
Что значит распознать файл
Обновлено: 06.07.2024
Наверное, каждый из нас сталкивался с задачей, когда нужно перевести бумажный документ в электронный вид. Особенно это часто нужно делать тем кто учиться, работает с документацией, переводит тексты при помощи электронных словарей и т.д.
В этой статье мне хотелось бы поделиться некоторыми азами этого процесса. Вообще, сканирование и распознавание текста — довольно трудоемко, так, как большинство операций придется делать вручную. Мы попытаемся разобраться по шагам, что, как и почему.
Не все сразу понимают одну вещь. После сканирования (пригона всех листов на сканере) у вас будут картинки формата BMP, JPG, PNG, GIF (могут быть и другие форматы). Так вот с этой картинки нужно получить текст — это процедура называется распознаванием. В таком порядке и будет изложение ниже.
1. Что нужно для сканирования и распознавания?
Для перевода печатных документов в текстовый вид, вам для начала нужен сканер и соответственно, «родные» программы и драйверы, которые с ним шли. При помощи них можно будет сканировать документ и сохранить его для дальнейшей обработки.
Можно воспользоваться и другими аналогами, но софт, который шел со сканером в комплекте, обычно работает быстрее и имеет больше опций.
В зависимости от того, какой у вас сканер — скорость работы может существенно различаться. Есть сканеры, которые могут получить картинку с листа за 10 сек., есть которые будут получать за 30 сек. Если сканируете книгу на 200-300 листов — думаю, не трудно подсчитать во сколько раз будет разница во времени?
2) Программа для распознавания
В нашей статье я буду показывать вам работу в одной из лучших программ для сканирования и распознавания абсолютно любых документов — ABBYY FineReader. Т.к. программа платная, то сразу дам ссылку и на другую — ее бесплатный аналог Cunei Form. Правда, я бы не стал их сравнивать, ввиду того, что FineReader выигрывает по всем параметрам, рекомендую все же попробовать именно ее.
ABBYY FineReader 11
Одна из лучших программ в своем роде. Она предназначена для того, чтобы распознать текст на картинке. Встроено множество опций и функций. Может разобрать кучу шрифтов, поддерживает даже рукописные варианты (правда, лично не пробовал, думаю, хорошо вряд ли будет распознавать рукописный вариант, если только у вас не идеальный каллиграфический почерк). Более подробно о работе с ней будет рассказано ниже. Здесь же отметим, что в статье будет рассказано о работе в программе 11 версии.
Как правило, разные версии ABBYY FineReader не сильно отличаются друг от друга. Вы без труда сделаете то же самое и в другой. Главные отличия могут быть в удобстве, быстроте работы программы и ее возможностях. Например, более ранние версии отказываются открывать документ PDF и DJVU…
3) Документы для сканирования
Да, вот так вот, решил вынести документы отдельной графой. В большинстве случаев сканируют какие-нибудь учебники, газеты, статьи, журналы и пр. Т.е. те книги и ту литературу которая пользуется спросом. Я это к чему веду? Из личного опыта могу сказать, что многое, что вы захотите сканировать — возможно уже есть в сети! Сколько раз лично я экономил время, когда находил ту или иную книгу уже сканированную в сети. Мне оставалось только скопировать текст в документ и продолжить с ним работу.
Из этого простой совет — прежде чем что-то сканировать, проверьте, может уже кто-то отсканировал и вам не нужно терять свое время.
2. Параметры сканирования текста
Здесь я не будут рассказывать о ваших драйверах для сканера, программах, которые вместе с ним шли, ибо все модели сканеров разные, ПО тоже везде разное и угадать и тем более показать наглядно как выполнять операцию — нереально.
Но во всех сканерах есть одни и те же настройки, которые сильно могут повлиять на скорость и качество вашей работы. Вот о них таки как раз и поговорим здесь. Буду перечислять по порядку.
1) Качество сканирования — DPI
Во-первых, качество сканирования поставьте в опциях не ниже 300 DPI. Желательно даже выставить побольше, если это возможно. Чем выше показатель DPI — тем четче получиться ваша картинка, ну и тем самым, быстрее пройдет дальнейшая обработка. К тому же чем выше качество сканирования — тем меньше ошибок вам в последствии придется исправлять.
Оптимальный вариант обеспечивает, обычно, 300-400 DPI.
Этот параметр очень сильно влияет на время сканирования (кстати, DPI тоже влияет, но те так сильно, и только когда пользователь ставит высокие значения).
Обычно выделяют три режима:
— черно-белый (отлично подойдет для простого текста);
— серый ( подойдет для текста с таблицами и картинками);
— цветной (для цветных журналов, книг, в общем, документов, где важна цветность).
Обычно от выбора цветности зависит время сканирования. Ведь если документ у вас большой, то даже лишние 5-10 секунд на странице в целом выльются в приличное время…
Документ вы можете получить не только сканированием, но и сфотографировав его. Как правило, в этом случае у вас будут некоторые другие проблемы: искажение картинки, смазанность. Из-за этого может потребоваться более длительная дальнейшая правка и обработка полученного текста. Лично я не рекомендую пользоваться фотоаппаратами для этого дела.
Важно отметить, что не каждый такой документ получится распознать, т.к. качество сканирования у него может быть крайне низким…
3. Распознавание текста документа
Будем считать, что заветные сканированные страницы вы получили. Чаще всего они представляют собой форматы: tif, bmb, jpg, png. В общем-то, для ABBYY FineReader — это не сильно важно…
После открытия в ABBYY FineReader картинки, программа, как правило, на автомате начинает выделять области и распознавать их. Но иногда она делает это не правильно. Для этого-то мы и рассмотрим выделение нужных областей вручную.
Важно! Не все сразу понимают, что после открытия документа в программе, слева в окне отображается исходный документ, в котором вы и выделяете различные области. После нажатия на кнопку «распознавания» программа в окне справа выведет вам готовый текст. После распознавания, кстати, целесообразно проверить текст на ошибки в том же самом FineReader.
3.1 Текст
Эта область используется для выделения текста. Картинки и таблицы нужно исключать из нее. Редкие и необычный шрифты придется вводить вручную…
Для выделения текстовой области, обратите внимание на панель в верхней части FineReader. Там есть кнопка «Т» (см. скриншот ниже, указатель мышки как раз на этой кнопке). Щелкаете по ней, затем на картинке ниже выделяете аккуратно прямоугольную область, в которой располагается текст. Кстати, в некоторых случаях нужно создавать текстовых блоков по 2-3, а иногда по 10-12 на страницу, т.к. форматирование текста может быть разным и одним прямоугольником всю область не выделить.
Важно отметить, что в текстовую область не должны попадать картинки! В дальнейшем это вам сэкономит кучу времени…
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-07-33](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-07-33.jpg)
3.2 Картинки
Используется для выделения картинок и тех областей, которые тяжело распознать из-за плохого качества, или необычности шрифта.
На скриншоте ниже указатель мышки находится на кнопке, используемой для выделения области «картинка». Кстати, в эту область можно выделить абсолютно любую часть страницы, а FineReader вставит ее потом в документ как обычную картинку. Т.е. просто «тупо» скопирует…
Обычно эту область используют для выделения плохо отсканированных таблиц, для выделения нестандартного текста и шрифта, само-собой картинок.
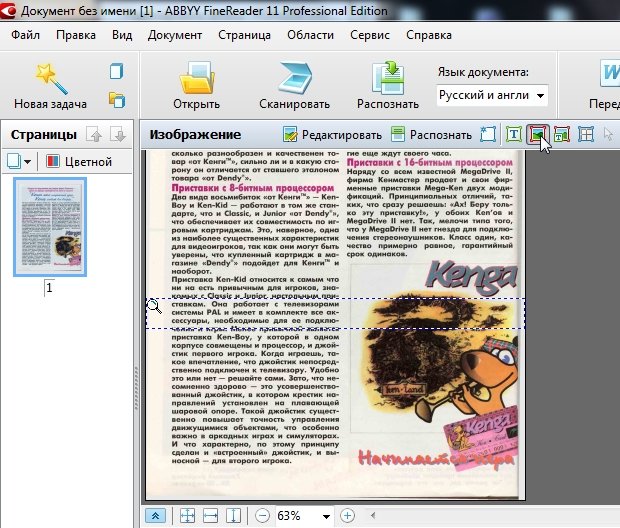
3.3 Таблицы
На скриншоте ниже показана кнопка для выделения таблиц. Вообще, лично я ее использую крайне редко. Дело в том, что вам придется довольно рутинно рисовать (фактически) каждую линию на таблице и показывать что и как программе. Если таблица небольшая и в не очень хорошем качестве, я рекомендую для этих целей использовать область «картинка». Тем самым сэкономите кучу времени, а таблицу можно потом в Word сделать быстренько на основе картинки.
![]()
3.4 Ненужные элементы
Важно отметить. Иногда на странице есть ненужные элементы, которые мешают распознать текст, или вообще не дают вам выделить нужную область. Их можно при помощи «ластика» удалить вовсе.
Для этого переходим в режим редактирования изображения.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-14-11](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-14-11.jpg)
Выбираем инструмент «ластик» и выделяем ненужную область. Она сотрется и на ее месте будет белый лист бумаги.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-14-21](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-14-21.jpg)
Кстати, рекомендую использовать вам эту опцию как можно чаще. Старайтесь все текстовые области которые вы выделили, где вам не нужен кусок текста, или присутствуют любые ненужные точки, размытости, искажения — удалять ластиком. Благодаря этому распознавание будет быстрее!
4. Распознавание файлов PDF/DJVU
Вообще, этот формат распознавания не будет отличаться ничем другим от остальных — т.е. работать с ним можно так же как с картинками. Единственное, программа не должна быть слишком старой версии, если файлы PDF/DJVU у вас не открываются — обновите версию до 11.
Небольшой совет. После открытия документа в FineReader — он автоматически начнет распознавать документ. Часто в файлах PDF/DJVU определенная область страницы не нужна во всем документе! Чтобы удалить такую область на всех страницах сделайте следующее:
1. Зайдите в раздел редактирования изображения.
2. Включите опция «обрезки».
3. Выделите область, нужную вам на всех страницах.
4. Нажмите применить ко всем страницам и обрежьте.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-19-21](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-19-21.jpg)
5. Проверка ошибок и сохранение результатов работы
Казалось бы, какие еще могут быть проблемы, когда все области были выделены, затем распознаны — бери да сохраняй… Не тут то было!
Во-первых, нужна проверка документа!
Чтобы ее включить, после распознавания, в окне справа, будет кнопка «проверка», см. скриншот ниже. После ее нажатия программа FineReader будет автоматически показывать вам те области, где у программы возникли ошибки и она не смогла достоверно определить тот или иной символ. Вам останется только выбирать, либо вы согласны с мнением программы, либо вводите свой символ.
Кстати, в половине случаев, примерно, программа будет вам предлагать готовое правильное слово — вам останется толкьо мышкой выбрать нужный вариант.
Во-вторых, после проверки вам нужно выбрать формат, в который вы сохраните результат своей работы.
Здесь FineReader дает вам развернуться на полную катушку: можно просто передать информацию в Word один в один, а можно сохранить ее в одном из десятков форматов. Но хотелось бы выделить другой важный аспект. Какой формат бы не выбрали, более важно выбрать тип копии! Рассмотрим самые интересные варианты…
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-24-08](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-24-08.jpg)
Все области, которые вы выделяли на странице в распознанном документе будут соответствовать точь в точь исходному документу. Очень удобный вариант, когда вам важно не потерять форматирование текста. Кстати, шрифты так же будут очень похожи на оригинал. Рекомендую при таком варианте передавать документ в Word, чтобы уже там продолжить дальнейшую работу.
Этот вариант хорош тем, что вы получите уже форматированный вариант текста. Т.е. отступов с «километр», которые возможно были в исходном документе — вы не встретите. Полезная опция, когда вы будете значительно редактировать информацию.
Правда, не стоит выбирать, если вам важно сохранить стилистику оформления, шрифты, отступы. Иногда, если распознавание прошло не очень успешно — ваш документ может «перекосить» из-за измененного форматирования. В этом случае целесообразно выбрать точную копию.
Вариант для тех, кому нужен просто текст со странице без всего остального. Подойдет для документов без картинок и таблиц.
На этом статья по сканированию и распознаванию документа подошла к концу. Надеюсь, что при помощи этих простых советов вы сможете решить свои задачи…
Этот сервис от компании Microsoft превращает камеру смартфона или ПК в бесплатный сканер документов. С помощью Office Lens вы можете распознать текст на любом физическом носителе и сохранить его в одном из «офисных» форматов или в PDF. Итоговые текстовые файлы доступны для редактирования в Word, OneNote и других сервисах Microsoft, интегрированных с Office Lens. К сожалению, с русским языком программа справляется не так хорошо, как с английским.






2. Adobe Scan
Adobe Scan тоже использует камеру смартфона, чтобы сканировать бумажные документы, но сохраняет их копии только в формате PDF. Приложение полностью бесплатно. Результаты удобно экспортировать в кросс‑платформенный сервис Adobe Acrobat, который позволяет редактировать PDF‑файлы: выделять, подчёркивать и зачёркивать слова, выполнять поиск по тексту и добавлять комментарии.


3. FineReader
- Платформы: веб, Android, iOS, Windows.
- Распознаёт: JPG, TIF, BMP, PNG, PDF, снимки камеры.
- Сохраняет: DOC, DOCX, XLS, XLSX, ODT, TXT, RTF, PDF, PDF/A, PPTX, EPUB, FB2.
4. Online OCR
- Платформы: веб.
- Распознаёт: JPG, GIF, TIFF, BMP, PNG, PCX, PDF.
- Сохраняет: TXT, DOC, DOCX, XLSX, PDF.
Веб‑сервис для распознавания текстов и таблиц. Без регистрации Online OCR позволяет конвертировать до 15 документов в час — бесплатно. Создав аккаунт, вы сможете отсканировать 50 страниц без ограничений по времени и разблокируете все выходные форматы. За каждую дополнительную страницу сервис просит от 0,8 цента: чем больше покупаете, тем ниже стоимость.
5. img2txt
- Платформы: веб.
- Распознаёт: JPEG, PNG, PDF.
- Сохраняет: PDF, TXT, DOCX, ODF.
Бесплатный онлайн‑конвертер, существующий за счёт рекламы. img2txt быстро обрабатывает файлы, но точность распознавания не всегда можно назвать удовлетворительной. Сервис допускает меньше ошибок, если текст на загруженных снимках написан на одном языке, расположен горизонтально и не прерывается картинками.
6. Microsoft OneNote
- Платформы: Windows, macOS.
- Распознаёт: популярные форматы изображений.
- Сохраняет: DOC, PDF.
В настольной версии популярного блокнота OneNote тоже есть функция распознавания текста, которая работает с загруженными в заметки изображениями. Если кликнуть правой кнопкой мыши по снимку документа и выбрать в появившемся меню «Копировать текст из рисунка», то всё текстовое содержимое окажется в буфере обмена. Программа доступна бесплатно.
7. Readiris 17
- Платформы: Windows, macOS.
- Распознаёт: JPEG, PNG, PDF и другие.
- Сохраняет: PDF, TXT, PPTX, DOCX, XLSX и другие.
Мощная профессиональная программа для работы с PDF и распознавания текста. С высокой точностью конвертирует документы на разных языках, включая русский. Но и стоит Readiris 17 соответственно — от 49 до 199 евро в зависимости от количества функций. Вы можете установить пробную версию, которая будет работать бесплатно 10 дней. Для этого нужно зарегистрироваться на сайте Readiris, скачать программу на компьютер и ввести в ней данные от своей учётной записи.
Чтобы не перепечатывать текст с бумаги, я использую специальные сервисы — они сканируют информацию и извлекают содержимое в текстовый редактор.
Сервисы неидеальны: какие-то слова не распознают вообще, какие-то определяют как набор букв с пробелами. Но отредактировать результат все равно быстрее, чем перепечатывать все с нуля.
Я сравнил работу 5 таких программ на двух образцах текста. Текст взял одинаковый, только в первом случае он четко выделяется на отсканированном документе, а во втором — еле виден на фотографии.
В образце я сделал пять наборов слов для распознаванияFineReader
Где работает: в онлайне, Windows, Android, iOS
Сколько стоит: от 3190 Р в год
Демодоступ: бесплатно распознает 10 страниц, после — 5 страниц в месяц
Что умеет. Бесплатная версия даст загрузить файлы в онлайн-версию или распознать фото в мобильном приложении. Умеет выгружать текст в «Блокнот», Word, Excel и в форматы электронных книг: FB2 или ePUB. Результаты будут доступны в течение двух недель.
За деньги сервис сможет распознавать PDF-файлы — от 2000 страниц в год.
FineReader предлагает выбрать, какой язык требуется расшифроватьСколько слов определил. Фотографию плохого качества не смог распознать вообще, трижды выдал ошибку. Скан хорошего качества распознал полностью, включая знаки препинания.
Как победить выгорание
Курс для тех, кто много работает и устает. Цена открыта — назначаете ее самиOffice Lens
Где работает: Android, iOS. С 2021 года официального приложения на Windows больше нет, Microsoft поддерживает только мобильные решения
Сколько стоит: бесплатно
Что умеет. Сервис превращает камеру смартфона в сканер. Можно преобразовать изображения в файлы DOC и PPT, сохранить их в OneNote или конвертировать в PDF, обрезать снимки, увеличить или уменьшить их яркость. Еще сервис частично распознает рукописный текст.
Формы для загрузки файлов в приложении нет. Но можно сначала сбросить картинку в телефон, а после загрузить ее в Lens из галереи.
Сколько слов определил. Со сканом хорошего качества Lens справился практически идеально — один раз не определил заглавную букву и вместо знака «№» написал «NQ».
С фотографией плохого качества сервис справился хуже: превратил два элемента списка в один, часть слов записал заглавными буквами, добавил дефисы. Результат можно редактировать, но придется потратить на это время.
CamScanner
Что умеет. Можно сканировать текст с помощью камеры или загружать готовые картинки. Приложение повысит резкость и яркость у снимков плохого качества. Есть автоматическое выравнивание — итоговый файл будет выглядеть так, будто вы не фотографировали, а положили документ в сканер.
Без регистрации дадут распознать два текста, после — три в месяц. За деньги — тысячу в месяц, плюс снимки будут храниться в облачном пространстве сервиса. Бесплатно доступно только 200 Мб.
Интерфейс у приложения минималистичный, без лишних кнопокСколько слов определил. Файл в хорошем качестве CamScanner распознал без ошибок. Плохую фотографию придется редактировать, но немного: не расшифровал знак «№», добавил пару лишних букв и поставил лишнюю точку в конце.
Online OCR
Где работает: в онлайне
Сколько стоит: бесплатно
Что умеет. Сервис распознает текст из PDF-сканов и изображений — для этого даже не нужно создавать аккаунт. После регистрации можно распознавать PDF-файлы объемом больше 15 страниц и изображения в ZIP-архивах.
Когда будете распознавать текст, выберите нужный язык, иначе будут ошибкиСколько слов определил. Хорошее качество распознал почти без ошибок — лишний пробел в начале и ошибка в знаке вопроса. В снимке плохого качества сервис сделал четыре ошибки, из них две критические — когда слово совсем непонятно. Но в остальном все отлично, поэтому редактировать придется недолго.
Этот сервис единственный из всех распознал еще и фон с картинкиGo4convert
Где работает: в онлайне
Сколько стоит: бесплатно
Что умеет. Распознает текст со сканов и картинок, включая редкий формат BMP. Результат предлагает скачать только в «Блокнот» в формате TXT.
Этот онлайн-сервис умеет распознавать текст с картинки в интернетеСколько слов определил. Файл хорошего качества распознал с одной ошибкой — превратил знак вопроса в английскую N. Из файла с плохим качеством практически без ошибок вытащил только список. Четыре слова превратил в беспорядочный набор букв, а фон — в набор символов.

Файлы с незнакомыми расширениями встречаются не каждый день. Однако бывают ситуации, когда именно их очень нужно открыть. CHIP расскажет, как определить формат данных, и предоставит необходимые приложения для работы с ними.

Каждому файлу — своя программа
Определить тип файла можно просто по его расширению, после чего станет понятно и его предназначение.
Заставляем систему отображать расширения
Выбираем приложение
Чтобы увидеть, какая программа будет обрабатывать файл по умолчанию, нужно кликнуть по нему правой кнопкой мыши и выбрать в контекстном меню пункт «Свойства». В открывшемся окне на вкладке «Общие» вы увидите тип файла и его расширение, а также утилиту, которая назначена ответственной за открытие данных в таком формате. Если нужно другое приложение, кликните по «Изменить». Откроется список рекомендуемых программ. Если ни одна из них вас не устраивает, нажмите кнопку «Обзор», в появившемся окне зайдите в папку, соответствующую нужной утилите, и кликните по исполняемому файлу. Как правило, это имя приложения с расширением EXE.
Определяем тип файла
Конвертируем в нужный формат
В некоторых случаях решить проблему с открытием файла помогает его преобразование в другой, более распространенный формат. Сделать это можно с помощью специальных программ-конвертеров.
Векторные изображения
С помощью универсального бесплатного инструмента UniConvertor вы можете преобразовывать файлы из одного векторного формата в другой. В плане импорта программа поддерживает такие расширения, как CDR, CDT, CCX, CDRX, CMX (CorelDRAW), AI, EPS, PLT, DXF, SVG и другие. Экспорт осуществляется в форматы AI, SVG, SK, SK1, CGM, WMF, PDF, PS. Утилита доступна в версиях для Windows и Linux.
Растровая графика
Программа Free Image Convert and Resize занимает мало места на жестком диске, но предлагает функции по конвертированию и преобразованию растровых изображений, в том числе в пакетном режиме. Поддерживаются следующие форматы файлов: JPEG, PNG, BMP, GIF, TGA, PDF (последний — только для экспорта).
Видеофайлы
Мощный бесплатный инструмент Hamster Video Converter обеспечивает преобразование видеофайлов из одного формата в другой. Поддерживается конвертирование в 3GP, MP3, MP4, AVI, MPG, WMV, MPEG, FLV, HD, DVD, M2TS и т. д. Доступна пакетная обработка.
Аудиоданные
Бесплатная программа Hamster Free Audio Converter от того же производителя предлагает конвертирование аудио между форматами AIFF, OGG, WMA, MP3, MP2, AC3, AMR, FLAC, WAV, ACC, COV, RM. На сайте производителя также имеются преобразователи архивных форматов и электронных книг.
Используем онлайн-сервисы
Не всегда есть возможность установить программу-конвертер на ПК — в этом случае помогут интернет-ресурсы для преобразования документов.
Zamzar
FreePDFconvert
Бесплатная утилита UniConvertor поможет быстро преобразовывать файлы векторных форматов в пакетном режиме Free Image Convert and Resize наделена простейшими функциями конвертирования и изменения размера изображений Для конвертации видео- и аудиофайлов удобно использовать программы Hamster со встроенными кодеками и набором пресетов Онлайн-ресурсы Zamzar (верхний скриншот) и FreePDFConvert — универсальные конвертеры с ограничением по объему
Просмотр любого файла
Программы-просмотрщики зачастую не позволяют работать с файлом полноценно — например, редактировать его. Но с их помощью вы сможете открыть файл и посмотреть на его содержимое.

Программа ICE Book Reader Professional является универсальным инструментом для чтения файлов электронных книг и различного рода текстовых документов, к которым относятся DOC, TXT, HTML, PDF и многие другие.
Бесплатная утилита Free Viewer открывает файлы разных форматов, отображая дополнительно окно с информацией. С ее помощью можно точно узнать, какая программа необходима для открытия того или иного файла. Кроме того, в приложении имеется встроенный конвертер, и оно позволяет установить ассоциацию для файлов на уровне ОС.

Небольшая бесплатная программа XnView послужит удобным просмотрщиком графических файлов. К тому же в ней можно выполнять элементарные операции редактирования картинок (вставка надписи, поворот, применение эффектов). Всего утилита поддерживает более 400 различных расширений и позволяет конвертировать их более чем в 50 форматов. Среди дополнительных возможностей программы — работа со сканером, создание скриншотов, запись рисунков на компакт-диск.

Если данные повреждены
Онлайн-справочники типов файлов
Прочесть о типах файлов и разобраться в их многообразии можно на специализированных онлайн-ресурсах.

Возможно ли изменение сканированного текста? Можно ли отредактировать сканированный текст, чтобы потом использовать его с другими целями? Да, дорогие друзья! Сегодня это не только возможно, но и вполне легко делается.
При наличии необходимости, желания, а также некоторых технических возможностей вам легко дастся:
- сканирование рукописного текста (например, конспекта),
- сканирование текста с фотографии или картинки,
- редактирование,
- распознавание текста после сканирования,
- преобразование текста в виде картинки в обычный текст, в котором вы можете изменить сканированный текст (например, в документе pdf) документа и др.
В общем, сделать с текстом на картинке сегодня можно все то же самое, что и с обычным текстом в вордовском документе. А делать это жизненно важно и полезно тем, кто постоянно имеет дела с многочисленной документацией и тратит много времени – то есть и для студентов в том числе. Давайте разбираться, как это делается.
Чем отличается сканирование от распознавания?
Как оказалось, сканирование и распознавание текста – это разные вещи. Сканирование листов документа – это его перевод текста в электронный вид. Делается это через сканер или при помощи обычного фотографирования на смартфон или цифровую камеру.
Распознавание – это преобразование сканированного документа (текста) в электронный вид.
Что нам понадобится для сканирования и распознавания текста по фото ?
Для сканирования и распознавания текста нам не обойтись без кое-каких вещей:
- Сканер. Собственно, роль сканера может выполнять не только этот вид техники, но и фотоаппарат (в смартфоне, например). Если вы пользуетесь сканером, убедитесь, что на компьютере установлены системные драйвера и программы, необходимые для его полноценной работы. Если сканера нет, но вы собираетесь его купить, обратите внимание на скорость обработки одного листа. Некоторые приборы обрабатывают лист за 10 секунд, другим для этого понадобится 30 и более. И если работать вам придется с объемными материалами по 300-400 листов, то этот фактор имеет значение.
- Программы для распознавания текста или онлайн-сервисы. Мы уже писали статью по сервисам, которые помогают распознать текст после сканирования документа через сканер. Но сейчас хотели бы посоветовать вам программу ABBYY FineReader. Несмотря на то, что она платная, ее функционал поистине впечатляет. И если вы будете работать с огромными объемами документов, она станет вашим незаменимым помощником. Впрочем, есть и бесплатный ее аналог Cunei Form, которая отлично справляется со сканированием и распознаванием текста онлайн. Правда, ее функционал сильно ограничен по сравнению с предыдущим собратом.
- Документы для сканирования. Студентам часто приходиться сталкиваться со сканированием документа в виде журналов, статей, книг, конспектов, распечаток, откуда потом зачастую нужно скопировать текст. И просто так, в виде совета – перед началом сканирования постарайтесь поискать эти документы в сети. Если до вас этими материалами уже пользовались, существует огромная вероятность, что добрый человек уже проделал всю работу за вас. Атк что вам останется только скопировать текст готового сканированного документа и заняться редактированием текста после сканирования.
Параметры сканирования текста
Итак, сканер купили, документы подготовили, программы установили. Что дальше? Дальше нам нужно будет сделать нужные настройки, которые тоже порой помогают существенно облегчить задачу, например, распознать сканированный текст в определенном формате, редактировать текст после сканирования в определенном режиме и так далее.
В общем, от настроек будет зависеть качество и скорость вашей работы. Итак, разбираемся вместе.
DPI-качество
Это разрешение изображения, которое будет важно при редактировании текста в сканированном документе. Ставьте в настройках качество не меньше 300 DPI, а если возможно - то больше. Чем выше эта величина, тем более четким получится изображение после сканирования.
Цветность
Благодаря этому параметру можно влиять на скорость сканирования текста. Как правило, в сканерах есть 3 режима: черно-белый (подходит для листов с обычным печатным текстом), серый (подходит для работы с документами с таблицами и простыми картинками), цветной (для журналов, книг и остальных документов, где цвет играет значение). Чем меньше цвета, тем выше скорость обработки документа.
Фото
Для сканирования можно использовать не только сканер, но и фотографирование. Но здесь будьте осторожны – любое смазывание, нечеткость и прочие искажения изображения могут повлиять на дальнейшее распознавание и редактирование текста в сканированном документе.
Распознавание
Итак, отсканировали и получили странички в электронном виде. Затем открываем программу для распознавания (например, FineReader) и начинаем распознавать текст. Некоторые программы (в том числе и наша) делают этот процесс с ошибками. Тогда область с ошибкой нужно будет выделять вручную.
Работа с текстом
В области Текст можно будет выделить текст. Любые таблицы и изображения можно будет удалить. А вот для работы с необычными и редкими символами придется поработать ручками. Вот как это выглядит в программе:

Картинки
Эта область в программе используется для работы с изображениями и с теми областями текста, которые плохо поддались распознаванию.

Таблицы
Кнопка выделения таблиц помогает работать с таблицами. Однако эта функция не очень хорошо развита. Иногда проще использовать редактор Картинка для работы с таблицами. Это сэкономит кучу времени и нервов, а доработать все потом можно в обычном ворде.

Лишние элементы
Если на странице остались элементы, которые вам совершенно не нужны или бесполезны, выделите ненужную область и удалите ее с помощью ластика. Достаточно перейти в режим редактирования и провести работу. Причем чем больше ненужных элементов вы уберете, тем быстрее будет происходить процесс распознавания текста.
Проверка ошибок и сохранение результатов работы
Как мы уже говорили, ошибки могут возникать тогда, когда вы используете некачественные, смазанные, нечеткие изображения или документы с редкими символами. Поэтому всегда проверяйте документ после процесса распознавания.
Нашли? Замечательно – просто введите нужный символ. Кстати, в программе есть режим проверки, который поможет быстро и без вашего участия проверить документ на наличие ошибок программы. И сразу же после окончания проверки можете прямо из программы импортировать документ (сохранить его в формате) в ворд или любую другую программу.

Тип копии
При сохранении документа (в режиме редактирования) вам предложат сохранить его в трех видах копии. Точная копия – это полная копия сканированного документа со всем произведенным форматированием. Если вы потом планируете редактировать текст после сканирования в ворде, то лучше всего выбрать именно этот вариант.
Редактируемая копия помогает сохранить уже отредактированный текст. Хорошо подходит, если вам предстоит обильное последующее редактирование.
Простой текст – идеально подходит для тех, кто хочет получить в итоге обычный текст без всех остальных элементов страницы.
Читайте также: