
Планировщик задач ядра linux что это
Обновлено: 07.07.2024
В данном посте обсуждаются базовые принципы написания скриптов и работа планировщика заданий в Oracle Linux. Рассматриваются следующие вопросы:
1. Скрипты в ОС Linux
Скрипты в ОС на базе Linux – это набор команд, записанных в файл. Это делается с целью быстрого и удобного вызова последовательности этих команд. Скрипты могут выполнять самые разные задачи – от автоматизации рутинных действий системного администратора до реализации сложных алгоритмов для ИТ инфраструктуры. При этом результаты работы команд могут служить входными данными для других задач (команд).
Пример ошибки, когда запускается неисполняемый файл:
Права на исполнение даются командой chmod. Например,
chmod +x filename.sh
Данная команда дает всем пользователям операционной системы право на запуск файла с именем filename.sh
Право на запуск того же файла только владельцу можно дать следующей командой: chmod u+x filename.sh.
Расширение .sh не обязательно, но таким образом легче определять, какой файл является скриптом.
Ниже рассматривается пример написания простейшего скрипта, копирующего все файлы из папки /home/rustam/Documents в папку /tmp/backup.
При работе со скриптами могут использоваться переменные. Они позволяют хранить в файле сценария различную информацию, например, результаты работы одних команд для дальнейшего их использования для других команд.
Исполнение отдельных команд без хранения результатов работы ограничивают их возможности.
Существуют два типа переменных, которые используются в bash-скриптах:
Используются при необходимости работы с системными данными в командах оболочки. Например, требуется вывести домашнюю директорию текущего пользователя. Список переменных для среды конкретного пользователя выдается командой env.
Можно использовать системную переменную $HOME в двойных кавычках, что не помешает ее распознаванию системой.
В дополнение к переменным среды, bash-скрипты позволяют задавать и использовать в скрипте свои собственные переменные. Подобные переменные хранят значение до тех пор, пока не завершится выполнение сценария. Как и в случае с системными переменными, к пользовательским переменным обращаются используя знак доллара:
Дополним соответствующим образом скрипт, написанный ранее – добавляется переменная для хранения пути к папке, в которую осуществляется копирование.
2. Что такое планировщик заданий. Работа сервиса cron.
Часто возникают ситуации, в которых приходится автоматизировать различные задачи по обслуживанию и работе с Linux с помощью скриптов. В этом случае удобно, если скрипт выполняет необходимые команды без участия пользователя. Для этого настраивается автоматический запуск требуемого скрипта в заданное время.
Для указанной настройки в Linux используется системный сервис cron. Это планировщик, который позволяет выполнять необходимые скрипты раз в час, раз в день, неделю или месяц, а также в любое заданное время или через любой интервал времени. Сервис cron также часто используется другими службами операционной системы.
Для настройки времени, даты и интервала выполнения задания, используется специальный синтаксис файла cron и специальная команда. Не рекомендуется непосредственно редактировать файл /etc/crontab. Вместо этого используется команда crontab. Ниже запускается команда crontab с ключом –e для редактирования файла
Рекомендуется ее выполнять с опцией -e, тогда для редактирования правил используется текстовый редактор по умолчанию. После выполнения команды открывается временный файл, в котором записаны текущие правила cron и есть возможность добавлять новые. Добавленные правила запускаются именно от того пользователя, от имени которого они были добавлены.
Файлы crontab, используемые для управления работой планировщика, располагаются в каталоге /etc/cron.d/. Кроме того, в каталогах /etc/cron.daily/, /etc/cron.weekly/ и /etc/cron.monthly/ размещаются автоматически запускаемые программы (ежедневно, еженедельно или ежемесячно).
Вывод содержимого текущего файла позволяет команда:
Таблица crontab состоит из 6 колонок, которые разделяются пробелами или табуляторами. Первые пять колонок отвечают за время выполнения, соответственно, минута, час, день месяца, месяц, день недели. В них может находиться: число, список чисел (1,2,3), диапазон чисел (1-3), символы * или /. Все остальные символы в строке интерпретируются как выполняемая команда с ее параметрами – можно указать как саму команду (например, echo “Доброе утро”), так и путь к исполняемому скрипту.

Как запускать скрипты через cron
Скрипты запускаются через cron, указанием команды либо пути к скрипту в последней колонке.
Обязательно требуется прописывать полный путь к команде, так как для команд, запускаемых от имени сервиса cron, переменная пользовательской среды PATH будет отличаться, и сервис не сможет найти команду.
Пример запуска ранее созданного скрипта filename.sh, который копирует файлы каждый день в 23:00:
или копирует файлы каждые 5 минут:
3. Примеры
Ниже приведены примеры настройки и работы cron:

Не за горами выход новой версии ядра Linux 5.14. За последние несколько лет это обновление ядра является самым многообещающим и одно из самых крупных. Была улучшена производительность, исправлены ошибки, добавлен новый функционал. Одной из новых функций ядра стал Core Scheduling, которому посвящена наша статья. Это нововведение горячо обсуждали в интернете последние несколько лет, и наконец-то оно было принято в ядро Linux 5.14.
Если вы работаете с Linux или занимаетесь информационной безопасностью, вам интересны новые технологии, то добро пожаловать под кат.
▍Введение
Для того чтобы понять Core Scheduling и для чего он нужен, стоит разобраться, как работают многозадачные системы, и как они развивались.
На современных компьютерах одновременно могут работать сотни, а то и тысячи программ одновременно. Монопольный доступ к процессору и памяти остались в прошлом, и на данный момент практически нигде не используется кроме микроконтроллеров и RT(Real Time) задач.
Изначально все процессоры были одноядерными, и могли выполнять только одну задачу одновременно. Практически сразу появилась необходимость выполнять несколько задач одновременно на одноядерном процессоре. Для этого был придуман scheduler, он же планировщик в операционных системах, который занимается переключением задач и управляет ресурсами компьютера. Ядро операционной системы всегда работает с большими привилегиями, чем пользовательские программы, такой режим работы называют Ring 0. Поэтому планировщик может в любой момент приостанавливать выполнение одной задачи и перейти к выполнению следующей. В нём существует специальная очередь задач, в которую добавляются все работающие программы и обработчики ядра, например, обработчик прерываний. Изначально эта очередь была простая, как очередь в магазине, и каждая программа выполнялась по очереди, как бы подходя к кассе в магазине. Каждая задача, после того, как выполнила свою работу, должна была явно уведомить планировщик, что задача завершила свою работу и планировщик может переключиться на следующую задачу. Такую очередь называют FIFO — First In First Out первым пришёл, первым ушёл. А такую многозадачность называют совместной или кооперативной многозадачностью.
Дальше очередь стала более сложной и появились приоритеты с вытеснением, задачи с более высоким приоритетом могут встать в очереди перед задачами с более низким приоритетом, или некоторые задачи вовсе могут быть пропущены в этом цикле обхода очереди. Простой пример такой очереди, когда в очереди к директору компании стоят сотрудники, но приходит какой-нибудь проверяющий, или какое-то важное лицо, и всех просят подождать, пока директор пообщается с этим более важным человеком. А могут и вовсе кого-то выгнать из кабинета начальника: -«Семён Семёнович, незамедлительно покиньте кабинет директора, к нему министр тяжёлой промышленности приехал!». Решение о переключении задач при такой многозадачности принимает OC. Через запрограммированные промежутки времени по таймеру происходит прерывание, и запускается планировщик, который переключает процессор на выполнение следующей задачи. Такую многозадачность называют вытесняющая многозадачность или PREEMPT, preemptive multitasking.
Каждая задача в ядре Linux описывается структурой task_struct, а список задач хранится в виде циклического двусвязного списка (Связный список). Описание структуры task_struct можно найти в файле: include/linux/sched.h исходников ядра. task_struct ещё называют дескриптором процесса и в нём находится вся важная информация об исполняемом процессе. Мы не будем углубляться в эту тему слишком глубоко, так как это тема отдельной статьи. Но вы всегда можете найти комментарии и пояснения к коду, в файле: include/linux/sched.h , и изучить эту тему самостоятельно. Умение читать исходные коды ядра, является очень важным навыком для каждого разработчика, который хочет углубиться в программирование ядра Linux. Часть полезной информации также можно найти в официальной документации ядра Linux — Scheduler, но всё же лучше смотреть исходные коды ядра.

Со временем системы стали многоядерными и имели количество потоков выполнения — равное количеству ядер процессора или количеству процессоров, в случае с одноядерными процессорами, что, в свою очередь, повысило возможности компьютеров и количество выполняемых задач одновременно. Чтобы уменьшить накладные расходы переключения задач в ОС, разработчики процессоров придумали простое и элегантное решение, переложили часть функций на процессор. Так были придуманы Intel Hyper-Threading (Intel HT) и AMD Simultaneous Multithreading (AMD SMT).
Технологии очень простые: Теперь вместо реальных ядер процессор начал показывать виртуальные ядра в количестве реальных ядер умноженных на 2. Процессоры с 1 ядром начали иметь 2 виртуальных процессора (2 потока выполнения), которые видит ОС. Теперь в процессоре, имея два потока выполнения на каждое ядро, ядро процессора может не простаивать, когда один из потоков спит, а переключится на второй поток. Тем самым процессор будет переключаться между потоками с минимальными задержками, и по максимуму использовать возможности каждого ядра.
Как работают Intel HT и AMD SMT можно понять по картинкам ниже. Первая картинка показывает, как занята очередь процессора при выполнении двух задач, а на второй картинке показана временная диаграмма, и что в случае с Intel HT и AMD SMT на обе задачи суммарно было потрачено меньше времени.


На самом деле, в некоторых случаях это решение является очень спорным и не даёт какого-либо выигрыша производительности. Но в некоторых задачах всё же есть заметный выигрыш, например, в виртуализации. Ничего не предвещало беды, но, как говорится, беда подкралась неожиданно…
Долгое время никто не замечал главной проблемы этой технологии. Все потоки используют одни и те же кэши и аппаратные возможности процессора. Это открыло уязвимость, что один процесс может извлекать данные, наблюдая за изменениями кэша другим процессом. Только с ростом потребностей бизнеса и популяризации виртуализации, такая уязвимость стала чаще обсуждаться. Единственным способом безопасно запускать два процесса не доверяющих друг-другу стало отключение Intel HT и AMD SMT. С появлением уязвимостей класса Spectre данная проблема ещё больше усугубилась и поставила облачных провайдеров перед очень тяжелым выбором: отключить Intel HT и AMD SMT? И даже вызывало сильное раздражение, так как клиенты — бизнес требуют безопасности их данных. Но что же это для них значило? Конечно же, увеличение затрат и миллионные потери прибыли. Если при наличии Intel HT и AMD SMT они могли иметь больше клиентов чем ядер, и клиенты могли балансироваться между ядрами и выравнивать нагрузку на процессор, то теперь все облачные технологии готовы были заключить в жесткие рамки количества реальных ядер. И тут облачные провайдеры задумались не на шутку, как сделать так чтобы оставить включенными Intel HT и AMD SMT, сделать данные клиента безопаснее, например, закрытые ключи шифрования и пароли. Так появился на свет Core Scheduling, который безопасно может выполнять потоки.
▍Core Scheduling
Как же работает Core Scheduling? Всё очень просто! Каждому процессу назначается метка — cookie , по которому его можно идентифицировать. Так же свой уникальный cookie можно назначить каждому пользователю. Тем самым ядро разрешает совместное использование процессора только в случае, если у двух процессов совпадает cookie . Как говорится, всё гениальное просто!

Для управления процессами или потоками используется системный вызов prctl:
В случае с Core Scheduling системный вызов принимает вид:
Где PR_SCHED_CORE говорит, что это операция с Core Scheduling, command это команда которую надо выполнить, pid process id — цифровой идентификатор процесса, pid_type тип pid, cookie — беззнаковое 32 битное число метки.
Для работы с Core Scheduling существует 4 команды:
- PR_SCHED_CORE_CREATE — говорит ядру создать новый cookie и назначить его процессу с pid . С помощью параметра pid_type мы можем управлять шириной назначения cookie. Если значение равно PIDTYPE_PID , то cookie устанавливается для конкретного процесса с pid , а при PIDTYPE_TGID всей группе потоков. cookie не должен быть равен NULL .
- PR_SCHED_CORE_GET — получает cookie для указанного pid , и сохраняет его в переменной cookie . Вы могли обратить внимание, что системному вызову передается не само значение cookie, а указатель на место в памяти где находится значение переменной cookie , тем самым системный вызов свободно может читать и писать значения по этому адресу. Полезность данной команды заключается только в получении cookie двух процессов и их сравнения. Большей ценности данная команда не имеет.
- PR_SCHED_CORE_SHARE_TO — процесс который вызвал prctl может поделится своим cookie с процессом pid которого был передан. В остальном команда полностью повторяет параметры PR_SCHED_CORE_CREATE.
- PR_SCHED_CORE_SHARE_FROM — извлекает cookie у процесса с pid , и назначает вызвавшему prctl .
Включить Core Scheduling можно при сборке ядра: General setup --> [*] Core Scheduling for SMT . Так же вы можете прочитать мою статью LTO оптимизация ядра Linux .
Так вот, если в системе включен Core Scheduling, то когда планировщик берет новую задачу с наивысшим приоритетом из списка, то он отправляет прерывание на родственные процессоры, на что каждый из них должен проверить cookie новой задачи и ответить есть ли задачи на нём с таким же cookie . Таким образом, при совпадении cookie , процессор уже имеющий задачу с таким же cookie , начинает выполнение этой новой задачи. Если же в системе нет процессов имеющий одинаковый cookie , то процессор будет бездействовать, пока такие процессы не появятся. Чтобы предотвратить простой процессора, планировщик будет переносить процессы между ядрами.
К сожалению первые версии Core Scheduling имели большой недостаток — высокие накладные расходы, падала производительность системы т.к. в некоторые моменты времени Core Scheduling заставлял процессор бездействовать, что в итоге стало ещё хуже чем отключение Intel HT и AMD SMT. Но со временем удалось улучшить алгоритм и решать большую часть проблем, но всё же не бесплатно. Поэтому Core Scheduling не подходит каждому т.к. немного снижает производительность системы, а только тем, кому очень важна безопасность, например облачным провайдерам. Так же Core Scheduling не подходит задачам которым важна скорость реакции, так называемые Real Time задачи, для них вовсе рекомендуется отключить Intel Hyper-Threading(Intel HT) и AMD SMT.
Моя прошлая статья LTO оптимизация ядра Linux вызвала у читателей много вопросов. Было много доброжелателей, которые мне писали лично и благодарили. Были и такие которые писали, чтобы поругаться и даже катали жалобы на мои проекты. Конечно же доброжелателей было значительно больше. Поэтому дам краткий ответ на частые вопросы:
- Насколько LTO ядро быстрее? Ответ с бенчмарками есть по ссылке Squeezing More Performance Out Of The Linux Kernel With Clang + LTO
- Для кого подходит LTO Оптимизация ядра? В первую очередь это разработчикам мобильных устройств, которым очень важна производительность и быстрый отклик. Изначально LTO оптимизация появилась для ядра Linux мобильных устройств, но показала свою высокую эффективность и была перенесена на x86_64 . Поэтому LTO Оптимизация ядра Linux подходит всем, кому важна более высокая производительность и быстрый отклик от системы. Например сервера, которым важна скорость обработки и отдачи контента. За месяцы тестов не было выявлено ни одного побочного эффекта от применения LTO Оптимизации. Так же в статье LTO оптимизация ядра Linux был дан ответ почему всё работает хорошо и почему именно выбран clang+llvm .
- Несколько читателей хабра мне написали и попросили сделать репозиторий для моих измененных пакетов arch-packages. Один из них, поработал какое-то время с моими пакетами, и вышел с предложением разместить репозиторий у него на сервере. Так появился Arch Linux Club. Теперь все легко могут протестировать, как влияют измененные пакеты на производительность. Через какое-то время мой проект заметили разработчики одного Linux дистрибутива(форка Arch Linux), связались со мной и написали восторженные отзывы.
- В чем различие моих пакетов от официальных Arch Linux? Основное различие больше патчей и багфиксов. После того, как начал переделывать пакеты, был поражен, что майнтенейры не всегда понимают, что у них в сборочных скриптах, и часто забивают на исправления ошибок и совсем не читают багрепорты в апстриме. Например, не редко было, что некоторые программы у меня при работе крешились, а мейнтейнеры ничего не делали. В этом разработчики RedHat, Gentoo, Suse просто на две головы выше.
Это заставило меня ещё больше переделать пакетов и добавить патчи. Возможно мое начинание даже перейдет в свой дистрибутив. Основной упор в пакетах на безопасность и производительность где возможно включены -z,relro,-z,now и -fstack-protector-strong -fstack-clash-protection -fPIE . Подробнее что это даёт можно прочесть на сайте RedHat.
При подготовке статьи использовалась переписка разработчиков ядра Linux — Linux Kernel Mailing List.
Ядро Linux продолжает развиваться - появляется поддержка новейших технологий, растут надежность, масштабируемость и производительность. Одним из важнейших компонентов ядра версии 2.6 является планировщик задач, разработанный Инго Молнаром (Ingo Molnar). Данный планировщик является динамическим, поддерживает распределение нагрузки, а его алгоритм имеет сложность O(1). Данная статья расскажет об этих и некоторых других свойствах планировщика.
В данной статье приведен обзор планировщика задач Linux 2.6 и его наиболее важных свойств. Но перед тем, как погрузиться в детали устройства планировщика, предлагаю разобраться с его основными задачами.
В общем смысле термина, операционная система является посредником между приложениями и ресурсами. К ресурсам обычно относят память и физические устройства. Но центральный процессор (ЦП) можно также считать ресурсом, который планировщик на некоторое время (измеряемое в отрезках ) выделяет задаче. Планировщик обеспечивает параллельное выполнение нескольких программ, распределяя ресурсы ЦП между различными задачами различных пользователей.
Важной целью планировщика является эффективное распределение отрезков процессорного времени при условии обеспечения пользователю времени ожидания на приемлемом уровне. Помимо этого, перед планировщиком могут стоять противоречащие друг другу цели, такие, как минимизация времени ожидания при выполнении критически важных задач реального времени и максимальное использование ресурсов ЦП. Посмотрим, как планировщик задач Linux 2.6 справляется с достижением этих целей в сравнении со своими предшественниками.
До выхода ядра версии 2.6 планировщик имел существенное ограничение, проявлявшееся при большом количестве выполняющихся задач. Причиной тому был алгоритм планировщика, имевший сложность O(n). При его использовании время, затрачиваемое на планирование, находится в функциональной зависимости от числа задач, выполняющихся в системе. Другими словами, чем больше число задач (n), тем больше времени требуется на их планирование. При очень высокой нагрузке планирование может занять почти все процессорное время, оставив собственно задачам лишь малую его долю. Таким образом, алгоритму не хватало масштабируемости.
Планировщик, применявшийся до выхода версии 2.6, также использовал единую очередь задач для симметричных мультипроцессорных (SMP) систем. Это означало, что задача могла быть назначена любому из процессоров, что хорошо для распределения нагрузки, но плохо для кэширования. Представим, например, что задача выполняется на ЦП-1 и ее данные находятся в кэше этого процессора. Если задача будет перепланирована на ЦП-2, ее данные потребуется убрать из кэша ЦП-1 и разместить в кэше ЦП-2.
Кроме того, предыдущая реализация планировщика использовала единую блокировку очереди задач, из-за чего на SMP-системах несколько процессоров не могли одновременно выполнять такие манипуляции с очередью, как выбор задачи для выполнения. Это приводило к простою процессоров, ожидающих освобождения блокировки очереди задач и, как следствие, к падению производительности.
В довершение всего, планировщик не поддерживал вытеснение. Это означало, что задача, имеющая высокий приоритет могла ожидать завершения задачи с более низким приоритетом.
Планировщик версии 2.6 спроектирован и разработан Инго Молнаром. Инго участвует в разработке ядра Linux с 1995 г. Он задался целью создать новый планировщик исключительно на основе алгоритмов сложности O(1) для пробуждения процессов, переключения контекстов и обработки прерывания таймера. Одной из причин возникновения потребности в новом планировщике были виртуальные машины Java™ (JVM). Модель программирования этого языка активно использует потоки, что приводит к росту накладных расходов при использовании планировщика с алгоритмом О(n). Планировщик с алгоритмом O(1) не имеет данного недостатка, поскольку его производительность не ухудшается при высокой нагрузке. Это позволяет обеспечить эффективную работу виртуальных машин Java™.
Помимо устранения прочих недостатков, в планировщике версии 2.6 решены три основные проблемы, присущие его предшественнику (O(n) и проблемы масштабируемости на многопроцессорных системах). Сейчас мы рассмотрим общие принципы устройства планировщика версии 2.6.
Начнем с обзора структур данных, используемых планировщиком. Каждый ЦП имеет очередь задач, состоящую из 140 списков, обслуживаемых в порядке FIFO и содержащих задачи, имеющие соответствующий приоритет. Задачи, запланированные к выполнению, добавляются в конец списка. Каждой задаче выделяется отрезок времени, определяющий продолжительность ее выполнения. Первые 100 списков очереди задач зарезервированы для задач реального времени, а последние 40 - для пользовательских задач (см. рисунок 1). Позже вы поймете важность этого разграничения.
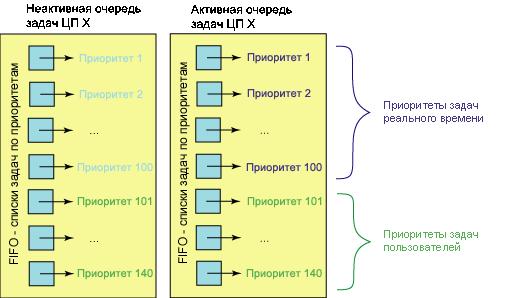
Помимо очереди задач ЦП, называемой активной очередью задач , существует еще неактивная очередь. После того, как задача, находящаяся в активной очереди, исчерпывает отведенный ей отрезок времени, она переносится в неактивную очередь . При переносе происходит пересчет ее отрезка времени (также пересчитывается ее приоритет, но об этом позже). Если в активной очереди отсутствуют задачи с данным приоритетом, соответствующие указатели активной и неактивной очередей меняются местами; при этом неактивный список становится активным.
Работа планировщика задач не отличается сложностью: он просто выбирает задачу для выполнения из списка с наивысшим приоритетом. Чтобы повысить эффективность этого процесса, для определения наличия задач в списке используется битовый массив. Следовательно, для поиска бита, соответствующего списку с наивысшим приоритетом, можно использовать инструкцию find-first-bit-set , которую поддерживает большинство архитектур процессоров. Время, затрачиваемое на поиск задачи, зависит не от числа активных задач, а от числа приоритетов. Следовательно, планировщик версии 2.6 является процессом сложности O(1), поскольку время, затрачиваемое на планирование задачи постоянно и детерминистично вне зависимости от числа активных задач.
Итак, что же такое симметричная многопроцессорная обработка? Это архитектура, обеспечивающая одновременное выполнение отдельных задач на нескольких ЦП, в отличие от традиционной асимметричной обработки, при которой все задачи выполняются единственным ЦП. Симметричная многопроцессорная обработка может быть полезной для многопоточных приложений.
Несмотря на то, что предыдущая реализация планировщика имела поддержку многопроцессорных систем, архитектура ее механизма блокировок имела особенность, из-за которой процессорам приходилось ожидать освобождения очереди задач, заблокированной другим процессором на время выбора задачи для выполнения. В планировщике версии 2.6 эта проблема устранена - теперь очереди задач имеют независимую блокировку, что позволяет любому ЦП осуществлять планирование задач, не создавая помех другим процессорам.
Кроме того, наличие у каждого ЦП отдельной очереди в общем случае обеспечивает привязку задачи к процессору, что способствует эффективному использованию его "горячего" кэша.
Еще одним преимуществом планировщика версии 2.6 является поддержка вытеснения. Это означает, что задача с более низким приоритетом не будет выполняться, если другая задача, имеющая более высокий приоритет, будет готова к выполнению. Планировщик вытеснит процесс с низким приоритетом, поместит его обратно в список и повторит планирование.
Помимо реализации алгоритмов сложности O(1) и механизмов вытеснения, в новом планировщике появилась поддержка динамического назначения приоритетов задач и распределения нагрузки между процессорами. Давайте посмотрим, какая, собственно, польза от этих новых возможностей.
Для предотвращения полной загрузки процессора единственной задачей и вызванного этим отсутствия доступа остальных задач к ЦП, планировщик версии 2.6 может динамически изменять приоритет задач. Это достигается путем "штрафования" задач, ограниченных скоростью процессора и "награждению" задач, ограниченных скоростью ввода/вывода. Задачи, ограниченные скоростью ввода/вывода, обычно создают нагрузку на ЦП при подготовке операций ввода/вывода и, затем, ожидают их завершения. Данный тип поведения позволяет другим задачам получить доступ к ЦП.
Поскольку задачи, ограниченные скоростью ввода/вывода считаются нетребовательными к вычислительным ресурсам, их приоритет, в качестве награды, снижается на величину до пяти уровней. Задачи, ограниченные производительностью ЦП, "наказываются" повышением приоритета также на величину до пяти уровней.
Принадлежность задачи к классу ограниченных скоростью ввода/вывода или ограниченных производительностью ЦП определяется с помощью эвристической процедуры вычисления интерактивности . Метрика интерактивности задачи вычисляется путем сравнения времени выполнения задачи и времени, в течение которого задача находится в состоянии ожидания. Следует заметить, что, поскольку задачи, ограниченные скоростью ввода/вывода, планируют операции ввода/вывода и, затем, ожидают их завершения, большую часть времени они проводят в ожидании, что повышает их метрику интерактивности.
Важно заметить, что коррекция приоритета производится только для пользовательских задач - задачи реального времени это не затрагивает.
Задачи, запущенные в SMP-системе, попадают в очередь задач одного из ЦП. В общем случае невозможно предсказать, завершится ли задача почти сразу или будет выполняться в течение длительного времени. Следовательно, первоначальное распределение задач по ЦП скорее всего будет неоптимальным.
Для того чтобы обеспечить сбалансированную загрузку процессоров, необходимо перераспределение задач путем их переноса с перегруженного ЦП на недозагруженный. Планировщик Linux 2.6 делает это путем распределения нагрузки . Каждые 200 миллисекунд планировщик проверяет, сбалансирована ли нагрузка на процессоры. Если нет, производится перенос задач между ними.
Данный процесс имеет негативный аспект, заключающийся в том, что кэш процессора, на который только что была перенесена задача, является для нее " холодным " (требует заполнения данными).
Теперь вспомним, что кэш ЦП представляет собой локальную (находящуюся непосредственно в ЦП) память, обеспечивающую более высокую, чем системная память скорость доступа. Локальный кэш ЦП считается " горячим " если содержит данные задачи, выполняющейся на этом процессоре. Если же таких данных в кэше нет, то для данной задачи он считается " холодным ".
К сожалению, обеспечение полной загрузки ЦП путем переноса задач приводит к возникновению такой неприятной проблемы, как "холодный" кэш.
Исходный код планировщика версии 2.6 компактно размещается в файле /usr/src/linux/kernel/sched.c. Список наиболее интересных функций, находящихся в данном файле, приведен в таблице 1.
Таблица 1. Функции, составляющие код планировщика версии 2.6
Кроме того, в файле /usr/src/linux/kernel/sched.c можно найти структуру очереди задач. Новый планировщик также имеет функцию сбора статистики, которую можно активировать с помощью параметра конфигурации ядра CONFIG_SCHEDSTATS . Собранная статистика может быть получена из файла /proc/schedstat, находящегося в файловой системе /proc, и содержит различные сведения по каждому ЦП системы, включая статистику распределения нагрузки и переноса задач.
Планировщик версии 2.6 значительно продвинулся в развитии по сравнению со своими предшественниками. Были сделаны огромные шаги в области повышения загруженности ЦП при одновременном снижении времени отклика. Поддержка механизма вытеснения и улучшенная поддержка многопроцессорных архитектур приближают к реальности идею операционной системы, одинаково эффективной на рабочих станциях и системах реального времени. Ядро Linux 2.8 появится еще нескоро, но, судя по изменениям в версии 2.6, впереди нас ждет много интересного.
В статье Планировщики ввода/вывода Linux были рассмотрены планировщики I/O. Еще одной из важных задач по обеспечению нормальной работы любого сервиса, помимо доступа к дисковым устройствам является доступ к процессору. За распределение процессорного времени между работающими приложениями занимаются другие планировщики.
На первый взгляд это простая задача, но если учесть что на современных компьютерах может выполняться сотни, а то и тысячи процессов, то неправильная его реализация может уменьшить общую производительность системы, так как даже на переключение контекста приложения процесса тратится драгоценное и при чем относительно не малое время. Планировщик сталкивется с такими противоречивыми задачами как ограниченное время ответа для критических задач, при увеличении количества процессов борющихся за CPU.
Алгоритм работы O(1) очень прост. Каждая задача имела фиксированное число (tick), которое пересчитывается с каждым системным тиком (по умолчанию 100 Hz), при выходе из режима ядра или при появлении более приоритетной задачи. Алгоритм просто делит число на два и добавляет базовую величину (по умолчанию 15, с учетом величины nice ). Когда тик становится равным 0, он пересчитывается. Кроме этого каждый процессор имеет две очереди. В одной находятся готовые к запуску задачи, во вторую помещаются отработавшие и спящие задачи, которые например, ожидают не доступного в настоящее время ресурса. Когда первая очередь пустеет, очереди меняются местами. Поэтому время работы алгоритма постоянно и не зависит от количества процессов. Современная реализация O(1) используют уже более сложные алгоритмы, анализируя среднее время сна процесса, чтобы обнаружить интерактивные задачи ожидающие ответа пользователя и стараясь задержать их подольше в активном дереве.
В ядро 2.6.23 после трех месяцев обкатки в экспериментальной -mm ветке ядра, был включен в качестве основного планировщик CFS (Completely Fair Scheduler, абсолютно справедливый планировщик). Алгоритм которого полностью пересмотрен и весьма сложен. В отличие от O(1) CFS равномернее распределяет процессорное время (фактически если задачи две, то каждая получит ровно 50% CPU), распределяет задачи по нескольким ядрам и имеет меньшее время отклика. Для настройки CFS используется файл /proc/sys/kernel/sched_granularity_ns , в котором по умолчанию установлен режим desktop (меньшее время задержки), но при необходимости его можно переключить в server .
$ cat server > /proc/sys/kernel/sched_granularity_ns
За последние 2,5 года было предложено около 300 алгоритмов, так что вряд ли здесь будет спокойно в ближайшее время.
Проект DeskOpt
$ cd deskopt-006-rc1
$ cp deskopt /usr/local/bin/
$ sudo mkdir /etc/deskopt/
$ sudo cp deskopt.conf /etc/deskopt/
$ sudo cp deskopt.rc /etc/init.d/
К онфигурационный файл имеет простой XML формат, в нем уже есть готовые настройки. В простейшем случае команда выглядит так:
$ sudo deskopt -c /etc/deskopt/deskopt.conf
2 комментария
Все эти планировщики хороши и разработчикам респект. Но! Применительно к реальной жизни. На сегодня рассматривать можно а) серверы баз данных; б) серверы приложений; в) рабочие станции. Кто бы мог предложить обзор производительности наиболее популярных планировщиков в этих задачах? Уже очень очевидно, что универсального планировщика не создать и потому интересует именно сравнение их между собою с целью выбора оптимального для той или иной задачи. Спасибо.
Читайте также: