 для STDOUT и 2 для STDERR. Вы можете увидеть их по:
Оттуда вы должны выбрать неиспользуемый номер между 0 и 63 (на самом деле больше, в зависимости от инструмента суперпользователя sysctl ) в качестве дескриптора файла:
Посоветуйте, пожалуйста, как сделать, что бы для каждой строки из файла ip.txt выполнить определенную команду?
То есть нужна программа, которая прочитает файл ip.txt и для каждой строки выполнит, команду подставив IP адрес из файла.
iptables -A INPUT -s 187.65.27.242 -j DROP
iptables -A INPUT -s 59.97.208.180 -j DROP
iptables -A INPUT -s 88.164.194.205 -j DROP
Можно ли это сделать на shell Linux? Если да то посоветуйте какие команды использовать.
for i in `cat ip.txt`
iptables -A INPUT -s $i -j DROP
Только не забудьте на всякий случай в начале явно разрешить свой айпи в фаере, а то мало ли..
cat ip.txt | xargs -n1 -I_ iptables -A BAN -s _ -j DROP
INPUT не стоит захламлять кучей отднотипных правил - вынесите
их в отдельную чепочку и подключите ее _одним_ правилом в INPUT.
cat ip.txt | while read $ip;
Будет работает для кучи команд и огромных файлов.
Совет по поводу цепочки - согласен. Еще лучше - загружать это одним сисколлом через iptables-save/iptables-restore
Boris A Dolgov:Будет работает для кучи команд и огромных файлов.
только $ в $ip - имхо, лишнее ;)
Boris A Dolgov:
Еще лучше - загружать это одним сисколлом через iptables-save/iptables-restore
скорее, не загружать, а _догружать_. как-то так:
Спасибо за помощь.
Хакеры снова начали ддосить.
Пока решил проблему напсанием на с++ анализатора логов апача, который получает список IP адресов ботнета, затем эти IP заносятся в iptables.
Пока атаку отбил.
Посмотрим, что они завтра придумают.
zexis:
Есть текстовый файл ip.txt, в каждой строке которого записан IP адрес в текстовом формате
Пример файла ip.txt
187.65.27.242
59.97.208.180
88.164.194.205
Посоветуйте, пожалуйста, как сделать, что бы для каждой строки из файла ip.txt выполнить определенную команду?
То есть нужна программа, которая прочитает файл ip.txt и для каждой строки выполнит, команду подставив IP адрес из файла.
Вот пример.
iptables -A INPUT -s 187.65.27.242 -j DROP
iptables -A INPUT -s 59.97.208.180 -j DROP
iptables -A INPUT -s 88.164.194.205 -j DROP
Можно ли это сделать на shell Linux? Если да то посоветуйте какие команды использовать.
Принцип действия и синтаксис
Прежде чем рассматривать примеры применения, важно разобраться с принципом действия команды. Говоря простыми словами, эта утилита считывает данные из выходных данных другой команды или стандартного потока ввода (по умолчанию) и выполняет команду, переданную в качестве аргумента. Один или несколько раз в зависимости от входных данных. Все пропуски и пробелы во входных данных воспринимаются как разделители, пустые строки игнорируются. Таким образом, в общем виде синтаксис команды следующий:
Если команда в качестве аргумента не передается, по умолчанию утилита выполняет команду echo. Например, в следующем примере мы просто выполнили команду без опций и ввели текст ‘Hello, World!’ в стандартный поток ввода. После нажатия Ctrl+D (чтобы сообщить xargs о завершении ввода), была автоматически выполнена команда echo, и на экран снова был выведен текст ‘Hello, World!’.

Опции
-l [число] -Выполнять команду для каждой группы из заданного числа непустых строк аргументов, прочитанных со стандартного ввода. Последний вызов команды может быть с меньшим числом строк аргументов. Считается, что строка заканчивается первым встретившимся символом перевода строки, если только перед ним не стоит пробел или символ табуляции; пробел/табуляция в конце сигнализируют о том, что следующая непустая строка является продолжением данной. Если число опущено, оно считается равным 1. Опция -l включает опцию -x.
-I [зам_цеп] Режим вставки: команда выполняется для каждой строки стандартного ввода, причём вся строка рассматривается как один аргумент и подставляется в начальные_аргументы вместо каждого вхождения цепочки символов зам_цеп. Допускается не более 5 начальных_аргументов, содержащих одно или несколько вхождений зам_цеп. Пробелы и табуляции в начале вводимых строк отбрасываются. Сформированные аргументы не могут быть длиннее 255 символов. Если цепочка зам_цеп не задана, она полагается равной < >. Опция -I включает опцию -x.
-n [число] Выполнить команду, используя максимально возможное количество аргументов, прочитанных со стандартного ввода, но не более заданного числа. Будет использовано меньше аргументов. Если их общая длина превышает размер (см. ниже опцию -s). Или если для последнего вызова их осталось меньше, чем заданное число. Если указана также опция -x, каждая группа из указанного числа аргументов должны укладываться в ограничение размера, иначе выполнение xargs прекращается.
-t Режим трассировки: команда и каждый построенный список аргументов перед выполнением выводится в стандартный поток ошибок.
-p Режим с приглашением: xargs перед каждым вызовом команды запрашивает подтверждение. Включается режим трассировки (-t), за счет чего печатается вызов команды, который должен быть выполнен, а за ним — приглашение ?…. Ответ y (за которым может идти что угодно) приводит к выполнению команды; при каком-либо другом ответе, включая возврат каретки, данный вызов команды игнорируется.
-x Завершить выполнение, если очередной список аргументов оказался длиннее, чем размер (в символах). Опция -x включается опциями -i и -l. Если ни одна из опций -i, -l или -n не указана, общая длина всех аргументов должна укладываться в ограничение размера.
-s [размер] Максимальный общий размер (в символах) каждого списка аргументов установить равным заданному размеру. Размер должен быть положительным числом, не превосходящим 470 (подразумеваемое значение). При выборе размера следует учитывать, что к каждому аргументу добавляется по одному символу; кроме того, запоминается число символов в имени команды.
-e [лконф_цеп] Цепочка символов лконф_цеп считается признаком логического конца файла. Если опция -e не указана, признаком конца считается подчеркивание (_). Опция -e без лконф_цеп аннулирует возможность устанавливать логический конец файла (подчеркивание при этом рассматривается как обычный символ). Команда xargs читает стандартный ввод до тех пор, пока не дойдет до конца файла или не встретит цепочку лконф_цеп.
Примеры xargs
Ниже рассмотрим наиболее часто используемые примеры команды xargs
Создание конвейеров
Команда xargs очень полезна при создании конвейеров команд. Это самый частый случай использования команды В этом случае результат выполнения предыдущей команды передается как аргумент в xargs.
Например поиск файлов, содержащих заданную строку или текст. Например, поиск всех файлов с расширением txt, содержащих текст ‘abc’, можно выполнить следующим образом:
Вот результат выполнения команды:

В данном случае команда xargs получает входные данные от команды find. И поочередно применяет название файла к команде grep. Которая в свою очередь уже ищет строку в файле.
Просмотр файлов в текущем рабочем каталоге и всех подкаталогов в двух столбцах:
Удалить файлы, созданные более 10 дней назад в директории /tmp
Массовая смена группы пользователей.
Эта команда сменит группу владельцев с root на user на все файлы и каталоги в текущей директории.
Выше приведенных примеров достаточно что бы стало понятно как можно использовать команду xargs. И на основе этих примеров строить уже свои конструкции по использованию. А пока рассмотрим еще несколько примеров.
Использование xargs с другими командами
По умолчанию xargs выполняет команду echo, но можно в явном виде указать любую другую команду. Например, можно передать в качестве аргумента команду find с опцией -name, а затем ввести в стандартном потоке ввода имя файла (или тип файлов), который вы хотите найти.
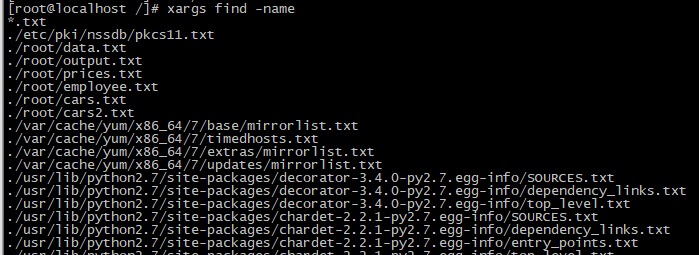
Многократное выполнение команды (для каждой строки/аргумента)

После этой опции необходимо указать число, которое означает максимальное количество непустых строк, которые за раз передаются команде в качестве входных данных. В нашем случае это значение будет равно 1. Так как нам требуется передача команде find одной строки за раз в качестве входных данных.
Команда будет иметь следующий вид:
А результат будет следующим:

Все работает. Теперь попытаемся ввести аргументы так:
Для таких ситуаций можно воспользоваться опцией командной строки -n.
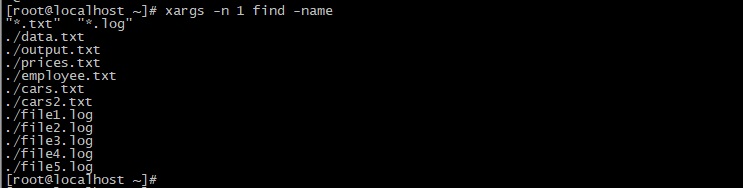
Обработка имен файлов с пробелами
В начале данной статьи было сказано, что xargs воспринимает пробелы (а также символы новой строки) как разделители. В случае, если передаваемые имена файлов содержат пробелы, это может вызвать проблемы.
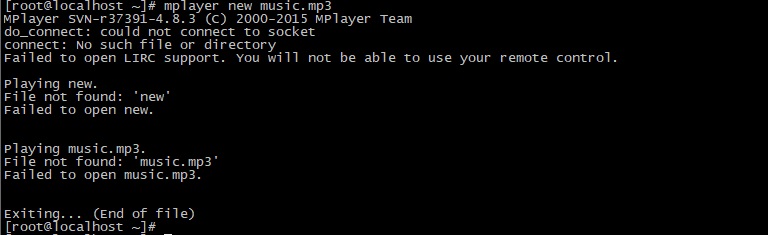
Данная команда будет воспринимать в качестве разделителя только символ новой строки.
Получение входных данных из файла
В рассмотренных выше примерах мы получали входные данные из стандартного потока ввода (по умолчанию) или от другой команды. Однако, при необходимости источником входных данных для xargs может быть файл.
Для этого используется опция -a. После которой нужно указать имя файла, используемого xargs в качестве источника входных данных.
xargs -a input.txt ls -lart
Результат выполнения команды:

Запрос разрешения пользователя перед выполнением команды
Мы уже рассмотрели, как обеспечить многократное выполнение команды. Но нам может потребоваться подтверждение пользователя при каждом запуске. Это можно сделать при помощи опции командной строки -p.

Как видим прежде чем удалить файлы команда запросила подтверждение
Заключение
Мы разобрали самые необходимые базовые функции команды xargs, необходимые для работы с этой полезной утилитой. Освоив принципы работы и функции команды, рассмотренные в данном руководстве, вы можете обратиться к соответствующей man-странице.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
В прошлый раз мы говорили о функциях в bash-скриптах, в частности, о том, как вызывать их из командной строки. Наша сегодняшняя тема — весьма полезный инструмент для обработки строковых данных — утилита Linux, которая называется sed. Её часто используют для работы с текстами, имеющими вид лог-файлов, конфигурационных и других файлов.

Если вы, в bash-скриптах, каким-то образом обрабатываете данные, вам не помешает знакомство с инструментами sed и gawk. Тут мы сосредоточимся на sed и на работе с текстами, так как это — очень важный шаг в нашем путешествии по бескрайним просторам разработки bash-скриптов.

Сейчас мы разберём основы работы с sed, а так же рассмотрим более трёх десятков примеров использования этого инструмента.
Основы работы с sed
Утилиту sed называют потоковым текстовым редактором. В интерактивных текстовых редакторах, наподобие nano, с текстами работают, используя клавиатуру, редактируя файлы, добавляя, удаляя или изменяя тексты. Sed позволяет редактировать потоки данных, основываясь на заданных разработчиком наборах правил. Вот как выглядит схема вызова этой команды:
По умолчанию sed применяет указанные при вызове правила, выраженные в виде набора команд, к STDIN . Это позволяет передавать данные непосредственно sed.
Вот что получится при выполнении этой команды.

Простой пример вызова sed
В данном случае sed заменяет слово «test» в строке, переданной для обработки, словами «another test». Для оформления правила обработки текста, заключённого в кавычки, используются прямые слэши. В нашем случае применена команда вида s/pattern1/pattern2/ . Буква «s» — это сокращение слова «substitute», то есть — перед нами команда замены. Sed, выполняя эту команду, просмотрит переданный текст и заменит найденные в нём фрагменты (о том — какие именно, поговорим ниже), соответствующие pattern1 , на pattern2 .
Выше приведён примитивный пример использования sed, нужный для того, чтобы ввести вас в курс дела. На самом деле, sed можно применять в гораздо более сложных сценариях обработки текстов, например — для работы с файлами.
Ниже показан файл, в котором содержится фрагмент текста, и результаты его обработки такой командой:

Текстовый файл и результаты его обработки
Здесь применён тот же подход, который мы использовали выше, но теперь sed обрабатывает текст, хранящийся в файле. При этом, если файл достаточно велик, можно заметить, что sed обрабатывает данные порциями и выводит то, что обработано, на экран, не дожидаясь обработки всего файла.
Выполнение наборов команд при вызове sed
Для выполнения нескольких действий с данными, используйте ключ -e при вызове sed. Например, вот как организовать замену двух фрагментов текста:

Использование ключа -e при вызове sed
К каждой строке текста из файла применяются обе команды. Их нужно разделить точкой с запятой, при этом между окончанием команды и точкой с запятой не должно быть пробела.
Для ввода нескольких шаблонов обработки текста при вызове sed, можно, после ввода первой одиночной кавычки, нажать Enter, после чего вводить каждое правило с новой строки, не забыв о закрывающей кавычке:
Вот что получится после того, как команда, представленная в таком виде, будет выполнена.

Другой способ работы с sed
Чтение команд из файла
Если имеется множество команд sed, с помощью которых надо обработать текст, обычно удобнее всего предварительно записать их в файл. Для того, чтобы указать sed файл, содержащий команды, используют ключ -f :
Вот содержимое файла mycommands :
Вызовем sed, передав редактору файл с командами и файл для обработки:
Результат при вызове такой команды аналогичен тому, который получался в предыдущих примерах.

Использование файла с командами при вызове sed
Флаги команды замены
Внимательно посмотрите на следующий пример.
Вот что содержится в файле, и что будет получено после его обработки sed.

Исходный файл и результаты его обработки
Команда замены нормально обрабатывает файл, состоящий из нескольких строк, но заменяются только первые вхождения искомого фрагмента текста в каждой строке. Для того, чтобы заменить все вхождения шаблона, нужно использовать соответствующий флаг.
Схема записи команды замены при использовании флагов выглядит так:
Выполнение этой команды можно модифицировать несколькими способами.
- При передаче номера учитывается порядковый номер вхождения шаблона в строку, заменено будет именно это вхождение.
- Флаг g указывает на то, что нужно обработать все вхождения шаблона, имеющиеся в строке.
- Флаг p указывает на то, что нужно вывести содержимое исходной строки.
- Флаг вида w file указывает команде на то, что нужно записать результаты обработки текста в файл.

Вызов команды замены с указанием позиции заменяемого фрагмента
Тут мы указали, в качестве флага замены, число 2. Это привело к тому, что было заменено лишь второе вхождение искомого шаблона в каждой строке. Теперь опробуем флаг глобальной замены — g :
Как видно из результатов вывода, такая команда заменила все вхождения шаблона в тексте.

Глобальная замена
Флаг команды замены p позволяет выводить строки, в которых найдены совпадения, при этом ключ -n , указанный при вызове sed, подавляет обычный вывод:
Как результат, при запуске sed в такой конфигурации на экран выводятся лишь строки (в нашем случае — одна строка), в которых найден заданный фрагмент текста.

Использование флага команды замены p
Воспользуемся флагом w , который позволяет сохранить результаты обработки текста в файл:

Сохранение результатов обработки текста в файл
Хорошо видно, что в ходе работы команды данные выводятся в STDOUT, при этом обработанные строки записываются в файл, имя которого указано после w .
Символы-разделители
Представьте, что нужно заменить /bin/bash на /bin/csh в файле /etc/passwd . Задача не такая уж и сложная:
Однако, выглядит всё это не очень-то хорошо. Всё дело в том, что так как прямые слэши используются в роли символов-разделителей, такие же символы в передаваемых sed строках приходится экранировать. В результате страдает читаемость команды.
К счастью, sed позволяет нам самостоятельно задавать символы-разделители для использования их в команде замены. Разделителем считается первый символ, который будет встречен после s :
В данном случае в качестве разделителя использован восклицательный знак, в результате код легче читать и он выглядит куда опрятнее, чем прежде.
Выбор фрагментов текста для обработки
До сих пор мы вызывали sed для обработки всего переданного редактору потока данных. В некоторых случаях с помощью sed надо обработать лишь какую-то часть текста — некую конкретную строку или группу строк. Для достижения такой цели можно воспользоваться двумя подходами:
- Задать ограничение на номера обрабатываемых строк.
- Указать фильтр, соответствующие которому строки нужно обработать.

Обработка только одной строки, номер который задан при вызове sed
Второй вариант — диапазон строк:

Обработка диапазона строк
Кроме того, можно вызвать команду замены так, чтобы файл был обработан начиная с некоей строки и до конца:

Обработка файла начиная со второй строки и до конца
Для того, чтобы обрабатывать с помощью команды замены только строки, соответствующие заданному фильтру, команду надо вызвать так:
По аналогии с тем, что было рассмотрено выше, шаблон передаётся перед именем команды s .

Обработка строк, соответствующих фильтру
Тут мы использовали очень простой фильтр. Для того, чтобы в полной мере раскрыть возможности данного подхода, можно воспользоваться регулярными выражениями. О них мы поговорим в одном из следующих материалов этой серии.
Удаление строк
Утилита sed годится не только для замены одних последовательностей символов в строках на другие. С её помощью, а именно, используя команду d , можно удалять строки из текстового потока.
Вызов команды выглядит так:
Мы хотим, чтобы из текста была удалена третья строка. Обратите внимание на то, что речь не идёт о файле. Файл останется неизменным, удаление отразится лишь на выводе, который сформирует sed.

Удаление третьей строки
Если при вызове команды d не указать номер удаляемой строки, удалены будут все строки потока.
Вот как применить команду d к диапазону строк:

Удаление диапазона строк
А вот как удалить строки, начиная с заданной — и до конца файла:

Удаление строк до конца файла
Строки можно удалять и по шаблону:

Удаление строк по шаблону
При вызове d можно указывать пару шаблонов — будут удалены строки, в которых встретится шаблон, и те строки, которые находятся между ними:

Удаление диапазона строк с использованием шаблонов
Вставка текста в поток
С помощью sed можно вставлять данные в текстовый поток, используя команды i и a :
- Команда i добавляет новую строку перед заданной.
- Команда a добавляет новую строку после заданной.

Теперь взглянем на команду a :

Как видно, эти команды добавляют текст до или после данных из потока. Что если надо добавить строку где-нибудь посередине?
Тут нам поможет указание номера опорной строки в потоке, или шаблона. Учтите, что адресация строк в виде диапазона тут не подойдёт. Вызовем команду i , указав номер строки, перед которой надо вставить новую строку:

Команда i с указанием номера опорной строки
Проделаем то же самое с командой a :

Команда a с указанием номера опорной строки
Обратите внимание на разницу в работе команд i и a . Первая вставляет новую строку до указанной, вторая — после.
Замена строк
Команда c позволяет изменить содержимое целой строки текста в потоке данных. При её вызове нужно указать номер строки, вместо которой в поток надо добавить новые данные:

Замена строки целиком
Если воспользоваться при вызове команды шаблоном в виде обычного текста или регулярного выражения, заменены будут все соответствующие шаблону строки:

Замена строк по шаблону
Замена символов
Команда y работает с отдельными символами, заменяя их в соответствии с переданными ей при вызове данными:

Замена символов
Используя эту команду, нужно учесть, что она применяется ко всему текстовому потоку, ограничить её конкретными вхождениями символов нельзя.
Вывод номеров строк
Если вызвать sed, использовав команду = , утилита выведет номера строк в потоке данных:

Вывод номеров строк
Потоковый редактор вывел номера строк перед их содержимым.
Если передать этой команде шаблон и воспользоваться ключом sed -n , выведены будут только номера строк, соответствующих шаблону:

Вывод номеров строк, соответствующих шаблону
Чтение данных для вставки из файла
Выше мы рассматривали приёмы вставки данных в поток, указывая то, что надо вставить, прямо при вызове sed. В качестве источника данных можно воспользоваться и файлом. Для этого служит команда r , которая позволяет вставлять в поток данные из указанного файла. При её вызове можно указать номер строки, после которой надо вставить содержимое файла, или шаблон.

Вставка в поток содержимого файла
Тут содержимое файла newfile было вставлено после третьей строки файла myfile .
Вот что произойдёт, если применить при вызове команды r шаблон:

Использование шаблона при вызове команды r
Содержимое файла будет вставлено после каждой строки, соответствующей шаблону.
Пример
Представим себе такую задачу. Есть файл, в котором имеется некая последовательность символов, сама по себе бессмысленная, которую надо заменить на данные, взятые из другого файла. А именно, пусть это будет файл newfile , в котором роль указателя места заполнения играет последовательность символов DATA . Данные, которые нужно подставить вместо DATA , хранятся в файле data .
Решить эту задачу можно, воспользовавшись командами r и d потокового редактора sed:

Замена указателя места заполнения на реальные данные
Как видите, вместо заполнителя DATA sed добавил в выходной поток две строки из файла data .
Итоги
Сегодня мы рассмотрели основы работы с потоковым редактором sed. На самом деле, sed — это огромнейшая тема. Его изучение вполне можно сравнить с изучением нового языка программирования, однако, поняв основы, вы сможете освоить sed на любом необходимом вам уровне. В результате ваши возможности по обработке с его помощью текстов будет ограничивать лишь воображение.
На сегодня это всё. В следующий раз поговорим о языке обработки данных awk.
Читайте также: