
Что такое hash join oracle
Обновлено: 08.07.2024
Читает индекс целиком (все строки) в порядке, представленном индексом. В зависимости от различной системной статистики СУБД может выполнять эту операцию, если нужны все строки в порядке индекса, например, из-за соответствующего предложения ORDER BY. Вместо этого оптимизатор может также использовать операцию Index Fast Full Scan и выполнить дополнительную операцию сортировки.
Index Fast Full Scan
Читает индекс целиком (все строки) в порядке, хранящемся на диске. Эта операция обычно выполняется вместо полного сканирования таблицы, если в индексе доступны все необходимые столбцы. Подобно операции TABLE ACCESS FULL, INDEX FAST FULL SCAN может извлечь выгоду из многоблочных операций чтения.
Table Access By Index ROWID
Извлекает строку из таблицы, используя ROWID, полученный из предыдущего поиска по индексу.
Table Access Full
Полное сканирование таблицы. Читает всю таблицу (все строки и столбцы), в порядке, хранящемся на диске. Хотя многоблочные операции чтения значительно повышают скорость сканирования полной таблицы, это все еще одна из самых дорогих операций. Помимо высоких затрат времени ввода-вывода, полное сканирование таблицы должно проверять все строки таблицы, что также занимает значительное количество процессорного времени.
Merge Join
Соединение слиянием объединяет два отсортированных списка. Обе стороны объединения должны быть предварительно отсортированы.
Nested Loops
Соединение вложенными циклами объединяет две таблицы, выбирая результат из одной таблицы и запрашивая другую таблицу для каждой строки из первой. Встречается очень часто. Выполняет довольно эффективное соединение относительно небольших наборов данных. Соединение вложенными циклами не требует сортировки входных данных.
Hash Join
Хеш-соединение загружает записи-кандидаты с одной стороны соединения в хеш-таблицу, которая затем проверяется для каждой строки с другой стороны соединения. Операция используется всегда, когда невозможно применить другие виды соединения: если соединяемые наборы данных достаточно велики и/или наборы данных не упорядочены по столбцам соединения.
Sort Unique
Сортирует строки и устраняет дупликаты.
Hash Unique
Более эффективная реализация алгоритма сортировки и устранения дупликатов с использованием хэш-таблицы. Заменяет операцию Sort Unique в определенных обстоятельствах.
Sort Aggregate
Вычисляет суммарные итоги с использованием агрегатных функций SUM, COUNT, MIN, MAX, AVG и пр.
Sort Order By
Сортирует результат в соответствии с предложением ORDER BY. Эта операция требует больших объемов памяти для материализации промежуточного результата.
Sort Group By
Сортирует набор записей по столбцам GROUP BY и агрегирует отсортированный результат на втором этапе. Эта операция требует больших объемов памяти для материализации промежуточного результата.
Sort Group By Nosort
Агрегирует предварительно отсортированный набор записей в соответствии с предложением GROUP BY. Эта операция не буферизует промежуточный результат.
Hash Group By
Группирует результат, используя хеш-таблицу. Эта операция требует больших объемов памяти для материализации промежуточного набора записей. Вывод не упорядочен каким-либо значимым образом.
Filter
Применяет фильтр к набору строк.
Создает промежуточное представление данных.
Count Stopkey
Прерывает выполение операций, когда было выбрано нужное количество строк.
Sort Join
Сортирует набор записей в столбце соединения. Используется в сочетании с операцией Merge Join для выполнения сортировки соединением слияния.
Intersection
Выполняет операцию пересечения между двумя источниками.
Union-All
Выполняет операцию объединения всех записей между двумя таблицами. Дублирующиеся строки не удаляются.
Load As Select
Прямая загрузка с использованием оператора SELECT в качестве источника.
Temp Table Generation/Transformation
Создает/преобразует временную таблицу. Используется в специфичных для Oracle преобразованиях типа Star.
С SQL работают почти все, но даже опытные разработчики иногда не могут ответить на простой вопрос. Каким образом СУБД выполняет самый обычный INNER JOIN?
Работа с несколькими коллекциями
В базе данных (в дальнейшем мы будем использовать PostgreSQL) для двух этих сущностей есть две таблицы с аналогичными полями:
Пусть наша задача сводится к написанию простейшего бизнес-правила - найти общую сумму выручки за 2020 год и ранее, которую принесли клиенты, находящиеся сейчас в активном статусе. Как можно реализовать решение такой простой задачи?
Nested Loop
Самая простая идея, которая приходит на ум. Бежим в цикле по клиентам и во вложенном цикле бежим по всем посещениям. Проверяем все условия и если находим совпадение - добавляем сумму затрат этого визита в итоговый результат.
Эта идея анимирована ниже:
Алгоритм очень простой, не потребляет дополнительной памяти. Но затратность его O(N²), что будет сказываться на большом числе элементов - чем их больше, тем больше телодвижений необходимо совершить.
Для того, чтобы оценить скорость его работы мы создадим тестовый набор данных с помощью следующего SQL скрипта:
Все на том же компьютере получилось порядка 2.1 миллисекунды на все. И кода заметно меньше. Т.е. в 10 раз быстрее самого метода, не считая логики по извлечению данных из БД и их материализации на стороне приложения.
Merge Join
Разница в скорости работы в 20 раз наталкивает на размышления. Скорее всего Nested Loop не очень нам подходити мы должны найти что-то получше. И есть такой алгоритм… Называется Merge Join или Sort-Merge Join. Общая суть в том, что мы сортируем два списка по ключу на основе которого происходит соединение. И делаем проход всего в один цикл. Инкрементируем индекс и если значения в двух списках совпали - добавляем их в результат. Если в левом списке идентификатор больше, чем в правом - увеличиваем индекс массива только для правой части. Если, наоборот, в левом списке идентификатор меньше, то увеличиваем индекс левого массива. Затратность такого алгоритма O(N*log(N)).
Hash Join
Этот алгоритм подходит для больших массивов данных. Его идея проста. Для каждого из списков считается хэш ключа, далее этот хэш используется для того, чтобы выполнить сам Join. Детально можно посмотреть в видео:
Динамический выбор алгоритма
Отлично! Похоже мы нашли универсальный алгоритм, который самый быстрый. Нужно просто использовать его всегда и не беспокоиться более об этом вопросе. Но если мы учтем еще и расход памяти все станет немного сложнее. Для Nested Loop - память не нужна, Merge Join - нужна только для сортировки (если она будет). Для Hash Join - нужна оперативная память.
Оказывается расход памяти - это еще не все. В зависимости от общего числа элементов в массивах скорость работы разных алгоритмов ведет себя по-разному. Проверим для меньшего числа элементов (P, V) равному (50, 100). И ситуация переворачивается на диаметрально противоположную: Nested Loop самый быстрый - 2.202 микросекунды, Merge Join - 4.715 микросекунды, Hash Join - 7.638 микросекунды. Зависимость скорости работы каждого алгоритма можно представить таким графиком:

Hash join - это алгоритм обработки базы данных для объединений в несколько таблиц. Для объединений в несколько таблиц существует два наиболее часто используемых метода: sort merge-join и вложенный цикл. Чтобы более четко представить сценарии использования хеш-соединения и почему вводится такой алгоритм соединения, здесь также кратко представлены два метода соединения, упомянутых выше.
Какое понятие является методом подключения, или почему у нас есть и есть несколько, для тех, кто не понимает базу данных, это может быть началом сомнений. Проще говоря, мы храним данные в разных таблицах, и разные таблицы имеют свою собственную структуру таблиц. Разные таблицы могут быть связаны. В большинстве практических случаев нам не нужна только одна таблица информации. Например, вам нужно найти учеников в Ханчжоу из таблицы классов, а затем использовать эту информацию для получения их математических оценок в таблице оценок. Если нет соединения с несколькими таблицами, вы можете только вручную запросить информацию в первой таблице как первую. Получая информацию из двух таблиц для запроса окончательного результата, можно представить, насколько это будет громоздко.
Для нескольких распространенных баз данных, таких как oracle, postgresql, все они поддерживают hash-join, mysql не поддерживает. В этом отношении oracle и pg работают относительно хорошо, реализация самого hash-join не очень сложна, но требует реализации оптимизатора для взаимодействия, чтобы максимизировать его преимущества, я думаю, что это самое сложное место.
Метод запроса многостолового соединения делится на следующие типы: внутреннее соединение, внешнее соединение и кросс-соединение. Внешние соединения делятся на: левое внешнее соединение, правое внешнее соединение и полное внешнее соединение. Для разных методов запросов использование одного и того же алгоритма соединения также будет сопряжено с разными затратами. Это тесно связано с методом его реализации. Необходимо рассмотреть, как реализовать разные методы запроса. Определенный используемый метод соединения определяется оптимизатором. В зависимости от измерения стоимости, расчет стоимости нескольких методов подключения будет кратко представлен позже. На самом деле, есть много мест, где можно рассмотреть и реализовать хеш-джойн, например, как справляться с серьезным перекосом данных, как справляться с внутренним хранилищем, как справляться с конфликтами и т. Д., Они не являются предметом данной статьи, более подробно не рассматриваются Я могу поговорить еще об одном.
nested loop join
Соединение с вложенным циклом - более общий метод соединения. Он делится на внутреннюю и внешнюю таблицы. Каждая строка данных, отсканированных во внешней таблице, должна быть найдена во внутренней таблице. Сложность без индекса составляет O (N * M), Эта сложность очень невыгодна для больших наборов данных, и, вообще говоря, индексы будут использоваться для повышения производительности.
Объединение слиянием должно сначала отсортировать две таблицы в соответствии со связанными полями и взять строку данных из двух таблиц для сопоставления, при необходимости поместить их в набор результатов, если не совпадает, выбросить меньшую строку и продолжить сопоставление с другой таблицей. Одна строка обрабатывается по очереди, пока не будут взяты данные двух таблиц. Большая часть стоимости объединения слиянием тратится на сортировку, и это также является основной причиной, по которой оно хуже, чем хеш-соединение при тех же условиях.
2. Принцип и реализация
Проще говоря, для двух таблиц, hash-join, даже если маленькая таблица (называемая S) в двух таблицах используется в качестве хэш-таблицы, а затем сканирует каждую строку данных в другой таблице (называемой M), используя полученные данные строки в соответствии с Условия соединения используются для отображения установленной хеш-таблицы Хеш-таблица помещается в память, чтобы можно было быстро получить соответствующие строки таблицы S и таблицы М.
Для случая, когда результирующий набор очень большой, объединение слиянием должно сортировать эффективность не очень высоко, а объединение с вложенным циклом - это метод запроса с вложенным циклом, несомненно, более непригоден для подключения больших наборов данных, а хеш-соединение является положительным Он был создан, чтобы иметь дело с этим сложным методом запроса, особенно в случае большой таблицы и маленькой таблицы, в основном нужно сканировать таблицу размеров только один раз, чтобы получить окончательный набор результатов.
Однако hash-join применим только к соединениям с равными значениями.Для соединений запросов, таких как>, <, <=,> =, по-прежнему необходим общий алгоритм соединения, такой как вложенный цикл. Если ключ подключения изначально заказан или должен быть отсортирован, то стоимость использования merge-join может быть меньше, чем hash-join, и merge-join будет иметь преимущество.
Ну, много глупостей, давайте поговорим о реализации, возьмем простую многостабильную SQL-инструкцию запроса, чтобы получить каштан: select * из t1 объединить t2 на t1.c1 = t2.c1, где t1.c2> t2. c2 и t1.c1> 1. Такой SQL входит в систему базы данных, как она обрабатывается и анализируется? sql: призрак знает, что я испытал. , ,
1. Базовые знания
1. Первый шаг, он должен пройти лексический и грамматический анализ, вывод этой части - грамматическое дерево с узлами токена.

Грамматический анализ, как следует из названия, эта часть является только анализом грамматического уровня. Оператор SQL строки обрабатывается в дерево узлов со структурой прототипа. Каждый узел имеет свой собственный специальный логотип, но этот узел не анализируется и не обрабатывается. Специфическое значение и ценность.
2. Второй шаг - это семантический анализ и переписывание.
Разные процессы перезаписи могут иметь разные базы данных, некоторые могут быть объединены с процессом выполнения логики, а некоторые могут быть отдельными.

Форма дерева после этого шага, как правило, соответствует дереву синтаксического анализа, но узлы в это время несут определенную информацию. Возьмем выражение, где в качестве примера каждый узел этого инфиксного выражения. Точка имеет свой собственный тип и определенную информацию, и ей все равно, какое значение. После завершения этого шага начинается процесс перезаписи. Перезапись - это логический метод оптимизации, который делает некоторые сложные операторы SQL проще или больше в соответствии с базой данных. Поток процесса.
3. Оптимизатор обработки
Обработка оптимизатора является относительно сложной, и это также самое трудное место модуля sql. Оптимизация бесконечна, поэтому у оптимизатора нет оптимального, а только лучше. Оптимизатор должен учитывать все аспекты факторов, не только быть очень универсальными, но и обеспечивать сильную способность и правильность оптимизации.
Наиболее важной ролью оптимизатора является выбор пути: для соединений с несколькими таблицами, как определить порядок и метод соединения для соединений с таблицами, разные базы данных имеют разные методы обработки, pg поддерживает алгоритмы динамического программирования, а генетические алгоритмы используются, когда таблиц слишком много. , Определение пути зависит от реализации модели затрат. Модель затрат содержит некоторую статистическую информацию, такую как максимальные, минимальные значения, значения NDV и DISTINCT столбца. Через эту информацию можно рассчитать коэффициент выбора для дальнейшего расчета стоимости.

Возвращаясь к тексту, здесь определяется, какой метод подключения использовать. Для хеш-соединения требуется таблица размеров, поэтому сформированный здесь план отличается от t1-t2 или t2-t1. Каждый метод подключения имеет свой собственный Метод расчета стоимости.
Оценка стоимости хеш-соединения:
COST = BUILD_COST + M_SCAN_COST + JOIN_CONDITION_COST + FILTER_COST
Проще говоря, стоимость хеш-соединения заключается в основном в создании хеш-таблицы, сканировании таблицы M, соединении условного соединения и фильтрации фильтрации, для S-таблицы и М-таблицы нужно сканировать только один раз, фильтрация фильтра относится к t1.c2> t2. Условная фильтрация, такая как c2, для условий, таких как t1.c1> 1, которые включают только одну таблицу, будет передана и отфильтрована до установления соединения.
После обработки оптимизатором будет сгенерировано дерево плана выполнения, и реальный процесс реализации будет рекурсивно обрабатывать данные снизу вверх в соответствии с данными операции процесса плана выполнения и возвращать данные.

2. Реализация хеш-соединения
Реализация хеш-соединения разделена на таблицу построения, которая представляет собой небольшую таблицу и таблицу зондов, используемые для построения хэш-карты.Вначале данные небольшой таблицы считываются последовательно, и для каждой строки данных в соответствии с условиями соединения генерируется кортеж в хэш-карте. Кэшируется в памяти, если внутренней памяти недостаточно, выведите дамп на внешнюю память. Сканируйте таблицу зондов по очереди, чтобы получить каждую строку данных, чтобы сгенерировать карту хеш-ключей в соответствии с условием соединения. Соответствующий кортеж в хэш-карте, строка, соответствующая кортежу, и строка таблицы зондов имеют одинаковый хэш-ключ, тогда нет уверенности в том, что эти две строки Данные, которые удовлетворяют условию, должны пройти через условие соединения и снова фильтроваться, а набор данных, который удовлетворяет условию, возвращает необходимый столбец проекции.

Hash объединить несколько деталей
1. Реализация хеш-соединения сама по себе не должна определять, является ли она маленькой таблицей. Оптимизатор уже определил порядок соединения таблицы при создании плана выполнения. Чтобы создать хеш-таблицу с левой таблицей в качестве маленькой таблицы, соответствующая модель затрат будет левой таблицей. Стоимость получается в виде небольшой таблицы, так что путь, сгенерированный в соответствии со стоимостью, соответствует требованиям реализации.
2. Размер хеш-таблицы и количество сегментов, которые должны быть выделены. Это нужно сделать с самого начала. Сколько выделения является проблемой. Слишком большое выделение приведет к потере памяти. Слишком маленькое выделение приведет к слишком малому количеству сегментов и слишком длинной открытой цепочке. Производительность ухудшается. Как только здесь будет превышен лимит памяти, будет рассмотрен дамп во внешнее хранилище. Различные базы данных имеют свою собственную реализацию.
3. Как хешировать данные, разные базы данных имеют свои собственные способы, и разные методы хеширования также будут оказывать определенное влияние на производительность.
Хэширование - преобразование массива входных данных произвольной длины в выходную битовую строку фиксированной длины, выполняемое определённым алгоритмом.
Преимуществом массива фиксированной длины является константное время доступа к его элементам из-за размещения ограниченного набора в процессорном кэше.
Самая большая проблема - это выбор хэширующей функции, которая давала бы минимум коллизий (одинаковых значений хэш функции для разных ключей массива).
Идеальная хэширующая функция не должна давать коллизий, но в реальности такую функцию сложно получить.
В моем случае алгоритмом хэширование я выбрал остаток от деления. Число в знаменателе даст нам такое же число элементов в хэш массиве.
Для разрешения проблемы коллизий используется 2 подхода, оба из них в зависимости от числа коллизий для доступа к нужному элементу дают от 1 до N обращений:
1. Открытая адресация
Коллизии размещаются в томже хэш массиве, но смещаются вправо, пока не найдется свободное место.
Пример:
Массив из элементов: 1, 11, 2, 3
Хэширующая функция: остаток от деления на 10
Результирующий хэш массив:
Реализацию на java можно посмотреть здесь.
2. Метод цепочек
Хэш таблица содержит список коллизий. Число элементов хэш таблицы фиксировано = числу различных вариантов хэширующей функции.
Пример на том же массиве и той же хэширующей функции:
3. Метод красно-черного дерева
В случае большого числа коллизий, когда все элементы попадают в одну хэш секцию, для хранения данных секции целесообразно использовать красно-черное дерево, замен списка во 2 методе. В этом случае поиск элемента будет осуществляться за логарифмическое время, вместо линейного в списке.
Плюсы и минусы подходов:
| Сравниваемое свойство | Цепочки | Открытая адресация |
| Разрешение коллизий | Используются дополнительные списки | Хранится в самом хэш массиве |
| Использование памяти | Дополнительная память для указателей в списке. В случае неудачной хэш функции, если все элементы легли в один элемент массива (хэш секцию), то размер памяти будет почти в 2 раза больше, т.к. необходимая память под указатели будет равна памяти под ключи. | Нет доп. расходов |
| Зависимость производительности от заполненности таблицы | Прямо пропорционально значению = число элементов / кол-во хэш секции таблицы | число элементов / ( кол-во хэш секции таблицы - число элементов ) |
| Возможность записи числа элементов больше размера хэш таблицы | Да, за счет записи коллизий в список | Нет, т.к. колллизии храняться в томже массиве |
| Простота удаления | Да, удаляется элемент из списка | Нет, пустое место нужно помечать удаленным, а не очищать физически. Т.к. при вставке ищутся пусты места справа, что может сломать последовательность |
| Использование кэша процессора | Нет (переходы по ссылке) | Да (Все данные рядом) |
Детали реализации Oracle:
Хэширование цепочками наиболее понятное, но оно же дает худшую производительность, т.к. не использует кэш процессора из-за постоянных переходов по ссылке.
По этому все нагруженные реализации используют Hash таблицы с открытой адресацией, где все данные лежат рядом и используют кэш сопроцессора.

Слева графически представлен механизм поиска в хэш таблице Oracle.
Изменения в реализации хэш таблиц Oracle:
* Хэш таблица над таблицей бд может быть сколь угодно большой и она может не поместиться в памяти
* битовая карта над данными в хэш таблице, если соответствующий бит таблицы установлен, то элемент есть в хэш таблице, иначе строку можно даже не искать.
Когда Oracle выбирает соединение хэшированием:
В основе выбора способ лежит стоимостная оценка:
Стоимость соединения вложенными циклами (NL) = стоимость получения T1 + кардинальность Т1 * Стоимость одного обращения к Т2
Стоимость соединения хэшированием (hash) = стоимость получения Т1 + стоимость получения Т2 + стоимость хэширования и сравнения.
Исходя из этих формул можно сделать вывод, что hash соединение выгодней, когда :
* Нужно считать большой объем данных для соединения или на правой таблице таблице нет индекса.
Многоблочное считывание при hash join выгодней, чем последовательное одноблочное сканирование индекса правой таблицы.
* Параллельное выполнение запросов - хэширование и поиск в хэш таблице хорошо распараллеливается, поиск по связанному списку индекса практически не параллелится.
Когда hash join не может быть использован:
* Поиск по диапазону (или любой операции отличной от = ) не применим для хэш таблицы, результат функции дает непоследовательные данные, которые не просканировать последовательно.
Рассмотрим подробней вариант, однопроходного поиска в хэш таблице, т.е. когда объема памяти достаточно, чтобы целиком разместить хэш секцию.
Для простоты будет использоваться Hash таблица цепочками.
1. Добавление элемента в хэш таблицу:
* Создаем объект и заполняем случайными парами: ключ хэширования - столбец хэширования в таблице, значение - rowid ссылка на таблице
* OraHash - является расширенной версией обычного хэш массива Hash
* В конструктор OraHash передаем размер доступной памяти под хэширование (hash_area_size) и создаем битовый массив массив (bitmap) произвольного размера (желательно больше размера хэш таблицы)
* Для установки флага битовой карты используется функция хэширования getBitmapHash - остаток от деления по числу элементов в битовой карте
* OraHash вызывает родительский класс Hash
Размер хэш таблицы задается равным 0.8 от доступной памяти
Полная формула количества хэш групп = 0.8 x hash_area_size / (db_block_size * hash_multiblock_io_count)
* Ключ хэшируется функцией getHash - остаток от деления на число секций
* Если секций пуста, то создается новый список для элементов HashEntryHolder
* Если список HashEntryHolder уже есть, то ищем в списке уникальных значений HashEntry
** Если его нет, то создаем новый HashEntry
** Иначе добавляем элемент в список дублей ValueList внутри уникального списка HashEntry
* При добавлении элемента происходит дополнительная проверка на доступность памяти в hash_area для нового элемента: HashEntryHolder.addCnt()
Если места нет, то элемент пишется на диск:
* В результате вставки получается хэш таблица (вывод функции dump). Хэширующая функция - остаток от деления на 10:
2. Реорганизация хэш таблицы:
По таблице видно, что ни одна секция не находится целиком в памяти, хотя каждая по отдельности меньше выделенной памяти (13)
Для решения этой проблемы секции в таблице реорганизуются, чтобы максимальное число секций оказалось в памяти:
3. Поиск элемента в хэш таблице:
* В первую очередь тестируем элемент на наличии в битовом массиве, без обращения к хэш таблице bitmap[getBitmapHash(key)
* Если элемент найден в битовом массиве и хэш секция находится в памяти, то ищем элемент в хэш массиве.
Если элементов с таким значеним несколько, то возвращается список этих элементов ValueList:
Дальнейший алгоритм не реализовался и описывается на словах:
* Если хэш секция не находится в памяти, то искомый элемент правой таблицы пропускается и добавляется в новую хэш таблицу для правой таблицы.
* И так до конца правой таблицы. В итоге после первого прохода мы имеем 2 хэш таблицы левой и правой таблицы. Oracle знает полное распределение данных в обоих частях.
* На основе этих данных хэш таблица для поиска, которая может целиком поместиться в памяти выбирается как из левой, так и из правой таблицы.
Также при следующих проходах не нужно считывать правую таблицу целиком, можно взять только соответствующую секцию из правой.
Т.е. если в память помещается только одна любая секция из левой таблицы, то для полного хэширования понадобится:
* 1 раз считать левую таблицу, чтобы ее прохэшировать и записать хэш - 1 секция на диск (2 I/O)
* 1 раз считать правую таблицу, чтобы также ее прохэшировать и записать на диск (2 I/O)
* Последовательно по 1 секции еще раз считать левую таблицу по 1 секции в память (1 I/O)
* Последовательно по 1 секции правой таблицы проверить наличие данных в левой (1 I/O)
Т.е. в итоге получается 6 считываний + записей левой+правой таблицы, против 2 считываний (I), если хэш таблица левой таблицы целиком помещается в память.
Итоговая стоимость соединения в 1 проход максимум в 3 раза больше, чем соединение таблиц в памяти.
Если в память помещается более 1 секции, то стоимость также уменьшается пропорционально, т.к. нужно меньшее число считываний+записей с диска.
Более сложный механизм, когда ни одна секция не помещается в памяти, алгоритм еще сильней усложняется, т.к. чтобы проверить наличие элемента в левой секции ее так или иначе надо считать целиком в память, хоть и последовательно. Описание алгоритма: Основы стоимостной оптимизации join
Данные рекомендации взяты мной из руководства Oracle по настройке базы данных, со временем они практически не меняются, посмотреть их можно здесь, это глава 11.5. Ссылка может не работать, все зависит от того, как долго Oracle решит хранить этот фрагмент документации в интернете.
Не используйте SQL-функции в предикатах. Любое выражение в котором используется колонка (expression), например функция, использующая колонку, как аргумент, приведет к тому, что индекс для данной колонки (если он есть) использоваться не будет, даже если это уникальный индекс. Хотя, если для колонки имеется составной индекс (function-based) на основе применяемой в предикате функции, то он может быть использован.
где numexpr выражение числового типа, то Oracle преобразует ваше условие в:
и индекс использован не будет.
Где по числовой колонке numcol построен индекс.
План запроса.
Практически любую задачу по получению каких-либо результатов из базы данных можно решить несколькими способами, т.е. написать несколько разных запросов, которые дадут один и тот же результат. Это, однако не означает, что база данных эти запросы будет выполнять по-разному. Также неверно мнение о том, что структура запроса может повлиять на то, как Oracle будет его выполнять, это касается порядка временных таблиц, JOINS и условий отбора в WHERE. Решение о том, как построить запрос принимает оптимизатор Oracle. Алгоритм получения сервером данных для конкретного запроса называют планом запроса.
Практически все продукты для работы с базой данных Oracle позволяют просмотреть план конкретного запроса. Так как слушатели этих лекций используют PL/SQL Developer, то для получения плана запроса в нем необходимо сделать следующее:
Существует стандартный механизм получения плана запроса. Для этого используется конструкция (команда) EXPLAIN PLAN FOR:
План запроса будет выведен в виде таблицы с одним полем, выглядит он так:
Важно ! Во всех планах запросов, первостепенное значение имеют колонки операций и названия объектов над которыми эти операции производятся. Все остальные колонки имеют оценочный характер, часть из них формируется на основе статистики, которая может устареть или вообще отсутствовать. При анализе плана запроса вы должны представлять объемы записей в таблицах, а также примерный алгоритм соединения таблиц.
В приведенном выше примере показан план запроса, полученный с помощью EXPLAIN PLAN FOR, более наглядную картину дает окно плана запроса в PL/SQL Developer:
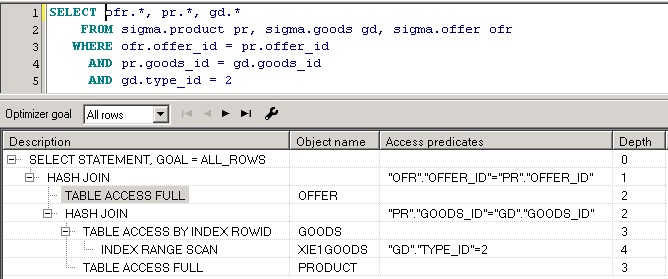
План всегда имеет иерархическую структуру. Операция соединения результирующих наборов оперирует парами дочерних операций. Операция получения данных может использовать вспомогательную операцию, такую, например, как сканирование индекса.
Данные результирующих наборов получаются в порядке следования этих наборов в плане запроса. Операция получения данных результирующего набора может состоять из нескольких шагов, которые характеризуются глубиной операции (колонка Depth).
При анализе плана в первую очередь необходимо обращать внимание на способы, с помощью которых получены данные результирующих наборов.
Некоторые термины в плане запроса.
План запроса имеет форму таблицы, один из столбцов которой описывает тип производимых сервером операций. Вот некоторые из них, которые встречаются наиболее часто:
Анализ плана запроса.
При анализе плана запроса вам необходимо примерно представлять объемы записей в таблицах и наличие у них индексов, которые могут пригодиться при фильтрации записей. Для доступа к данным Oracle использует несколько стратегий, какие из них выбраны для каждой из таблиц можно понять из плана запроса. При просмотре плана, вам необходимо решить, правильная ли выбрана стратегия в том или ином случае. Ниже приведены краткие описания способов доступа и механизмов отбора записей при соединениях результирующих наборов.
Full Table Scan (Table Access Full).
Может показаться, что доступ к данным таблицы быстрее осуществлять через индекс, но это не так. Иногда дешевле прочитать всю таблицу целиком, чем прочитать, например, 80% записей таблицы через индекс, так как чтение индекса тоже требует ресурсов. Очень не желательна ситуация, когда эта операция стоит первой в объединении наборов записей и таблица, которая читается полностью, большая. Еще хуже ситуация с большой таблицей на второй позиции в объединении, это означает, что она также будет прочитана полностью, как минимум, один раз, а если объединение производится через NESTED LOOPS, то таблица будет читаться несколько раз, поэтому запрос будет работать очень долго.
Nested Loops.
Такое соединение может использоваться оптимизатором, когда небольшой основной набор записей (стоит первым в плане запроса) объединяется с помощью условия, позволяющего эффективно выбрать записи из второго набора. Важным условием успешного использования такого соединения является наличие связи между основным и второстепенным набором записей. Если такой связи нет, то для каждой записи в первом наборе, из второго набора будут извлекаться одни и те же записи, что может привести к значительному увеличению времени запроса. Если вы видите, что в плане запроса применен NESTED LOOPS, а соединяемые наборы не удовлетворяют этому условию, то налицо ошибка.
Hash Joins.
Используется при соединении больших наборов данных. Оптимизатор использует наименьший из наборов данных для построения в памяти хэш-таблицы по ключу соединения. Затем он сканирует большую таблицу, используя хэш-таблицу для нахождения записей, которые удовлетворяют условию объединения.
Оптимизатор использует HASH JOIN, если наборы данных соединяются с помощью операторов и ключевых слов эквивалентности (=, AND) и если присутствует одно из условий:
■ Необходимо соединить наборы данных большого объема.
■ Большая часть небольшого набора данных должна быть использована в соединении.
Sort Merge Join.
Данное соединение может быть применено для независимых наборов данных. Обычно Oracle выбирает такую стратегию, если наборы данных уже отсортированы ранее, и если дальнейшая сортировка результата соединения не требуется. Обычно это имеет место для наборов, которые соединяются с помощью операторов , >=. Для этого типа соединения нет понятия главного и вспомогательного набора данных, сначала оба набора сортируются по общему ключу, а затем сливаются в одно целое. Если какой-то из наборов уже отсортирован, то повторная сортировка для него не производится.
Cartesian Joins.
Это соединение используется, когда одна и более таблиц не имеют никаких условий соединения с какой-либо другой таблицей в запросе. В этом случае произойдет объединение каждой записи из одного набора данных с каждой записью в другом. Такое соединение может быть выбрано между двумя небольшими таблицами, а в дальнейшем этот набор данных будет соединен с другой большой таблицей. Наличие такого соединения может обозначать присутствие серьезных проблем в запросе, особенно, если соединяемые таблицы по MERGE JOIN CARTESIAN. В этом случае, возможно, упущены дополнительные условия соединения наборов данных.
Хинты.
Использование хинтов.
Хинт ставится после ключевого слова, которое определяет некую цельную конструкцию запроса, в данном разделе речь пойдет о хинтах в запросах к данным, т.е. тех, которые оформляются оператором SELECT и ключевых словах, используемых в сочетании с ним. Хинт указывается в закрытом комментарии после оператора:
В данном примере используется хинт RULE.
FIRST_ROWS.
Данный хинт дает указание оптимизатору выбрать такой план запроса при котором первые записи результатов будут получены максиально быстрым способом. Хорош при отладке запроса, чтобы убедиться, что выдается то, что необходимо. Если предполагается, что запрос вернет много записей, то при использовании такого хинта он может работать дольше.
ORDERED / LEADING.
При использовании этого хинта оптимизатор соединяет наборы данных в том порядке, в каком они следуют после оператора FROM. Вот пример разных последовательностей:
Порядок наборов данных необходимо выбирать аккуратно, чтобы соединяемые объекты имели какое-то условие связи в WHERE или после ключевого слова ON. Например в приведенном выше примере 4 версия списка во FROM приведет к перемножению таблиц GOODS и OFFER, так как они не связаны друг с другом условиями.
Данный хинт часто бывает полезен, если статистика по таблицам не собрана, план запроса не верный, и вам точно известно, как должны соединяться таблицы. При использовании данного хинта старайтесь выстроить порядок соединения так, чтобы тяжесть обработки данных следовала в сторону увеличения, т.е. сначала соедините наборы поменьше или с хорошими условиями отбора, чтобы результат их соединения был наименьшим по количеству записей, затем подключайте наборы данных большего размера.
Более удобен в использовании хинт LEADING. Он позволяет соединить наборы данных в порядке перечисления их (или их алиасов) в списке аргументов хинта:
Порядок связи в этом примере будет такой: product -> offer -> goods. Использование этого хинта предпочтительнее при отладке, если список наборов данных большой.
MATERIALIZE.
Дает указание оптимизатору построить временную таблицу (материализовать результаты) для запроса, к которому этот хинт применяется, работает только в конструкции WITH. Очень полезен при обработке больших объемов данных, так как позволяет разбить запрос на части, в этом случае улучшается читабельность запроса, а также может быть получен правильный план. Пример использования:
План запроса выглядит так:
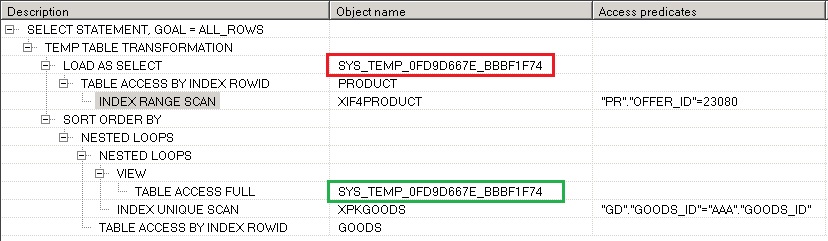
Красным цветом помечена таблица при ее создании, зеленым ее использование в соединении.
INDEX.
Дает указание оптимизатору использовать индекс при чтении данных из таблицы. Полезен тем, что может предотвратить чтение всего содержимого таблицы, если вы считаете, что этого делать не нужно. Пример использования:
Этот хинт сработает в том случае, если у таблицы есть указываемый индекс, и его можно использовать на основе одного или нескольких условий при получении данных таблицы. В приведенном примере в составе индекса есть поле OFFER_ID на второй позиции и он может быть использован, план запроса выглядит в этом случае так:

Комбинации хинтов.
Использование комбинации хинтов допустимо. Нужный эффект можно получить, если хинты в одном запросе не протеворечат друг другу. При записи хинты разделяются пробелами:
В данном примере используется хинт для установки порядка соединения наборов данных и способа доступа к таблице, противоречия в их использовании нет.
Читайте также: