Файлы lru что это
Обновлено: 07.07.2024
Почему "Наименее используемая" лучше, чем FIFO в отношении файлов страниц?
спросил(а) 2010-01-13T19:32:00+03:00 11 лет, 10 месяцев назадЕсли вы имеете в виду разгрузку страниц памяти на диск - если ваш процесс часто обращается к странице, вы действительно не хотите, чтобы он был выгружен на диск, даже если он был первым, к которому вы обращались. С другой стороны, если вы не получили доступ к странице памяти в течение нескольких дней, вряд ли вы это сделаете в ближайшем будущем.
Если это не то, что вы имеете в виду, отредактируйте свой вопрос, чтобы предоставить более подробную информацию.
ответил(а) 2010-01-13T19:36:00+03:00 11 лет, 10 месяцев назадНет единого алгоритма кеша, который всегда будет хорошо, потому что это требует совершенного знания будущего. (И если вы знаете, где это получить. ). Доминирование LRU в дизайне кэша VM является результатом долгой истории поведения системы измерения. Учитывая реальные рабочие нагрузки, LRU работает очень хорошо в очень большую часть времени. Тем не менее, не так сложно построить ссылочную строку, для которой FIFO будет иметь превосходную производительность по сравнению с LRU.
Рассмотрим линейную развертку по большому адресному пространству, значительно большему, чем доступная доступная для просмотра реальная память. LRU основывается на предположении, что "то, что вы недавно затронули, вы, вероятно, снова коснетесь", но линейная развертка полностью нарушает это предположение. Вот почему некоторые операционные системы позволяют программам сообщать ядру об их контрольном поведении - одним из примеров является сборка мусора "mark and sweep", типичная для классических интерпретаторов LISP. (И главный драйвер для работы над более современными GC, такими как "поколение".)
Другим примером является таблица символов в некотором античном макропроцессоре (STAGE2). Бинарное дерево выполняется с корнем для каждого символа, а оценка строки выполняется в стеке. Оказалось, что сокращение доступных страниц с помощью "проводки вниз" на корневой странице дерева символов, а нижняя страница стека значительно улучшила скорость сбоев страниц. Кэш был крошечным, и он сильно бушевал, всегда выталкивая две наиболее часто используемые страницы, потому что кеш был меньше расстояния между ссылками на эти страницы. Таким образом, небольшой кеш работал лучше, но ТОЛЬКО, потому что эти два кадра страниц, украденные из кеша, были использованы с умом.
Сеть всего этого заключается в том, что LRU является стандартным ответом, поскольку он обычно довольно хорош для реальных рабочих нагрузок в системах, которые не являются ужасно перегруженными (VM много раз имеет реальную память), и это подтверждается годами тщательных измерений, Однако,
вы, безусловно, можете найти случаи, когда альтернативное поведение будет выше. Вот почему измерение реальных систем важно.

Эта публикация – незначительно сокращенный перевод статьи Сантьяго Валдаррама Caching in Python Using the LRU Cache Strategy. Переведенный текст также доступен в виде блокнота Jupyter.
Кэширование – один из подходов, который при правильном использовании значительно ускоряет работу и снижает нагрузку на вычислительные ресурсы. В модуле стандартной библиотеки Python functools реализован декоратор @lru_cache , дающий возможность кэшировать вывод функций, используя стратегию Least Recently Used (LRU, «вытеснение давно неиспользуемых»). Это простой, но мощный метод, который позволяет использовать в коде возможности кэширования.
В этом руководстве мы рассмотрим:
- какие стратегии кэширования доступны и как их реализовать с помощью декораторов;
- что такое LRU и как работает этот подход;
- как повысить производительность программы с помощью декоратора @lru_cache ;
- как расширить функциональность декоратора @lru_cache и прекратить кэширование по истечении определенного интервала времени.
Кэширование – это метод оптимизации хранения данных, при котором операции с данными производятся эффективнее, чем в их источнике.
Как поступит программа, если читатель решит сравнить пару статей и станет многократно между ними перемещаться? Без кэширования приложению придется каждый раз получать одно и то же содержимое. В этом случае неэффективно используется и система пользователя, и сервер со статьями, на котором создается дополнительная нагрузка.
Лучшим подходом после получения статьи было бы хранить контент локально. Когда пользователь в следующий раз откроет статью, приложение сможет открыть контент из сохраненной копии, вместо того, чтобы заново загружать материал из источника. В информатике этот метод называется кэшированием.
В Python можно реализовать кэширование, используя словарь. Вместо того, чтобы каждый раз обращаться к серверу, можно проверять, есть ли контент в кэше, и опрашивать сервер только если контента нет. В качестве ключа можно использовать URL статьи, а в качестве значения – ее содержимое:
Примечание. Для запуска этого примера у вас должна быть установлена библиотека requests :
Хотя вызов get_article() выполняется дважды, статья с сервера загружается лишь один раз. После первого доступа к статье мы помещаем ее URL и содержимое в словарь cache . Во второй раз код не требует повторного получения элемента с сервера.
В этой простой реализации кэширования закралась очевидная проблема: содержимое словаря будет неограниченно расти: чем больше статей открыл пользователь, тем больше было использовано места в памяти.
Чтобы обойти эту проблему, нам нужна стратегия, которая позволит программе решить, какие статьи пора удалить. Существует несколько различных стратегий, которые можно использовать для удаления элементов из кэша и предотвращения превышения его максимального размера. Пять самых популярных перечислены в таблице.
| Стратегия | Какую запись удаляем | Эти записи чаще других используются повторно |
| First-In/First-Out (FIFO) | Самая старая | Новые |
| Last-In/First-Out (LIFO) | Самая недавняя | Старые |
| Least Recently Used (LRU) | Использовалась наиболее давно | Недавно прочитанные |
| Most Recently Used (MRU) | Использовалась последней | Прочитанные первыми |
| Least Frequently Used (LFU) | Использовалась наиболее редко | Использовались часто |
Кэш, реализованный посредством стратегии LRU, упорядочивает элементы в порядке их использования. Каждый раз, когда мы обращаемся к записи, алгоритм LRU перемещает ее в верхнюю часть кэша. Таким образом, алгоритм может быстро определить запись, которая дольше всех не использовалась, проверив конец списка.
На следующем рисунке показано представление кэша после того, как пользователь запросил статью из сети.

Процесс заполнения LRU-кэша, шаг 1
Статья сохраняется в последнем слоте кэша перед тем, как будет передана пользователю. На следующем рисунке показано, что происходит, когда пользователь запрашивает следующую статью.

Процесс заполнения LRU-кэша, шаг 2
Вторая статья занимает последний слот, перемещая первую статью вниз по списку.
Стратегия LRU предполагает: чем позже использовался объект, тем больше вероятность, что он понадобится в будущем. Алгоритм сохраняет такой объект в кэше в течение максимально длительного времени.
Один из способов реализовать кэш LRU в Python – использовать комбинацию двусвязного списка и хеш-таблицы. Головной элемент двусвязного списка указывает на последнюю запрошенную запись, а хвостовой – на наиболее давно использовавшуюся.
На рисунке ниже показана возможная структура реализации кэша LRU.

Схема реализации кэширования
Используя хеш-таблицу, мы обеспечиваем доступ к каждому элементу в кэше, сопоставляя каждую запись с определенным местом в двусвязном списке. При этом доступ к недавно использовавшемуся элементу и обновление кэша – это операции, выполняемые за константное время (то есть с временной сложностью алгоритма 𝑂 ( 1 ) .
Примеры временной сложности различных функций Python рассматривались на proglib в статье «Сложность алгоритмов и операций на примере Python».Начиная с версии 3.2, для реализации стратегии LRU Python включает декоратор @lru_cache .
Декоратор @lru_cache за кулисами использует словарь. Результат выполнения функции кэшируется под ключом, соответствующим вызову функции и предоставленным аргументам. То есть чтобы декоратор работал, аргументы должны быть хешируемыми.
Наглядное представление алгоритма: перепрыгиваем ступеньки
Представим, что мы хотим определить число способов, которыми можем достичь определенной ступеньки на лестнице. Сколько есть способов, например, добраться до четвертой ступеньки, если мы можем переступить-перепрыгнуть 1, 2, 3 (но не более) ступеньки? На рисунке ниже представлены соответствующие комбинации.

Под каждым из рисунков приведен путь с указанием числа ступенек, преодоленных за один прыжок. При этом количество способов достижения четвертой ступеньки равно общему числу способов, которыми можно добраться до третьей, второй и первой ступенек:

Получается, что решение задачи можно разложить на более мелкие подзадачи. Чтобы определить различные пути к четвертой ступеньке, мы можем сложить четыре способа достижения третьей ступеньки, два способа достижения второй ступеньки и единственный способ для первой. То есть можно использовать рекурсивный подход.
Опишем программно рекурсивное решение в точности, как мы его сейчас видим:
Код работает для 4 ступенек. Давайте проверим, как он подсчитает число вариантов для лестницы из 30 ступенек.
Получилось свыше 53 млн. комбинаций. Однако когда мы искали решение для тридцатой ступеньки, сценарий мог длиться довольно долго.
Измерим, как долго длится выполнение кода.
Для этого мы можем использовать модуль Python timeit или соответствующую команду в блокноте Jupyter.
Количество секунд зависит от характеристик используемого компьютера. В моей системе расчет занял 3 секунды, что довольно медленно для всего тридцати ступенек. Это решение можно значительно улучшить c помощью мемоизации.
Один из примеров мемоизации рассматривался в статье«Python и динамическое программирование на примере задачи о рюкзаке».Наша рекурсивная реализация решает проблему, разбивая ее на более мелкие шаги, которые дополняют друг друга. На следующем рисунке показано дерево для семи ступенек, в котором каждый узел представляет определенный вызов steps_to() :

Дерево вызовов функции step_to()
Можно заметить, что алгоритму приходится вызывать steps_to() с одним и тем же аргументом несколько раз. Например, steps_to(5) вычисляется два раза, steps_to(4) – четыре раза, steps_to(3) – семь раз и т. д. Вызов одной и той же функции несколько раз запускает вычисления, в которых нет необходимости – результат всегда один и тот же.
Чтобы решить эту проблему, мы можем использовать мемоизацию: мы сохраняем в памяти результат, полученный для одних и тех же входных значений и затем возвращаем при следующем аналогичном запросе. Прекрасная возможность применить декоратор @lru_cache !
Если вы незнакомы с концепцией декораторов, но хотите глубже разобраться в вопросе, просто прочитайте материал«Всё, что нужно знать о декораторах Python» (она также адаптирована в форматеJupyterи Colab). Для наших задач достаточно знать, что это функции-обертки, которые позволяют модифицировать поведение функций и классов. Чтобы применить декоратор, достаточно объявить его перед определением функции.Импортируем декоратор из модуля functools и применим к основной функции.
В Python 3.8 и выше, если вы не указываете никаких параметров, можно использовать декоратор @lru_cache без скобок. В более ранних версиях необходимо добавить круглые скобки: @lru_cache() .От единиц секунд к десяткам наносекунд – потрясающее улучшение, обязанное тем, что за кулисами декоратор @lru_cache сохраняет результаты вызова steps_to() для каждого уникального входного значения.
Подключив декоратор @lru_cache , мы сохраняем каждый вызов и ответ в памяти для последующего доступа, если они потребуются снова. Но сколько таких комбинаций мы можем сохранить, пока не иссякнет память?
У декоратора @lru_cache есть атрибут maxsize , определяющий максимальное количество записей до того, как кэш начнет удалять старые элементы. По умолчанию maxsize равен 128. Если мы присвоим maxsize значение None , то кэш будет расти без всякого удаления записей. Это может стать проблемой, если мы храним в памяти слишком много различных вызовов.
Применим @lru_cache с использованием атрибута maxsize и добавим вызов метода cache_info() :
Мы можем использовать информацию, возвращаемую cache_info() , чтобы понять, как работает кэш, и настроить его, чтобы найти подходящий баланс между скоростью работы и объемом памяти:
- hits=52 – количество вызовов, которые @lru_cache вернул непосредственно из памяти, поскольку они присутствовали в кэше;
- misses=30 – количество вызовов, которые взяты не из памяти, а были вычислены (в случае нашей задачи это каждая новая ступень);
- maxsize=16 – это размер кэша, который мы определили, передав его декоратору;
- currsize=16 – текущий размер кэша, в этом случае кэш заполнен.
Перейдем от учебного примера к более реалистичному. Представьте, что мы хотим отслеживать появление на ресурсе Real Python новых статей, содержащих в заголовке слово python – выводить название, скачивать статью и отображать ее объем (число символов).
Real Python предоставляет протокол Atom, так что мы можем использовать библиотеку feedparser для анализа канала и библиотеку requests для загрузки содержимого статьи, как мы это делали раньше.
Скрипт будет работать непрерывно, пока мы не остановим его, нажав [Ctrl + C] в окне терминала (или не прервем выполнение в Jupyter-блокноте).
Код загружает и анализирует xml-файл из RealPython. Далее цикл перебирает первые пять записей в списке. Если слово python является частью заголовка, код печатает заголовок и длину статьи. Затем код «засыпает» на 5 секунд, после чего вновь запускается мониторинг.
Мы можем реализовать описанную идею в новом декораторе, который расширяет @lru_cache . Кэш должен возвращать результат на запрос только, если срок кэширования записи еще не истек – в обратном случае результат должен забираться с сервера. Вот возможная реализация нового декоратора:
Декоратор @timed_lru_cache реализует функциональность для оперирования временем жизни записей в кэше (в секундах) и максимальным размером кэша.
Код оборачивает функцию декоратором @lru_cache . Это позволяет нам использовать уже знакомую функциональность кэширования.
Перед доступом к записи в кэше декоратор проверяет, не наступила ли дата истечения срока действия. Если это так, декоратор очищает кэш и повторно вычисляет время жизни и срок действия. Время жизни распространяется на кэш в целом, а не на отдельные статьи.
Теперь мы можем использовать новый декоратор @timed_lru_cache с функцией monitor() , чтобы предотвратить скачивание с сервера содержимого статьи при каждом новом запросе. Собрав код в одном месте, получим следующий результат:
В приведенном примере скрипт пытается получить доступ к статьям каждые 5 секунд, а срок действия кэша истекает раз в минуту.
Кэширование – важный метод оптимизации, повышающий производительность любой программной системы. Понимание того, как работает кэширование, является фундаментальным шагом на пути к его эффективному включению в программный код.
В этом уроке мы кратко рассмотрели:
- какие бывают стратегии кэширования;
- как работает LRU-кэширование в Python;
- как использовать декоратор @lru_cache ;
- как рекурсивный подход в сочетании с кэшированием помогает достаточно быстро решить задачу.
Следующим шагом к реализации различных стратегий кэширования в ваших приложениях может стать библиотека cachetools, предоставляющая особые типы данных и декораторы, охватывающие самые популярные стратегии кэширования.
Сам апплет не предоставляет механизма кэширования, такого как файловая LRU. Сделать наш План художника Картинки генерируются быстрее.Мы разработали небольшой программный файл для кода, связанного с хранилищем LRU. Таким образом, нам не нужно повторно загружать материалы для рисования, которые могут использоваться часто, что значительно увеличивает скорость рисования.
Кэш апплета разделен на две части: кеш данных и кеш файлов. Файловый кеш делится на временный файловый кеш и локальное файловое хранилище. Размер локального файлового хранилища ограничен 10 МБ.
Кэш данных
Мы можем использовать набор асинхронных и синхронных методов, предоставляемых апплетом, для добавления, удаления и проверки структурированных данных. Предел хранения одной и той же мини-программы для одного и того же пользователя WeChat составляет 10 МБ. Если места недостаточно, LRU будет выполняться на уровне апплета, то есть область кэша данных апплета, которая не часто используется, будет полностью очищена.
Подробности см. В официальном документе WeChat:
Примечание. Кэш данных используется совместно в пробной версии, версии для разработки и онлайн-версии и не будет изолирован.
Временный кеш файла
Однако нет никаких объяснений по поводу ограничения размера хранилища, поэтому теоретически, независимо от размера файла, он может быть временно кэширован. Конечно, если он слишком большой, это обязательно вызовет некоторые магические ошибки.
Локальное хранилище
После получения временного файла мы можем сохранить временный файл в локальном пространстве, вызвав интерфейс wx.saveFile, а объем локального хранилища ограничен 10 МБ. Если хранилище заполнено, следующие файлы не могут быть успешно сохранены, и будет сообщено об ошибке, превышающей максимальный предел хранилища.
Что нам нужно сделать сейчас, так это открыть пространство в этом локальном хранилище в качестве хранилища для наших загружаемых файлов.Из-за ограниченного пространства нам необходимо выполнить управление LRU в этом пространстве.
Информацию об интерфейсах, связанных с локальным хранилищем, см. В следующих документах:
Примечание. После успешного вызова временного файла saveFile путь к временному файлу становится недействительным. Не забывайте помнить.
Существует ограничение в 10 МБ для локального хранилища апплета, но нет LRU.Теперь нам нужно объединить три метода хранения апплета, упомянутых выше, чтобы реализовать набор механизмов LRU для загрузки файла апплета.
Дизайн структуры данных
Среди них мы используем загруженный URL-адрес в качестве ключа. Вышеупомянутая структура данных будет существовать в области кэша данных (позже мы будем называть эту область областью хранения) и будет считана из хранилища в память при создании загрузчика. Будущие файловые операции также будут синхронизированы с файловой информацией, записанной в хранилище в реальном времени.
Вы можете понять, что основная информация о файле хранится в хранилище, а путь эквивалентен указателю на фактический файл.
Общий дизайн процесса
Отказоустойчивость
Поскольку хранилище и файловые операции являются асинхронными, между ними могут быть несоответствия. Здесь есть два несоответствия
Первый тип заключается в том, что определенная файловая информация хранилища была удалена, но сам файл не был удален из-за магической ошибки. Кроме того, файл добавлен успешно, но хранилище не было добавлено успешно.
Во-вторых, не удалось удалить информацию о файле в хранилище, но файл был удален.
Вышеупомянутые два имеют разную природу, поэтому к ним нужно относиться по-разному. Для первого типа пространство хранения файла будет несовместимо с информацией о файле, записанной в хранилище, то есть будут случайные файлы (не отслеживаемые хранилищем).
Второй тип эквивалентен существованию нулевого указателя, которого абсолютно необходимо избегать, потому что он заставит вас использовать несуществующий файл. Непосредственно приведет к серьезным ошибкам.
Принимая во внимание два вышеупомянутых особых случая, выполняется следующая отказоустойчивая обработка. Прежде всего, мы должны убедиться, что операция удаления файла должна выполняться после успешного сохранения. Это гарантирует, что второй тип не ошибется.
И для первого вида бесплатных файлов. Мы обработаем это во время saveFile. Если есть свободные файлы, это в конечном итоге приведет к несогласованным расчетам общего размера нашего пространства. Это может в конечном итоге привести к тому, что наша внешняя логика будет думать, что его можно сохранить, но фактическое пространство для хранения заполнено. Это приведет к тому, что saveFile сообщит об ошибке. После ошибки saveFile, независимо от того, что Независимо от причины, мы все опустошили весь контент, связанный с хранилищем этой стратегии, и начали заново. Поскольку у нас всегда есть карманы tempFilePath, даже если это произойдет, это не повлияет на нормальное использование пользователями. Это лишь немного повлияет на работу пользователя (в конце концов, предыдущего кеша нет).
Примечание. Причина, по которой первый случай не гарантируется так же, как и второй случай, заключается в том, что я не думаю, что есть необходимость тратить производительность на редкие сценарии ошибок, которые влияют на взаимодействие с пользователем. Пока мы делаем хорошую работу, даже если эта ошибочная ситуация действительно возникает, вся система не вызовет проблем и будет по-прежнему использоваться в обычном режиме.
У мини-программ много подводных камней. Опыт работы многих небольших программ на рынке не очень хороший. Следовательно, чтобы создать высокопроизводительную небольшую программу, нам нужно потратить много времени, чтобы попытаться сделать ошибки. Ступайте на яму больше, чем жизнь, и не жалейте денег.

Кэш - это временное хранилище для данных, которые с наибольшей вероятностью могут быть повторно запрошены. Загрузка данных из кэша осуществляется быстрее, чем из хранилища с исходными данными, но и его объём существенно ограничен.
Алгоритмы кэширования
Алгоритмы кэширования - это подробный список инструкций, который указывает, какие элементы следует отбрасывать в кэш. Их еще называют алгоритмами вытеснения или политиками вытеснения.
Когда кэш заполнен, алгоритм должен выбрать, какую именно запись следует из него удалить, чтобы записать новую, более актуальную информацию.
Least recently used - LRU (Вытеснение давно неиспользуемых)
LRU - это алгоритм, при котором вытесняются элементы, которые дольше всего не запрашивались. Соответственно, необходимо хранить время последнего запроса к элементу. И как только кэш становится заполненным, необходимо вытеснить из него элемент, который дольше всего не запрашивался.
Общая реализация этого алгоритма требует сохранения «бита возраста» для элемента и за счет этого происходит отслеживание наименее используемых элементов. В подобной реализации, при каждом обращении к элементу меняется его «возраст».

LRU на самом деле является семейством алгоритмов кэширования, в которое входит 2Q, а также LRU/K.
Для реализации понадобятся две структуры данных:
- Хеш-таблица, которая будет хранить закэшированные значения.
- Очередь, которая будет хранить приоритеты элементов и выполнять следующие операции:
- Добавить пару значение и приоритет.
- Извлечь (удалить и вернуть) значение с наименьшим приоритетом.
- Проверяем, есть ли значение в кэше:
- Если значение уже есть, то обновляем время последнего к нему запроса и возвращаем значение.
- Если значения нет в кэше - вычисляем его.
- Если кэш заполнен, то вытесняем самый старый элемент.
Достоинства:
- константное время выполнения и использование памяти.
Недостатки:
- алгоритм не учитывает ситуации, когда к определенным элементам обращаются часто, но с периодом, превышающим размер кэша (т.е. элемент успевает покинуть кэш).
Псевдо-LRU - PLRU
PLRU - это алгоритм, который улучшает производительность LRU тем, что использует приблизительный возраст, вместо поддержания точного возраста каждого элемента.
Most Recently Used - MRU (Наиболее недавно использовавшийся)
MRU - алгоритм, который удаляет самые последние использованные элементы в первую очередь. Он наиболее полезен в случаях, когда чем старше элемент, тем больше обращений к нему происходит.
Least-Frequently Used - LFU (Наименее часто используемый)
LFU - алгоритм, который подсчитывает частоту использования каждого элемента и удаляет те, к которым обращаются реже всего.
В LFU каждому элементу присваивается counter - счётчик. При повторном обращении к элементу его счётчик увеличивается на единицу. Таким образом, когда кэш заполняется, необходимо найти элемент с наименьшим счётчиком и заменить его новым элементом. Если же все элементы в кэше имеют одинаковый счётчик, то в этом случае вытеснение осуществляется по методу FIFO: первым вошёл - первым вышел.
Недостатки:
- много обращений к элементу за короткое время накручивает счётчик и в результате элемент зависает в кэше.
- алгоритм не учитывает “возраст” элементов.
Multi queue - MQ (Алгоритм многопоточного кэширования)
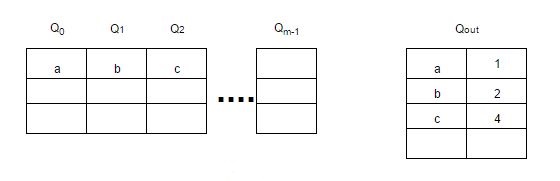
MQ - алгоритм, использующий несколько LRU очередей - Q0, Q1, …, Qn, между которыми элементы ранжируются/перемещаются в зависимости от частоты обращения к ним.
В дополнение к очередям используется буфер “истории” - Qout, где хранятся все идентификаторы элементов со счётчиками (частота обращения к элементу). При заполнении Qout удаляется самый старый элемент.
Элементы остаются в LRU очередях в течение заданного времени жизни, которое динамически определяется специальным алгоритмом.
Если к очереди не ссылались в течение её времени жизни, то её приоритет понижается с Qi до Qi-1 или удаляется из кэша, если приоритет равен 0 - Q0.
Каждая очередь также имеет максимальное количество обращений к её элементам. Поэтому если к элементу в очереди Qi обращаются более 2i раз, то этот элемент перемещается в очередь Qi+1.
При заполнении кэша, будет вытеснен элемент из очереди Q0, который дольше всех не использовался.
Картинка для наглядности:
![mq-replacement-algortithm.jpg]()
Другие алгоритмы
Алгоритмов кэширования достаточно много, поэтому на данный момент не все здесь рассмотрены. С полным списком можно ознакомиться здесь.
Со временем буду дополнять.
Полезные ссылки
Алгоритмы кэширования - статья на wiki.
LRU (Least Recently Used) - подробная статья о LRU с примерами реализации на C, C++, Java.
LRU, метод вытеснения из кэша - статья о том, как быстро реализовать алгоритм LRU.
Least Frequently Used (LFU) Cache Implementation - статья о LFU с примером на C++.
LFU cache in O(1) in Java - пример реализации LFU на Java.
Алгоритмы кэширования - что-то вроде презентации некоторых алгоритмов кэширования в формате PDF.Читайте также: