
Что такое yolo в компьютерном зрении
Обновлено: 02.07.2024
YOLO означает «Вы смотрите только один раз: унифицированное обнаружение объектов в реальном времени». Это алгоритм обнаружения целей, предложенный в CVPR2016. Основная идея заключается в преобразовании обнаружения целей в решение проблем регрессии, основанном на отдельной сквозной сети. Завершите ввод исходного изображения для вывода положения и категории объекта. YOLO и Faster RCNN имеют следующие различия:
- Ускоренный RCNN разбивает обнаружение цели на задачи классификации и регрессии соответственно: во-первых, независимая сеть RPN используется для конкретного получения предложения региона, то есть вычисляется P (objetness) на фиг.1, затем регрессия блока связанной области используется для извлечения предложения региона Выполните коррекцию положения, то есть рассчитайте смещения Box на рисунке 1 (проблема регрессии), и, наконец, используйте softmax для классификации (проблема классификации).
- YOLO решает проблему обнаружения объектов как проблему регрессии: входное изображение проходит через сеть один раз, и затем можно получить положение всех объектов на изображении, категорию, к которой они принадлежат, и соответствующую доверительную вероятность.

Рисунок 1 Разница между YOLO и Faster RCNN
Можно видеть, что YOLO объединяет всю проблему обнаружения в задачу регрессии, что делает структуру сети простой и скорость обнаружения значительно ускоряется, поскольку сеть не имеет ответвлений, обучение необходимо выполнить только один раз. Эта идея «преобразования обнаружения в регрессию» очень эффективна, и многие более поздние алгоритмы обнаружения (включая SSD) заимствовали эту идею.
1. Структура сети YOLO

Структура сети YOLO показана на рисунке 2 выше. По сравнению с Faster RCNN, YOLO имеет простую структуру, и сеть содержит только уровни conv, relu, pooling и полностью подключенные, и, наконец, уровень обнаружения, используемый для синтеза информации. Среди них свертка 1x1 используется для многоканального объединения информации (если вы не понимаете свертку 1x1, см. Предыдущую статью Faster RCNN).
2. Основная идея YOLO

Рабочий процесс YOLO делится на следующие процессы:
(1) Разделите исходное изображение на сетку SxS.Если центр цели попадает в определенную сетку, эта сетка отвечает за обнаружение цели.

(2) Каждая сетка должна предсказать ограничивающие рамки B и вероятности класса C Pr (classi | object).Здесь, чтобы объяснить, C - общее количество классификаций сети, определенных обучением. В демонстрационной версии, приведенной автором, C = 20, включая следующие категории:
В YOLO каждая сетка имеет только одну категорию C. Это эквивалентно игнорированию ограничивающих рамок B. Каждая сетка оценивает категорию только один раз. Это очень просто и грубо.
(3) В дополнение к возвращению в свою собственную позицию, каждый ограничивающий прямоугольник также должен предсказать значение достоверности.Эта достоверность представляет двойную уверенность в том, что предсказанный прямоугольник содержит достоверность цели, а ограничивающий прямоугольник предсказывает:

Если в сетке есть целевой центр падения Pr (Object) = 1, иначе Pr (Object) = 0. Второе слагаемое - это долговая расписка между предсказанной ограничивающей рамкой и фактической наземной истиной.
Поэтому каждый ограничивающий прямоугольник содержит 5 предикторов: (x, y, w, h, достоверность), где (x, y) представляет предсказанный прямоугольник относительно центра сетки, а (w, h) представляет прогнозируемый прямоугольник относительно Для соотношения ширины и высоты изображения достоверность является вышеуказанной достоверностью. Необходимо пояснить, что x, y, w и h здесь нормализованы, и объясним позже.
(4) Поскольку входное изображение делится на сетки SxS, каждая сетка включает в себя 5 предикторов: (x, y, w, h, достоверность) и класс C, поэтому выходной сигнал сети имеет размер SxSx (5xB + C)
(5) При обнаружении цели условная вероятность класса, прогнозируемая каждой сеткой, и информация о достоверности, прогнозируемая ограничивающей рамкой, умножаются для получения индивидуальной для класса оценки достоверности каждой ограничивающей рамки:

Очевидно, что эта доверительная оценка для конкретного класса включает в себя не только вероятность того, к какой категории в конечном итоге принадлежит ограничивающий прямоугольник, но также и точность определения местоположения ограничивающего прямоугольника. Наконец, установите порог для сравнения с классовой доверительной оценкой, отфильтруйте блоки, оценка которых ниже порогового значения, а затем выполните не максимальное подавление (NMS, не максимальное подавление) для блоков, оценка которых выше порога, чтобы получить окончательный кадр обнаружения. ,
3. Нормализация ограничивающего прямоугольника в YOLO
У YOLO есть важная деталь в реализации, то есть нормализация координат (x, y, w, h) ограничительной рамки для регрессии. Автор считает, что это очень важная деталь. В оригинальном разделе 2.2 Traing есть следующий параграф:
Далее проанализируем, как этого добиться.

Рисунок 5 Соотношение между сеткой SxS и ограничительной рамкой (S = 7, row = 4 и col = 1)
Как показано на рисунке 5, входное изображение в YOLO разделено на сетки SxS. Предположим, что существует ограничивающий прямоугольник (как показано в красном прямоугольнике на рисунке 4), центр которого попадает в сетку (строка, столбец), тогда эта сетка должна отвечать за прогнозирование цели собаки во всем красном прямоугольнике. Предположим, что ширина изображения равна widthimage, а высота - heightimage, центр красного прямоугольника - (xc, yc), ширина - widthbox, а высота - heightbox:
(1) Нормализуйте ширину и высоту ограничительной рамки следующим образом, чтобы ширина и высота вывода находились в диапазоне от 0 до 1:

(2) Используйте смещение сетки (row, col), чтобы нормализовать координаты центра ограничительной рамки:

Нормализация (x, y, w, h), полученная по вышеприведенной формуле, плюс вышеупомянутая достоверность вместе образуют ограничивающий прямоугольник, который действительно используется для регрессии в сети;
Когда сеть находится на этапе тестирования (x, y, w, h) после обратного декодирования, цель может быть получена в кадре системы координат изображения. Соответствующий код декодирования находится в функции get_detection_boxes () в детектировании_layer.c платформы darknet. Ключевые части следующие:
В то время как w и h - ширина и высота изображения, l.side - это S, упомянутый выше.
4. ЙОЛО учебный процесс
Для любого типа сети потеря очень важна и напрямую определяет качество эффекта сети. Функция потери функции YOLO в основном рассмотрела следующие три аспекта
(1) Ошибка предсказания координат (x, y, w, h) ограничительной рамки.При фактическом использовании алгоритмов обнаружения обычно существует такой опыт: при прогнозировании ограничивающих прямоугольников разных размеров, по сравнению с прогнозированием размера большого прямоугольника, измерение размера небольшого прямоугольника определенно невыносимо. Следовательно, необоснованно одинаково обрабатывать коробки разных размеров при потере. Чтобы решить эту проблему, автор использовал более изобретательный метод: сначала найти диапазон сжатых значений квадратного корня для w и h, а затем выполнить регрессию.

С последующим эффектом, это эффективно, но это не полностью решает проблему.
(2) Ошибка предсказания достоверности ограничительной рамки.Поскольку большинство сеток не содержат целей, что приводит к доверительному значению = 0 для большинства блоков, при проектировании ошибок достоверности нецелесообразно одинаково обрабатывать блоки с целями и без них, в противном случае модель будет нестабильной. Автор умножает вес штрафа на погрешность доверительного предсказания коробки без объекта =0.5。
Кроме того, неразумно обрабатывать ошибку прогнозирования координат в 4 значениях (x, y, w, h) и ошибку прогнозирования конференции в 1 значение в равной степени, поэтому автор умножает вес перед ошибкой прогнозирования координат.(Что касается того, почему это 5 вместо 4, я не знаю T_T).
(3) Ошибка прогнозирования классификации.То есть, к какой категории принадлежит каждый блок, следует отметить, что сетка предсказывает категорию только один раз, то есть все ограничивающие блоки B в каждой сетке по умолчанию относятся к одной и той же категории. Следовательно, окончательная ошибка YOLO выглядит следующим образом:
Loss = λcoord * Ошибка прогнозирования координат + (ошибка прогнозирования достоверности с объектом + λnoobj * Ошибка предсказания достоверности коробки без объекта) + Ошибка предсказания категории

Реализация сети в различных общих рамках обычно требует завершения прямого и обратного процессов. Функцию прямого необходимо кодировать только в соответствии с потерей, а функцию обратного хода просто необходимо рассчитать остаточную дельту. Вот краткое объяснение отрицательной обратной связи YOLO, то есть метода реализации в обратном направлении. В руководстве UFLDL метод прямого распространения по сети определяется как:

Последний слой остатков обратного распространения определяется как:

Для YOLO последний уровень - это layer_layer, а предпоследний уровень - connected_layer (полностью подключенный уровень). Между ними нет уровня ReLU, что эквивалентно функции активации последнего уровня:

Затем остаток для обнаружения_ слоя становится:

5. Дальнейшее понимание YOLO
- В сети YOLO сначала извлекаются карты функций через набор CNN
- Затем генерируется последний полностью связанный слой FCSxSx(5*B+C)=7x7x(5*2+20)=1470Длинный вектор
- Затем положить1470Вектор изменить вSxSx(5*B+C)=7x7x30Многомерная матрица
- Получите ограничивающую рамку Обнаружения + Уверенность, анализируя многомерную матрицу
- Наконец, выполните Не максимальное подавление в ограничительной рамке Обнаружение + Доверие, чтобы получить выходные данные.
После настройки сети и ее инициализации мы можем получить матрицу SxSx (5 * B + C), которая нам нужна, вперед, но значение не то, что мы хотим. После вышеупомянутого обучения отрицательной обратной связи в рамках YOLO Loss, очевидно, мы можем получить нашу матрицу SxSx (5 * B + C), а затем мы можем получить окно вывода после анализа + NMS.
По существу, более быстрый RCNN получает кадр обнаружения путем различения и исправления якорей, а YOLO получает кадр обнаружения путем принудительной регрессии.

Рисунок 8 Вывод YOLO
6. Анализ результатов
В статье автор приводит сравнение результатов обнаружения YOLO и Fast RCNN, как показано ниже. Уровень неправильной оценки фона YOLO (4,75%) намного ниже, чем у Fast RCNN (13,6%). Тем не менее, точность позиционирования YOLO является низкой, составляя 19,0% от общей ошибки, в то время как быстрый рсн составляет всего 8,6%. Это показывает, что идея преобразования обнаружения в регрессию в YOLO имеет лучшую точность, но метод позиционирования ограничительной рамки нуждается в дальнейшем улучшении.

Если ты смотрел «Терминатор», то помнишь кадры из глаз T-800: он смотрел по сторонам и определял разные объекты. Тогда о такой машине можно было только мечтать, а сегодня ее можно смастерить самому из готовых частей.

Кадр из фильма «Терминатор»
Распознавание объектов сегодня пригождается для решения самых разных задач: классификации видов растений и животных, распознавания лиц, определения габаритов объектов — и это далеко не полный список.
Какие бывают алгоритмы
Существует несколько алгоритмов обнаружения объектов на изображениях и видео. Посмотрим, что они собой представляют.
R-CNN, Region-Based Convolutional Neural Network
Сперва на изображении с помощью алгоритма выборочного поиска выделяются регионы, которые предположительно содержат объект. Далее сверточная нейронная сеть (CNN) пытается выявить признаки объектов для каждого из этих регионов, после чего машина опорных векторов классифицирует полученные данные и сообщает класс обнаруженного объекта.
Обработка в режиме реального времени: не поддерживается.
Fast R-CNN, Fast Region-Based Convolutional Neural Network
Подход аналогичен алгоритму R-CNN. Но вместо того, чтобы предварительно выделять регионы, мы передаем входное изображение в CNN для создания сверточной карты признаков, где затем будет происходить выборочный поиск, а предсказание класса объектов выполняет специальный слой Softmax.
Обработка в режиме реального времени: не поддерживается.
Faster R-CNN, Faster Region-Based Convolutional Neural Network
Подобно Fast R-CNN, изображение передается в CNN создания сверточной карты признаков, но вместо алгоритма выборочного поиска для прогнозирования предложений по регионам используется отдельная сеть.
Обработка в режиме реального времени: поддерживается при высоких вычислительных мощностях.
YOLO, You Only Look Once
Изображение делится на квадратную сетку. Для каждой ячейки сети CNN выводит вероятности определяемого класса. Ячейки, имеющие вероятность класса выше порогового значения, выбираются и используются для определения местоположения объекта на изображении.
Обработка в режиме реального времени: поддерживается!
Как видишь, YOLO пока что лучший вариант для обнаружения и распознавания образов. Он отличается высокой скоростью и точностью обнаружения объектов, а еще этот алгоритм можно использовать в проектах на Android и Raspberry Pi с помощью нетребовательного tiny-варианта сети, с которым мы с тобой сегодня будем работать.
Tiny-вариант несколько проигрывает в точности полноценному варианту сети, но и требует меньшей вычислительной мощности, что позволит запустить проект, который мы сегодня будем делать, как на слабом компьютере, так и, при желании, на смартфоне.
Пишем код
Чтобы написать легковесное приложение для обнаружения объектов на изображении, нам с тобой понадобятся:
Дополнительно установим библиотеки OpenCV и NumPy:
Теперь напишем приложение, которое будет находить объекты на изображении при помощи YOLO и отмечать их.
Мы попробуем обойти CAPTCHA с изображениями грузовиков — класс truck в датасете COCO. Дополнительно мы посчитаем количество обнаруженных объектов нужного нам класса и выведем всю информацию на экран.
Начнем с написания функции для применения YOLO. С ее помощью определяются самые вероятные классы объектов на изображении, а также координаты их границ, которые позже мы будем использовать для отрисовки.

В данной статье мы напишем небольшую программу для решения задачи детектирования и распознавания объектов (object detection) в режиме реального времени. Программа будет написана на языке программирования Swift под платформу iOS. Для детектирования объектов будем использовать свёрточную нейронную сеть с архитектурой под названием YOLOv3. В статье мы научимся работать в iOS с нейронными сетями с помощью фреймворка CoreML, немного разберемся, что из себя представляет сеть YOLOv3 и как использовать и обрабатывать выходы данной сети. Так же проверим работу программы и сравним несколько вариаций YOLOv3: YOLOv3-tiny и YOLOv3-416.
Исходники будут доступны в конце статьи, поэтому все желающие смогут протестировать работу нейронной сети у себя на устройстве.
Object detection
Для начала, вкратце разберемся, что из себя представляет задача детектирования объектов (object detection) на изображении и какие инструменты применяются для этого на сегодняшний день. Я понимаю, что многие довольно хорошо знакомы с этой темой, но я, все равно, позволю себе немного об этом рассказать.
Сейчас очень много задач в области компьютерного зрения решаются с помощью свёрточных нейронных сетей (Convolutional Neural Networks), в дальнейшем CNN. Благодаря своему строению они хорошо извлекают признаки из изображения. CNN используются в задачах классификации, распознавания, сегментации и еще во множестве других.
Популярные архитектуры CNN для распознавания объектов:
- R-CNN. Можно сказать первая модель для решения данной задачи. Работает как обычный классификатор изображений. На вход сети подаются разные регионы изображения и для них делается предсказания. Очень медленная так как прогоняет одно изображение несколько тысяч раз.
- Fast R-CNN. Улучшенная и более быстрая версия R-CNN, работает по похожему принципу, но сначала все изображение подается на вход CNN, потом из полученного внутреннего представления генерируются регионы. Но по прежнему довольно медленная для задач реального времени.
- Faster R-CNN. Главное отличие от предыдущих в том, что вместо selective search алгоритма для выбора регионов использует нейронную сеть для их «заучивания».
- YOLO. Совсем другой принцип работы по сравнению с предыдущими, не использует регионы вообще. Наиболее быстрая. Более подробно о ней пойдет речь в статье.
- SSD. По принципу похожа на YOLO, но в качестве сети для извлечения признаков использует VGG16. Тоже довольная быстрая и пригодная для работы в реальном времени.
- Feature Pyramid Networks (FPN). Еще одна разновидность сети типа Single Shot Detector, из за особенности извлечения признаков лучше чем SSD распознает мелкие объекты.
- RetinaNet. Использует комбинацию FPN+ResNet и благодаря специальной функции ошибки (focal loss) дает более высокую точность (аccuracy).
Почему YOLO?

YOLO или You Only Look Once — это очень популярная на текущий момент архитектура CNN, которая используется для распознавания множественных объектов на изображении. Более полную информацию о ней можно получить на официальном сайте, там же можно найти публикации в которых подробно описана теория и математическая составляющая этой сети, а так же расписан процесс её обучения.
Главная особенность этой архитектуры по сравнению с другими состоит в том, что большинство систем применяют CNN несколько раз к разным регионам изображения, в YOLO CNN применяется один раз ко всему изображению сразу. Сеть делит изображение на своеобразную сетку и предсказывает bounding boxes и вероятности того, что там есть искомый объект для каждого участка.
Плюсы данного подхода состоит в том, что сеть смотрит на все изображение сразу и учитывает контекст при детектировании и распознавании объекта. Так же YOLO в 1000 раз быстрее чем R-CNN и около 100x быстрее чем Fast R-CNN. В данной статье мы будем запускать сеть на мобильном устройстве для онлайн обработки, поэтому это для нас это самое главное качество.
Более подробную информацию по сравнению архитектур можно посмотреть тут.
YOLOv3
YOLOv3 — это усовершенствованная версия архитектуры YOLO. Она состоит из 106-ти свёрточных слоев и лучше детектирует небольшие объекты по сравнению с её предшествиницей YOLOv2. Основная особенность YOLOv3 состоит в том, что на выходе есть три слоя каждый из которых расчитан на обнаружения объектов разного размера.
На картинке ниже приведено её схематическое устройство:

YOLOv3-tiny — обрезанная версия архитектуры YOLOv3, состоит из меньшего количества слоев (выходных слоя всего 2). Она более хуже предсказывает мелкие объекты и предназначена для небольших датасетов. Но, из-за урезанного строения, веса сети занимают небольшой объем памяти (
35 Мб) и она выдает более высокий FPS. Поэтому такая архитектура предпочтительней для использования на мобильном устройстве.
Пишем программу для распознавания объектов
Начинается самая интересная часть!
Давайте создадим приложение, которое будет распознавать различные объекты на изображении в реальном времени используя камеру телефона. Весь код будем писать языке программирования Swift 4.2 и запускать на iOS устройстве.
В данном туториале мы возьмём уже готовую сеть с весами предобученными на COCO датасете. В нем представлено 80 различных классов. Следовательно наша нейронка будет способна распознать 80 различных объектов.
Из Darknet в CoreML
Оригинальная архитектура YOLOv3 реализована с помощью фремворка Darknet.
На iOS, начиная с версии 11.0, есть замечательная библиотека CoreML, которая позволяет запускать модели машинного обучения прямо на устройстве. Но есть одно ограничение: программу можно будет запустить только на устройстве под управлением iOS 11 и выше.
Проблема в том, что CoreML понимает только определённый формат модели .coreml. Для большинства популярных библиотек, таких как Tensorflow, Keras или XGBoost, есть возможность напрямую конвертировать в формат CoreML. Но для Darknet такой возможности нет. Для того, что бы преобразовать сохраненную и обученную модель из Darknet в CoreML можно использовать различные варианты, например сохранить Darknet в ONNX, а потом уже из ONNX преобразовать в CoreML.
Мы воспользуемся более простым способом и будем использовать Keras имплементацию YOLOv3. Алгоритм действия такой: загрузим веса Darknet в Keras модель, сохраним её в формате Keras и уже из этого напрямую преобразуем в CoreML.
- Скачиваем Darknet. Загрузим файлы обученной модели Darknet-YOLOv3 отсюда. В данной статье я буду использовать две архитектуры: YOLOv3-416 и YOLOv3-tiny. Нам понадобится оба файла cfg и weights.
- Из Darknet в Keras. Сначала склонируем репозиторий, переходим в папку репо и запускаем команду:
Создание iOS приложения
Полностью весь код приложения я описывать не буду, его можно посмотреть в репозитории ссылка на который будет приведена в конце статьи. Скажу лишь что у нас есть три UIViewController-a: OnlineViewController, PhotoViewController и SettingsViewController. В первом идет вывод камеры и онлайн детектирование объектов для каждого кадра. Во втором можно сделать фото или выбрать снимок из галереи и протестировать сеть на этих изображениях. В третьем находятся настройки, можно выбрать модель YOLOv3-416 или YOLOv3-tiny, а так же подобрать пороги IoU (intersection over union) и object confidence (вероятность того, что на текущем участке изображения есть объект).
Загрузка модели в CoreML
После того как мы преобразовали обученную модель из Darknet формата в CoreML, у нас есть файл с расширением .mlmodel. В моем случае я создал два файла: yolo.mlmodel и yolo-tiny.mlmodel, для моделей YOLOv3-416 и YOLOv3-tiny соответсвенно. Теперь можно подгружать эти файлы в проект в Xcode.
Создаем класс ModelProvider в нем будет хранится текущая модель и методы для асинхронного вызова нейронной сети на исполнение. Загрузка модели осуществляется таким образом:
Класс YOLO отвечает непосредственно за загрузку .mlmodel файлов и обработку выходов модели. Загрузка файлов модели:
Обработка выходов нейронной сети
Теперь разберемся как обрабатывать выходы нейронной сети и получаться соответсвующие bounding box-ы. В Xcode если выбрать файл модели то можно увидеть, что они из себя представляет и увидеть выходные слои.


Как можно видеть на изображении выше у нас есть три для YOLOv3-416 и два для YOLOv3-tiny выходных слоя в каждом из которых предсказываются bounding box-ы для различных объектов.
В данном случае это обычный массив чисел, давайте же разберемся как его парсить.
Модель YOLOv3 в качестве выхода использует три слоя для разбиения изображения на различную сетку, размеры ячеек этих сеток имеют такие значения: 8, 16 и 32. Допустим на входе у нас есть изображение размером 416x416 пикселей, тогда выходные матрицы (сетки) будут иметь размер 52x52, 26x26 и 13x13 (416/8 = 52, 416/16 = 26 и 416/32 = 13). В случае с YOLOv3-tiny все тоже самое только вместо трех сеток имеем две: 16 и 32, то есть матрицы размерностью 26x26 и 13x13.
После запуска загруженно CoreML модели на выходе мы получим два (или три) объекта класса MLMultiArray. И если посмотреть свойство shape у этих объектов, то увидим такую картину (для YOLOv3-tiny):
Как и ожидалось размерность матриц будет 26x26 и 13x13.Но что обозначат число 255? Как уже говорилось ранее, выходные слои это матрицы размерностью 52x52, 26x26 и 13x13. Дело в том, что каждый элемент данной матрицы это не число, это вектор. То есть выходной слой это трех-мерная матрица. Этот вектор имеет размерность B x (5 + C), где B — количество bounding box в ячейке, C — количество классов. Откуда число 5? Причина такая: для каждого box-a предсказывается вероятность что там есть объект (object confidence) — это одно число, а оставшиеся четыре — это x, y, width и height для предсказанного box-a. На рисунке ниже показано схематичное представление этого вектора:

Cхематичное представление выходного слоя (feature map).
Для нашей сети обученной на 80-ти классах, для каждой ячейки сетки разбиения предсказывается 3 bounding box-a, для каждого из них — 80 вероятностей классов + object confidence + 4 числа отвечающие за положение и размер этого box-a. Итого: 3 x (5 + 80) = 255.
Для получения этих значений из класса MLMultiArray лучше воспользоваться сырым указателем на массив данных и адресной арифметикой:
Теперь необходимо обработать вектор из 255 элементов. Для каждого box-a нужно получить распределение вероятностей для 80 классов, сделать это можно сделать с помощью функции softmax.
где K — размерность вектора.
Функция softmax на Swift:
Для получения координат и размеров bounding box-a нужно воспользоваться формулами:
где — предсказанные x, y координаты, ширина и высота соответственно, — функция сигмоиды, а — значения якорей(anchors) для трех box-ов. Эти значения определяются во время тренировки и заданы в файле Helpers.swift:

Схематическое изображение расчета положения bounding box-а.
Non max suppression
После того как получили координаты и размеры bounding box-ов и соответсвующие вероятности для всех найденных объектов на изображении можно начинать отрисовывать их поверх картинки. Но есть одна проблема! Может Возникнуть такая ситуация когда для одного объекта предсказано несколько box-ов c достаточно высокими вероятностями. Как быть в таком случае? Тут нам на помощь приходит довольно простой алгоритм под названием Non maximum suppression.
Порядок действия алгоритма такой:
- Ищем bounding box с наибольшей вероятностью принадлежности к объекту.
- Пробегаем по всем bounding box-ам которые тоже относятся к этому объекту.
- Удаляем их если Intersection over Union (IoU) с первым bounding box-ом больше заданного порога.
После этого работу непосредственно с результатами предсказания нейронной сети можно считать законченной. Далее необходимо написать функции и классы для получение видеоряда с камеры, вывода изображения на экран и отрисовки предсказанных bounding box-ов. Весь этот код в данной статье описывать не буду, но его можно будет посмотреть в репозитории.
Еще стоит упомянуть, что я добавил небольшое сглаживание bounding box-ов при обработки онлайн изображения, в данном случае это обычное усреднение положения и размера предсказанного квадрата за последние 30 кадров.
Тестирование работы программы
Теперь протестируем работу приложения.
Еще раз напомню: В приложении есть три ViewController-а, один для обработки фотографий или снимков, второй для обработки онлайн видео потока, третий для настройки работы сети.
Начнем с третьего. В нем можно выбрать одну из двух моделей YOLOv3-tiny или YOLOv3-416, подобрать confidence threshold и IoU threshold, так же можно включить или выключить онлайн сглаживание.

Теперь посмотрим как работает обученная нейронка с реальными изображениями, для этого возьмем фотографию из галереи и пропустим её через сеть. Ниже на картинке представлены результаты работы YOLOv3-tiny с разными настройками.

Разные режимы работы YOLOv3-tiny. На левой картинке обычный режим работы. На средней — порог IoU = 1 т.е. как будто отсутствует Non-max suppression. На правой — низкий порог object confidence, т.е. отображаются все возможные bounding box-ы.
Далее приведен результат работы YOLOv3-416. Можно заметить, что по сравнению с YOLOv3-tiny полученные рамки более правильные, а так же распознаны более мелкие объекты на изображении, что соответствует работе третьего выходного слоя.

Изображение обработанное с помощью YOLOv3-416.
При включении онлайн режима работы обрабатывался каждый кадр и для него делалось предсказание, тесты проводились на iPhone XS поэтому результат получился довольно приемлемый для обоих вариантов сети. YOLOv3-tiny в среднем выдает 30 — 32 fps, YOLOv3-416 — от 23 до 25 fps. Устройство на котором проходило тестирование довольно производительное, поэтому на более ранних моделях результаты могут отличатся, в таком случае конечно предпочтительнее использовать YOLOv3-tiny. Еще один важный момент: yolo-tiny.mlmodel (YOLOv3-tiny) занимает около 35 Мб, в свою очередь yolo.mlmodel (YOLOv3-416) весит около 250 Мб, что очень существенная разница.
Заключение
В итоге было написано iOS приложение которое с помощью нейронной сети может распознавать объекты на изображении. Мы увидели как работать с библиотекой CoreML и как с её помощью исполнять различные, заранее обученные, модели (кстати обучать с её помощью тоже можно). Задача распознавания объекта решалась с помощью YOLOv3 сети. На iPhone XS данная сеть (YOLOv3-tiny) способна обрабатывать изображения с частотой
30 кадров в секунду, что вполне достаточно для работы в реальном времени.

Что такое YOLO? Эта аббревиатура расшифровывается как “You Only Look Once” (“Стоит только раз взглянуть”). YOLO — современный алгоритм глубокого обучения, который широко используется для обнаружения объектов. Он был разработан Джозефом Редмоном и Али Фархади в 2016 году.
Чем YOLO отличается от других алгоритмов глубокого обучения для обнаружения объектов?
Основное отличие YOLO от других алгоритмов сверточной нейронной сети (CNN), используемых для обнаружения объектов, заключается в том, что он очень быстро опознает объекты в режиме реального времени. Принцип работы YOLO подразумевает ввод сразу всего изображения, которое проходит через сверточную нейронную сеть только один раз. Именно поэтому он называется “Стоит только раз взглянуть”. В других алгоритмах этот процесс происходит многократно, то есть изображение проходит через CNN снова и снова. Так что YOLO обладает преимуществом высокоскоростного обнаружения объектов, чем не могут похвастать другие алгоритмы.
Представьте себе автомобиль, оснащенный функцией самостоятельного вождения, который использует обычный алгоритм обнаружения объектов сети CNN. Если алгоритм заметит впереди препятствие, машина затормозит сама. Но в данном случае все будет происходить медленно, и алгоритм увидит объект-препятствие довольно поздно. Это может привести к аварии. Теперь представьте себе ту же ситуацию с YOLO. На этот раз автомобиль оснащен алгоритмом YOLO и остановится как раз вовремя, так как очень быстро обнаружит препятствие в режиме реального времени.
Как работает YOLO?
Алгоритм YOLO был обучен на определенном типе набора данных, который состоит из 80 различных типов классов (см. ниже):
Алгоритм YOLO способен обнаруживать все эти 80 видов объектов на изображении. Он также может быть специально обучен, чтобы легко находить новые объекты. Набор данных, который использовался для обучения обнаружения 80 классов объектов, известен под названием “Coco”.
Мы расскажем о работе алгоритма YOLO очень кратко и просто, так как эта статья предназначена для новичков!
Сначала изображение, которое вводится в сеть, разделяется на секции. Возьмем для примера матрицу-сетку 3×3.
Итак, этому изображению был дан формат матрицы размером 3×3. На данном фото в общей сложности 9 секций. Каждая из них имеет определенные параметры. Если мы допустим, что общее количество классов, которые мы ищем на рисунке, равно 3 (предположительно это будут человек, автомобиль и самолет), то каждая секция будет иметь в общей сложности 8 параметров. Но почему именно 8? Потому что каждая секция содержит 5 параметров и три параметра класса. Эти 5 параметров перечислены ниже:
Чтобы комментировать эти параметры, нам нужно знать, что такое ограничивающие рамки. При подготовке обучающих данных мы должны выделить объект, который хотим обнаружить на изображении. Делаем мы это с помощью ограничивающих рамок. Как правило, они представляют собой квадраты или прямоугольники, которые выделяют определенную часть изображения (как на примере ниже):
В данном случае нам нужно обнаружить автомобили, поэтому мы помещаем ограничивающие рамки вокруг всех автомобилей, присутствующих на нем. Теперь нам необходимо узнать значения 5 параметров в каждой секции в матрице 3×3. Ниже представлена фотография отдельной секции, в которой есть автомобиль.
Красная точка в середине обозначает центр ограничивающей рамки. Горизонтальная синяя стрелка — это параметр “tx” (расстояние между красной точкой и самой левой частью этой секции). Вертикальная синяя стрелка — это “ty” (расстояние между красной точкой и самой верхней частью секции). Горизонтальная белая стрелка — это ширина ограничительной рамки по отношению к секции (параметр “tw”). Вертикальная белая стрелка обозначает высоту ограничивающей рамки по отношению к секции и указывается как “th”.
Параметр “po”, также известный как индекс объектности, выражает вероятность успешного обнаружения объекта в ограничивающей рамке. И да, вы угадали, значение 0,99 на первой картинке этой статьи— индекс объектности, указывающий на наличие лица в ограничивающей рамке, которая его окружает. Индексы “p1”, “p2” и “p3” говорят нам о вероятности того, что этот объект окажется человеком, автомобилем или самолетом соответственно. Все 9 секций, присутствующих в матрице 3×3, имеют эти 8 параметров, и именно они помогают алгоритму YOLO точно обнаружить объект.
Заключение
Работа алгоритма YOLO по корректному обнаружению объектов не обходится без некоторых сложностей. Здесь мы просто хотели дать вам краткое представление о его функционировании простым языком.

До Yolo большинство подходов к распознаванию объектов заключалось в попытках адаптировать классификаторы к распознаванию. В YOLO, распознавание объектов было реализовано как задача регрессии к раздельным ограничивающим рамкам, с которыми связаны вероятности принадлежности к разным классам. Ниже мы познакомимся с моделью распознавания объектов YOLO и методом ее реализации в Tensorflow 2.0.
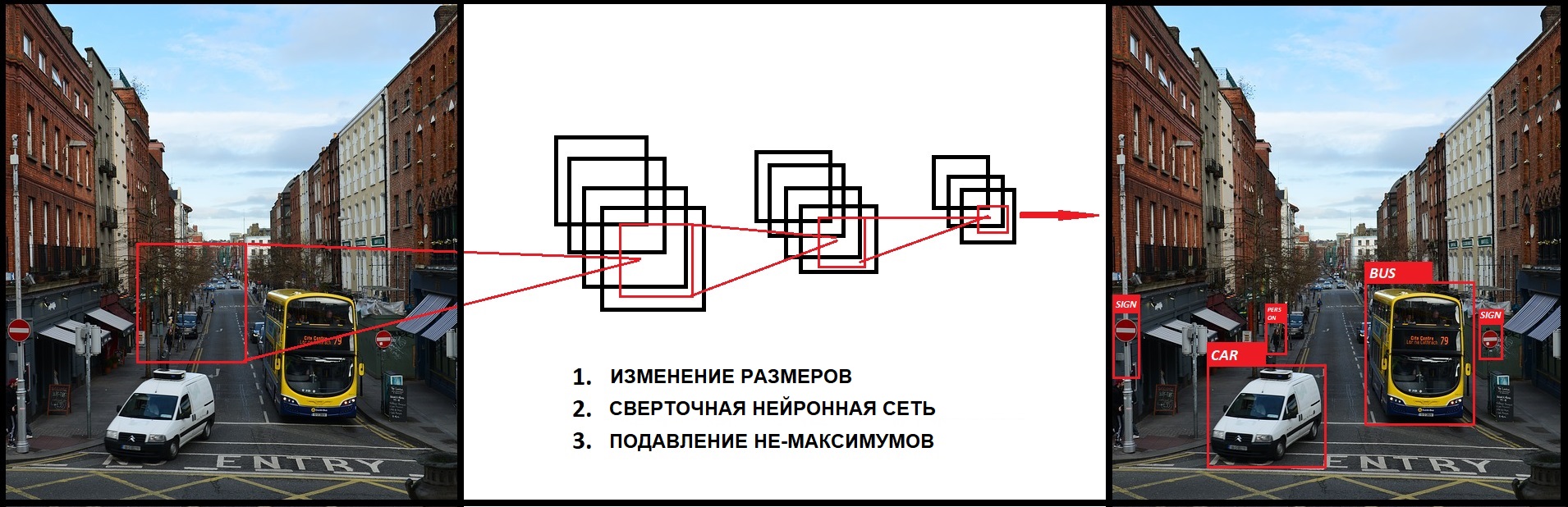
Что такое YOLO?
YOLO – это передовая сеть для распознавания объектов (object detection), разработанная Джозефом Редмоном (Joseph Redmon). Главное, что отличает ее от других популярных архитектур – это скорость. Модели семейства YOLO действительно быстрые, намного быстрее R-CNN и других. Это значит, что мы можем распознавать объекты в реальном времени.
Во время первой публикации (в 2016 году) YOLO имела передовую mAP (mean Average Precision), по сравнению с такими системами, как R-CNN и DPM. С другой стороны, YOLO с трудом локализует объекты точно. Тем не менее, она обучается общему представлению объектов. В новой версии как скорость, так и точность системы были улучшены.
Другие подходы в основном использовали метод плавающего над изображением окна, и классификатора для этих регионов (DPM – deformable part models). Кроме этого, R-CNN использовал метод предложения регионов (region proposal). Этот метод сначала генерировал потенциальные содержащие рамки, после чего для них вызывался классификатор, а потом производилась пост-обработка для удаления двойных распознаваний и усовершенствования содержащих рамок.YOLO преобразовала задачу распознавания объектов к единой задаче регрессии. Она проходит прямо от пикселей изображения до координат содержащих рамок и вероятностей классов. Таким образом, единая CNN предсказывает множество содержащих рамок и вероятности классов для этих рамок.
Теория
Поскольку YOLO смотрит на изображение только один раз, плавающее окно – это неправильный подход. Вместо этого, все изображение разбивается с помощью сетки на ячейки размером 𝑆 ∗ 𝑆 . После этого каждая ячейка отвечает за предсказание нескольких вещей
Во-первых, каждая ячейка отвечает за предсказание нескольких содержащих рамок и показателя уверенности (confidence) для каждой из них – другими словами, это вероятность того, что данная рамка содержит объект. Если в какой-то ячейке сетки объектов нет, то очень важно, чтобы confidence для этой ячейки был очень малым.
Когда мы визуализируем все эти предсказания, мы получаем карту всех объектов и набор содержащих рамок, ранжированных по их confidence.
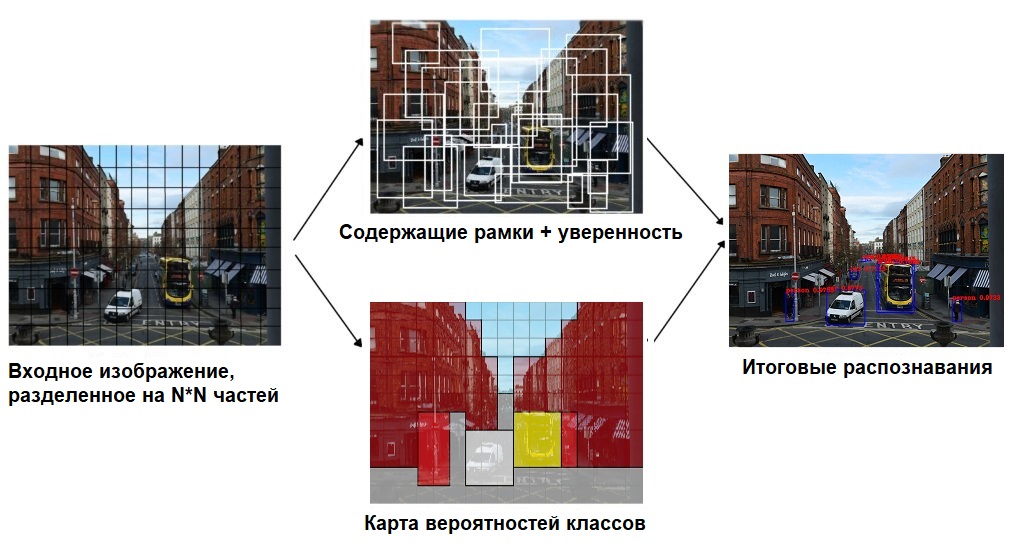
Во-вторых, каждая ячейка отвечает за предсказание вероятностей классов. Это не значит, что какая-то ячейка содержит какой-то объект, это всего лишь вероятность. Таким образом, если ячейка сети предсказывает автомобиль, это не значит, что он там есть, но это значит, что если там есть какой-то объект, то это автомобиль.
Давайте опишем детально, как может выглядеть выдаваемый моделью результат.
В YOLO для предсказания содержащих рамок используются якорные рамки (anchor boxes). Их основная идея заключается в предопределении двух разных рамок, называемых якорными рамками или формой якорных рамок. Это позволяет нам ассоциировать два предсказания с этими якорными рамками. В общем, мы можем использовать и большее количество якорных рамок (пять или даже больше). Якоря были рассчитаны на датасете COCO с помощью k-means кластеризации.

У нас есть сетка, каждая ячейка которой должна предсказать:
- для каждой содержащей рамки: 4 координаты ( 𝑡 𝑥 , 𝑡 𝑦 , 𝑡 𝑤 , 𝑡 ℎ ) и одну "ошибку объектности" – то есть, метрику confidence, определяющую, есть объект или нет.
- некоторое количество вероятностей классов.
Если есть некоторое смещение относительно верхнего левого угла 𝑐 𝑥 , 𝑐 𝑦 , то эти предсказания соответствуют следующим формулам:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t hгде 𝑝 𝑤 и 𝑝 ℎ соответствуют ширине и высоте содержащей рамки. Вместо предсказания смещений, как было во второй версии YOLO, авторы предсказывают координаты локации относительно расположения ячейки сети.
Этот вывод – это вывод нашей нейронной сети. Всего там 𝑆 ∗ 𝑆 ∗ [ 𝐵 ∗ ( 4 + 1 + 𝐶 ) ] выводов, где 𝐵 – количество содержащих рамок, предсказываемых каждой ячейкой (зависит от того, в скольких масштабах мы хотим делать наши предсказания), 𝐶 – количество классов, 4 – количество содержащих рамок, а 1 – предсказание объектности. За один проход мы можем пройти от исходного изображения до выходного тензора, соответствующего распознанным объектам изображения. Стоит также упомянуть, что YOLO v3 предсказывает рамки в трех разных масштабах.
Теперь, если мы возьмем вероятности и умножим их на значения confidence, мы получим все содержащие рамки, взвешенные по их вероятности содержания этого объекта.
Простое сравнение с порогом позволит нам избавиться от предсказаний с низкой confidence. Для следующего шага важно определить, что такое пересечение относительно объединения (intersection over union). Это отношение площади пересечения прямоугольников к площади их объединения:

После этого у нас еще могут быть дубликаты, и чтобы от них избавиться, мы применяем подавление не-максимумов. Подавление не-максимумов берет содержащую рамку с максимальной вероятностью и смотрит на другие содержащие рамки, расположенные близко к первой. Ближайшие рамки с максимальным пересечением относительно объединения с первой рамкой будут подавлены.
Поскольку все делается за один проход, модель работает почти с такой же скоростью, как классификация. Кроме того, все предсказания производятся одновременно, а это значит, что модель неявно встраивает в себя глобальный контекст. Проще говоря, модель может усвоить, какие объекты обычно встречаются вместе, относительные размеры и расположение объектов и так далее.
Мы настоятельно рекомендуем изучить все три документа YOLO:
Реализация YOLO в Tensorflow
Мы создадим полную сверточную нейронную сеть (Fully Convolutional Network, FCN) без тренировки. Чтобы что-то предсказать с помощью этой сети, нужно загрузить веса от заранее тренированной модели. Эти веса получены после тренировки YOLOv3 на датасете COCO (Common Objects in Context), и их можно загрузить с официального сайта.
Создаем папку для хранения весов
Импортируем все необходимые библиотеки
Проверяем версию Tensorflow. Она должна быть не ниже 2.0:
Определим несколько важных переменных, которые будем использовать ниже.
Список слоев в YOLOv3 FCN — Fully Convolutional Network
Очень трудно загрузить веса с помощью чисто функционального API, поскольку порядок слоев в Darknet и tf.keras различаются. Здесь лучшее решение – создание подмоделей в keras. Для сохранения подмоделей рекомендуется использовать Checkpoint'ы Tensorflow, поскольку они официально поддерживаются Tensorflow.
Вот функция для загрузки весов из оригинальной тренированной модели YOLO в Darknet:
Функция для расчета пересечения относительно объединения
Функция для отрисовки содержащей рамки, имени класса и вероятности:
Мы используем пакетную нормализацию (batch normalization), чтобы нормализовать результаты для ускорения тренировки. К сожалению, tf.keras.layers.BatchNormalization работает не очень хорошо для transfer learning, поэтому здесь предлагается другое решение этой проблемы.
Для каждого масштаба мы определяем три якорные рамки для каждой ячейки. В этом примере маска такова:
- 0,1,2 – мы будем использовать три первые якорные рамки
- 3,4,5 – мы используем четвертую, пятую и шестую рамки
- 6,7,8 – мы используем седьмую, восьмую и девятую рамки
Реализация YOLO v3
Пришло время реализовать сеть YOLOv3. Вот как выглядит ее структура:
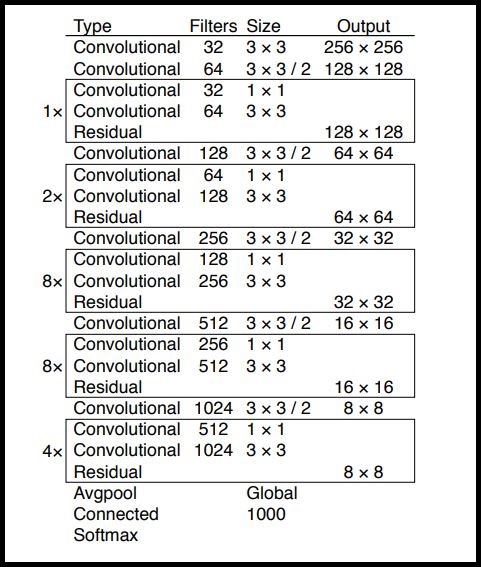
Darknet 53 – YOLO v3
Здесь основная идея – использовать только сверточные слои. Их там 53, так что проще всего создать функцию, в которую мы будем передавать важные параметры, изменяющиеся от слоя к слою.
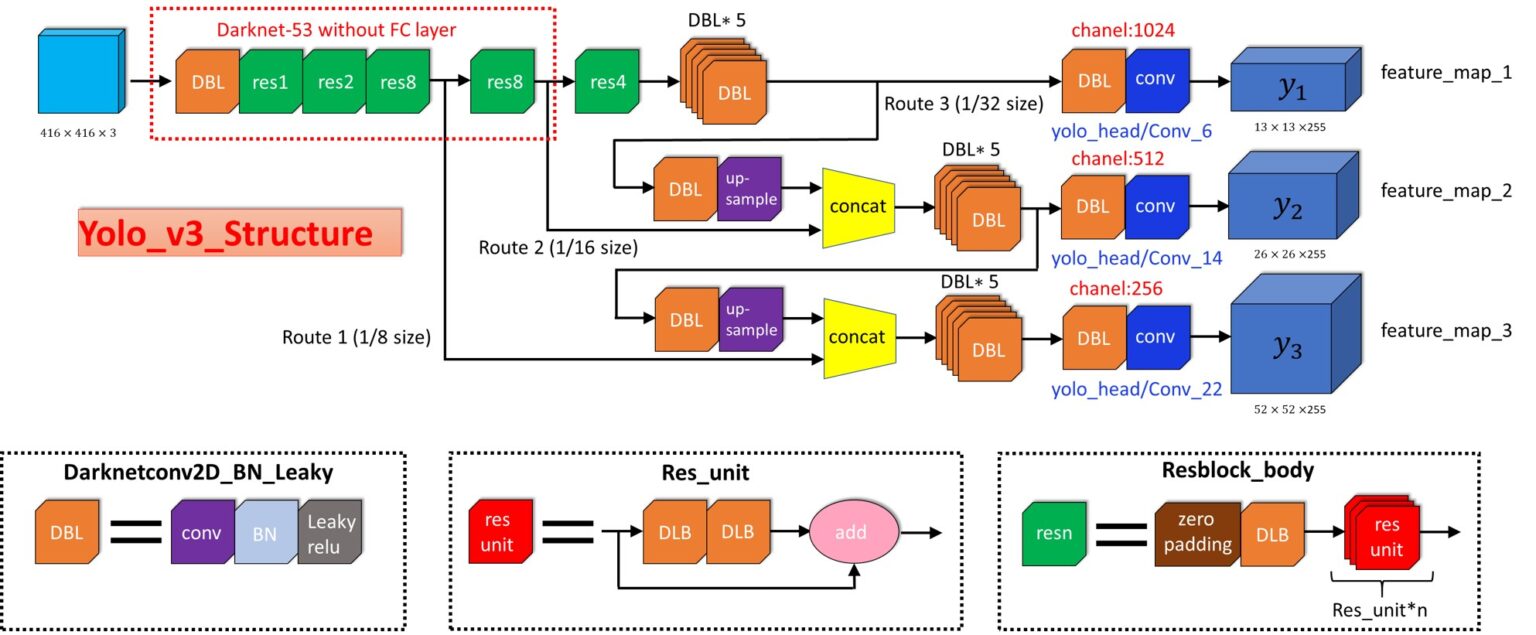
Остаточные блоки (Residual blocks) на диаграмме архитектуры YOLOv3 используются для обучения признакам. Остаточный блок состоит из нескольких сверточных слоев и обходных путей:
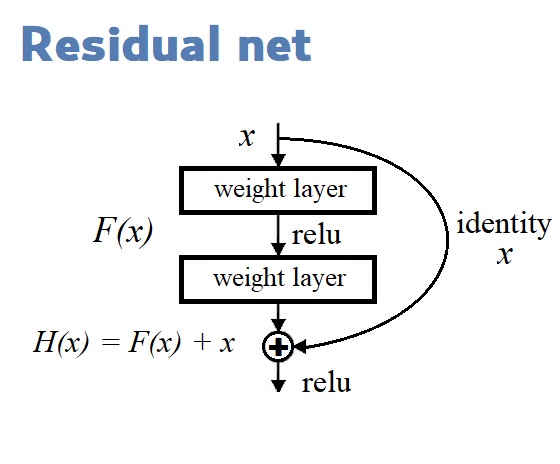
Мы строим нашу модель с помощью Функционального API, простого в использовании. С ним мы можем легко задавать ветви в нашей архитектуре (блок ResNet) и легко использовать одни и те же слои несколько раз внутри архитектуры.
Основная функция, создающая всю модель:
Функция потерь с декоратором:
Следующая функция трансформирует целевые выводы к кортежу (tuple) следующей формы:
( [ N , 13 , 13 , 3 , 6 ] , [ N , 26 , 26 , 3 , 6 ] , [ N , 52 , 52 , 3 , 6 ] )Здесь N – количество меток в пакете (batch), а 6 представляет [x, y, w, h, obj, class] содержащих рамок.
Теперь мы создаем экземпляр нашей модели, загружаем веса и имена классов. В датасете COCO их 80.
Вот и все! Прямо сейчас мы можем запустить и протестировать нашу модель на каком-нибудь изображении.

Сохраните это изображение в файл detect.jpg
После выполнения этого кода в файле output.jpg окажется то же изображение с рамками, отмечающими объекты, распознанные нашей нейронной сетью:

Распознавание видео с камеры
Мы уже добились впечатляющего результата, но главное еще впереди! Самое важное в архитектуре YOLO не то, что она довольно неплохо умеет распознавать объекты, а то, что она делает это быстро. Настолько быстро, что успевает обработать все кадры, поступающие от веб-камеры. Включите веб-камеру и запустите следующий код:
Вы увидите на экране изменяющуюся картинку с камеры, на которой будут отмечены все распознанные объекты. Теперь вы можете перемещать свою камеру или двигать объекты в кадре, и нейронная сеть будет успевать обрабатывать меняющиеся изображения.
Читайте также: