
Stegsolve linux как установить
Обновлено: 07.07.2024
Недавно образовалась команда новичков по ctf нашего любимого форума, в связи с этим своей статьей хотел бы начать обмен опытом, так сказать, по решению тасков той или иной направленности. Ведь всегда есть некий алгоритм, которому вы следуете при решении тасков, который приводит, на легком и среднем уровне, к найденному флагу. Это тот уровень, который находится между «пфф, изипизи» и тем, когда вы начинаете видеть заговоры иллюминатов во всех хинтах и файлах.
И так, я попробую рассказать вам основы стеганографии. Точнее сказать, основы в моем представлении. Приятного чтения
1. Область применения
Что такое стеганография рассказывать не буду, дабы не захламлять статью. Просто поясню, что это метод сокрытия информации в объектах(картинка, музыка, видео, кожа головыJ(это не шутка) и т.д.) в которых непосвященный человек не сможет разглядеть ничего подозрительного.
В ctf чаще всего встречается стего в следующих типах файлов:
----> Картинки – bmp, png, jpg, tiff, gif
----> Звуковые файлы – wav, mp3, midi
----> Видео файлы – mp4, avi
И для каждой области файлов свои инструменты обнаружения стего.
2. Инструменты
Ниже будут приведены тулзы для определения стеганографии разделенные по операционным системам. Я их выделил две: Linux и Windows.
Думаю этого пока будет достаточно что бы решить практически любой таск по стего легкого и среднего уровня.
Звуковые файлы:
Со звуковыми файлами нет необходимости разделения по операционным система т.к. софт и там и там одинаков. За исключения основных утилит: file, strings exiftool и их аналогов в Windows, которые я описал выше.
Видео файлы:
----> ffmpeg - набор свободных библиотек с открытым исходным кодом, которые позволяют записывать, конвертировать и передавать цифровые аудио- и видеозаписи в различных форматах
Я извинтиляюсь за такой скудный набор тулз для стего видео файлов, но это связано с моим скудным опытов в ctf. И все задачи которые я решал по стего, которые были связаны с видео файлами, сходились к тому, что бы разбить видео ряд на кадры и уже с ними продолжать работу.
Что же, инструменты даны. Теперь я бы хотел показать вам как я с этими инструментами работа при решении тасков.
Картинки:
Windows:
----> PentestBox
Первым делом качаем PentestBox. Он нам необходим для возможности использовать утилиты Linux (file, strings, grep).
После установки и запуская вы должны будете увидеть консольку, в которой можно использовать некоторые unix команды.
----> Утилита file
Вот смотрите, допустим у нас есть файл steg.txt
и вы только посмотрите какой хитрец подлец. Оказывается это bmp файл. Картинка.
----> Утилита strings
Далее, снова имеем в наличии файл steg.bmp. Давайте попробуем использовать утилиту strings. Мы там увидим много чего(неполезного), а вот что бы увидеть полезное давайте немного подружим strings с grep и вот что мы получим:
«Изипизи» как говорится. Ессесно слово flag замените на любое другое по которому вы его будете искать.
Этот метод, кстати, будет бесполезен если вы получите данные картинки, в виде одной строки. Например после манипуляций с python. Т.к. утилита strings, как следует из названия, читает файл по строкам. Ну вы понимаете конечно, что если искать вхождение какой нибудь подстроки в большой строке, то тут можно получить только один тип информации. А именно есть эта подстрока в этой строке или нет.
----> Stegsolve
ООооочень полезная утилите для стего. Качаем прогу тут. Это исполняем jar файл, по этому для запуска необходим предустановленный jdk или jre.
И так программа имеет следующий интерфейс
Ну и самое главное, это начальный экран программы, который позволяет просматривать картинку по слоям, оставляя только сини пикси или зеленые, или только первые биты красного цвета и многое другое.
Вывод прост – очень полезная программа, которая достойна быть в арсенале любого, кто решать стего таски.
Linux:
За исключением exiftool, binwalk и steghide все что мы перечислили выше справедливо и для Linux. По этому далее мы рассмотрим только три этих утилите.
----> Утилита exiftool – читает мета-данные файлом. Применяется первым делом. Может дать много разной информации от автора статьи до кол-во фреймов на секунду в видео файле.
----> Steghide оооочень хорошо описан данный инструмент тут. Так же эта утилита фигурирует в курсе ParaNoID, так что советую к ней приглядеться
----> Binwalk
То же очень полезная тулза. Распознает сигнатуры внутри файла. Но я не советую свято верить ему. Были моменты когда он давал неправильную информацию. Как я понял это из за того, что он просматривает только сигнатуры начала.
Binwalk имеет очень много функций, но нам достаточно 2х. Просто передавая ему файл на вход мы получаем инфу о хранящихся в нем файлах.
А добавив ключ -e распакуем эти файлы в ту же директорию, что и оригинальный файл в отдельную директорию _[имя файла].
Выглядит это примерно так: Есть файл steg.jpg, вот что выдает утилита file
Он думает что это картинка Давайте спросим у binwalkа
У него есть другое мнение. Давайте дадим ему попробовать распаковать их binwalk -e steg.jpg
вот мы и нашли спрятанные картинки
Звуковые файлы:
----> Sonic Visualizer
Функционал:
Открывать звуковые файлы различных форматов (WAV/AIFF, Ogg, mp3 и т.д.) и просматривать их графическое представление;
Просматривать такие визуализации, как волновое представление и спектрограмма с возможностью интерактивного управления параметрами отображения;
В одном окне программы строить несколько волновых представлений и спектрограмм, причем каждая визуализация может иметь собственные параметры отображения;
Синхронно прокручивать все интересующие построенные визуализации и изменять их масштаб;
Снабжать звуковые данные примечаниями с помощью добавления различных меток и выделения отрезков сигнала
По моему опыту вся работа в этом редакторе сводится только к тому, что бы просмотреть звуковой ряд под разными слоями спектрограмм и игры с их настройками.
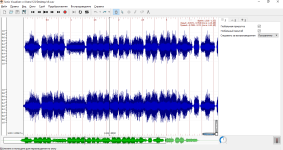
Давай те покажу на примере. Пусть имеется некий wav файл. Если просто открыть его в SV то вот что мы увидим
Пока что ничего не понятно. Но если наложить слой спектрограммы
и вот мы уже видим более осмысленную картину, с которой уже можно работать
Что касается Audacity, то это аналогичный аудио редактор с практически теми же возможностями. Тут уж кто чем привык пользоваться.
Видео файлы:
Как я уже писал выше весь мой опыт работы с видео файлами, в стего, сводился к тому, что бы разрезать видео ряд на кадры и уже с ними работать как с картинками. По этому приведу лишь одну строчку кода, которая позволяет это сделать с помощью ffmpeg.
ffmpeg -i input.mp4 -r 25 -f image2 images%05d.jpg
где:
----> i – видео файл, который необходимо разбить на фреймы
----> -r – кол-во фреймов в секунду. Можно узнать в мета данных файла
----> -f – тип файла в который необходимо перевести фрейм
Так же может быть полезен ключ –t: ffmpeg -i input.mp4 -r 25 –t 00:00:01 -f image2 images%05d.jpg
Этот ключ позволяет обработать заданное кол-во времени видео файла. В данном примере 1 секунду.
Теперь я бы хотел расписать некие алгоритмы для различных ситуаций:
- Первым делом, не важно, какой это файл, проверяйте утилитами file, exiftool, binwalk.
- Далее проверьте утилитой strings [имя файла] | grep –I [искомая подстрока(например flag)]
- Если ничего из этого не дало результата, то далее уже все зависит от вида объекта.
Картинка:
- Если картинка монотонная, то первым делом попробуйте открыть его в каком нибудь реакторе и примините заливку или используйте утилиту Steglove и прогоните по слоям.
было:
Есть с чем работать, как говорится.
- Если на картинке вы видите два цвета, то первая ваша мысль должна быть – бинарный код
Например:
Для облегчения это задачи есть наш верный друг python и его библиотека PIL.
- Если же у нас дана обычная картинка и в ней зашифровано стего, то стоит поискать оригинал картинки с помощью сервисов google pictures или аналогов.
- Так же было бы не лишним прогнать картинку по всем веб ресурсам которые я указывал выше.
Звуковые файлы:
- Если звуковой файл при прослушивании похож на зов пришельцев в брачный период, то сразу же посмотрите спектрограмму этого файла как я описывал выше. С большой вероятностью вы увидите, что то с чем можно будет работать.
- Если звуковая дорожка монотонно. Я имею ввиду, что на протяжении всей дорожки частоты не превышают определенной границы, то скорее всего это в файле зашифрована бинарная последовательность. На разных слоях спектрограммы будет лучше видно. Так же в этом может помочь наш друг python и его библиотека scipy.io.wavfile.
Т.е. каждый элемент массива samples будет иметь массив из двух значений. Первой и второй дорожки соответственно.
Кстати из за этого можно попробовать найти разность звуковых дороже.
Вполне может оказаться, что результатом станет последовательность цифр каждый элемент которой, переведя в нужную кодировку, может составлять флаг.
На этом я хочу, пока что, закончить. Статья будет дополняться, украшаться и улучшаться, что бы стать достойным пособием для новичков в стего. Так же хотелось бы прочитать о ваших способах работы со стего.
Надеюсь эта статья пригодится новичкам и поспособствует приливу новой крови в бурную реку ctf соревнований. Всем удачи!

Вы можете использовать один и тот же метод, чтобы скрыть данные в аудио- или видеофайлах.
В цифровой стеганографии электронная связь может включать в себя стеганографическое кодирование внутри транспортного уровня, такое как файл документа, файл изображения, программа или протокол.
Медиа-файлы идеально подходят для стеганографической передачи из-за их большого размера.
Например, отправитель может начать с файла безвредного изображения и настроить цвет каждого 100-го пикселя, чтобы соответствовать букве в алфавите, что настолько тонко, что кто-то, кто не ищет его, вряд ли заметит его.
Стеганография в Kali Linux
а. Steghide
В Kali Linux есть два основных инструментария для стеганографического использования.
Цветно-чувствительные частоты выборок не изменяются, что делает встраивание устойчивым к статистическим испытаниям первого порядка.
Особенности:
- сжатие встроенных данных
- шифрование встроенных данных
- встраивание контрольной суммы для проверки целостности экстрадированных данных
- поддержка файлов JPEG, BMP, WAV и AU
б. StegoSuite
Особенности:
Скрытие данных в изображении с помощью steghide
Установка Steghide
Установка в Kali Linux проста, так как steghide уже доступен в репозитории Kali Linux.
Выполните следующую команду, и все готово:
Скрыть текстовый файл в изображении
Я создал папку steguide в корневой домашней папке и разместил файл picture.jpg и secret.txt там же.
Я собираюсь показать здесь команды по всему этому безобразию.
Чтобы скрыть текстовый файл в картинке в Kali Linux с помощью steghide, используйте следующую команду:
Эта команда вставит файл secret.txt в файл picture.jpg. Теперь вы можете отправлять, делиться или делать что-либо с этим новым файлом picture.jpg без необходимости беспокоиться о том, что кто-то сможет разоблачить ваши данные.Извлечение текстового файла из изображения
Принимающий должен использовать steghide следующим образом:
Если поставленная кодовая фраза верна, содержимое исходного файла secret.txt будет извлечено из файла picture.jpg и сохранено в текущем каталоге.
Чтобы быть в безопасности, я проверяю содержимое секретного файла, который я извлек.
После проверки убеждаемся,что все в порядке.
Просмотр информации о встроенных данных
Если вы получили файл, содержащий встроенные данные, и хотите получить информацию об этом до его извлечения, используйте команду info:
После вывода некоторых общих сведений о файле (формат, емкость) вам будет задан вопрос, следует ли steghide попытаться получить информацию о встроенных данных.
Если вы ответите «yes», вы должны предоставить кодовую фразу.
Скрытие данных на изображении с помощью Stegosuite
Установка stegosuite
Установка в Kali Linux очень проста, так как stegosuite уже доступен в репозитории Kali Linux.
Выполните следующую команду, и все будет установлено:
Вставить текстовый файл в изображение с помощью Stegosuite
Вам нужно запустить его из меню «Application» (или просто выполнить поиск). Откройте File > Open и откройте изображение, которое хотите использовать.
Щелкните правой кнопкой мыши раздел файла и выберите файл и выберите файл secret.txt.
Введите ключевую фразу и нажмите «embed».
Несколько секунд, и он создаст новый файл picture_embed.jpg.
Извлечение текстового файла из изображения с использованием Stegosuite
Если вы хотите извлечь текстовый файл или данные из изображения, просто откройте изображение, введите парольную фразу и нажмите «extract».
Стеганализ и обнаружение
При вычислении стеганографически кодированное изображение с обнаружением пакета данных называется стеганализ.
Например, чтобы обнаруживать информацию, перемещаемую через графику на веб-сайте, аналитик может поддерживать известные чистые копии этих материалов и сравнивать их с текущим содержимым сайта.
Различия, предполагающие, что носитель один и тот же, составляют пэйлоад.
В общем, использование чрезвычайно высоких скоростей сжатия затрудняет стеганографию, но оно возможно.
Ошибки сжатия обеспечивают скрытие данных, но высокое сжатие уменьшает объем данных, доступных для хранения полезной нагрузки, повышая плотность кодирования, что облегчает обнаружение (в крайних случаях даже при случайном наблюдении).
Добрый вечер, я уже довольно долго наблюдаю, как люди тренируют свое зрение и выискивают невыискиваемое то, что спрятали другие в своих переводах комиксов.
Есть одна утилитка, предназначенная для решения CTF-задачек связанных с различными картинками, которая позволяет различными способами обрабатывать изображения, а так же комбинировать их с другими изображениями различными способами.
Утилитка называется Stegsolve и найти ее можно по первой ссылке в гугле.
Собственно, сегодня я встал с дивана и решил проверить на ней различные комиксы автора @bazil371.
Алогоритм действий довольно простой:
-Автор предоставляет в каждом комиксе ссылку на оригинал. По этой ссылке нам необходимо скачать исходное изображение и изображение, которое выложил автор.
-Скачиваем картинку, которую выложил автор.
-Совмещаем картинки и используем различные методы их совмещения.
Например, начнем с этого поста Пёсика жалко.

Третья картинка представляет собой первые две, совмещенные с помощью логической операции XOR (одинаковые пиксели станут черными, а разные будут светиться). Можно заметить, что в левом нижнем углу светятся 3 палочки, которые собственно можно было заметить и до этого, но мы же экспериментаторы. Пойдем дальше, вариант посложнее.
Совместим далее вот картинки из этого поста Приложение для девушек. Здесь уже не все так очевидно. Исходные картинки прикладывать не буду, далее результат совмещения различными способами. При быстром переключении вперед назад между первыми двумя, изменение довольно быстро бросается в глаза (уголок купюры).
При совмещении их при помощи XOR приходится вглядываться, ибо из-за сжатия jpg картинки становятся разными и однозначно совместить их не получается, но уголок купюры засветился всеми цветами радуги.

Если у вас есть сервер данных, веб-сервер или веб-сайт, вы можете установить и настроить механизм Elasticsearch в своей системе для поиска параметров базы данных. Elasticsearch можно установить и настроить вместе с серверами и системами Linux для сортировки данных, улучшения результатов поиска, фильтрации параметров поиска. По сути, вы можете использовать движок Elasticsearch на своем сервере, чтобы делать всевозможные вещи для создания надежной поисковой системы.
Как работает Elasticsearch
Elasticsearch работает с инструментом управления производительностью приложений (APM) для сбора данных индекса, метаданных и других полей данных из исходной базы данных. Это также обеспечивает поддержку API для повышения производительности.
Elasticsearch позволяет создавать круговую диаграмму и другие графические представления ваших данных. Это не бизнес-аналитика, но данные довольно хорошо анализируются. Вы можете найти использование ЦП и памяти, обнаружить отклонения и сохранить данные с помощью Elasticsearch в системе Linux.
Установите Elasticsearch в Linux
Elasticsearch написан на Java, поэтому вам потребуется установить Java в вашей системе Linux, чтобы установить Elasticsearch в вашей системе. Он позволяет интегрировать API, чтобы вы могли использовать его в различных веб-приложениях. Вы можете установить Elasticsearch в системе Linux и настроить его с существующим сервером Apache или Nginx. В этом посте мы увидим, как установить и использовать эластичный поиск в системе Linux.
1. Установите Elasticsearch в Ubuntu / Debian Linux.
Установка Elasticsearch в системе Linux на базе Debian не является сложной задачей; Это просто и понятно. Вам необходимо знать несколько основных команд терминала и иметь привилегию root в вашей системе. Следующие шаги помогут вам установить Elasticsearch на Ubuntu и другие машины Debian Linux.
Шаг 1. Установите Java для Elasticsearch
Elasticsearch требует Java для настройки функций веб-библиотеки в системе Linux. Если в вашей системе не установлена Java, вы можете запустить следующую команду терминала в своей оболочке, чтобы установить Java.
sudo apt установить openjdk-11-jre-headless
Когда установка Java завершится, не забудьте проверить версию Java, чтобы убедиться, что она установлена правильно.
Шаг 2. Добавьте ключ GPG для Elasticsearch в Debian Linux
Для простой установки Elasticsearch вам необходимо добавить GPG-ключ (Gnu Privacy Guard) Elasticsearch в вашу систему Linux. Выполните следующую команду cURL в оболочке терминала, чтобы добавить ключ GPG.
Для дистрибутивов Dedina Elasticsearch доступен в репозитории Linux. Вам необходимо добавить его в системный репозиторий. Вы можете запустить следующую команду echo, чтобы добавить Elasticsearch в репозиторий вашей системы.

Когда команда echo завершится, обновите системный репозиторий и проверьте, добавлен ли он в ваше программное обеспечение. Вы можете найти свой системный репозиторий на вкладке «Другое программное обеспечение» в инструменте «Программное обеспечение и обновления».
sudo apt-get update

Шаг 3. Установите Elasticsearch в Debian / Ubuntu
После добавления ключа GPG и обновления репозитория установка Elasticsearch теперь осуществляется в несколько кликов. Теперь вы можете запустить следующую команду aptitude в оболочке терминала с привилегиями root, чтобы установить Elasticsearch в вашей системе Debian.
sudo apt установить elasticsearch

2. Установите Elasticsearch на рабочую станцию Fedora.
Если вы используете систему Fedora Linux, следующие шаги помогут вам установить Elasticsearch на свой компьютер. Я протестировал следующие шаги на своей рабочей станции Fedora; эти шаги также могут быть выполнены в других системах на базе Red Hat.
Шаг 1. Установите Java на рабочую станцию Fedora.
Как я упоминал ранее, для установки Elasticsearch требуется Java; Сначала мы установим Java в нашу систему. Если в вашей системе уже установлена Java, вы можете пропустить ее установку. Чтобы убедиться, установлена ли Java или нет, вы можете запустить команду быстрой проверки версии в оболочке терминала.
Если вы не видите взамен какую-либо версию Java, теперь вы можете запустить следующую команду DNF, чтобы установить ее в Fedora Linux.
sudo dnf установить java-11-openjdk

Шаг 2. Добавьте Gnu Privacy Guard для Elasticsearch
На этом этапе нам нужно добавить GPG-ключ для Elasticsearch в нашу систему. Вы можете запустить следующую команду в оболочке терминала, чтобы добавить ключ GPG.

Теперь нам нужно создать файл репозитория для Elasticsearch в каталоге /etc/yum.repos.d. Вы можете открыть файловую систему и создать новый скрипт текстового документа и переименовать его в elasticsearch.repo. Если у вас есть проблемы с разрешениями при создании нового файла репозитория, вы можете запустить следующую команду chown для доступа к файлу. Не забудьте заменить слово ubuntupit своим именем пользователя.
sudo chown ubuntupit elasticsearch.repo

Затем вам нужно скопировать и вставить следующий скрипт в файл elasticsearch.repo, сохранить и выйти из файла.

Шаг 3. Установите Elasticsearch в Fedora
После установки Java и добавления ключа GPG мы теперь установим Elasticsearch в нашу Fedora Linux. Перед установкой вам может потребоваться выполнить быструю команду очистки DNF, чтобы очистить метаданные репозитория из вашей системы. Затем выполните следующую команду YUM в своей оболочке с правами root, чтобы установить Elasticsearch в вашей системе.
sudo dnf clean
sudo yum install elasticsearch
Если у вас возникли проблемы с его установкой в вашей системе, вы можете запустить следующую команду DNF, чтобы избежать ошибок.
sudo dnf установить elasticsearch-oss

После завершения установки вы можете запустить следующие команды управления системой в оболочке терминала, чтобы запустить и включить Elasticsearch на вашем компьютере с Linux.
sudo systemctl start elasticsearch
sudo systemctl enable elasticsearch
Если все пойдет правильно, вы можете запустить следующую команду управления системой, чтобы проверить состояние Elasticsearch на вашем компьютере. Взамен вы увидите имя службы, основной PID, статус активации, сведения о задаче и время выполнения ЦП.
sudo systemctl статус elasticsearch

Настроить Elasticsearch в Linux
После установки Elasticsearch на машину Linux вам может потребоваться настроить его с IP-адресом вашего сервера, чтобы загрузить его вместе с вашим сервером. Здесь я использую адрес localhost (127.0.0.1) для его загрузки. Вы можете запустить следующую команду в оболочке терминала, чтобы открыть сценарий конфигурации.
sudo nano /etc/elasticsearch/elasticsearch.yml
Когда скрипт откроется, найдите параметр network.host и замените существующее значение на адрес вашего активного сервера. После изменения IP-адреса сохраните и выйдите из файла.

Теперь запустите и включите Elasticsearch в вашей системе Linux, чтобы перезагрузить его на вашем компьютере.
sudo systemctl start elasticsearch
sudo systemctl enable elasticsearch

Когда вы добавляете новый IP-адрес с новым портом, всегда полезно добавить его в брандмауэр. Надо сказать, что по умолчанию Elasticsearch использует сетевые порты 9200-9300. Здесь я буду использовать порт 9200 для настройки Elasticsearch с адресом localhost.
Поскольку Ubuntu использует инструмент UFW для настройки брандмауэра, вы можете запустить следующие команды UFW в оболочке терминала, чтобы разрешить порт 9200 в вашей системе.
sudo ufw разрешить с 127.0.0.1 на любой порт 9200
sudo ufw enable
Теперь вы можете проверить статус UFW в оболочке терминала, чтобы проверить, добавлен ли порт в сетевой системе.
sudo ufw статус

Если вы используете Fedora, Red Hat Linux и другие дистрибутивы Linux, вы используете команду Firewalld, чтобы включить порт 9200 для вашей среды. Сначала включите Firewalld в вашей системе Linux.
Теперь добавьте правило в настройки Firewalld. Затем перезапустите систему Angular CLI.
Начать работу с Elasticsearch

Мы можем попытаться вставить строковые данные в базу данных Elasticsearch и извлечь данные, чтобы проверить, работает ли она правильно или нет. Выполните следующую команду cURL, чтобы протолкнуть данные внутрь системы.
Чтобы получить строковые данные через Elasticsearch, выполните следующую команду в оболочке терминала вашей системы.
Выводы
Читайте также: