
Чем ограничен размер адресуемой памяти
Обновлено: 05.07.2024
Содержание
Методы адресации [2]
Адресное пространство
Исполнение программ
Кодирование адресов
Вычисление адресов
Способы адресации
Подразумеваемый операнд
В команде может не содержаться явных указаний об операнде; в этом случае операнд подразумевается и фактически задается кодом операции команды.
Подразумеваемый адрес
В команде может не содержаться явных указаний об адресе участвующего в операции операнда или адреса, по которому должен быть размещен результат операции, но этот адрес подразумевается.
Непосредственная адресация
В команде содержится не адрес операнда, а непосредственно сам операнд. При непосредственной адресации не требуется обращения к памяти для выборки операнда и ячейки памяти для его хранения. Это способствует уменьшению времени выполнения программы и занимаемого ею объёма памяти. Непосредственная адресация удобна для хранения различного рода констант.
Прямая адресация
Относительная (базовая) адресация
Относительная адресация позволяет при меньшей длине адресного кода команды обеспечить доступ к любой ячейке памяти. Для этого число разрядов в базовом регистре выбирают таким, чтобы можно было адресовать любую ячейку оперативной памяти, а адресный код команды используют для представления лишь сравнительно короткого «смещения». Смещение определяет положение операнда относительно начала массива, задаваемого базовым адресом.
Укороченная адресация
В адресном поле командного слова содержатся только младшие разряды адресуемой ячейки. Дополнительный указательный регистр.
- Адресация с регистром страницы является примером сокращённой адресации. При этом вся память разбивается на блоки-страницы. Размер страницы диктуется длиной адресного поля.
Регистровая адресация
Регистровая адресация является частным случаем укороченной. Применяется, когда промежуточные результаты хранятся в одном из рабочих регистров центрального процессора. Поскольку регистров значительно меньше чем ячеек памяти, то небольшого адресного поля может хватить для адресации.
Косвенная адресация
Адресный код команды в этом случае указывает адрес ячейки памяти, в которой находится адрес операнда или команды. Косвенная адресация широко используется в малых и микроЭВМ, имеющих короткое машинное слово, для преодоления ограничений короткого формата команды (совместно используются регистровая и косвенная адресация).
Адресация слов переменной длины
Эффективность вычислительных систем, предназначенных для обработки данных, повышается, если имеется возможность выполнять операции со словами переменной длины. В этом случае в машине может быть предусмотрена адресация слов переменной длины, которая обычно реализуется путем указания в команде местоположения в памяти начала слова и его длины.
Стековая адресация
Стековая память, реализующая безадресное задание операндов, особенно широко используется в микропроцессорах и Мини-ЭВМ.
Автоинкрементная и автодекрементная адресации
Поскольку регистровая косвенная адресация требует предварительной загрузки регистра косвенным адресом из оперативной памяти, что связано с потерей времени, такой тип адресации особенно эффективен при обработке массива данных, если имеется механизм автоматического приращения или уменьшения содержимого регистра при каждом обращении к нему. Такой механизм называется соответственно автоинкрементной и автодекрементной адресацией. В этом случае достаточно один раз загрузить в регистр адрес первого обрабатываемого элемента массива, а затем при каждом обращении к регистру в нём будет формироваться адрес следующего элемента массива.
При автоинкрементной адресации сначала содержимое регистра используется как адрес операнда, а затем получает приращение, равное числу байт в элементе массива. При автодекрементной адресации сначала содержимое указанного в команде регистра уменьшается на число байт в элементе массива, а затем используется как адрес операнда.
Индексация
Для реализуемых на ЭВМ методов решения математических задач и обработки данных характерна цикличность вычислительных процессов, когда одни и те же процедуры выполняются над различными операндами, упорядоченно расположенными в памяти. Поскольку операнды, обрабатываемые при повторениях цикла, имеют разные адреса, без использования индексации требовалось бы для каждого повторения составлять свою последовательность команд, отличающихся адресными частями.
Программирование циклов существенно упрощается, если после каждого выполнения цикла обеспечено автоматическое изменение в соответствующих командах их адресных частей согласно расположению в памяти обрабатываемых операндов. Такой процесс называется модификацией команд, и основан на возможности выполнения над кодами команд арифметических и логических операций.
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents Loading
Copy raw contents
Copy raw contents
Аппаратное управление памятью
Большинство компьютеров используют большое количество различных запоминающих устройств, таких как: ПЗУ, ОЗУ, жесткие диски, магнитные носители и т.д. Все они представляют собой виды памяти, которые доступны через разные интерфейсы. Два основных интерфейса — это прямая адресация процессором и файловые системы. Прямая адресация подразумевает, что адрес ячейки с данными может быть аргументом инструкций процессора.
Режимы работы процессора x86:
- реальный — прямой доступ к памяти по физическому адресу
- защищенный — использование виртуальной памяти и колец процессора для разграничения доступа к ней
Виртуальная память — это подход к управлению памятью компьютером, который скрывает физическую память (в различных формах, таких как: оперативная память, ПЗУ или жесткие диски) за единым интерфейсом, позволяя создавать программы, которые работают с ними как с единым непрерывным массивом памяти с произвольным доступом.
- поддержка изоляции процессов и защиты памяти путём создания своего собственного виртуального адресного пространства для каждого процесса
- поддержка изоляции области ядра от кода пользовательского режима
- поддержка памяти только для чтения и с запретом на исполненение
- поддержка выгрузки не используемых участков памяти в область подкачки на диске (свопинг)
- поддержка отображённых в память файлов, в том числе загрузочных модулей
- поддержка разделяемой между процессами памяти, в том числе с копированием-при-записи для экономии физических страниц

Виды адресов памяти:
- физический - адрес аппаратной ячейки памяти
- логический - виртуальный адрес, которым оперирует приложение

Кроме того, этот дополнительный уровень позволяет через тот же самый интерфейс обращения к данным по адресу в памяти реализовать другие функции, такие как обращение к данным в файле (через механизм mmap ) и т.д. Наконец, он позволяет обеспечить более гибкое, эффективное и безопасное управление памятью компьютера, чем при использовании физической памяти напрямую.
На аппаратном уровне виртуальная память, как правило, поддерживается специальным устройством — Модулем управления памятью.
Страничная организация памяти
Страничная память — способ организации виртуальной памяти, при котором единицей отображения виртуальных адресов на физические является регион постоянного размера — страница.

При использовании страничной модели вся виртуальная память делится на N страниц таким образом, что часть виртуального адреса интерпретируется как номер страницы, а часть — как смещение внутри страницы. Вся физическая память также разделяется на блоки такого же размера — фреймы. Таким образом в один фрейм может быть загружена одна страница. Свопинг — это выгрузка страницы из памяти на диск (или другой носитель большего объема), который используется тогда, когда все фреймы заняты. При этом под свопинг попадают страницы памяти неактивных на данный момент процессов.


Размер страницы и количество страниц зависит от того, какая часть адреса выделяется на номер страницы, а какая на смещение. К примеру, если в 32-разрядной системе разбить адрес на две равные половины, то количество страниц будет составлять 2^16, т.е. 65536, и размер страницы в байтах будет таким же, т.е. 64 КБ. Если уменьшить количество страниц до 2^12, то в системе будет 4096 страницы по 1МБ, а если увеличить до 2^20, то 1 миллион страниц по 4КБ. Чем больше в системе страниц, тем больше занимает в памяти таблица страниц, соответственно работа процессора с ней замедляется. А поскольку каждое обращение к памяти требует обращения к таблице страниц для трансляции виртуального адреса, такое замедление очень нежелательно. С другой стороны, чем меньше страниц и, соотвественно, чем они больше по объему — тем больше потери памяти, вызванные внутренней фрагментацией страниц, поскольку страница является единицей выделения памяти. В этом заключается диллема оптимизации страничной памяти. Она особенно актуальна при переходе к 64-разрядным архитектурам.
Для оптимизации страничной памяти используются следующие подходы:
- специальный кеш — TLB (translation lookaside buffer) — в котором хранится очень небольшое число (порядка 64) наиболее часто используемых адресов страниц (основные страницы, к которым постоянно обращается ОС)
- многоуровневая (2, 3 уровня) таблица страниц — в этом случае виртуальный адрес разбивается не на 2, а на 3 (4. ) части. Последняя часть остается смещением внутри страницы, а каждая из остальных задает номер страницы в таблице страниц 1-го, 2-го и т.д. уровней. В этой схеме для трансляции адресов нужно выполнить не 1 обращение к таблице страниц, а 2 и более. С другой стороны, это позволяет свопить таблицы страниц 2-го и т.д. уровней, и подгружать в память только те таблицы, которые нужны текущему процессу в текущий момент времени или же даже кешировать их. А каждая из таблиц отдельного уровня имеет существенно меньший размер, чем имела бы одна таблица, если бы уровень был один

- инвертированная таблица страниц — в ней столько записей, сколько в системе фреймов, а не страниц, и индексом является номер фрейма: а число фреймов в 64- и более разрядных архитектурах существенно меньше теоретически возможного числа страниц. Проблема такого подхода — долгий поиск виртуального адреса. Она решается с помощью таких механизмов как: хеш-таблицы или кластерные таблицы страниц
Сегментная организация памяти
Сегментная организация виртуальной памяти реализует следующий механизм: вся память делиться на сегменты фиксированной или произвольной длины, каждый из которых характеризуется своим начальным адресом — базой или селектором. Виртуальный адрес в такой системе состоит из 2-х компонент: базы сегмента, к которому мы хотим обратиться, и смещения внутри сегмента. Физический адрес вычисляется по формуле:

Историческая модель сегментации в архитектуре х86
В архитектуре х86 сегментная модель памяти была впервые реализована на 16-разрядных процессорах 8086. Используя только 16 разрядов для адреса давало возможность адресовать только 2^16 байт, т.е. 64КБ памяти. В то же время стандартный размер физической памяти для этих процессоров был 1МБ. Для того, чтобы иметь возможность работать со всем доступным объемом памяти и была использована сегментная модель. В ней у процессора было выделено 4 специализированных регистра CS (сегмент кода), SS (сегмент стека), DS (сегмент данных), ES (расширенный сегмент) для хранения базы текущего сегмента (для кода, стека и данных программы).
Физический адрес в такой системе расчитывался по формуле:
Это приводило к возможности адресовать большие адреса, чем 1МБ — т.н. Gate A20.
Плоская модель сегментации
32-разрядный процессор 80386 мог адресовать 2^32 байт памяти, т.е. 4ГБ, что более чем перекрывало доступные на тот момент размеры физической памяти, поэтому изначальная причина для использования сегментной организации памяти отпала.
Однако, помимо особого способа адресации сегментная модель также предоставляет механизм защиты памяти через кольца безопасности процессора: для каждого сегмента в таблице сегментов задается значение допустимого уровня привилегий (DPL), а при обращении к сегменту передается уровень привилегий текущей программы (запрошенный уровень привилегий, RPL) и, если RPL > DPL доступ к памяти запрещен. Таким образом обеспечивается защита сегментов памяти ядра ОС, которые имеют DPL = 0 . Также в таблице сегментов задаються другие атрибуты сегментов, такие как возможность записи в память, возможность исполнения кода из нее и т.д.
Таблица сегментов каждого процесса находится в памяти, а ее начальный адрес загружается в регистр LDTR процессора. В регистре GDTR процессора хранится указатель на глобальную таблицу сегментов.
В современных процессорах x86 используется "Плоская модель сегментации", в которой база всех сегментов выставлена в нулевой адрес.

Виртуальная память в архитектуре x86

Системные вызовы для взаимодействия с подсистемой виртуальной памяти:
- brk , sbrk - для увеличения сегмента памяти, выделенного для данных программы
- mmap , mremap , munmap - для отображения файла или устройства в память
- mprotect - изменение прав доступа к областям памяти процесса
Пример выделение памяти процессу:

Алгоритмы выделения памяти
Эффективное выделение памяти предполагает быстрое (за 1 или несколько операций) нахождение свободного участка памяти нужного размера.
Способы учета свободных участков:
- битовая карта (bitmap) — каждому блоку памяти (например, странице) ставится в соответствие 1 бит, который имеет значение занят/свободен
- связный список — каждому непрерывному набору блоков памяти одного типа (занят/свободен) ставится в соответствеи 1 запись в связном списке блоков, в которой указывается начало и размер участка
- использование нескольких связных списков для участков разных размеров — см. алгоритм Buddy allocation
Кеш — это компонент компьютерной системы, который прозрачно хранит данные так, чтобы последующие запросы к ним могли быть удовлетворены быстрее. Наличие кеша подразумевает также наличие запоминающего устройства (гораздо) большего размера, в которых данные хранятся изначально. Запросы на получение данных из этого устройства прозрачно проходят через кеш в том смысле, что если этих данных нет в кеше, то они запрашиваются из основного устройства и параллельно записываются в кеш. Соответственно, при последующем обращении данные могут быть извлечены уже из кеша. За счет намного меньшего размера кеш может быть сделан намного быстрее и в этом основная цель его существования.
По принципу записи данных в кеш выделяют:
- сквозной (write-through) — данные записываются синхронно и в кеш, и непосредственно в запоминающее устрйоство
- с обратной записью (write-back, write-behind) — данные записываются в кещ и иногда синхронизируются с запоминающим устройством
По принципу хранения данных выделяют:
- полностью ассоциативные
- множественно-ассоциативные
- прямого соответствия


Алгоритмы замещения записей в кеше
Поскольку любой кеш всегда меньше запоминающего устройства, всегда возникает необходимость для записи новых данных в кеш удалять из него ранее записанные. Эффективное удаление данных из кеша подразумевает удаление наименее востребованных данных. В общем случае нельзя сказать, какие данные являются наименее востребованными, поэтому для этого используются эвристики. Например, можно удалять данные, к которым происходило наименьшее число обращений с момента их загрузки в кеш (least frequently used, LFU) или же данные, к которым обращались наименее недавно (least recently used, LRU), или же комбинация этих двух подходов (LRFU).
Кроме того, аппаратные ограничения по реализации кеша часто требуют минимальных расходов на учет служебной информации о ячейках, которой является также и использование данных в них. Наиболее простым способом учета обращений является установка 1 бита: было обращение или не было. В таком случае для удаления из кеша может использоваться алгоритм часы (или второго шанса), который по кругу проходит по всем ячейками, и выгружает ячейку, если у нее бит равен 0, а если 1 — сбрасывает его в 0.
Более сложным вариантом является использование аппаратного счетчика для каждой ячейки. Если этот счетчик фиксирует число обращений к ячейке, то это простой вариант алгоритма LFU. Он обладает следующими недостатками:
- может произойти переполнение счетчика (а он, как правило, имеет очень небольшую разрядность) — в результате будет утрачена вся информация об обращениях к ячейке
- данные, к которым производилось множество обращений в прошлом, будут иметь высокое значение счетчика даже если за последнее время к ним не было обращений
Для решения этих проблем используется механизм старения, который предполагает периодический сдвиг вправо одновременно счетчиков для всех ячеек. В этом случае их значения будут уменьшаться (в 2 раза), сохраняя пропорцию между собой. Это можно считать вариантом алгоритм LRFU.
Для адресации операндов в физическом адресном пространстве программы используют логическую адресацию. Процессор автоматически транслирует логические адреса в физические, выдаваемые затем на системную шину.
Архитектура компьютера различает физическое адресное пространство (ФАП) и логическое адресное пространство (ЛАП). Физическое адресное пространство представляет собой простой одномерный массив байтов, доступ к которому реализуется аппаратурой памяти по адресу, присутствующему на шине адреса микропроцессорной системы . Логическое адресное пространство организуется самим программистом исходя из конкретных потребностей. Трансляцию логических адресов в физические осуществляет блок управления памятью MMU .
В архитектуре современных микропроцессоров ЛАП представляется в виде набора элементарных структур: байтов, сегментов и страниц. В микропроцессорах используются следующие варианты организации логического адресного пространства:
- плоское (линейное) ЛАП: состоит из массива байтов, не имеющего определенной структуры; трансляция адреса не требуется, так как логический адрес совпадает с физическим;
- сегментированное ЛАП: состоит из сегментов - непрерывных областей памяти, содержащих в общем случае переменное число байтов; логический адрес содержит 2 части: идентификатор сегмента и смещение внутри сегмента; трансляцию адреса проводит блок сегментации MMU ;
- страничное ЛАП: состоит из страниц - непрерывных областей памяти, каждая из которых содержит фиксированное число байтов. Логический адрес состоит из номера (идентификатора) страницы и смещения внутри страницы; трансляция логического адреса в физический проводится блоком страничного преобразования MMU ;
- сегментно-страничное ЛАП: состоит из сегментов, которые, в свою очередь, состоят из страниц; логический адрес состоит из идентификатора сегмента и смещения внутри сегмента. Блок сегментного преобразования MMU проводит трансляцию логического адреса в номер страницы и смещение в ней, которые затем транслируются в физический адрес блоком страничного преобразования MMU .
Таким образом, основой получения физического адреса памяти служит логический адрес . В какой-то степени логическое адресное пространство , с которым имеет дело программист, можно сравнить со структурой книги, где аналогом сегмента выступает рассказ, страница книги соответствует странице ЛАП, а искомая информация - это некоторое слово . При этом если память организована как линейная, то номер искомого слова задается в явном виде и просто отсчитывается от начала книги. При сегментном представлении памяти искомое слово определяется его номером в заданном рассказе. Страничное представление памяти предполагает задание информации о слове в виде номера страницы в книге и номера слова на указанной странице. При сегментно-страничном представлении логический адрес слова задается номером слова в определенном рассказе. В этом случае по оглавлению книги определяется номер страницы, с которой начинается указанный рассказ. Затем, зная количество слов на странице и положение слова в рассказе, можно вычислить страницу книги и положение искомого слова на этой странице.
Формирование физического адреса в универсальном микропроцессоре при различных режимах работы
Микропроцессор способен работать в двух режимах: реальном и защищенном.
При работе в реальном режиме возможности процессора ограничены: емкость адресуемой памяти составляет 1 Мбайт, отсутствует страничная организация памяти, сегменты имеют фиксированную длину 2 16 байт .
Этот режим обычно используется на начальном этапе загрузки компьютера для перехода в защищенный режим.
В реальном режиме сегментные регистры процессора содержат старшие 16 бит физического адреса начала сегмента. Сдвинутый на 4 разряда влево селектор дает 20-разрядный базовый адрес сегмента. Физический адрес получается путем сложения этого адреса с 16-разрядным значением смещения в сегменте, формируемого по заданному режиму адресации для операнда или извлекаемому из регистра EIP для команды (рис. 3.1). По полученному адресу происходит выборка информации из памяти.
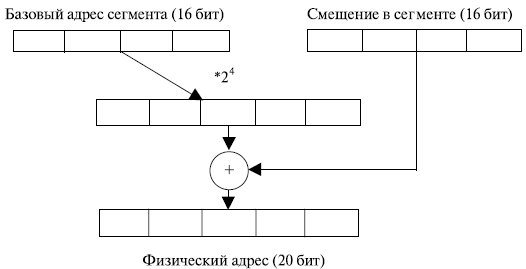
Наиболее полно возможности микропроцессора по адресации памяти реализуются при работе в защищенном режиме. Объем адресуемой памяти увеличивается до 4 Гбайт, появляется возможность страничного режима адресации. Сегменты могут иметь переменную длину от 1 байта до 4 Гбайт.
Общая схема формирования физического адреса микропроцессором , работающим в защищенном режиме, представлена на рис. 3.2.
Как уже отмечалось, основой формирования физического адреса служит логический адрес . Он состоит из двух частей: селектора и смещения в сегменте.
Селектор содержится в сегментном регистре микропроцессора и позволяет найти описание сегмента (дескриптор) в специальной таблице дескрипторов. Дескрипторы сегментов хранятся в специальных системных объектах глобальной ( GDT ) и локальных ( LDT ) таблицах дескрипторов. Дескриптор играет очень важную роль в функционировании микропроцессора , от формирования физического адреса при различной организации адресного пространства и до организации мультипрограммного режима работы. Поэтому рассмотрим его структуру более подробно.
Сегменты микропроцессора , работающего в защищенном режиме, характеризуются большим количеством параметров. Поэтому в универсальных 32-разрядных микропроцессорах информация о сегменте хранится в
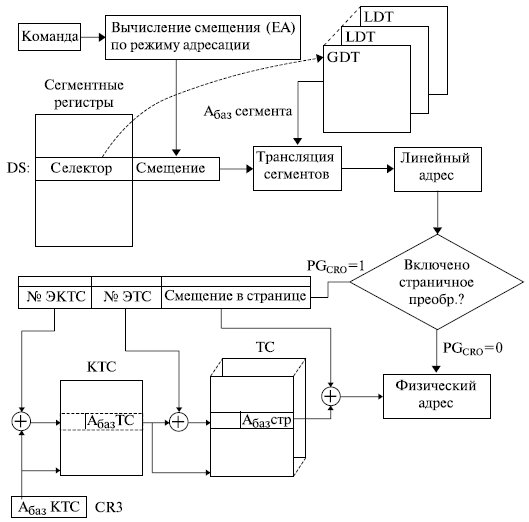
Рис. 3.2. Формирование физического адреса при сегментно-страничной организации памяти
Структура дескриптора сегмента представлена на рис. 3.3.
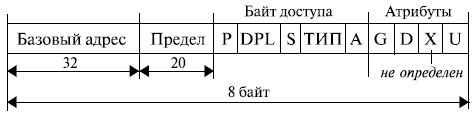
Мы будем рассматривать именно структуру, а не формат дескриптора, так как при переходе от микропроцессора i286 к 32-разрядному МП расположение отдельных полей дескриптора потеряло свою стройность и частично стало иметь вид "заплаток", поставленных с целью механического увеличения разрядности этих полей.
32-разрядное поле базового адреса позволяет определить начальный адрес сегмента в любой точке адресного пространства в 2 32 байт (4 Гбайт).
Поле предела (limit) указывает длину сегмента (точнее, длину сегмента минус 1: если в этом поле записан 0, то это означает, что сегмент имеет длину 1) в адресуемых единицах, то есть максимальный размер сегмента равен 2 20 элементов.
Величина элемента определяется одним из атрибутов дескриптора битом G ( Granularity - гранулярность , или дробность):

Таким образом, сегмент может иметь размер с точностью до 1 байта в диапазоне от 1 байта до 1 Мбайт (при G = 0 ). При объеме страницы в 2 12 = 4 Кбайт можно задать объем сегмента до 4 Гбайт (при G = l ):

Так как в архитектуре IA-32 сегмент может начинаться в произвольной точке адресного пространства и иметь произвольную длину, сегменты в памяти могут частично или полностью перекрываться.
Бит размерности ( Default size ) определяет длину адресов и операндов, используемых в команде по умолчанию:

Конечно, этот бит предназначен не для обычного пользователя, а для системного программиста, применяющего его, например, для отметки сегментов для сбора"мусора" или сегментов, базовые адреса которых нельзя модифицировать. Этот бит доступен только программам, работающим на высшем уровне привилегий. Микропроцессор в своей работе его не меняет и не использует.
Байт доступа определяет основные правила обращения с сегментом.
Бит присутствия P (Present) показывает возможность доступа к сегменту. Операционная система (ОС) отмечает сегмент, передаваемый из оперативной во внешнюю память , как временно отсутствующий, устанавливая в его дескрипторе P = 0 . При P = 1 сегмент находится в физической памяти. Когда выбирается дескриптор с P = 0 (сегмент отсутствует в ОЗУ ), поля базового адреса и предела игнорируются. Это естественно: например, как может идти речь о базовом адресе сегмента, если самого сегмента вообще нет в оперативной памяти? В этой ситуации процессор отвергает все последующие попытки использовать дескриптор в командах, и определяемое дескриптором адресное пространство как бы"пропадает".
Возникает особый случай неприсутствия сегмента. При этом операционная система копирует запрошенный сегмент с диска в память (при этом, возможно, удаляя другой сегмент), загружает в дескриптор базовый адрес сегмента, устанавливает P = 1 и осуществляет рестарт той команды, которая обратилась к отсутствовавшему в ОЗУ сегменту.
Двухразрядное поле DPL ( Descriptor Privilege Level ) указывает один из четырех возможных (от 0 до 3) уровней привилегий дескриптора, определяющий возможность доступа к сегменту со стороны тех или иных программ (уровень 0 соответствует самому высокому уровню привилегий).
Бит обращения A (Accessed) устанавливается в"1" при любом обращении к сегменту. Используется операционной системой для того, чтобы отслеживать сегменты , к которым дольше всего не было обращений.
Пусть, например, 1 раз в секунду операционная система в дескрипторах всех сегментов сбрасывает бит А. Если по прошествии некоторого времени необходимо загрузить в оперативную память новый сегмент, места для которого недостаточно, операционная система определяет"кандидатов" на то, чтобы очистить часть оперативной памяти, среди тех сегментов, в дескрипторах которых бит А до этого момента не был установлен в"1", то есть к которым не было обращения за последнее время.
Поле типа в байте доступа определяет назначение и особенности использования сегмента. Если бит S ( System - бит 4 байта доступа) равен 1, то данный дескриптор описывает реальный сегмент памяти. Если S = 0 , то этот дескриптор описывает специальный системный объект , который может и не быть сегментом памяти, например, шлюз вызова, используемый при переключении задач, или дескриптор локальной таблицы дескрипторов LDT . Назначение битов <3. 0> байта доступа определяется типом сегмента (рис. 3.4).
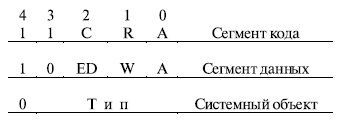
В сегменте кода: бит подчинения, или согласования, C ( Conforming ) определяет дополнительные правила обращения, которые обеспечивают защиту сегментов программ. При C = 1 данный сегмент является подчиненным сегментом кода. В этом случае он намеренно лишается защиты по привилегиям. Такое средство удобно для организации, например, подпрограмм, которые должны быть доступны всем выполняющимся в системе задачам. При C = 0 - это обычный сегмент кода; бит считывания R ( Readable ) устанавливает, можно ли обращаться к сегменту только на исполнение или на исполнение и считывание, например, констант как данных с помощью префикса замены сегмента. При R = 0 допускается только выборка из сегмента команд для их выполнения. При R = 1 разрешено также чтение данных из сегмента.
Запись в сегмент кода запрещена. При любой попытке записи возникает программное прерывание .
В сегменте данных:
- ED ( Expand Down) - бит направления расширения. При ED = 1 этот сегмент является сегментом стека и смещение в сегменте должно быть больше размера сегмента. При ED = 0 - это сегмент собственно данных (смещение должно быть меньше или равно размеру сегмента);
- бит разрешения записи W(Writeable) . При W = 1 разрешено изменение сегмента. При W = 0 запись в сегмент запрещена, при попытке записи в сегмент возникает программное прерывание .
В случае обращения за операндом смещение в сегменте формируется микропроцессором по режиму адресации операнда, заданному в команде. Смещение в сегменте кода извлекается из регистра - указателя команд EIP .
Сумма извлеченного из дескриптора начального адреса сегмента и сформированного смещения в сегменте дает линейный адрес (ЛА).
Если в микропроцессоре используется только сегментное представление адресного пространства, то полученный линейный адрес является также и физическим.
Если помимо сегментного используется и страничный механизм организации памяти , то линейный адрес представляется в виде двух полей: старшие разряды содержат номер виртуальной страницы , а младшие смещение в странице. Преобразование номера виртуальной страницы в номер физической проводится с помощью специальных системных таблиц: каталога таблиц страниц (КТС) и таблиц страниц (ТС). Положение каталога таблиц страниц в памяти определяется системным регистром CR3. Физический адрес вычисляется как сумма полученного из таблицы страниц адреса физической страницы и смещения в странице, полученного из линейного адреса.
Рассмотрим теперь все этапы преобразования логического адреса в физический более подробно.
В вычислениях , A адрес памяти является ссылкой на конкретные памяти местоположение , используемом на различных уровнях программного обеспечения и аппаратных средствами . Адреса памяти представляют собой последовательности цифр фиксированной длины, которые обычно отображаются и обрабатываются как целые числа без знака . Такая числовая семантика основана на особенностях ЦП (таких как указатель команд и регистры инкрементного адреса ), а также на использовании памяти, например массива, поддерживаемого различными языками программирования .
СОДЕРЖАНИЕ
Физические адреса
Логические адреса
Компьютерная программа использует адрес памяти для выполнения машинного кода , а также для хранения и извлечения данных . В ранних компьютерах логические и физические адреса соответствовали друг другу, но с момента появления виртуальной памяти большинство прикладных программ не знали физических адресов. Скорее, они адресуют логические адреса или виртуальные адреса , используя блок управления памятью компьютера и отображение памяти операционной системы ; см. ниже .
Единица разрешения адреса
Некоторые старые компьютеры (компьютеры с десятичным числом ) имели адрес с десятичной цифрой . Например, каждый адрес в IBM 1620 «S память на магнитных сердечниках идентифицирован один шесть бит двоично-десятичном разряд, состоящий из бита четности , бит флага и четыре цифровых битов. В 1620 использовались пятизначные десятичные адреса, поэтому теоретически максимально возможным адресом было 99 999. На практике ЦП поддерживал 20 000 ячеек памяти, и можно было добавить до двух дополнительных модулей внешней памяти, каждый из которых поддерживает 20 000 адресов, всего 60 000 (00000–59999).
Размер слова по сравнению с размером адреса
Размер слова - это характеристика компьютерной архитектуры, обозначающая количество бит, которые ЦП может обработать за один раз. Современные процессоры, включая встроенные системы , обычно имеют размер слова 8, 16, 24, 32 или 64 бита; большинство современных компьютеров общего назначения используют 32 или 64 бита. Исторически использовалось много разных размеров, включая 8, 9, 10, 12, 18, 24, 36, 39, 40, 48 и 60 бит.
Очень часто, говоря о размере слова в современном компьютере, также описывают размер адресного пространства на этом компьютере. Например, компьютер, называемый « 32-битным », также обычно допускает 32-битные адреса памяти; 32-разрядный компьютер с байтовой адресацией может адресовать 2 32 = 4 294 967 296 байт памяти или 4 гибибайта (ГиБ). Это позволяет эффективно хранить один адрес памяти в одном слове.
Теоретически современные 64-битные компьютеры с байтовой адресацией могут адресовать 2 64 байта (16 эксбибайт ), но на практике объем памяти ограничен ЦП, контроллером памяти или конструкцией печатной платы (например, количеством физических разъемы памяти или количество распаянной памяти).
Содержимое каждой ячейки памяти
Каждая ячейка памяти в хранящей программе компьютере имеет двоичное число или десятичное число некоторого вида . Его интерпретация как данные некоторого типа данных или как инструкция, и использование определяются инструкциями, которые извлекают их и манипулируют ими.
Некоторые ранние программисты объединили инструкции и данные в словах, чтобы сэкономить память, когда это было дорого: у Manchester Mark 1 было место в 40-битных словах для хранения небольших битов данных - его процессор игнорировал небольшой участок в середине одно слово - и это часто использовалось как дополнительное хранилище данных. Самовоспроизводящиеся программы, такие как вирусы, иногда воспринимают себя как данные, а иногда как инструкции. Самомодифицирующийся код , как правило , не рекомендуются в настоящее время, так как это делает тестирование и обслуживание несоразмерно трудно экономии нескольких байт, а также может дать неверные результаты из - за компилятор или предположений процессора о машинах состоянии , но до сих пор иногда используются намеренно, с большой осторожностью.
Адресное пространство в прикладном программировании
В современной многозадачной среде процесс приложения обычно имеет в своем адресном пространстве (или пробелах) блоки памяти следующих типов:
- Машинный код , в том числе:
- собственный код программы (исторически известный как сегмент кода или текстовый сегмент );
- общие библиотеки .
- инициализированные данные ( сегмент данных );
- неинициализированные (но выделенные) переменные;
- стек времени выполнения ;
- куча ;
- совместно используемая память и файлы с отображением памяти .
Некоторые части адресного пространства могут вообще не отображаться.
Некоторые системы имеют архитектуру «разделенной» памяти, где машинный код, константы и данные находятся в разных местах и могут иметь разный размер адреса. Например, микроконтроллеры PIC18 имеют 21-битный программный счетчик для адресации машинного кода и констант во флэш-памяти и 12-битные адресные регистры для адресации данных в SRAM.
Схемы адресации
Компьютерная программа может получить доступ к явно заданному адресу - в низкоуровневом программировании это обычно называется абсолютный адрес , а иногда иконкретный адрес, которыйв языках более высокого уровняизвестен кактип данныхуказателя. Но программа также может использоватьотносительный адрес,который указывает местоположение относительно другого места ( базовый адрес ). Есть еще много режимы косвенной адресации .
Сопоставление логических адресов с физической и виртуальной памятью также добавляет несколько уровней косвенности; см. ниже.
Модели памяти
Многие программисты предпочитают адресовать память таким образом, чтобы не было различий между пространством кода и пространством данных (см. Выше ), а также между физической и виртуальной памятью (см. Ниже ) - другими словами, числовые идентичные указатели относятся к одному и тому же байту. оперативной памяти.
Однако многие ранние компьютеры не поддерживали такую модель плоской памяти - в частности, машины с гарвардской архитектурой заставляют хранилище программ быть полностью отделено от хранилища данных. Многие современные DSP (например, Motorola 56000 ) имеют три отдельных области хранения - программную память, память коэффициентов и память данных. Некоторые часто используемые инструкции извлекаются из всех трех областей одновременно - меньшее количество областей памяти (даже если бы было одинаковое общее количество байтов памяти) замедлило бы выполнение этих инструкций.
Модели памяти в архитектуре x86
Ранние компьютеры x86 использовали адреса модели сегментированной памяти на основе комбинации двух чисел: сегмента памяти и смещения внутри этого сегмента.
Некоторые сегменты неявно рассматриваются как сегменты кода , предназначенные для инструкций , сегментов стека или обычных сегментов данных . Хотя способы использования различаются, сегменты не имеют разной защиты памяти, отражающей это. В модели с плоской памятью все сегменты (регистры сегментов) обычно устанавливаются в ноль, и только смещения являются переменными.
Читайте также: