
Что такое nlu и как компьютер понимает естественную речь
Обновлено: 06.07.2024
Чтобы с навыком можно было общаться на естественном языке, он должен уметь корректно обрабатывать реплики пользователей — распознавать задачу, которую хочет решить пользователь (например, заказать такси), а также извлекать нужные детали (на какое число и по какому адресу).
Для упрощения задач NLP (Natural Language Processing) Диалоги предоставляют специальный инструмент — встроенный язык описания пользовательского запроса. С его помощью вы можете описать правила, по которым Диалоги будут классифицировать запросы и извлекать из них нужные данные, в консоли разработчика.
Когда пользователь произносит команду, Диалоги распознают текст и извлекают те фразы, которые описывают намерения пользователя согласно вашим правилам. Распознанные данные Диалоги присылают в навык.
Что такое интент, форма и слоты
Чтобы формализовать разбор реплик, Диалоги используют интенты, формы и слоты.
Интент — это задача, которую пользователь формулирует в конкретной реплике. Например, узнать погоду . Каждому интенту соответствует одна форма.
Форма — контейнер с информацией, который Диалоги заполняют, распознавая запрос пользователя. Форма всегда соответствует одному интенту и содержит набор типизированных слотов.
Слот — поле формы. Каждый слот имеет название, тип данных и признак обязательности. Например, из реплики погода на завтра в Питере для заполнения слотов будут извлечены дата ( завтра ) и место ( в Питере ).
При обработке реплики Диалоги сначала определяют, к какому интенту она относится. После этого извлекают из реплики необходимые параметры и заполняют ими слоты формы. Распознанные данные Диалоги отправят в навык в поле запроса request.nlu . Если реплика не относится ни к одному интенту, поле request.nlu будет пустым (подробнее).
Синтаксис
Ниже показан пример описания интента:
Примечание. Вложенные элементы следует обозначать отступом в 4 пробела. Описание интента состоит из ключевых слов root , slots и filler , а также нетерминалов — фраз на естественном языке, описывающих, на какие запросы должна срабатывать грамматика. Нетерминалы обозначаются символом $ . Они эквиваленты переменным в языках программирования. Нетерминалы можно скрыть, чтобы они были доступны только внутри родительского нетерминала.Внутри нетерминала $PlayGame $Game сработает только на слово «игру» , а снаружи — на все падежи слова «игра» .
Поддерживаемые ключевые слова:
root — обозначение корневого элемента. Описывает шаблон, по которому будет отбираться вся реплика целиком.В этом примере используются квантификатор и оператор [].
slots — описание слотов запроса. Это поле будет присутствовать в JSON, который Диалоги отправят в навык после обработки запроса. Подробнее см. Какие данные передаются в навык. filler — стоп-слова, которые можно отбросить при разборе запроса. Для исключения незначащих, неинформативных слов используется специальный классификатор, использующий контекст предложения. Например, для разбора из примера выше срабаботает как фраза «включи свет» , так и «включи свет, пожалуйста» . Примечание. Порядок описания элементов в грамматике не имеет значения.Типизированные слоты
Слоты могут содержать не только строковое значение, но и именованные сущности:
Для указания типизированного слота используются поля type и нетерминал, содержащий этот тип:
Пользовательские сущности в слотах
Чтобы задать собственные типы слотов, опишите их в разделе Сущности , например:
После этого тип станет доступен в качестве нетерминала грамматики и типа слота:
При указании lemma: true в описании сущности все ее элементы будут сравниваться без учета формы слова.Сработает на пешка , пешку , пешкой .
Примечание. lemma: true распространяется на всю сущность и не отменяется при помощи директивы %exactДирективы
Директива — это специальная команда, переключающая парсер запросов в определенный режим работы. Директивы всегда начинаются с символа % . Например:
Действие директивы распространяется на все последующие нетерминалы. Директиву можно указать в начале всей грамматики, а также непосредственно перед нетерминалом. В последнем случае директива будет действовать до конца отступа или до отменяющей директивы. Пример:Ниже перечислены поддерживаемые директивы.
Нетерминалы будут сравниваться без учета формы слова. Пример (запросы включи свет и включай свет будут засчитаны как совпадение): Нетерминалы будут сравниваться по точному совпадению. Пример (под правило попадет только запрос включи свет ): С помощью директивы %negative можно указать отрицательные примеры для элемента. Пример (такая форма сработает для условия включи игру города , и не сработает для включи игру престолов ):\n Внимание. Отрицательные правила должны быть более конкретными, чем положительные. Например, если в обозначении корневого элемента root указать элемент включи сказку .* , а в %negative — включи .* , то фраза включи сказку о лисе будет положительной в такой грамматике.Директива %positive делает все последующие правила положительными.
Оператор []
Позволяет игнорировать порядок слов в грамматике. Пример:В этом примере положительными срабатываниями будут включи свет и свет включи .
Квантификаторы
В описании элементов грамматики можно использовать квантификаторы:
Совпадением будет как включи свет , так и включи, пожалуйста, свет .
Совпадениями будут включи свет на кухне , включи свет на кухне и во всем доме и т. д.
Совпадениями будут включи свет на кухне и в ванной , включи свет на кухне и ванной, и в коридоре и т. д., но не просто «включи свет на кухне» .
В слот попадет только первый распознанный нетерминал, если в одном интенте он используется несколько раз (только первый $Where из примеров выше попадет в слот).
Встроенные интенты
Если в навыке есть хотя бы один интент, Яндекс.Диалоги дополнительно отправляют интенты, универсальные для большинства навыков:
YANDEX.REPEAT — просьба повторить последний ответ навыка.Какие данные передаются в навык
После того как запрос будет обработан, Диалоги отправят навыку распознанные данные — в поле request.nlu . Это поле содержит идентификатор интента, а также описание заполненных слотов. Например:
Если реплика не относится ни к одному интенту, поле request.nlu будет пустым.
В случае типизированных слотов в запросе будет указан тип слота и его каноническое значение.
Полезные ссылки
">,"extra_meta":[>,>,>,>,>,>,>,>,>,>,>,>,>,>,>,>,>,>,>,>,>,>],"title":"Обработка естественного языка (NLP). Алиса. Диалоги","canonical":"https://dialogs.yandex.ru/docs/alice/doc/nlu.html","extra_js":[[],[,"mods":<>,"__func136":true,"tag":"script","bem":false,"attrs":,"__func63":true>,,"mods":<>,"__func136":true,"tag":"script","bem":false,"attrs":,"__func63":true>],[,"mods":<>,"__func136":true,"tag":"script","bem":false,"attrs":,"__func63":true>]],"extra_css":[[],[,"mods":<>,"__func65":true,"__func64":true,"bem":false,"tag":"link","attrs":>,,"mods":<>,"__func65":true,"__func64":true,"bem":false,"tag":"link","attrs":>],[,"mods":<>,"__func65":true,"__func64":true,"bem":false,"tag":"link","attrs":>]],"csp":<"script-src":[]>,"documentPath":"/dev/dialogs/alice/doc/nlu.html","isBreadcrumbsEnabled":true,"lang":"ru","params":<>>>>'>Чтобы с навыком можно было общаться на естественном языке, он должен уметь корректно обрабатывать реплики пользователей — распознавать задачу, которую хочет решить пользователь (например, заказать такси), а также извлекать нужные детали (на какое число и по какому адресу).Для упрощения задач NLP (Natural Language Processing) Диалоги предоставляют специальный инструмент — встроенный язык описания пользовательского запроса. С его помощью вы можете описать правила, по которым Диалоги будут классифицировать запросы и извлекать из них нужные данные, в консоли разработчика.
Когда пользователь произносит команду, Диалоги распознают текст и извлекают те фразы, которые описывают намерения пользователя согласно вашим правилам. Распознанные данные Диалоги присылают в навык.
Что такое интент, форма и слоты
Чтобы формализовать разбор реплик, Диалоги используют интенты, формы и слоты.
Интент — это задача, которую пользователь формулирует в конкретной реплике. Например, узнать погоду . Каждому интенту соответствует одна форма.
Форма — контейнер с информацией, который Диалоги заполняют, распознавая запрос пользователя. Форма всегда соответствует одному интенту и содержит набор типизированных слотов.
Слот — поле формы. Каждый слот имеет название, тип данных и признак обязательности. Например, из реплики погода на завтра в Питере для заполнения слотов будут извлечены дата ( завтра ) и место ( в Питере ).
При обработке реплики Диалоги сначала определяют, к какому интенту она относится. После этого извлекают из реплики необходимые параметры и заполняют ими слоты формы. Распознанные данные Диалоги отправят в навык в поле запроса request.nlu . Если реплика не относится ни к одному интенту, поле request.nlu будет пустым (подробнее).
Синтаксис
Ниже показан пример описания интента:
Примечание. Вложенные элементы следует обозначать отступом в 4 пробела. Описание интента состоит из ключевых слов root , slots и filler , а также нетерминалов — фраз на естественном языке, описывающих, на какие запросы должна срабатывать грамматика. Нетерминалы обозначаются символом $ . Они эквиваленты переменным в языках программирования. Нетерминалы можно скрыть, чтобы они были доступны только внутри родительского нетерминала.Внутри нетерминала $PlayGame $Game сработает только на слово «игру» , а снаружи — на все падежи слова «игра» .
Поддерживаемые ключевые слова:
root — обозначение корневого элемента. Описывает шаблон, по которому будет отбираться вся реплика целиком.В этом примере используются квантификатор и оператор [].
slots — описание слотов запроса. Это поле будет присутствовать в JSON, который Диалоги отправят в навык после обработки запроса. Подробнее см. Какие данные передаются в навык. filler — стоп-слова, которые можно отбросить при разборе запроса. Для исключения незначащих, неинформативных слов используется специальный классификатор, использующий контекст предложения. Например, для разбора из примера выше срабаботает как фраза «включи свет» , так и «включи свет, пожалуйста» . Примечание. Порядок описания элементов в грамматике не имеет значения.Типизированные слоты
Слоты могут содержать не только строковое значение, но и именованные сущности:
Для указания типизированного слота используются поля type и нетерминал, содержащий этот тип:
Пользовательские сущности в слотах
Чтобы задать собственные типы слотов, опишите их в разделе Сущности , например:
После этого тип станет доступен в качестве нетерминала грамматики и типа слота:
При указании lemma: true в описании сущности все ее элементы будут сравниваться без учета формы слова.Сработает на пешка , пешку , пешкой .
Примечание. lemma: true распространяется на всю сущность и не отменяется при помощи директивы %exactДирективы
Директива — это специальная команда, переключающая парсер запросов в определенный режим работы. Директивы всегда начинаются с символа % . Например:
Действие директивы распространяется на все последующие нетерминалы. Директиву можно указать в начале всей грамматики, а также непосредственно перед нетерминалом. В последнем случае директива будет действовать до конца отступа или до отменяющей директивы. Пример:Ниже перечислены поддерживаемые директивы.
Нетерминалы будут сравниваться без учета формы слова. Пример (запросы включи свет и включай свет будут засчитаны как совпадение): Нетерминалы будут сравниваться по точному совпадению. Пример (под правило попадет только запрос включи свет ): С помощью директивы %negative можно указать отрицательные примеры для элемента. Пример (такая форма сработает для условия включи игру города , и не сработает для включи игру престолов ): Внимание. Отрицательные правила должны быть более конкретными, чем положительные. Например, если в обозначении корневого элемента root указать элемент включи сказку .* , а в %negative — включи .* , то фраза включи сказку о лисе будет положительной в такой грамматике.Директива %positive делает все последующие правила положительными.
Оператор []
Позволяет игнорировать порядок слов в грамматике. Пример:В этом примере положительными срабатываниями будут включи свет и свет включи .
Квантификаторы
В описании элементов грамматики можно использовать квантификаторы:
Совпадением будет как включи свет , так и включи, пожалуйста, свет .
Совпадениями будут включи свет на кухне , включи свет на кухне и во всем доме и т. д.
Совпадениями будут включи свет на кухне и в ванной , включи свет на кухне и ванной, и в коридоре и т. д., но не просто «включи свет на кухне» .
В слот попадет только первый распознанный нетерминал, если в одном интенте он используется несколько раз (только первый $Where из примеров выше попадет в слот).
Встроенные интенты
Если в навыке есть хотя бы один интент, Яндекс.Диалоги дополнительно отправляют интенты, универсальные для большинства навыков:

Что такое Natural Language Processing?
Natural Language Processing (далее – NLP) – обработка естественного языка – подраздел информатики и AI, посвященный тому, как компьютеры анализируют естественные (человеческие) языки. NLP позволяет применять алгоритмы машинного обучения для текста и речи.
Сегодня у многих из нас есть смартфоны с распознаванием речи – в них используется NLP для того, чтобы понимать нашу речь. Также многие люди используют ноутбуки со встроенным в ОС распознаванием речи.
Примеры
Cortana

В Windows есть виртуальный помощник Cortana, который распознает речь. С помощью Cortana можно создавать напоминания, открывать приложения, отправлять письма, играть в игры, узнавать погоду и т.д.

Gmail
Известный почтовый сервис умеет определять спам, чтобы он не попадал во входящие вашего почтового ящика.
Dialogflow

Платформа от Google, которая позволяет создавать NLP-ботов. Например, можно сделать бота для заказа пиццы, которому не нужен старомодный IVR, чтобы принять ваш заказ.
Python-библиотека NLTK
NLTK (Natural Language Toolkit) – ведущая платформа для создания NLP-программ на Python. У нее есть легкие в использовании интерфейсы для многих языковых корпусов, а также библиотеки для обработки текстов для классификации, токенизации, стемминга, разметки, фильтрации и семантических рассуждений. Ну и еще это бесплатный опенсорсный проект, который развивается с помощью коммьюнити.
Мы будем использовать этот инструмент, чтобы показать основы NLP. Для всех последующих примеров я предполагаю, что NLTK уже импортирован; сделать это можно командой import nltk
Основы NLP для текста
В этой статье мы рассмотрим темы:
- Токенизация по предложениям.
- Токенизация по словам. и стемминг текста.
- Стоп-слова.
- Регулярные выражения. . .
1. Токенизация по предложениям
Токенизация (иногда – сегментация) по предложениям – это процесс разделения письменного языка на предложения-компоненты. Идея выглядит довольно простой. В английском и некоторых других языках мы можем вычленять предложение каждый раз, когда находим определенный знак пунктуации – точку.
Но даже в английском эта задача нетривиальна, так как точка используется и в сокращениях. Таблица сокращений может сильно помочь во время обработки текста, чтобы избежать неверной расстановки границ предложений. В большинстве случаев для этого используются библиотеки, так что можете особо не переживать о деталях реализации.
Возьмем небольшой текст про настольную игру нарды:
Чтобы сделать токенизацию предложений с помощью NLTK, можно воспользоваться методом nltk.sent_tokenize
На выходе мы получим 3 отдельных предложения:
2. Токенизация по словам
Токенизация (иногда – сегментация) по словам – это процесс разделения предложений на слова-компоненты. В английском и многих других языках, использующих ту или иную версию латинского алфавита, пробел – это неплохой разделитель слов.
Тем не менее, могут возникнуть проблемы, если мы будем использовать только пробел – в английском составные существительные пишутся по-разному и иногда через пробел. И тут вновь нам помогают библиотеки.
Давайте возьмем предложения из предыдущего примера и применим к ним метод nltk.word_tokenize
3. Лемматизация и стемминг текста
Обычно тексты содержат разные грамматические формы одного и того же слова, а также могут встречаться однокоренные слова. Лемматизация и стемминг преследуют цель привести все встречающиеся словоформы к одной, нормальной словарной форме.
Приведение разных словоформ к одной:
То же самое, но уже применительно к целому предложению:
Лемматизация и стемминг – это частные случаи нормализации и они отличаются.
Стемминг – это грубый эвристический процесс, который отрезает «лишнее» от корня слов, часто это приводит к потере словообразовательных суффиксов.
Лемматизация – это более тонкий процесс, который использует словарь и морфологический анализ, чтобы в итоге привести слово к его канонической форме – лемме.
Отличие в том, что стеммер (конкретная реализация алгоритма стемминга – прим.переводчика) действует без знания контекста и, соответственно, не понимает разницу между словами, которые имеют разный смысл в зависимости от части речи. Однако у стеммеров есть и свои преимущества: их проще внедрить и они работают быстрее. Плюс, более низкая «аккуратность» может не иметь значения в некоторых случаях.
- Слово good – это лемма для слова better. Стеммер не увидит эту связь, так как здесь нужно сверяться со словарем.
- Слово play – это базовая форма слова playing. Тут справятся и стемминг, и лемматизация.
- Слово meeting может быть как нормальной формой существительного, так и формой глагола to meet, в зависимости от контекста. В отличие от стемминга, лемматизация попробует выбрать правильную лемму, опираясь на контекст.
4. Стоп-слова

Стоп-слова – это слова, которые выкидываются из текста до/после обработки текста. Когда мы применяем машинное обучение к текстам, такие слова могут добавить много шума, поэтому необходимо избавляться от нерелевантных слов.
Стоп-слова это обычно понимают артикли, междометия, союзы и т.д., которые не несут смысловой нагрузки. При этом надо понимать, что не существует универсального списка стоп-слов, все зависит от конкретного случая.
В NLTK есть предустановленный список стоп-слов. Перед первым использованием вам понадобится его скачать: nltk.download(“stopwords”) . После скачивания можно импортировать пакет stopwords и посмотреть на сами слова:
Рассмотрим, как можно убрать стоп-слова из предложения:
Если вы не знакомы с list comprehensions, то можно узнать побольше здесь. Вот другой способ добиться того же результата:
Тем не менее, помните, что list comprehensions быстрее, так как оптимизированы – интерпретатор выявляет предиктивный паттерн во время цикла.
Вы можете спросить, почему мы конвертировали список во множество. Множество это абстрактный тип данных, который может хранить уникальные значения, в неопределенном порядке. Поиск по множеству гораздо быстрее поиска по списку. Для небольшого количества слов это не имеет значения, но если речь про большое количество слов, то строго рекомендуется использовать множества. Если хотите узнать чуть больше про время выполнения разных операций, посмотрите на эту чудесную шпаргалку.
5. Регулярные выражения.

Регулярное выражение (регулярка, regexp, regex) – это последовательность символов, которая определяет шаблон поиска. Например:
- . – любой символ, кроме перевода строки;
- \w – один символ;
- \d – одна цифра;
- \s – один пробел;
- \W – один НЕсимвол;
- \D – одна НЕцифра;
- \S – один НЕпробел;
- [abc] – находит любой из указанных символов match any of a, b, or c;
- [^abc] – находит любой символ, кроме указанных;
- [a-g] – находит символ в промежутке от a до g.
Регулярные выражение используют обратный слеш (\) для обозначения специальных форм или чтобы разрешить использование спецсимволов. Это противоречит использованию обратного слеша в Python: например, чтобы буквально обозначить обратный слеш, необходимо написать '\\\\' в качестве шаблона для поиска, потому что регулярное выражение должно выглядеть как \\ , где каждый обратный слеш должен быть экранирован.
Решение – использовать нотацию raw string для шаблонов поиска; обратные слеши не будут особым образом обрабатываться, если использованы с префиксом ‘r’ . Таким образом, r”\n” – это строка с двумя символами (‘\’ и ‘n’) , а “\n” – строка с одним символом (перевод строки).
Мы можем использовать регулярки для дополнительного фильтрования нашего текста. Например, можно убрать все символы, которые не являются словами. Во многих случаях пунктуация не нужна и ее легко убрать с помощью регулярок.
Модуль re в Python представляет операции с регулярными выражениями. Мы можем использовать функцию re.sub, чтобы заменить все, что подходит под шаблон поиска, на указанную строку. Вот так можно заменить все НЕслова на пробелы:
Регулярки – это мощный инструмент, с его помощью можно создавать гораздо более сложные шаблоны. Если вы хотите узнать больше о регулярных выражениях, то могу порекомендовать эти 2 веб-приложения: regex, regex101.
6. Мешок слов

Алгоритмы машинного обучения не могут напрямую работать с сырым текстом, поэтому необходимо конвертировать текст в наборы цифр (векторы). Это называется извлечением признаков.
Мешок слов – это популярная и простая техника извлечения признаков, используемая при работе с текстом. Она описывает вхождения каждого слова в текст.
Чтобы использовать модель, нам нужно:
- Определить словарь известных слов (токенов).
- Выбрать степень присутствия известных слов.
Интуиция подсказывает, что схожие документы имеют схожее содержимое. Также, благодаря содержимому, мы можем узнать кое-что о смысле документа.
Пример:
Рассмотрим шаги создания этой модели. Мы используем только 4 предложения, чтобы понять, как работает модель. В реальной жизни вы столкнетесь с бОльшими объемами данных.
1. Загружаем данные

Представим, что это наши данные и мы хотим загрузить их в виде массива:
Для этого достаточно прочитать файл и разделить по строкам:
2. Определяем словарь

Соберем все уникальные слова из 4 загруженных предложений, игнорируя регистр, пунктуацию и односимвольные токены. Это и будет наш словарь (известные слова).
Для создания словаря можно использовать класс CountVectorizer из библиотеки sklearn. Переходим к следующему шагу.
3. Создаем векторы документа

Далее, мы должны оценить слова в документе. На этом шаге наша цель – превратить сырой текст в набор цифр. После этого, мы используем эти наборы как входные данные для модели машинного обучения. Простейший метод скоринга – это отметить наличие слов, то есть ставить 1, если есть слово и 0 при его отсутствии.
Теперь мы можем создать мешок слов используя вышеупомянутый класс CountVectorizer.

Это наши предложения. Теперь мы видим, как работает модель «мешок слов».

Еще пару слов про мешок слов

Сложность этой модели в том, как определить словарь и как подсчитать вхождение слов.
Когда размер словаря увеличивается, вектор документа тоже растет. В примере выше, длина вектора равна количеству известных слов.
В некоторых случаях, у нас может быть неимоверно большой объем данных и тогда вектор может состоять из тысяч или миллионов элементов. Более того, каждый документ может содержать лишь малую часть слов из словаря.
Как следствие, в векторном представлении будет много нулей. Векторы с большим количеством нулей называются разреженным векторами (sparse vectors), они требуют больше памяти и вычислительных ресурсов.
Однако мы можем уменьшить количество известных слов, когда используем эту модель, чтобы снизить требования к вычислительным ресурсам. Для этого можно использовать те же техники, что мы уже рассматривали до создания мешка слов:
- игнорирование регистра слов;
- игнорирование пунктуации;
- выкидывание стоп-слов;
- приведение слов к их базовым формам (лемматизация и стемминг);
- исправление неправильно написанных слов.
N-грамма это последовательность каких-либо сущностей (слов, букв, чисел, цифр и т.д.). В контексте языковых корпусов, под N-граммой обычно понимают последовательность слов. Юниграмма это одно слово, биграмма это последовательность двух слов, триграмма – три слова и так далее. Цифра N обозначает, сколько сгруппированных слов входит в N-грамму. В модель попадают не все возможные N-граммы, а только те, что фигурируют в корпусе.
Рассмотрим такое предложение:
Вот его биграммы:
- the office
- office building
- building is
- is open
- open today
Оценка (скоринг) слов
Когда создан словарь, следует оценить наличие слов. Мы уже рассматривали простой, бинарный подход (1 – есть слово, 0 – нет слова).
Есть и другие методы:
- Количество. Подсчитывается, сколько раз каждое слово встречается в документе.
- Частотность. Подсчитывается, как часто каждое слово встречается в тексте (по отношению к общему количеству слов).
7. TF-IDF
TF-IDF (сокращение от term frequency — inverse document frequency) – это статистическая мера для оценки важности слова в документе, который является частью коллекции или корпуса.
Скоринг по TF-IDF растет пропорционально частоте появления слова в документе, но это компенсируется количеством документов, содержащих это слово.
Формула скоринга для слова X в документе Y:
TF (term frequency — частота слова) – отношение числа вхождений слова к общему числу слов документа.

IDF (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое слово встречается в документах коллекции.

В итоге, вычислить TF-IDF для слова term можно так:


Заключение
В этой статье были разобраны основы NLP для текста, а именно:
- NLP позволяет применять алгоритмы машинного обучения для текста и речи;
- NLTK (Natural Language Toolkit) – ведущая платформа для создания NLP-программ на Python;
- токенизация по предложениям – это процесс разделения письменного языка на предложения-компоненты;
- токенизация по словам – это процесс разделения предложений на слова-компоненты;
- лемматизация и стемминг преследуют цель привести все встречающиеся словоформы к одной, нормальной словарной форме;
- стоп-слова – это слова, которые выкидываются из текста до/после обработки текста;
- регулярное выражение (регулярка, regexp, regex) – это последовательность символов, которая определяет шаблон поиска;
- мешок слов – это популярная и простая техника извлечения признаков, используемая при работе с текстом. Она описывает вхождения каждого слова в текст.
Если вы хотите увидеть все описанные концепции в одном большом примере, то вам сюда.

Обработка естественного языка или NLP (от англ. Natural language processing) — одна из самых известных областей науки о данных. За последнее десятилетие она приобрела большую популярность как в промышленных, так и в академических кругах.
Но правда в том, что NLP — это далеко не новая область. Стремление человека к тому, чтобы компьютеры понимали наш язык, существовало с момента их создания. Да, те старые компьютеры, которые с трудом могли запустить несколько программ одновременно, всё же успели познакомится со сложностью естественных языков.
Естественный язык — это любой человеческий язык, такой как английский, арабский, русский и т. д. Насколько трудно сделать так, чтобы компьютер понимал естественные языки, зависит от их структуры. Более того, когда мы говорим, то часто по-разному произносим слова, наши акценты отличаются, независимо от того, используем ли мы родной язык или иностранный. Мы также часто склонны «жевать» слова во время разговора, чтобы быстрее донести мысль, не говоря уже обо всех сленговых словах, которые появляются каждый день.
Цель этой статьи — пролить свет на историю естественной обработки языка и её подразделы.
Начало развития NLP
Естественная обработка языка — это междисциплинарная область на стыке информатики и лингвистики. Существует бесконечное количество способов, чтобы соединить слова и составить из них предложение. Конечно, не все эти предложения будут грамматически правильными или даже иметь смысл.
Люди могут их различать, но компьютер — нет. Более того, нереально загрузить в него словарь со всеми возможными предложениями на всех возможных языках.
На ранних этапах учёные предлагали разделять любое предложение на набор слов, которые можно обрабатывать индивидуально, что гораздо проще, чем обрабатывать предложение целиком. Этот подход аналогичен тому, с помощью которого обучают новому языку детей и взрослых.
Когда мы только начинаем учить язык, нас знакомят с его частями речи. Для примера возьмём английский язык. В нём есть 9 основных частей речи: существительные, глаголы, прилагательные, наречия, местоимения, артикли и др. Эти части речи помогают понять назначение каждого слова в предложении.
Однако недостаточно знать категорию слова, особенно для тех, которые могут иметь более одного значения. Например, слово «leaves» может быть формой глагола « to leave» (англ. уходить) или формой множественного числа существительного «leaf» (англ. лист).
Поэтому компьютерам необходимо базовое понимание грамматики, чтобы обращаться к ней в случае замешательства. Таким образом появились правила структуры фраз.
Они представляют собой набор правил грамматики, по которым строится предложение. В английском языке оно образуется с помощью именной и глагольной группы. Рассмотрим предложение: «Anne ate the apple» (англ. Энн съела яблоко). Здесь «Anne» — это именная группа, а «ate the apple» — это глагольная группа.
Различные предложения формируются с использованием разных структур. По мере увеличения количества правил структуры фраз можно создавать дерево синтаксического анализа, чтобы классифицировать каждое слово в конкретном предложении и прийти к его общему значению.

Всё это отлично работает, если предложения просты и ясны. Но проблема в том, что они могут быть достаточно сложными, или в них могут использоваться не совсем однозначные слова или неологизмы. В этом случае компьютерам будет сложно понять, что имелось в виду.
Подразделы NLP
Обработка текста
Чат-боты — один из хорошо известных примеров NLP. Изначально чат-боты были основаны на системе правил. Это означало, что специалисты должны были закодировать сотни, а возможно, и тысячи правил структуры фраз, чтобы чат-бот корректно ответил на данные, которые вводит человек. Таким примером является Eliza. Это чат-бот, разработанный в 1960-х годах и пародирующий диалог с психотерапевтом.
Сегодня большинство чат-ботов и виртуальных помощников создаются и программируются с использованием методов машинного обучения. Эти методы основываются на многочисленных гигабайтах данных, собранных во время разговоров между людьми.
Чем больше данных будет передано модели машинного обучения, тем лучше будет работать чат-бот.
Распознавание речи
Чат-боты про то, как компьютеры понимают письменный язык. А что насчёт устной речи? Как компьютеры могут превратить звук в слова, а затем понять их значение?
Распознавание речи — второй подраздел обработки естественного языка. Это тоже совсем не новая технология. Она была в центре внимания многих исследователей в течение последних десятилетий. В 1970-х годах в Университете Карнеги-Меллона была разработана Harpy. Это была первая компьютерная программа, которая понимала 1000 слов.
В то время компьютеры не были достаточно мощными для распознавания речи в реальном времени, если только вы не говорили очень медленно. Это препятствие было устранено с появлением более быстрых и мощных компьютеров.
Синтез речи
Синтез речи во многом противоположен распознаванию речи. С помощью этой технологии у компьютера появилась возможность издавать звуки или произносить слова.
Первым в мире устройством для синтеза речи считается VODER (англ. Voice Operating Demonstrator — модель голосового аппарата). Оно было разработано Гомером Дадли из компании Bell Labs в 1930-х годах. У VODER было ручное управление. С тех пор многое изменилось.
В системах распознавания речи и чат-ботах предложения разбиваются на фонемы. Чтобы произнести определенное предложение, компьютер сохраняет эти фонемы, преобразовывает и воспроизводит.
Такой способ соединения фонем был и остаётся причиной того, что речь компьютера звучит очень роботизировано, поскольку на границах сшивки элементов часто возникают искажения.
Конечно, со временем звучание стало лучше. Использование современных алгоритмов в новейших виртуальных помощниках, таких как Siri, Cortana и Alexa, подтверждает то, что мы далеко продвинулись. Однако их речь по звучанию по-прежнему немного отличается от человеческой.
Заключение
Обработка естественного языка — общее название области, которое охватывает множество подразделов. Во всех них обычно используют модели машинного обучения, в основном нейросети, и данные множества разговоров между людьми.
Поскольку человеческие языки постоянно и стихийно развиваются, а компьютеру нужны чёткие и структурированные данные, при обработке возникают определённые проблемы и страдает точность. Кроме того, методы анализа текстов сильно зависят от языка, жанра, темы — всегда требуется дополнительная настройка. Однако сегодня многие задачи обработки естественного языка всё же решаются с применением глубокого обучения нейронных сетей.
Обработка естественного языка или NLP (англ. Natural Language Processing) — направление на стыке информатики и лингвистики, которое даёт возможность компьютерам понимать человеческий, т. е. естественный язык. Сейчас это одна из самых популярных областей науки о данных. Однако она существует с момента изобретения компьютеров.
Именно развитие техники и вычислительной мощности привело к невероятным достижениям в сфере NLP. Технологии синтеза и распознавания речи становятся такими же востребованными, как и технологии, работающие с письменными текстами. Разработка виртуальных помощников, таких как Siri, Alexa и Cortana, свидетельствует о том, насколько далеко продвинулись учёные.
Так что же необходимо знать, чтобы начать заниматься естественной обработкой языка? Нужна ли степень по информатике?
Чтобы стать специалистом по NLP, никакие степени не понадобятся. Всё, что вам потребуется, это изучить и попрактиковать определённые навыки, а также создать несколько проектов, чтобы подтвердить свои знания.
В начале пути в сфере обработки естественного языка может быть сложно. Объём информации в интернете огромен и может сбивать с толку или вести не туда. Я, как человек, который сам через это прошёл, решила написать статью и поделиться коротким и чётким руководством для старта.
1. Основы лингвистики
По сути, NLP — это про изучение языков. Разработчик пытается объяснить компьютеру, как понимать мудрёную письменную и устную речь человека.
Я занялась NLP, потому что меня всегда интересовали языки и то, как они образовывались и развивались с течением времени. Однако говорить на каком-то языке не означает полностью понимать его логику.
Чтобы иметь прочную основу для начала работы в NLP, необходимо полностью осознавать базовую логику языка, которому вы пытаетесь «научить» компьютер. Этот язык не обязательно должен быть вашим родным. Вы даже можете выучить новый при разработке проекта для его анализа.
Я не имею в виду, что нужно получать степень по лингвистике или что-то в этом роде. Я пытаюсь сказать, что понимание того, как языки решают различные проблемы, может оказаться полезным при разработке и анализе приложений для NLP. Более того, зная о межъязыковом влиянии, вы можете создавать многоязычные приложения.
Я рекомендую начать изучение основ лингвистики для обработки естественного языка с книги Эмили М. Бендер «Основы лингвистики для естественной обработки языка» (англ. Emily M. Bender Linguistic Fundamentals for Natural Language Processing).
2. Манипуляции со строками
«Язык», на котором вы пытаетесь анализировать и создавать приложения, обычно имеет форму строк. Даже если это приложение для распознавания речи, она всё равно преобразовывается в текст перед анализом.
Поэтому первый шаг, который вам нужно освоить перед погружением в основные техники NLP, — это манипуляции со строками с использованием любого языка программирования.
Если у вас нет опыта программирования, то рекомендую начать с Python. Он широко используется в различных областях науки о данных, включая NLP. Если у вас уже есть опыт программирования на других языках, то освоить манипуляцию со строками не составит труда.
3. Регулярные выражения
После того, как вы освоите операции со строками с помощью встроенных функций на выбранном вами языке программирования, следующим шагом будут регулярные выражения.
Это один из самых мощных и эффективных методов обработки текста. У регулярных выражений своя терминология, условия и синтаксис. Некоторые разработчики рассматривают их как мини-язык программирования. Они помогут обобщить правила и сделать приложения для обработки тестов более эффективными.
4. Очистка данных
Качество результата работы зависит от входных данных. Поэтому важно, чтобы они были подготовлены наилучшим образом. Этот навык применим не только к проектам по NLP, но и ко всем областям науки о данных. Однако подходы к очистке данных различаются в зависимости от задач и целевых результатов.
При подготовке текста к обработке и анализу мы обычно удаляем все знаки препинания. Это помогает улучшить вариативность слов в тексте. Также существуют различные типы слов, например стоп-слова, которые можно удалить для более эффективного анализа.
Три основных шага очистки текста для NLP:
- переведите все слова в нижний регистр;
- удалите стоп-слова (это часто используемые слова, которые не вносят дополнительную информацию в текст);
- приведите все слова к первоначальному корню.
5. Анализ текста
Наконец-то мы подошли к разделу навыков непосредственно из обработки естественного языка. Получив чистый набор данных, вы будете готовы создавать модели и начинать анализировать текст. Но для этого вам нужно немного знать терминологию из NLP.
Вот пять основных навыков и их значение:
- n-граммы — это тип вероятностной языковой модели, используемой для предсказания следующего элемента в последовательности слов;
- токенизация — это процесс разбиения предложения на отдельные слова или токены: глаголы, существительные, местоимения и т. д.;
- стемминг — это процесс нахождения основы для заданного слова, например cleaning => clean, но это не всегда работает;
- POS tagging — процесс обработки текста, задачей которого является определение части речи слова и присвоение ему соответствующего тега;
- лемматизация — процесс приведения заданного слова к его словарной форме.
6. Основы машинного обучения
Воспользовавшись основными навыками обработки языка, мы получаем корпус — набор данных после очистки текста и выполнения других основных задач NLP. Далее его необходимо проанализировать и извлечь полезную информацию. Для этого понадобится алгоритм машинного обучения.
Давайте рассмотрим два наиболее часто используемых алгоритма:
- Алгоритм кластеризации: применяется для поиска закономерностей в данных, таких как тональность, количество и частота используемых слов. Он подходит для обнаружения ложных новостей или неточной информации.
- Алгоритм классификации: используется для размещения текста в заранее определённых тегах. Его наиболее известное применение — сортировка входящих писем по папкам «входящие» или «спам».
7. Оценочные метрики
Это очень важный пункт, о котором обычно забывают. Каждый раз, когда вы применяете модель машинного обучения к данным, необходимо оценивать её результаты. Для каждой модели нужны свои метрики.
Вот некоторые из них:
- матрица неточностей;
- точность;
- F-score (среднее гармоничное значение между точностью и полнотой);
- ROC-кривая (англ. Receiver Operating Characteristic — рабочая характеристика приёмника).
Более подробную информацию вы можете узнать в материалах лекции из Массачусетского университета в Амхерсте (материалы на англ. яз.).
8. Глубокое обучение
Глубокое обучение полезно для определённых задач, требующих нелинейности пространства признаков. Оно предоставляет улучшенные модели с более высокой точностью и качественными результатами.
Один из самых часто используемых методов глубокого обучения в NLP — рекуррентные нейронные сети. К счастью, нет необходимости знать, как реализовать этот алгоритм или множество других, благодаря открытым библиотекам, таким как Keras и Scikit-learn, написанным на языке Python.
А что действительно нужно сделать, так это научиться эффективно использовать алгоритм, изучая его способ работы и узнавая, какие он даёт результаты.
9. Создание проектов
У меня этот шаг под номером 9, но его необходимо выполнять параллельно со всеми предыдущими шагами. Всегда сразу применяйте свои знания на практике. Это единственный способ проверить, насколько вы их усвоили.
При этом, чем больше вы знаете, тем более крутые приложения вы можете создавать. Вот несколько идей, которые можно опробовать, когда у вас будет достаточно знаний.
- приложение для тематического моделирования;
- идентификатор языка;
- генератор хайку;
- приложение, мониторящее социальные сети.
Таких идей ещё много. Дерзайте.
10. Научные статьи
Все подразделы науки о данных являются активными областями исследований. Как специалисту по данным в целом и специалисту по обработке естественного языка в частности, вам необходимо быть в курсе последних разработок в этой сфере. Единственный способ это сделать — следить за недавно опубликованными научными статьями о NLP.
Мне удобно создавать оповещения в Google Академии о новых публикациях по конкретным темам, которые меня интересуют: я получаю электронное письмо, как только они выходят.
Заключение
Иногда изучение нового навыка или получение новых знаний — довольно сложная задача. Но если не бросать это на полпути, а продолжать практиковаться и постоянно расширять базу знаний, вы достигнете своей цели.
«Мы можем делать всё, что захотим, если будем придерживаться этого достаточно долго», — Хелен Келлер.
Освоение обработки естественного языка может быть трудной задачей из-за огромного количества информации в интернете. Я надеюсь, что эта статья поможет вам сориентироваться в процессе обучения и сделает его немного проще.
Согласно данным компании Research and Market объём мирового рынка обработки естественного языка увеличится с $10,2 млрд. в 2019 году до $26,4 млрд. К 2024 году при совокупном годовом темпе роста (CAGR) на 21,0% в течение прогнозируемого периода.
Основные факторы роста рынка NLP: стали больше использоваться интеллектуальные устройства, а также облачные решения и приложения на основе NLP, которые улучшают обслуживание клиентов, увеличились технологические инвестиции в отрасль здравоохранения.
Какие задачи сегодня может решать NLP?
Машинный перевод текстов с одного языка на другой

Это один из самых распространённых сценариев. Однако несмотря на значительный прогресс машинного перевода, современные решения до сих пор не всегда справляются с переводом устойчивых оборотов, игры слов, а также выбором подходящих падежей и правильным построением предложений.
Анализ текстов
Анализ текстов реализуется в трёх основных форматах: классификации, отражении содержания и анализе тональности.
Все задачи по классификации текстов (text classification) можно разделить на два типа:
- бинарная классификация позволяет определить релевантность предложенного пользователю документа;
- мультиклассовая классификация позволяет определить тематику документа и отнести его к одному из сотни тематических классов.
Отражение содержания текста (text summarization) работает так: на вход NLP-система принимает текст большого размера, а на выходе отдаёт текст меньшего размера, отражающий содержание большого.
ABBYY , Москва, можно удалённо , От 220 000 ₽
Например, от машины можно потребовать сгенерировать пересказ текста, заголовок или аннотацию. Чуть подробнее про генерацию текста можно почитать в материале «Генерируем заголовки фейковых новостей в стиле Ленты.ру» с подробным разбором способов, которыми можно обучить нейросети созданию осмысленных и забавных для человеческого восприятия заголовков.

Наконец, анализ тональности текста (sentiment analysis) позволяет находить в тексте мнения и выявлять их свойства. Какие именно свойства будут исследоваться, зависит от поставленной задачи. К примеру, целью анализа может быть сам автор — анализ тональности определяет типичный для него стиль, эмоциональную окраску текста и т. д.
Распознавание и синтез речи
Распознавание речи представляет собой процесс преобразования речевого сигнала в цифровую информацию, например в текст. Синтез речи работает в обратном направлении, формируя речевой сигнал по печатному тексту.
Синтез и распознавание речи применяются в самых разных областях, например, в работе голосовых ассистентов, IVR-систем и «умных домах».
Разработка диалоговых систем
Диалоговыми системами можно считать:
- умные помощники (Яндекс.Алиса, Siri, Alexa);
- чат-боты — текстовые системы, следующие сценариям диалога (бот «Связного», Facebook Messenger);
- QA-системы.
Все они опираются на NLP-инструменты: распознавание речи, выделение смысла, контекста, определение намерения, а затем выстраивание диалога, исходя из вышеперечисленного (в идеале — путём синтеза речи).
Выделение сущностей и фактов
Ещё одна популярная задача NLP — извлечение именованных сущностей (Named-entity recognition, NER) из текста. Представим, что у есть сплошной текст о покупке-продаже активов, и необходимо выделить персон, а также даты и активы.
На фоне роста аналитических прогнозов, миллиардер Иван Петров выкупил контрольный пакет акций компании « Рога и Копыта » в 1999 году.
Задача NER — понять, что участок текста «1999 года» является датой, «Иван Петров» — персоной, а «пакет акций» — активом.
Без NER тяжело представить решение многих задач NLP, допустим, разрешения местоименной анафоры или построения вопросно-ответных систем. Если задать в поисковике вопрос «Кто играл роль Бэтмена в фильме “Темный рыцарь”», то ответ находится как раз с помощью выделения именованных сущностей: выделяем сущности (фильм, роль и т. п.), понимаем, что спрашивается, и дальше ищем ответ в базе данных.
Постановка задачи NER очень гибкая. Можно выделять любые нужные непрерывные фрагменты текста, которые чем-то отличаются от остального текста. В результате можно подобрать свой набор сущностей для конкретной практической задачи, обработать тексты этим набором и обучить модель. Такой сценарий встречается повсеместно, и это делает NER одной из самых часто решаемых задач NLP в индустрии.
Вот как выглядит подобный проект для крупной нефтяной компании. Перед заказчиком стояла задача подготовить данные об активах: промышленных установках, эксплуатируемом оборудовании, а также средствах измерения и контроля. Источниками данных служили текстовые документы — технические регламенты, наиболее полно описывающие техпроцессы и необходимые объекты производства.
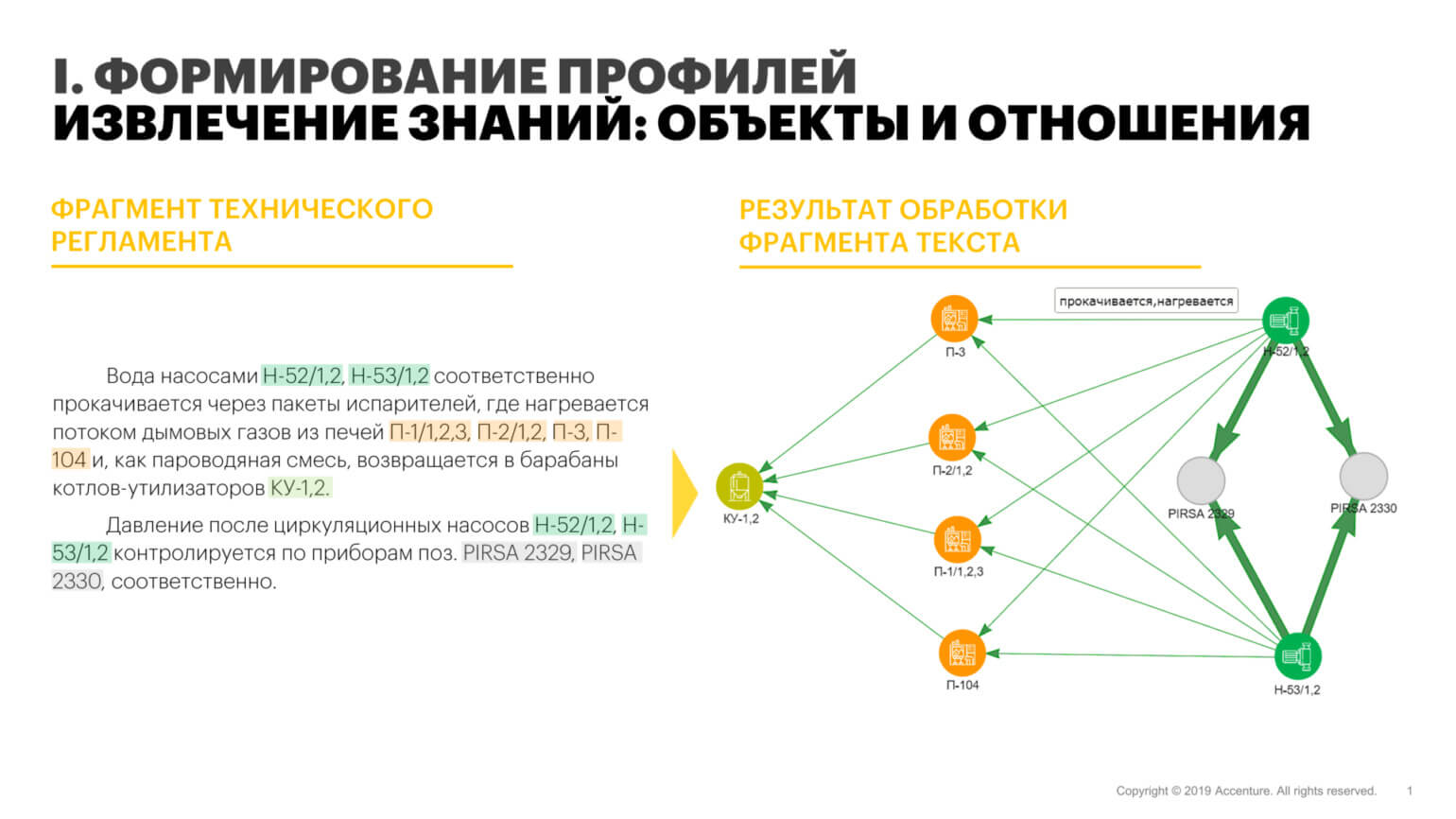
Мы продемонстрировали возможность применения технологий ML и NLP для извлечения информации из текстового описания (и формирования профилей оборудования на её основе). Сформированные профили были сопоставлены с результатами ручного маппинга, взятого за эталон — достигнутая точность составила 97,3%. Подход позволяет существенно снизить затраты труда и времени, а также свести к минимуму риски, связанные с ошибками ручной обработки текстов.
Как обрабатывается естественный язык?
Некоторые задачи NLP для естественного языка, в отличие от обработки изображений, до недавних пор решались с помощью классических алгоритмов машинного обучения.
Для решения большинства задач требовался тщательный выбор архитектуры, а также ручной сбор и обработка признаков. Однако в последнее время нейронные сети начали давать более точные результаты по сравнению с классическими моделями и сформировали общий подход для решения задач NLP.
Конвейер NLP
Реализация любой сложной задачи обычно означает построение пайплайна (конвейера).

Суть этого подхода в том, чтобы разбить задачу на ряд последовательных подзадач и решать каждую из них отдельно. В построении пайплайна можно условно выделить две части: предобработку входных данных (обычно занимает больше всего времени) и построение модели. Основных этапов — семь.
1. Первые два шага пайплайна, которые выполняются для решения практически любых задач NLP, — это сегментация (деление текста на предложения) и токенизация (деление предложений на токены, то есть отдельные слова).
2. Вычисление признаков каждого токена. Вычисляются контекстно-независимые признаки токена. Это набор признаков, не зависящих от соседних с токеном слов.
- Один из самых часто использующихся признаков — часть речи.

- Для языков со сложной морфологией (русский язык) также важны морфологические признаки: например, в каком падеже стоит существительное, какой род у прилагательного. Из этого можно сделать выводы о структуре предложения.
- Морфология также нужна для приведения слов к начальной форме, с помощью которой мы можем уменьшить объём признакового пространства.
Например: I had a pony. I had two ponies.
Оба предложения содержат существительное «pony», но с разными окончаниями. Если тексты обрабатывает компьютер, он должен знать начальную форму каждого слова, чтобы понимать, что речь идёт об одной и той же концепции пони. Иначе токены «pony» и «ponies» будут восприняты как совершенно разные. В NLP этот процесс называется лемматизацией.
3. Определение значимости и фильтрация стоп-слов. В русском и английском языках очень много вспомогательных слов, например «and», «the», «a». При статистическом анализе текста эти токены создают много шума, так как появляются чаще, чем остальные. Поэтому их отмечают как стоп-слова и отсеивают.

4. Разрешение кореференции. В русском и английском языках очень много местоимений вроде he, she, it или ты, я, он и т. д. Это сокращения, которыми мы заменяем на письме настоящие имена и названия. Человек может проследить взаимосвязь этих слов от предложения к предложению, основываясь на контексте. Но NLP-модель не знает, что означают местоимения, ведь она рассматривает всего одно предложение за раз.

5. Парсинг зависимостей. Конечная цель этого шага — построение дерева, в котором каждый токен имеет единственного родителя. Корнем может быть главный глагол. Также нужно установить тип связи между двумя словами:
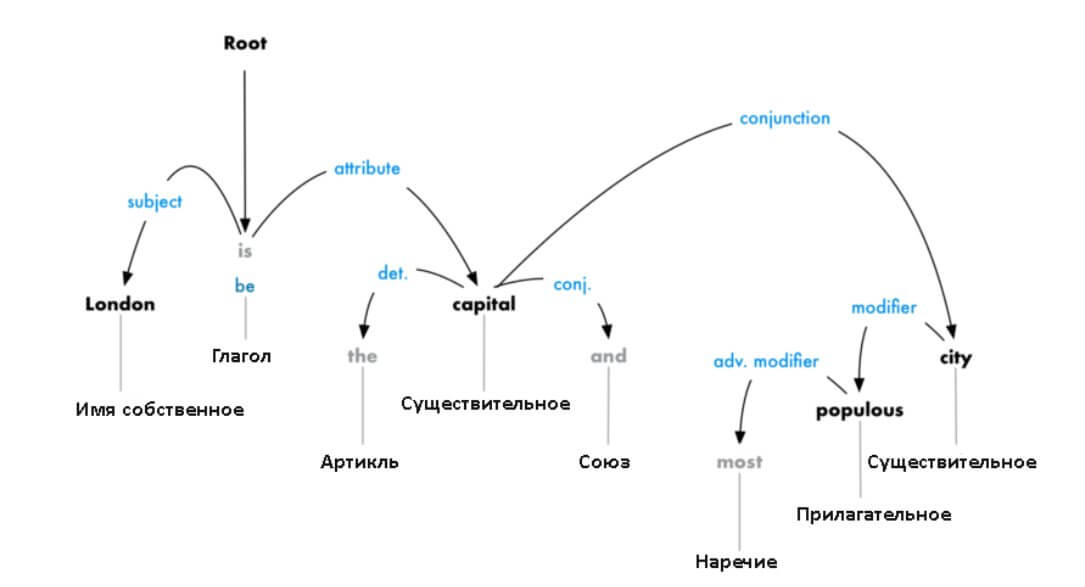
Это дерево парсинга демонстрирует, что главный субъект предложения — это существительное «London». Между ним и «capital» есть связь «be». Вот так мы узнали, что Лондон — это столица. Если бы мы проследовали дальше по веткам дерева (уже за границами схемы), то могли бы узнать, что «London is the capital of Great Britain».
6. Перевод обработанного текста в векторную форму. Данный шаг позволяет сформировать векторные представления слов. Таким образом, у слов, используемых в одном и том же контексте, похожие векторы.
7. Построение модели в зависимости от поставленной цели. Например, модель для классификации или генерации новых текстов.
Приведённый пример пайплайна не является единственно верным. Для решения конкретной задачи некоторые шаги можно исключить или добавить новые. Однако этот пайплайн содержит все наиболее типичные этапы и подходы, позволяющие извлекать практическую пользу из NLP.
Читайте также: