Настройка дедупликации windows server 2012 r2
Обновлено: 03.07.2024
егодня хотелось бы провести обзор такой интересной новой возможности Windows Server 2012 как дедупликация данных (data deduplication). Возможность крайне интересная, но все же сначала нужно разобраться, насколько она нужна…
А нужна ли вообще дедупликация?
С каждым годом (если не днем) объемы жестких дисков растут, а при этом носители сами еще и дешевеют.
Исходя из этой тенденции, возникает вопрос: «А нужна ли вообще дедупликация данных?».
Однако, если мы с вами живем в нашей Вселенной и на нашей планете, то всё в этом мире имеет свойство подчиняться третьему закону Ньютона. Может аналогия и не совсем прозрачная, но я подвожу к тому, что как бы не дешевели дисковые системы и сами диски, как бы не увеличивался объем самих носителей — требования с точки зрения бизнеса к доступному для хранения данных пространству постоянно растут и тем самым нивелируют увеличение объема и падение цен.
По прогнозам IDC примерно через год в суммарном объеме будет требоваться порядка 90 миллионов терабайт. Объем, скажем прямо, не маленький.
.jpg)
И вот тут как раз вопрос о дедупликации данных выходит на первый план. Ведь данные, которые мы используем, бывают и разных типов, и назначение у них могут быть разные — где-то это production-данные, где-то это архивы и резервные копии, а где-то это потоковые данные, — я специально привел такие примеры, поскольку в первом случае эффект от использования дедупликации будет средним, в архивных данных — максимальным, а в случае с потоковыми данным — минимальным. Но все же экономить пространство мы с вами сможем, тем более что теперь дедупликация — это удел не только специализированных систем хранения данных, но и компонент серверной ОС Windows Server 2012.
Типы дедупликации и их применение
Прежде чем перейти к обзору самого механизма дедупликации в Windows Server 2012, давайте разберемся, какие типы дедупликации бывают. Предлагаю начать сверху-вниз, на мой взгляд, так оно будет нагляднее.
1) Файловая дедупликация — как и у любого механизма дедупликации, работа алгоритма сводится к поиску уникальных наборов данных и повторяющихся, и вторые типы наборов заменяются ссылками на первые наборы. Иными словами алгоритм пытается хранить только уникальные данные, заменяя повторяющиеся данные ссылками на уникальные. Как нетрудно догадаться из названия данного типа дедупликации — все подобные операции происходят на уровне файлов. Если вспомнить историю продуктов Microsoft — то данный подход уже неоднократно применялся ранее — в Microsoft Exchange Server и Microsoft System Center Data Protection Manager — и назывался этот механизм S.I.S. (Single Instance Storage). В продуктах линейки Exchange от него в свое время отказались из соображений производительности, а вот в Data Protection Manager этот механизм до сих пор успешно применяется и, кажется, будет применяться и дальше. Как нетрудно догадаться, файловый уровень — самый высокий (если вспомнить устройство систем хранения данных в общем), а потому и эффект будет самый минимальный по сравнению с другими типами дедупликации. Область применения — в основном пархивные данные.
2) Блочная дедупликация — данный механизм уже интереснее, поскольку работает он на субфайловом уровне — а именно на уровне блоков данных. Такой тип дедупликации, как правило, характерен для промышленных систем хранения данных, а также именно этот тип дедупликации применяется в Windows Server 2012. Механизмы всё те же, что и раньше — но на уровне блоков (кажется, я это уже говорил, да?). Здесь сфера применения дедупликации расширяется и теперь распространяется не только на архивные данные, но и на виртуализованные среды, что вполне логично, особенно для VDI-сценариев. Если учесть, что VDI — это целая туча повторяющихся образов виртуальных машин, в которых все же есть отличия друг от друга (именно поэтому файловая дедупликация тут бессильна), то блочная дедупликация — наш выбор!
3) Битовая дедупликаия — самый низкий (глубокий) тип дедупликации данных. Он обладает самой высокой степенью эффективности, но при этом также является лидером по ресурсоемкости. Оно и понятно — проводить анализ данных на уникальность и плагиатичность — процесс нелегкий. Честно скажу — я лично не знаю систем хранения данных, которые оперируют на таком уровне дедупликации, но я точно знаю, что есть системы дедупликации трафика, которые работают на битовом уровне, допустим, тот же Citrix NetScaler. Смысл подобных систем и приложений заключается в экономии передаваемого трафика — это очень критично для сценариев с территориально-распределенными организациями, где есть множество разбросанных географически отделений предприятия, но отсутствуют или крайне дороги в эксплуатации широкие каналы передачи данных — тут решения в области битовой дедупликации найдут себя как нигде ранее и раскроют свои таланты.
Очень интересным в этом плане выглядит доклад Microsoft на USENIX 2012, который состоялся в Бостоне в июне месяце. Был проведен достаточно масштабный анализ первичных данных с точки зрения применения к ним механизмов блочной дедупликации в WIndows Server 2012 — рекомендую ознакомиться с данным материалом.
Вопросы эффективности
Для того чтобы понять, насколько эффективны технологии дедупликации в Windows Server 2012, сначала нужно определить, на каком типе данных эту самую эффективность следует измерять. За эталоны были взяты типичные файловые разделяемые ресурсы, документы пользователей из папки «Мои документы», хранилища дистрибутивов и библиотеки и хранилища виртуальных жестких дисков.
.jpg)
Насколько же эффективна дедупликация с точки зрения рабочих нагрузок, проверили в Microsoft в отделе разработки ПО.
Три наиболее популярных сценария стали объектами исследования:
- Сервера сборки билдов ПО. В MS каждый день собирается приличное количество билдов самых разных продуктов. Даже незначительное изменение в коде приводит к процессу сборки билда, и, следовательно, дублирующихся данных создается очень много
- Разделяемые ресурсы с дистрибутивами продуктов на релиз. Как не сложно догадаться, все сборки и готовые версии ПО нужно где-то размещать. Внутри Microsoft для этого есть специальные сервера, где все версии и языковые редакции всех продуктов размещаются — это тоже достаточно эффективный сценарий, где эффективность от дедупликации может достигать до 70%.
- Групповые разделяемые каталоги. Это сочетание разделяемых папок с документами и файлами разработчиков, а также их перемещаемые профили и перенаправленные папки, которые хранятся в едином центральном пространстве.
.jpg)
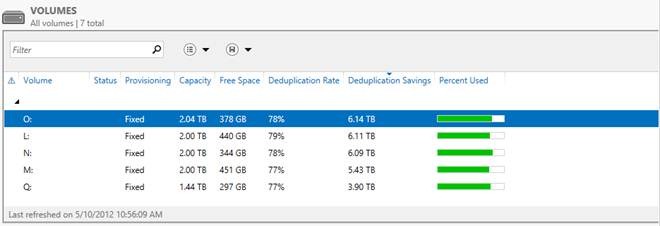
А теперь самое интересное — ниже приведен снимок окна с томами в Windows Server 2012, на которых размещаются все эти данные.
Я думаю слова здесь излишни — все и так очень наглядно. Экономия в 6 Тб на носителях в 2 Тб — термоядерное хранилище? Не так опасно — но столь эффективно!
Характеристики дедупликации в Windows Server 2012
А теперь давайте рассмотрим основные характеристики дедупликации в Windows Server 2012.
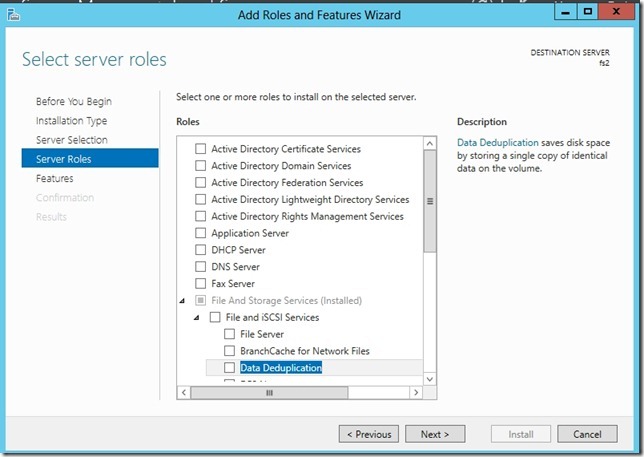
- Прозрачность и легкость в использовании. Настроить дедупликацию крайне просто. Сначала в мастере ролей в Windows Server вы раскрываете роль File and Storage Services, далее File and iSCSI Services, и уже там включаете опцию Data Deduplication.
- После этого в Server Manager вы выбираете File and Storage Services, клик правой кнопкой мыши, и там выбираете пункт «Enable Volume Deduplication». Специальная ссылка для любителей PowerShell. Все крайне просто. С точки зрения конечного пользователя и приложений доступ и работа с данными осуществляются прозрачно и незаметно. Если говорить про дедупликацию с точки зрения фаловой системы, то поддерживается только NTFS. ReFS не поддается дедупликации, ровно как и тома, защищенные с помощью EFS (Encrypted File System). Также под дедупликацию не попадают файлы объемом менее 32 KB и файлы с расширенными атрибутами (extended attributes). Дедупликация, однако, распространяется на динамические тома, тома, зашифрованные с помощью BitLocker, но не распространяется на тома CSV, а также системные тома (что логично).
- Оптимизация под основные данные. Стоит сразу отметить, что дедупликация — это не онлайн-процесс. Дедупликации подвергаются файлы, которые достигают определенного уровня старости с точки зрения задаваемой политики. После достижения определенного срока хранения данные начинают проходить через процесс дедупликации — по умолчанию этот промежуток времени равен пяти дням, но никто не мешает вам изменить этот параметр (будьте разумны в своих экспериментах!)
- Планирование процессов оптимизации. Механизм, который каждый час проверяет файлы на соответствие параметрам дедупликации и добавляет их в расписание.
- Механизмы исключения объектов из области дедупликации. Данный механизм позволяет исключит файлы из области дедупликации по их типу (например, JPG, MOV, AVI. Это потоковые данные — то, что меньше всего поддается дедупликации, если вообще поддается). Можно также исключить сразу целые папки с файлами из области дедупликации (это для любителей немецких фильмов, у которых их тьма-тьмущая).
- Мобильность. Дедуплицированный том — это целостный объект, и его можно переносить с одного сервера на другой (речь идет исключительно о Windows Server 2012). При этом вы без проблем получите доступ к вашим данным и сможете продолжить работу с ними. Всё что для этого необходимо — это включенная опция Data Deduplication на целевом сервере.
- Оптимизация ресурсоемкости. Данные механизмы подразумевают оптимизацию алгоритмов для снижения нагрузки по операциям чтения/записи, таким образом, если мы говорим про размер хеш-индекса блоков данных, то размер индекса на 1 блок данных составляет 6 байт. Таким образом, применять дедупликацию можно даже к очень массивным наборам данных.
- Также алгоритм всегда проверяет, достаточно ли ресурсов памяти для проведения процесса дедупликации. Если ответ отрицательный, то алгоритм отложит процесс до высвобождения необходимого объема ресурсов.
- Интеграция с BranchCache. Механизмы индексация для дедупликация являются общими также и для BranchCache, поэтому эффективность использования данных технологий в связке не вызывает сомнений!
Вопросы надежности дедуплицированных томов
Вопрос надежности крайне остро встает для дедуплицированных данных — представьте, что блок данных, от которого зависят по крайней мере 1000 файлов, безнадежно поврежден… Думаю, валидол-эз-э-сервис тогда точно пригодится, но не в нашем случае.
- Резервное копирование. Windows Server 2012, как и System Center Data Protection Manager 2012 SP1 полностью поддерживают дедуплицированные тома с точки зрения процессов резервного копирования. Также доступен специальный API, который позволяет сторонним разработчикам использовать и поддерживать механизмы дедупликации, а также восстанавливать данные из дедуплицированных архивов.
- Дополнительные копии для критичных данных. Те данные, которые имеет самый частый параметр обращения, подвергаются процессу создания дополнительных резервных блоков — это особенности алгоритма механизма. Также, в случае использования механизмов Storage Spaces, при нахождении сбойного блока, алгоритм автоматически заменяет его на целостный из пары в зеркале.
- По умолчанию, один раз в неделю запускается процесс нахождения мусора и сбойных блоков, который исправляет данные приобретенные патологии. Есть также возможность вручную запустить данный процесс на более глубоком уровне. Если процесс по умолчанию исправляет ошибки, которые были зафиксированы в логе событий, то более глубокий процесс подразумевает сканирование всего тома целиком.
С чего начать и как померить
Перед тем как включать дедупликацию, всегда нормальному человеку в голову придет мысль о том, насколько эффективен будет данный механизм конкретно в его случае. Для этого вы можете использовать Deduplication Data Evaluation Tool.
На этом мой обзор завершен. Надеюсь, вам было интересно. Если у вас возникнут вопросы — можете смело найти меня в соц.сетях ВКонтакте, Facebook по имени и фамилии, и я постараюсь вам помочь.
В этой статье описано, как установить дедупликацию данных, оценить рабочие нагрузки для дедупликации, а также включить дедупликацию данных для отдельных томов.
Если вы планируете использовать дедупликацию данных в отказоустойчивом кластере, на каждом узле кластера должна быть установлена роль сервера дедупликации данных.
Установка дедупликации данных
Обновление KB4025334 содержит накопительный пакет исправлений, в том числе обеспечивающих надежность системы. Мы настоятельно рекомендуем установить его при использовании дедупликации данных в Windows Server 2016.
Установка дедупликации данных с помощью диспетчера сервера
Установка дедупликации данных с помощью PowerShell
Чтобы установить дедупликацию данных, выполните следующую команду PowerShell от имени администратора: Install-WindowsFeature -Name FS-Data-Deduplication
Чтобы установить дедупликацию данных на Nano Server:
Создайте установку Nano Server с установленным хранилищем, как описано в руководстве Приступая к работе с сервером Nano Server.
На сервере под управлением Windows Server 2016 в любом режиме, отличном от Nano Server, или на персональном компьютере Windows с установленным пакетом средств удаленного администрирования сервера (RSAT) установите дедупликацию данных с явной ссылкой на экземпляр Nano Server (замените текст "MyNanoServer" реальным именем экземпляра Nano Server):
Включение дедупликации данных
Определение рабочих нагрузок для дедупликации
Дедупликация данных может очень эффективно снизить затраты, связанные с потреблением данных серверного приложения, уменьшая объем, занимаемый избыточными данными на дисках. Прежде чем включать дедупликацию, очень важно определить характеристики рабочей нагрузки. Это позволит добиться максимальной производительности хранилища. Существует два класса рабочих нагрузок, для которых стоит применять дедупликацию.
- Рекомендуемые рабочие нагрузки — используют наборы данных, для которых дедупликация крайне эффективна. Такие нагрузки также используют схемы потребления ресурсов, которые совместимы с моделью постобработки, применяемой при дедупликации данных. Для следующих рабочих нагрузок включать дедупликацию данных рекомендуется всегда:
- файловые серверы общего назначения (GPFS) с такими общими ресурсами, как общие групповые папки, домашние папки пользователей, рабочие папки и общие ресурсы для разработки программного обеспечения;
- серверы инфраструктуры виртуальных рабочих столов (VDI);
- Виртуализированные приложения резервного копирования, такие как Microsoft Data Protection Manager (DPM).
- узлы Hyper-V общего назначения;
- Серверы SQL Server
- производственные серверы.
Оценка дедупликации данных для рабочих нагрузок
Если вы используете рекомендуемые рабочие нагрузки, можно пропустить этот раздел и сразу включить дедупликацию данных.
Чтобы определить, применимость дедупликации для рабочей нагрузки, ответьте на следующие вопросы. Если вы не уверены в характеристиках рабочей нагрузки, можно выполнить пилотное развертывание дедупликации данных на тестовом наборе данных этой рабочей нагрузки.
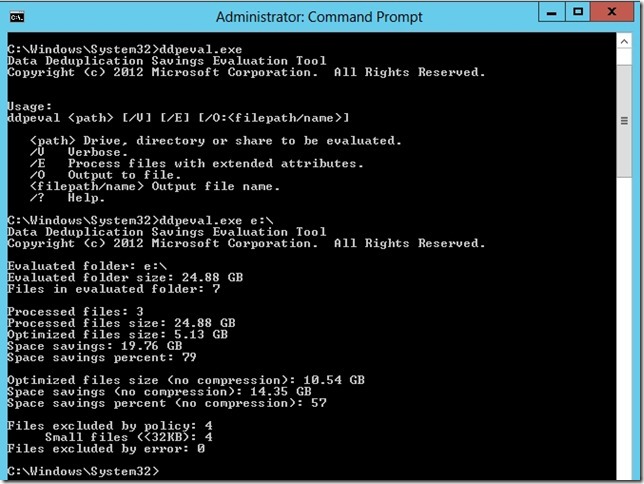
Есть ли в наборе данных рабочей нагрузки достаточный объем дублирующихся данных, чтобы включение дедупликации дало ощутимый эффект? Прежде чем включать дедупликацию данных для рабочей нагрузки, оцените объем дублирующихся данных в наборе данных, используя средство оценки экономии от дедупликации данных (DDPEval). После установки дедупликации данных это средство можно найти здесь: C:\Windows\System32\DDPEval.exe . DDPEval поможет вам оценить потенциальный эффект оптимизации для непосредственно подключенных томов (включая локальные диски или общие тома кластера), а также для сопоставленных или несопоставленных сетевых папок. При выполнении DDPEval.exe будут возвращены выходные данные, аналогичные следующим: Data Deduplication Savings Evaluation Tool Copyright 2011-2012 Microsoft Corporation. All Rights Reserved. Evaluated folder: E:\Test Processed files: 34 Processed files size: 12.03MB Optimized files size: 4.02MB Space savings: 8.01MB Space savings percent: 66 Optimized files size (no compression): 11.47MB Space savings (no compression): 571.53KB Space savings percent (no compression): 4 Files with duplication: 2 Files excluded by policy: 20 Files excluded by error: 0
Как выглядят шаблоны ввода-вывода рабочей нагрузки в наборе данных? Какова производительность для моей рабочей нагрузки? Дедупликация данных оптимизирует файлы, выполняя периодическое задание, а не во время сохранения файла на диск. В связи с этим сначала следует оценить ожидаемые шаблоны рабочей нагрузки на чтение из дедуплицированного тома. Поскольку дедупликация данных перемещает содержимое файла в хранилище блоков и пытается как можно плотнее заполнять его файлами, более эффективно будут выполняться операции чтения из последовательных диапазонов файла.
Рабочие нагрузки баз данных обычно имеют более случайный характер операций чтения, так как база данных не гарантирует оптимальную структуру данных для всех возможных выполняемых запросов. Данные из одного раздела хранилища блоков могут располагаться в разных частях тома, поэтому обращение к хранилищу данных может приводить к дополнительным задержкам. Высокопроизводительные рабочие нагрузки особенно чувствительны к таким задержкам, но это справедливо не для всех баз данных.
Эти проблемы особенно важны для рабочих нагрузок, которые хранят данные на томах, состоящих из традиционных носителей с вращающимися дисками (жесткие диски или HDD). Любая инфраструктура флэш-памяти (твердотельные накопители или SSD) менее подвержена проблемам случайных операций ввода-вывода, так как флэш-память обеспечивает одинаковое время доступа ко всем расположениям на носителе. Таким образом, дедупликация будет сопряжена с разной величиной задержки при операциях чтения в зависимости от того, где хранятся наборы данных рабочей нагрузки: на носителях на основе флэш-памяти или на традиционных вращающихся дисках.
Какие требования к ресурсам сервера предъявляет рабочая нагрузка? Так как дедупликация данных использует модель постобработки, она предполагает периодическое выделение значительных системных ресурсов для выполнения оптимизации и других заданий. Это означает, что рабочие нагрузки с определенными периодами простоя (например, в вечернее время или выходные дни) прекрасно подходят для дедупликации, в отличие от рабочих нагрузок, выполняемых круглосуточно изо дня в день. Но при этом дедупликацию можно успешно применить и для рабочих нагрузок без периодов простоя, если такие нагрузки не имеют высоких требований к ресурсам сервера.
Включение дедупликации данных
Перед включением дедупликации данных следует выбрать тип использования, который соответствует вашей рабочей нагрузке. Существует три типа использования для дедупликации данных:
-
— оптимальные настройки для файлового сервера общего назначения. — настройки специально для серверов VDI. — оптимальные настройки для виртуализированных приложений резервного копирования, таких как Microsoft DPM.
Включение дедупликации данных с помощью диспетчера сервера
Дополнительные сведения об исключении определенных расширений файлов или папок, а также о создании расписания дедупликации (включая описание причин этих изменений), см. на странице Настройка дедупликации данных.
Включение дедупликации данных с помощью PowerShell
Выполните следующую команду PowerShell с правами администратора:
Если вы используете рекомендуемую рабочую нагрузку, на этом процесс окончен. Для других рабочих нагрузок изучите раздел Дополнительные вопросы.
Командлеты PowerShell для дедупликации данных, включая Enable-DedupVolume , можно запустить удаленно, добавив -CimSession параметр в сеанс CIM. Это особенно полезно для удаленного выполнения командлетов PowerShell на экземпляре Nano Server. Чтобы создать новый сеанс CIM, выполните команду New-CimSession .
Дополнительные рекомендации
Если ваша рабочая нагрузка относится к категории рекомендуемых, этот раздел можно пропустить.
- Типы использования, доступные при дедупликации данных, предусматривают практические стандартные значения для рекомендуемых рабочих нагрузок, а также используются в качестве отправной точки для остальных рабочих нагрузок. Для рабочих нагрузок, не входящих в категорию рекомендуемых, вы можете изменить дополнительные параметры дедупликации данных, чтобы повысить ее эффективность.
- Если рабочая нагрузка характеризуется высокими требованиями к ресурсам сервера, задания дедупликации данных следует запланировать на период ожидаемого простоя рабочей нагрузки. Это особенно важно, если дедупликация выполняется на гиперконвергированном узле, ведь в рабочее время процессы дедупликации могут истощить ресурсы виртуальных машин.
- Если рабочая нагрузка не особо требовательна к ресурсам или быстрое выполнение заданий оптимизации важнее, чем обслуживание запросов рабочей нагрузки, вы можете настроить параметры выделения памяти, ЦП и приоритета для заданий дедупликации.
Вопросы и ответы
Я хочу выполнить дедупликацию данных в наборе данных для рабочей нагрузки X. Поддерживается ли это? Мы полностью гарантируем целостность данных при применении дедупликации данных с любой рабочей нагрузкой, кроме включенных в список несовместимых с дедупликацией. Для рекомендуемых рабочих нагрузок корпорация Майкрософт также гарантирует повышение производительности. Производительность других рабочих нагрузок в значительной мере зависит от того, какие действия они выполняют на сервере. Необходимо определить, каким образом дедупликация данных повлияла на вашу рабочую нагрузку и допустимо ли такое влияние для этой нагрузки.
Каковы требования к размеру тома для дедуплицированных томов? В Windows Server 2012 и Windows Server 2012 R2 размер тома следует выбирать осторожно, чтобы дедупликация данных выполнялась в соответствии со скоростью обновления данных в томе. В большинстве случаев максимальный размер дедуплицированного тома для рабочей нагрузки с высокой скоростью обновления данных составляет 1–2 ТБ. Мы рекомендуем в любом случае не превышать размер 10 ТБ. Эти ограничения устранены в Windows Server 2016. Дополнительные сведения см. в статье Новые возможности функции дедупликации данных.
Нужно ли изменять расписание или другие параметры дедупликации данных для рекомендуемых рабочих нагрузок? Нет, предоставленные типы использования были созданы для предоставления разумных значений по умолчанию для рекомендуемых рабочих нагрузок.
Каковы требования к памяти для дедупликации данных? При дедупликации данных следует выделить по меньшей мере 300 МБ, а также дополнительно 50 МБ на каждый терабайт логических данных. Например, если вы оптимизируете том размером 10 ТБ, для дедупликации следует выделить не менее 800 МБ памяти ( 300 MB + 50 MB * 10 = 300 MB + 500 MB = 800 MB ). Дедупликация данных может выполняться и с меньшим объемом памяти, но такое ограничение ресурсов замедлит выполнение заданий этой функции.
Лучше всего, если для дедупликации данных будет выделено по 1 ГБ памяти на каждый 1 ТБ логических данных. Например, если вы оптимизируете том размером 10 ТБ, оптимальный объем памяти для дедупликации составит 10 ГБ ( 1 GB * 10 ). Такое соотношение обеспечит максимальную производительность для заданий дедупликации данных.
Каковы требования к объему хранилища для дедупликации данных? В Windows Server 2016 дедупликация данных может поддерживать тома размером до 64 ТБ. Дополнительные сведения см. в статье What's new in Data Deduplication (Новые возможности функции дедупликации данных).
Сегодня хотелось бы провести обзор такой интересной новой фичи в Windows Server 2012 как дедупликация данных (data deduplication). Фича крайне интересная, но все же сначала нужно разобраться насколько она нужна…
![]()
С каждым годом (если не днем) объемы жестких дисков растут, а при этом носители сами еще и дешевеют.
Исходя из этой тенденции возникает вопрос: «А нужна ли вообще дедупликация данных?».
Однако, если мы с вами живем в нашей вселенной и на нашей планете, то практически все в этом мире имеет свойство подчиняться 3-му закону Ньютона. Может аналогия и не совсем прозрачная, но я подвожу к тому, что как бы не дешевели дисковые системы и сами диски, как бы не увеличивался объем самих носителей — требования с точки зрения бизнеса к доступному для хранения данных пространства постоянно растут и тем самым нивелируют увеличение объем и падение цен.
По прогнозам IDC примерно через год в суммарном объеме будет требоваться порядка 90 миллионов терабайт. Объем, скажем прямо, не маленький.![]()
И вот тут как раз вопрос о дедупликации данных очень сильно становится актуальным. Ведь данные, которые мы используем бывают и разных типов, и назначение у них могут быть разные — где-то это production-данные, где-то это архивы и резервные копии, а где-то это потоковые данные — я специально привел такие примеры, поскольку в первом случае эффект от использования дедупликации будет средним, в архивных данных — максимальным, а в случае с потоковыми данным — минимальным. Но все же экономить пространство мы с вами сможем, тем более что теперь дедупликация — это удел не только специализированных систем хранения данных, но и компонент, фича серверной ОС Windows Server 2012.
Типы дедупликации и их применение
Прежде чем перейти к обзору самого механизма дедупликации в Windows Server 2012, давайте разберемся какие типы дедупликации бывают. Предлагаю начать сверху-вниз, на мой взгляд так оно будет нагляднее.
1) Файловая дедупликация — как и любой механизм дедупликации, работа алгоритма сводится к поиску уникальных наборов данных и повторяющихся, где вторые типы наборов заменяются ссылками на первые наборы. Иными словами алгоритм пытается хранить только уникальные данные, заменяя повторяющиеся данные ссылками на уникальные. Как нетрудно догадаться из названия данного типа дедупликации — все подобные операции происходят на уровне файлов. Если вспомнить историю продуктов Microsoft — то данный подход уже неоднократно применялся ранее — в Microsoft Exchange Server и Microsoft System Center Data Protection Manager — и назывался этот механизм S.I.S. (Single Instance Storage). В продуктах линейки Exchange от него в свое время отказались из соображений производительности, а вот в Data Protection Manager этот механизм до сих пор успешно применяется и кажется будет продолжать это делать. Как нетрудно догадаться — файловый уровень самый высокий (если вспомнить устройство систем хранения данных в общем) — а потому и эффект будет самый минимальный по сравнению с другими типами дедупликации. Область применения — в основном применяется данный тип дедупликации к архивным данным.
2) Блочная дедупликация — данный механизм уже интереснее, поскольку работает он суб-файловом уровне — а именно на уровне блоков данных. Такой тип дедупликации, как правило характерен для промышленных систем хранения данных, а также именно этот тип дедупликации применяется в Windows Server 2012. Механизмы все те же, что и раньше — но на уровне блоков (кажется, я это уже говорил, да?). Здесь сфера применения дедупликации расширяется и теперь распространяется не только на архивные данные, но и на виртуализованные среды, что вполне логично — особенно для VDI-сценариев. Если учесть что VDI — это целая туча повторяющихся образов виртуальных машин, в которых все же есть отличия друг от друга (именно по этому файловая дедупликация тут бессильна) — то блочная дедупликация — наш выбор!
3) Битовая дедупликаия — самый низкий (глубокий) тип дедупликации данных — обладает самой высокой степенью эффективности, но при этом также является лидером по ресурсоемкости. Оно и понятно — проводить анализ данных на уникальность и плагиатичность — процесс нелегкий. Честно скажу — я лично не знаю систем хранения данных, которые оперируют на таком уровне дедупликации, но я точно знаю что есть системы дедупликации трафика, которые работают на битовом уровне, допустим тот же Citrix NetScaler. Смысл подобных систем и приложений заключается в экономии передаваемого трафика — это очень критично для сценариев с территориально-распределенными организациями, где есть множество разбросанных географически отделений предприятия, но отсутствуют или крайне дороги в эксплуатации широкие каналы передачи данных — тут решения в области битовой дедупликации найдут себя как нигде еще и раскроют свои таланты.
Очень интересным в этом плане выглядит доклад Microsoft на USENIX 2012, который состоялся в Бостоне в июне месяце. Был проведен достаточно масштабный анализ первичных данных с точки зрения применения к ним механизмов блочной дедупликации в WIndows Server 2012 — рекомендую ознакомиться с данным материалом.
Вопросы эффективности
Для того чтобы понять насколько эффективны технологии дедупликации в Windows Server 2012, сначала нужно определить на каком типе данных эту самую эффективность следует измерять. За эталоны были взяты типичные файловые шары, документы пользователей из папки «Мои документы», Хранилища дистрибутивов и библиотеки и хранилища виртуальных жестких дисков.
![]()
Насколько же эффективна дедупликация с точки зрения рабочих нагрузок проверили в Microsoft в отделе разработки ПО.
3 наиболее популярных сценария стали объектами исследования:1) Сервера сборки билдов ПО — в MS каждый день собирается приличное количество билдов самых разных продуктов. Даже не значительно изменение в коде приводит к процессу сборки билда — и следовательно дублирующихся данных создается очень много
2) Шары с дистрибутивами продуктов на релиз — Как не сложно догадаться, все сборки и готовые версии ПО нужно где-то размещать — внутри Microsoft для этого есть специальные сервера, где все версии и языковые редакции всех продуктов размещаются — это тоже достаточно эффективный сценарий, где эффективность от дедупликации может достигать до 70%.
3) Групповые шары — это сочетание шар с документами и файлами разработчиков, а также их перемещаемые профили и перенаправленные папки, которые хранятся в едином центральном пространстве.
![]()
А теперь самое интересное — ниже приведен скриншот с томами в Windows Server 2012, на которых размещаются все эти данные.
![]()
Я думаю слова здесь будут лишними — и все и так очень наглядно. Экономия в 6 Тб на носителях в 2 Тб — термоядерное хранилище? Не так опасно — но столь эффективно!
Характеристики дедупликации в Windows Server 2012
А теперь давайте рассмотрим основные характеристики дедупликации в Windows Server 2012.
1) Прозрачность и легкость в использовании — настроить дедупликацию крайне просто. Сначала в мастере ролей в Windows Server вы раскрывайте роль File and Storage Services, далее File and iSCSI Services — а у же там включаете опцию Data Deduplication.
После этого в Server Manager вы выбираете Fike and Storage Services, клик правой кнопкой мыши — и там вы выбираете пункт «Enable Volume Deduplication». Спешл линк для любителей PowerShell. Все крайне просто. С точки зрения конечного пользователя и приложений доступ и работа с данными осуществляются прозрачно и незаметно. Если говорить про дедупликацию с точки зрения фаловой системы — то поддерживается только NTFS. ReFS не поддается дедупликации, ровно как и тома защищенные с помощью EFS (Encrypted Fike System). Также под дедупликацию не попадают фалы объемом менее 32 KB и файлы с расширенными атрибутами (extended attributes). Дедупликация, однако, распространяется на динамические тома, тома зашифрованные с помощью BitLocker, но не распространяется на тома CSV, а также системные тома (что логично).2) Оптимизация под основные данные — стоит сразу отметить, что дедупликация — это не онлайн-процесс. Дедупликации подвергаются файлы, которые достигают определенного уровня старости с точки зрения задаваемой политики. После достижения определенного срока хранения данные начинают проходить через процесс дедупликации — по умолчанию этот промежуток времени равен 5 дням, но никто не мешает вам изменить этот параметр — но будьте разумны в своих экспериментах!
3) Планирование процессов оптимизации — механизм который каждый час проверяет файлы на соответствия параметрам дедупликации и добавляет их в расписание.
4) Механизмы исключения объектов из области дедупликации — данный механизм позволяет исключит файлы из области дедупликации по их типу (JPG, MOV, AVI — как пример, это потоковые данны — то, что меньше всего поддается дедупликации — если вообще поддается). Можно также исключить сразу целые папки с файлами из области дедупликации (это для любителей немецких фильмов, у которых их тьма-тьмущая).
5) Мобильность — дедуплицированный том — это целостный объект — его можно переносить с одного сервера на другой (речь идет исключительно о Windows Server 2012). При этом вы без проблем получите доступ к вашим данным и сможете продолжить работу с ними. Все что для этого необходимо — это включенная опция Data Deduplication на целевом сервере.
6) Оптимизация ресурсоемкости — данные механизмы подразумевают оптимизацию алгоритмов для снижения нагрузки по операциям чтения/записи, таким образом если мы говорим про размер хеш-индекса блоков данных, то размер индекса на 1 блок данных составляет 6 байт. Таким образом применять дедупликацию можно даже к очень массивным наборам данных.
Также алгоритм всегда проверяет достаточно ли ресурсов памяти для проведения процесса дедупликации — если ответ отрицательный, то алгоритм отложит процесс до высвобождения необходимого объема ресурсов.7) Интеграция с BranchCache — механизмы индексация для дедупликация являются общими также и для BranchCache — поэтому эффективность использования данных технологий в связке не вызывает сомнений!
Вопросы надежности дедуплицированных томов
Вопрос надежности крайне остро встает для дедуплицированных данных — представьте, что блок данных, от корого зависят по-крайней мере 1000 файлов безнадежно поврежден… Думаю, валидол-эз-э-сервис тогда точно пригодится, но не в нашем случае.
1) Резервное копирование — Windows Server 2012, как и System Center Data Protection Manager 2012 SP1 полностью поддерживают дедуплицированные тома, с точки зрения процессов резервного копирования. Также доступно специальное API, которое позволяет сторонним разработчикам использовать и поддерживать механизмы дедупликации, а также восстанавливать данные из дедуплицированных архивов.
2) Дополнительные копии для критичных данных — те данные, которые имеет самый частый параметр обращения продвергаются процессу создания дополнительных резервных блоков — это особенности алгоритма механизма. Также, в случае использования механизмов Storage Spaces, при нахождение сбойного блока, алгоритм автоматически заменяет его на целостный из пары в зеркале.
3) По умолчанию, 1 раз в неделю запускается процесс нахождения мусора и сбойных блоков, который исправляет данные приобретенные патологии. Есть также возможность вручную запустить данный процесс на более глубоком уровне. Если процесс по умолчанию исправляет ошибки, которые были зафиксированы в логе событий, то более глубокий процесс подразумевает сканирование всего тома целиком.
С чего начать и как померить
Перед тем как включать дедупликацию, всегда нормальному человеку в голову придет мысль о том насколько эффективен будет данный механизм конкретно в его случае. Для этого вы можете использовать Deduplication Data Evaluation Tool.
После установки дедупликации вы можете найти инструмент под названием DDPEval.exe, который находится в \Windows\System32\ — данная утиль может быть портирована на сменный носитель или другой том. Поддерживаются ОС Windows 7 и выше. Так что вы можете проанализировать ваши данный и понять стоимость овечье шкурки. (смайл).На этом мой обзор завершен. Надеюсь вам было интересно. Если у вас возникнут вопросы — можете смело найти меня в соц.сетях — ВКонтакте, Facebook — по имени и фамилии — и я постараюсь вам помочь.
Для тех, кто хочет узнать про новые возможности в Windows Server 2012, а также System Center 2012 SP1 — я всех приглашаю посетить IT Camp — 26 ноября, накануне TechEd Russia 2012 состоится данное мероприятие — проводить его будем я, Георгий Гаджиев и Саймон Перриман, который специально прилетает к нам из США.
14.12.2015![date]()
Windows Server 2012![directory]()
Один комментарий![comments]()
В Windows Server 2012 появилась новая функция Data Deduplication (Дедупликация данных). Что же такое дедубликация? Дедупликация данных в общем случае – это процедура поиска и удаления дублирующих данных на носителе информации без ущерба для целостности информации. Цель дудупликации – хранить информацию в небольших блоках (32-128 Кб), выявлять одинаковые (дублирующие блоки) и сохранять только одну копию для каждого блока, а блоки-дубликаты заменять ссылками на единственную копию.
Ранее для организации дедупликации приходилось использовать сторонние продукты (существуют как аппаратные решение по дедупликации на уровне дисковых массивов, так и программные на уровне файлов). Стоимость подобных решений была достаточно высока, ведь они в первую очередь ориентированы на богатых корпоративных заказчиков. Теперь эта функция абсолютно бесплатно доступна всем пользователям a Windows Server 2012.
Есть небольшой хак, позволяющий включить дедупликацию и в клиентских ОС (Windows 8 и Windows 8.1). Подробности в статье: Как включить дедупликацию данных в Windows 8.1В Windows Server 2012 функция дедупликация реализована в виде двух компонентов:
Указанные компоненты отвечают за поиск совпадающих данных, организации их хранения в единственном числе и корректное предоставление к ним доступа.
Функционал управления дедупликацей доступен из графического интерфейса и через PowerShell. Рассмотрим оба варианта.
Windows Server 2012 Data Deduplication GUI
Чтобы включить дедупликацию данных нужно установить компонент Data Deduplicaion роли File and Storage Services. Сделать это можно из консоли Server Manahger.
![Функция data deduplication в windows server 2012]()
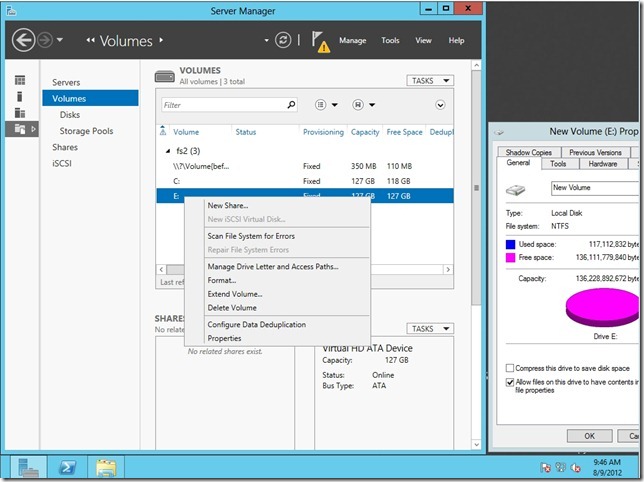
После окончания установки компонента откройте консоль Server manager -> File and Storage Servcies -> Volumes –> и щелкните правой кнопкой по разделу, для которого хотите включить дедупликацию и выберите Configure Data Deduplication.
![Включаем дедупликация для тома в windows server 2012]()
В следующем окне поставьте галочку на пункт “Enable data deduplication”. Здесь же можно указать каталоги, которые не нужно дедуплицировать и настройки планировщика дедупликации.
![Статус дедупликации в windows 2012]()
Текущий уровень дедупликации будет отображаться в столбце Deduplication Rate (обновится через несколько часов).
Для анализа использования дискового пространства и возможной экономии от включения дедупликаций для данного тома, разработана утилита DDPEVAL.exe. Оценить, сколько же дискового пространства получится сэкономить после включении Data deduplication, можно с помощью следующей команды (учтите, для больших томов она может создать существенную нагрузку на CPU)
![утилита DDPEVAL.exe]()
В моем случае экономия составила бы порядка 57%.
Дедупликация с Powershell
Процессом дедупликации можно управлять и из Powershell. Для этого нужно установить функцию Data-Deduplicationс помощью команд:
После того, как функция дедупликации включена, ее нужно сконфигурировать. Чтобы включить дедуплликацию для диска D:, выполним команду:
![Управление дедупликацией через PoSh]()
По-умолчаию дедупликации подвергаются файлы, к которым не было доступа (Last Access)более 30 дней. Это значение можно изменить, например, на 2 дня, для этого выполните команду:
Обычно процесс дедупликации запускается планировщиком Windows, но его можно запустить и вручную:
Текущую статистику можно посмотреть с помощью команды:
![Get-DedupStatus]()
Со списком текущих заданий можно познакомится с помощью команды:
Все результаты работы для тома можно отобразить командой PoSH:
И, наконец, полностью отменить дедупликацию для тома можно командой:
![Занятое место до и после включения дедупликации в Windows Server 2012]()
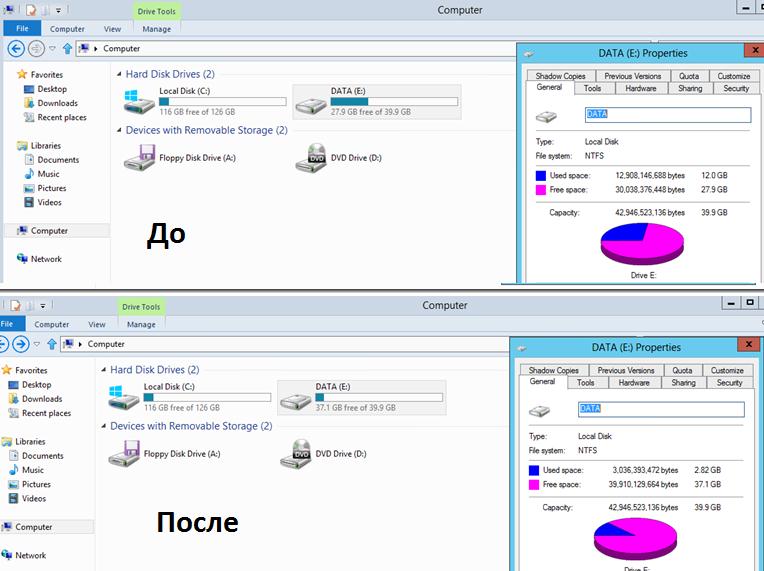
На скриншоте ниже видно, что после включения дедупликации на диске E: (для теста я сложил на него 4 одинаковых ISO с Windows 8), размер занятого места на диске уменьшился с 12 Гб до 3Гб.
Служба дедупликации хранит свою базу и дедуплицированные чанки в каталоге System Volume Information. Поэтому ни в коем случае не стоит вручную вмешиваться в его структуру.Рекомендации по использованию технологии Data Deduplication в Windows Server 2012
Microsoft опубликовала следующие результаты исследования эффективности при дудупликации различных типов данных.
Типы данных Возможная экономия места Общие данные 50-60% Документы 30-50% Библиотека приложений 70-80% Библиотека VHD(X) 80-95% Основные особенности Data Deduplication в Windows Server 2012:
Новые версии серверных ОС от Microsoft, кроме спорного интерфейса, содержат большое количество новых возможностей, многие из которых раннее были доступны только крупным предприятиям и требовали значительных финансовых затрат. Одна из таких возможностей - дедупликация, технология позволяющая по новому посмотреть на использование уже существующих систем хранения для предприятий любого масштаба.
Основная проблема с которой сталкиваются сегодня администраторы систем хранения, это стремительный рост хранимых данных, который требует все нового и нового дискового пространства. А если добавить сюда необходимость хранения резервных копий, архивов и т.п., то проблема рационального использования дискового пространства встает в полный рост.
В тоже время очень многие файлы содержат дублирующуюся информацию, а то и являются практически полными дубликатами. Это характерно для файловых серверов общего назначения, где различные сотрудники могут хранить практически полные или незначительно различающиеся копии одного и того же файла. В хранилищах резервных копий и архивах дублирование информации также может достигать существенных объемов.
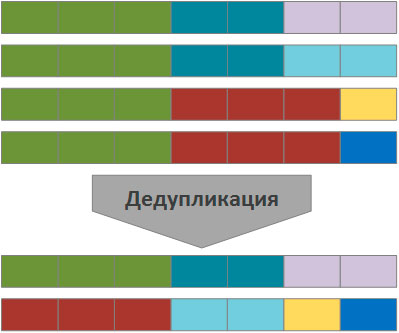
Дедупликация позволяет найти одинаковые части файлов и хранить их в единственном экземпляре, заменяя данные ссылкой на дублирующийся блок. Windows Server 2012 разбивает файлы на небольшие блоки (32-128 Кб), находит среди них одинаковые и помещает их в специальное хранилище, избыточные копии блоков заменяются ссылкой на единственный экземпляр в хранилище.
Схематично дедупликацию можно представить следующим образом (одинаковым цветом помечены одинаковые области данных):
![win2k12r2-deduplication-001.jpg]()
В зависимости от характера хранимой информации результат оптимизации может давать существенный выигрыш в дисковом пространстве, позволяя отложить увеличение емкости системы хранения, а, следовательно дополнительные материальные затраты.
Но данная технология не является панацеей, как нетрудно заметить, наибольший выигрыш будет на больших массивах данных, которые имеют много общих блоков и редко изменяются, для часто меняющихся данных дедупликация не даст никакого эффекта.
Наиболее подходящие кандидаты на дедупликацию:
- Файловые сервера
- Хранилища резервных копий и архивы
- Хранилища инсталляционных файлов и иной информации использующейся преимущественно только для чтения
- Библиотеки образов виртуальных машин
Не рекомендуется использовать дедупликацию для:
- Узлов Hyper-V
- SQL и Exchange серверов
- Служб WSUS
В остальных случаях требуется предварительный анализ и взвешивание всех возможных плюсов и минусов. Из общих рекомендаций: не рекомендуется включать дефрагментацию на томах с интенсивным вводом-выводом.
Также не следует заполнять дедуплицированные тома "под завязку", всегда необходимо иметь резерв на случай одновременного изменения большого объема дедуплицированных данных, чтобы не столкнуться с проблемой нехватки дискового пространства.
В Windows Server 2012 дедупликация поддерживается на уровне тома, в том числе допускается использование томов, расположенных во внешних хранилищах и подключенных по iSCSI. Не допускается дедупликация для системных томов и общих томов кластера (CSV).
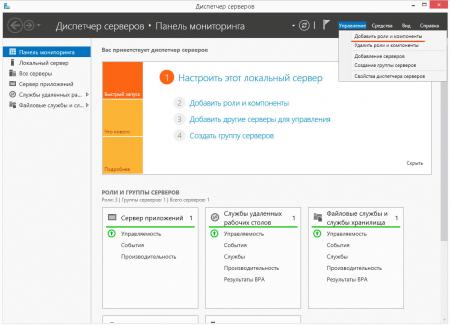
Перейдем от теории к практике. Для включения дедупликации откроем Диспетчер серверов - Управление - Добавить роли и компоненты.
![win2k12r2-deduplication-002.jpg]()
Затем выберем нужный сервер и, развернув роль Файловые службы и службы iSCSI, включим данную опцию. Закончим установку роли, перезагрузка сервера не потребуется.
![win2k12r2-deduplication-004.jpg]()
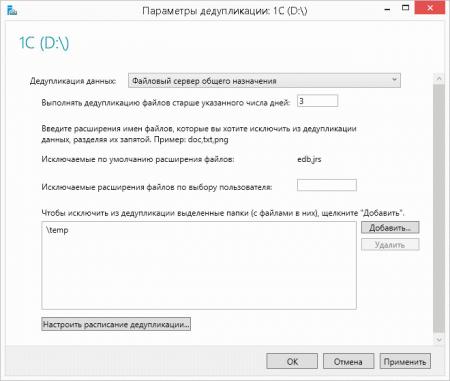
Настройки просты и понятны: выбираем профиль, срок хранения файла для включения его в дедупликацию и исключения, как по расширению, так и по местам хранения. Например, мы исключили из дедупликации временную папку.
![win2k12r2-deduplication-005.jpg]()
Отдельно стоит остановиться на возрасте файлов, выбирать этот параметр следует исходя из реальных условий, а именно интенсивности изменения данных и их объемов. После того как вы настроите дедупликацию, фоновая оптимизация будет производиться каждый час, поэтому если данные в течении этого времени будут активно изменяться, то система будет постоянно выполнять пустую работу. Слишком большие значения могут, наоборот, приводить к неэффективности процесса дедупликации, т.е. будут дублироваться довольно редко изменяемые данные.
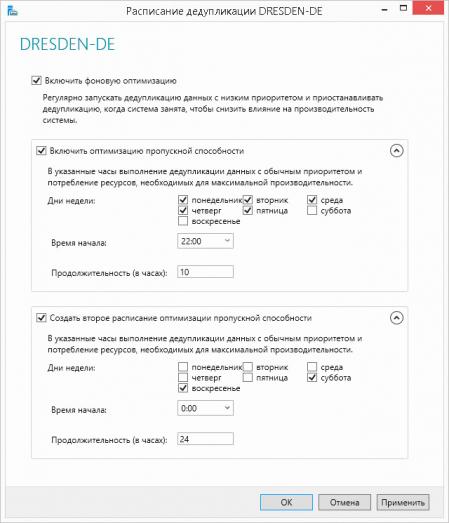
Также имеет смысл более детально настроить расписание, чтобы служба дедупликации могла использовать ресурсы системы полностью в нерабочее время или периоды с малой нагрузкой.
![win2k12r2-deduplication-006.jpg]()
В нашем случае мы настроили два расписания, одно позволяет выделять максимум ресурсов каждую ночь, с 22:00 до 8:00, второе полностью снимает ограничения на выходные.
В принципе на этом можно закончить, система сама выполнит все необходимые действия и через некоторое время у вас появится возможность оценить эффективность данной технологии применительно к вашей системе хранения. Также можно инициировать процесс дедупликации вручную. При этом стоит учитывать, что дедупликация будет выполняться с обычным приоритетом и правильно оценить необходимое для этого время. Средняя скорость дедупликации - 20 МБ/с или 72 ГБ в час, поэтому на больших объемах данных данный процесс может занять весьма продолжительное время.
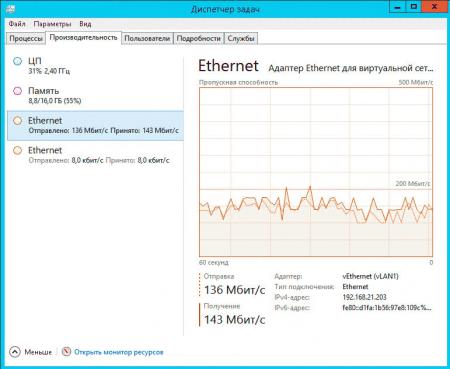
Если вы используете дедупликацию для томов во внешнем хранилище, то также следует принять во внимание загрузку сети. Ниже показана сетевая активность при дедупликации iSCSI диска:
![win2k12r2-deduplication-007.jpg]()
Если принять среднюю скорость за 150 Мбит/с, то получим скорость дедупликации 18,75 МБ/с, что соответствует заявленным Microsoft значениям.
Для запуска процесса дедупликации откройте консоль PowerShell и выполните команду (указав букву необходимого тома, в нашем случае это D:):
Контролировать ход выполнения задания можно командой:
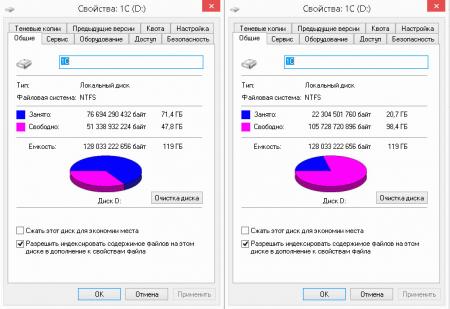
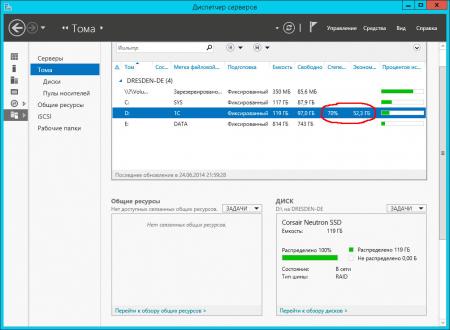
Взвесив все за и против, мы пришли к решению, что дедупликация существенно не повлияет на производительность, но в тоже время поможет более оптимально использовать дорогостоящую емкость SSD диска. И мы не ошиблись, результат говорит сам за себя:
![win2k12r2-deduplication-009.jpg]()
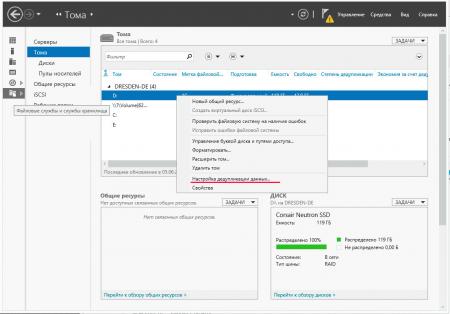
Также эффективность дедупликации можно оценить открыв оснастку Тома в Диспетчере серверов.
![win2k12r2-deduplication-010.jpg]()
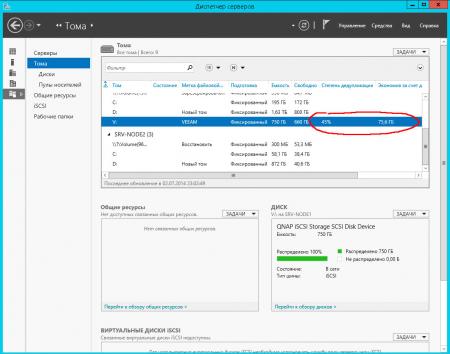
Степень дедупликации сильно зависит от характера данных, ниже показаны результаты для хранилища резервных копий виртуальных машин Hyper-V:
![win2k12r2-deduplication-011.jpg]()
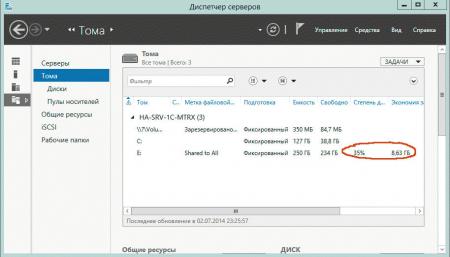
И файлового сервера общего назначения:
![win2k12r2-deduplication-012.jpg]()
В любом случае результат можно назвать неплохим, так как даже 30-40% экономия в масштабах предприятия позволяет предотвратить вполне ощутимые затраты по наращиванию емкости системы хранения. Также дедупликацию можно рассматривать как серьезный аргумент к переходу на новое семейство серверных операционных систем от Microsoft.
Читайте также: