
Что значит индексируется файл в облако
Обновлено: 03.07.2024
Очень маленькая скорость загрузки файлов на облако, программа постоянно что-то индексирует и занимает этот процесс дни и недели! В это время ничего не обновляется. Кроме того - программа зачастую непредсказуема!
Решил синхронизировать папку со своими файлами на компьютере и ноутбуке с помощью данной программы. То есть, задача была такая. на компьютере папка, в которой файлы постоянно обновляются и корректируются. Я хотел её скопировать с компьютера на облако, и от туда - на ноутбук, и чтобы все изменения на ноуте автоматически вносились через облако. Привлекло то, что сервис "Облако Мэил ру" даёт бесплатных 1000 Гигабайт, а у меня - около 280 Гб различных данных (музыка, видео, фото и т. д.). Установил программу на оба устройства. Думал, что максимум пол дня и на ноуте появится содержимое папки. Как бы ни так! Приложение сначала начало индексировать одну папку, потом - вторую, потом третью. и так далее. И каждую по несколько часов! "Ну ладно", подумал я, "проиндексирует и потом начнет копировать на облако, а с облака на ноут". Но нет! После индексации папок - программа начала индексировать каждый файл в этих папках! На индексацию каждого файла еще дополнительно от 4 сек до минуты! Файлов около 40000. В общем, дополнительно еще на это ушло 2-3 дня. Сразу отмечу, и на компьютере, и на ноуте у меня очень хорошее железо - процессор Core i7, оперативки 16 Гб.+ быстрые винчестеры (не SSD). В общем, почти неделя у меня ушла на этот обмен данными! А после копирования данных - индексация началась и на ноутбуке! И опять почти неделю ноут включен днями и ночами. "Ну ладно", подумал я, "проиндексирует один раз всё и потом будет просто синхронизировать файлы". Но нет! Индексация на ноутбуке возобновляется где-то по два-три раза в месяц! И каждый раз - почти по неделе ноут стоит круглосуточно включенный. А однажды я решил почистить память в этих папках и на компьютере удалил часть файлов, думая, что они удалятся и на облаке. Как бы ни так! После удаления на компьютере - эти файлы начали мне заново копироваться с облака! Причем, у части этих файлов почему-то изменилась дата редактирования и их стало крайне трудно найти!
Итог - я заплатил 80 руб (800 рублей в год) за 100 Гб на Яндекс-диске (230 Гб у меня уже там было) и перешёл на него! Программа "Яндекс. Диск" работает ГОРАЗДО быстрее, всё чётко и предсказуемо! После установки она СРАЗУ начала загружать файлы на облако и пересылать их на ноут. В итоге весь обмен данными занял НЕСКОЛЬКО ЧАСОВ! И нервы в порядке, и ни каких проблем :)

А несколько месяцев назад произошло неизбежное — мой жёсткий диск с архивом приказал долго жить. К счастью, к тому времени все файлы были скопированы в облако и ничего не потерялось.
После покупки нового диска я заново установил облачный клиент и стал ждать, когда скачаются мои файлы. Но спустя пару минут я увидел, что на диске ничего не появилось, а вот из Облака файлы стремительно удаляются.
В конце статьи есть UPD, UPD2, UPD3 и UPD4, в котором описаны причины такого поведения.
TL;DR: ложная тревога, с файлами и синхронизацией всё в порядке, а вот пользовательский интерфейс и работу тех. поддержки нужно дорабатывать.
Как выяснилось после общения с тех. поддержкой, это стандартное поведение клиента — какую бы папку вы ни скормили ему, он начинает синхронизировать её в облако, удаляя оттуда всё, чего в папке нет.

Остаётся только возможность скачать файлы через веб-интерфейс. Файлы там можно скачивать по одному, а можно выбрать несколько файлов или папок и скачать их одним архивом, что довольно удобно. Единственное ограничение — архив не может превышать 4Гб.

Я попробовал пойти этим путём, но быстро понял, что это очень неудобный вариант:
- Ограничение в 4 гигабайта означает, что если у вас в облаке находится около терабайта, придётся качать как минимум 250 архивов.
- Каждый архив нужно создавать вручную, выбирая папки, считая их суммарный размер и помечая те, что уже скачаны.
- Иногда архивы не открываются по неизвестной причине.
- Теряется структура папок.
Первым делом нужно понять, как получить список папок и файлов. Изначально я планировал просто парсить страницы, выдирать с них информацию о папках и файлах и строить дерево. Но, открыв исходный код страницы, я сразу же увидел, что весь интерфейс работы с документами строится через javascript, что, если подумать, весьма логично.
Поэтому, у меня появилось два возможных варианта решения: подключить
Selenium и всё-таки строить дерево из html или разобраться с внутренним API, которое используется в скрипте.
Я выбрал второй путь, как самый разумный — зачем что-то парсить с использованием сторонних инструментов, если уже есть готовое API?
К счастью, скрипт не был обфусцирован и даже не сжат — мне были доступны исходные имена переменных и функций и комментарии разработчиков, это сильно облегчило задачу.
После нескольких минут изучения я увидел, что все доступные методы API описаны в массиве:

Вот поэтому я и не трачу в своём коде времени на красивое форматирование — кто-нибудь его обязательно поломает.
Открываем страницу в браузере и видим такой ответ:
Очевидно, нужно авторизоваться на портале. Авторизуюсь, повторяю запрос и вижу другую ошибку:
Ничего удивительного, для выполнения запросов к API требуется токен. В списке методов есть два подходящих: tokens/csrf и tokens/download .
Запрашиваем его, добавляем в вызов метода folder параметр ?token=X9ccJNwYeowQTakZC1yGHsWzb7q6bTpP и получаем новую ошибку:
Здесь мне пришлось снова читать исходники, чтобы выяснить какие аргументы принимает этот метод. Оказалось, что нужно указать папку, содержимое которой мы хотим получить в параметре home.
Информация о файлах и директориях — то, что нужно!
Работоспособность API подтверждена, схема его работы понятная — можно приступать к написанию программы. Я решил писать консольное приложение на php, поскольку хорошо знаю этот язык. Для этой задачи идеально подходит компонент Console из состава Symfony. Я уже писал консольные команды для Laravel, которые построены как раз на этом компоненте, но там уровень абстракции довольно высок и напрямую с ним я не работал, поэтому решил, что настало время познакомиться поближе.
Не буду пересказывать документацию, она довольно подробная и очень простая. Ничего не зная о компоненте, за несколько часов я написал вот такие нехитрые интерфейсы:

Так выглядит приложение в процессе скачивания файлов.

А вот так по завершении: показывается небольшая табличка (максимум 100 строк) с информацией о скачаных файлах. Никакой практической пользы она не несёт и сделана исключительно в образовательных целях.
В состав консольного приложения может входить несколько команд, вызываемых следующим образом: php app.php command argument --option . Но для моих целей нужна всего одна команда и я хотел бы запускать скачивание так: php app.php argument --option . Этого легко добиться при помощи инструкции из документации компонента.
Итак, консольное приложение готово, оно выводит информацию из заранее заготовленных фикстур и даже покрыто тестами. Самое время реализовать непосредственно получение информации о файлах и папках из облака.
Вот так выглядит метод авторизации в моём приложенииПоскольку в ответ на запрос авторизации возвращается несколько редиректов, которые в итоге приводят в почтовый ящик пользователя, я решил просто проверять заголовок страницы, чтобы определить успешно ли прошла авторизация.
Проверка простая настолько, что сейчас она проваливается если в почтовом ящике есть непрочитанные письма — их количество выводится в заголовке страницы. Но я ящиком не пользуюсь, поэтому для моих целей этого достаточно.
Далее я попробовал запросить csrf-токен, но с удивлением получил уже знакомую ошибку:
Я занялся отладкой запросов и увидел, что авторизация происходит успешно, но, тем не менее, токен мне не отдавался. Очень похоже на проблему с куками и действительно, оказывается, в Guzzle они по-умолчанию выключены и их нужно включать руками.
Проще всего это сделать один раз при инициализации клиента:
Ещё одним параметром инициализации является 'debug' => true, с ним отладка запросов почти безболезненна.
Настроив куки, я снова попробовал получить токен и получил в ответ ошибку авторизации, с которой до этого не сталкивался:
Я добавил этот запрос после запроса авторизации и наконец-то смог получить токен. Ну а дальше дело техники — запрашивать содержимое корневой папки и рекурсивно содержимое её подпапок, и дерево готово.
Как оказалось, дерево в итоге даже не понадобилось — каждый файл хранит полный путь от корня, поэтому для скачивания достаточно плоского списка.
Учитывая, что адреса шардов отличаются только цифрой, думаю, можно было бы не заморачиваться и захардкодить адрес, но если уж делать, то делать до конца!
Нас интересует массив, хранящийся в get.
Выбираем случайный элемент из массива шардов, добавляем к нему адрес файла и ссылка для скачивания готова!
Для экономии памяти можно сразу при создании запроса указать, куда Guzzle должен записать ответ, для этого используется параметр sink.
Итоговый код выложен на GitHub под лицензией MIT, буду рад, если он кому-то пригодится.
Приложение далеко от идеала, его функционал ограничен, в нём совершенно точно есть баги и покрытие тестами оставляет желать лучшего, но оно на все 100% решило мою задачу, а ведь именно это требуется от MVP.
* Все, которые не успело сначала удалить.
UPD: Общение с тех. поддержкой.
[[[[ У меня возникают проблемы с синхронизацией. другая проблема, Форма обратной связи ]]]] Добрый день.Я заменил жесткий диск, на котором располагалась папка облака. Старый диск сломался, поэтому перенести данные с него нет возможности. В веб-интерфейсе все мои данные на месте.
Когда я создал пустую папку на новом диске и настроил её в приложении, при синхронизации начали удаляться файлы в облаке.
Как мне настроить приложение на компьютере, чтобы оно считало основной копией веб, а не пустую папку — то есть начало бы скачивать файлы на компьютер, а не удалять их в облаке.
Пробовал скачивать файлы через браузер, но это нереально — их очень много.
К сожалению, восстановить удалённые одновременно и в Облаке, и на ПК файлы
нельзя.
По умолчанию между web-интерфейсом и приложением на компьютере
осуществляется полная двусторонняя синхронизация — если вы удаляете файл из
Облака в web-интерфейсе, то файл удаляется и в приложении, так же и
наоборот: удаляя файл в приложении, вы удаляете файл и в Облаке.
Вы можете настроить выборочную синхронизацию в ПК-клиенте Облака. Для этого
кликните на иконке Облака (в системном трее) правой кнопкой мыши и
перейдите в раздел «Выбрать папки».
В открывшемся окне снимите галочки напротив тех папок, синхронизацию для
которых вы хотите отменить и нажмите «Выбрать».
Если ранее папка была синхронизирована, то она будет удалена с вашего
компьютера, но в web-интерфейсе Облака папка, а также все содержащиеся в
ней файлы, сохранятся.
Чтобы вновь включить синхронизацию для удаленной ранее папки, кликните на
иконку приложения Облака правой кнопкой мыши, нажмите «Выбрать папки» и
установите галочку напротив имени необходимой папки.
Вы также можете временно отключить синхронизацию. Для этого кликните на
иконку приложения Облака правой кнопкой мыши и выберите «Приостановить
синхронизацию».
Возможно, я не совсем явно обозначил свою проблему, попробую перефразировать.
Все мои файлы на данный момент есть в облаке. Я купил новый HDD и хочу эти файлы на него скачать. Но когда я создал на нем пустую папку и указал её в приложении, вместо скачивания файлов из облака на компьютер, файлы начали удаляться из облака.
Как мне запустить процесс в обратном направлении — скачать всё из облака на компьютер, не используя веб-интерфейс.
Если это невозможно сделать через приложение, есть ли какие-то альтернативные инструменты? WebDav, как я понимаю, еще не реализован?
На текущий момент данная функциональность отсутствует.
Ваше замечание передано разработчикам.
UPD3: На ноутбук, где до этого облачный клиент никогда не стоял, скачал последнюю версию с официального сайта, установил, запустил. При выборе существующей папки история повторяется: файлы вместо скачивания начинают удаляться. Попробовал не создавать папку — аналогично.

Если есть одна вещь, которая бьется в голове каждого пользователя компьютера, это реализовать схему резервного копирования данных. Мол, прямо сейчас. Это разумный совет, но в зависимости от того, как и где вы создаете резервную копию своих данных, вы можете раскрыть больше о себе, чем поделиться. Подумайте на мгновение о содержимом вашего жесткого диска (или твердотельного накопителя) и о том, насколько комфортно вам будет с незнакомцами, разбирающими ваши цифровые биты.
Использование облака стало популярным способом ведения дел, и, хотя вы, возможно, не захотите хранить свои фотографии и видео NSFW на сторонних серверах по понятным причинам, вы можете выбежать и приобрести устройства резервного копирования, которые создают персональное облако, предназначенное только для вы. Разумеется, за прошедшие годы мы рассмотрели многие из них, такие как Personal Cloud Server компании Western Digital и, в последнее время, Personal Cloud Server WD My Cloud EX2, обновленную модель с большей емкостью и возможностями хранения.
В большинстве случаев информация была доступна в Интернете, потому что кто-то неправильно настроил устройство, действующее как персональное облако, или на его маршрутизаторе был включен FTP. В случае включения FTP вы можете предположить, что это был несчастный случай, хотя в некоторых случаях XSS сказал, что он был специально настроен таким образом по той или иной причине. Независимо от причины, результатом является то, что информация была аккуратно проиндексирована Google и легко доступна для поиска.
Под легким поиском мы подразумеваем, что вам просто нужно искать данные, и
БАМ, это для всех. Вам не нужен пароль или любой другой тип
авторизации. Итак, скажем, у вас есть внешний диск, подключенный к вашему
роутер и FTP включен. Когда устройства работают как FTP-серверы, используя
IP-адрес человека или имя хоста в качестве адреса, поисковые системы обрабатывают внешний
диск как публичный архив.
Некоторые из архивов восходят к 2004 году, а некоторые были обновлены совсем недавно, в прошлом месяце. Это данные за десятилетие. И если вы думаете, что эти сбои происходят только на устаревшем оборудовании, подумайте еще раз. По крайней мере, в одном случае были найдены личные данные с внешнего диска, подключенного к маршрутизатору Linksys WRT1900AC, который является популярной в настоящее время моделью среди энтузиастов. Легко понять, почему кто-то включил FTP-сервисы для удаленной передачи файлов на устройство и с него, но без надлежащей защиты это не имеет большого значения после нанесения ущерба.

XSS связался с семьей, которой принадлежал роутер, чтобы сообщить им, что их финансовая история за последние пять лет была доступна для просмотра в Интернете. Взамен семья поделилась историей, рассказывающей о том, как в конце прошлого года они не могли понять, как их кредитные карты были скомпрометированы в течение нескольких минут после их активации.
Мораль истории? Не думайте, что ваши данные являются конфиденциальными, даже если вы используете персональное облако. Удвойте и утроите ваши настройки чека, и, если сомневаетесь, сделайте ошибку в пользу безопасности.


Лет 15 – 20 назад компьютер с жестким диском на 200 – 300 ГБ считался непозволительной роскошью. В 2000-х забить под завязку такую емкость казалось чем-то из разряда фантастики: практически весь интернет тарифицировался помегабайтно, а с безлимитным тарифом можно было провести вечность, чтобы забить те самые 200 ГБ.
Но время все изменило. В середине сентября Apple анонсировала iPhone XS и XS Max, топовая комплектация которых предусматривает размер встроенной памяти в целых 512 ГБ. И, поверьте, те, кто выберет смартфон с такой памятью, наверняка найдут что в нем хранить.
Что делать пользователям, которым нужно хранить большие объемы данных, но нет возможности повсюду носиться с внешним накопителем? На помощь придут «облака» или облачные хранилища.
Разберемся, по какому принципу они работают и что происходит с пользовательскими данными при хранении в облаке.
Тайна за семью печатями

Вы будете удивлены, но как на самом деле работают облачные хранилища сказать очень сложно. У каждой компании, будь то Apple, Google или Amazon свои алгоритмы сжатия, хранения и предоставления доступа.
Информация эта весьма конфиденциальна. Учитывая растущую активность хакеров всех мастей, посвящать в нее никто не хочет. А все потому, что одно интервью и пару технических уточнений могут поставить под угрозу петабайты информации.
Тем не менее есть определенная схема, по которой работает классическое облачное хранилище.
Вы проходите регистрацию на том или ином сервисе, и тут же получаете бесплатный тариф в размере 5 – 10 ГБ. А дальше либо самостоятельно загружаете файлы через браузер, либо устанавливаете отдельный клиент на компьютер, где автоматическая загрузка из подтвержденной вами директории происходит автоматически.
Как устроены облачные хранилища
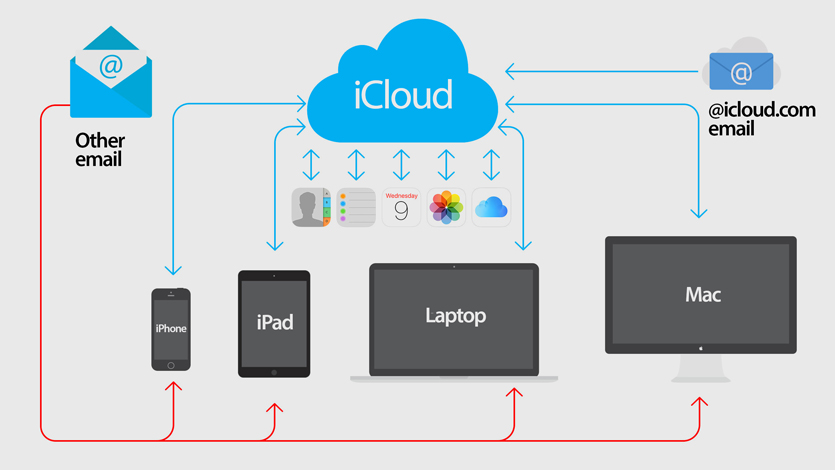
На сегодняшний день существует масса всевозможных облачных систем хранения. У каждого свои задачи. Одни отвечают за хранение переписки в мессенджерах, другие — для переноса фотографий или резервного копирования писем из электронной почты. Есть и универсальные, благодаря которым можно загружать файлы любого типа и с любым расширением.
В зависимости от масштабов оборудование, необходимое для хранения данных, может занимать как небольшую комнату, так и отдельные здания, по площади сопоставимые с полноценными ангарами для самолетов. Такие места называются центрами обработки данных.
Для компаний, предоставляющий дисковое пространство в качестве облачного, важно иметь не только достаточную мощность, но и позаботиться о нескольких дополнительных факторах.
Избыточное резервирование. Центра обработки данных не может состоять из серверов, которые рассчитаны сугубо на конкретную клиентскую базу. Говоря проще: если облаком пользуется 1000 человек по тарифу 10 ГБ в облаке, то компании нужно позаботиться о наличии не 10 ТБ емкости хранилища, а о значительно большем.
Дело в том, что серверам необходима периодическая профилактика. Ведь, по сути, это железо, которое покрывается слоем пыли, перегревается, выходит из строя. Но клиент должен быть уверен в том, что получит доступ к своим файлам в любое время.

Для этого используются избыточные сервера. На них хранятся, как бы странно это не звучало, копии копии ваших данных. А оригиналы — у вас на компьютере или смартфоне. Во время профилактики сервера отключаются в такой последовательности, чтобы, как минимум, одна копия данных всегда оставалась доступной.

Резервное питание. В облачных хранилищах инженеры подключают сервера таким образом, чтобы пользователи, опять-таки, всегда имели доступ к файлам даже при аварии в электросети.
Для обеспечения бесперебойного доступа используются автономные электрические генераторы, способные обеспечить весьма продолжительное время работы.

У той же Apple, учитывая приоритеты компании в «зеленой» энергетике, роль таких генераторов выполняют солнечные панели.
Шифрование. С целью безопасности и предотвращения несанкционированного доступа, все загруженные в облако данные шифруются посредством сложного алгоритма кодирования. Получить доступ к таким данным можно лишь с помощью ключа шифрования, которые есть лишь у пользователя.
Само по себе облачное хранение разделяется на три категории: инфраструктура как услуга (IaaS) — ситуация, в которой такие крупные игроки как Amazon и Google предоставляю свои аппаратные мощности в аренду другим компаниям; платформа как сервис (PaaS) — объемы пространства в онлайне, в которых разработчики создают приложения для различных категорий пользователей; ПО как сервис (SaaS) — когда пользователи используют программное обеспечение для доступа к облаку через интернет.
Итак, вы решили загрузить очередную порцию фотографий с отпуска в облачное хранилище. Открыв мобильный клиент, выбираете снимки для синхронизации и выбираете «Загрузить».
Со смартфона через интернет поступает запрос на управляющий концентратор облачного сервера. Его еще называют «распределительным сервером» или MasterMind-сервером. Он отвечает за обработку вашего запроса и отправку файлов точно по адресу, то несть непосредственно в папку, которая принадлежит вам.
При это концентратор вычисляет доступный и остаточный объем дискового пространства, которым вы можете пользоваться по условиям вашего тарифного плана. Во время загрузки файлов, они перераспределяются между серверами и копируются в резервное хранилище. То есть параллельно загрузка ведется на несколько накопителей для мгновенного резервирования.
Внутри дата-центров Apple

Чтобы представить, как может выглядеть центр обработки данных, давайте заглянем в «серверную» компании Apple. Журналистам издания The Arizona Republic удалось договориться о съемке всего месяц назад, поэтому предоставленные данные актуальны.
Площадь помещения, в котором хранятся сотни серверов, составляет 120 тыс. квадратных метров. Представьте себе, что это 2 400 квартир, площадью 50 квадратов.
Все это пространство заставлено «серверными шкафами», стоящими на бетонном полу.

На снимке выше — помещение, получившее название центра глобальных данных. Здесь трудятся несколько человек. Смена каждого составляет 10 часов. Именно из этой точки контролируется работа таких сервисов, как Siri, iCloud, iMessage.
Всего здесь трудятся около 150 человек, хотя изначально Apple планировала привлечь около 600 сотрудников. Видимо, потребности в большем количестве рабочих нет — все работает и так стабильно.
Территория дата-центра строго охраняема, а сам объект признан стратегически важным. Найти какую-либо информацию о принципах работы хранилищ Apple практически невозможно. Разве что, устроиться на работу в подобный центр обработки.
Размеры подобных «серверных» могут быть просто огромными. Вот, к примеру, один из дата-центров Apple. Расположен он в Аризоне (США):

А так выглядит проект одного из центров обработки в Айове (США).

Интересный факт: Apple планирует создать дополнительные рабочие места за счет строительства дополнительных дата-центров. Так вот, стоимость часа работы одного инженера в таком месте составляет около $30.
Спорное право собственности

Облачные хранилища — это удобно. Вы получаете доступ к гигагабайтам информации с любой точки мира. А все, что нужно для доступа — учетная запись и интернет. Никаких переносных дисков и боязни за сохранность информации во время транспортировки накопителя.
Но так ли все однозначно? Многих пользователей интересуют несколько ключевых вопросов, которые их останавливают перед использованием облачных сервисов.
Кому принадлежат загруженные данные: пользователю или компании, которая предоставляет место в облаке? Что будет с данными, если пользователь решит попрощаться с хранилищем?
Физически ваши данные могут храниться на дисках, которые расположены на самых разных странах и континентах. Все зависит от того, где именно компания, предоставляющая облачное пространство, располагает свои центры обработки. Учитывая, что сервера принадлежат конкретной компании, то и ваши данные отправляются в ее владение.
Не верите? Тогда достаточно вспомнить выдержку из лицензионного соглашения Google Drive:
Загружая или иным образом добавляя материалы в наши Службы, вы предоставляете нам действующую во всем мире лицензию, которая позволяет нам использовать это содержание, размещать его, хранить, воспроизводить, изменять, создавать на его основе производные работы, обмениваться им, публиковать его, открыто воспроизводить, отображать, а также распространять.
Потом эти условия использования пережили еще несколько редакций, превратившись в это:
Наши Условия использования гласят: "Все права на интеллектуальную собственность в отношении… материалов остаются у их владельца. Проще говоря, все, что было вашим, таковым и останется".
Мы не претендуем на права собственности на контент, который вы загружаете, передаете или храните на Диске (в том числе любые файлы, текстовые и графические данные). Условия использования лишь наделяют нас правом предоставления требуемых сервисов.
Например, мы можем реализовать возможность настройки совместного доступа к документам или поддержку открытия файлов на других устройствах.
Но так потрудилась поступить лишь Apple, Google и еще парочку авторитетных компаний.
А вот еще пример того, что, по сути, компании не несут ответственности за все, что вы у них храните. Условия постараются обеспечить максимально комфортные, но, если что, пинайте на себя.
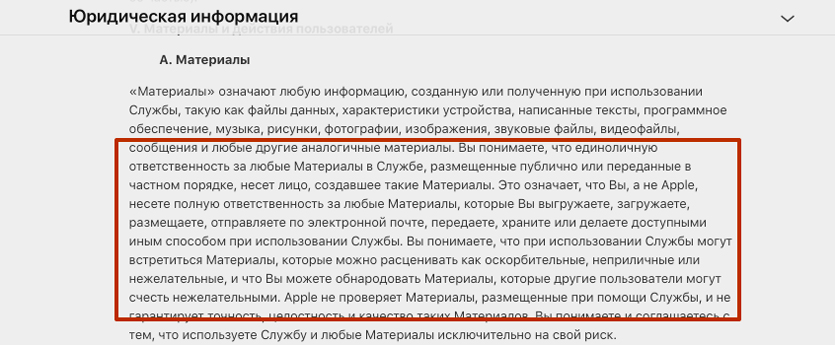
Выдержка из условия использования сервиса iCloud.
В большинстве же сервисов условия использования звучат так, как будь-то вас заведомо предупреждаю: «Все, что вы загрузили на наши сервера, теперь принадлежит нам». То есть файлы по-прежнему остаются вашими, но облачный сервис может делать с ними все, что захочет.
Эта информация — явно повод задуматься над хранением особо важных и секретных данных.
Стоит ли им доверять?

Когда вы задаете себе подобный вопрос, сразу же вспомните ваше поведение во время установки десктопного клиента Dropbox, Google Drive, Яндекс.Диска и прочих.
В момент, когда вы ставите галочку и щелкаете по кнопке «Принимаю», вы предварительно читаете добрый десяток страниц текста с «Условиями обслуживания»?
Главное — правильно выбирать «облако», в котором планируете хранить свои данные. Из тех, кому можно доверять, стоит отметить:
— Apple с сервисом iCloud и весьма гуманными тарифами;
— Google с сервисом Google Drive и безлимитном для загрузки фотографий со смартфона в стандартном качестве;
— Dropbox с дорогим, но крутым тарифом на 1 ТБ пространства в облаке.
А сервисы, предлагающие вам сотни гигабайт бесплатно — сомнительное удовольствие. Рискуете либо потерять данные, либо отправлять/скачивать их целую вечность.
Облачные хранилища действительно существенно упрощают нашу жизнь. Они заменили нам громоздкие винчестеры и вечно теряющиеся флешки, предоставив мгновенный доступ к сотням гигабайт информации. Стоит ли отказываться от таких преимуществ из суеверности? Вряд ли.
(19 голосов, общий рейтинг: 4.89 из 5)
Облачное хранилище — это структура распределенных в сети онлайн-серверов, как правило, в виде онлайн-сервиса, предоставляющая пользователям место для хранения их данных. Хранилище нужно синхронизировать со своим устройством. После этого туда можно загружать файлы любого типа. Они будут доступны со всех устройств онлайн.
Для чего нужны облачные хранилища?
Для экономии места на смартфонах и компьютерах. В облако можно выгрузить фотографии, музыку и любые другие данные, которые жалко удалить или которые занимают много места, например записи с камер видеонаблюдения.
Для резервного копирования и восстановления, если важно сохранить файлы.
Для миграции данных бизнеса. В облаке удобнее делиться файлами с коллегами и организовать совместную работу.
Виды хранилищ

Блочное
Весь объем информации делится на равные части — блоки с идентификаторами. Основное преимущество таких облачных хранилищ — разделение клиентских сред. Благодаря этому к каждой из них открывается быстрый отдельный доступ. Но платить нужно за весь выделенный объем памяти, даже если она ничем не занята.
Примеры хранилищ: Amazon Elastic Block Storage (EBS).
Файловое
Данные хранятся в иерархической системе. Это значит, что информация представляет собой файлы, объединяющиеся в папки, подкаталоги и каталоги. Основное преимущество — интуитивный интерфейс и легкость использования. Главный недостаток — плохая масштабируемость: с увеличением объема данных иерархия очень сильно усложняется и замедляет работу системы.
Примеры хранилищ: Яндекс.Диск, Dropbox, OneDrive, Google Диск.
Объектное
Это универсальный и современный способ хранения в облаке больших информационных массивов. Объектное хранилище используется для данных любого вида: медиаконтента, программ, бухгалтерской/статистической отчетности и др. Главный недостаток — пользователь не может просто взять и переместить файл в нужную папку. Для загрузки информации нужно использовать специальный программный интерфейс — API (он позволяет двум независимым компонентам ПО обмениваться информацией).
Примеры хранилищ: Amazon Simple Storage Service (S3).
Помогаем лучше разобраться с облачными хранилищами и учим строить пайплайны данных. Дополнительная скидка 5% по промокоду BLOG.
Как работают облачные хранилища
Принцип работы облачного хранилища данных заключается в следующем: на ноутбук, ПК или любой другой гаджет устанавливается программа, в которую с устройства переносится информация. Потом облако будет самостоятельно отслеживать изменения в них и автоматически подгружать новые файлы. Связав хранилище со всеми устройствами, можно получить доступ ко всем данным с любого гаджета.
Плюсы облачного хранилища
- Доступ к данным с любого устройства, имеющего выход в интернет.
- Сохранение данных даже в случае сбоев.
- Организация совместной работы с информацией.
- Отсутствие необходимости покупать, поддерживать и обслуживать инфраструктуру по хранению данных (сервера).
Минусы облачного хранилища
- Необходимость качественного интернета.
- Замедление работы в облаке, если файлы весят много.
- Могут быть проблемы с безопасностью сохранности данных (например, однажды хакеры взломали 68 млн учетных записей Dropbox).
Критерии выбора хранилища
Размер облачного хранилища. Если нужно хранить небольшое количество фотографий и легких файлов типа Word, Excel, то 10 ГБ может вполне хватить. Но если требуется копировать в облако большие файлы, например видео, то лучше сразу выбрать тариф, предлагающий большой/максимальный объем хранения.
Возможность увеличения объема хранилища. Особенно важный критерий для пользователей, которые планируют хранить большие массивы данных. Если это так, лучше выбирать сервис, в котором в любой момент можно изменить тариф.
Наличие ПО для компьютера и смартфона. У сервиса облачного хранения обязательно должно быть приложение и/или программа для установки и синхронизации.
Имеющиеся ограничения. Перед выбором важно узнать о всех имеющихся ограничениях. Например, о количестве объема памяти, размере одного загружаемого файла.
Примеры популярных облачных хранилищ
Яндекс.Диск
Бесплатный объем: 10 Гб
- настройка общего доступа к папкам;
- отправка ссылок на файлы;
- просмотр фото в галерее, создание альбомов, настройка автозагрузки видео и фото со смартфона;
- просмотр файлов/папок, перемещение их, редактирование документов.
Google Диск
Бесплатный объем: 7 Гб
- общий доступ к данным и совместное редактирование;
- работа с Google Документами, Таблицами и Презентациями;
- индексация общедоступных документов поисковыми системами.
Dropbox
Бесплатный объем: 7 Гб
- хранение и синхронизация файлов;
- совместная работа над файлами;
- резервное копирование файлов.
Microsoft OneDrive
Бесплатный объем: 15 Гб
- совместный доступ к фотографиям, видео, папкам и различным документам;
- сканирование и сохранение документов, квитанций, визиток, заметок;
- работа в Word, Excel и других приложениях Office.
Важно! Принцип синхронизации зависит от ОС компьютера, поэтому перед работой с хранилищем следует скачать подходящую программу для его адаптации.
Mega
Бесплатный объем: 15 Гб (до 50 Гб в течение месяца после регистрации)
- шифрование контента в браузере при помощи алгоритма AES (ключ хранится только у владельца);
- передача зашифрованных файлов другим пользователям;
- обеспечение информационной неприкосновенности за счет хранения данных на серверах компании, расположенных в Новой Зеландии.
Бесплатный объем: 8 Гб
- работа с общими папками;
- редактирование документов, таблиц и презентаций;
- настройка автозагрузки фотографий со смартфона и выборочная синхронизация;
- распознавание документов на фотографиях.
Примеры употребления термина
Правильно: Используйте облачное хранилище для экономии места на компьютере или смартфоне.
Неправильно: Сделайте облачное хранилище для файлов с компьютера или смартфона.
Помогаем лучше разобраться с облачными хранилищами и учим строить пайплайны данных. Дополнительная скидка 5% по промокоду BLOG.
Читайте также: