Настройка сетевого стека linux для высоконагруженных систем
Обновлено: 06.07.2024
Вот опции, что необходимо добавить в конец /etc/sysctl.conf
А теперь о каждой опции более детально.
Целочисленное значение параметра tcp_max_orphans определяет максимальное число допустимых в системе сокетов TCP, не связанных каким-либо идентификатором пользовательского файла (user file handle). При достижении порогового значения “осиротевшие” (orphan) соединения незамедлительно сбрасываются с выдачей предупреждения. Этот порог помогает предотвращать только простые атаки DoS. Не следует уменьшать пороговое значение (скорее увеличить его в соответствии с требованиями системы – например, после добавления памяти. Каждое orphan-соединение поглощает около 64 Кбайт несбрасываемой на диск (unswappable) памяти.
Параметр tcp_fin_timeout определяет время сохранения сокета в состоянии FIN-WAIT-2 после его закрытия локальной стороной. Партнер может не закрыть это соединение никогда, поэтому следует закрыть его по своей инициативе по истечении тайм-аута. По умолчанию тайм-аут составляет 60 секунд. В ядрах серии 2.2 обычно использовалось значение 180 секунд и вы можете сохранить это значение, но не следует забывать, что на загруженных WEB-серверах вы рискуете израсходовать много памяти на сохранение полуразорванных мертвых соединений. Сокеты в состоянии FIN-WAIT-2 менее опасны, нежели FIN-WAIT-1 , поскольку поглощают не более 1,5 Кбайт памяти, но они могут существовать дольше.
tcp_keepalive_time Переменная определяет как часто следует проверять соединение, если оно давно не используется. Значение переменной имеет смысл только для тех сокетов, которые были созданы с флагом SO_KEEPALIVE . Целочисленная переменная tcp_keepalive_intvl определяет интервал передачи проб. Произведение tcp_keepalive_probes * tcp_keepalive_intvl определяет время, по истечении которого соединение будет разорвано при отсутствии откликов. По умолчанию установлен интервал 75 секунд, т.е., время разрыва соединения при отсутствии откликов составит приблизительно 11 минут.
Целочисленное значение в файле tcp_max_syn_backlog определяет максимальное число запоминаемых запросов на соединение, для которых не было получено подтверждения от подключающегося клиента. Если на сервере возникают перегрузки, можно попытаться увеличить это значение.
Целочисленное значение (1 байт) tcp_synack_retries определяет число попыток повтора передачи пакетов SYNACK для пассивных соединений TCP. Число попыток не должно превышать 255. Значение 5 соответствует приблизительно 180 секундам на выполнение попыток организации соединения.
Векторная (минимум, режим нагрузки, максимум) переменная в файле tcp_mem cодержит общие настройки потребления памяти для протокола TCP. Эта переменная измеряется в страницах (обычно 4Кб), а не байтах.
Минимум: пока общий размер памяти для структур протокола TCP менее этого количества страниц, операционная система ничего не делает.
Режим нагрузки: как только количество страниц памяти, выделенное для работы протокола TCP, достигает этого значения, активируется режим работы под нагрузкой, при котором операционная система старается ограничивать выделение памяти. Этот режим сохраняется до тех пор, пока потребление памяти опять не достигнет минимального уровня.
Максимум: максимальное количество страниц памяти, разрешенное для всех TCP сокетов.
Векторная (минимум, по умолчанию, максимум) переменная в файле tcp_rmem содержит 3 целых числа, определяющих размер приемного буфера сокетов TCP.
Минимум: каждый сокет TCP имеет право использовать эту память по факту своего создания. Возможность использования такого буфера гарантируется даже при достижении порога ограничения (moderate memory pressure). Размер минимального буфера по умолчанию составляет 8 Кбайт (8192).
Значение по умолчанию: количество памяти, допустимое для буфера передачи сокета TCP по умолчанию. Это значение применяется взамен параметра /proc/sys/net/core/rmem_default , используемого другими протоколами. Значение используемого по умолчанию буфера обычно (по умолчанию) составляет 87830 байт. Это определяет размер окна 65535 с заданным по умолчанию значением tcp_adv_win_scale и tcp_app_win = 0 , несколько меньший, нежели определяет принятое по умолчанию значение tcp_app_win .
Векторная переменная в файле tcp_wmem содержит 3 целочисленных значения, определяющих минимальное, принятое по умолчанию и максимальное количество памяти, резервируемой для буферов передачи сокета TCP.
Минимум: каждый сокет TCP имеет право использовать эту память по факту своего создания. Размер минимального буфера по умолчанию составляет 4 Кбайт (4096)
Значение по умолчанию: количество памяти, допустимое для буфера передачи сокета TCP по умолчанию. Это значение применяется взамен параметра /proc/sys/net/core/wmem_default , используемого другими протоколами и обычно меньше, чем /proc/sys/net/core/wmem_default . Размер принятого по умолчанию буфера обычно (по умолчанию) составляет 16 Кбайт (16384)
Целочисленной значение tcp_orphan_retries определяет число неудачных попыток, после которого уничтожается соединение TCP, закрытое на локальной стороне. По умолчанию используется значение 7, соответствующее приблизительно периоду от 50 секунд до 16минут в зависимости от RTO . На сильно загруженных WEB-серверах имеет смысл уменьшить значение этого параметра, поскольку закрытые соединения могут поглощать достаточно много ресурсов.
Согласно рекомендациям разработчиков ядра, этот режим лучше отключить.
Максимальное количество соединений для работы механизма connection tracking (используется, например, iptables). При слишком маленьких значениях ядро начинает отвергать входящие подключения с соответствующей записью в системном логе.
Разрешает временные метки протокола TCP. Их наличие позволяет управлять работой протокола в условиях серьезных нагрузок (см. tcp_congestion_control ).
Разрешить выборочные подтверждения протокола TCP. Опция необходима для эффективного использования всей доступной пропускной способности некоторых сетей.
Протокол, используемый для управления нагрузкой в сетях TCP. bic и cubic реализации, используемые по умолчанию, содержат баги в большинстве версий ядра RedHat и ее клонов. Рекомендуется использовать htcp .
Не сохранять результаты измерений TCP соединения в кеше при его закрытии. В некоторых случаях помогает повысить производительность.
Актуально для ядер 2.4. По странной причине в ядрах 2.4, если в рамках TCP сессии произошел повтор передачи с уменьшенным размером окна, все соединения с данным хостом в следующие 10 минут будут иметь именно этот уменьшенный размер окна. Данная настройка позволяет этого избежать.
Активируем защиту от IP-спуфинга.
Увеличиваем диапазон локальных портов, доступных для установки исходящих подключений
Разрешаем повторное использование TIME-WAIT сокетов в случаях, если протокол считает это безопасным.
Разрешаем динамическое изменение размера окна TCP стека
Запрещаем переадресацию пакетов, поскольку мы не роутер.
Не отвечаем на ICMP ECHO запросы, переданные широковещательными пакетами
Можно вообще не отвечать на ICMP ECHO запросы (сервер не будет пинговаться)
Максимальное число открытых сокетов, ждущих соединения. Имеет смысл увеличить значение по умолчанию.
Параметр определяет максимальное количество пакетов в очереди на обработку, если интерфейс получает пакеты быстрее, чем ядро может их обработать.
Сетевой стек Linux по умолчанию замечательно работает на десктопах, но на серверах с нагрузкой чуть выше средней и настройками по умолчанию - уже не очень, в основном из-за неравномерного распределения нагрузки на процессор.
Как работает сетевой стек
Коротко
- Материнские платы могут поддерживать одновременную работу нескольких процессоров, у которых может быть несколько ядер, у которых может быть несколько потоков.
- Оперативная память, NUMA. При использовании нескольких процессоров, как правило, у каждого процессора есть “своя” и “чужая” память. Обе они доступны, но доступ в чужую - медленнее. Бывают архитектуры, в которых память не делится между процессорами на свою и чужую. Сочетание ядер процессора и памяти называется NUMA-нодой. Иногда сетевые карты тоже принадлежат к NUMA-ноде.
- Сетевые карты можно поделить по поддержке RSS (аппаратное масштабирование захвата пакетов). Серверные поддерживают, бюджетные и десктопные нет. Зачастую, несмотря на диапазон, указанный в smp_affinity_list у обработчика прерываний, прерывания обрабатываются только одним ядром (как правило CPU0). Все сетевые карты работают следующим образом:
- IRQ (top-half): сетевая карта пишет пакеты в свою внутреннюю память. В оперативной памяти той же NUMA-ноды, к которой привязана сетевая карта, под неё выделен кольцевой буфер. По прерыванию процессора сетевая карта копирует свою память в кольцевой буфер и делает пометку, что у неё есть пакеты, которые надо обработать. Кольцевых буферов может быть несколько и они могут обрабатываться параллельно.
- Softirq (bottom half): сетевой стек периодически проверяет пометки от сетевых карт о необходимости обработать пакеты. Пакеты из кольцевых буферов обрабатываются, проходят, файрволы, наты, сессии, доходят до приложения при необходимости. На этом уровне есть программный аналог аппаратных очередей, который уместен в случае с сетевыми картами с одной очередью.
- Cache locality. Если пакет обрабатывался на определённом CPU и попал в приложение, которое работает там же - это лучший случай, кэши работают максимально эффективно.
Подробнее - путь пакета из кабеля в приложение:
Сразу оговорю неточности: не прописано прохождение L2, который ethernet. С L1 как-то сразу в L3 прыгнул.
Выводы
Перед главной задачей, выполняется первостепенная задача - подбор аппаратной части, само собой с учётом того, какие задачи лежат на сервере, откуда и сколько приходит и уходит трафика и т.д.
Есть два способа распределить нагрузку по обработке пакетов между ядрами процессора:
- RSS - назначить smp_affinity для каждой очереди сетевой карты.
- RPS (можно считать его программным аналогом RSS) - назначить rps_cpus для каждой очереди сетевой карты.
- Комбинирование RSS и RPS. Дополнительный буфер с одной стороны - снижает вероятность потери пакета при пиковой нагрузке, с другой стороны - увеличивает общее времени обработки и может за счёт этого увеличивать вероятность потерь. Для сетевых карт с несколькими очередями и равномерным распределением пакетов перенос пакета с ядра на ядро будет использовать драгоценный budget и снизит эффективность использования кэша процессора.
Как подбирать аппаратное обеспечение
- Процессоры
- Число процессоров:
- Однопроцессорный сервер эффективен, если трафик приходит только на одну сетевую карту, в том числе в её порты, если их несколько.
- Двухпроцессорный сервер эффективен, если есть больше двух источников трафика, с потоком более 2 Гбит/сек и они обрабатываются отдельными сетевыми картами (не портами).
- Не нужно больше ядер, чем максимальное суммарное количество очередей всех сетевых карт.
- Hyper-Threading: не помогает, если обработка пакетов - основной вид нагрузки на процессор. Оценивайте процессор по числу ядер, а не потоков.
- Размер RX-буферов: чем он больше, тем лучше.
- Максимальное число очередей: чем их больше, тем лучше. Некоторые (mellanox) сетевые карты поддерживают только число очередей равное степени двойки. Если у Вас 6-ядерный процессор - имеет смысл подобрать другую сетевую карту.
- Бракованные сетевые карты - вероятность мала, но иногда случается. Заменяем одну сетевую карту на точно такую же и всё замечательно.
- Драйвер: не рекомендую использовать десктопные карты (обычно D-Link, Realtek).
Мониторинг и тюнинг сетевого стека
Мониторинг можно условно поделить на
- краткосрочный - посмотреть как чувствует себя система прямо сейчас;
- долгосрочный - с алертами, вот это всё.
Заниматься тюнингом без краткосрочного мониторинга равноценно случайным действиям. Я разработал инструменты для такого мониторинга - netutils-linux, они протестированы и работают на версиях python 2.6, 2.7, 3.4, 3.6, 3.7 и, возможно на более новых. Изначально делал для технической поддержки, объяснять каждому такой объёмный материал - долго, сложно. Есть фраза “код - лучшая документация”, а моей целью было “инструменты вместо документации”.
При возникновении проблем - сообщайте о них на github, а лучше присылайте pull-request’ы.
Мониторинг
network-top
Эта утилита отображает полную картину процесса обработки пакетов. Вы увидите равномерность распределения нагрузки (прерывания, softirqs, число пакетов в секунду на ядро процессора и на сетевой интерфейс) на ресурсы сервера, ошибки обработки пакетов. Аномальные значения счётчиков подсвечиваются красным.
Вверху отображаются источники прерываний, чтобы всё влезало на экран редкие прерывания скрыты. Имена ядер подсвечиваются в зависимости от принадлежности к NUMA-ноде или к процессору.
Посередине находится самое важное - распределение обработки пакетов по CPU:
- Interrupts. Суммарное число прерываний на ядро. Лучше держаться не более 10000 прерываний на 1GHz частоты ядра. В случае с hyperthreading - 5000. Настраивается утилитой rss-ladder .
- NET_RX. Число softirq на приём пакетов. Настраивается утилитой autorps .
- NET_TX. Число softirq на отправку пакетов. Настраивается утилитой autoxps .
- Total. Число обработанных данным ядром пакетов.
- Dropped. Число отброшенных в процессе обработки пакетов. Отбрасывание приводит медленной работе сети, хосты повторно отправляют пакеты, у них задержки, потери, люди жалуются в техподдержку.
- Time squuezed. Число пакетов, которым не хватило времени для обработки и их обработку отложили на следующий виток цикла. Повод задуматься о дополнительном тюнинге.
- CPU Collision. times that two cpus collided trying to get the device queue lock. Ни разу не видел на своей практике.
Внизу находится статистика по сетевым девайсам.
- rx-errors - общее число ошибок, обычно суммирует остальные. В какой именно счётчик попадает пакет зависит от драйвера сетевой карты.
- dropped , fifo , overrun - пакеты, не успевшие обработаться сетевым стеком
- missed - пакеты, не успевшие попасть в сетевой стек
- crc - прилетают битые пакеты. Часто бывает следствием высокой нагрузки на коммутатор.
- length - слишком большие пакеты, которые не влезают в MTU на сетевой карте. Лечится его увеличением: ip link set eth1 mtu 1540 . Постоянное решение для RHEL-based систем - прописать строчку MTU=1540 в файле конфигурации сетевой карты, например /etc/sysconfig/network-scripts/ifcfg-eth1 .
Флаги утилиты
- Задать список интересующих девайсов: --devices=eth1,eth2,eth3
- Отсеять девайсы регуляркой: --device-regex='^eth'
- Сделать вывод менее подробным, спрятав все специфичные ошибки: --simple
- Убрать данные об отправке пакетов: --rx-only .
- Представление данных об объёме трафика можно менять ключами: --bits , --bytes , --kbits , --mbits .
- Показывать абсолютные значения: --no-delta-mode
Альтернативные способы получения этой информации:
Потери могут быть не только на Linux-сервере, но и на порту связанного с ним сетевого оборудования. О том, как это посмотреть можно узнать из документации производителя сетевого оборудования.
Стандартный top
server-info
Если приходится иметь дело с разношёрстными серверами, которые закупались разными людьми, полезно знать какое оборудование у них внутри и насколько оно подходит под текущие нагрузки. Утилита server-info именно для этого и предназначена. У неё два режима:
- --show - показать оборудование;
- --rate - оценить оборудование.
Вывод в YAML. Примеры:
и оценивать это железо по шкале от 1 до 10:
Вместо --server можно указать --subsystem , --device или вообще ничего, тогда оценка будет вестись по каждому параметру устройства в отдельности.
Тюнинг
maximize-cpu-freq
Плавающая частота процессора плохо сказывается для нагруженных сетевых серверов. Если процессор может работать на 3.5GHz - не надо экономить немного ватт ценой потерь пакетов. Утилита включает для cpu_freq_governour режим performance и устанавливает минимальную частоту всех ядер в значение максимально-доступной базовой. Узнать текущие значения можно командой:
Помимо плавающей частоты есть ещё одно но, которое может приводить к потерям: режим энергосбережения в UEFI/BIOS. Лучше его выключить, выбрав режим “производительность” (для этого потребуется перезагрузить сервер).
rss-ladder
Утилита автоматически распределяет прерывания “лесенкой” на ядрах локального процессора для сетевых карт с поддержкой нескольких очередей.
Если сетевых карт несколько, лучше выделить для каждой очереди каждой сетевой карты одно физическое ядро, ответственное только за неё. Если ядер не хватает - число очередей можно уменьшить с помощью ethtool, например: ethtool -L eth0 combined 2 или ethtool -L eth0 rx 2 в зависимости от типа очередей.
Для RSS по возможности используйте разные реальные ядра, допустим, дано:
- 1 процессор с гипертредингом
- 4 реальных ядра
- 8 виртуальных ядер
- 4 очереди сетевой карты, которые составляют 95% работы сервера
В зависимости от того как расположены ядра и потоки (узнать можно по выводу lscpu -e ), использовать 0, 2, 4 и 6 ядра будет эффективнее, чем 0, 1, 2 и 3.
rx-buffers-increase
Увеличивает RX-буфер сетевой карты. Чем больше буфер - тем больше пакетов за один тик сетевая карта сможет скопировать с помощью DMA в кольцевой буфер в RAM который уже будет обрабатываться процессором.
Для работы после перезагрузки в RHEL-based дистрибутивах (платформа Carbon, CentOS, Fedora итд) укажите в настройках интерфейса, например /etc/sysconfig/network-scripts/ifcfg-eth1 , строчку вида:
autorps
Утилита для распределения нагрузки на сетевых картах с одной очередью. Вычисляет и применяет маску процессоров для RPS, например:
Настройка драйверов сетевых карт для работы в FORWARD/Bridge-режимах
Опции General Receive Offload и Large Receive Offload в таких режимах могут приводить к паникам ядра Linux и их лучше отключать либо при компиляции драйвера, либо на ходу, если это поддерживается драйвером:
Примеры
1. Максимально простой
Параметр Значение Число процессоров 1 Ядер 4 Число карт 1 Число очередей 4 Тип очередей combined Режим сетевой карты 1 Гбит/сек Объём входящего трафика 600 Мбит/сек Объём входящего трафика 350000 пакетов/сек Максимум прерываний на ядро в секунду 55000 Объём исходящего трафика 0 Мбит/сек Потери 200 пакетов/сек Детали Все очереди висят на CPU0, остальные ядра простаивают Решение: распределяем очереди между ядрами и увеличиваем буфер:
Параметр Значение Максимум прерываний на ядро в секунду 15000 Потери 0 Детали Нагрузка равномерна Пример 2. Чуть сложнее
Параметр Значение Число процессоров 2 Ядер у процессора 8 Число карт 2 Число портов у карт 2 Число очередей 16 Тип очередей combined Режим сетевых карт 10 Гбит/сек Объём входящего трафика 3 Гбит/сек Объём исходящего трафика 100 Мбит/сек Детали Все 4 порта привязаны к одному процессору Одну из 10 Гбит/сек сетевых карт перемещаем в другой PCI-слот, привязанный к NUMA node1.
Уменьшаем число combined очередей на каждый порт до числа ядер одного физического процессора (временно, нужно делать это при перезагрузке) и распределить прерывания портов. Ядра будут выбраны автоматически, в зависимости от того к какой NUMA-ноде принадлежит сетевая карта. Увеличиваем сетевым картам RX-буферы:
Необычные примеры
Не всегда всё идёт идеально:
Проблема Решение Сетевая карта теряет пакеты при использовании RSS. 1 RX-очередь для захвата на CPU0, а обработка на остальных ядрах: autorps --cpus 1,2,3,4,5 eth0 У сетевой карты несколько очередей, но 99% пакетов обрабатывается одной очередью Причина в том, что у 99% трафика одинаковый хэш, такое бывает при использовании QinQ, Vlan, PPPoE и во время DDoS атак. Решений несколько: от DDoS защититься ранним DROP трафика, перенести агрегацию VLAN на другое оборудование, сменить сетевую карту, которая учитывает Vlan при вычислении хэша для RSS, попробовать использовать RPS Сетевые карты intel X710 начала работать без прерываний, вся нагрузка висела на CPU0. Нормальная работа восстановилась после включения и выключения RPS. Почему началось и закончилось - неизвестно. Некоторые SFP-модули для Intel 82599ES при обновлении драйвера (сборка ixgbe из исходников с sourceforge) “пропадают” из списка сетевых карт и даже флаг unsupported_sfp=1 не помогает. При этом в lspci этот порт отображается, второй аналогичный порт работает, а в dmesg на оба порта одинаковые warning’и. Не нашлось. Некоторые драйверы сетевых карт работают с числом очередей только равным степени двойки Замена сетевой карты или процессора. Блог Олега Стрижеченко
30% личного, 20% linux, 30% наблюдения за разработкой, 5% книги, 10% математика и статистика, 10% шуток
![]()
Приглашаем всех желающих посетить открытый демо-урок Практикум по написанию Ansible роли. На этом вебинаре участники вместе с экспертом будут писать, тестировать и отлаживать ansible роли. Это важно для тех, кто хочет автоматизировать настройку инфраструктуры, поскольку это один из инструментов, который это позволяет сделать. Сетевой стек одна из самых запутанных вещей в Linux. И не только из-за сложности некоторых концепций и терминов, но и из-за изменения смысла некоторых параметров в разных версиях ядра. В этой статье приведена информация для ядра 2.2 и выше, а также, там где это возможно, указано различие между версиями вплоть до 5.5.
Очередь приема и netdev_max_backlog
Очередь ожидающих запросов на соединение и tcp_max_syn_backlog
Соединения создаются для SYN-пакетов из очереди приема и перемещаются в очередь ожидания (SYN Backlog Queue). Также соединение помечается как "SYN_RECV" и клиенту отправляется "SYN+ACK". Эти соединения не перемещаются в очередь установленных соединений ожидающих обработки accept() (accept queue) до тех пор, пока не будет получен и обработан соответствующий ACK. Максимальное количество соединений в этой очереди устанавливается параметром net.ipv4.tcp_max_syn_backlog .
Для просмотра очереди приема используйте команду netstat . На правильно настроенном сервере при нормальной нагрузке значение не должно быть больше 1. При большой нагрузке значение должно быть меньше размера очереди ожидания (SYN Backlog):
Если в состоянии "SYN_RECV" находятся много соединений, то можно также подстроить продолжительность нахождения SYN-пакета в этой очереди.
SYN Cookie
Повторы SYN+ACK
Что происходит, если SYN+ACK отправлен, но ответа ACK нет? В этом случае сетевой стек сервера повторит отправку SYN+ACK. Задержка между попытками вычисляется таким образом, чтобы обеспечить восстановление сервера. Если сервер получает SYN и отправляет SYN+ACK, но не получает ACK, то тайм-аут повторной передачи вычисляется по экспоненте (Exponental Backoff) и, следовательно, зависит от количества повторных попыток. Количество повторных попыток отправки SYN+ACK задается параметром ядра net.ipv4.tcp_synack_retries (по умолчанию равно 5). Повторные попытки будут через следующие интервалы: 1с, 3с, 7с, 15с, 31с. При шести попытках последняя будет примерно через 63 секунды после первой. Это позволяет удержать SYN-пакет в очереди ожидания более 60 секунд до истечения времени ожидания пакета. Если очередь SYN backlog мала, то не требуется большого количества соединений, чтобы возникла ситуация, когда полуоткрытые соединения никогда не завершатся и тогда никакие соединения не смогут быть установлены. Установите количество повторных попыток SYN+ACK равным 0 или 1, чтобы избежать такого поведения на высоконагруженных серверах.
Повторы SYN
Несмотря на то что повторные SYN-пакеты отправляются клиентом во время ожидания SYN+ACK, они могут влиять и на высоконагруженные серверы, работающие с прокси-соединениями. Например, сервер nginx, устанавливающий несколько десятков прокси-соединений к бэкенд-серверу, из-за всплесков трафика может на некоторое время перегрузить сетевой стек, а повторные попытки создадут дополнительную нагрузку на бэкэнд как в очереди приема, так и в очереди ожидания (SYN backlog). Это, в свою очередь, может повлиять на клиентские соединения. Повторные попытки SYN контролируются параметром net.ipv4.tcp_syn_retries (по умолчанию 5 или 6 в зависимости от дистрибутива). Ограничьте количество повторных попыток SYN до 0 или 1, чтобы не было долгих повторных попыток отправки в течение 63–130 с.
Более подробно о проблемах с клиентскими соединениями при обратном прокси-сервере читайте в статье Linux Kernel Tuning for High Performance Networking: Ephemeral Ports.
Очередь установленных соединений ожидающих принятия (accept queue) и somaxconn
Очередь запросов на соединение создает приложение, используя listen() и указывая размер очереди в параметре "backlog". Начиная с ядра 2.2 поведение этого параметра изменилось с максимального количества неоконченных запросов на соединение, которое может удерживать сокет, на максимальное количество полностью установленных соединений, ожидающих, пока они будут приняты. Как описано выше, максимальное количество неоконченных запросов на соединение теперь задается с помощью параметра ядра net.ipv4.tcp_max_syn_backlog .
somaxconn и параметр backlog в listen()
Хотя за размер очереди для каждого слушателя отвечает приложение, есть ограничение на количество соединений, которые могут находиться в очереди. Размером очереди управляют два параметра: 1) параметр backlog в функции listen() и 2) параметр ядра net.core.somaxconn , задающий максимальный размер очереди.
Значения по умолчанию для очереди
Значение по умолчанию для net.core.somaxconn берется из константы SOMAXCONN, которая в ядрах Linux вплоть до версии 5.3 имеет значение 128, но в 5.4 она была увеличена до 4096. Однако, на момент написания этой статьи, ядро 5.4 еще не очень распространено, поэтому в большинстве систем значение будет 128, если вы не модифицировали net.core.somaxconn.
Часто приложения для размера очереди по умолчанию используют константу SOMAXCONN, если этот размер не задается в конфигурации приложения. Хотя некоторые приложения устанавливают и свои значения по умолчанию. Например, в nginx размер очереди равен 511, который автоматически усекается до 128 в ядрах Linux до версии 5.3.
Изменение размера очереди
Многие приложения позволяют указывать размер очереди в конфигурации, указывая значение параметра backlog для listen() . Если приложение вызывает listen() со значением backlog , превышающим net.core.somaxconn, то размер очереди будет автоматически усечен до значения SOMAXCONN.
Потоки
Соединения и файловые дескрипторы
Системные ограничения
Любое сокетное соединение использует файловый дескриптор. Максимальное количество дескрипторов, которые могут быть созданы в системе, задается параметром ядра fs.file-max. Посмотреть количество используемых дескрипторов можно следующим образом:
Пользовательские ограничения
Помимо системного ограничения количества файловых дескрипторов, у каждого пользователя есть свои лимиты. Они настраиваются в системном файле limits.conf (nofile) или, при запуске процесса под управлением systemd, в unit-файле systemd (LimitNOFILE). Чтобы увидеть значение по умолчанию запустите:
Для systemd (на примере nginx):
Настройка
Для настройки системных ограничений установите параметр ядра fs.max-file в максимальное количество файловых дескрипторов, которое может быть в системе (с учетом некоторого буфера). Например:
Для настройки пользовательского лимита установите достаточно большое значение, чтобы хватило сокетам и файловым дескрипторам рабочих процессов (также с некоторым буфером). Пользовательские ограничения устанавливаются в /etc/security/limits.conf, в conf-файле в /etc/security/limits.d/ или в unit-файле systemd. Например:
Системные ограничения
Процессы могут создавать рабочие потоки. Максимальное количество потоков, которые могут быть созданы, задается параметром ядра kernel.threads-max . Для просмотра максимального и текущего количества потоков, выполняющихся в системе, запустите следующее:
Пользовательские ограничения
Есть свои ограничения и у каждого пользовательского процесса. Это также настраивается с помощью файла limits.conf (nproc) или unit-файла systemd (LimitNPROC). Для просмотра максимального количества потоков, которое может создать пользователь запустите:
Для systemd (на примере nginx):
Настройка
Как и в случае с nofile , ограничения для пользователей ( nproc ) устанавливаются в /etc/security/limits.conf, в conf-файле в /etc/security/limits.d/ или в unit-файле systemd. Пример с nproc и nofile :
Обратный прокси и TIME_WAIT
Управляет этим тайм-аутом параметр net.ipv4.tcp_fin_timeout . Рекомендуемое значение для высоконагруженных систем составляет от 5 до 7 секунд.
Собираем все вместе
Очередь приема (receive queue) должна быть рассчитана на обработку всех пакетов, полученных через сетевой интерфейс, не вызывая отбрасывания пакетов. Также необходимо учесть небольшой буфер на случай, если всплески будут немного выше, чем ожидалось. Для определения правильного значения следует отслеживать файл softnet_stat на предмет отброшенных пакетов. Эмпирическое правило использовать значение tcp_max_syn_backlog, чтобы разрешить как минимум столько же SYN-пакетов, сколько может быть обработано для создания полуоткрытых соединений. Помните, что этот параметр задает количество пакетов, которое каждый процессор может иметь в своем буфере, поэтому разделите значение на количество процессоров.
Размер SYN очереди ожидания (SYN backlog queue) на высоконагруженном сервере должен быть рассчитан на большое количество полуоткрытых соединений для обработки редких всплесков трафика. Здесь эмпирическое правило заключается в том, чтобы установить это значение, по крайней мере, на максимальное количество установленных соединений, которое слушатель может иметь в очереди приема, но не выше, чем удвоенное количество установленных соединений. Также рекомендуется отключить SYN cookie, чтобы избежать потери данных при больших всплесках соединений от легитимных клиентов.
Очередь установленных соединений, ожидающих принятия (accept queue) должна быть рассчитана таким образом, чтобы в периоды сильного всплеска трафика ее можно было использовать в качестве временного буфера для установленных соединений. Эмпирическое правило устанавливать это значение в пределах 25% от числа рабочих потоков.
Параметры
В этой статье были рассмотрены следующие параметры ядра:
И следующие пользовательские ограничения:
Заключение
Все параметры в этой статье приведены в качестве примеров и не должны вслепую применяться на ваших продакшн-серверах без тестирования. Есть и другие параметры ядра, которые влияют на производительность сетевого стека. Но в целом, это наиболее важные параметры, которые я использовал при настройке ядра для высоконагруженных систем.
![Тюнинг сетевого стека при помощи sysctl]()
Тема настройки ядра Linux «на лету», актуальная для многих системных администраторов, уже была освещена нами в статье «Что такое sysctl». В прошлой статье был описан сам принцип настройки ядра с помощью утилиты sysctl, приведены базовые команды и даны примеры некоторых наиболее распространенных параметров ядра Linux.
В этом материале хочется остановиться на конфигурации параметров сетевого стека на базе ОС Linux. Данная статья будет полезна системным администраторам при настройке высоконагруженных серверных ОС для «тяжелых» веб-проектов, а также поможет специалистам в сфере кибербезопасности построить оптимальную защиту от DDoS атак.
Все настройки сетевого стека необходимо внести в конфигурационный файл /etc/sysctl.conf. Также можно изменить опции любого сетевого параметра ядра «на лету» с помощью команды:
Например, ниже на скриншоте показано, как изменить параметр rp_filter:
![Параметр rp_filter]()
Команда sysctl -p — выводит на экран текущие настройки сетевого параметра из файла /etc/sysctl.conf
Чтобы посмотреть значение одного сетевого параметра, который вас интересует в конкретный момент, нужно выполнить следующую команду, например для ip_forward:
![Вывод конкретного параметра sysctl]()
Еще один способ для просмотра параметров ядра Linux — это использование директории /proc/sys и команды cat, о чем вы можете более подробно прочитать в статье на нашем сайте FREEhost.UA.
Для изменения параметров таким способом используется команда ниже (например, вместо 1 указываем нужное значение параметра, на которое мы хотим изменить опцию rp_filter):
Однако, не все параметры могут быть изменены таким образом, некоторые из них задаются сразу только при загрузке ядра и на лету не меняются.
Например, ниже показано, как вывести на экран (командой cat) конкретные сетевые параметры настроек ядра Ubuntu:
![Работа с директорией /proc/sys и командой cat]()
В следующем разделе статьи мы приведем основные параметры сетевого стека ядра Linux, расскажем для каких целей они нужны и какие значения необходимо выставить для оптимальной работы TCP/IP и для обеспечения безопасной работы сервера.
Настройка сетевых параметров ядра Linux
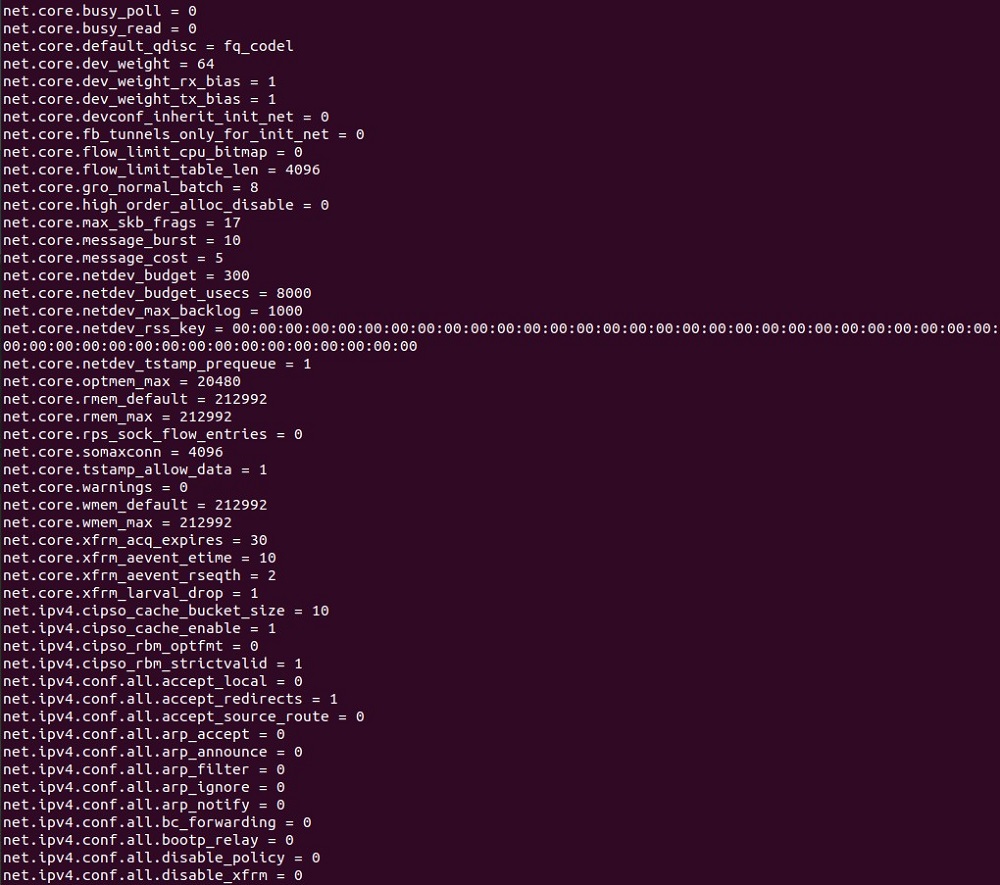
Для начала выведем текущие настройки параметров ядра «по умолчанию» (раздел net). В результате, получим листинг на несколько листов, ниже на скриншоте показана только часть этого списка параметров:
![Параметры ядра Linux группы net]()
Для тюнинга сетевого стека нам нужны не все эти сетевые параметры, а только наиболее важные.
1. Приступим к настройкам, и начнем с группы параметров, которые отвечают за работу протокола 3-го уровня модели OSI — ICMP (Internet Control Message Protocol), которые обычно применяются для «пингования» хоста, т.е. для выполнения команд ping и traceroute. В нашем случае, хакеры могут использовать ICMP-пакеты перенаправления, чтобы изменить таблицы маршрутизации. Поэтому, если вы не занимаетесь настройкой маршрутизатора, то для хоста необходимо выставить значение «0» для следующих параметров ядра Linux:
2. Следующим этапом настройки, идет выставление значения параметра tcp_max_orphans, в дословном переводе — это «осиротевшие» (orphan) соединения. Когда параметр достигнет своего порогового значения, такие соединения просто сбрасываются, и система выдает предупреждение. Советуем увеличить пороговое значение этого параметра (каждое «осиротевшее» соединение требует 64 Кбайт unswappable памяти). Правильная настройка данной опции поможет в защите от наиболее простых типов DDoS-атак.
3. Затем необходимо установить правильное значение для параметра tcp_fin_timeout, который обозначает время, в течении которого сокет может быть сохранен в состоянии FIN-WAIT-2, когда локальная сторона осуществила уже его закрытие. Данное соединение может быть вообще не закрыто партнером, поэтому необходимо его закрыть принудительно (когда «тайм-аут» истек). Значение «по умолчанию» для данного параметра — 60 секунд. Можно оставить значения «по умолчанию», но в случае, если вы эксплуатируете какие-то «тяжелые» веб-приложения, будет расходоваться много памяти на поддержку «мертвых соединений». Поэтому следует настроить данный параметр таким образом:
4. Сейчас настроим еще 3 важных параметра:
tcp_keepalive_time — показывает, как часто нужно проверять соединение, в том случае, если оно давно не используется (только для сокетов с флагом SO_KEEPALIVE), «по умолчанию» это значение равно 7200 секунд;
tcp_keepalive_intvl — обозначает интервал передачи проб, значение «по умолчанию» выставлено 75 сек;
tcp_keepalive_probes * tcp_keepalive_intvl = время, после истечения которого, соединение должно быть разорвано (если нет откликов), примерное значение — 11 минут;
tcp_keepalive_probes — показывает значение для передач проб keepalive, после достижения которого, соединение будет разорвано, «по умолчанию» выставлено 9.
Ниже приводятся рекомендуемые значения для данных 3-х параметров*:
*Примечание: для параметра tcp_keepalive_time рекомендованные значения от 60 до 300.
5. Следующий важный параметр, который требует нашего внимания — это
tcp_max_syn_backlog, показывающий максимум полуоткрытых соединений, т.е. запоминаемых запросов на соединение, для которых подключающийся клиент не дал подтверждение. Советуем увеличить заданное «по умолчанию» значение, особенно в случае возникновения перезагрузок сервера.6. На этом шаге настроим параметр tcp_synack_retries, отвечающий за время удержания «полуоткрытых» соединений. Здесь задается количество попыток повтора передачи SYN-ACK пакетов для пассивных соединений TCP, которое не должно быть более 255. «По умолчанию» выставлено число 5 (соответствует 180 сек. времени, выделенного на эти попытки). Рекомендуется уменьшить это время до 9 сек, что будет соответствовать единице.
7. Параметр tcp_mem описан в виде векторной переменной, которая может принимать три значения, определяющие объем памяти, который может быть использован стеком TCP. Задается параметр в страницах памяти и зависит от архитектуры серверного оборудования, например, для i386 — это будет 4Кб (4096 байт). Три значения переменной (минимальное, значение в режиме нагрузки и максимальное) будут вычислены во время нагрузки. Если значение ниже минимального, то ОС вообще не выполняет никаких действий по управлению памятью, потребляемой сокетами TCP. Работа в режиме нагрузки: при достижении данного значения включается этот режим, и операционная система будет ограничивать выделение памяти. Причем, работа в таком режиме происходит до того момента времени, когда потребление памяти опять не снизится до минимума. И наконец, при достижении максимального значения этой переменной, TCP будет просто «терять» пакеты и соединения, пока объем используемой памяти не начнет снижаться. Для увеличения пропускной способности каналов рекомендуется оптимально настроить сразу 3 переменные tcp_mem, tcp_rmem и tcp_wmem. При настройке этих параметров советуем вам: для более мощных серверов выставлять большие параметры, а для серверов с более слабой конфигурацией — меньшие значения параметров. «По умолчанию» net.ipv4.tcp_mem настроен следующим образом*:
*Примечание: если ресурсы сервера позволяют выделить больше памяти под сеть.
В некоторых источниках рекомендуется выставить такие параметры*:
*Примечание: данные параметры рекомендованы для более слабых серверов.
8. Параметр tcp_wmem также, как и в предыдущем случае, является векторной переменной с 3-мя значениями в виде целых чисел (минимум, значение «по умолчанию», максимальное значение) и задает он размер для буфера передачи TCP сокета. При настройке данных параметров учитывайте конфигурацию и производительность ваших серверов, для более производительных серверов можно брать большие параметры. «По умолчанию», могут быть следующие параметры (можно оставить данные настройки):
Для более мощных серверов в некоторых источниках рекомендуется выставить следующие настройки:
9. Еще один подобный параметр в виде векторной переменной tcp_rmem задает размер приемного буфера сокетов TCP и также имеет 3 значения (минимальное значение, значение «по умолчанию», максимальное).
«По умолчанию», этот параметр может быть настроен таким образом:
Согласно рекомендациям из специализированных источников, можно настроить эту опцию так (для более производительных серверов):
10. Параметры rmem_default, wmem_default служат для описания значений «по умолчанию» для размера буферов приема и передачи данных соответственно, они не могут перекрывать значения переменных tcp_rmem и tcp_wmem (см. пункты выше).
Ниже рекомендованы оптимальные значения для этих параметров:
11. Параметры rmem_max, wmem_max служат для перекрытия максимальных значений переменных tcp_rmem и tcp_wmem (описания их см. выше), при увеличении нагрузки на сервер, рекомендованы следующие настройки:
12. Параметр tcp_orphan_retries задает величину, определяющую количество неудачных попыток, после достижения которой, происходит уничтожение соединения TCP, уже закрытого на локальной стороне. Закрытые соединения также расходуют ресурсы системы, поэтому советуем поставить 0, см. ниже:
15. Этот параметр (ip_conntrack_max) необходим для грамотной настройки механизма определения состояния соединений connection tracking (используется для iptables), в общем, эта опция важна для работы межсетевых экранов. Если выставить очень маленькие значения, то ядро будет отвергать входящие соединения, это можно будет увидеть затем системном логе.
16. Параметр tcp_timestamps предназначен для включения временных меток TCP (см. RFC 1323), для высокоскоростной сети и в условиях высоких нагрузок на сервера, советуем оставить ее включенной:
17. Опция tcp_sack необходима для разрешения выборочных подтверждений протокола TCP (Selective Acknowledgements — SACK, см. RFC 2883 и RFC 2883). Данная функция будет полезна на неустойчивых соединениях, где возможны обрывы связи. Включенный «по умолчанию» tcp_sack = 1, разрешает произвести передачу повторно лишь отдельных не подтвержденных фрагментов (а не всего окна TCP), работает совместно с опцией tcp_timestamps.
18. Параметр tcp_congestion_control позволяет осуществлять контроль за управлением нагрузкой в сетях TCP. Выбор настроек контроля за перегрузкой осуществляется при сборке ядра, доступны следующие режимы: reno (default), cubic:CUBIC-TCP, bic:BIC-TCP, htcp:Hamilton TCP, vegas:TCP Vegas, westwood (для сетей с потерями). Для работы сервера рекомендуется использовать htcp. Значение параметра «по умолчанию» — cubic (однако, есть ошибки в ядре Linux 2.6.18).
19. Эта настройка (tcp_no_metrics_save) не разрешает сохранение результатов изменений TCP соединения в кэше, в случае его закрытия. «По умолчанию», она в выключенном состоянии «0», но рекомендуем ее включить для увеличения производительности:
20. Параметр net.ipv4.route.flush актуален для ядра версии 2.4, если ваша ОС на этой версии ядра, то включите его:
21. Следующая группа параметров rp_filter предназначена для защиты от спуфинга (подмены адресов), отвечает за включение/выключение reverse path filter (т.е. проверку обратного адреса). Однако, если вы используете таблицы маршрутизации большой сложности, то перед настройкой этого параметра, рекомендуется изучить RFC 1812. В состоянии «по умолчанию» данные параметры выключены (значение «0»), рекомендуем включить в режим «1» (строгая проверка).
22. На этом этапе необходимо настроить запрет маршрутизации от источника (source routing), т.е. группу параметров accept_source_route; «по умолчанию», настройки находятся в состоянии «выключено» (ноль). Эта опция может предоставлять разрешение отправителю для определения пути пакета, который тот проходит по сети для достижения пункта назначения. Для сетевого инженера — это очень удобная опция, однако ей может воспользоваться и злоумышленник, поэтому рекомендуется ее оставить в выключенном состоянии.
23. Сейчас требуется настроить опцию ip_local_port_range, отвечающую за диапазон локальных портов, которые нам доступны для установки исходящих подключений. Параметр содержит 2 целых числа, где первое из них служит для задания нижней границы этого диапазона, а второе — устанавливает верхнюю границу. Значения выставляются в зависимости от объема ОЗУ сервера. Рекомендуемый диапазон для высоконагруженных проектов:
24. Параметр tcp_tw_reuse служит для разрешения повторного использования сокетов TIME-WAIT, когда это безопасно. Рекомендуется его включить:
25. Для разрешения или запрета масштабирования окна стека TCP необходима настройка параметра tcp_window_scaling (подробно см. RFC 1323). Фактически, разрешая динамическое изменение TCP-окна, можно увеличить размер канала, а также значительно снизить потери пропускной способности.
26. Для установления защиты от атак типа TIME_WAIT, стоит включить параметр tcp_rfc1337. Детально смысл этого параметра "TIME-WAIT Assassination Hazards in TCP" изложен в RFC 1337, а сама проблема заключена в том, что устаревшие дубликаты пакетов вносят помехи в новые соединения и тем самым порождают различные проблемы. Но, так как «по умолчанию» эта опция выключена (значение «0»), для сервера нам необходимо ее включить:
27. Чтобы запретить переадресацию пакетов для сервера, необходимо отключить параметр ip_forward. В случае включения ip_forward (значение «1»), операционная система будет вести себя «как маршрутизатор» и работать согласно RFC1812, т.е. перенаправлять пакеты в соответствии с таблицей маршрутизации.
28. Функция icmp_echo_ignore_broadcasts разрешает (или запрещает) отвечать на запросы ICMP ECHO, которые передаются широковещательными пакетами.
29. Полный запрет ответа на ICMP ECHO запросы (сервер не «пингуется») можно настроить таким образом:
31. Параметр somaxconn необходим для установления значения максимального количества открытых сокетов, которые ожидают соединения. Рекомендуемое значение параметра 15000 (используется для высоконагруженных систем), 65535 — максимальное значение данного параметра, используется в редких случаях:
32. Также необходимо настроить параметр netdev_max_backlog, который задает максимальное число пакетов, находящихся в очереди «на обработку», в случае, когда интерфейс получает пакеты гораздо быстрее, чем ядро их обрабатывает. Ниже приведено значение «по умолчанию» (рекомендуемое).
Пример готового файла с настройками
Для удобства мы свели все вышеописанные параметры в один список, который вам необходимо добавить в конец файла /etc/sysctl.conf и сохранить данный файл, затем перезагрузить ОС, чтобы настройки вступили в силу.
![Пример файла sysctl.conf с настройками]()
Заключение
В этой части статьи мы дали практические рекомендации для системных администраторов, как провести тюнинг сетевого стека при помощи sysctl. Мы привели только основные переменные типа net для ядра Linux, оптимально настроив которые, системные инженеры смогут выстроить грамотную защиту своей сети от атак, а также эффективно эксплуатировать высоконагруженные сервера с «тяжелыми» веб-приложениями.
Читайте также:
- Число процессоров: