
Tesseract ocr как установить на windows
Обновлено: 07.07.2024
Давайте представим, что вам нужно оцифровать страницу книги или печатного документа, вы будете использовать сканер для создания изображения реальной страницы. Однако, несмотря на то, что у вас есть права на редактирование содержимого отсканированной книги, вы не можете редактировать его на своем компьютере, потому что это изображение, и вы не можете просто отредактировать изображение, как если бы это был цифровой документ. Да, пользователь может использовать программы, которые создают PDF с возможностью выбора текста, а затем они могут делать то, что хотят, однако, как разработчик, вы можете предложить своему пользователю возможность извлекать текст из изображений с помощью технологии оптического распознавания символов. Чтобы достичь цели преобразования изображений в текст, мы собираемся использовать Tesseract, написанный на C ++, установить его в системе, а затем использовать командную строку с оболочкой PHP.
В этой статье вы узнаете, как извлечь текст из изображения в проекте Symfony с помощью Tesseract.
1. Установите Tesseract в вашей системе
Чтобы использовать API оптического распознавания символов, как упоминалось в статье, мы собираемся использовать Tesseract. Тессеракт является механизмом оптического распознавания символов (OCR) с открытым исходным кодом, доступным по лицензии Apache 2.0. Его можно использовать напрямую с помощью API для извлечения печатного, рукописного или печатного текста из изображений. Он поддерживает широкий спектр языков (которые должны быть установлены). Tesseract поддерживает различные форматы вывода: обычный текст, hocr (html) и pdf.
Процесс установки Tesseract в вашей системе зависит от используемой вами операционной системы:
Windows
Процесс установки очень прост, просто следуйте инструкциям мастера. Однако мы рекомендуем вам установить в настройках непосредственно все языки, которые вам нужны для tesseract (только те, которые вам нужны, в противном случае процесс загрузки займет много времени) и зарегистрировать tesseract в PATH:
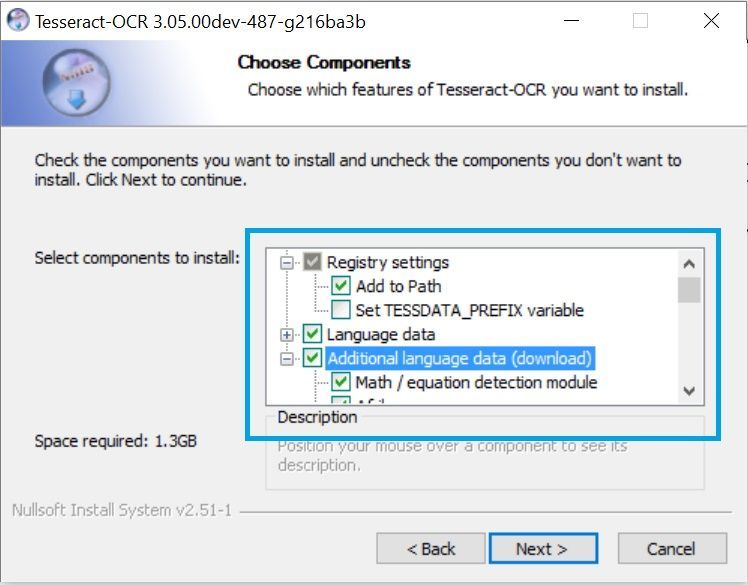
Подождите, пока установка закончится, и вы готовы к работе. Вы можете проверить, правильно ли он был установлен, запустив новое окно командной строки. tesseract -v (это должно вывести установленную версию).
Ubuntu
Установите Tesseract с помощью следующей команды:
Затем установите языки, которые необходимо распознать (например, -deu, -fra, -eng, -spa требуемый английский):
Тогда tesseract должен быть доступен на любом терминале и, следовательно, доступен для наших сценариев PHP позже.
MacOS
Если вы используете Mac OS X, вы можете установить tesseract, используя либо MacPorts или же Homebrew:
MacPorts
Чтобы установить Tesseract, запустите эту команду:
Чтобы установить любые языковые данные, выполните:
Homebrew
Чтобы установить Tesseract, запустите эту команду:
Если вам нужна дополнительная информация или вашей операционной системы нет в списке, обратитесь к Установка вики репозитория Tesseract в Github здесь.
2. Установите PHP-оболочку Tesseract
Для работы с Tesseract с помощью PHP мы будем использовать самый известный Wrapper of Tesseract, написанный @thiagoalessio. Тессеракт OCR для PHP является полезной и очень простой в использовании оболочкой инструкций командной строки для Tesseract OCR внутри PHP.
Или, если хотите, отредактируйте composer.json файл и добавьте следующую зависимость и выполните затем composer install :
После установки вы сможете использовать Wrapper в ваших контроллерах Symfony.
Замечания: вам нужно установить указанную версию, как в документации библиотеки, метод распознавания текста на изображении с использованием Tesseract $tesseract->run() , В старых версиях вам нужно использовать $tesseract->recognize() вместо.
3. Реализация в контроллере
Использование библиотеки довольно просто и легко понять:
В следующем примере показано, как распознать текст следующего изображения:

Обратите внимание, что файл будет находиться в /your-project/web/text.jpg :
Перейдите к маршруту, который соответствует действию индекса этого контроллера, и вы увидите, как выводится распознанный текст изображения.
4. Поддержка языков
Как вы знаете, в мире есть другие языки, в которых используются специальные символы, поэтому Tesseract предлагает различные языковые пакеты. Например, если вы попытаетесь распознать следующее изображение без немецкого пакета:

В результате вы получите «грифон». Это совсем не так, это происходит потому, что эти персонажи немецкого языка. Чтобы решить эту проблему, вам нужно добавить немецкий пакет (обозначается как deu ):
Замечания: чтобы использовать разные языки, вам также понадобятся соответствующие пакеты.
5. Пользовательские параметры
Если вы уже прочитали некоторое содержание документация по использованию Tesseract с командной строкой, Вы знаете, что есть много свойств, которые вы можете изменить. Оболочка PHP tesseract предоставляет несколько методов для наиболее часто используемых опций:
Изменить путь к исполняемому файлу
Сегментация страницы
Вы можете установить режим сегментации страницы с помощью ->psm($mode) инструкция, которая инструктирует тессеракт, как интерпретировать данное изображение:
Возможные значения для сегментации страницы:
| Значение | Описание |
| Только ориентация и обнаружение сценариев (OSD). | |
| 1 | Автоматическая сегментация страницы с помощью экранного меню. |
| 2 | Автоматическая сегментация страницы, но без OSD или OCR. |
| 3 | Полностью автоматическая сегментация страниц, но без OSD. (Это значение используется по умолчанию, если ни один не предоставлен) |
| 4 | Предположим, что один столбец текста переменного размера. |
| 5 | Предположим, что один однородный блок текста вертикально выровнен. |
| 6 | Предположим, что один единый блок текста. |
| 7 | Рассматривайте изображение как одну текстовую строку. |
| 8 | Рассматривайте изображение как одно слово. |
| 9 | Рассматривайте изображение как одно слово в кругу. |
| 10 | Относитесь к изображению как к одному персонажу. |
Установите языки для распознавания
Вы можете определить один или несколько языков, которые будут использоваться во время распознавания, используя ->lang($lang1, $lang2) метод. Вы можете получить список все поддерживаемые языки по tesseract в документации здесь:
Используйте слова из списка
Вы можете предоставить список. этот список должен быть простым текстовым файлом, содержащим список слов, которые вы хотите, чтобы tesseract считал обычными словарными словами, например ( mywords.txt ):
И добавьте это с оберткой:
Этот список действительно полезен при работе с контентом, который содержит техническую терминологию.
Белый список персонажей
Вы можете даже ограничить символы, которые распознает tesseract, например, с помощью следующего изображения:
Установить значение конфигурации
Tesseract предлагает более 600 настраиваемых свойств (вы можете перечислить их, используя в консоли tesseract --print-parameters ) что вы можете изменить с помощью ->config($propertyName, $value) :
Если вам нужна дополнительная информация о поддерживаемых методах этой оболочки, пожалуйста, посетите официальный репозиторий здесь.
Блог по web технологиям. Веб студия г. Воронеж. Создание и поддержка сайтов на заказ.
Оригинальный проект находится на гитхабе, а скачать установщик можно здесь, На момент написания статьи версия установщика была 3.05.01. Мне понадобилось немало времени на постижение всей его глубины, поэтому я решил написать что и как, вдруг забуду что-то в будущем, а также чтобы помочь другим пройти этот путь в следующий раз быстрее.
0. Что нам нужно
Сборки этой библиотеки есть под windows (можно скачать установщик отсюда) и под linux. Для большинства linux-дистрибутивов установить tesseract можно просто через sudo apt-get install tesseract-ocr.
- Изображение с текстом для тренировки
Между всеми символами должны быть чётко различимые промежутки. Кладём наше изображение в отдельную директорию и называем в виде <код языка>.<имя шрифта>.exp<номер>.tif. Изображение может быть не одно и отличаться они должны только номером в наименовании файла. Формат наименований файлов очень важен. На файлы с неверными наименованиями утилиты, которые мы будем использовать будут ругаться ошибками сегментирования и т.п. Для определённости будем считать, что изучаем мы язык ссс и шрифт eee. Таким образом называем файл со сканом тренировочного образца ccc.eee.exp0.tif
1. Создаём и редактируем box-файл
Для того чтобы отметить символы на изображении и задать им соответствие utf-8 символам текста служат box-файлы. Это обычные текстовые файлы, в которых каждому символу соответствует строка с символом и координатами прямоугольника в пикселях. Первоначально файл генерируем утилитой из пакета tesseract:
tesseract ccc.eee.exp0.tif ccc.eee.exp0 batch.nochop makebox
получим файл
в текущей директории. Заглянем в него. Да, чуть не забыл, не забудьте прописать адрес установленной Tesseract-OCR в переменную среды Path в windows, иначе команда tesseract не будет работать в консоли.
Работа нудная и кропотливая, но к счастью для этого есть ряд сторонних утилит. Я например пользовался jTessBoxEditor. Открываем им изображение, box-файл с таким же именем он сам подтянет (главное чтобы всё лежало в одной папке).
Способность современных машин (вычислительных устройств) использовать камеры для получения информации об окружаем мире и способность интерпретировать/обрабатывать эти данные с каждым годом оказывает все большее влияние на жизнь современного общества. Сейчас уже никого не удивишь роботом доставщиком еды (например, Starship Robots) или автомобилем с функцией автопилота (например, Tesla) – эти устройства во время своего движения для принятия решений полагаются на информацию, получаемую от своих высоко технологичных камер. В данной статье мы рассмотрим основы технологии оптического распознавания символов (Optical Character Recognition, OCR), применяемой в современных электронных устройствах для распознавания отдельных символов на изображении.

У этой технологии очень много возможностей для практического применения в современном мире: считывание информации с визиток, распознавание магазине по его названию, распознавание дорожных знаков и многое другое. Наверняка многие из вас уже слышали о таком приложении как Google Lens, которое представляет собой систему искусственного интеллекта, распознающую в режиме реального времени объекты на фотографии и предоставляющую имеющуюся по ним сведения в сети интернет. В данной статье мы рассмотрим похожий инструмент от компании Google для выполнения задачи оптического распознавания символов (OCR) под названием Tesseract-OCR Engine, работающий на основе языка python и библиотеки OpenCV. Данный инструмент позволяет распознавать/идентифицировать символы на изображениях с помощью платы Raspberry Pi.
Установка Tesseract на Raspberry Pi
Для выполнения задачи оптического распознавания символов (OCR) в Raspberry Pi нам необходимо установить на нее Tesseract OCR engine. Чтобы сделать это нам сначала нужно сконфигурировать Debian Package (dpkg), который затем поможет нам установить Tesseract OCR. Для конфигурирования Debian Package выполните следующую команду:
Далее мы можем приступить к установке Tesseract OCR (Optical Character Recognition) с помощью опции apt-get. Выполните для этого команду:
После этого в окне терминала вы должны увидеть примерно следующую картину:

Процесс установки Tesseract OCR займет около 5-10 минут.
Теперь, когда у нас Tesseract OCR установлен, нам необходимо установить еще пакет PyTesseract с помощью установщика пакетов pip. Pytesseract – это python оболочка для Tesseract OCR engine, которая позволяет использовать возможности Tesseract из языка python. Для установки PyTesseract выполните следующую команду:
Прежде чем продолжать далее убедитесь в том, что на вашей плате установлена библиотека pillow. О том, как ее установить, можно прочитать в статье про распознавание лиц с помощью платы Raspberry Pi. После завершения установки pytesseract вы в окне терминала должны увидеть примерно следующую картину:

Tesseract 4.0 на Windows/Ubuntu
Проект оптического распознавания символов изначально начинал разрабатываться компанией Hewlett Packard в 1980 году. Затем он был выкуплен компанией Google, которая и осуществляет его поддержку вплоть до настоящего времени. Многие годы Tesseract хорошо работал только на изображениях определенного формата. К примеру, если фон изображения был сильно зашумлен или объект для распознавания был не в фокусе, то Tesseract работал не очень хорошо.
Для преодоления этой проблемы последние версии tesseract (к примеру, версия Tesseract 4.0) стали использовать технологии машинного обучения (Deep Learning) для улучшения распознавания символов и даже почерка. Tesseract 4.0 использует Long Short-Term Memory (LSTM) и рекуррентную нейронную сеть (Recurrent Neural Network, RNN) для повышения точности распознавания символов. К сожалению, на момент написания оригинала данной статьи (август 2019 г., ссылка на оригинал в конце статьи) Tesseract 4.0 был доступен для использования только в операционных системах Windows и Ubuntu, а для Raspberry Pi он находился в стадии бета тестирования. Поэтому в оригинале данной статьи автор использовал ее версию Tesseract 3.04 на Raspberry Pi. На момент прочтения вами данной статьи, скорее всего, будут доступны уже и более свежие версии Tesseract для Raspberry Pi. Но мы надеемся, что после прочтения данной статьи у вас их применение не вызовет никаких затруднений.
Простое распознавание символов в Raspberry Pi
В предыдущем пункте статьи мы уже установили на плату Raspberry Pi библиотеку Tesseract OCR и пакет Pytesseract. Поэтому в данном разделе статьи мы напишем небольшую программу чтобы проверить как работает распознавание символов на тестовом изображении. В качестве тестового изображения мы будем использовать следующее:

Текст используемой нами программы будет очень простой. Как видите, он даже не использует пакеты библиотеки OpenCV.
В представленной программе мы пытаемся прочитать текст с изображения под названием ‘1.jpg’, которое расположено в том же самом каталоге, что и наша программа. Для открытия этого изображения используется пакет Pillow, после чего оно сохраняется в переменной img . Затем мы используем метод image_to_string из пакета pytesseract для обнаружения любого текста на изображении и сохраняем его в переменной text . И, наконец, мы выводим значение переменной text на экран чтобы проверить результат работы программы.
Как вы можете видеть, тестовое изображение содержит текст Explain that Stuff! 01234567890”, а в результате работы нашей небольшой программы мы получили текст “Explain that stuff! Sdfiosiefoewufv”. Это означает, что наша программа не смогла распознать цифры на изображении. Для преодоления этой проблемы обычно используют библиотеку OpenCV чтобы удалить шум (зашумленность) из программы и затем настраивают Tesseract OCR engine чтобы получить более впечатляющие результаты. Но помните о том, что не стоит ожидать 100% точности распознавания от Tesseract OCR Python.
Настройка Tesseract OCR для улучшения результатов
Pytesseract позволяет нам производить настройку Tesseract OCR engine при помощи установки флагов (flags), которые влияют на способ поиска символов на изображении. Для настройки Tesseract OCR используется 3 основных флага:
- language (-l) (язык);
- OCR Engine Mode (--oem) (режим работы "движка" распознавания символов);
- Page Segmentation Mode (- -psm) (режим сегментации страниц).
Кроме английского языка (по умолчанию) Tesseract также поддерживает множество других языков: Hindi, Турецкий, Французский и др. Мы в нашем проекте будем использовать только английский язык (English), но вы можете скачать соответствующие обучающие пакеты со страницы на github и добавить их в свой пакет чтобы иметь возможность распознавать символы на других языках. Также возможно производить распознавание двух или более языков на одном и том же изображении. Язык распознавания устанавливается с помощью флага language, значение этого флага –l соответствует английскому языку (English), для других языков необходимо использовать другие значения этого флага.
Следующим флагом является OCR Engine Mode, с помощью которого можно использовать 4 различных режима распознавания. Каждый режим использует свой собственный алгоритм для распознавания символов на изображении. По умолчанию используется алгоритм, который устанавливается вместе с пакетом. Но мы можем изменить его чтобы использовать LSTM или Neural nets (нейронные сети). 4 доступных режима OCR Engine Mode показаны на следующем рисунке. Этот флаг устанавливается с помощью префикса --oem, то есть чтобы использовать mode 1 (режим 1), необходимо ввести -- oem 1.

И, наконец, один из самых значимых флагов, которые используются для настройки Tesseract OCR – это флаг режима сегментации страниц (page segmentation mode flag). Этот флаг очень полезен когда фон вашего изображения имеет много незначащих деталей (шум) или символы на изображении написаны в различной ориентации и с различными размерами. Всего доступно 14 различных режимов сегментации страниц, которые представлены на рисунке ниже. Флаг устанавливается с помощью префикса –psm, в нашем случае мы будем использовать –psm 11.

Использование флагов oem и psm в Tesseract на Raspberry Pi для улучшения результатов распознавания
Проверим эффективность рассмотренных режимов. На представленном ниже рисунке мы сделали попытку распознавания символов на дорожном знаке, обозначающем ограничение скорости. На знаке написано “SPEED LIMIT 35”. Как вы можете видеть из представленного рисунка, число 35 на нем значительно большего размера, чем все остальные символы. Это обстоятельство существенно затрудняет работу Tesseract, поэтому он смог распознать с этого изображения “SPEED LIMIT”, а цифры не распознал.

Чтобы преодолеть эту проблему, мы попробуем настроить флаги. В ранее рассмотренной программе флаг настройки пуст (config=’’), исправим это. Текст на изображении на английском языке, поэтому используем флаг –l eng, флаг oem оставим в режиме по умолчанию, то есть –oem 3 (режим 3). Теперь нам осталось только настроить флаг psm, нам необходимо найти больше символов на изображении, поэтому мы будем использовать режим 11, то есть получим флаг –psm 11. Окончательная настройка флагов будет выглядеть следующим образом:
Сегодня мы с вами поговорим на тему языка Python и рассмотрим пример создания крутого приложения. Наша программа будет способна считывать текст из любой фотографии.
Что сделаем за урок?
Мы с вами рассмотрим пример работы с библиотекой Tesseract ORC и на её основе построим приложение для распознавания текста с фото.
Что забавно, так это возраст библиотеки. Tesseract — является программой, разрабатывавшейся компанией Hewlett-Packard с середины 1980-х по середину 1990-х годов. Затем программа около 10 лет «пролежала на полке» и в августе 2006 года её купила Google. Google открыл исходный код под лицензией Apache 2.0 для продолжения разработки.
На сегодняшний день библиотека является наиболее крутым решением, если вам требуется считать данные из какого-либо фото.
Установка библиотеки
Первое, что необходимо сделать, то это выполнить установку Tesseract ORC. Установка Tesseract удобна на Маке и Линукс. Если вы на Windows, то придется выполнить на одно движение больше.
Если вы на Маке, то скачайте HomeBrew и далее в терминале пропишите brew install tesseract . Если вы на Линукс, тогда в зависимости от операционной системы вам нужно прописать соответствующую команду в терминале.
И если вы на Windows, то вам нужно скачать приложение на ПК. Вам нужно скачать файл Windows Installer . После скачивания выполните установку данной программы.
С самой программой вам никак не придется взаимодействовать, а лишь скопировать её расположение. Обычно оно устанавливается на диск С в Program files. Найдите вашу программу и скопируйте путь к этой папке.
Разработка проекта
Полная разработка проекта показывается в видео. Вы можете просмотреть его ниже:
Полезные ссылки:
- Плейлист по нейронным сетям ;
- Официальный сайт Tesseract;
- Tesseract для Windows ;
- Различные языки для Tesseract .
Код для реализации проекта из видео:
Больше интересных новостей




Читайте также: