Снижение пропускной способности существенно влияет на объем памяти fifo в mac средстве станции
Обновлено: 08.07.2024
Устройства имеют независимые порты записи и чтения, поддерживающие работу на частоте до 133 МГц. Пользователь может конфигурировать ширину шин ввода и вывода. Максимальная ширина шины, равная 36 битам, обеспечивает максимальный поток данных до 4.8 Гбит/с. Порты записи и чтения поддерживают различные стандарты напряжений питания линий ввода/вывода. Конфигурируемые пользователем регистры обеспечивают работу устройства в соответствии необходимым требованиям приложения. Простой и легкий в использовании интерфейс позволяет ускорить разработку и отладку решения, а также уменьшить время вывода на рынок готового продукта и расходы на проектирование.
Микросхемы FIFO памяти серии CYFxxV идеально подходят для широкого круга применений, включая мультипроцессорные интерфейсы, обработка видео и изображений, сетевое и телекоммуникационное оборудование, высокоскоростные системы сбора данных и любые другие системы, где необходима буферизация высокоскоростных потоков данных между несколькими доменами.
Отличительные особенности:
- Объем памяти: 18/36/72 Мбит
- Организация памяти, программируемая пользователем: × 9, × 12, × 16, × 18, × 20, × 24, × 32, × 36 бит
- Рабочая частота: до 133 МГц (CYF0xV), до 100 МГц (CYF1xV/CYF2xV)
- Пропускная способность: до 4.8 Гбит/с (CYF0xV), до 3.6 Гбит/с (CYF1xV/CYF2xV)
- Независимые порты записи и чтения
- Одновременная поддержка операций записи и чтения
- Поддержка различных стандартов напряжения питания линий ввода/вывода: 3.3 В и 1.8 В
- Поддержка одной очереди (CYF0xV)
- Поддержка до 2 очередей (CYF1xV)
- Поддержка до 8 очередей (CYF2xV)
![]()
Документация на CYF0018V, CYF0036V, CYF0072V (англ.)
![]()
Документация на CYF1018V, CYF1036V, CYF1072V (англ.)
![]()
Документация на CYF2018V, CYF2036V, CYF2072V (англ.)
![]()
бу де т рассматривать ся ЛВС Ethernet стандарта 1 980 года вып уска .
Архитект у ра локальных вычислит ельных си стем ( ЛВС ) основа на на со зданной в
результа те международного сотр удничества много уровневой эталонной модели ( ЭМ ), на
каждом у ровне которой выделены определяющие фу нкции взаимо действия объектов . Под
объектами понимаются обору дование или программы систем , вк лючаемых в сост ав ЛВ С .
Такой подход позволяет создавать ЛВС ка к многомодульну ю стр у кт уру , где изменение
или опт имиз ация схемотехн ических , решений моду ля с целью ул уч ше н и я его технико -
эксплу атационны х показа телей не влечет за собой переделки друг их мод у лей , входящих в
Термин Ethernet обозначает как готовое изделие , так и реализованный в нем метод .
Изделие предст авляет собой локальную сеть , поставляемую фирмой Xerox . Фирмы Xerox
Digital Equipment и In t e l имеют и продают лиц ензию на метод переда чи данны х ,
использу емый в этой сети . Целью этой лицензионной процеду ры является сопряжение
разнообразного обору дования с любой сетью , использу ющие метод Ethernet в том виде , в
![]()
котором он определен фирмой Xerox и дру гими участн иками консорциума ми . Это
подру зумевает не только стандартный мето д доступа , но и схем у прис вое ния адресов , так
что любое устройство для Ethernet, где бы оно не было изготов лено , может
использова ться в любой сети Ethernet, имея у ника льный адрес . Ниже дается краткое
Топология : древовидна я , составленная из отдельны х шинных сегментов . Между любыми
двумя ус тройствами можно у становить не более дву х повторителей . Это несколько
ограничива ет топологию сети , и самым лу чшим решением оказывается магистральная
шина , к которой подсоединены все прочие шинные сегменты .
Передающая среда : коксильный кабель , сопротивлен ие которого равно 50 Ом . Каждый
сегмент должен с обоих концов иметь согласу ющую нагрузку 50 Ом . Чтобы облегчить
подключение к кабелю , его следует поделить метками на участк и 2,5 м длиной , поскол ьку
соед инители о пределенного типа , бу ду ч и поме щены в местах , расст ояния межд у
которыми не кратны указанной длине , могу т неблагоприятно повлиять на электрически е
Метод передачи сигнала : немодулирова нный сигнал , по следовательная побитовая
Метод доступа : множественн ый доступ с контролем нес у щей и обнару жением
Кадр : переменна я длина ( от 72 до 1 526 байт ). Особое поле (" преамбула ") указыв ает на
К сожале нию в данном реферате невозмож но подробно рассмотреть все хар акт ер ист ики
ЛВС Ethernet, однако некоторые бу ду т рассмотрены достаточно детально .
Как говорилось выше , в сети данного вида применяется множественный дост у п с
контролем несущей и обнару жение м конфликтов (CSMA/CD). Это объясняется
эффектив ностью обна ру жения и устранени я конфликтов и простото й схемных решений
нижнего по ду ровня канального у ровня ( так называемого MAC- ур о в н я - Medium Access
Control), а также возможностью высоко й загру зки моноканала и большой нагру з ки ЛВС .
Верхний поду ров ень канального протокола наз ывается LLC- ур о ве н ь (L ogic al L ink
![]()
Функции MAC- у ровня определены группой стандартов IEEE802.3, I EEE802.4, IEEE802.5
и EEE802.6. Согласно этим стандартам второй подуровень формируе т полную стр у кт уру
кадра и передает этот кадр с помощью средств протокола физического ур о в н я ЭМ . При
этом второй подуровень у правляет просл у шиванием монокана ла , обнару живанием
конфликтов и восстан овлением передачи после ликвидации конфликтов . В ЛВС Ethernet
применены два критерия о п ределения конфл икта : минимальная пауза между кадрам и и
Принц ип метода CSMA/CD заключает ся в следующем . Если какое - то устройство нач инает
передав ать пакет , сигнал , вос принимае мым веду щим в настоящий момент переда чу
устройством , не бу де т соо тветс вовать передаваемой информации . Устройства бу дут
принима ть неразборчиву ю смесь сигналов . Когда кажды й отправитель замечает , что его
пакет конф ликту ет с дру гим па кетом , то он сразу же прекращ ает передачу , чтобы не
тратить бесполезно время си гнала . Так как " окно конфл иктов " ( время , треб у ющие ся на
распростран ение сигн ала по всем участкам сети ) мало , то потерянное время оказывает ся
небольшим по сравнению с длительностью переда чи типичного паке та . Раз личают
след у ю щие протоколы доступа : нена стойчивы е , настойчивые , прогнозир у емые ,
сег ментиру е мые , приоритетные , бесприоритетные , резервиру емые . Та кое обилие
протоколов объясняется прежде всего стремлен ием различных фирм обеспечить
максимальн ую эффективнос ть исполь зования ми кроэлектронны х средств дост упа к
монокана лу за счет более уз к о й специализаци и сх ем и их ориентацию на конкретну ю
технологию производства блоков досту п а . Ненастойчивые мет оды CSMA/CD удлиняют
кажды й раз после конфлик та пау з у ожидания перед повторной попыт кой пере дать кадр .
Удлинение происходит на опр едел ен ную дет ерминированну ю велич ину , определяем у ю
счетчик ом числа конфликтов . Настойчивые методы CSMA/CD у длиняют паузу
ожидания на случайн ую величин у , вырабатыв аемую датчиком сл учайных чисел . Диап азон
чисел определяется ди апазоном станций , подключ аен ных к монока налу ЛВС .
Прогнозирующ ие метод ы CSMA/CD определяют пау з у ожидания в зависи мости от
предыстории интенсив нос ти передач кадров в монока нале . Специа льный счетчик
регистрирует за определенный интерв ал времени , задаваемый таймером ста нции , число
кадров , прошедших мимо данного MAC- уровня . На основании пока заний этого счетчик а
у станавлив ают пау з у ожидания перед передачей кадра и определяют у ровень активности
данной станции в зависимости от уровня активности дру гих ст анций , подключенных к
монокана лу . Д анный метод имеет пр еимущества в случае применения в ЛВ С с большим
числом станций , имеющих различны й уровень активности . Тако й режим отличается
существен но несбаланси рованным трафиком и осложняет безошибочную работу
монокана ла . Небольшое общее с нижение пропус кной способности ко мпенсир у ется
существен ным снижение м числа конфликтов . Недостаток этого метода зак лючается в
повышенной сложности анализ атора , который не тол ько сл у шает моноканал даже ес ли в
памяти FI FO МАС - средст ва нет информаци и готовой к передаче , но и определяет число
кадров и конфликтов в единицу времен и . Др угой существенны й недостаток заключается в
том , что снижение пропу скной способности существенн о влияет на объем памяти FI FO в
МАС - средстве станции . Поэтому иногда метод прогнозирующего CSMA /CD
комбиниру ют с методо м настойчивого CSMA/CD с помощью введени я в МАС - средство
специального переключат еля режима . Этот переключат ель в случае переполнения FIF O в
МАС - средство осущ ес тв ляет переход на алгоритм , реализу ющий настой чивый метод
CSMA/CD, на этап прослушивания монокана ла . Такой подход эффективен при
применени и длинны х кадров и ограниче нном объеме па мяти FI FO. Сегмент ируемые
методы CSMA/CD преду сматрив ают де ление времени , в течении которого м оноканал
свободен , на сегмент ы . Сегме нтирование приме няют в случае , если не обходимо повы сить
у стойчивость синхро низаци и взаимоде йствия процессов . Использование этих сегментов
осуществляется сред ствами MAC- ур овн я различными способами , среди которых наиболее
распростран енными являются способы определения преимущества при использовании
свободного сегмента . Из них можн о выделить два способа : безусловного и условного
выделе ния сегмента вре мени . Безусловное сегментирова ние заклю чается в выделении
групп средств MAC- у ровней (MAC- средст в ) с одинаковыми приори тетами . Имеется
столько сегментов , сколько выделено приоритетных гру п п . Если MAC- средства ,
относящиеся к первой группе , им еют кадры в очереди памяти FIF O, а другие MAC-
средства , относящиеся к более высок ой приоритетной гру ппе , таковых кадров не имеют ,
то MAC- средства первой группы пос ылают заявочный кадр и информиру ют о жела нии
захв ати ть моно канал , MAC- средства из групп с более низким пр иоритетом в ответ на это
задерживают свои передачи . Конфликт возможен с MAC- средствами более высокими или
равными приоритетами . Если все сегменты пус тые , то любые MAC- средства мог ут
передать свой кадр . Условное сегментирование определяет правила назна чения сегмента
времени , после того как произошел конфл икт . Считает ся , что вероятность возникнов ения
конфликта между одними и теми же ис точникам и несколько раз очень мала . Поэтому
MAC- средства , имеющие подготовленный ка др , начина ют пере дачу в свободный
монокана л в интерв ал времени свободного сегмента . Если происх одит конфликт , то при
повторной попытке предпочте ние отдается MAC- средствам , вступив шим в
конфликт . Условное сег ментирова ние имеет пр еимущества перед безусловным только в
том случае , если число конфликту ющих пар нев елико . После конфл икта ко нфликту ющим
станциям выделяется дополнительный сегмен т , в тече ние которого они выдержат пау з у и
передадут свою информацию . Поскольку в конфликте участв уют две станции
( вероятность конфликта межд у нескольк ими станц иями очень мала ), то деление
сегментов , выделенных в их распоряжение , производится между ним и в заранее
у становленном порядке . Для сети Ethernet, как имеющу ю шинн у ю топологию , в
распоряжение дву х станций , предоставляется двойной сегмент времен и , и любая из них в
режиме конку ренции может , выдержав пау з у захв атить сегмент . Оста ток остается др угой
станции . В ыделе ние сегментов времен и для каждого МАС - средства происходит с
помощью вну тренних таймеров , входящих обычно в комплект ми кроЭВМ станц ии .
Таймер у стана вливае т интерва л времени работы МАС - средст ва . Причем этот интервал
может произвольно менятся по какому - либо алгоритм у . Приорите тные метод ы
CSMA/CD реализ уют приритет того или иного MAC- средства в виде времени , в течении
котоорого данное МАС - средство может испльзовать м онока нал . Чем выше приоритет , те м
большее время может занимать м оноканал МАС - средство . Др у гим выражение м
приоритетности является прерыв ания кадра более приорите тным у стройством . Здесь в
каждом ка дре должен имется спе циальный пр изнак возможност и прерыва ния со стороны
более приоритетного ус тройства . Элемент ы бесприори тетных методов CSMA/CD
прису т ствуют во многих рассмотрен ных выше методах , наприме р в нена стойчив ых ,
настойчи вых , прогнозиру ющих . Наи более часто бесприоритетные методы CSMA/CD
обеспечиваю т динамиче ское распределени е пропускной способности мо ноканала с
помощью сегме нтирования и присваив ания сегментов времени в порядке очередности
всем МАС - средств ам станций ЛВС . Резе рвируемые методы CSMA/CD
преду сматрив ают пере дачу кадра только после полного захв ата свободного моноканала .
После этого передается специальный коро ткий кадр , резервиру ющий моноканал для
передач и кадра . Убедившись в том , что др угие с танции воспринимают его как должное и
не переда ют свои резервирующие ка дры , МАС - средство начинает пе редачу ка дра . Этот
агоритм может выполнятся эффективно только в том случае , если допу скается снижение
загру зки моноканала и на первое место выдви гается требован ие повышения на дежности
работы канала передач и данных . Кроме того , здесь действует ограниче ние активн ости
станций ЛВС . Так при у величе нии длины кадра до 1 500 байт , уменьшени и чи сла
акти вных станци й до 64 и скорости переда чи кадров до 1 Мбит / с можно достичь заг ру зки
монокана ла порядка 1 8%. Фактически дейс твенност ь этого метода по загру зке монока нала
приб лижается к методам CSMA. Работа этого метода регламент ируется ст андартом
Обычно каждый блок досту па , реализ у ю щий метод CSMA/CD, должен работать в дву х
типовых режимах : нормальном и конфликтном . В первом режиме блок доступа передае т и
принима ет информа цию в темпе , определяемой пропускной способностью ЛВ С и
временем синхронизаци и сигналов в ман честерском коде . Во втором режиме в
монокана ле возникаю т конфл икты , которые должны обнару живаться и устранят ся
аппара тными МАС - средствами . . Блок дост упа , реализующий алгоритм нена стойчивого
метода дост у п а CSMA/CD выполняет следующие функции : об нару жение конфли ктов в
монокана ле с помощью выносной сх ем ы , вх одящей в состав приемника , ответвителя или
декодера ; блокировку своего передатчика при обнару жении конфликта ; фиксирование
заранее заданной прогрессирующей задержки повторной по пытки пе редачи своей
информации после обнару жения конфлик та ; разъединени е прие мник и пе редатчика .
Такой разрыв необходим только в сетях с кольцев ым монока налом .
Таким образом мы видим , что повышение эффект ивности пау з ожидания перед
повторными попыткам и пере дать кадр , а та кже сниже ние времени реакци и на конф ликт и
повышение общей пропускной способности позволяют подключа ть до 1 000 станци й и
передав ать сотни кадров в сек унду . Необходимо заметить , что метод CSMA/CD
использу ется не только в сети Ethernet, а также в ряде других сетей , таких ка к Omninet,
GlusterBus, Hyperchannel и других . Метод настойчи вого CSMA/CD более пре дпочтителе н ,
чем метод не настойчив ого CSMA/CD. Это объясняется те м , что датчик случайных чисел ,
определяющий значени е пау зы ожидания , лу чше защищает от повторного ко нфликта ,
нежели простое у величение задержки , прим еняемого в методе не настойчиво го CSMA/CD.
Случ айность обращения здесь хорошо у вязывается со случай ной природой пау зы
ожидания , в резу льтате чего вероятность конфликта снижается .
Как уж е у поминалось ранее стандартный кадр Ethernet может содержат ь от 72 до 1 526
байт . Здесь бу де т рассмотрено назна чение полей кадра более детально .
Кадр начинает ся с преамб у лы - специального кода на чала ка дра . Преамбула может
содержать информация кадров по мо ноканалу . Зате м иду т адреса получа теля и
отправителя . В поле у пр авления размещается код типа кадра . Далее расположен блок
данных . Завершает кадр проверочная последовательност ь , уста навлива ющая иска жен ка др
Характерной особенностью памяти FIFO по сравнению с обычной памятью RAM или ROM является отсутствие адресных линий. Базовая архитектура FIFO представлена в виде массива (RAM ARRAY) с перемещаемыми при считывании и записи указателями начала (READ POINTER) и конца (WRITE POINTER) свободного пространства памяти (рис. 1). Преимуществом такого способа организации памяти является выводная совместимость микросхем FIFO, имеющих разную информационную емкость.
Другим отличительным свойством памяти FIFO является наличие отдельного порта для чтения и отдельного — для записи данных. Благодаря наличию указателей и двухпортовой структуре памяти FIFO, стробы считывания и записи данных могут поступать на одноименные входы микросхемы в произвольном порядке. И если в памяти RAM операции чтения и записи данных выполняются строго последовательно во времени, то в памяти FIFO допускается выполнение записи и считывания в независимых друг от друга асинхронных режимах.
Недостатком FIFO является то, что содержимое уже прочитанной ячейки памяти может быть автоматически замещено новым значением, тогда как в RAM или ROM содержимое ячеек может быть изменено только путем непосредственной адресации и записи в них новых значений. Для предотвращения непредусмотренной потери данных в состав микросхем памяти FIFO введены флаги заполненности. В процессе функционирования память FIFO может находиться в одном из следующих возможных состояний: «нормальная работа», «буфер пуст», «буфер почти пуст», «буфер заполнен на 1/2 от максимального размера пространства памяти», «буфер почти полон», «буфер полон». Флаги заполненности являются индикаторами этих состояний и позволяют внешним устройствам осуществлять гибкий контроль над потоками считываемых или записываемых данных. С целью обеспечения помехоустойчивой передачи данных в канале связи, в состав большинства современных микросхем памяти FIFO добавлена функция повторного считывания данных из буфера, начиная с первого слова. Расширением этой функции является возможность повторного считывания произвольного сегмента памяти путем пользовательской установки указателя начала записи.
Общими характеристиками памяти FIFO, RAM и ROM, принимаемыми в расчет на этапе проектирования, остаются быстродействие, разрядность слова и информационная емкость. Быстродействие характеризуют временем цикла считывания или записи, разрядность определяют числом бит в слове чтения или записи, информационную емкость характеризуют числом единиц информации в битах или словах, которое микросхема памяти может хранить одновременно.
2. Классификация памяти FIFO производства IDT Inc.
Все устройства FIFO можно подразделить на классы, определяемые по способу воздействия входных управляющих сигналов (асинхронная и синхронная память) и по способу управления передачей данных (однонаправленная и двунаправленная память). В качестве подкласса асинхронной памяти можно выделить микросхемы Serial-to-Parallel FIFOs (последовательная запись/параллельное считывание) и Parallel-to-Serial FIFOs (параллельная запись/последовательное считывание). В микросхему Parallel-to-Serial FIFO данные записываются всеми разрядами одновременно, а считываются с одного выхода последовательно во времени. По аналогии осуществляется обращение к данным в микросхеме Serial-to-Parallel FIFO. Классификацию устройств памяти FIFO, производимых корпорацией IDT, можно представить в следующем виде:
Асинхронная память
- семейство Asynchronous x9 и Asynchronous Dual x9256…64Kx9;
- семейство Specialty FIFOs
Parallel-to-Serial FIFOs 256…1Kx16, 1K…4Kx9
Serial-to-Parallel FIFOs 2K…4Kx9
Синхронная память
-
семейство Super Sync II (133 МГц)
Двунаправленная память
-
семейство Bi-directional Asynchronous FIFOs x18
3. Принцип работы асинхронной памяти FIFO
Рис. 4. Временные диаграммы переключения флагов заполненности4. Принцип работы синхронной памяти FIFO
5. Наращивание разрядности и информационной емкости FIFO
В процессе проектирования новых устройств нередко возникает задача объединения микросхем памяти FIFO в один модуль. Наращивание разрядности достигается путем соединения всех одноименных входов микросхем, кроме информационных. Для контроля за потоками данных могут использоваться флаги заполненности одной из микросхем в модуле. Способ решения этой задачи иллюстрирует рис. 9, на котором показан блок FIFO емкостью 512 слов и разрядностью слова 18 бит, построенный на микросхемах IDT7201. Каждая микросхема имеет организацию 512ґ9 бит.
6. Рекомендации по применению памяти FIFO
Основными областями применения памяти FIFO являются устройства с последовательными потоками параллельных данных (например, цифровая видеокамера, сетевой концентратор и др.). В их составе память FIFO может применяться в качестве буфера для приема, накопления и выдачи по запросу накопленных данных. Наличие такого буфера позволяет высвободить ресурсы процессора от постоянного сканирования магистрали при приеме медленных асинхронных потоков данных. Процессор в этом случае можно будет подключать к буферу FIFO только для выгрузки накопленных данных, пользуясь информацией о состоянии флагов заполненности.
Другим примером применения памяти FIFO является преобразование скорости передачи данных в процессе взаимодействия двух асинхронных устройств с разной пропускной способностью. Для организации непрерывного обмена потоками данных преобразованию подлежит также разрядность входной и выходной шины данных.
В случае применения RAM для решения аналогичных задач требуется наличие дополнительной схемы управления, представляющей собой контроллер прямого доступа к памяти. Это связано с необходимостью формирования адресов ячеек в процессе выполнения операций записи и чтения. Преимущество в применении памяти FIFO состоит в естественном порядке прохождения данных (первым поступил — первым выводится) и в отсутствии внешней схемы для формирования адресов ячеек.В качестве реальных примеров применения памяти FIFO можно привести следующие: устройство цифровой обработки и вывода на монитор сигналов, поступающих от рентгеновской установки; устройство сопряжения мультипроцессорного модуля на базе DSP с PCI-шиной; кодек MPEG для телевидения высокой четкости.
В первом случае микросхемы «IDT72V21105, 256Kx18 FIFO» применяются для согласования скорости передачи данных между тремя асинхронными устройствами: источником цифрового рентгеновского сигнала, модулем цифровой обработки данных на базе нескольких DSP- процессоров и видеоконтрольного устройства. Для обеспечения требуемой ширины пакета передаваемых данных микросхемы FIFO включены в режиме наращивания информационной емкости и образуют модуль памяти с организацией 1,5Mґ18.
Во втором случае две однонаправленные микросхемы «IDT72V36110, 128Kx36 FIFO» используются для организации двунаправленного обмена данными между 32-разрядным PCI-интерфейсом с тактовой частотой 33 МГц и модулем, состоящим из двух DSP-процессоров с пропускной способностью шины данных 66 МГц и разрядностью 16 бит. Для поддержания обмена данными между 32-разрядной и 16-разрядной шинами используется дополнительная функция BUS MATCHING.
В кодеке MPEG-2 для телевидения высокой четкости удачным решением является использование памяти FIFO и, в частности, «IDT72V2113, 512Kx9». Стандарт MPEG-2 предусматривает возможность гибкого изменения скорости передачи видеоданных в очень широких пределах, а также работы как с чересстрочной, так и с прогрессивной развертками при частоте полей 50 или 60 Гц.Итак, микросхемы памяти FIFO можно рекомендовать к применению:
Если с годами скорость работы вашего устройства Mac снизилась, возможно, настало время немного позаботиться о нем. Чтобы повысить быстродействие iMac или MacBook, не нужны огромные затраты. Мы составили список того, что вы можете сделать, чтобы повысить скорость работы устройства Mac без необходимости замены.
Закройте программы с высоким энергопотреблением
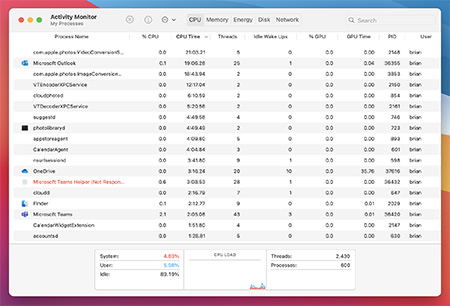
![Mac Activity Monitor]()
Одна из простейших вещей, которые вы можете предпринять для повышения производительности устройства iMac или MacBook, — закрыть все приложения и программы, которые вы не используете. Mac может выделять память и мощность процессора для программ, которые вы не используете активно. Это позволит освободить место и снизить нагрузку от ненужных программ, которые снижают производительность.
Также есть утилита Activity Monitor (Монитор активности), которая показывает все процессы, выполняемые на устройстве Mac. Чтобы открыть Activity Monitor, перейдите в меню System Preferences (Системные настройки) > Utilities (Утилиты) или выполните поиск, нажав Command + пробел. Некоторые приложения и программы потребляют значительно больше мощности и ресурсов, чем другие. Activity Monitor показывает данные по уровням потребления ЦП, ОЗУ, энергии, дисковой памяти и сети для каждой открытой программы.
Выберите вкладку CPU, чтобы просмотреть сведения об использовании ресурсов процессора каждым приложением или программой. Закройте неиспользуемые приложения и программы, особенно если они используют много ресурсов процессора. Activity Monitor — полезный инструмент для проверки уровня потребления системных ресурсов вашими приложениями и программами.
Очистите список автоматического запуска
Виновниками медленной работы могут быть те назойливые приложения и программы, которые запускаются каждый раз при включении вашей системы. Откройте System Preferences (Системные настройки) и выберите Users & Groups (Пользователи и группы). В этом разделе откройте вкладку Login Items (Объекты входа), чтобы просмотреть приложения и программы, которые запускаются при включении iMac или MacBook. Выберите программу, которую не следует запускать при включении системы, и щелкните значок «-» внизу списка, чтобы удалить ее.
Синхронизация с iCloud
Синхронизация файлов и фотографий с iCloud на нескольких настольных системах и устройствах также может замедлить работу Mac. При использовании iCloud старайтесь не хранить большие файлы и документы в вашей настольной системе. Храните только необходимые документы и файлы, которые помогут ускорить вашу работу и тратить меньше времени на ожидание синхронизации всех ваших файлов.
Это относится и к синхронизации фотографий в iCloud. Если устройство Mac тратит слишком много времени на синхронизацию всех фотографий со всеми вашими устройствами, вы всегда можете отключить iCloud Photos на своем устройстве Mac, чтобы снизить нагрузку на него и повысить производительность.
Освободите место в хранилище
Неудивительно, что ваш Mac работает слишком медленно, когда хранилище почти заполнено. Фотографии, видео и музыкальные треки — это самые крупные файлы, которые занимают много места на диске.
Многие думают, что покупка iCloud поможет решить проблему нехватки места для хранения, но это не так. Если вы удалите файлы с вашего устройства Mac после резервного копирования в iCloud, они будут удалены со всех ваших устройств. Если у вас уже есть iCloud, и выполнена синхронизация на всех ваших устройствах, вероятно, многие файлы и документы находятся на вашем устройстве Mac и занимают место на диске. Например, фотографии, сделанные с помощью iPhone и синхронизированные в iCloud, будут храниться на вашем Mac, занимая место на диске.
Возможно, будет лучше выключить синхронизацию фотографий iCloud на устройстве Mac. Существуют и другие службы, которые вы можете использовать для резервного копирования файлов и документов в облаке, чтобы можно было удалить их с вашего компьютера. Такие службы, как DropBox и Google Drive, позволяют точно так же создавать резервные копии ваших файлов, например фотографий, в облаке без необходимости хранить их на устройстве Mac, чтобы обеспечить к ним доступ.
Загруженные музыкальные треки также могут занимать много места на вашем устройстве Mac. Можно сэкономить место на диске, выгрузив музыкальные файлы на внешний жесткий диск, чтобы освободить место на вашем компьютере. Вы также можете приобрести потоковые сервисы, такие как Apple Music, у которых есть функция, позволяющая переместить всю вашу коллекцию музыкальных треков в облако. Тогда вы сможете удалить их со своего Mac и получать к ним доступ с любого из ваших устройств. Кроме того, вы сможете воспользоваться преимуществами потокового сервиса Apple Music для прослушивания любой песни или исполнителя без необходимости загружать треки на свой Mac, если у вас есть доступ к каналу передачи данных или Wi-Fi.
Удалите старые и неиспользуемые файлы, очистите корзину
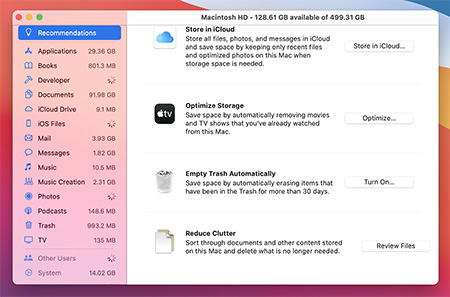
![MacOS Big Sir Recommendations]()
Быстрый и простой способ освободить место на диске, чтобы повысить скорость работы вашего устройства Mac, — это удалить старые и неиспользуемые файлы и очистить корзину. Рекомендуется периодически проверять устройство Mac на наличие старых и неиспользуемых файлов и документов. Локальное хранение неиспользуемых файлов просто занимает место на диске и снижает производительность устройства Mac.
Не забывайте удалять элементы из папки Загрузки. Откройте программу Finder и перейдите к папке Загрузки, чтобы переместить элементы в корзину. О папке Загрузки часто забывают, и в ней остается множество документов и файлов.
Сохраните старые файлы и документы на внешний жесткий диск и удалите их с устройства Mac. Если они вам больше не нужны, вы всегда можете удалить их с вашего компьютера. Не забудьте очистить корзину после удаления. В ином случае удаленные файлы и документы по-прежнему будут занимать место на диске (в корзине).
Вы можете настроить системные параметры на регулярную очистку корзины, что избавит вас от необходимости выполнять это вручную. Щелкните логотип Apple в строке меню, выберите About This Mac (Информация о системе), щелкните Storage (Хранилище), а затем Manage (Управление). На открывшемся экране можно настроить автоматическую очистку корзины каждые 30 дней.
Уменьшите качество или отключите графику
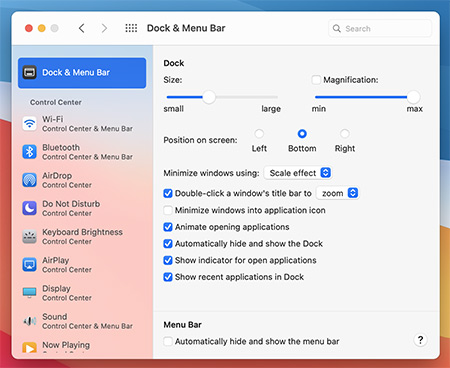
![MacOS Big Sir Dock & Menu Var]()
Обычно MacOS работает на компьютерах Apple без проблем, но иногда нагрузка может быть слишком высокой для поддержания должной производительности. Снижение качества или выключение графики поможет ускорить работу Mac.
Некоторые пользователи предпочитают выключать панель Dock, чтобы не допустить снижения быстродействия системы. Для этого откройте System Preferences (Системные настройки), выберите Dock и снимите галочки рядом со следующими параметрами:
- Magnification (Увеличение)
- Animate opening application (Анимировать открывающиеся программы)
- Automatically hide and show the dock (Автоматически показывать или скрывать Dock)
Также можно выбрать параметр "Minimize windows using" (Убирать в Dock с эффектом) и изменить его значение с Genie Effect (Джинн) на Scale Effect (Простое уменьшение).
Последний вариант
Если ничто не помогает, вы можете попробовать полностью перезагрузить Mac и выполнить установку чистой ОС. Это следует рассматривать в крайнем случае, поскольку вам потребуется полностью удалить весь загрузочный диск. При этом будут удалены все файлы в вашей системе и пользовательских библиотеках, которые, возможно, собирались не один год.
Мы рекомендуем выполнить резервное копирование всех важных файлов, документов, изображений, музыки и всего прочего, что может вам понадобиться после установки ОС. В конце концов, если ситуация становится все хуже, и быстродействие вашего Mac не повышается, возможно, пришло время найти ему замену.
Читайте также: