
Enter binds oracle что это
Обновлено: 30.06.2024
Oracle/PLSQL оператор EXECUTE IMMEDIATE подготавливает (анализирует) и немедленно выполняет динамический SQL-запрос или анонимный PL/SQL блок.
Основным аргументом EXECUTE IMMEDIATE является строка, содержащая SQL-запрос для выполнения. Вы можете создать строку, используя конкатенацию, или использовать предопределенную строку.
Динамическая строка может содержать любой оператор SQL (без последней точки с запятой), за исключением многострочных запросов или любой PL/SQL блок (с последней точкой с запятой).
Строка dynamic_string также может содержать заполнители, произвольные имена, которым предшествует двоеточие, для аргументов связывания bind_argument . В этом случае вы указываете, какие переменные PL/SQL соответствуют заполнителям, с помощью операторов INTO, USING и RETURNING INTO. Во время выполнения аргументы связывания заменяют соответствующие заполнители в динамической строке. Каждый заполнитель должен быть связан с аргументом связывания в предложении USING и/или предложении RETURNING INTO.
Синтаксис
Синтаксис Oracle/PLSQL оператора EXECUTE IMMEDIATE для передачи значения в переменную или строку:
EXECUTE IMMEDIATE dynamic_string[ INTO <[define_variable[, define_variable] . | record_name>]
[USING [IN | OUT | IN OUT] bind_argument ]
returning_clause;
или синтаксис Oracle/PLSQL оператора EXECUTE IMMEDIATE для передачи значения в коллекцию
EXECUTE IMMEDIATE dynamic_string[[ BULK COLLECT] INTO ]
[USING [IN | OUT | IN OUT] bind_argument]
returning_clause;
Параметры или аргументы
dynamic_string Строковый литерал, переменная или выражение, представляющее один оператор SQL или блок PL/SQL. Он должен иметь тип CHAR или VARCHAR2, а не NCHAR или NVARCHAR2. BULK COLLECT Сохраняет значения результатов в одной или нескольких коллекциях для более быстрых запросов, чем циклы с операторами FETCH. INTO Используется только для однострочных запросов, в этом разделе указываются переменные или записи, в которые извлекаются значения столбцов. Для каждого значения, полученного запросом, в предложении INTO должна быть соответствующая тип-совместимая переменная или поле. define_variable Переменная, в которой сохраняется значение выбранного столбца. record_name Пользовательская запись или запись %ROWTYPE, в которой сохраняется выбранная строка. bind_argument Выражение, значение которого передается в динамический оператор SQL, или переменная, в которой сохраняется значение, возвращаемое динамическим оператором SQL. collection_name Объявленная коллекция, в которую извлекаются значения select_item из dynamic_string . Для каждого select_item должна быть соответствующая, совместимая с типом коллекция в списке. host_array_name Массив (объявленный в хост-среде PL/SQL и переданный PL/SQL как переменная связывания), в который извлекаются значения select_item. Для каждого select_item должен быть соответствующий, совместимый с типом массив в списке. Массивы хоста должны начинаться с двоеточия. USING По умолчанию - IN. Определяет список входных и/или выходных аргументов привязки. returning_clause Возвращает значения из вставленных строк, устраняя необходимость SELECT строки после. Вы можете извлечь значения столбца в переменные или в коллекции. Вы не можете использовать предложение RETURNING для удаленной или параллельной вставки. Если инструкция не влияет ни на какие строки, значения переменных, указанных в предложении RETURNING, не определены.Примеры:
Некоторые примеры динамического SQL
Рассмотрим несколько примеров использования Oracle/PLSQL оператора EXECUTE IMMEDIATE, чтобы понять как использовать EXECUTE IMMEDIATE в Oracle/PLSQL.
Описание команд в комментариях (--).
Автор статьи – Виктор Варламов(varlamovVp18), OCP.
Оригинал статьи опубликован 07.07.2017.
Отдельное спасибо автору перевода — brutaltag.
В нашей системе подготовки отчетности обычно выполняются сотни длительных запросов, которые вызываются различными событиями. Параметрами запросов служат список клиентов и временной интервал (дневной, недельный, месячный). Из-за неравномерных данных в таблицах один запрос может выдать как одну строку, так и миллион строк, в зависимости от параметров отчета (у разных клиентов — различное количество строк в таблицах фактов). Каждый отчет выполнен в виде пакета с основной функцией, которая принимает входные параметры, проводит дополнительные преобразования, затем открывает статический курсор со связанными переменными и в конце возвращает этот открытый курсор. Параметр БД CURSOR_SHARING выставлен в FORCE.
В такой ситуации приходится сталкиваться с плохой производительностью, как в случае повторного использования плана запроса оптимизатором, так и при полном разборе запроса с параметрами в виде литералов. Связанные переменные могут вызвать неоптимальный план запроса.
В своей книге “Oracle Expert Practices” Алекс Горбачев приводит интересную историю, рассказанную ему Томом Кайтом. Каждый дождливый понедельник пользователям приходилось сталкиваться с измененным планом запроса. В это трудно поверить, но так и было:
«Согласно наблюдениям конечных пользователей, в случаях, когда в понедельник шел сильный дождь, производительность базы данных была ужасной. В любой другой день недели или же в понедельник без дождя проблем не было. Из разговора с администратором БД Том Кайт узнал, что трудности продолжались до принудительного рестарта базы данных, после чего производительность становилась нормальной. Вот такой был обходной маневр: дождливый понедельник – рестарт».
Это реальный случай, и проблема была решена совершенно без всякой магии, только благодаря отличным знаниям того, как работает Oracle. Я покажу решение в конце статьи.
Вот небольшой пример, как работают связанные переменные.
Создадим таблицу с неравномерными данными.
Другими словами, у нас есть таблица VVP_HARD_PARSE_TEST с миллионом строк, где в 10.000 случаев поле C2 = 99, 8 записей с C2 = 1, а остальные с C2 = 1000000. Гистограмма по полю С2 указывает оптимизатору Oracle об этом распределении данных. Такая ситуация известна как неравномерное распределение данных, и гистограмма может помочь выбрать правильный план запроса в зависимости от запрашиваемых данных.
Понаблюдаем за простыми запросами к этой таблице. Очевидно, что для запроса
SELECT * FROM VVP_HARD_PARSE_TEST WHERE c2 = :p
если p = 1, то наилучшим выбором будет INDEX RANGE SCAN, для случая p = 1000000 лучше использовать FULL TABLE SCAN. Запросы Query1 и Query1000000 идентичны, за исключением текста в комментариях, это сделано чтобы получить различные идентификаторы планов запроса.
Теперь посмотрим на планы запросов:
Как можно видеть, план для разных запросов создается только один раз, в момент первого выполнения (только один дочерний курсор с CHILD_NUMBER = 0 существует для каждого запроса). Каждый запрос выполняется дважды (EXECUTION = 2). Во время жесткого разбора Oracle получает значения связанных переменных и выбирает план соответственно этим значениям. Но он использует тот же самый план и для следующего запуска, несмотря на то что связанные переменные изменились во втором запуске. Используются неоптимальные планы – Query1000000 с переменной C2 = 1 использует FULL TABLE SCAN вместо INDEX RANGE SCAN, и наоборот.
Понятно, что исправление приложения и использование параметров как литералов в запросе – это самый подходящий способ решения проблемы, но он ведет к динамическому SQL с его известными недостатками. Другой путь – отключение запроса связанных переменных ( ALTER SESSION SET "_OPTIM_PEEK_USER_BINDS" = FALSE ) или удаление гистограмм (ссылка).
Одно из возможных решений — это альтернативное использование политик на доступ к данным, также известных как Virtual Private Database (детальный контроль доступа, Fine Grained Access Control, контроль на уровне строк). Это позволяет менять запросы на лету и поэтому может вызвать полный разбор плана запроса каждый раз, когда запрос использует детальный контроль доступа. Эта техника подробно описана в статье Рэндальфа Гейста. Недостатком этого метода является возрастающее число полных разборов и невозможность манипулировать планами запросов.
Посмотрите, что мы сейчас сделаем. После анализа наших данных мы решаем разбить клиентов на три категории – Большие, Средние и Маленькие (L-M-S или 9-5-1) – согласно количествам сделок или транзакций в течение года. Также количество строк в отчете строго зависит от периода: Месячный – Large, Недельный – Middle, Дневной – Small или 9-5-1. Далее решение простое – сделаем предикат политики безопасности зависящим от каждой категории и от каждого периода. Так, для каждого запроса мы получим 9 возможных дочерних курсоров. Более того, запросы с разными политиками приведут нас к одним и тем же идентификаторам запросов, это дает возможность реализовать SQL PLAN MANAGEMENT (sql plan baseline).
Теперь, если мы хотим встроить такую технологию в отчет, нам надо добавить HARD_PARSE_TABLE в запрос (это ни капельки его не испортит) и вызывать CALC_PREDICATES перед тем, как выполняется основной запрос.
Посмотрим, как эта техника может преобразить предыдущий пример:
Посмотрим на планы выполнения:
Выглядит здорово! Каждый запрос выполняется дважды, с различными дочерними курсорами и разными планами. Для параметра C2 = 1000000 мы видим FULL TABLE SCAN в обоих запросах, а для параметра C1 = 1 мы видим всегда INDEX RANGE SCAN.
Я пытаюсь запустить запрос от разработчика sql, и у запроса есть переменные ( :var ). у меня проблема с переменными даты.
Я использовал все возможные комбинации для форматирования даты с помощью функции to_date() . Каждый раз попадая ниже исключения:
Извините не могу разместить изображение здесь
Я так много раз пытался показать текущую дату в моем диалоге выбора даты, но потерпел неудачу . Он показывает 1/1/1990 . я уже следую некоторому ответу от stack overflow, но они, к сожалению, не работают для меня. кто-нибудь может объяснить мне код для отображения текущей даты в диалоге.
Попробуйте изменить свой запрос, чтобы он был:
затем, когда появится запрос, введите '20-JAN-2010' .
Просто копирую ответ с форума сообщества Oracle:
Вы должны иметь возможность вводить даты, соответствующие вашим настройкам NLS_DATE_FORMAT .
например , если NLS_DATE_FORMAT равно DD-MON-YYYY , вы можете ввести 24-jan-2011 на сегодняшнюю дату.
Работал на меня.
Попробуйте использовать переменную подстановки. Например:
sql разработчик попросит вас ввести значение переменной подстановки, которое вы можете использовать в качестве значения даты (например, sysdate или to_date('20140328', 'YYYYMMDD') или любую другую дату, которую вы пожелаете).
а затем введите что-то вроде 01.02.2017 (без ' ) в качестве значения :my_var
Это невозможно. Вероятно, потому, что у SQL plus его нет.
В запросе укажите дату в приведенном ниже формате
и при выполнении запроса от разработчика sql укажите значение параметра var bind как 29-DEC-1995
обратите внимание, что вы не должны использовать кавычки. Это неявно сделано разработчиком SQL. Счастливого Кодирования!
Я не понимаю, почему (даже если бы я мог себе представить. ), но:
- этот оператор select работает:: date_var = 09122019
select * from t where date_field = to_date(:date_var,'ddmmyyyy');
- аналогичная инструкция delete или update не работает:: date_var = 09122019
delete t where date_field = to_date(:date_var,'ddmmyyyy');
с этой ошибкой: ORA-01847: день месяца должен быть между 1 и последним днем месяца
Используя разделительные символы, такие как ' / ' или '.', удаление работает:: date_var = 09/12/2019
delete t where date_field = to_date(:date_var,'dd/mm/yyyy');
Похожие вопросы:
Я подключил Stata через ODBC к базе данных SQL. Моя проблема заключается в том, что Stata считывает переменные даты как строки. В SQL у них есть формат даты. Как я могу импортировать переменную даты.
У меня был диалог выбора даты, в котором мне нужно было показать текущую дату в этом диалоге, а предыдущие даты должны быть отключены и должны быть показаны в диалоге выбора даты. В диалоге выбора.
Я так много раз пытался показать текущую дату в моем диалоге выбора даты, но потерпел неудачу . Он показывает 1/1/1990 . я уже следую некоторому ответу от stack overflow, но они, к сожалению, не.
Я видел привязки как аргумент во многих методах, но без какой-либо документации. например , исходный код Rails def find_by_sql(sql, binds = [], preparable: nil, &block) result_set =.
Я использую новый Dagger2 (ver 2.11) и использую новые функции , такие как AndroidInjector и ContributesAndroidInjector . У меня есть компонент деятельности , @Module abstract class.
Я хочу использовать переменную даты (DD/MM/YYYY HH:MI:SS ) в pl/sql. я использую следующий код, но он не работает : BEGIN declare dateMig date ; dateMig := to_date('19/05/2017 05:05:00', 'DD/MM/YYYY.
Не удалось открыть инструменты разработчика в модальном диалоге в IE11 на windows 10. Недавно я обновился до Windows10, я сделал прикрепленные настройки в моем IE, но все равно он не работает.
Я просто хочу определить, а затем использовать переменную в Oracle SQL в SQL Developer (версия 18.1.0.095) (ПРЕДЫСТОРИЯ: У нас есть некоторые устаревшие скрипты production SQL, которые периодически.
Что касается значений datetime, есть ли кодировка, из которой я могу выбрать SQL Разработчик, что при экспорте в Excel он форматируется как datetime ? . Я попробовал UTF-8 & UTF8 . То, что.
Хотя переменные связывания и улучшают производительность и масштабирование за счет сокращения времени, затрачиваемого на выполнение синтаксического анализа, и объема используемой памяти, применение литеральных значений, а не значений связывания для переменных в действительности приводит к получению более качественных планов выполнения. При принудительном разделении курсора в базе данных в результате установки для параметра CURSOR_SHARING значения EXACT или SIMILAR, некоторые SQL-операторы могут получать квазиоптимальные планы выполнения по каким-то из значений переменных связывания. CBO может создать квазиоптимальный план при считывании значений переменных связывания и принятии решения о том, что значения переменных связывания, используемые в первых подлежащих помещению в разделяемый пул SQL-операторах, не отражают истинных значений переменной. Разработчики и администраторы базы данных иногда прибегают к установке неофициального параметра инициализации _OPTIM_PEEK_USER_BINDS (ALTER SESSION SET "_optim_peek_user_binds"=FALSE;) для лишения базы данных возможности считывать значения переменных связывания. Адаптивное разделение курсора (adaptive cursor sharing) представляет собой куда более элегантный способ для предотвращения создания оптимизатором квазиоптимальных планов выполнения из-за считывания значений переменных связывания.
Oracle полагается на свою технологию “считывания значений переменных связывания” (bind peeking) при первом синтаксическом анализе SQL-оператора. Оптимизатор всегда подвергает новый оператор полному синтаксическому анализу и считывает значения переменных связывания для получения представления о том, как они выглядят.
Первоначальные значения переменных связывания, которые он видит на этапе считывания, оказывают серьезное влияние на выбираемый для оператора план выполнения. Если, например, на этапе считывания эти первоначальные значения диктуют использовать индекс, Oracle будет продолжать использовать индекс, даже если последующие значения будут в действительности диктовать использовать вместо этого операцию полного сканирования таблицы. Из-за того, что считывание значений переменных связывания фактически приводит к созданию квазиоптимальных планов выполнения в подобных случаях, жестко закодированные значения переменных оказываются предпочтительнее значений переменных связывания.
Как показывает вышесказанное, разделение курсора за счет использования переменных связывания может не всегда приводить к получению наилучших (оптимальных) планов выполнения. Использование жестко закодированных значений для переменных на самом деле может давать более оптимальные планы выполнения, чем применение переменных связывания, особенно при работе с очень несимметричными данными. В качестве попытки устранить конфликт между разделением курсора с помощью переменных связывания и оптимизацией запросов Oracle и предлагает механизм адаптивного разделения курсора. В случае применения этого механизма, всякий раз, когда база данных будет вычислять, что дешевле создать новый план выполнения для оператора, чем повторно использовать те же самые курсоры, для оператора будут генерироваться новые дочерние курсоры. Oracle будет все равно стараться сводить количество дочерних курсоров к минимуму и пользоваться преимуществами механизма разделения курсоров, однако пытаться использовать курсоры повторно больше не будет.
Совет. Механизм адаптивного разделения курсора работает автоматически и всегда включен. Отключить его никак нельзя.
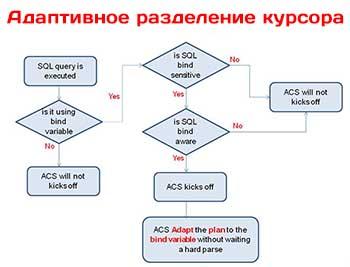
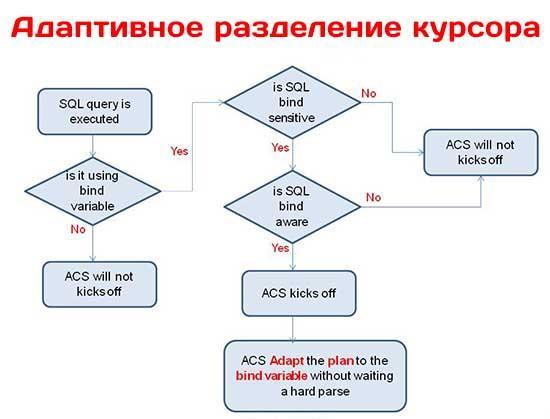
Как работает механизм адаптивного разделения курсора
В работе механизма адаптивного разделения курсора важную роль играют две концепции: чувствительность курсора к связыванию и осведомленность курсора о связывании. Если изменение значений переменной связывания ведет к созданию других планов выполнения, курсор называют чувствительным к связыванию (bind-sensitive). Всякий раз, когда база данных выясняет, что требуется создавать новые планы выполнения из-за того, что значения переменной связывания сильно варьируются, переменная признается чувствительной к связыванию. После того, как база данных помечает курсор как являющийся чувствительным к связыванию, он начинает называться осведомленным о связывании (bind-aware).
Важно! Механизм адаптивного разделения курсора работает независимо от обычного механизма разделения курсора.
Ниже приведен пример, демонстрирующий работу механизма адаптивного разделения курсора. Предположим, что в базе данных несколько раз выполняется следующий запрос:
Как видно, в этом SQL-операторе присутствуют две переменных связывания: SALARY и DEPARTMENT_ID.
При самом первом выполнении нового SQL-оператора база данных считывает значения переменных связывания, вычисляет степень избирательности предиката и делает курсор чувствительным к связыванию. Она создает каждый план выполнения с набором значений избирательности наподобие (0.25, 0.0050), которые свидетельствуют о диапазоне избирательности плана выполнения. Если новые значения переменных связывания подпадают под этот диапазон, оптимизатор использует данный план выполнения повторно, а если нет, то создает новый план выполнения.
На следующем этапе выясняется, является ли курсор осведомленным о связывании. После выполнения первого полного синтаксического анализа база данных далее выполняет только частичный синтаксический анализ выполняемого повторно оператора и сравнивает его статистику со статистикой выполнения полного синтаксического анализа. Если она решает, что курсор осведомлен о связывании, она применяет технологию сопоставления с осведомленным о связывании курсором, когда выполняет запрос снова. Если новая пара значений переменных связывания подпадает под диапазон избирательности какого-то плана выполнения, база данных просто использует повторно этот план; в противном случае она снова проводит полный синтаксический анализ и, соответственно, генерирует новый дочерний курсор с другим планом. Если новое выполнение приводит к получению похожего плана, база данных производит слияние дочерних курсоров, а это значит, что если значения переменных связывания являются приблизительно одинаковыми, операторы будут разделять один и тот же план выполнения.
Осуществление мониторинга за механизмом адаптивного разделения курсора
В представлении V$SQL содержится два столбца с именами IS_BIND_SENSITIVE и IS_BIND_AWARE, которые помогают осуществлять мониторинг за работой механизма
адаптивного разделения курсора в базе данных.
В частности, столбец IS_BIND_SENSITIVE позволяет узнать, является ли курсор чувствительным к связыванию, а столбец IS_BIND_AWARE — пометила ли база данных курсор как осведомленный о связывании. Например, ниже приведен запрос, сообщающий, какие SQL-операторы чувствительны к связыванию, а какие — осведомленными о нем:
В выводе этого запроса столбец IS_BIND_SENSITIVE показывает, будет ли база данных генерировать разные планы выполнения на основе значений переменных связывания. Любой курсор, для которого в столбце IS_BIND_SENSITIVE отображается значения Y, является кандидатом на изменение плана выполнения. Когда база данных планирует использовать множество планов выполнения для оператора на основе наблюдаемых значений в переменных связывания, она отображает для этого оператора значение Y в столбце IS_BIND_AWARE. Это свидетельствует об осознании оптимизатором того, что разные значения переменных связывания будут вести к разными схемам данных, что требует подвергания оператора полному синтаксическому анализу при следующем выполнении. Для принятия решения о том, следует ли менять план выполнения, база данных просчитывает несколько следующих выполнений SQL-оператора. Если она после этого приходит к выводу о необходимости изменения плана выполнения оператора, курсор помечается как осведомленный о связывании, а в столбец IS_BIND_AWARE для этого оператора помещается значение Y. Осведомленный о связывании курсор представляет собой такой курсор, для которого база данных на самом деле изменила план выполнения на основании обнаруженных значений в переменных связывания.
Ниже перечислены представления, которые можно использовать для управления механизмом адаптивного разделения курсора.
- V$SQL_CS_HISTOGRAM. Это представление показывает, как распределяется количество выполнений в виде гистограммы хронологии выполнений.
- V$SQL_CS_SELECTIVITY. Это представление показывает, как выглядят диапазоны избирательности, хранящиеся в курсорах для предикатов с переменными связывания.
- V$SQL_CS_STATISTICS. В этом представлении содержатся касающиеся выполнений статистические данные курсора с различными собранными базой данных наборами значений переменных связывания.
Регулярное повторное создание таблиц и индексов
В базе данных с большим количеством DML-операций индексы со временем могут становиться несбалансированными. Поэтому очень важно регулярно создавать такие индексы повторно, чтобы запросы могли выполняться быстрее. Повторно создавать индексы может быть необходимо, если нужно изменить их характеристики хранения или консолидировать их и тем самым сократить фрагментацию. Применяйте для повторного создания индекса оператор ALTER INDEX. REBUILD, если старый индекс должен оставаться доступным во время создания нового. (В качестве альтернативного варианта можно сначала удалить индекс, а потом воссоздавать его заново.)
При повторном создании индексов следует включить оператор COMPUTE STATISTICS, чтобы после воссоздания не приходилось отдельно собирать статистические данные. Разумеется, в среде, работающей 24 часа в сутки 7 дней в неделю, необходимо использовать оператор ALTER INDEX. REBUILD ONLINE, чтобы не оказывать влияния на доступ пользователей к базе данных. Очень важно, чтобы при воссоздании индекса в оперативном режиме таблицы не подвергались массе DML-операций, поскольку механизм выполнения этой операции в оперативном режиме при таких обстоятельствах может не работать так, как ожидается. На самом деле он может даже внезапно начать мешать выполнению одновременных обновлений пользователями.
Освобождение неиспользуемого пространства
Утилита Segment Advisor запускается автоматически во время запланированного ночного процесса обслуживания и выдает рекомендации касательно тех объектов, которые можно сжать, чтобы освободить неэффективно используемое пространство. Главное запомнить, что для применения этой утилиты необходимо использовать локально управляемые табличные пространства с опцией Automatic Segment Space Management (Автоматическое управление пространством в сегментах). Сжатие сегментов позволяет экономить пространство, и, что еще более важно, улучшать производительности за счет понижения маркера максимального уровня заполнения сегментов и устранения неизбежной фрагментации, которая происходит со временем в объектах, подвергающихся большому количеству операций обновления и удаления.
Кэширование небольших таблиц в памяти
Если приложение не использует данные таблицы повторно на протяжении длительного времени, эти данные могут удаляться из SGA и снова нуждаться в считывании с диска. Небольшие таблицы можно безопасно закреплять в кэше буферов следующим образом:
Читайте также: