Дисковые подсистемы серверных компьютеров подключение конфигурирование повышение отказоустойчивости
Обновлено: 07.07.2024
Характеристики дисковых систем для отказоустойчивого кластера:
· Дисковые системы хостов Hyper-V должны обеспечивать максимально возможную производительность
· Отдельный логический том для хранения служебной информации кластера Windows Failover Cluster Service;
· Балансировку нагрузки по путям к дисковым группам к каждой дисковой группе и логическому тому с данными;
· Отказоустойчивую конфигурацию дисковой подсистемы по управляющим, коммуникационным компонентам и по физическим шпинделям (HDD Drive);
· Обеспечить соответствующую дисковую ёмкость, свободное пространство для функционалов требуемой программной части.
· Обеспечить зеркалирование каждого тома серверов за счёт введения RAID
Отказоустойчивый кластер должен использовать две независимые сети для различных типов взаимодействия компонентов.
Частная сеть - для служебного взаимодействия узлов и подсистем кластера отказоустойчивой системы управления базами данных.
Публичная сеть - для взаимодействия системы с внешними потребителями сервисов.
Сетевая инфраструктура должна обеспечивать минимальные задержки и максимальную пропускную способность для каждой из сетей.
Публичная сеть кластера систем управления должна отвечать следующим требованиям:
· Маршрутизируемая, доступная IP подсеть для потребителей сервиса;
· Отказоустойчивое подключение к сетевой инфраструктуре каждого из узлов кластера, в случае выхода из строй физического интерфейса или линка узла кластера, сетевая связанность не нарушается;
· Производительность сетевых интерфейсов не менее 1 Гб/с;
Частная сеть кластера систем управления базами данных должна отвечать следующим требованиям:
Не маршрутизируемая, не доступная извне кластера IP подсеть;
Отдельная виртуальная подсеть только для служебного трафика (VLAN).
Проектируемая система должна обеспечивать следующие показатели по надёжности:
· Доступность системы 24/7/365;
· Техническое окно по обслуживанию системы - не более 24 часов в год;
· В случае аппаратного сбоя одного из компонентов системы, продолжить выполнять свои функции.
Система управления базами данных должна обеспечивать следующие показатели по отказоустойчивости, предоставление сервисов потребителям в случае:
· Выхода из строя одного из узлов кластера;
· Выхода из строя одного из сетевых интерфейсов узлов кластера;
· Выхода из строя одного из коммутаторов сетевой инфраструктуры;
· Выхода из строя одного из предпочитаемых путей к системе хранения данных;
Одной из целей концепции RAID была возможность обнаружения и коррекции ошибок, возникающих при отказах дисков или в результате сбоев. Достигается это за счет избыточного дискового пространства, которое задействуется для хранения дополнительной информации, позволяющей восстановить искаженные или утерянные данные. В RAID предусмотрены три вида такой информации:
Первый из вариантов заключается в дублировании всех данных, при условии, что экземпляры одних и тех же данных расположены на разных дисках массива. Это позволяет при отказе одного из дисков воспользоваться соответствующей информацией, хранящейся на исправных МД. В принципе распределение информации по дискам массива может быть произвольным, но для сокращения издержек, связанных с поиском копии, обычно применяется разбиение массива на пары МД, где в каждой паре дисков информация идентична и одинаково расположена. При таком дублировании для управления парой дисков может использоваться общий или раздельные контроллеры. Избыточность дискового массива здесь составляет 100%.
Второй способ формирования корректирующей информации основан на вычислении кода Хэмминга для каждой группы полос, одинаково расположенных на всех дисках массива (пояса). Корректирующие биты хранятся на специально выделенных для этой цели дополнительных дисках (по одному диску на каждый бит). Так, для массива из десяти МД требуются четыре таких дополнительных диска, и избыточность в данном случае близка к 30%.
В третьем случае вместо кода Хэмминга для каждого набора полос, расположенных в идентичной позиции на всех дисках массива, вычисляется контрольная полоса, состоящая из битов паритета. В ней значение отдельного бита формируется как сумма по модулю два для одноименных битов во всех контролируемых полосах. Для хранения полос паритета требуется только один дополнительный диск. В случае отказа какого-либо из дисков массива производится обращение к диску паритета, и данные восстанавливаются по битам паритета и данным от остальных дисков массива. Реконструкция данных достаточно проста. Рассмотрим массив из пяти дисковых ЗУ, где диски Х0–Х3 содержат данные, а Х4 – это диск паритета. Паритет для i-го бита вычисляется как
Предположим, что дисковод Х1 отказал. Если мы добавим , к обеим частям предыдущего выражения, то получим:
Таким образом, содержимое каждой полосы данных на любом диске массива может быть восстановлено по содержимому соответствующих полос на остальных дисках массива. Избыточность при таком способе в среднем близка к 20%.
RAID уровня 0
RAID уровня 0, строго говоря, не является полноценным членом семейства RAID, поскольку данная схема не содержит избыточности и нацелена только на повышение производительности в ущерб надежности.
В основе RAID 0 лежит расслоение данных. Полосы распределены по всем дискам массива дисковых ЗУ по циклической схеме (рис. 75). Преимущество такого распределения в том, что если требуется записать или прочитать логически последовательные полосы, то несколько таких полос (вплоть до n) могут обрабатываться параллельно, за счет чего существенно снижается общее время ввода/вывода. Ширина полос в RAID 0 варьируется в зависимости от применения, но в любом случае она не менее размера физического сектора МД.
Рис. 75. RAID уровня 0.
RAID 0 обеспечивает наиболее эффективное использование дискового пространства и максимальную производительность дисковой подсистемы при минимальных затратах и простоте реализации. Недостатком является незащищенность данных — отказ одного из дисков ведет к разрушению целостности данных во всем массиве. Тем не менее, существует ряд приложений, где производительность и емкость дисковой системы намного важнее возможного снижения надежности. К таким можно отнести задачи, оперирующие большими файлами данных, в основном в режиме считывания информации (библиотеки изображений, большие таблицы и т. п.), и где загрузка информации в основную память должна производиться как можно быстрее. Учитывая отсутствие в RAID 0 средств по защите данных, желательно хранить дубликаты файлов на другом, более надежном носителе информации, например на магнитной ленте.
RAID уровня 1
В RAID 1 избыточность достигается с помощью дублирования данных. В принципе исходные данные и их копии могут размещаться по дисковому массиву произвольно, главное чтобы они находились на разных дисках. В плане быстродействия и простоты реализации выгоднее, когда данные и копии располагаются идентично на одинаковых дисках. Рисунок 76 показывает, что, как и в RAID 0, здесь имеет место разбиение данных на полосы. Однако в этом случае каждая логическая полоса отображается на два отдельных физических диска, так что каждый диск в массиве имеет так называемый «зеркальный» диск, содержащий идентичные данные. Для управления каждой парой дисков может быть использован общий контроллер, тогда данные сначала записываются на основной диск, а затем — на «зеркальный» («зеркалирование»). Более эффективно применение самостоятельных контроллеров для каждого диска, что позволяет производить одновременную запись на оба диска.
Рис. 76. RAID уровня 1.
Запрос на чтение может быть обслужен тем из двух дисков, которому в данный момент требуется меньшее время поиска и меньшая задержка вращения. Запрос на запись требует, чтобы были обновлены обе соответствующие полосы, но это выполнимо и параллельно, причем задержка определяется тем диском, которому нужны большие время поиска и задержка вращения. В то же время у RAID 1 нет дополнительных затрат времени на вычисление вспомогательной корректирующей информации. Когда одно дисковое ЗУ отказывает, данные могут быть просто взяты со второго.
Принципиальный изъян RAID 1 — высокая стоимость: требуется вдвое больше физического дискового пространства. По этой причине использование RAID 1 обычно ограничивают хранением загрузочных разделов, системного программного обеспечения и данных, а также других особенно критичных файлов: RAID 1 обеспечивает резервное копирование всех данных, так что в случае отказа диска критическая информация доступна практически немедленно.
RAID уровня 2
В системах RAID 2 используется техника параллельного доступа, где в выполнении каждого запроса на В/ВЫВ одновременно участвуют все диски. Обычно шпиндели всех дисков синхронизированы так, что головки каждого ЗУ в каждый момент времени находятся в одинаковых позициях. Данные разбиваются на полосы длиной в 1 бит и распределены по дискам массива таким образом, что полное машинное слово представляется поясом, то есть число дисков равно длине машинного слова в битах. Для каждого слова вычисляется корректирующий код (обычно это код Хэмминга, способный корректировать одиночные и обнаруживать двойные ошибки), который, также побитово, хранится на дополнительных дисках (рис. 77). Например, для массива, ориентированного на 32-разрядные слова (32 основных диска) требуется семь дополнительных дисковых ЗУ (корректирующий код состоит из 7 разрядов).
RAID 2 позволяет достичь высокой скорости В/ВЫВ при работе с большими последовательными записями, но становится неэффективным при обслуживании записей небольшой длины. Основное преимущество RAID 2 состоит в высокой степени защиты информации, однако предлагаемый в этой схеме метод коррекции уже встроен в каждое из современных дисковых ЗУ.
Рис. 77. RAID уровня 2.
Корректирующие разряды вычисляются для каждого сектора диска и хранятся в соответствующем поле этих секторов. В таких условиях использование нескольких избыточных дисков представляется неэффективным, и массивы уровня RAID 2 в настоящее время не выпускаются.
RAID уровня 3
RAID 3 организован сходно с RAID2. Отличие в том, что RAID 3 требует только одного дополнительного диска — диска паритета, вне зависимости от того, насколько велик массив дисков (рис. 78). В RAID 3 используется параллельный доступ к данным, разбитым на полосы длиной в бит или байт. Все диски массива синхронизированы. Вместо кода Хэмминга для набора полос идентичной позиции на всех дисках массива (пояса) вычисляется полоса, состоящая из битов паритета. В случае отказа дискового ЗУ производится обращение к диску паритета, и данные восстанавливаются по битам паритета и данным от остальных дисков массива.
Рис. 78. RAID уровня 3.
Так как данные разбиты на очень маленькие полосы, RAID 3 позволяет достигать очень высоких скоростей передачи данных. Каждый запрос на ввод/вывод приводит к параллельной передаче данных со всех дисков. Для приложений, связанных с большими пересылками данных, это обстоятельство очень существенно. С другой стороны, параллельное обслуживание одиночных запросов невозможно, и производительность дисковой подсистемы в этом случае падает.
Ввиду того что для хранения избыточной информации нужен всего один диск, причем независимо от их числа в массиве, именно уровню RAID 3 отдается предпочтение перед RAID 2.
RAID уровня 4
По своей идее и технике формирования избыточной информации RAID 4 идентичен RAID 3, только размер полос в RAID 4 значительно больше (обычно один-два физических блока на диске). Главное отличие состоит в том, что в RAID 4 используется техника независимого доступа, когда каждое ЗУ массива в состоянии функционировать независимо, так, что отдельные запросы на ввод/вывод могут удовлетворяться параллельно (рис. 79).
Рис. 79. RAID уровня 4.
Для RAID 4 характерны издержки, обусловленные независимостью дисков. Если в RAID 3 запись производилась одновременно для всех полос одного пояса, в RAID 4 осуществляется запись полос в разные пояса. Это различие ощущается особенно при записи данных малого размера.
Каждый раз для выполнения записи программное обеспечение дискового массива должно обновить не только данные пользователя, но и соответствующие биты паритета. Рассмотрим массив из пяти дисковых ЗУ, где ЗУ X0 . ХЗ содержат данные, а Х4 — диск паритета. Положим, что производится запись, охватывающая только полосу на диске Х1. Первоначально для каждого бита iмы имеем следующее соотношение:
После обновления для потенциально измененных битов, обозначаемых с помощью апострофа, получаем:
Для вычисления новой полосы паритета программное обеспечение управления массивом должно прочитать старую полосу пользователя и старую полосу паритета. Затем оно может заменить эти две полосы новой полосой данных и новой вычисленной полосой паритета. Таким образом, запись каждой полосы связана с двумя операциями чтения и двумя операциями записи.
В случае записи большого объема информации, охватывающего полосы на всех дисках, паритет вычисляется достаточно легко путем расчета, в котором участвуют только новые биты данных, то есть содержимое диска Паритета может быть обновлено параллельно с дисками данных и не требует дополнительных операций чтения и записи.
Массивы RAID 4 наиболее подходят для приложений, требующих поддержки высокого темпа поступления запросов ввода/вывода, и уступает RAID 3 там, где приоритетен большой объем пересылок данных.
RAID уровня 5
RAID 5 имеет структуру, напоминающую RAID 4. Различие заключается в том, что RAID 5 не содержит отдельного диска для хранения полос паритета, а разносит их по всем дискам. Типичное распределение осуществляется по циклической схеме, как это показано на рис. 80. В n-дисковом массиве полоса паритета вычисляется для полос п-1 дисков, расположенных в одном поясе, и хранится в том же поясе, но на диске, который не учитывался при вычислении паритета. При переходе от одного пояса к другому эта схема циклически повторяется.
Рис. 80. RAID уровня 5.
Распределение полос паритета по всем дискам предотвращает возникновение проблемы, упоминавшейся для RAID 4.
RAID уровня 6
RAID 6 очень похож на RAID 5. Данные также разбиваются на полосы размером в блок и распределяются по всем дискам массива. Аналогично, полосы паритета распределены по разным дискам. Доступ к полосам независимый и асинхронный. Различие состоит в том, что на каждом диске хранится не одна, а две полосы паритета. Первая из них, как и в RAID 5, содержит контрольную информацию для полос, расположенных на горизонтальном срезе массива (за исключением диска, где эта полоса паритета хранится). В дополнение формируется и записывается вторая полоса паритета, контролирующая все полосы какого-то одного диска массива (вертикальный срез массива), но только не того, где хранится полоса паритета. Сказанное иллюстрируется рис. 81.
Рис. 81. RAID уровня 6.
Такая схема массива позволяет восстановить информацию при отказе сразу двух дисков. С другой стороны, увеличивается время на вычисление и запись паритетной информации и требуется дополнительное дисковое пространство. Кроме того, реализация данной схемы связана с усложнением контроллера дискового массива. В силу этих причин, схема среди выпускаемых RAID-систем встречается крайне редко.
RAID уровня 7
Схема RAID 7, запатентованная Storage Computer Corporation, объединяет массив асинхронно работающих дисков и кэш-память, управляемые встроенной в кон троллер массива операционной системой реального времени (рис. 82). Данные разбиты на полосы размером в блок и распределены по дискам массива. Полосы паритета хранятся на специально выделенных для этой цели одном или нескольких дисках.
Схема некритична к виду решаемых задач и при работе с большими файлами не уступает по производительности RAID 3. Вместе с тем RAID 7 может так же эффективно, как и RAID 5, производить одновременно несколько операций чтения и записи для небольших объемов данных. Все это обеспечивается использованием кэш-памяти и собственной операционной системой.
Рис. 82. RAID уровня 7.
RAID уровня 10
Данная схема совпадает с RAID 0, но в отличие от нее роль отдельных дисков выполняют дисковые массивы, построенные по схеме RAID 1 (рис. 83).
Таким образом, в RAID 10 сочетаются расслоение и дублирование. Это позволяет добиться высокой производительности, характерной для RAID 0 при уровне отказоустойчивости RAID 1. Основной недостаток схемы — высокая стоимость ее реализации. Кроме того, необходимость синхронизации всех дисков приводит к усложнению контроллера.
Рис. 83. RAID уровня 10.
RAID уровня 53
В этом уровне сочетаются технологии RAID 0 и RAID 3, поэтому его правильнее было бы назвать RAID 30. В целом данная схема соответствует RAID 0, где роль отдельных дисков выполняют дисковые массивы, организованные по схеме RAID 3. Естественно, что в RAID 53 сочетаются все достоинства RAID 0 и RAID 3. Недостатки схемы такие же, что и у RAID 10.

Есть разновидности бизнеса, где перерывы в предоставлении сервиса недопустимы. Например, если у сотового оператора из-за поломки сервера остановится биллинговая система, абоненты останутся без связи. От осознания возможных последствий этого события возникает резонное желание подстраховаться.
Мы расскажем какие есть способы защиты от сбоев серверов и какие архитектуры используют при внедрении VMmanager Cloud: продукта, который предназначен для создания кластера высокой доступности.
В области защиты от сбоев на кластерах терминология в Интернете различается от сайта к сайту. Для того чтобы избежать путаницы, мы обозначим термины и определения, которые будут использоваться в этой статье.
- Отказоустойчивость (Fault Tolerance, FT) — способность системы к дальнейшей работе после выхода из строя какого-либо её элемента.
- Кластер — группа серверов (вычислительных единиц), объединенных каналами связи.
- Отказоустойчивый кластер (Fault Tolerant Cluster, FTC) — кластер, отказ сервера в котором не приводит к полной неработоспособности всего кластера. Задачи вышедшей из строя машины распределяются между одной или несколькими оставшимися нодами в автоматическом режиме.
- Непрерывная доступность (Continuous Availability, CA) — пользователь может в любой момент воспользоваться сервисом, перерывов в предоставлении не происходит. Сколько времени прошло с момента отказа узла не имеет значения.
- Высокая доступность (High Availability, HA) — в случае выхода из строя узла пользователь какое-то время не будет получать услугу, однако восстановление системы произойдёт автоматически; время простоя минимизируется.
- КНД — кластер непрерывной доступности, CA-кластер.
- КВД — кластер высокой доступности, HA-кластер.
На первый взгляд самый привлекательный вариант для бизнеса тот, когда в случае сбоя обслуживание пользователей не прерывается, то есть кластер непрерывной доступности. Без КНД никак не обойтись как минимум в задачах уже упомянутого биллинга абонентов и при автоматизации непрерывных производственных процессов. Однако наряду с положительными чертами такого подхода есть и “подводные камни”. О них следующий раздел статьи.
Бесперебойное обслуживание клиента возможно только в случае наличия в любой момент времени точной копии сервера (физического или виртуального), на котором запущен сервис. Если создавать копию уже после отказа оборудования, то на это потребуется время, а значит, будет перебой в предоставлении услуги. Кроме этого, после поломки невозможно будет получить содержимое оперативной памяти с проблемной машины, а значит находившаяся там информация будет потеряна.
Для реализации CA существует два способа: аппаратный и программный. Расскажем о каждом из них чуть подробнее.
Аппаратный способ представляет собой “раздвоенный” сервер: все компоненты дублированы, а вычисления выполняются одновременно и независимо. За синхронность отвечает узел, который в числе прочего сверяет результаты с половинок. В случае несоответствия выполняется поиск причины и попытка коррекции ошибки. Если ошибка не корректируется, то неисправный модуль отключается.
На Хабре недавно была статья на тему аппаратных CA-серверов. Описываемый в материале производитель гарантирует, что годовое время простоя не более 32 секунд. Так вот, для того чтобы добиться таких результатов, надо приобрести оборудование. Российский партнёр компании Stratus сообщил, что стоимость CA-сервера с двумя процессорами на каждый синхронизированный модуль составляет порядка $160 000 в зависимости от комплектации. Итого на кластер потребуется $1 600 000.
Программный способ.
На момент написания статьи самый популярный инструмент для развёртывания кластера непрерывной доступности — vSphere от VMware. Технология обеспечения Continuous Availability в этом продукте имеет название “Fault Tolerance”.
В отличие от аппаратного способа данный вариант имеет ограничения в использовании. Перечислим основные:
- На физическом хосте должен быть процессор:
- Intel архитектуры Sandy Bridge (или новее). Avoton не поддерживается.
- AMD Bulldozer (или новее).
Лицензирование vSphere привязано к физическим процессорам. Цена начинается с $1750 за лицензию + $550 за годовую подписку и техподдержку. Также для автоматизации управления кластером требуется приобрести VMware vCenter Server, который стоит от $8000. Поскольку для обеспечения непрерывной доступности используется схема 2N, для того чтобы работали 10 нод с виртуальными машинами, нужно дополнительно приобрести 10 дублирующих серверов и лицензии к ним. Итого стоимость программной части кластера составит 2 *(10 +10 )*(1750 +550 )+8000 =$100 000.
Мы не стали расписывать конкретные конфигурации нод: состав комплектующих в серверах всегда зависит от задач кластера. Сетевое оборудование описывать также смысла не имеет: во всех случаях набор будет одинаковым. Поэтому в данной статье мы решили считать только то, что точно будет различаться: стоимость лицензий.
Стоит упомянуть и о тех продуктах, разработка которых остановилась.
Есть Remus на базе Xen, бесплатное решение с открытым исходным кодом. Проект использует технологию микроснэпшотов. К сожалению, документация давно не обновлялась; например, установка описана для Ubuntu 12.10, поддержка которой прекращена в 2014 году. И как ни странно, даже Гугл не нашёл ни одной компании, применившей Remus в своей деятельности.
Предпринимались попытки доработки QEMU с целью добавить возможность создания continuous availability кластера. На момент написания статьи существует два таких проекта.
Первый — Kemari, продукт с открытым исходным кодом, которым руководит Yoshiaki Tamura. Предполагается использовать механизмы живой миграции QEMU. Однако тот факт, что последний коммит был сделан в феврале 2011 года говорит о том, что скорее всего разработка зашла в тупик и не возобновится.
Второй — Micro Checkpointing, основанный Michael Hines, тоже open source. К сожалению, уже год в репозитории нет никакой активности. Похоже, что ситуация сложилась аналогично проекту Kemari.
Таким образом, реализации continuous availability на базе виртуализации KVM в данный момент нет.
Итак, практика показывает, что несмотря на преимущества систем непрерывной доступности, есть немало трудностей при внедрении и эксплуатации таких решений. Однако существуют ситуации, когда отказоустойчивость требуется, но нет жёстких требований к непрерывности сервиса. В таких случаях можно применить кластеры высокой доступности, КВД.
В контексте КВД отказоустойчивость обеспечивается за счёт автоматического определения отказа оборудования и последующего запуска сервиса на исправном узле кластера.
В КВД не выполняется синхронизация запущенных на нодах процессов и не всегда выполняется синхронизация локальных дисков машин. Стало быть, использующиеся узлами носители должны быть на отдельном независимом хранилище, например, на сетевом хранилище данных. Причина очевидна: в случае отказа ноды пропадёт связь с ней, а значит, не будет возможности получить доступ к информации на её накопителе. Естественно, что СХД тоже должно быть отказоустойчивым, иначе КВД не получится по определению.
Таким образом, кластер высокой доступности делится на два подкластера:
- Вычислительный. К нему относятся ноды, на которых непосредственно запущены виртуальные машины
- Кластер хранилища. Тут находятся диски, которые используются нодами вычислительного подкластера.
- Heartbeat версии 1.х в связке с DRBD;
- Pacemaker;
- VMware vSphere;
- Proxmox VE;
- XenServer;
- Openstack;
- oVirt;
- Red Hat Enterprise Virtualization;
- Windows Server Failover Clustering в связке с серверной ролью “Hyper-V”;
- VMmanager Cloud.
Наше решение VMmanager Cloud использует виртуализацию QEMU-KVM. Мы сделали выбор в пользу этой технологии, поскольку она активно разрабатывается и поддерживается, а также позволяет установить любую операционную систему на виртуальную машину. В качестве инструмента для выявления отказов в кластере используется Corosync. Если выходит из строя один из серверов, VMmanager поочерёдно распределяет работавшие на нём виртуальные машины по оставшимся нодам.
В упрощённой форме алгоритм такой:
- Происходит поиск узла кластера с наименьшим количеством виртуальных машин.
- Выполняется запрос хватает ли свободной оперативной памяти для размещения текущей ВМ в списке.
- Если памяти для распределяемой машины достаточно, то VMmanager отдаёт команду на создание виртуальной машины на этом узле.
- Если памяти не хватает, то выполняется поиск на серверах, которые несут на себе большее количество виртуальных машин.
Практика показывает, что лучше выделить одну или несколько нод под аварийные ситуации и не развёртывать на них ВМ в период штатной работы. Такой подход исключает ситуацию, когда на “живых” нодах в кластере не хватает ресурсов, чтобы разместить все виртуальные машины с “умершей”. В случае с одним запасным сервером схема резервирования носит название “N+1”.
VMmanager Cloud поддерживает следующие типы хранилищ: файловая система, LVM, Network LVM, iSCSI и Ceph . В контексте КВД используются последние три.
При использовании вечной лицензии стоимость программной части кластера из десяти “боевых” узлов и одного резервного составит €3520 или $3865 на сегодняшний день (лицензия стоит €320 за ноду независимо от количества процессоров на ней). В лицензию входит год бесплатных обновлений, а со второго года они будут предоставляться в рамках пакета обновлений стоимостью €880 в год за весь кластер.
Рассмотрим по каким схемам пользователи VMmanager Cloud реализовывали кластеры высокой доступности.
Компания FirstByte начала предоставлять облачный хостинг в феврале 2016 года. Изначально кластер работал под управлением OpenStack. Однако отсутствие доступных специалистов по этой системе (как по наличию так и по цене) побудило к поиску другого решения. К новому инструменту для управления КВД предъявлялись следующие требования:
- Возможность предоставления виртуальных машин на KVM;
- Наличие интеграции с Ceph;
- Наличие интеграции с биллингом подходящим для предоставления имеющихся услуг;
- Доступная стоимость лицензий;
- Наличие поддержки производителя.
Отличительные черты кластера:
- Передача данных основана на технологии Ethernet и построена на оборудовании Cisco.
- За маршрутизацию отвечает Cisco ASR9001; в кластере используется порядка 50000 IPv6 адресов.
- Скорость линка между вычислительными нодами и коммутаторами 10 Гбит/с.
- Между коммутаторами и нодами хранилища скорость обмена данными 20 Гбит/с, используется агрегирование двух каналов по 10 Гбит/с.
- Между стойками с нодами хранилища есть отдельный 20-гигабитный линк, используемый для репликации.
- В узлах хранилища установлены SAS-диски в связке с SSD-накопителями.
- Тип хранилища — Ceph.
Данная конфигурация подходит для хостинга сайтов с высокой посещаемостью, для размещения игровых серверов и баз данных с нагрузкой от средней до высокой.
Компания FirstVDS предоставляет услуги отказоустойчивого хостинга, запуск продукта состоялся в сентябре 2015 года.
К использованию VMmanager Cloud компания пришла из следующих соображений:
- Большой опыт работы с продуктами ISPsystem.
- Наличие интеграции с BILLmanager по умолчанию.
- Отличное качество техподдержки продуктов.
- Поддержка Ceph.
- Передача данных основана на сети Infiniband со скоростью соединения 56 Гбит/с;
- Infiniband-сеть построена на оборудовании Mellanox;
- В узлах хранилища установлены SSD-носители;
- Используемый тип хранилища — Ceph.
В случае общего отказа Infiniband-сети связь между хранилищем дисков ВМ и вычислительными серверами выполняется через Ethernet-сеть, которая развёрнута на оборудовании Juniper. “Подхват” происходит автоматически.
Благодаря высокой скорости взаимодействия с хранилищем такой кластер подходит для размещения сайтов со сверхвысокой посещаемостью, видеохостинга с потоковым воспроизведением контента, а также для выполнения операций с большими объёмами данных.
Подведём итог статьи. Если каждая секунда простоя сервиса приносит значительные убытки — не обойтись без кластера непрерывной доступности.
Однако если обстоятельства позволяют подождать 5 минут пока виртуальные машины разворачиваются на резервной ноде, можно взглянуть в сторону КВД. Это даст экономию в стоимости лицензий и оборудования.
Кроме этого не можем не напомнить, что единственное средство повышения отказоустойчивости — избыточность. Обеспечив резервирование серверов, не забудьте зарезервировать линии и оборудование передачи данных, каналы доступа в Интернет, электропитание. Всё что только можно зарезервировать — резервируйте. Такие меры исключают единую точку отказа, тонкое место, из-за неисправности в котором прекращает работать вся система. Приняв все вышеописанные меры, вы получите отказоустойчивый кластер, который действительно трудно вывести из строя.
Если вы решили, что для ваших задач больше подходит схема высокой доступности и выбрали VMmanager Cloud как инструмент для её реализации, к вашим услугам инструкция по установке и документация, которая поможет подробно ознакомиться с системой. Желаем вам бесперебойной работы!
P. S. Если у вас в организации есть аппаратные CA-серверы — напишите, пожалуйста, в комментариях кто вы и для чего вы их используете. Нам действительно интересно услышать для каких проектов использование такого оборудование экономически целесообразно :)
В 1-й части статьи были рассмотрены конструктивные особенности исполнения серверов, форм-факторы и и уровни серверов для разных сегментов рынка.
В 2-й части статьи рассмотрены характеристики процессора и памяти сервера, а также чипсетов (наборов микросхем платформы).
В заключительной части рассмотрим характеристики дисковой подсистема сервера, источника питания, а также рекомендации по выбору сервера.
Дисковая подсистема
Дисковая подсистема сервера предназначена для долговременного хранения данных и состоит из накопителей системы хранения данных (СХД). Из всех подсистем сервера она самая медленная, особенно если построена на жёстких дисках.
Тип дисков: HDD, SSD
Название «диск», строго говоря, применимо только к накопителям на жёстких магнитных дисках HDD (Hard Disk Drive), поскольку только HDD и содержат диски, на которые записываются и считываются данные при помощи магнитных головок (про накопители на магнитооптических дисках и CD мы здесь не говорим).
Основные технические характеристики накопителей HDD:
- Интерфейс — стандарт обмена данными: SAS, SATA, Fibre Channel (FC);
- Ёмкость — максимальное количество данных, которые может хранить жесткий диск (ГБ, ТБ). В настоящее время одно устройство HDD может хранить до 80 терабайт данных и более.
- Форм-фактор — установочный размер диска: 3.5 или 2.5 дюйма;
- Время доступа — время, выполнения операции чтения или записи на любом участке магнитного диска (от 2.5 до 16 мс);
- Скорость вращения диска, от которой зависит время доступа и средняя скорость передачи данных (5400, 7200 и 10 000 об/мин.);
- Количество операций ввода-вывода в секунду IOPS (Input Output Per Second) — обычно жесткий диск производит около 50 операций IO в секунду при произвольном доступе и около 100 при последовательном;
- Потребление энергии — потребляемая мощность в Ваттах (W);
- Ударостойкость — сопротивляемость накопителя резким скачкам давления или ударам. Измеряется в единицах допустимой перегрузки (G) во включённом и выключенном состоянии;
- Скорость передачи данных – скорость чтения/записи при последовательном доступе (внутренняя зона диска — от 44 до 75 Мб/с, внешняя зона диска — от 60 до 111 Мб/с);
- Объём буфера — промежуточная память (от 8 до 64 Мб), предназначенная для демпфирования скоростей чтения/записи и передачи данные.
Твердотельные накопители SSD (Solid State Drive) не имеют дисков, и вообще каких-либо вращающихся или движущихся внутренних частей, поскольку представляют собой набор микросхем постоянной памяти достаточно большого объёма на плате внутри стандартного корпуса 2.5 или 3.5 дюйма.
Характеристики SSD – в основном те же, что и для HDD, за исключением того, что у них может быть быстродействующий интерфейс NVMe (Non-Volatile Memory express), а также отсутствует параметр скорости вращения диска, поскольку в них нет дисков.
Однако для SSD следует принимать во внимание другой, очень важный параметр: выносливость, т.е. допустимое количество циклов перезаписи на ячейку памяти. Для HDD этот параметр не указывается, поскольку количество циклов перезаписи магнитных диполей для них практически не ограничено.
Ячейка памяти SSD представляет собой полевый транзистор с изолированным затвором, количество заряда в котором определяет значение двоичного бита, или нескольких битов, записанных в ячейке. Поскольку изменение заряда затвора требует приложения высокого напряжения (до 20 В), это ограничивает количество циклов перезаписи, при превышении которого ячейка перестаёт достаточно надёжно работать.
Поэтому SSD подразделяются на два основных класса – бытовые и корпоративные. Для бытовых SSD (флешки, внутренние накопители для ноутбуков и мобильных телефонов) параметр выносливости, хотя и не очень высокий, однако позволяет использовать SSD без ограничений на весь срок службы устройства. Для серверов, где происходит интенсивный обмен данными, недорогие бытовые SSD неприменимы – допустимое число циклов перезаписи на ячейку в них может быть выбрано за один рабочий день.
Память класса СХД
Если говорить о памяти (SRAM, DRAM) и системе хранения данных (СХД) сервера (HDD, SSD) то можно выстроить следующую иерархию.
Рис. 3-3. Иерархия параметров памяти и СХД сервера.
Параметры ёмкости, задержки считывания-записи данных увеличиваются от ОЗУ к СХД. Поэтому самая быстродействующая память – SRAM, самая медленная – HDD (накопитель). По удельной стоимости на один бит наоборот, самая дорогая в этом плане – кэш-память процессора (SRAM), самая дешёвая – HDD.
Однако, между оперативной памятью DRAM и SSD имеется достаточно широкий зазор задержек. Слишком уж сильно различаются их рабочие характеристики и принцип работы.
Однако, в последние годы была создана постоянная память, которая представляет собой некий компромисс между ОЗУ и СХД. Она получила название SCM (Storage Class Memory) – память класса СХД. С одной стороны, она достаточно долго хранит информацию, а с другой – по быстродействию приближается к ОЗУ. По принципу работы такая память представляет собой разновидность SSD.
Это, возможно, приведёт к тому, что в будущем для серверов не будут отдельно специфицироваться объёмы оперативной памяти и накопителя СХД (HDD, SSD). Будет указываться просто общий объём памяти хранения сервера. Какая доля будет относиться к оперативной памяти, а какая к постоянной – не будет иметь принципиального значения.
Резервирование и RAID-контроллеры
Для серверов требуется не только высокая скорость чтения и записи данных, но и сохранность данных при возможном выходе из строя накопителей СХД. Объёмы информации, которыми оперируют серверы, много больше, чем может дать один накопитель. С повышением числа накопителей, выше и вероятность выхода из строя какого-то из них, особенно при высокой нагрузке.
Проблемы производительности и отказоустойчивости дисковой подсистемы решаются созданием массивов резервирования, в которые с помощью контроллера RAID (Redundant Array of Independent Disks) объединяется несколько накопителей — HDD и/или SSD. В таких массивах автоматически сохраняются две или более копии каждого блока данных, а также коды избыточности. При этом RAID-массив представлен для сервера как единое пространство хранения.
Существует много видов RAID-массивов (от RAID-0 до RAID-10), отличающихся производительностью, надёжностью хранения данных и минимально необходимым количеством дисков. Выбор вида RAID зависит от задач и требований к серверу.
Кроме того, в серверах могут использоваться различные виды RAID-контроллеров, каждый из которых может поддерживать все, или только некоторые, типы RAID-массивов. Основные виды RAID-контроллеров, следующие:
- Программные, когда функции RAID-контроллера полностью выполняет центральный процессор сервера, забирая таким образом, часть ресурса производительности. Такой метод приемлем только для серверов начального (Entry) класса, поскольку это наименее производительное и наименее отказоустойчивое решение.
- Интегрированные, когда RAID-контроллер располагается на материнской плате сервера. При этом также частично задействуется центральный процессор. Такие RAID-контроллеры более функциональные, более быстрые и достаточно надёжные.
- Аппаратные, которые выполнены в виде плат расширения или отдельных устройств. Они имеют свой процессор и кэш-память.
- Внутренние — предназначены для подключения накопителей, установленных в сам сервер.
- Внешние — используются для подключения внешних дисковых хранилищ.
Выбор вида RAID-контроллера также зависит от задач и требований, предъявляемых к серверу.
Источники питания для серверов
Когда в дата-центре используются много серверов, то очень важно выбрать наиболее эффективный тип источника питания для них, чтобы существенно сэкономить на электроэнергии. Для серверов различают три класса источники питания:
- Titanium – наиболее эффективный по потребляемой мощности источник питания с КПД до 96%;
- Platinum – имеет эффективность в 94%;
- Gold – обеспечивает наименьшую эффективность 92%.
Рис. 3-4. Источник питания стоечного сервера (источник: Integrity Global Solutions).
Блок питания следует выбирать исходя не только из текущих потребностей, но и на перспективу. Если при апгрейде сервера понадобится более высокая мощность питания, мощности блока питания, приобретённого «впритык», может не хватить и придется приобретать новый, более мощный блок питания, а старый придётся списать.
Источники питания для серверов обычно используют с резервированием. Это означает, что каждый серверный модуль имеет два параллельно работающих блока питания с мощностью, достаточной для работы сервера от одного блока. В случае выхода из строя одного блока питания, сервер не отключается, а продолжает работу, при этом отказавший блок можно заменить в «горячем» режиме, то есть, не отключая сервер.
Кроме того, для серверов обычно требуются источники бесперебойного питания (ИБП). Главная функция источника бесперебойного питания — обеспечение работы сервера в течение десяти-пятнадцати минут после аварии в системе электроснабжения дата-центра. За это время работающие приложения должны завершить работу и сохранить данные.
Если нужно, чтобы серверы могли работать в автономном режиме длительное время, необходимо создавать в дата-центре резервное электропитание, например, с использованием дизельного генератора или аккумуляторных батарей.
Как выбрать сервер
Сервер необходимо выбирать, исходя из бизнес-задач организации. Не следует приобретать на рынке просто максимально доступную по цене конфигурацию, поскольку при таком подходе можно сделать ряд ошибок. Например, купить сервер, многие функции которого никогда не понадобятся, а мощность будет превышать реальные потребности.
Другая крайность – излишнее стремление к экономии, что может привести к приобретению сервера, в котором будут отсутствовать нужные функции, или мощности которого не будет хватать для нужд организации. В таком случае, либо понадобится дорогостоящий «апгрейд», либо – списание неудачно приобретённого и приобретение нового сервера.
Поэтому, при выборе сервера целесообразно пользоваться услугами компетентных специалистов, которые могут вникнуть в задачи заказчика, оценить его потребности и предложить ему наиболее подходящий тип, конфигурацию и производительность сервера. Затраты на таких консультантов всегда окупаются.
Однако, и самому заказчику тоже необходимо до некоторой степени «говорить на одном языке» с таким специалистом и иметь в виду, по крайней мере, следующее.
Параметры, определяющие производительность сервера
- Тип и тактовая частота процессоров;
- Объем, тип, частота оперативной памяти;
- Объем и производительность СХД.
Процессор
Основные параметры процессорной системы:
- Количество процессоров;
- Частота процессоров;
- Объем встроенной кэш-памяти процессора (память, служащая для маскирования обращений к оперативной памяти, это важный параметр при работе с базами данных).
Память сервера можно выстроить в иерархию по удалённости от процессора. Так, кэш-память находится на ближе всего к процессору, оперативная память на второй позиции, дисковые накопители на третьей. Примерно так же распределяется и их стоимость — чем ближе к процессору, тем дороже.
В последнее время цены на оперативную память снижаются. Поэтому, чем больше памяти будет на вашем сервере, тем лучше — приложения смогут хранить больше данных ближе к процессору и работать быстрее. Но и здесь необходимо исходить из разумных потребностей, например, нет смысла использовать терабайтное ОЗУ для сервера начального или среднего уровня.
Следует также обратить внимание на память класса СХД (SCM), что позволит увеличить эффективность работы с данными в сервере: нужные данные всегда будут «на расстоянии вытянутой руки» от процессора.
Выбор дисковой подсистемы зависит от задач сервера. Поэтому необходимо установить приоритет параметров:
- Быстрая скорость записи-считывания данных (IOPS);
- Возможность обработать большое количество одновременных запросов;
- Объем носителей;
- Стоимость.
Как выстроить эту последовательность приоритетов – зависит от бизнес-задач организации.
Имеющиеся на рынке жесткие диски отличаются друг от друга скоростью вращения шпинделя, объемом и интерфейсом подключения (SAS, SCSI, Fibre Channel, SATA3, NVMe).
SATA-диски обладают относительно небольшой скоростью доступа, но их объём может доходить до десятков терабайт, а удельная стоимость существенно ниже, чем у дисков SCSI. Эти диски идеально подходят для хранения данных, которые запрашиваются не столь часто (FTP-серверы, серверы общего доступа в Internet).
Интерфейса Fibre Channel позволяет передавать данные по оптическому каналу с очень высокой скоростью, но для его применения требуется специальная и весьма дорогостоящая инфраструктура. Оптимально применять FC-диски в системах, где требуется максимальное быстродействие.
Наконец, накопители SSD позволят значительно повысить скорость работы практически любых приложений сервера, однако, при этом следует выбирать твердотельную память корпоративного, а не бытового класса.
Все эти данные приведены исключительно для справочных целей. В вопросе выбора сервера, лучше полагаться на помощь компетентных специалистов, например, компании ITELON, которые смогут квалифицированно разобраться в требованиях вашей организации и предложить наилучший вариант сервера, как по функциям и параметрам, так и по цене.
Ставилась задача по настройке а втоматической отказоустойчивости и отсутствию возможности утраты данных для 1С - была рализована с настройкой кластера 1С и кластера MS SQL.
Но хотелось, чтобы базы на MS SQL - были зеркальные, потому что :
Основные достоинства Database Mirroring
- Восстановление менее 3 секунд
- Полноценный резерв
- Два отдельных сервера
- Две отдельных копии данных
- Взаимодействие между серверами через стандартное сетевое соединение
- Нет специальных требований на аппаратное обеспечение
- Самоконтроль
- Высокая доступность для базы данных
Но 1С сама не может переключиться на другую базу-тогда пришло такое решение.
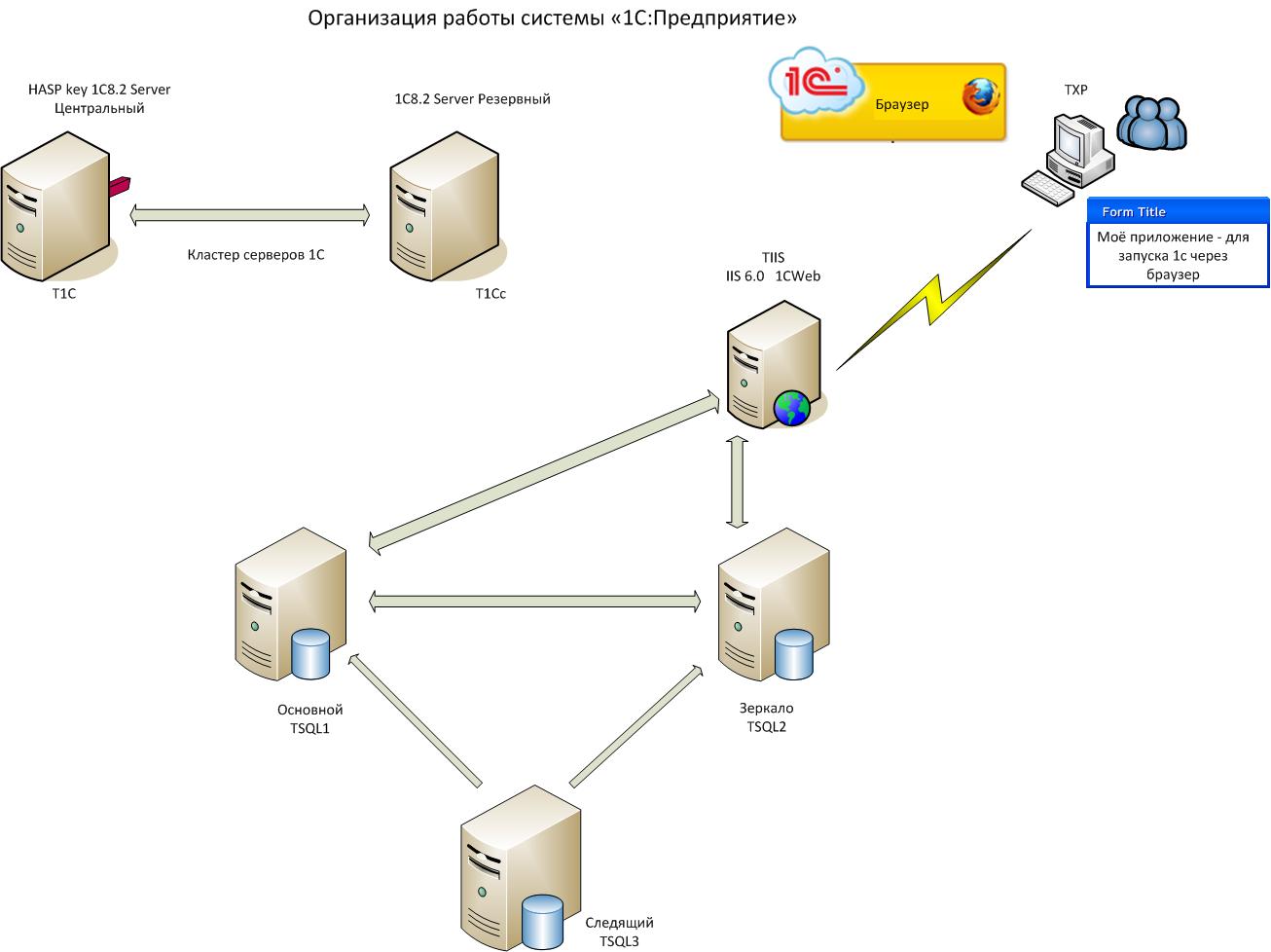
В проекте были задействованы 6 серверов: 2 сервера 1С, 3 SQL сервера и 1 веб-сервер (рис.1).
![]()
Был настроен кластер серверов 1С: Центральный и резервный (на рис.1) T1C и T1Сс, затем настроено зеркальное отображение базы данных. Сделав это - будет не просто улучшена возможность аварийного восстановления вашего приложения, вы будете использовать высокий уровень доступности зеркального отображения базы данных - функция, которую вы найдете в SQL Server 2005 и выше, это означает, что отказоустойчивость базы данных, в случае если потеряете ваш главный SQL сервер. Нам понадобиться 3 SQL сервера (TSQL1, TSQL2, TSQL3). 2 SQL сервера (Principal и Mirror) должны быть идентичными, например, это означает версия (Standard или Enterprise), пакеты обновлений должны быть одинаковы на обоих серверах. Третий сервер может быть SQL Server Standard, Enterprise, Workgroup или Express. Свидетель (Witness) сервер будет, пинговать 2 других серверах, если есть что-то неправильно, это сервер имеет способность узнавать о начале автоматического перехода на другой, он не будет содержать базу данных, поэтому бессмысленно использовать SQL Server, кроме Express Edition.
Создав базы на серверах 1С и SQL – серверах опубликуем из конфигуратора веб-сервис на сервере TIIS.
Подробно как настраивать ваше написанное, описывать не стал, в сети много ресурсов, которые дают подробную инструкцию об этом.
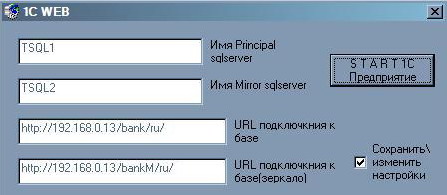
Сама 1С не может переключиться на другой SQL сервер, при остановке главного. Выход - было написано приложение для запуска 1С.(рис.2)
![]()
Приложение проверяет работу SQL серверов - включен ли сервер физически, потом происходит проверка работоспособности самого SQL-сервера, а затем запускает 1С через введенный адрес для IE.
Читайте также: