
Abbyy finereader 14 как распознать одну страницу
Обновлено: 07.07.2024
Новый FineReader 14 можно сравнить со швейцарским ножом — теперь под его личиной кроются сразу четыре продукта именитого разработчика, объединённых в одну программу с единым рабочим окружением. Помимо успевшей зарекомендовать себя с наилучшей стороны системы оптического распознавания текста Optical Character Recognition (OCR), которая обеспечивает конвертирование отсканированных изображений, фотографий, документов или PDF-файлов в редактируемые электронные форматы, в составе программы представлены редактор PDF, инструмент «Сравнение документов» для сравнения документов различных форматов, включая бумажные и электронные, а также средства автоматизации задач по конвертации документов Hot Folder. Вряд ли кто-то мог предполагать, что в почти четвертьвековой истории развития FineReader (первая версия продукта увидела свет в 1993 году) случится такой крутой поворот, однако в ABBYY убеждены в правильности выбранного курса и уверены, что подобного рода перемены сделают программу ещё более востребованной в пользовательской среде.

Новая концепция FineReader 14
Своё стремление уйти от устоявшихся традиций в компании объясняют современными тенденциями развития рынка электронного документооборота. Согласно проведённым ABBYY исследованиям, сотрудники различных организаций регулярно сталкиваются со следующими сценариями работы с документами: преобразование изображений и PDF-файлов в редактируемые форматы и внесение в них правок; сравнение документов разных форматов; создание, просмотр и редактирование PDF-файлов, а также извлечение из них данных. При этом типичный пользователь имеет дело с четырьмя и более сценариями и для решения каждой задачи использует разные программные продукты. В результате получается так, что вместо того, чтобы выполнять свою задачу, сотрудник компании занимается тем, что изучает эти инструменты и переключается между ними в процессе работы. Это очень неудобно и, по сути, является бесполезной тратой ресурсов, правильно распорядиться которыми должен новый FineReader 14.

ABBYY FineReader 14 предоставляет широкий спектр возможностей в одной программе
Не остались без изменений в обновлённом FineReader и фирменные технологии оптического распознавания текста ABBYY OCR и обработки структуры документа Adaptive Document Recognition Technology. Приложение определяет расположение текста, тип и размер шрифта, начертание и другие особенности форматирования, а также воссоздаёт структурные элементы — таблицы и диаграммы, колонки, заголовки, сноски, колонтитулы, номера страниц. В результате пользователь получает электронную копию документа, идентичную оригиналу. Распознанный текст можно сохранить как текстовый документ (DOCX, ODT, RTF), электронную таблицу (XLSX), презентацию (PPTX), файл HTML, электронную книгу (ePub и FB2), а также в форматах PDF и PDF/A.

Профессиональные инструменты для распознавания текста

С помощью встроенного в программу редактора пользователь может сравнить в одном окне оригинальный документ и распознанную копию. Расширенные функции по редактированию позволяют корректировать форматирование документа, вносить правки в текст, редактировать изображения, искать информацию, управлять страницами документа. Кроме того, имеется возможность вручную задавать области для распознавания и даже научить программу распознаванию специфических шрифтов.

В четырнадцатую версию FineReader были добавлены новые языки распознавания: математические символы (для распознавания однострочных математических формул) и английская транскрипция. Таким образом, теперь программа умеет оперировать документами на 192 мировых языках и любых их комбинациях.
Также при подготовке FineReader 14 к выпуску специалисты ABBYY увеличили скорость обработки и точность распознавания документов, доработали средства конвертирования PDF-файлов с текстовым слоем, улучшили работу с таблицами, графиками, диаграммами и документами на арабском языке. Множеству доработок подверглись другие компоненты программного комплекса. В частности, теперь FineReader позволяет создавать PDF-документы из файлов различных редактируемых форматов (DOCX, XLSX, RTF и др.) и объединять их в один PDF-документ.
Самый важный компонент нового FineReader – PDF-редактор, построенный на базе программы ABBYY PDF Transformer+. Приложение позволяет выполнять рецензирование и согласование PDF-документов, а также предлагает полный набор функций для их защиты от несанкционированного доступа и изменений. Кроме того, приложение интегрировано с Adobe PDF Library , что обеспечивает гарантированное открытие любых PDF -файлов и возможность внесения в них изменений без преобразования в редактируемый формат. С прицелом на корпоративный сегмент рынка в программе предусмотрены инструменты удаления конфиденциальной информации, добавления цифровой подписи и разграничения прав на печать и редактирование документов.

Внесение изменений в текст PDF-документов
FineReader 14 позволяет преобразовывать PDF в популярные форматы Microsoft Word, Excel, PowerPoint, HTML, OpenOffice (ODT) и другие. При этом исходная структура и форматирование документа сохраняются. Благодаря упомянутой выше поддержке ePub и FB2, пользователи могут создавать из PDF-документов любительские электронные книги для чтения на планшетах и других портативных устройствах. Отдельно стоит отметить возможность создания PDF из файлов изображений (JPEG, JPEG2000, JBIG2, PNG, BMP, GIF, TIFF) и поддержку потокового конвертирования документов.

Пригодится новый FineReader и тем, кто по долгу службы часто сталкивается с процессом согласования договоров или работает с документами, для которых характерна версионность. Возможности инструмента «Сравнение документов» позволяют сверять документы в различных форматах, быстро находить даже самые мелкие несоответствия в тексте и предотвращать тем самым подписание или публикацию некорректной версии документа. Автоматическое сравнение документов поможет существенно сэкономить время юристам, менеджерам по продажам, финансистам, логистам, а также всем офисным сотрудникам, которые сталкиваются со сравнением документов — договоров, актов, прайс-листов или других материалов.

Параллельный просмотр различий
Проводить сравнение документов можно как в текстовых, так и в графических (отсканированные документы или их фотографии, PDF без текстового слоя и т. п.) форматах. Для удобства работы с полученными результатами все обнаруженные несоответствия отображаются на отдельной панели, а также подсвечиваются по тексту в обоих документах. Предусмотрена возможность создания подробного отчёта о различиях и последующего его сохранения в виде таблицы в формате Word или PDF-документа с комментариями в местах изменений. Полученную таблицу можно использовать для вставки в отчёт о согласовании документов или для ведения переговоров с контрагентом. Несущественные различия перед формированием отчёта можно удалить.

Сохранение результатов сравнения
Для предприятий среднего и крупного бизнеса в составе FineReader 14 представлено приложение-планировщик ABBYY Hot Folder, с помощью которого можно автоматизировать однотипные или повторяющиеся задачи по обработке документов в сети организации. Возможности программы позволяют выполнять пакетное конвертирование файлов, преобразование документов по расписанию и обработку почтовых вложений. Для начала работы необходимо выбрать компьютер, который будет заниматься выполнением перечисленных операций, указать рабочую директорию на файловом сервере и настроить список задач.

Обработка документов по расписанию
Таковы основные отличительные особенности нового поколения FineReader, определённо заслуживающего внимания тех, кто часто занимается оцифровкой бумажных документов. Программа предназначена для запуска в среде Windows, совместима со всеми популярными моделями сканеров и многофункциональных устройств (МФУ) и поставляется разработчиком в трёх редакциях — Standard, Business и Enterprise. Они различаются набором включённых инструментов, формами поставки и условиями лицензирования.

Редакции и формы поставки ABBYY FineReader 14
И последний штрих. Как и в случае с предыдущими версиями FineReader, условия лицензионного договора допускают установку продукта на один стационарный и один мобильный компьютер при соблюдении двух требований: оба устройства должны принадлежать человеку, который приобрёл продукт, и одновременно может быть запущена только одна копия программы. Таким образом, приложение можно установить и на рабочий ноутбук, и на домашний ПК, не нарушая тем самым условий лицензионного соглашения с компанией ABBYY.

В этот раз расскажу как превращать бумажные документы в электронный вид формата PDF, а также, как бумажный документ перекинуть в компьютер с целью изменить текст. Итак начнем.
У меня на руках бумажный документ.
СКАНИРОВАНИЕ в PDF
Задача: перекинуть в компьютер (перевести в электронный вид) этот документ. Притом нужно сделать именно в таком виде чтобы нельзя было его в будущем изменить (грубо говоря надо сделать фото документа). Потом этот электронный документ нужно переслать по почте на электронный адрес. Притом клиент просит именно в формате pdf.
По этапам:
1) пропускаю документ через сканер
2) сохраняю полученный отпечаток в формате pdf на свой компьютер
3) пересылаю полученный файл по почте
В своей работе я использую для решения такой задачи 2 программы:
Foxit Phantom или ABBYY FineReader. Для понятности прикладываю скриншоты:
В Foxit Phantom при включенном сканере необходимо в главном меню выбрать ФАЙЛ-СОЗДАТЬ PDF-СО СКАНЕРА…
Произойдет сканирование и появится предложение сохранить файл. Выбираем место, пишем название файла и сохраняем.

В ABBYY FineReader в панели инструментов есть огромные кнопки. Одна из них называется СКАНИРОВАТЬ в PDF. Её и используем.

Если же надо отсканировать многостраничный документ то, по этапам:
1) Нажимаем кнопку под номером 1 СКАНИРОВАНИЕ

Получаем отсканированный документ

Также сканируем ещё одну страницу (нажимаем ещё раз кнопку под номером 1 СКАНИРОВАНИЕ).
2) Сохраняем в PDF


В итоге получаем готовый многостраничный документ в виде файла в формате PDF.

Теперь данный файл можно отправлять по электронной почте.
РАСПОЗНАВАНИЕ ТЕКСТА
Задача: перевести бумажный документ в электронный вид (в компьютер)
По этапам:
1) Сканирование (кнопка 1 СКАНИРОВАНИЕ)

2) Распознавание (кнопка 2 РАСПОЗНАТЬ ВСЕ)

Распознавание нужно понимать как процесс перевода фотографии (картинки) в текст (буквы, цифры, знаки). Если Вы сфотографировали текстовую страницу, то после распознавания 99% текста с бумаги превратиться в текст электронный. Электронный текст уже можно на компьютере менять (редактировать) так, как Вам захочется.
3) Сохранение в текстовый редактор (кнопка 4 Сохранить)
Советую выбирать ПЕРЕДАТЬ ВСЕ СТРАНИЦЫ В—MICROSOFT WORD


Хотелось бы указать на важные моменты при процедуре РАСПОЗНАВАНИЯ. Есть нюансы при работе.
Сразу после распознавания советую поглядеть на результат. Особенно на блоки, которые создает программа FineReader.

Это области выделенные в прямоугольные рамки. Рамки эти разного цвета. Если красного цвета-то этот блок распознался как КАРТИНКА. Если черного цвета — то ТЕКСТ. Блоки бывают разного типа. Тип блока можно узнать щелкнув на блоке ПРАВОЙ клавишей мыши и выбрав ИЗМЕНИТЬ ТИП БЛОКА.

Маленькая хитрость: можно выделить произвольную область и пометить любым типом блок. Например выделим ту часть текста, которая плохо распознается, при помощи левой клавиши мыши (нажимает, удерживаем и тянем, рамка меняет размер).



В итоге документ в Word-е будет иметь блок текста и блок картинка. Блок картинка будет иметь абсолютно неизменный вид. Данный способ я использую при сохранении печатей, нестандартных шрифтов, картинок, фотографий.
ЗЫ: Знания и умения работать с PDF, сканировать и распознавать документы очень часто выручают в офисной работе. Знание — экономит Ваше время!

Программа FineReader – полезное средство для просмотра PDF-файлов, конвертации документов, а так же распознания и переноса текста в цифровой вид. В обзоре мы подробно разберем возможности 14-й редакции программы, настройки и дополнительные инструменты, а так же основные преимущества и недостатки.
Назначение и позиционирование
Типичные сценарии использования программы: открытие и редактирование офисных документов, преобразование из одного формата в другой, а так извлечение данных. В 14-й редакции программы разработчики объединили несколько инструментов, что исключит необходимость поиска и изучения дополнительных программ, для работы с различными форматами офисных файлов.
Возможности FineReader
Примерно 60% возможностей программы направлено на работу с PDF-файлами: просмотр, создание, объединение, редактирование, добавление заметок, защита и т.д. Поддерживается конвертация документов в PDF либо обратная конвертация из PDF в Word/Excel и т.д. Доступно распознание текста, включая ручную разметку страниц и обучение неизвестным и нестандартным символам.
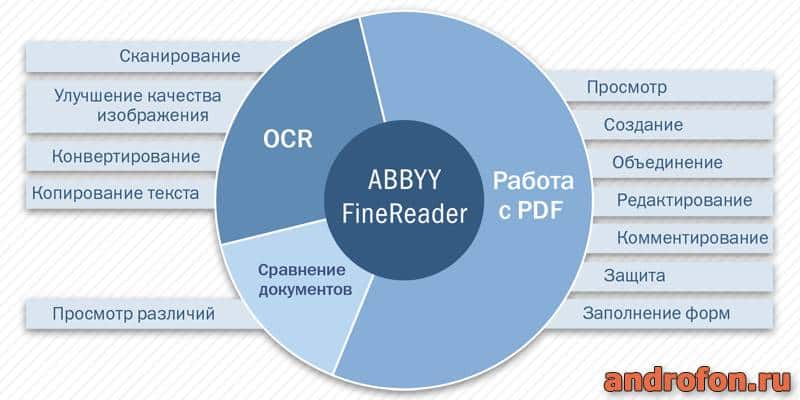
В программе реализована функция сканирования документов. Причем поддерживаются разнообразные модели стационарных сканеров. В качестве сканера также подойдет камера фотоаппарата, что удобно при домашнем использовании или в офисе, где отсутствует стационарный сканер. Перед сканированием документа предлагается выбор конечного формата: PDF, Word, Excel, в виде изображения или другого формата.
Ещё поддерживается функция сравнения документов. Программа анализирует файл в формате PDF, Word, JPEG и т.д., выявляет и подсвечивает различия в двух файлах. При этом такая функция доступна только в версии Enterprise.
Интерфейс программы
Начальное окно FineReader встречает пользователя предложением новой задачи, для чего требуется нажать на одну из вкладок:
Открыть – просмотреть или отредактировать PDF-документ, конвертирование документов в другой формат.
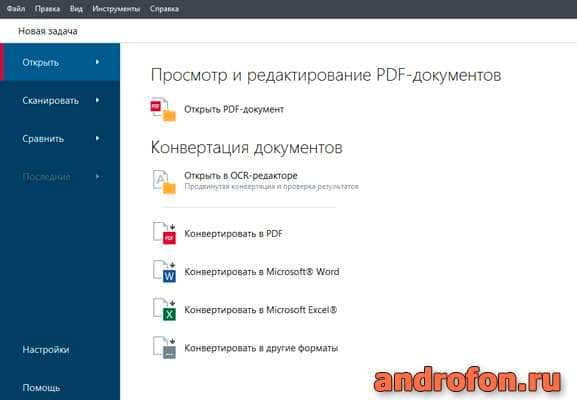
Сканировать – сканирование документов в один из предпочтительных форматов.
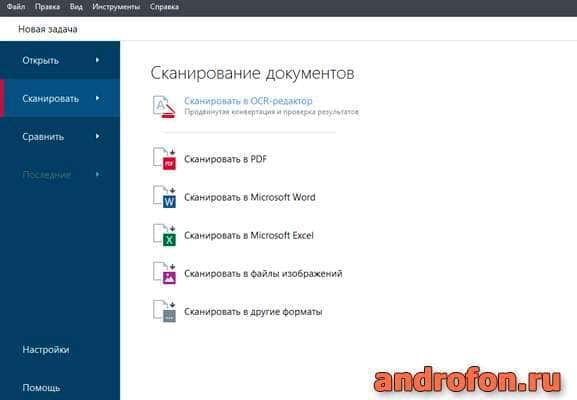
Сравнить – сравнение документов для выявления возможных различий.
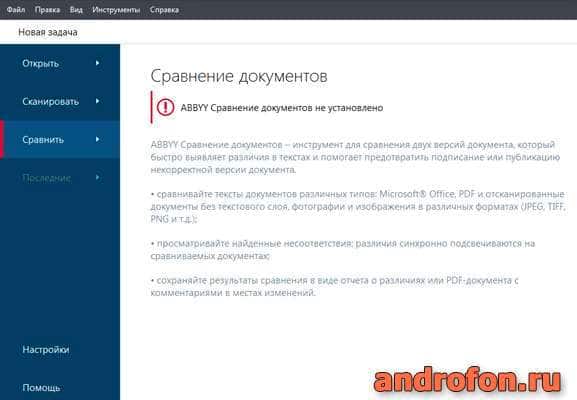
Последние – открытие ранее просмотренных документов.
Так же на главной странице имеется раздел «Настройки» и «Помощь». А ещё функции вышеперечисленных вкладок доступны на строке меню – пункт «Файл».
Работа с документами
При работе с PDF файлами имеются все необходимые инструменты для редактирования документа: добавление, замена, удаление и обрезка страницы; поиск и распознание текста.
Набор инструментов позволяет редактировать текст, добавить водяной знак или изображение, удалить данные либо защитить паролем. Доступно так же сравнение файлов, что актуально для отслеживания изменений в договорах или других документов.
Программа FineReader также поддерживает работу с файлами Word. Документ в формате DOC открылся без проблем, но предварительно конвертировался в PDF для дальнейшего редактирования. По окончанию работы готовый документ легко преобразовать в исходный или любой другой формат.
Сканирование и распознание документов
Внутри FineReader 14 владелец найдет раздел сканирования документов, что поможет перевести файлы из физического состояния в цифровое. Функция полезна для офисного и домашнего применения – сканирование чеков, гарантийных талонов, конспектов, книг и фотографий. Программа позволяет считывать информацию с обычных сканеров и цифровых фотоаппаратов. Последнее пригодится владельцам, что не располагают стационарными сканерами или не часто пользуются функцией сканирования.
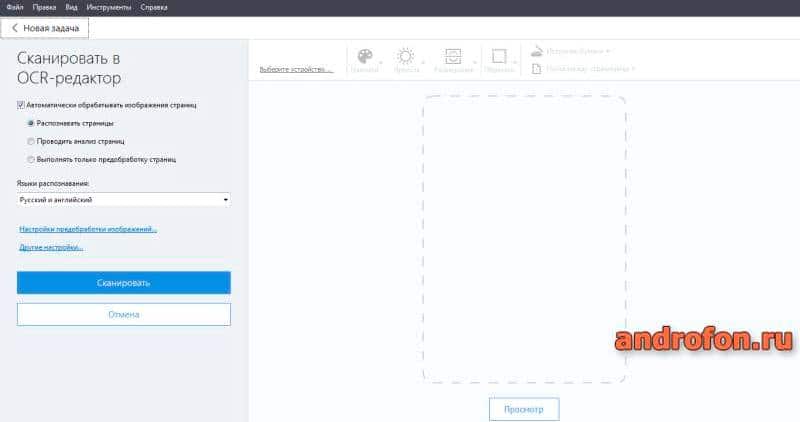
В FineReader 14 реализована функция автоматического сканирования и продвинутого – с конвертацией и проверкой результатов. В первом случае достаточно приложить документ и выбрать конечный тип файла: PDF, Word, Excel, обычное изображение или другой формат. В процессе сканирования предлагается выбрать качество изображения, цветность, яркость и разрешение. А при необходимости обрезать конечный файл.
В случае продвинутой конвертации, файл сканируется в OCR-редактор с предварительным распознанием или анализом страниц и указанием распознаваемого языка. Такой тип сканирования актуален для точного перевода таблиц, книг, журналов, комиксов или манги. Поскольку позволяет отметить любой участок документа и указать тип информации – картинка или текст. А благодаря технологии оптического распознавания программа в точности воссоздаст шрифт и размер текста.
Настройки программы
Раздел настроек не перегружен изобилие параметров, что позволит легко разобраться и начинающему пользователю. Все установки разделены на 6 вкладок:
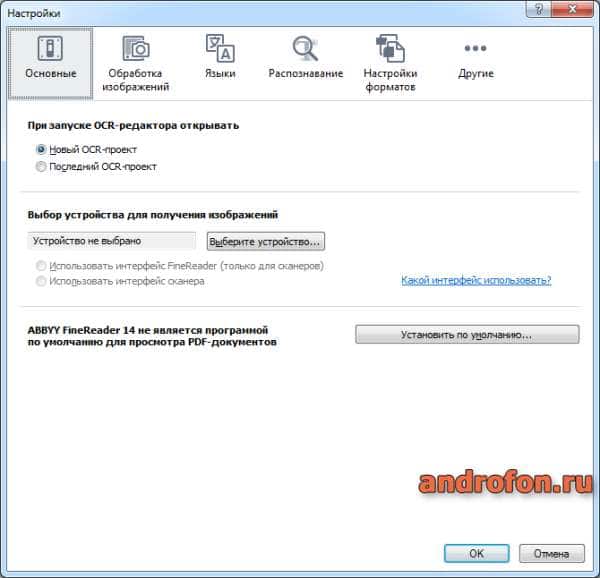
Основные. Задается устройство для получения изображений – сканер или камера. Так же действия при запуске OCR-редактора – новый проект или загрузить последний проект.
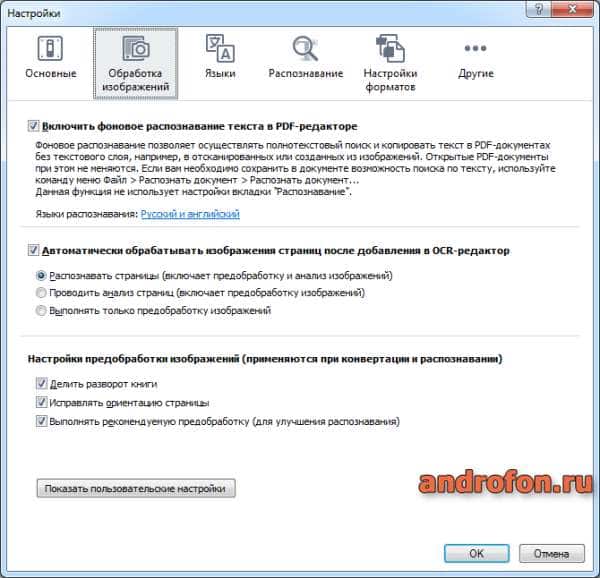
Обработка изображений. Включает параметры фонового распознавания текста в PDF-редакторе. Автоматическая обработка изображения страниц после добавления в OCR-редактор. Так же задаются настройки переработки изображений.
Языки. Выбор языков, что будут распознаны в процессе сканирования документов.
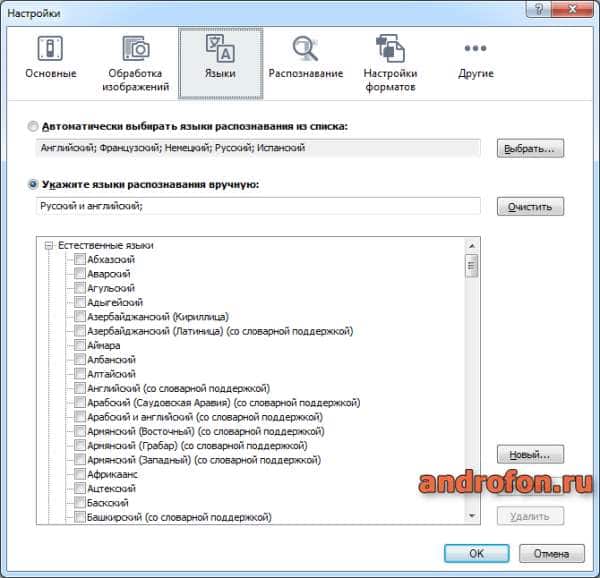
Распознавание. Режимы распознавания PDF. Скорость и качество распознания. Использование эталонов и обучения программы в процессе использования.
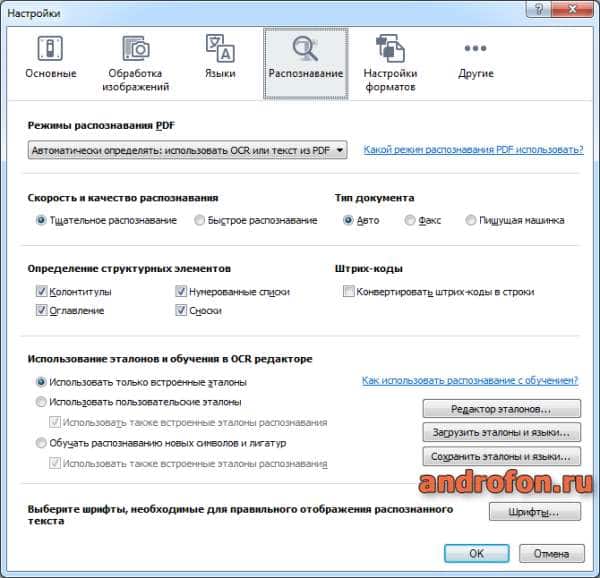
Настройка форматов. Установка качества изображений, текста и т.д. для каждого поддерживаемого формата.
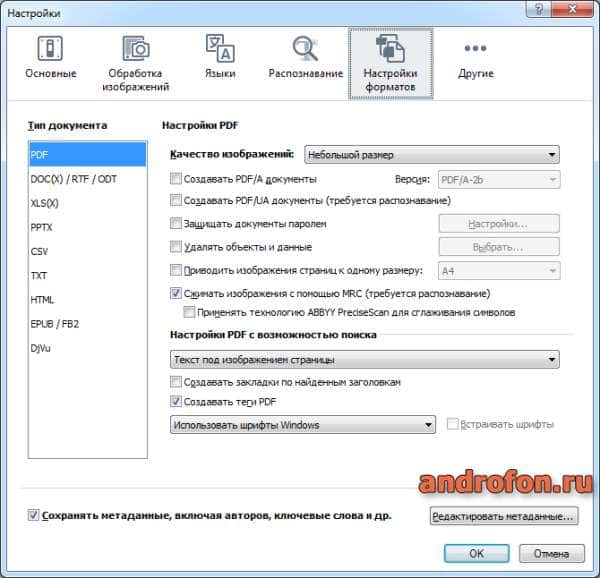
Другие. Региональные настройки и установка FineReader 14 по умолчанию.
Дополнительные модули
В 14-ю редакцию FineReader включены так же три отдельных модуля для отдельного использования:
Comparator – сравнение и поиск различий в документах.
FineReaderOCR – редактор с оптическим распознаванием текста для конвертирования отсканированных файлов в редактируемые форматы.
Screenshot Reader – программа для снятия скриншотов в выделенной области, окна или экрана. Изображение автоматически распознается и конвертируется в текст.
Стоимость и ссылка на скачивание
FineReader выпускается для ОС Windows и MAC на платной основе. Стоимость версии Standard на год – 3990 RUB, бессрочная лицензия – 8690 RUB. Версия Business на год – 6790 RUB или 14990 RUB за бессрочную лицензию. За версию Enterprise придется выложить 22190 RUB в год или 48690 RUB за бессрочную версию. Актуальные цены и другие предложения разработчика смотрите на официальной странице.
Для ознакомления с программой компания ABBYY предлагает для ознакомления пробную версию сроком на 30 дней.
Вывод
Благодаря широкой функциональности ABBYY FineReader 14 пригодится для школьников и студентов, переводчиков манги и комиксов, офисных и корпоративных работников. Удобные инструменты позволят работать с офисной документацией, сканировать и конвертировать документы в различные форматы.
А вам приходилось пользоваться программой FineReader? Поделитесь своим мнением в комментариях.

После короткого рассказа о том, как устроен ABBYY FineReader (aka «теоретическая часть»), самое время перейти к применению полученных знаний. И да, котиков под катом нет: всё очень серьёзно.
Как пользователю поучаствовать в обработке документа
Чтобы не изобретать велосипед, начну с простой и понятной схемы из Справки (см. рисунок справа).
Теперь, зная список всех операций, посмотрим на примерах – что может пойти не по плану и как с этим бороться.
Хорошо распознаются только хорошие изображения
А что делать, когда изображения есть, но не очень хорошие? Улучшить прямо в FineReader всё что можно, а, если улучшить нельзя, — попытаться получить изображение заново, устранив проблему. Поскольку тема очень обширная, то при должном интересе будет отдельный пост про то, как подружиться с автоматическими и ручными инструментами обработки изображений прямо в FineReader. Пока же ограничусь замечанием, что изображение будет обработано лучше, если оно:
- (после сканирования) не имеет выраженных геометрических искажений — перекоса или заметного изгиба страниц толстой книги у корешка двухстраничного разворота,
- (после фотографирования, в дополнение к предыдущему) не имеет ещё и нелинейных геометрических искажений («подушка», «трапеция»), имеет равномерную фокусировку (а желательно и яркость) по всей площади, не имеет шумов от недостаточной освещённости, не имеет выраженной засветки от вспышки (особенно на глянцевой бумаге).
Этап настройки документа/проекта

Можно и нужно сразу указать язык текста, параметры предобработки изображений, некоторые параметры анализа и распознавания. Вот скриншот одной из вкладок диалога настроек.
Эти и прочие настройки подробно описаны в Справке
Этап анализа
Назначение областей разных типов
В пользовательском интерфейсе FineReader доступны области нескольких типов, для них есть разные варианты скрываемой панели свойств (внизу окна «Изображение») и контекстного меню (по щелчку правой кнопкой мыши):
-
«Зона распознавания» (по умолчанию серая рамка) — такое название использовано в пользовательском интерфейсе, на мой взгляд правильнее было бы назвать «область для автоматического анализа». Назначение такой области – указать, где на странице вообще нужно искать что-то полезное. Поэтому в результате последующего анализа или анализа+распознавания в пределах каждой «зоны распознавания» может найтись ноль и более областей других типов. Особенно полезны зоны распознавания бывают в шаблонах блоков (подробнее о них в Справке).

Помните, что в отличие от текстовой области область распознавания может превратиться в области разных типов, что бывало нужно и в этом проекте.
Эти параметры задаются на блок, так что выделять текст разного направления или разной инверсности в один блок – другая плохая идея.
Важные соображения
- Распознавание и синтез видят только те фрагменты текста, которые оказались выделены в текстовые области или текстовые ячейки таблиц. Если кусок текста не выделен в блоки – распознаваться он не будет.
- Аналогично и с картинками — если часть картинки оказалась вне области или одна целостная картинка оказалась разделена на несколько областей – скорее всего, в результате обработки будут проблемы.
- Языки распознавания в FineReader задаются не для галочки – они влияют на очень многие механизмы, начиная уже с анализа: например, иероглифический (китайский, японский, корейский языки) или арабский текст имеют много особенностей, которые учитываются не всегда, а только при выборе соответствующих языков распознавания.
Особенности взаимодействия близкорасположенных или пересекающихся областей
-
Пересечение текстовых и табличных блоков друг с другом, если есть символы или их части, оказавшиеся в более чем одном блоке – практически всегда ошибка, такие результаты анализа нужно исправлять, тем более что обычно это делается в несколько движений мыши.
Пересечение картиночных областей друг с другом – практически всегда ошибка, хотя и менее критичная для обработки именно текста. Такие случаи тоже желательно исправлять.



Текстовая область на фоне «картиночной» области — тоже важный инструмент: на фоне обычных картиночных областей могут находиться подписи к ним, на «фоновых» картиночных областях может располагаться и основной («колоночный») текст документа, а также таблицы.
Примеры правильного использования текстовых областей на фоне картинок
Маленькие хитрости для облегчения работы с блоками
Описанные соглашения отражены в поведении редактора блоков. Например, если вы рисуете новый или растягиваете имеющийся блок так, что он полностью или почти полностью перекрывает другие блоки — эти другие блоки автоматически удаляются.
Логичность/нелогичность выделения областей
Тут самое время подумать — для каких целей и какого формата документ хочется получить в результате обработки. Вот некоторые соображения, влияющие на количество и характер исправлений разметки блоков в сложных случаях:
Вариант 1: нам нужен только текст (возможно, мы этого не понимаем, но дело обстоит именно так)
- нет «мусорных» областей, где в качестве текста или таблиц распознаются (мусором) элементы картинок или элементов оформления страницы.
- области логично выделяют строки, не допуская попадания символов в более чем одну область и неоправданного дробления строк на более чем одну область.
- то, что с точки зрения человека является таблицами в оригинале, должно быть выделено в табличные области. Это влияет как на качество распознавания (например, базовые линии строк в разных ячейках могут быть не выровнены по вертикали), так и на удобство поиска и копирования фрагментов текста в выходном документе.
Если отдельные картинки не должны копироваться из выходного PDF-документа – то такие области можно из документа исключить вовсе (не создавать новые и не оставлять найденные автоматикой, как минимум – удалять нелогично найденные картинки, а если не лень – то и все).
Я надеюсь шире и глубже раскрыть тему «разумности» картинок в статье про сохранение документов — если такая будет интересна читателям данного материала.
Вариант 2: нужно всё и сразу
Если документ, включающий не одно лишь текстовое содержимое (в одну или две колонки), предполагается сохранить сразу как электронную книгу в форматах FB2/e-pub или в любой промежуточный редактируемый формат (Вордовый или HTML) для дальнейшего редактирования и производства электронной книги, то осмысленное выделение таблиц и картинок становится особенно важно.
Среди прочего нужно определиться с тем, что делать с группами рядом расположенных картинок, и что делать с подписями к картинкам, как рядом стоящими, так и накладывающимися на картинки. Подробнее разберём эту тему в «Практикуме», на реальных примерах.
Читайте также: