
Перенос базы oracle с windows на linux
Обновлено: 07.07.2024
Исходные данные: На предприятии используется БД Oracle для всего на свете. Крутилось оно на сервере с вин2003сервер эдишн. Однажды начальство задолбали глюки и нестабильность винды. Волевым решением начальник ИТ отдела велел единственному линуксоиду на заводе (который вовсе не админом там работает и юзает (как юзер юзает) исключительно Убунту) перевести сервер на Linux и установить на него БД Оракл. Смена парадигмы явилась поводом поапгрейдить сервер и установить на него побольше ОЗУ. Еще на горизонте проглядывалась проблема аппаратного рэйда. Неясна была перспектива установки на него ОС, поймет ли установщик такой девайс? Так как БД Оракл заточена под рпм-базед дистрибутивы в качестве боевого дистрибутива была выбрана Fedora 12 (sic!), причем выбрана, глядя на ЛОР, типа: там стоит, а чего у нас не будет? Ну еще причинами выбора были неосиляние РедХат Ентерпрайз и ЦентОС последней стабле. По словам «внедренца», Федора показала себя неплохо и костылей городить в ней нужно было не так много как в РХ или Центоси. Фишка БД Оракл еще в том, что для установки оно требует ГУИ даже на сервер.
Проба сил состоялась на домашней машине в виртуалбоксе. Домашняя машина имеет 6 гигов ОЗУ, потому все было вполне достойно. Проба сил включала в себя:
Установку родной для «внедренца» Убунту и проверка работоспособности Оракла на ней. Итог печальный: очень много костылей необходимо..и просто так и потому, что Оракл заточено под рпм-базед дистры. Установку Ред Хат Энтерпрайза и та же самая проверка. Результат вообще ошеломителен. Костыли остались, что вообще говоря странно, но факт есть факт. Итог: отметена из-за излишней интерпрайзности и ваще. Установка ЦентОСи и т.п. Итог: немногим отличается от Ред Хата, если вообще отличается. Установка Федоры и БД на ней….видимо поосвоившись и покопавшись в двух предыдущих осях «внедренец» смирился с неизбежным и осилил-таки рпм. Итог: вот он, выбор ОС для сервера)Процесс пробы сил длился неделю во внерабочее время и выходные (ах Россия…т.е. Республика Беларусь).

| PLATFORM_NAME | ENDIAN_FORMAT |
| Oracle Solaris on SPARC (32-bit & 64-bit) | Big |
| AIX-Based Systems (64-bit) | Big |
| HP-UX (64-bit) | Big |
| HP-UX IA (64-bit) | Big |
| IBM zSeries Based Linux | Big |
| Apple Mac OS | Big |
| IBM Power Based Linux | Big |
| HP Tru64 UNIX | Little |
| Linux IA (32-bit & 64-bit) | Little |
| HP Open VMS | Little |
| Microsoft Windows IA (32-bit & 64-bit) | Little |
| Oracle Solaris on x86 & x86-64 | Little |
| Linux 64-bit for AMD | Little |
| Microsoft Windows 64-bit for AMD | Little |
В последних версиях Oracle Database задача миграции между платформами с одинаковым Endian-форматом стала заметно проще. Как правило, работа Oracle Data Guard (Physical Standby) между такими платформами сертифицирована. Миграция через Standby хорошо документирована, требует минимального простоя базы данных и имеет прозрачную процедуру отката (обратный Switchover), если что-то пошло не так. Обычно такую миграцию компании выполняют самостоятельно.
Второй вопрос — сайзинг
Миграция Oracle Database между платформами с разным Endian-форматом значительно сложнее и связана со многими дополнительными аспектами. Например, в сообществе широко обсуждаются вопросы сайзинга. Несколько лет назад мы провели масштабное исследование производительности Oracle Database на самых распространенных рисковых платформах Power/AIX и Sparc/Solaris в сравнении с платформой x86.
Для тестирования мы выбрали нагружающие скрипты Silly Little Oracle Benchmark (SLOB), разработанные Кевином Клоссоном. В отличие от большинства генераторов синтетической нагрузки с «вшитыми» запросами, эти скрипты в несколько потоков запускают собственные запросы к базе данных. Запросы мы разработали так, чтобы избежать влияния дисковой подсистемы (все данные были в прогретом кеше) и конкуренции за внутренние ресурсы экземпляра Oracle (у каждого потока свои данные). Мы измеряли число логических чтений в секунду при растущем объеме параллельных неконкурирующих потоков SLOB. В исследовании участвовали 16-ядерные домены рисковых серверов с актуальными на момент исследования процессорами Power8 и Sparc M7 в сравнении с 16-ядерным x86 сервером Intel. На рисунке показан характерный результат, полученный при сравнении платформ (ось X — потоки SLOB, ось Y — логические чтения в секунду).

На невысоких нагрузках лучшую производительность показывает x86 сервер, в том числе за счет аппаратных возможностей процессора Intel. При росте количества сессий SLOB (после 32) происходит перелом и рисковые серверы выходят вперед — начинает работать многопоточность (в ядре процессора Intel два треда, в ядре процессоров Power8 и Sparc M7 до восьми тредов). Следует заметить, что запросы к Oracle были разработаны таким образом, чтобы утилизировать все треды — в реальных системах это бывает далеко не всегда. Именно многопоточность объясняет окончательную «победу» сервера Sparc. В процессоре Power8 режим SMT=8 (восемь тредов на ядро) работал настолько своеобразно, что даже сам вендор рекомендовал использовать режим SMT=4 (четыре треда на ядро).
Результаты сравнительного исследования оказались неоднозначными. Для себя мы сделали вывод, что получить точный сайзинг можно, только тестируя работу конкретной базы данных на новой платформе. Но для этого базу нужно мигрировать. Поэтому часто требуется предварительный сайзинг, для которого мы используем принцип «ядро в ядро», несмотря на разнообразие сравнительных синтетических тестов типа SpecInt. Этот принцип серьезно усложняет обоснование, почему нужно мигрировать на Power/AIX. Нередко приходится искать дополнительные аргументы со стороны заказчика, а то и с помощью вендора. Дело в том, что оракловый коэффициент многоядерности (Core Factor) для процессоров IBM вдвое выше. И при одинаковом количестве ядер лицензирование Oracle получается вдвое дороже:
| Vendor and Processor | Core Factor |
| Intel Xeon Platinum 92XX, Intel Xeon Platinum 82XX, Intel Xeon Platinum 81XX, Intel Xeon Gold 62XX, Intel Xeon Gold 61XX, Intel Xeon Gold 52XX, Intel Xeon Gold 51XX, Intel Xeon Silver 42XX, Intel Xeon Silver 41XX, Intel Xeon Bronze 32XX, Intel Xeon Bronze 31XX, Intel Xeon Series 56XX, Series 65XX, Series 75XX, Series E7-28XX, E7-28XX v2, Series E7-48XX, E7-48XX v2, E7-48XX v3, E7-48XX v4, Series E7-88XX, E7-88XX v2, E7-88XX v3, E7-88XX v4, Series E5-24XX, E5-24XX v2, E5-24XX v3, Series E5-26XX, E5-26XX v2, E5-26XX v3, E5–26XX v4, Series E5-46XX, E5-46XX v2, E5-46XX v3, E5-46XX v4, E3-15XX v5, E3-15XX v6, Series E3-12XX, E3-12XX v2, E3-12XX v3, E3-12XX v4, E3–12XX v5, E3-12XX v6, E5-14XX v3, E5-14XX v2, E5-16XX v4, E5-16XX v3, E5-16XX v2, and E5-16XX or earlier Multicore chips | 0.5 |
| SPARC M5, SPARC M6, SPARC M7, SPARC M8 | 0.5 |
| IBM POWER6, IBM POWER7, IBM POWER7+ | 1.0 |
| IBM POWER8, POWER9 | 1.0 |
Третий вопрос — окно простоя
Вернемся к теме миграции. Есть три принципиально разных подхода к переносу Oracle Database между платформами:
- Логическая миграция. Классический Export/Import, Data Pump, SQL-команды через Database Link. При этом способе между платформами переносятся не файлы данных, а сами данные. Этот вариант проверен временем и относительно несложный. Он имеет всего одно ограничение: время простоя базы данных получается очень большим.
- Физическая миграция — Transportable Tablespace или TTS. При физической миграции между платформами переносятся файлы с данными, что значительно быстрее. Созданные на одной платформе файлы подключаются к базе данных на другой, поэтому необходимо тщательное тестирование, в том числе на предмет внутренних ошибок Oracle. TTS имеет сравнительно небольшое количество ограничений, а способы их обхода хорошо документированы.
- Репликация. Как правило, используется Oracle Golden Gate, хотя это не единственное решение. В основе любой репликации лежит разбор транзакционных журналов на базе-источнике с последующим применением (возможно с трансформацией) на базе-приемнике. Несмотря на развитые средства верификации данных (Oracle вместе с Golden Gate предлагает специальное ПО Veridata), остается серьезный риск потерять данные и не заметить это. Получается, что за целостность перенесенных данных в случаях логической и физической миграции отвечает Oracle, а в случае репликации — исполнитель.
Миграция с помощью TTS создавалась, чтобы быстро переносить оракловые файлы в рамках одной платформы. Уже потом она была расширена функционалом конвертации из одного Endian-формата в другой (технология RMAN Convert). Такая миграция состоит из трех этапов:
- выгрузка метаданных из словаря старой базы;
- перенос файлов данных с конвертацией RMAN;
- загрузка метаданных в словарь новой базы.
Это важно по следующей причине. Начиная с 12 версии RMAN (сама БД при этом быть версии 11) появилась возможность переносить и конвертировать не файлы с данными (что требует недоступности базы на все время переноса), а файлы бекапа (Backup Set). Это позволяет сделать полный бекап и восстановить его на новой платформе без остановки базы данных, а в технологическое окно перенести инкрементальный бэкап — «сконвертировать дельту». Такой способ намного быстрее переноса целой базы. Более того, можно повторить перенос инкрементального бэкапа несколько раз, пока «конвертация дельты» не начнет умещаться в заданное бизнесом технологическое окно.
Такой относительно новый функционал RMAN получил несколько названий, самое точное из которых, на наш взгляд — Cross-Platform Backup/Restore. С его помощью можно сократить время простоя, необходимое для конвертации: особенно если конвертируемые файлы Backup Set расположить на специальной файловой системе Veritas, допускающей переключение между платформами. При этом время выгрузки и загрузки метаданных данный способ не уменьшает!
Новая старая миграция
Новый способ миграции по сути является расширением TTS и на сегодня недостаточно документирован. Чтобы изучить его, необходимо читать синтаксис конкретных команд RMAN. Поэтому поделимся общей процедурой Cross-Platform Backup-Restore, реализованной нами в нескольких конкретных проектах миграции с рисковых платформ на x86.
Ниже приведены основные шаги этой процедуры. При создании скриптов миграции конкретных баз мы активно использовали генерацию текстов команд из SQL *Plus во всех случаях, когда необходимо перечисление файлов данных либо табличных пространств.
- Проверки перед миграцией. Проверки для классического TTS изложены в Metalink-ноте 371556.1 и для Cross-Platform Backup/Restore они в целом такие же. Особое внимание следует обратить на пользовательские объекты в табличном пространстве SYSTEM, которое при TTS не переносится и на режим Block Change Tracking.
- Создание базы данных на целевой платформе с правильной кодировкой и Timezone.
- Выполнение на исходной базе полного бекапа (level0) с помощью RMAN-команд Backup Incremental Level 0 Datafile ‘номер_файла’ Format ‘формат_backup_set’.
- Перенос пользователей с исходной базы в целевую базу: временное создание табличных пространств, перенос пользователей утилитами expdp/impdp, удаление табличных пространств (таким образом удается перенести пользователей до того, как табличные пространства будут перенесены TTS).
- Генерация на исходной базе скрипта по раздаче привилегий пользователей.
- Восстановление целевой базы из перенесенного полного бекапа (level0) с помощью RMAN-команд Restore From Platform ‘название_исходной_платформы’ All Foreign Datafiles Format ‘формат_backup_set’ From Backupset ‘имя_backup_set’. Название исходной платформы следует писать строго как в таблице Endian-форматов (см. начало статьи) — например, для Power/AIX это AIX-Based Systems (64-bit).
- Выполнение на исходной базе инкрементального бекапа (level1) с помощью RMAN-команд Backup Incremental Level 1 Datafile ‘номер_файла’ Format ‘формат_backup_set’.
- Применение на целевой базе перенесенного инкрементального бекапа level1 c помощью RMAN-команд Recover From Platform ‘название_исходной_платформы’ Foreign Datafilecopy ‘формат_backup_set’ From Backupset ‘имя_backup_set’. Шаги 1-8 можно делать вне технологического окна. Далее перечислены шаги процедуры миграции, требующие простоя.
- Перевод табличных пространств исходной базы данных в режим READ ONLY с помощью SQL-команд Alter Tablespace имя Read Only.
- Выполнение на исходной базе инкрементального бекапа (level1) с помощью RMAN-команд Backup Incremental Level 1 Datafile ‘номер_файла’ Format ‘формат_backup_set’.
- Параллельно п. 10 выгрузка из исходной базы метаданных пользователей утилитой expdp. Мы используем параметры «content=metadata_only exclude=user,role,role_grant,profile»).
- Параллельно п. 10 выгрузка из исходной базы метаданных табличных пространств утилитой expdp. Мы обычно используем параметры «exclude=table_statistics,index_statistics transport_full_check=no transport_tablespaces=список_табличных_пространств» т. к. выгрузка статистики оптимизатора часто оказывается долгой, особенно в базах данных 12 версии. В этом случае статистику нужно либо перенести пакетом DBMS_STATISTICS, либо частично собрать на целевой базе.
- Применение на целевой базе перенесенного инкрементального бекапа level1 (это второй инкрементальный бекап, выполненный в окно простоя) c помощью RMAN-команд Recover From Platform ‘название_исходной_платформы’ Foreign Datafilecopy ‘формат_backup_set’ From Backupset ‘имя_backup_set’.
- Загрузка в целевую базу метаданных табличных пространств, метаданных пользователей утилитой (оба действия — утилита impdp) и раздача пользователям привилегий (созданный в п. 5 скрипт).
- Перевод табличных пространств целевой базы данных в режим READ WRITE с помощью SQL-команд Alter Tablespace имя Read Write.
- Проверка INVALID объектов целевой базы данных и при необходимости их компиляция. Это последний шаг описанной процедуры. На этом межплатформенная физическая миграция с помощью Cross-Platform Backup/Restore завершена!
Автор: Алексей Струченко, руководитель направления СУБД «Инфосистемы Джет»
Я бы переносил через RMAN
1) бэкап базы на источнике
2) восстановление на новом инстансе с переименованием файлов ( можно использовать OMF)
3) Ну и переустановка словарей и каталогов.
Можно ещё expdp/impdp делать
В той статье я ни слова не вижу о кросплатформенном переносе базы. Это вариант для Linux to Linux или Windows to Windows.
Я скажу больше в разных платформах форматы файлов могут различаться ( и различаются).
Так что RMAN или expdp/impdp - это единственное средство. Потому не тратьте время и делайте бэкап. Только почитайте о том как это делается RMAN ом, в некоторых случаях там есть специфические ключики для кросплатформенном миграций. Сам точно подсказать не могу - я в дороге.
Жаль, ок спасибо. буду пробовать.
Ещё дам несколько советов.
На самом деле велика вероятность что у вас ничего не получится в эти выходные из-за отсутствия должной подготовки. Можно рассмотреть временные решения которые оттянут время но дадут подготовится.
По поводу переноса, нашел статью Kamran Agayev Agamehdi по переносу БД с помощью rman. Вроде получается, правда времени требуется слишком много, но ничего не остается :(
ПС: Самая большая печаль отсутствие дисков для сервера с БД, из-за чего бекап/конвертация делаются по сети на СХД. При этом даже на СХД места только под БД+бекап, либо БД+конвертируемые файлы. Тупо некуда бекап сунуть.
Насколько я понимаю, организация с использованием датафайлов и выбрана для минимизации
затрат на кросплатформенном окружении.
Различаются разве, что - контролфайлы и архивлоги - и то в плане путей до датафайлов.
Я делал так:
1. переносил датафайлы
2. делал дамп контрольника в трейс, правил в нем пути
3. пересоздавал контрольник
4. запускал БД на linux
Для минимизации downtime, я бы попробовал на линуксе создать шару( smb/nfs),
смонтировать на виндовой машине, выполнить
1. backup as copy datafiles на нее
2. периодически выполнять инкрементальное обновление (включить block change tracking, если БД EE - очень сильно
помогает)
3. Останавливаем листенер
4. выполняем последнее инкрементальное обновление
5. останавливаем БД
6. пересоздаем контрольник а linux
7. запускаем БД на линукс
Сделал миграцию через rman(есть там миграция с windows на linux)
не обошлось без проблем, но таки получилось БД запустить.
Дополнительный вопрос:
Если сделана миграция с помощью rman:
Это считается бекапом?
Т.е. могу ли я чистить архивлоги таким образом:
impdp через network_link неплохо работает. Я сам, буквально, на прошлой неделе тестировал время переноса 2,3 Тб базы с HP-UX на Oracle Linux.
Первый раз все прошло без 2-х часов двое суток. ХМ. Неприемлемо долго.
Со второй попытки пересоздал редо, темп и undo на tmpfs и переливка больших таблиц заняла 7 ч 20 минут, а схемы с остатками данных 84 Гб перелились за 1 ч 40 минут. Общее время переноса составило порядка 9 часов, что уже приемлемо.
Привет, сейчас мы с Вами рассмотрим технологию Oracle Data Pump, с помощью которой мы можем экспортировать данные в дамп и импортировать данные из дампа в СУБД Oracle. Эта технология подразумевает использование утилит expdp и impdp, которые заменяют традиционные exp и imp, и сегодня мы с Вами научимся использовать их для создания дампа базы данных и импорта данных из этого дампа.
Как Вы, наверное, уже догадались, сейчас речь пойдет о СУБД Oracle, а именно о технологии Oracle Data Pump и начнем мы, конечно же, с обзора данной технологии.
Что такое Oracle Data Pump?

Oracle Data Pump – это технология позволяющая экспортировать и импортировать данные и метаданные в СУБД Oracle Database в специальный формат файлов дампа.
Данная технология впервые появилась в версии 10g и включается во все последующие версии Oracle Database. Для экспорта и импорта данных до Oracle Data Pump, т.е. до версии 10g, использовались традиционные утилиты exp и imp, возможности которых в 10 и выше версиях сохранены в целях совместимости. Особенностью Oracle Data Pump является то, что экспорт и импорт данных происходит на стороне сервера, dmp-файл формируется на файловой системе сервера, а также главным преимуществом Oracle Data Pump перед традиционным способом экспорта и импорта данных является более быстрая выгрузка и загрузка данных.
В Oracle Data Pump для экспорта и импорта данных созданы новые серверные утилиты expdp и impdp. Формат файлов дампа (dmp) используемый в этих утилитах, несовместим с форматом, который используется в exp и imp.
Expdp – утилита для экспорта данных в СУБД Oracle Database в дамп.
Impdp – утилита для импорта данных в СУБД Oracle Database из дампа.
Утилиты expdp и impdp поддерживают несколько режимов работы:
Для того чтобы посмотреть подробную справку (описание параметров) по этим утилитам запустите их с параметром help=y, например
Примечание! Запуск утилит в операционной системе Windows запускается из командной строки. В случае если системный каталог bin СУБД Oracle не добавлен в переменную среды Path, то запускать утилиты нужно из данного каталога, т.е. предварительно перейдя в него (например, с помощью команды cd). Для демонстрации примеров ниже я использую Oracle Database Express Edition 11g Release 2 установленный на операционной системе Windows 7.
Пример создания дампа базы данных Oracle с помощью expdp
Для того чтобы создавать дампы в Oracle с помощью утилиты expdp предварительно необходимо определится с логической директорией, в которую Вы будете экспортировать дампы, т.е. где они будут храниться. Можно использовать стандартную директорию DATA_PUMP_DIR, но Вы, если хотите, можете создать новую, конкретно для Ваших целей отдельную директорию. Давайте создадим отдельный каталог для наших задач с экспортом и импортом данных, заодно и научимся создавать такие директории.
Сначала создаем каталог в файловой системе, например, я создал D:\OracleEX\ExportImport.
Затем уже создаем директорию в Oracle, для этого открываем SQL*Plus или SQLDeveloper и запускаем следующую команду (я запустил в SQL*Plus и директорию назвал ExportImport).
Чтобы посмотреть, какие директории уже созданы, можете использовать следующий запрос.
Теперь давайте перейдем непосредственно к экспорту. Я все действия выполнял от имени системного пользователя Oracle.
Создание дампа всей базы данных
Для того чтобы создать полный дамп базы данных выполните следующую команду в командной строке
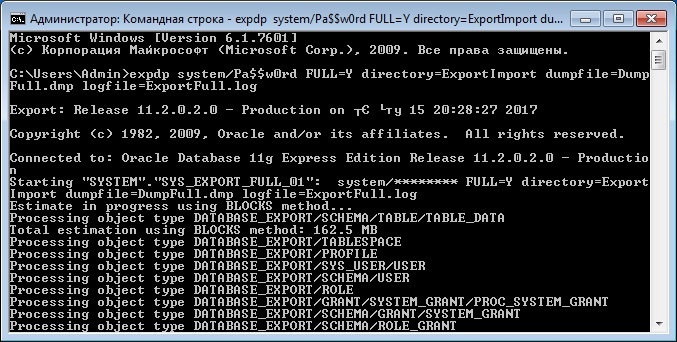
- system/Pa$$w0rd – это логин и пароль пользователя в СУБД;
- FULL=Y – параметр, который указывает, что мы делаем полный экспорт базы данных;
- directory=ExportImport – параметр указывает директорию, в которую мы будем выгружать дамп файл;
- dumpfile=DumpFull.dmp – параметр для указания названия дамп файла;
- logfile=ExportFull.log – параметр для указания названия лог файла экспорта данных.
Создание дампа на основе отдельной схемы базы данных
В большинстве случае все-таки, наверное, понадобится экспортировать отдельную, выбранную схему базы данных, а не всю БД. Для того чтобы выгрузить схему, указываем параметр SCHEMAS.
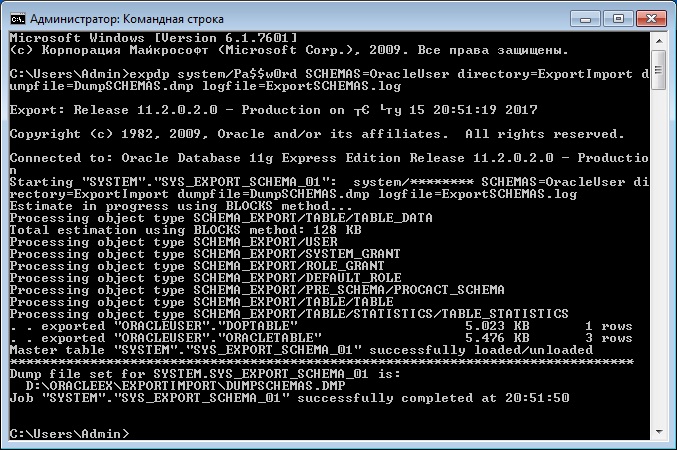
SCHEMAS=OracleUser – параметр, в котором мы указываем схему для экспорта, в нашем случае OracleUser.
Создание дампа на основе отдельных таблиц базы данных
Иногда нужно экспортировать только одну или несколько таблиц, для этого мы можем использовать параметр TABLES. В примере ниже мы экспортируем таблицу OracleTable в схеме OracleUser.
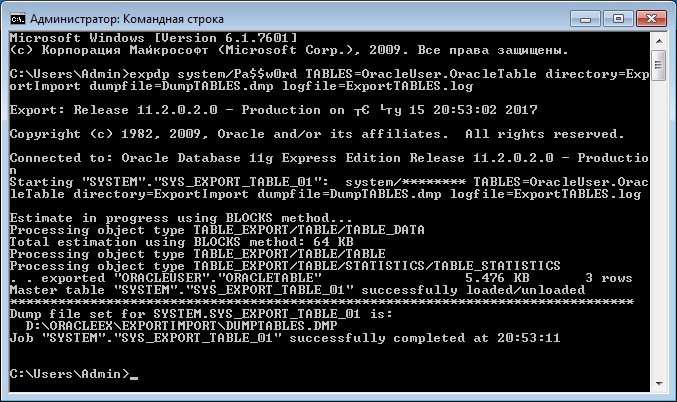
TABLES=OracleUser.OracleTable – это параметр, в котором мы указываем таблицу для экспорта (или несколько таблиц через запятую).
Пример импорта данных из дампа Oracle с помощью impdp
Сейчас давайте перейдем к импорту данных из дампа. Как Вы помните, для этих целей у нас существует утилита impdp.
Импорт схемы из дампа
Для импорта всей схемы запускаем утилиту impdp с параметром SCHEMAS. В случае если у Вас уже создана схема, которую Вы собираетесь импортировать, то ее предварительно нужно удалить. Для удаления схемы используйте следующий запрос в SQL*Plus или SQLDeveloper
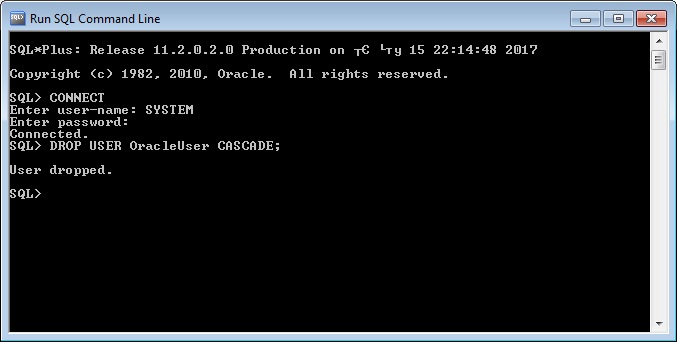
После этого, для того чтобы импортировать схему, запускаем утилиту impdp со следующими параметрами
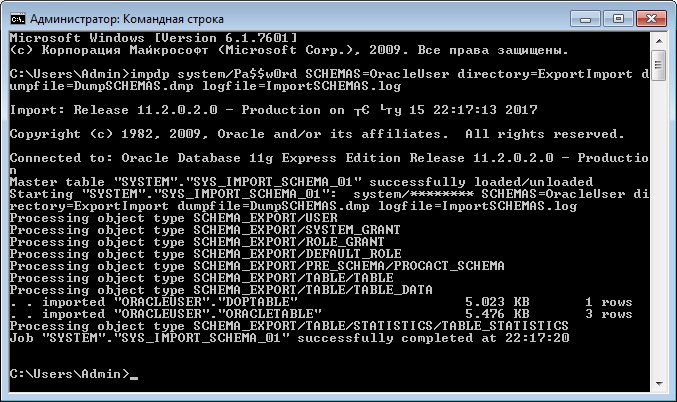
- system/Pa$$w0rd – это логин и пароль пользователя в СУБД;
- SCHEMAS=OracleUser – параметр, который указывает, что мы хотим импортировать конкретную схему (в нашем случае OracleUser);
- directory=ExportImport – параметр указывает директорию, в которой расположен файл дампа данных;
- dumpfile=DumpSCHEMAS.dmp – параметр для указания названия дамп файла;
- logfile=ImportSCHEMAS.log – параметр для указания названия лог файла импорта данных.
Импорт таблиц из дампа
Если Вы хотите импортировать одну или несколько таблиц, то можете использовать параметр TABLES, также как и при экспорте. В случае если таблица или таблицы уже созданы, т.е. существуют, то их необходимо или удалить вручную (DROP TABLE) или указать параметр TABLE_EXISTS_ACTION, который может принимать следующие значения:
Для примера давайте запустим impdp с параметром TABLE_EXISTS_ACTION=REPLACE, для того чтобы перезаписать существующую таблицу.
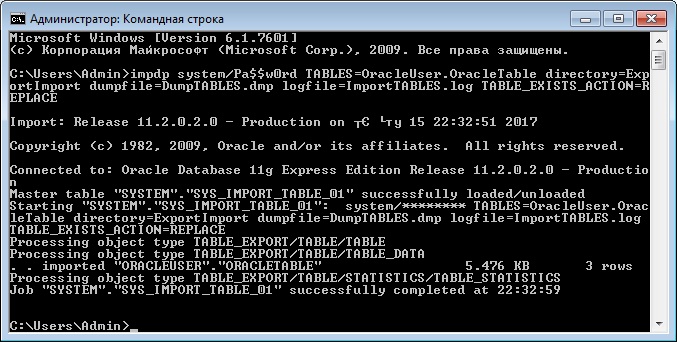
Заметка! Для изучения языка SQL как стандарта, чтобы его можно было использовать в любой СУБД, рекомендую почитать книгу «SQL код», в ней рассматриваются конструкции SQL, которые будут работать везде и не привязаны к какой-то конкретной СУБД.

В ЖИЗНИ ЛЮБОЙ КОМПАНИИ МОЖЕТ ПОЯВИТЬСЯ НЕОБХОДИМОСТЬ ПЕРЕХОДА НА НОВУЮ ПЛАТФОРМУ. ПРИЧИНЫ И АРГУМЕНТЫ НАС НЕ ИНТЕРЕСУЮТ. САМОЕ ВАЖНОЕ — УЖЕ ИМЕЮЩИЕСЯ ДАННЫЕ, НАРАБОТКИ, РЕЗУЛЬТАТЫ ТРУДОВ ДОЛГИХ НЕДЕЛЬ/МЕСЯЦЕВ/ЛЕТ ПРЕДЫДУЩЕЙ IT-СИСТЕМЫ.
Есть аппаратное обеспечение, закуплено/скачано необходимое ПО. Все неплохо, кроме одного: требуется перенести всю существующую инфраструктуру на новую платформу и перенести быстро, эффективно и безопасно. Как это сделать? Что нужно применять и в каких случаях?
Компоненты инфраструктуры компании могут иметь разную природу и, соответственно, к ним необходимо применять разные методики переноса. Условно разделим активы на две наиболее часто используемые категории: приложения и данные, которые, возможно, и потребуется переносить.
Ситуация целиком зависит от типа СУБД, использовавшейся при работе с Windows-платформой. Хотя у всех профессиональных баз данных (MSSQL, MySQL, InterBase/Firebird, Oracle и других) есть инструменты, позволяющие без особых проблем сделать резервную копию базы и перенести ее на другой сервер. Кроме того, можно использовать специальные программные пакеты, ориентированные на профессиональный перенос с одной платформы на другую.
EMS Database — решения для работы с базами данных от EMS достаточно популярны. Продукты EMS работают со следующими типами СУБД:
• MYSQL
• MSSQL
• POSTGRESQL
• INTERBASE/FIREBIRD
• ORACLE
• DB2
Почти все решения кросс-платформенны и являют собой мощнейший инструментарий импорта/экспорта/резервного копирования как на одной платформе, так и между разными, и содержащий колоссальные возможности автоматизации.
Что касается ODBC-драйверов и драйверов баз данных, которые могут применяться в клиентских и бизнес-приложениях, то этот вопрос возник, конечно, не сегодня и даже не вчера. Программисты уже создали ODBC-драйверы под Linux. Главный поставщик ПО такого рода — компания InterSolve, выпускающая пакет DataDirect ODBC Driver Pack, имеющий около 30 драйверов для различных баз данных под многие системы – Windows, Unix, Mac OS и другие.
Прежде всего, почта. При использовании на Windows-платформе Microsoft Outlook, легко перейти к Evolution — одинаковый интерфейс, принципы работы. Переход осуществим без потери данных, так как Evolution понимает формат файлов Outlook. Кроме того, Evolution без всяких проблем интегрируется в уже существующую систему Exchange, что весьма удобно в том случае, если сначала решено внедрить Linux на пользовательские машины, чтобы оценить уровень готовности пользователей к работе с этой системой. Если на машинах использовался TheBat, то с помощью сценария нетрудно автоматизировать экспорт почтовых архивов в формат Unix-mail. Если же требуется аналог Exchange, то возможен вариант перехода на Рostfix, который не менее эффективно выполняет те же самые функции.
Данные Microsoft Office хорошо понимают как Open Office, так и Star Office, но нередко требуется решать проблемы с кодировкой. OpenOffice полностью поддерживает недавно стандартизованный формат ODF (Open Document Format), основанный на XML и позволяющий создавать все наиболее распространенные типы офисных документов (презентации, книги, таблицы и так далее) полностью открыто и независимо от различных поставщиков. Microsoft же (главным образом в Office 2007) начала «продвигать» своего конкурента этому формату – Microsoft Office Open XML, также основанного на XML-формате. Тем не менее, компания сообщила о поддержке Office 2007 ODF формата, что должно в будущем упростить миграцию/обмен данными между двумя офисными пакетами. Для OpenOffice существуют специальные инструменты импортирования Microsoft Office документов и большое количество документации.
В ситуации с подбором аналогов используемого под Windows софта порой трудно что-то придумать (хотя теперь даже у 1С есть версия для Linux). Что же касается более простых приложений, то проблем практически нет — аналогов все больше и больше с каждым днем. Но нас интересует перенос приложений, написанных IT-специалистами для поддержки специфичных для компании процессоров. Как быть с ними?
Есть несколько вариантов. К примеру, использование различных эмуляторов Windows-окружения в Linux, но это не всегда эффективный и приемлемый путь.
Другой путь — портирование под Linux-платформу. Тут все зависит от сложности приложения. Если оно использует какую-то очень сложную логику/низкоуровневые функции, придется затратить немало времени и труда для того, чтобы качественно перенести приложение. Обычно пользовательский интерфейс и системную логику портируют отдельно. Ситуацию сильно упрощает применение специальных библиотек и технологий: ACE, Boost, wxWidgets и так далее. Если портирование невозможно, тогда необходимо полностью переписывать приложение. В более простых достаточно только перекомпиляции, с использованием одного из многочисленных пакетов, созданных для этих целей.
Если вы уже перенесли сервер на Unix, а пользователи пока работают на прежней платформе, пригодится Samba — удобное решение, позволяющее клиентам Windows получать доступ к файлам и принтерам Unix. Установка такого решения может быть неплохой «перевалочной» базой на пути к полному переходу на Unix и на сервере, и на рабочих станциях.
Читайте также: