
Bash если размер файла больше
Обновлено: 04.07.2024
В первой части статьи мы рассмотрели командные оболочки, профили, синонимы и первые команды. Под спойлером я также рассказал, как развернуть тестовую виртуальную машину.
В этой части речь пойдет о файлах скриптов, их параметрах и правах доступа. Также я расскажу про операторы условного выполнения, выбора и циклы.
Скрипты
Для выполнения нескольких команд одним вызовом удобно использовать скрипты. Скрипт – это текстовый файл, содержащий команды для shell. Это могут быть как внутренние команды shell, так и вызовы внешних исполняемых файлов.
Как правило, имя файла скрипта имеет окончание .sh, но это не является обязательным требованием и используется лишь для того, чтобы пользователю было удобнее ориентироваться по имени файла. Для интерпретатора более важным является содержимое файла, а также права доступа к нему.
Перейдем в домашнюю директорию командой cd
и создадим в ней с помощью редактора nano ( nano script.sh )файл, содержащий 2 строки:
Чтобы выйти из редактора nano после набора текста скрипта, нужно нажать Ctrl+X, далее на вопрос "Save modified buffer?" нажать Y, далее на запрос "File Name to Write:" нажать Enter. При желании можно использовать любой другой текстовый редактор.
Скрипт запускается командой ./<имя_файла> , т.е. ./ перед именем файла указывает на то, что нужно выполнить скрипт или исполняемый файл, находящийся в текущей директории. Если выполнить команду script.sh , то будет выдана ошибка, т.к. оболочка будет искать файл в директориях, указанных в переменной среды PATH, а также среди встроенных команд (таких, как, например, pwd):
Ошибки не будет, если выполнять скрипт с указанием абсолютного пути, но данный подход является менее универсальным: /home/user/script.sh . Однако на данном этапе при попытке выполнить созданный файл будет выдана ошибка:
Проверим права доступа к файлу:
Из вывода команды ls видно, что отсутствуют права на выполнение. Рассмотрим подробнее на картинке:

Права доступа задаются тремя наборами: для пользователя, которому принадлежит файл; для группы, в которую входит пользователь; и для всех остальных. Здесь r, w и x означают соответственно доступ на чтение, запись и выполнение.
В нашем примере пользователь (test) имеет доступ на чтение и запись, группа также имеет доступ на чтение и запись, все остальные – только на чтение. Эти права выданы в соответствии с правами, заданными по умолчанию, которые можно проверить командой umask -S . Изменить права по умолчанию можно, добавив вызов команды umask с нужными параметрами в файл профиля пользователя (файл
/.profile), либо для всех пользователей в общесистемный профиль (файл /etc/profile).
Для того, чтобы установить права, используется команда chmod <параметры> <имя_файла> . Например, чтобы выдать права на выполнение файла всем пользователям, нужно выполнить команду:
Чтобы выдать права на чтение и выполнение пользователю и группе:
Чтобы запретить доступ на запись (изменение содержимого) файла всем:
Также для указания прав можно использовать маску. Например, чтобы разрешить права на чтение, запись, выполнение пользователю, чтение и выполнение группе, и чтение – для остальных, нужно выполнить:
Будут выданы права -rwxr-xr-- :
Указывая 3 цифры, мы задаем соответствующие маски для каждой из трех групп. Переведя цифру в двоичную систему, можно понять, каким правам она соответствует. Иллюстрация для нашего примера:

Символ – перед наборами прав доступа указывает на тип файла ( – означает обычный файл, d – директория, l – ссылка, c – символьное устройство, b – блочное устройство, и т. д.). Соответствие числа, его двоичного представления и прав доступ можно представить в виде таблицы:
Я новый пользователь сценариев оболочки bash. Как узнать размер файла в моем сценарии оболочки bash и сохранить этот размер файла в переменной оболочки bash?
3 января стартует курс «SQL-injection Master» © от команды The Codeby
За 3 месяца вы пройдете путь от начальных навыков работы с SQL-запросами к базам данных до продвинутых техник. Научитесь находить уязвимости связанные с базами данных, и внедрять произвольный SQL-код в уязвимые приложения.
На последнюю неделю приходится экзамен, где нужно будет показать свои навыки, взломав ряд уязвимых учебных сайтов, и добыть флаги. Успешно сдавшие экзамен получат сертификат.
Запись на курс до 10 января. Подробнее .
Как проверить размер файла в unix с помощью команды wc
Команда wc показывает количество строк, слов и байтов, содержащихся в файле. Для получения размера файла, используйте синтаксис, который выглядит следующим образом:
Примеры возможных выводов данных:
Вы может с легкостью извлечь первое поле, используя или команду cut или команду awk:
Примеры возможных выводов данных:
или присвоить этот размер переменной bash:
Как узнать размер файла в сценарии bash, используя команду stat
Команда stat показывает информацию о файле. Используйте следующий синтаксис для того, чтобы узнать размер файла на GNU/Linux с помощью команды stat:
Чтобы присвоить этот размер переменной bash:
Используйте следующий синтаксис для того, чтобы узнать размер файла на BSD/MacOS с помощью команды
Обратите внимание, что если файл является символьной ссылкой, вы получите размер этой ссылки только с помощью команды stat.
Примеры команды du
Синтаксис выглядит следующим образом
Примеры возможных выводов данных указанных выше команд:
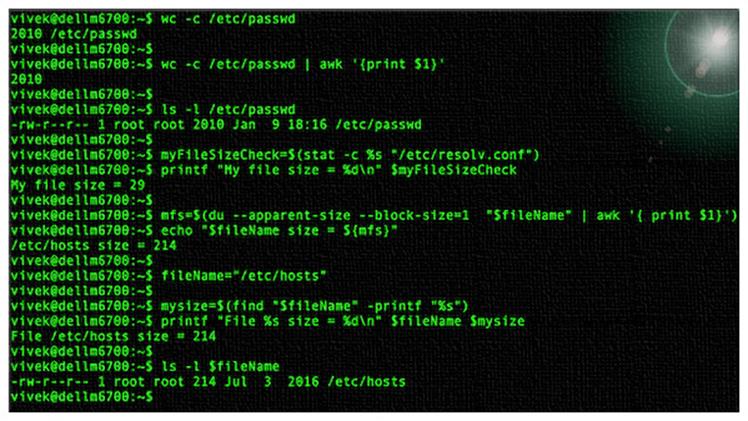
Рисунок 01: Как проверить размер файла с помощью оболочки bash/ksh/zsh/sh/tcsh?
Найдите пример команды
Синтаксис выглядит следующим образом:
1 декабря стартует зимний поток курса " Тестирование Веб-Приложений на проникновение " от команды codeby . Общая теория, подготовка рабочего окружения, пассивный фаззинг и фингерпринт, активный фаззинг, уязвимости, пост-эксплуатация, инструментальные средства, Social Engeneering и многое другое. На курс можно записаться до 10 декабря включительно. Подробнее .
У меня есть сценарий, который проверяет размер файла 0, но я подумал, что должен быть более простой способ проверить размер файлов. Т.е. file.txt обычно составляет 100 КБ; как заставить скрипт проверять, меньше ли он 90 КБ (включая 0), и заставить его получить новую копию, потому что в этом случае файл поврежден.
Чем я сейчас пользуюсь ..
[ -n file.txt ] не проверяет свой размер, он проверяет, что строка file.txt имеет ненулевую длину, поэтому всегда будет успешно.
Если вы хотите сказать, что размер не равен нулю, вам понадобится [ -s file.txt ] .
Чтобы получить размер файла, вы можете использовать wc -c , чтобы получить размер (длину файла) в байтах:
В данном случае это похоже на то, что вы хотите.
Но к вашему сведению, если вы хотите знать, сколько дискового пространства использует файл, вы можете использовать du -k , чтобы получить размер (используемое дисковое пространство) в килобайтах:
Если вам нужен больший контроль над форматом вывода, вы также можете посмотреть stat . В Linux вы должны начать с чего-то вроде stat -c '%s' file.txt , а в BSD / Mac OS X с чего-то вроде stat -f '%z' file.txt .
Хорошо, если вы используете Mac, сделайте следующее: stat -f %z "/Users/Example/config.log" Это оно!
Я бы использовал для этого du --threshold . Не уверен, что эта опция доступна во всех версиях du , но она реализована в версии GNU.
Цитата из руководства du (1):
Вот мое решение, использующее du --threshold= для варианта использования OP:
Преимущество этого состоит в том, что du может принимать аргумент для этой опции в известном формате - будь то человеческий, как в 10K , 10MiB , или то, что вам удобно - вы не делаете » Нет необходимости вручную преобразовывать форматы / единицы измерения, поскольку du это обрабатывает.
Для справки, вот объяснение этого аргумента SIZE на странице руководства:
Предполагая, что команда ls сообщает размер файла в столбце №6
Основываясь на ответе gniourf_gniourf,
Запишет file.txt в стандартный вывод тогда и только тогда, когда размер file.txt меньше 90 КБ, и
Выполнит команду command , если file.txt имеет размер менее 90 КБ. Я тестировал это в Linux. Из find(1) ,
… Аргументы командной строки, следующие за (параметры -H , -L и -P ), считаются именами файлов или каталогов до первого аргумента, который начинается с '-', .
Для получения размера файла как в Linux, так и в Mac OS X (и, предположительно, в других BSD) существует не так много вариантов, и большинство из предложенных здесь будут работать только в одной системе.
что работает в Bash для Linux и Mac :
Другие ответы отлично работают в Linux, но не в Mac:
du не имеет параметра -b в Mac, и трюк BLOCKSIZE = 1 не работает («минимальный размер блока равен 512», что приводит к неверному результату)
cut -d' ' -f1 не работает, потому что на Mac номер может быть выровнен по правому краю и дополнен пробелами впереди.
Так что, если вам нужно что-то гибкое, это либо оператор perl -s , либо wc -c , переданный по конвейеру в awk '' (awk проигнорирует начальный пробел).
И, конечно же, что касается остальной части вашего исходного вопроса, используйте оператор -lt (или -gt ):
if [ $size -lt $your_wanted_size ]; then и т. Д.
Портативный, все разновидности питона, избегает вариаций в диалектах статов
Это работает как в Linux, так и в MacOS.
stat , похоже, делает это с наименьшим количеством системных вызовов:
Если вы ищете только размер файла:
Если ваш find поддерживает этот синтаксис, вы можете использовать его:
Это выведет file.txt на стандартный вывод тогда и только тогда, когда размер file.txt меньше 90 КБ. Чтобы выполнить сценарий script , если file.txt имеет размер менее 90 КБ:
Альтернативное решение с awk и двойными скобками:
Меня удивляет, что никто не упомянул stat , чтобы проверить размер файла. Некоторые методы определенно лучше: использовать -s , чтобы узнать, пуст файл или нет, проще, чем что-либо еще, если это все, что вам нужно. И если вы хотите найти файлы определенного размера, то find , безусловно, вам подойдет.
Мне также очень нравится du получать размер файла в килобайтах, но для байтов я бы использовал stat :
Как назначить это переменной bash, чтобы впоследствии использовать ее?
Лучше всего, если в системе GNU:
ПРИМЕЧАНИЕ: см. @chbrown ниже ответ, как использовать stat в терминале в Mac OS X или
Проблема с использованием stat заключается в том, что это расширение GNU (Linux). du -k и cut -f1 задаются POSIX и поэтому переносятся в любую систему Unix.
Solaris, например, поставляется с bash, но не с stat . Так что это не совсем гипотетически.
ls имеет аналогичную проблему, так как точный формат вывода не указан, поэтому синтаксический анализ его вывода не может выполняться портативно. du -h также является расширением GNU.
Придерживайтесь переносных конструкций, где это возможно, и вы сделаете чью-то жизнь проще в будущем. Возможно, ваш собственный.
Вы также можете использовать команду «count count» ( wc ):
Проблема с wc заключается в том, что она добавит имя файла и сделает отступ выходным. Например:
Если вы хотите избежать связывания полного интерпретируемого языка или редактора потока только для получения количества файлов, просто перенаправьте входные данные из файла, чтобы wc никогда не видел имя файла:
Эта последняя форма может использоваться с подстановкой команд, чтобы легко получить значение, которое вы искали в качестве переменной оболочки, как указано Жиль ниже.
BSD (Mac OS X) stat имеет другой флаг аргументов формата и разные спецификаторы полей. Из man stat(1) :
- -f format : отображение информации в указанном формате. См. Раздел FORMATS для описания допустимых форматов.
- . раздел FORMATS .
- z : размер файла в байтах.
Итак, теперь все вместе:
Этот сценарий сочетает в себе множество способов расчета размера файла:
Скрипт работает во многих Unix-системах, включая Linux, BSD, OSX, Solaris, SunOS и т. д.
Размер файла показывает количество байтов. Это видимый размер, который представляет собой байты, которые файл использует на типичном диске, без специального сжатия или специальных разреженных областей или нераспределенных блоков и т. Д.
Зависит от того, что вы подразумеваете под size .
предоставит вам количество байтов, которые можно прочитать из файла. IOW, это размер содержимого файла. Однако он прочитает содержимое файла (за исключением того, что файл является обычным файлом или символической ссылкой на обычный файл в большинстве реализаций wc в качестве оптимизации). Это может иметь побочные эффекты. Например, для именованного канала то, что было прочитано, больше не может быть прочитано снова и для таких вещей, как /dev/zero или /dev/random , которые имеют бесконечный размер , это займет некоторое время. Это также означает, что вам нужен read доступ к файлу.
Это стандартная и портативная, однако обратите внимание, что некоторые реализации wc могут включать в себя ведущие пробелы в этом выпуске. Один из способов избавиться от них - использовать:
или во избежание ошибки о пустом арифметическом выражении в dash или yash , когда wc не выводит результат (например, когда файл может " t будет открыт):
ksh93 имеет встроенный wc (при включении его вы также можете вызвать его как команду command /opt/ast/bin/wc ) что делает его наиболее эффективным для обычных файлов в этой оболочке.
В разных системах есть команда под названием stat , которая является интерфейсом к системным вызовам stat() или lstat() .
Данные отчета, найденные в inode. Одна из этих данных - это атрибут st_size . Для обычных файлов это размер содержимого (сколько данных можно было прочитать из него при отсутствии ошибки (это то, что используют большинство wc -c ) в своей оптимизации)). Для символических ссылок это размер в байтах целевого пути. Для именованных каналов, в зависимости от системы, это либо 0, либо количество байтов, находящихся в настоящее время в буфере канала. То же самое для блочных устройств, где в зависимости от системы вы получаете 0 или размер в байтах базового хранилища.
Вам не нужно разрешение на чтение файла для получения этой информации, только разрешение на поиск в каталоге, к которому он привязан.
По хронологическому порядку:
возвращает st_size атрибут $file ( lstat() ) или:
то же самое, за исключением случаев, когда $file является символической ссылкой, и в этом случае это символ st_size файла после разрешения символической ссылки.
zsh stat builtin (теперь также известный как stat ) в модуле zstat (загружается с помощью zsh/stat ) (1997):
или сохранить в переменной:
, очевидно, это наиболее эффективно в этой оболочке.
GNU stat -L -A size +size -- $file (2001); также в BusyBox stat с 2005 года (скопировано из GNU stat ):
AIX также имеет perl -le 'print((lstat shift)[7])' -- "$file" , который выведет все istat (не stat() , поэтому не будет работать с символическими ссылками), и что вы может выполнять пост-обработку, например:
В LC_ALL=C istat "$file" | awk 'NR == 4 ' :
(размер после разрешения символической ссылки)
Задолго до того, как GNU представила свой @ size = -Z $file:q команды, то же самое можно было бы сделать с помощью команды GNU stat с ее предикатом find (уже в 1991 году):
Стандартная команда для получения информации ( / stat() : lstat() .
POSIXly, вы можете сделать:
и добавьте LC_ALL=C ls -dn -- "$file" | awk '' для него после разрешения symlink. Это не работает для файлов устройств, хотя поле 5 th является основным номером устройства, а не размером.
Для блочных устройств, систем, где -L возвращает 0 для stat() , обычно имеют другие API-интерфейсы, чтобы сообщать размер блочного устройства. Например, Linux имеет st_size BLKGETSIZE64 , и большинство дистрибутивов Linux теперь поставляются с командой ioctl() , которая может ее использовать:
Однако для этого вам требуется разрешение на чтение файла устройства. Обычно можно получить размер другими способами. Например (еще в Linux):
Должна работать, кроме пустых устройств.
Подход, который работает для всех файлов с возможностью поиска (включая обычные файлы, большинство блочных устройств и некоторые символьные устройства), заключается в том, чтобы открыть файл и найти его до конца:
С помощью lsblk -bdno size -- "$device_file" (после загрузки модуля zsh ):
Для именованных каналов мы видели, что некоторые системы (AIX, Solaris, HP /UX, по крайней мере) делают объем данных в буфере каналов доступным в perl -le 'seek STDIN, 0, 2 or die "seek: $!"; print tell STDIN' < "$file" ' stat() . Некоторые (например, Linux или FreeBSD) этого не делают.
В Linux, по крайней мере, вы можете использовать st_size FIONREAD после открытия канала (в режиме чтения + записи, чтобы избежать его зависания):
Однако обратите внимание, что, хотя он не читает содержимое канала, простое открытие именованного канала здесь может по-прежнему иметь побочные эффекты. Мы используем fuser -s -- "$fifo_file" && perl -le 'require "sys/ioctl.ph"; ioctl(STDIN, &FIONREAD, $n) or die$!; print unpack "L", $n' <> "$fifo_file" , чтобы сначала проверить, что в каком-то процессе уже открыт канал, чтобы облегчить это, но это не является надежным, поскольку fuser , возможно, не сможет проверить все процессы.
Теперь мы рассматриваем только размер первичных данных, связанных с файлами. Это не учитывает размер метаданных и всю вспомогательную инфраструктуру, необходимую для хранения этого файла.
Другой атрибут inode, возвращаемый fuser , это stat() . Это число блоков по 512 байт, которые используются для хранения данных файла (а иногда и некоторых его метаданных, таких как расширенные атрибуты файловых систем ext4 в Linux). Это не включает сам индекс или записи в каталогах, к которым связан файл.
Размер и использование диска не обязательно тесно связаны с сжатием, редкостью (иногда некоторыми метаданными), дополнительная инфраструктура, такая как косвенные блоки в некоторых файловых системах, влияет на последних.
Обычно для использования дискового пространства используется st_blocks . Большинство команд, перечисленных выше, смогут получить эту информацию.
- du
- POSIXLY_CORRECT=1 ls -sd -- "$file" | awk '' (не для каталогов, где это будет включать использование файлов в файлах внутри).
- GNU POSIXLY_CORRECT=1 du -s -- "$file"
- find -- "$file" -printf '%b\n'
- GNU zstat -L +block -- $file
- BSD stat -c %b -- "$file"
- stat -f %b -- "$file"
ls -l filename предоставит вам много информации о файле, включая его размер файла, разрешения и владельца.
Размер файла в пятом столбце и отображается в байтах. В приведенном ниже примере размер файла составляет менее 2 КБ:
Изменить: Это, по-видимому, не так надежно, как команда stat .
Читайте также: