
Dns failover что это
Обновлено: 04.07.2024
От чтения, кажется, что переключение DNS не рекомендуется только потому, что DNS не был предназначен для этого. Но если у вас есть два веб-сервера в разных подсетях с избыточным контентом, какие другие методы существуют, чтобы гарантировать, что весь трафик будет перенаправлен на живой сервер, если один сервер опустится?
В ответ на «DNS failover», я полагаю, вы имеете в виду DNS Round Robin в сочетании с некоторым мониторингом, т. е. публикацией нескольких IP-адресов для имени хоста DNS и удалением мертвого адреса при мониторинге обнаружения того, что сервер не работает. Это может быть осуществимо для небольших, менее продаваемых сайтов.
По дизайну, когда вы отвечаете на запрос DNS, вы также предоставляете Time To Live (TTL) для ответа, который вы раздаете. Другими словами, вы сообщаете другим DNS-серверам и кешам «вы можете сохранить этот ответ и использовать его за x минут, прежде чем проверять меня». Недостатки исходят из этого:
- При переходе на другой ресурс DNS неизвестный процент ваших пользователей будет кэшировать ваши данные DNS с разным количеством TTL. До истечения срока действия TTL они могут подключаться к мертвому серверу. Есть более быстрые способы завершения перехода на другой ресурс, чем это.
- Из-за вышеизложенного вы склонны устанавливать TTL довольно низко, скажем, 5-10 минут. Но установка его выше дает (очень малое) преимущество в производительности и может помочь вашей службе распространения DNS работать надежно, даже если есть короткий сбой сетевого трафика. Таким образом, использование отказоустойчивости на основе DNS идет против высоких TTL, но высокие TTL являются частью DNS и могут быть полезны.
Более распространенные методы получения хорошего времени работы включают:
В очень небольшом меньшинстве веб-сайтов используются настройки нескольких центров обработки данных, с «гео-балансировкой» между центрами обработки данных.
DNS не был разработан для отказоустойчивости - но он был разработан с TTL, которые поразительно работают для обеспечения отказоустойчивости в сочетании с надежной системой мониторинга. TTL могут быть установлены очень короткими. Я эффективно использовал TTL в течение 5 секунд в производстве для облегчения быстрых решений, основанных на отказе DNS. У вас должны быть DNS-серверы, способные обрабатывать дополнительную нагрузку - и имя не будет сокращать его. Тем не менее, powerdns подходит для счета при поддержке реплицируемых баз данных mysql на резервных серверах имен. Вам также нужна надежная распределенная система мониторинга, на которую вы можете доверять автоматическую интеграцию с отказоустойчивостью. Zabbix работает для меня - я могу проверить сбои от нескольких распределенных систем Zabbix почти мгновенно - обновить записи mysql, используемые powerdns на лету, - и обеспечить почти мгновенный переход на другой ресурс во время сбоев и трафик трафика.
Но эй, я создал компанию, которая предоставляет службы восстановления DNS после многих лет работы над крупными компаниями. Так что, по моему мнению, с солью. Если вы хотите увидеть некоторые диаграммы трафика zabbix сайтов с большими объемами во время сбоя - убедитесь сами, как работает DNS-переключение - напишите мне, что я более чем рад поделиться.
Проблема с отказоустойчивостью DNS заключается в том, что она во многих случаях ненадежна. Некоторые интернет-провайдеры будут игнорировать ваши TTL, это происходит не сразу, даже если они уважают ваши TTL, а когда ваш сайт возвращается, это может привести к некоторой странности с сеансами, когда таймер DNS пользователя истекает, и они заканчивают заголовок на другой сервер.
К сожалению, это в значительной степени единственный вариант, если вы недостаточно велик, чтобы выполнять свою (внешнюю) маршрутизацию.
Преобладающее мнение заключается в том, что с DNS RR, когда IP уходит, некоторые клиенты будут продолжать использовать сломанный IP в течение нескольких минут. Это было сказано в некоторых предыдущих ответах на вопрос, и оно также написано в Википедии.
Использование нескольких записей A - это не трюк в торговле, или функция, задуманная поставщиками оборудования для балансировки нагрузки. Протокол DNS был разработан с поддержкой нескольких записей A по этой причине. Такие приложения, как браузеры, прокси и почтовые серверы, используют эту часть протокола DNS.
Возможно, какой-то эксперт может прокомментировать и дать более четкое объяснение того, почему DNS RR не подходит для высокой доступности.
PS: извините за неработающую ссылку, но, как новый пользователь, я не могу опубликовать более 1
Я запускал переключение DNS RR на ограниченный рынок, но важный для бизнеса веб-сайт (по двум географическим регионам) в течение многих лет.
Он отлично работает, но есть, по крайней мере, три тонкости, которые я усвоил.
1) Браузеры откажутся от отказа от неработающего IP до рабочего IP через 30 секунд (последний раз, когда я проверил), если оба они считаются активными в любом кэшированном DNS, доступном вашим клиентам. Это в основном хорошая вещь.
Но наличие «половины» ваших пользователей в ожидании 30 секунд неприемлемо, поэтому вы, вероятно, захотите обновить свои записи TTL на несколько минут, а не на несколько дней или недель, чтобы в случае сбоя вы могли быстро удалить вниз сервер из вашего DNS. Другие ссылались на это в своих ответах.
2) Если один из ваших серверов имен (или одна из ваших двух географических регионов целиком) идет вниз, что обслуживает ваш круглый домен, и если основной из них идет вниз, я смутно помню, что вы можете столкнуться с другими проблемами, для удаления этого сбитого сервера имен из DNS, если вы еще не установили SOA TTL /expiration для сервера имен и достаточно низкое значение. У меня могут быть технические подробности здесь, но есть более чем один TTL-параметр, который вам нужно, чтобы получить право на защиту от одиночных точек отказа.
3) Если вы публикуете веб-API, службы REST и т. д., они обычно не вызываются браузерами, и, таким образом, на мой взгляд, DNS failover начинает показывать реальные недостатки. Возможно, поэтому некоторые говорят, что, как вы выразились, «это не рекомендуется». Вот почему я говорю это. Во-первых, приложения, которые потребляют эти URL-адреса, обычно не являются браузерами, поэтому им не хватает 30-секундных свойств переключения /логики общих браузеров. Во-вторых, независимо от того, вызвана ли вторая запись DNS или даже переименована DNS, очень многое зависит от низкоуровневых сведений о программировании сетевых библиотек на языках программирования, используемых этими клиентами API /REST, а также точно, как они вызываются клиентское приложение API /REST. (Под их крышкой, вызывает ли библиотека get_addr, а когда? Если сокеты зависают или закрываются, приложение снова открывает новые сокеты? Есть ли какая-то логика таймаута? И т. Д. И т. Д.)
Это дешево, хорошо проверено и «в основном работает». Так как в большинстве случаев ваш пробег может меняться.
Есть группа людей, которые используют нас (Dyn) для перехода на другой ресурс. Это та же самая причина, по которой сайты могут делать страницу статуса, когда у них есть время простоя (подумайте о таких вещах, как Twitter Fail Whale) . или просто просто перенаправляйте трафик на основе TTL. Некоторые люди могут подумать, что DNS Failover - это гетто . но мы серьезно разработали нашу сеть с откатом с самого начала . так, чтобы это работало, а также аппаратное обеспечение. Я не уверен, как DME это делает, но у нас есть 3 из 17 наших самых близких anycasted PoPs, которые контролируют ваш сервер из ближайшего местоположения. Когда он обнаруживает от двух из трех, что он не работает, мы просто перенаправляем трафик на другой IP-адрес. Единственное время простоя - это те, которые были запрошены на оставшуюся часть этого интервала TTL.
Некоторым людям нравится использовать оба сервера одновременно . и в этом случае может сделать что-то вроде балансировки нагрузки на круговой платформе . или на основе геостационарной балансировки нагрузки. Для тех, кто действительно заботится о производительности . наш диспетчер трафика в реальном времени будет следить за каждым сервером . и если он медленнее . перенаправляйте трафик на самый быстрый, исходя из того, какие IP-адреса вы связываете в своих именах хостов. Опять же . это работает на основе ценностей, которые вы создали в нашем интерфейсе /API /Portal.
Я думаю, моя точка зрения . мы специально разработали отказоустойчивость dns. Хотя DNS не был создан для восстановления после сбоя, когда он был первоначально создан . наша DNS-сеть была разработана для ее реализации с самого начала. Он обычно может быть столь же эффективным, как и аппаратное обеспечение. Без амортизации или стоимости аппаратного обеспечения. Надеюсь, что это не заставляет меня замолчать за подключение Dyn . есть много других компаний, которые это делают . Я просто говорю с точки зрения нашей команды. Надеюсь, это поможет .
Другой вариант - установить сервер имен 1 в местоположении A и сервер имен 2 в местоположении B, но установить каждый из них так, чтобы все записи A в NS1 указывали на IP-адреса для местоположения A, а на NS2 - все точки A к IP-адресам для местоположения B. Затем установите TTL для очень низкого номера и убедитесь, что ваша запись домена в регистраторе настроена для NS1 и NS2. Таким образом, он автоматически загрузит баланс и завершит сбой, если один сервер или одна ссылка на местоположение снизятся.
Я использовал этот подход несколько иначе. У меня есть одно место с двумя интернет-провайдерами и используйте этот метод для прямого трафика по каждой ссылке. Теперь это может быть немного больше обслуживания, чем вы готовы сделать . но я смог создать простую часть программного обеспечения, которая автоматически вытягивает записи NS1, обновляет записи IP-адресов для избранных зон и толкает эти зоны в NS2.
Альтернативой является отказоустойчивая система на основе BGP. Это не просто настроить, но это должно быть пуленепробиваемым. Настройте сайт A в одном месте, сайт B в секунду со всеми локальными IP-адресами, затем получите класс C или другой блок ip, которые переносимы и настроили перенаправление с портативных IP-адресов на локальные IP-адреса.
Есть подводные камни, но это лучше, чем DNS-решения, если вам нужен этот уровень контроля.
Я использую DNS-привязку на основе DNS и отказоустойчивость на протяжении последних десяти лет, и есть некоторые проблемы, но они могут быть смягчены. BGP, в то время как превосходящий в некотором роде не является 100% -ным решением с повышенной сложностью, возможно, дополнительными затратами на оборудование, временем конвергенции и т. Д.
Я нашел, что объединение локальных (LAN-based) балансировки нагрузки, GSLB и облачного хостинга на основе облачных вычислений работает достаточно хорошо, чтобы закрыть некоторые проблемы, обычно связанные с балансировкой нагрузки DNS.
Все эти ответы имеют для них некоторую юридическую силу, но я думаю, что это действительно зависит от того, что вы делаете и каков ваш бюджет. Здесь, в CloudfloorDNS, большой процент нашего бизнеса - это DNS и предлагает не только быстрый DNS, но и низкие параметры TTL и переключение DNS. Мы бы не были в бизнесе, если бы это не работало и не работало хорошо.
Если вы являетесь многонациональной корпорацией с неограниченным бюджетом на время безотказной работы, да, аппаратные балансировочные балансы GSLB и центры обработки данных уровня 1 великолепны, но ваш DNS все еще должен быть быстрым и надежным. Как многие из вас знают, DNS является критическим аспектом любой инфраструктуры, кроме самого имени домена, это служба низкого уровня, на которой распространяется любая другая часть вашего онлайн-присутствия. Начиная с твердотельного регистратора доменов, DNS так же критичен, как не допустить истечения срока действия вашего домена. DNS идет вниз, это означает, что весь онлайн-аспект вашей организации также не работает!
При использовании отказоустойчивости DNS другие критические аспекты - это мониторинг сервера (всегда нужно проверять несколько географических местоположений для проверки и всегда несколько (по крайней мере 3), чтобы исключить ложные срабатывания) и правильное управление записями DNS. Низкие TTL и некоторые опции с отказоустойчивостью могут сделать этот процесс беспрепятственным, и бьет из-за пробуждения до пейджера посреди ночи, если вы администратор sys.
В целом, DNS Failover действительно работает и может быть очень доступным. В большинстве случаев у нас или большинства управляемых DNS-провайдеров вы получите Anycast DNS вместе с мониторингом серверов и отказоустойчивостью для частичной стоимости аппаратных опций.
Итак, настоящий ответ - да, он работает, но это для всех и каждого бюджета? Возможно, нет, но пока вы не попробуете его и не выполните тесты для себя, трудно игнорировать, если вы являетесь малым и средним бизнесом с ограниченным бюджетом ИТ, который хочет наилучшего времени безотказной работы.
"и почему вы тратите свои шансы на его использование для большинства производственных сред (хотя это лучше, чем ничего).
Собственно, «лучше, чем ничего» лучше выражается как «единственный вариант», когда присутствия географически разнообразны. Балансировщики оборудования отлично подходят для одной точки присутствия, но одна точка присутствия также является единственной точкой отказа.
Существует много сайтов с большим долларом, которые эффективно используют управление трафиком на основе DNS. Это тип сайтов, которые знают почасово, если продажи не работают. Похоже, что они являются последними для того, чтобы «использовать ваши шансы, используя его для большинства производственных сред». Действительно, они тщательно изучили свои варианты, выбрали технологию и хорошо заплатили за нее. Если бы они подумали, что что-то лучше, они уйдут в сердце. Тот факт, что они по-прежнему предпочитают оставаться, говорит о том, как реально жить в мире.
При отказе на основе Dns происходит определенное количество задержек. Об этом нет. Но он по-прежнему остается единственным жизнеспособным подходом к управлению отказоустойчивостью в многопользовательском сценарии. Как единственный вариант, это намного больше, чем «лучше, чем ничего».
Если вы хотите узнать больше, прочитайте примечания к приложению
Они охватывают: отказоустойчивость, глобальную балансировку нагрузки и множество связанных вопросов.
Если ваша бэкэнд-архитектура позволяет это, лучшим вариантом является глобальная балансировка нагрузки с параметром перехода на другой ресурс. Таким образом, все серверы и пропускная способность играют как можно больше. Вместо того, чтобы вставлять дополнительный доступный сервер при сбое, эта настройка выводит неудавшийся сервер из службы до его восстановления.
Короткий ответ: он работает, но вы должны понимать ограничения.
Я считаю, что идея отказоустойчивости была предназначена для кластеризации, но поскольку она также могла работать соло, она все же позволяла работать в режиме «один к одному».
Я бы рекомендовал вам либо A, либо выбрать центр обработки данных, который является многосетевым на своем собственном AS или B, размещать ваши серверы имен в общедоступном облаке. ДЕЙСТВИТЕЛЬНО маловероятно, что EC2, или HP, или IBM снизятся. Просто мысль. В то время как DNS работает как исправление, это просто просто исправление плохого дизайна в фундаменте сети в этом случае.
Другой вариант, в зависимости от вашей среды, заключается в использовании комбинации с IPSLA, PBR и FHRP для выполнения ваших потребностей в избыточности.
Рано или поздно сервер сломается, каким бы надежным он ни был. Риск выхода из строя железа решается только посредством избыточности. Т.е. тогда, когда каждый узел имеет резервную копию. И в случае выхода их строя основного сервера, резервный может взять на себя работу основного. По-другому это и называется failover.
Избыточность
Резервные компоненты должны повторять конфигурацию основных (количество оперативной памяти, мощность процессора и т.п.). Два сервера послабее лучше одного помощнее, т.к. вероятность выхода из строя двух серверов одновременно намного ниже, чем одного.
Существует несколько простых подходов по резервированию основных компонент Web приложения:
1. DNS
Обычно для одного домена указывается несколько NS записей:
В случае, если один из NS серверов выходит из строя, запросы обрабатывают другие.
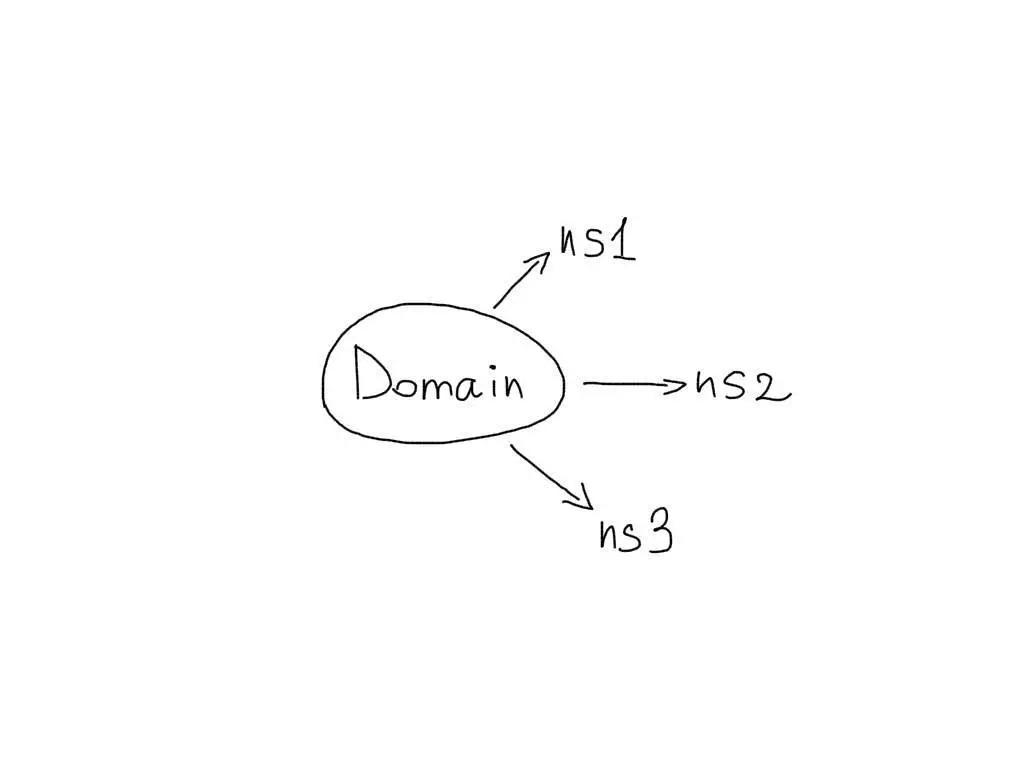
Это и позволяет обеспечить высокий уровень доступности для обслуживания запросов к DNS. Убедитесь, что Ваш домен имеет несколько NS записей:
2. Фронтенды
Резервирование фронтендов удобно реализовывать с помощью виртуальных IP адресов UCARP. Тогда один из двух идентичных серверов получает виртуальный IP, к которому привязан домен. При выходе из строя текущего сервера, этот IP адрес назначается резервному серверу.
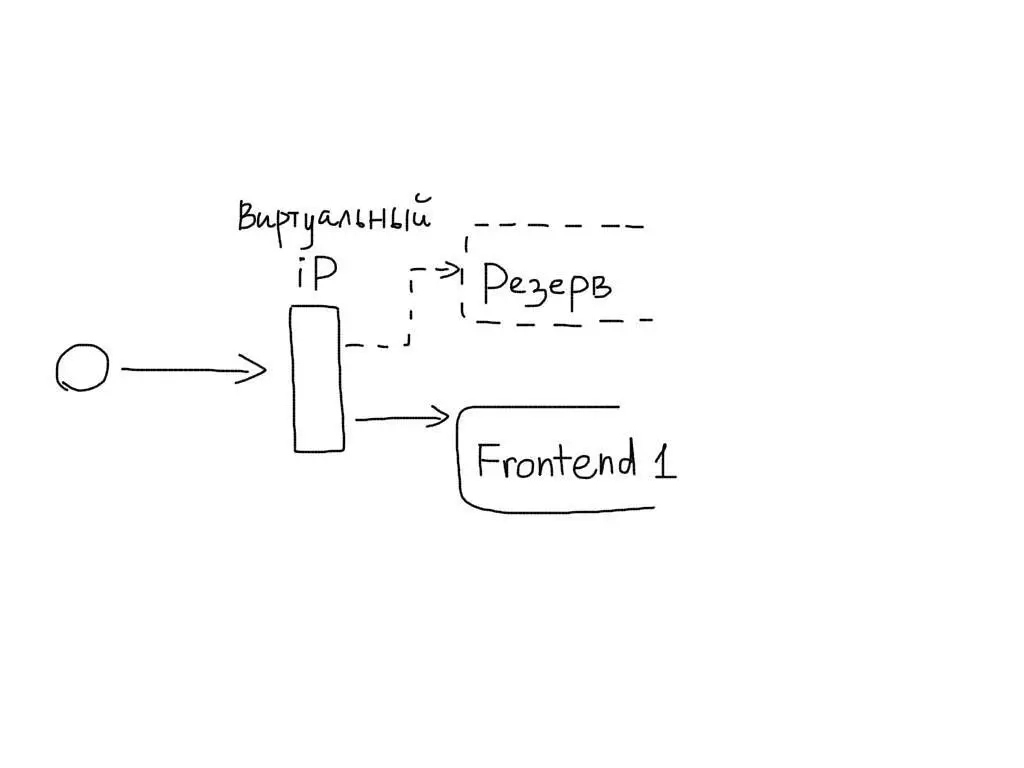
Отслеживание состояния и переключение IP адреса следует автоматизировать. Можно каждую секунду опрашивать основной сервер на корректность работы (т.н. heartbeat). В случае, если корректный ответ не был получен, переназначать IP адрес на резервный фронтенд:
Более низкий уровень мониторинга (доступность сервера) UCARP реализует самостоятельно.
3. Бекенды
Однако, при отключении одного из серверов, повысится нагрузка на остальные. Количество бекендов лучше рассчитывать исходя из того, что в любой момент может выйти из строя 25% их общего количества.
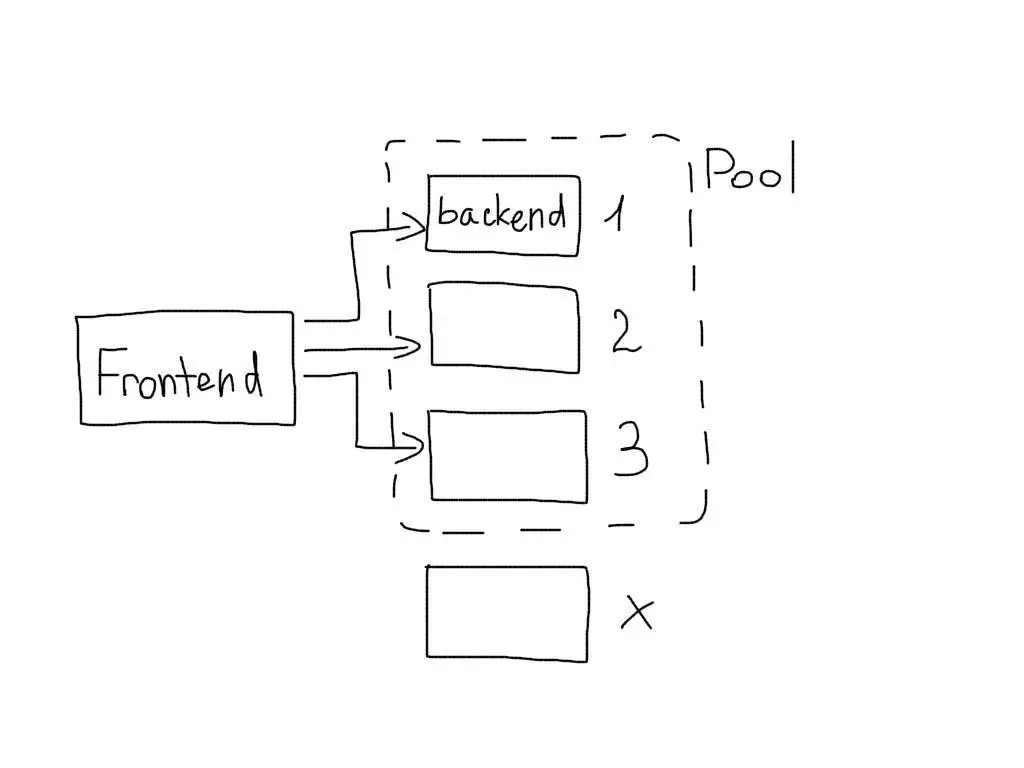
Nginx позволяет указать несколько серверов для обработки fastcgi запросов с помощью upstream:
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
Запросы будут автоматически распределяться между указанными серверами.
Кроме этого, Ngxinx будет в реальном времени анализировать ошибки в ответах от бекендов. В случае обнаружения ошибки, он перестанет отправлять запросы на сломанный бекенд. Время и количество попыток можно настроить:
server 10.10.0.5 fail_timeout=360s max_fails=2;
server 10.10.0.6 fail_timeout=360s max_fails=2;
server 10.10.0.7 **fail_timeout=360s max_fails=2**;
4. Базы данных
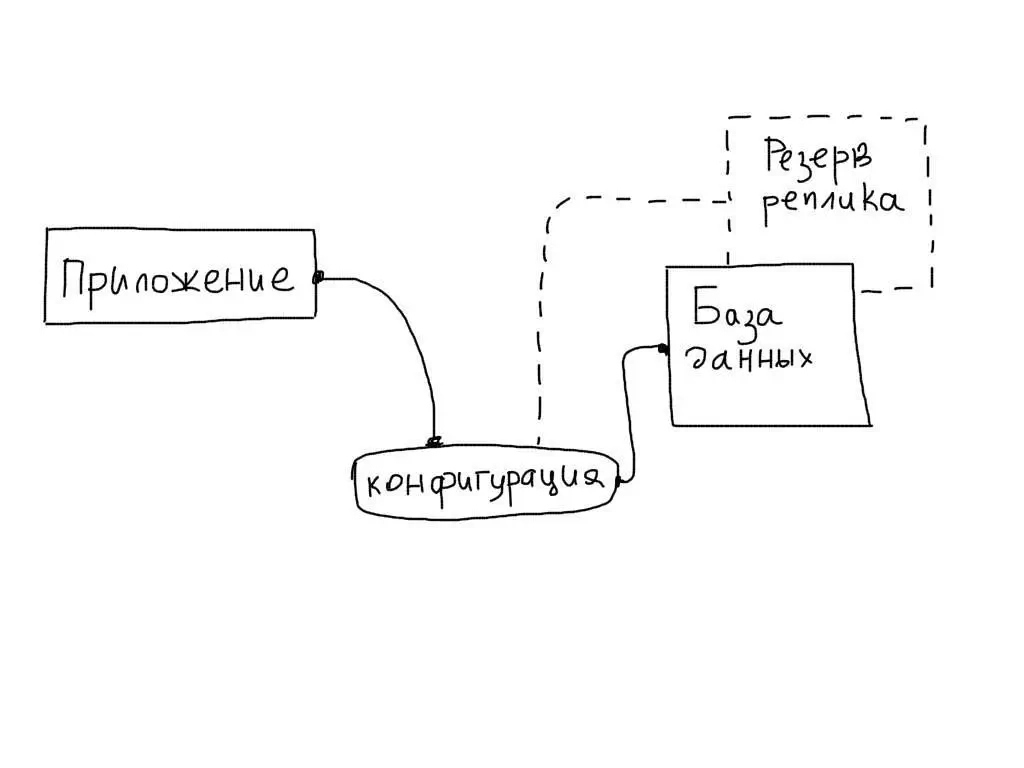
Удобно автоматизировать отслеживание состояния баз данных. В случае обнаружения ошибки, настройки в приложении автоматически изменяются на сервер реплики:
$master = include 'config/db/master.php';
Процесс восстановления сломанного сервера будет таким:
Настройку слейва с работающего мастера можно выполнить с помощь утилиты Xtrabackup.
После этого, бывший слейв становится основным (т.е. Мастером), а восстановленный сервер становится резервным (т.е. Слейвом).
Самое важное
Любой сервер когда-то сломается. Избегайте узлов, которые работают в единственном экземпляре. Отдавайте предпочтение менее мощным серверам, но большему их количеству.
Highload нужны авторы технических текстов. Вы наш человек, если разбираетесь в разработке, знаете языки программирования и умеете просто писать о сложном!
Откликнуться на вакансию можно здесь .
Что такое индексы в Mysql и как их использовать для оптимизации запросов
Как перезапустить nginx после обновления конфигурации
Основные понятия о шардинге и репликации
Примеры ad-hoc запросов и технологии для их исполнения
Устройство колоночных баз данных
Настройка Master-Master репликации на MySQL за 6 шагов
Включение и использование log-файлов для проверки работы Nginx
Пример управления фоновыми процессами в supervisor'e
Как создать и использовать составной индекс в Mysql
Как проверить работу сайта под нагрузками
Анализ медленных PHP скриптов с помощью XHprof
Рекомендации по настройке Redis для оптимизации ресурсов и повышения стабильности на производственном сервере
Анализ медленных запросов (профилирование) в MySQL с помощью Percona Toolkit
Система отказоустойчивости DNS от ClouDNS сохранит ваши сайты и веб-службы в сети в случае сбоя системы или сети. Это делается путем перемещения DNS-трафика на другой рабочий IP-адрес.
DNS Failover is a technology mechanism that automatically updates DNS records if something goes wrong with a DNS name server on the network. When a failure is detected, DNS Failover will be activated to execute different actions to keep your availability. Depending on how you set it up it can only notify the problem, or to solve the issue by giving users a different IP address from an alternative server.
С помощью DNS Failover вы также можете переносить трафик между избыточными сетевыми подключениями.
Как работает DNS Failover?
Как только ваш основной IP-адрес перестанет отвечать, ваши DNS мгновенно обновятся на всех серверах имен ClouDNS по всему миру, чтобы указать на рабочий резервный IP-адрес или просто отключить отказавший IP-адрес во время простоя.
Вы получите уведомление по электронной почте о каждом изменении DNS записей.
Преимущества и особенности
Наша система аварийного переключения DNS контролирует ваши серверы каждую минуту и держит вас в курсе состояния ваших услуг.
ClouDNS предназначен для работы в качестве облачной инфраструктуры. Наша саморазвитая система синхронизации и распределения данных позволяет нашим клиентам осуществлять мониторинг в режиме реального времени статуса зон DNS в каждом месте. Наша инфраструктура синхронизирует ваши настройки одновременно во всех POP (точки присутствия), поэтому никаких дополнительных действий с вашей стороны не требуется, как только вы настраиваете свои зоны.
Нет простоев = лучшая эффективность (покупки, доход, рентабельность инвестиций и т. д.)
Начните работать с DNS Failover всего за несколько минут. Просто нажмите на значок DNS Failover для записи A или AAAA, которую вы хотите отслеживать, и введите информацию об услуге, которую вы хотите отслеживать. Как только ваши настройки будут сохранены, первая проверка будет выполнена в течение 60 секунд!
Наша служба DNS Failover предназначена для работы в облаке, поэтому вам не нужно беспокоиться о сбоях. Мы проводим независимые проверки сети и услуг из разных мест по всему миру. Каждое дерево проверок уникально для максимальной точности.
Независимо от дня недели, независимо от времени суток, мы обеспечиваем непрерывный мониторинг и поддержку сети. Наша техническая поддержка онлайн для вас 24/7 с помощью чата и заявок. Мы можем перенести ваши зоны бесплатно,читайте больше здесь.
DNS Failover является частью наших стандартных тарифных планов хостинга - Premium DNS, DDoS Protected DNS и GeoDNS. Дополнительные проверки могут быть добавлены в качестве дополнения к каждому плану хостинга.
Из чтения кажется, что отказоустойчивость DNS не рекомендуется только потому, что DNS не был разработан для этого. Но если у вас есть два веб-сервера в разных подсетях, в которых размещается избыточный контент, какие существуют другие способы, чтобы гарантировать, что весь трафик будет перенаправлен на работающий сервер, если один сервер выйдет из строя?
Ищите здесь обновленную дискуссию на эту тему. Отработка отказа теперь выполняется автоматически современными браузерами.Под «отказоустойчивостью DNS» я понимаю, что вы имеете в виду DNS Round Robin в сочетании с некоторым мониторингом, т.е. публикацией нескольких IP-адресов для имени хоста DNS и удалением мертвого адреса, когда мониторинг обнаруживает, что сервер не работает. Это может быть работоспособно для небольших, менее посещаемых сайтов.
Когда вы отвечаете на запрос DNS, вы также предоставляете время жизни (TTL) для ответа, который вы раздаете. Другими словами, вы говорите другим DNS-серверам и кешам: «Вы можете сохранить этот ответ и использовать его в течение x минут, прежде чем проверять со мной». Недостатки происходят от этого:
- При сбое DNS неизвестный процент ваших пользователей будет кэшировать ваши данные DNS с различным количеством оставшихся TTL. До истечения срока действия TTL они могут подключаться к мертвому серверу. Есть более быстрые способы завершения аварийного переключения, чем этот.
- Из-за вышеизложенного вы склонны устанавливать TTL достаточно низким, например, 5-10 минут. Но его установка дает (очень небольшое) выигрыш в производительности и может помочь вашему DNS-распространению работать надежно, даже если в сетевом трафике есть небольшая задержка. Таким образом, использование отработки отказа на основе DNS идет против высоких TTL, но высокие TTL являются частью DNS и могут быть полезны.
Более распространенные методы получения хорошего времени работы включают в себя:
Очень небольшое количество веб-сайтов используют настройки нескольких центров обработки данных с «геобалансировкой» между центрами обработки данных.
Я думаю, что он специально пытается управлять аварийным переключением между двумя разными центрами обработки данных (обратите внимание на комментарии о разных подсетях), поэтому размещение серверов вместе / использование балансировщиков нагрузки / избыточная избыточность ему не помогут (кроме избыточных центров обработки данных. Но вы еще нужно сказать интернету, чтобы перейти к тому, который еще работает). Добавьте anycast в настройку мультицентра, и он станет защищенным от сбоев. DDoS-атаки стали настолько распространенным явлением, что теперь все центры обработки данных можно отключить (это произошло с Linode London и другими центрами обработки данных в декабре 2015 года). Поэтому использовать один и тот же провайдер в одном центре обработки данных не рекомендуется. Таким образом, несколько центров обработки данных с разными поставщиками будут хорошей стратегией, которая возвращает нас к отказоустойчивости DNS, если не существует лучшей альтернативы. Разве не существует отказоустойчивость, потому что вам нужно поддерживать работоспособность вашего сайта, когда устройство не работает / неисправно? Что хорошего в вашем отказоустойчивости, когда он находится в одной и той же сети и использует одни и те же устройства, например, маршрутизаторы?Но, эй, я построил компанию, которая предоставляет службы аварийного переключения DNS после многих лет работы для крупных компаний. Так что прими мое мнение с крошкой соли. Если вы хотите увидеть некоторые графики трафика zabbix для сайтов большого объема во время сбоя - чтобы убедиться, как именно работает отказоустойчивость DNS - напишите мне, я более чем рад поделиться.
Пока не случится какая-то проблема — разницы особой нет. А вот когда случится, то без failover'а часто происходит следующее: вы пытаетесь быстро разобраться, в чем проблема, не получается (бэкапы не разворачиваются, софт почему-то не работает как ему следует из документации, итд), а времени нет, сервера-сайты лежат, клиенты звонят, все на нервах, пытаетесь как-то починить грубо и грязно «на скотче», потом как-то вроде запускается с костылями и живет. Вы думаете, что на досуге надо будет подробнее разобраться и переделать все красиво, но нет ничего более постоянного, чем временное.
Теперь, как это происходит в красивом варианте с файловером:
- Ошибка случается
- Ошибка обнаруживается автоматически
- Рассылается оповещение
- Переводится переключение на один из резервных серверов
- Спокойно и без паники разбирается проблема, исправляется и сервер снова вводится в строй.
Будущее уже здесь!
Раньше, основная проблема, которая делала failover часто неприемлемым решением заключалась в сумме затрат на него. Либо нужно было покупать дорогие железяки (и приглашать еще более дорогих специалистов). Либо колхозить что-то сложное по гайдам (мне попадался даже вариант, когда два сервера связываются дополнительно нуль-модемным кабелем, и гоняют по нему heartbeat, чтобы в нужный момент запасной сервер узнал, и перехватил управление). Сейчас есть способы проще и бесплатные. Если у вас есть сайт с котиками — нет вам оправдания, если вы еще не реализовали для него failover!
Ну и кроме того, для failover схемы нужен еще сервер (а может быть и не один) и раньше это было большими затратами, сейчас можно взять VDSку за копейки.
Самый надежный сайт с котиками
В технической информации есть строчка “status=OK”. Иногда сервера симулируют проблемы и пишут status=ERR. Главный сервер “как бы падает” в 20 минут каждого часа (0:20, 1:20, 2:20, . ). Запасной (backup) сервер в 40 минут. Последний сервер (“sorry”-сервер) работает всегда. В 0 минут каждого часа, основной и запасной сервер “восстанавливаются”.

Если вы откроете сайт, и оставите его во вкладке — увидите, что он никогда не падает (хотя каждый отдельный сервер периодически симулирует проблему), а в случае проблемы с сервером, просто “бегает” между живыми серверами. Будет меняться картинка, имя и адрес сервера и его роль. Иногда можно поймать момент когда status=ERR (проблема уже есть, но вся схема failover еще не отработала), но уже следующее обновление покажет вам страничку с рабочего сайта.
Failover на okerr + dynamic DNS

В настройках проекта мы создали failover схему с этими индикаторами:

В схеме три индикатора (три сервера), разные по приоритетам. Главный сервер для сайта — charlie, если он не работает (не будет “status=OK” или просто недоступен), то bravo и в последнем случае — alpha. В правой части страницы показывается состояние DNS записи на разных серверах.
От падения к поднятию
По шагам, как работает эта схема:
Дополнительно
Что может okerr вообще — посмотрите на сайте презентацию. Вообще, это мониторинг (zabbix из облака), а файловер — это приятная доп.функция. Также с сайта можно без регистрации зайти в демо.
При изменении состояния индикатора — отсылается уведомление на почту или Telegram. (Мы тут посмотрели что происходит, и поняли, что, похоже, telegram — самый надежный мессенджер. Спасибо РКН за стресс-тест!) При правильной настройке okerr, любое уведомление — это либо сигнал “бросайте все, надо чинить!”, либо “отбой!”. Лишних алертов от окерра быть не должно (если они есть — надо настраивать как-то иначе). Например, для нашего котосайта сервер alpha последний и никогда не имитирует ошибку. Если он ляжет — мы должны знать. А вот остальные сервера постоянно симулируют ошибки, поэтому, чтоб не получать алерты несколько раз в час, у тех индикаторов стоит статус “тихий”.
Читайте также: