
Чему равен компьютерный алфавит
Обновлено: 05.07.2024
Единицей измерения количества информации является бит – это наименьшаяединица.
1 Кб (килобайт) = 1024 байта= 2 10 байтов
1 Мб (мегабайт) = 1024 Кб = 2 10 Кб
1 Гб (гигабайт) = 1024 Мб = 2 10 Мб
1 Тб (терабайт) =1024 Гб = 2 10 Гб
Формулы, которые используются при решении типовых задач:
Информационный вес символа алфавита и мощность алфавита связаны между собой соотношением: N = 2 i .
i – информационный вес одного символа.
Основная литература:
- Босова Л. Л. Информатика: 7 класс. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2017. – 226 с.
Дополнительная литература:
- Босова Л. Л. Информатика: 7–9 классы. Методическое пособие. // Босова Л. Л., Босова А. Ю., Анатольев А. В., Аквилянов Н.А. – М.: БИНОМ, 2019. – 512 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 1. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 2. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Гейн А. Г. Информатика: 7 класс. // Гейн А. Г., Юнерман Н. А., Гейн А.А. – М.: Просвещение, 2012. – 198 с.
Теоретический материал для самостоятельного изучения.
Что же такое символ в компьютере? Символом в компьютере является любая буква, цифра, знак препинания, специальный символ и прочее, что можно ввести с помощью клавиатуры. Но компьютер не понимает человеческий язык, он каждый символ кодирует. Вся информация в компьютере представляется в виде нулей и единичек. И вот эти нули и единички называются битом.
Информационный вес символа двоичного алфавита принят за минимальную единицу измерения информации и называется один бит.
Алфавит любого понятного нам языка можно заменить двоичным алфавитом. При этом мощность исходного алфавита связана с разрядностью двоичного кода соотношением: N = 2 i .
Эту формулу можно применять для вычисления информационного веса одного символа любого произвольного алфавита.
Рассмотрим пример:
Алфавит древнего племени содержит 16 символов. Определите информационный вес одного символа этого алфавита.
Составим краткую запись условия задачи и решим её:
16 = 2 i , 2 4 = 2 i , т. е. i = 4
Ответ: i = 4 бита.
Информационный вес одного символа этого алфавита составляет 4 бита.
Математически это произведение записывается так: I = К · i.
32 = 2 i , 2 5 = 2 i , т.о. i = 5,
I = 180 · 5 = 900 бит.
Ответ: I = 900 бит.
I = 23 · 8 = 184 бита.
Как и в математике, в информатике тоже есть кратные единицы измерения информации. Так, величина равная восьми битам, называется байтом.
Бит и байт – это мелкие единицы измерения. На практике для измерения информационных объёмов используют более крупные единицы: килобайт, мегабайт, гигабайт и другие.
1 Кб (килобайт) = 1024 байта= 2 10 байтов
1 Мб (мегабайт) = 1024 Кб = 2 10 Кб
1 Гб (гигабайт) = 1024 Мб = 2 10 Мб
1 Тб (терабайт) =1024 Гб = 2 10 Гб
Материал для углубленного изучения темы.
Как текстовая информация выглядит в памяти компьютера.
Набирая текст на клавиатуре, мы видим привычные для нас знаки (цифры, буквы и т.д.). В оперативную память компьютера они попадают только в виде двоичного кода. Двоичный код каждого символа, выглядит восьмизначным числом, например 00111111. Теперь возникает вопрос, какой именно восьмизначный двоичный код поставить в соответствие каждому символу?
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код ‑ просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.Таблица для кодировки – это «шпаргалка», в которой указаны символы алфавита в соответствии порядковому номеру. Для разных типов компьютеров используются различные таблицы кодировки.
Таблица ASCII (или Аски), стала международным стандартом для персональных компьютеров. Она имеет две части.

В этой таблице латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений. Это правило соблюдается и в других таблицах кодировки и называется принципом последовательного кодирования алфавитов. Благодаря этому понятие «алфавитный порядок» сохраняется и в машинном представлении символьной информации. Для русского алфавита принцип последовательного кодирования соблюдается не всегда.
Запишем, например, внутреннее представление слова «file». В памяти компьютера оно займет 4 байта со следующим содержанием:
01100110 01101001 01101100 01100101.
А теперь попробуем решить обратную задачу. Какое слово записано следующим двоичным кодом:
01100100 01101001 01110011 01101011?
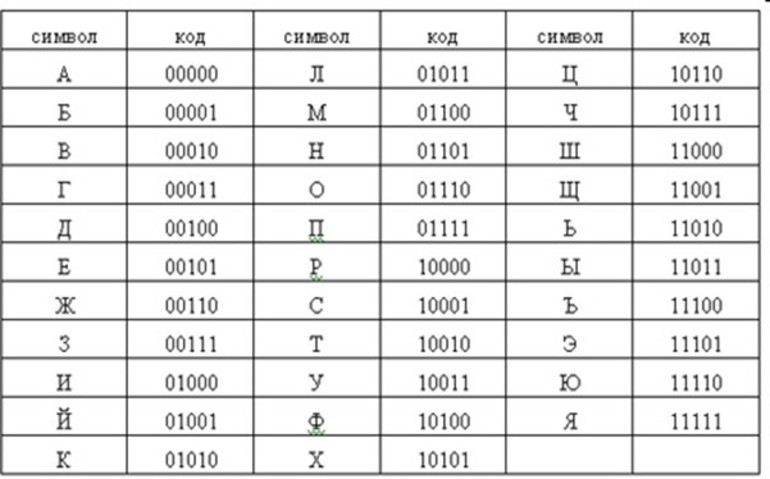
В таблице 2 приведен один из вариантов второй половины кодовой таблицы АSСII, который называется альтернативной кодировкой. Видно, что в ней для букв русского алфавита соблюдается принцип последовательного кодирования.

Вывод: все тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные для нас буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в форме двоичного кода.
Из памяти же компьютера текст может быть выведен на экран или на печать в символьной форме.
Разбор решения заданий тренировочного модуля
Информационный вес символа алфавита и мощность алфавита связаны между собой соотношением: N = 2 i .
Алфавит — это набор символов, которые используются в некотором языке с целью представления информации.
В качестве символов могут быть использованы буквы, цифры, скобки, специальные знаки.
Мощность алфавита — это количество символов в алфавите, которое вычисляется по формуле:
Например, мощность алфавита, состоящего из \(26\) латинских букв и дополнительных символов (скобки, пробел, знаки препинания (\(11\) шт.), \(10\) цифр), — \(47\).
1. определим, какое количество бит необходимо для кодировки одного символа. Так как мощность используемого алфавита \(N\)\(=\) 256 , то \(i\) \(=\) 8 (использовали формулу N = 2 i ).
Поскольку \(1\) байт \(=\) \(8\) бит, \(1\) Кбайт \(=\) \(1024\) байт, получим:
65536 бит \(=\) 65536 8 байт \(=\) 8192 байт \(=\) 8192 1024 Кбайт \(=\) 8 Кбайт.
Любая компьютерная техника работает в двоичном коде, понимая только значения \(0\) — «сигнал есть» и \(1\) — «сигнала нет». Эти значения хранятся в бите — наименьшей единице измерения информации. Однако удобнее использовать более крупные единицы измерения информации, которые приведены в таблице.
| \(1\) байт | \(8\) бит \(=\) 2 3 бит |
| \(1\) Кбайт (килобайт) | 2 10 байт |
| \(1\) Мбайт (мегабайт) | 2 10 Кбайт |
| \(1\) Гбайт (гигабайт) | 2 10 Мбайт |
| \(1\) Тбайт (терабайт) | 2 10 Гбайт |
1) определить, сколько Мбайт информации содержится в \(512\) битах. Ответ дай в виде степени числа \(2\).
2) Какое количество бит содержится в 1 256 Гбайт памяти? Ответ дай в виде степени числа \(2\).

Понятие мощности алфавита находится в основании изучения информатики. Алфавитом принято называть набор многочисленных символов. Сумма всех их в определённом языке и есть алфавитная мощность. Иными словами, это количество всех символов, входящих в конкретно взятый язык. Сюда входят не только буквы, но и прочие обозначения, в частности:

- числа;
- спецсимволы;
- двоеточия;
- пробел;
- скобки;
- запятые;
- точки;
- многоточия и прочее.
Основным постулатом в информатике является тот факт, что устройство разбирает введённую информацию исключительно в двоичном коде в форме нуля и единицы. В итоге получается, что абсолютно любой символ алфавита может быть успешно закодирован при помощи соответствующего подбора этих двух цифровых символов. Самая маленькая последовательность, применяемая при обозначении какой-либо цифры, буквы или другого знака, состоит из двух элементов.
Информационная масса отдельно взятого символа обычно изображается в форме информационной стандартной измерительной единицы, которая называется «бит». Восемь битов становятся равны одному байту.
Отображение символов в двоичном коде
Алфавитная мощность может быть использована на практике только при наличии двоичного кода. В качестве примера можно использовать упрощённый алфавит, состоящий всего из четырёх символов. В этом случае разрядность их и информационное представление описываются следующим образом:
Из этого списка можно сделать вывод о том, что если алфавитная мощность равняется 4, то масса отдельного единичного символа будет составлять 2 бита. Если же есть алфавит, состоящий из 8 символов, то при подборе двоичного трёхзначного кода для него комбинационное количество будет следующим:
- 1 — 000;
- 2 — 001;
- 3 — 010;
- 4 — 011;
- 5 — 100;
- 6 — 101;
- 7 — 110;
- 8 — 111.
Иными словами, если алфавитная мощность равна 8, то вес отдельно взятого символа для двоичного трёхзначного кода составит 3 бита.
Вычисление мощности алфавита

Эта формула была изобретена американским инженером Ральфом Хартли более сотни лет тому назад. Она применяется для работы с равновероятными событиями и используется для определения мощности конкретного буквенного набора, которая обозначается буквой N (информационная масса или объём). n означает численность бит в словесной единице, иными словами, количество знаков внутри двоичного кода. Так, если n равен 1, то N тоже равен 1, при n = 2 N = 4, при n = 3 N = 8, при n = 4 N = 16.
Чтобы сформулировать теорию о численности информации в набранном словосочетании, пользуются формулой I=K*i. В этом случае К обозначает численность всех символов в предложении, а i — это информационная масса символа.
При ответе на вопрос, как найти мощность алфавита, нужно сказать, что в русском языке 33 буквы, поэтому это можно выразить как N = 33. Для сравнения, аналогичный показатель в английском, немецком и французском языках равняется 26, в испанском — 27. Венгерский язык, например, является 40-символьным.
Существует также и клавиатурный язык, куда входят не только буквы, но и дополнительные знаки. Так, в русском языке есть ещё 10 цифр и 11 символов, а также пробел и пара скобок. Их мощность прибавляется к аналогичному буквенному показателю, и на выходе получается N = 33+10+11+1+2=57. В некоторых случаях букву «ё» не выделяют в качестве отдельного самостоятельного символа, и в таком случае полная мощность русского алфавита становится равна 56.
Определение информационного объёма в тексте
Почти всегда при наборе текста на компьютерах и других электронных устройствах приходится сталкиваться с написанием различных символов. К ним следует отнести:
- заглавные и жирные буквы;
- курсив;
- скобки;
- знаки препинания;
- вычислительные операции и прочее.
По всем расчётам получается, что мощность компьютерного алфавита составляет 256 различных символов и вариантов. В соответствии с формулой Хартли, N = 256, а i — масса любого из значков в клавиатурном алфавите соответствует одному байту, или восьми битам.

Размер любой напечатанной фразы может быть вычислен по формуле V=K ⋅ log2N. В этом случае N обозначает количество всех символов в алфавите, а K — это численность знаков непосредственно в напечатанной фразе. Так, например, имеется произвольный текст объёмом в 25 листов. На каждом из них расположено по 45 строчек текста, содержащих по 58 символов.
Исходя из этого, на любой отдельной странице будет 45*58 = 2610 байт информации. В целом же по всему тексту этот объём будет равен 2610*25 = 65250 байт. Для обозначения мощности алфавита в информатике общепринятым вариантом является буква N из формулы Хартли. Именно ее чаще всего указывают в большинстве учебников и профессиональной литературе.
Для удобства их всегда переводят в увеличенные величины — кило-, мега-, гигабайты и прочее. Для их упрощённого обозначения используются специальные сокращения: Кб, Мб, Гб и так далее. 1 Кб равняется 1024 байтам (2 байта в десятой степени), 1 Мб составляет 1024 Кб (2 Кб в десятой степени) и так далее. Исходя из этого, 65250 байт будут составлять 63,72 килобайта.
Поскольку один отдельный символ состоит из 8 битов, то устанавливать их кодировку целиком не представляется возможным. Вместо этого предпочтительнее образовать кодировку трёхбитовых комбинаций. Расчёт этого действия проводится по формуле Хартли, где n-ная степень будет равняться трём. В результате получается N, равная 8.
Примеры расчёта мощности

«Однажды, в студеную зимнюю пору,
Я из лесу вышел; был сильный мороз»
будет 67 символов вместе с пробелами, то есть, в соответствии с условиями задания, 67 байт. Их количество умножают на 8 (количество битов в байте), и на выходе получается 536 битов.
1 бит – это наименьшая единица измерения информации.
Информационный вес символа алфавита и мощность алфавита связаны между собой соотношением: N = 2 i
1 Кб (килобайт) = 1024 байта= 2 10 байт
1 Мб (мегабайт) = 1024 Кб = 2 10 Кб
1 Гб (гигабайт) = 1024 Мб = 2 10 Мб
1 Тб (терабайт) =1024 Гб = 2 10 Гб
Как текстовая информация выглядит в памяти компьютера?
Набирая текст на клавиатуре, мы видим привычные для нас знаки (цифры, буквы и т. д.). В оперативную память компьютера они попадают только в виде двоичного кода. Двоичный код каждого символа, выглядит восьмизначным числом, например 00111111. Теперь возникает вопрос, какой именно восьмизначный двоичный код поставить в соответствие каждому символу?
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код – просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки. Таблица кодировки – это «шпаргалка», в которой указаны символы алфавита в соответствии порядковому номеру. Для разных типов компьютеров используются различные таблицы кодировки.
Таблица ASII (или Аски), стала международным стандартом для персональных компьютеров. Она имеет две части.

В этой таблице латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений. Это правило соблюдается и в других таблицах кодировки и называется принципом последовательного кодирования алфавитов. Благодаря этому понятию, «алфавитный порядок» сохраняется и в машинном представлении символьной информации. Для русского алфавита принцип последовательного кодирования соблюдается не всегда.
Запишем, например, внутреннее представление слова «file». В памяти компьютера оно займет 4 байта со следующим содержанием:
01100110 01101001 01101100 01100101.
А теперь попробуем решить обратную задачу. Какое слово записано следующим двоичным кодом:
01100100 01101001 01110011 01101011?
В таблице 2 приведен один из вариантов второй половины кодовой таблицы АSСII, который называется альтернативной кодировкой. Видно, что в ней для букв русского алфавита соблюдается принцип последовательного кодирования.

Вывод: все тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные нам буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в форме двоичного кода.
Из памяти же компьютера текст может быть выведен на экран или на печать в символьной форме.
Читайте также: