
Insufficient disk space on datastore vmware что это
Обновлено: 07.07.2024



В этой статье мы рассмотрим, как увеличить размер VMFS хранилища с помощью веб интерфейса vSphere Client и из командной строки VMWare ESXi.
При проверке свободного места на VMFS датасторах, вы обнаружили что на одном из них заканчивается свободное место. Вам нужно увеличить размер VMFS хранилища, добавив дополнительное место на СХД.
Сначала нужно увеличить размер LUN на СХД. Как это сделать – зависит от вендора вашей хранилки (если вы используете Microsoft iSCSI, то увеличить размер диска можно через Server Manager -> File and Storage Services -> iSCSI -> выберите диск -> Extend iSCSI Virtual Disk). В нашем примере мы увеличили размер LUN со 100 до 105 Гб.
VMWare ESXi поддерживает два способа расширения VMFS хранилищ – за счет неиспользуемого места на этом же LUN (этот способ мы рассматриваем в статье) или за счет добавление дополнительного LUN-а (способ называется extent). VMFS extent – своеобразный span раздела на несколько LUN. Запись на второй LUN начнется после того, как заполнится первый и т.д.Как увеличить VMFS хранилище из веб-интерфейса VMWare vSphere Client?

- В интерфейсе vSphere Client выберите раздел Storage;
- Щелкните правой кнопкой мыши по датастору и выберите Increase Datastore Capacity;
- Выберите диск (LUN), который надо расширить. Обратите внимание на значение поля Expandable. В нем должно быть указано Yes. Это значит, что данное VMFS хранилище можно расширить;
В некоторых случая расширить VMFS хранилище из графического интерфейса vSphere Client нельзя. Чаще всего проблема связана с невозможностью расширить VMFS хранилище на загрузочном диске. При этом появляется ошибка:

В этом случае придется расширить хранилище из командной строки хоста ESXi.
Расширить VMFS хранилище из командной строки VMWare ESXi

- Подключитесь к хосту ESXi через SSH (можно использовать встроенный SSH клиент Windows)
- Пересканируйте адаптеры хранения: esxcli storage core adapter rescan --all
- Затем нужно определить диск, соответствующий вашему VMFS хранилищу: vmkfstools -P /vmfs/volumes/DCx2VMFS1 . В нашем случае диск выглядит так /vmfs/devices/disks/naa.60003ff44dc75adca68b263bd62e4d1f.:1 означает, что VMFS хранилище расположено на первом разделе диска;
- Проверим таблицу разделов диска: partedUtil get /vmfs/devices/disks/naa.60003ff44dc75adca68b263bd62e4d1f
Как вы видите, вы успешно расширили VMFS хранилище на 5 Гб. Операция выполнялась онлайн без отмонтирования хранилища и без остановки ВМ.
Причины ошибки "There is no more space for virtual disk"
Вот такое вот веселое уведомление вы можете обнаружить у себя на гипервизоре.
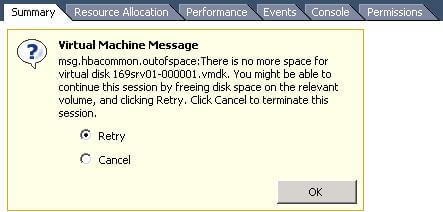
Полный текст ошибки следующий.
«msg,hbacommon.outofspace: There is no more space for virtual disk 169srv01-000001.vmdk. You might be able to continue this session by freeling disk space on the relevant volume and click Retry. ClickCancel to terminate this session»место на разделе с VMFS закончилось, стало невозможным ни создание снапшота, ни нормальная работа виртуальной машины, в результате наша виртуальная машина перешла в режим паузы (включена, но не использует ресурсы CPU).
- У меня данная ошибка выскочила из-за бэкапа veeam, который с начало делает snapshot, а потом идет резервное копирование vm.
- Не правильное планирование дискового массива, выделение пространства больше чем у вас есть, очень часто встречается при применении тонких дисков.
Как я и писал выше я такое наблюдал и у облачных провайдеров, у которых все построено на vCloud Director. История была такая, вечером на виртуальной машине стали проводиться работы, вдруг в какой-то момент, она стала отваливаться, и через некоторое время становиться доступной, время работы сервера не сбивалось, что означало, что перезапусков не было. Зайдя в консоль управления vCloud Director, я обнаружил на против нужной мне виртуальной машины, предупреждение "Require action".
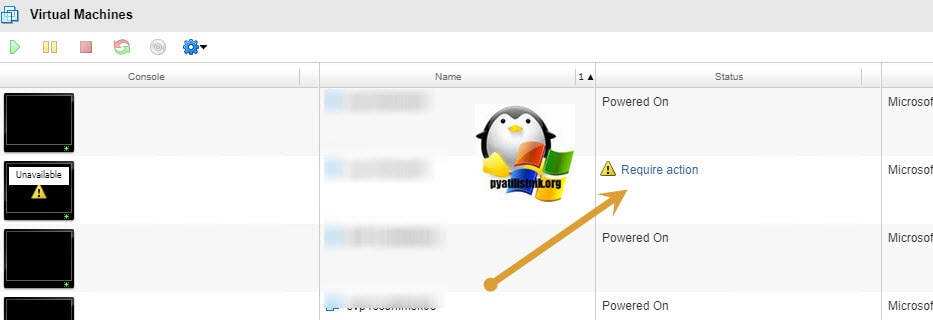
Нажав на "Require action", открылось дополнительное окно.
There is no more space for virtual disk /vmfs/volumes/5ac745dc-bb7f6862-141a-3c7843285a20/имя (cd4fdab7-c7a0-46c6-b304-c655c88191f8)/имя (cd4fdab7-c7a0-46c6-b304-c655c88191f8).vmdk. You might be able to continue this session by freeing disk space on the relevant volume, and clicking Retry. Click Cancel to terminate this session.Что так же говорило, о том, что закончилось место. В итоге выяснилось, что на более низком уровне (СХД), была допущена ошибка со стороны ЦОДА, и наша виртуалка просто перестала умещаться.
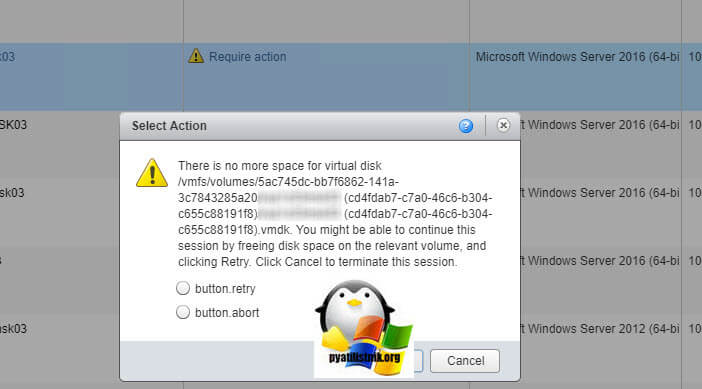
Ошибка There is no more space for virtual disk в vCenter 7
Вчера поймал данную ошибку во время рабочего дня. Есть виртуальная машина с большим количеством виртуальных дисков и приличным дисковым объемом. СУБД администратор стал разворачивать дополнительную базу на ней, со стороны Windows Server 2019 место в системе было

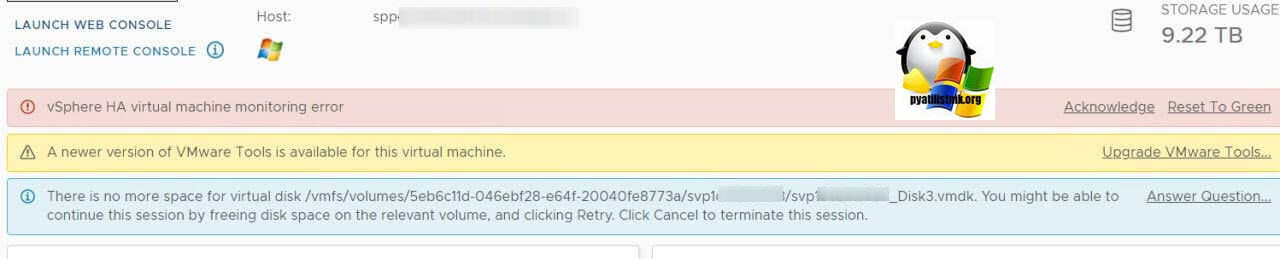
По мере выяснения причины оказалось, что диски располагавшиеся на данном датасторе были тонкие (Thin Provision), и их суммарный объем был 6,8 ТБ, а размер хранилища, где они лежали был 6 ТБ, меньше чем нужно.

- VMware Technology Network
- :
- Global
- :
- Russian
- :
- Russian Discussions
- :
- Закончилось место на виртуальном диске
- Mark as New
- Bookmark
- Subscribe
- Mute
- Email to a Friend
Закончилось место на датасторе, подцепленному к виртуальной машинке. На гостевой машине диск почти полностью свободен, не могу понять куда делось все место, нашел тред, где этот вопрос уже поднимался Закончилось место на виртуальном диске , ситуация аналогичная, но вопрос я так понял решен не был. Если виной снэпшоты, подскажите пожлауйста где их найти, чтобы удалить? Прошу помочь.
Почитал в интернете, что проблемой могут являться невидимые снапшоты, которые может не удалять veeam 7.0 после резервного копирования машинки (как раз эта версия установлена) , но теперь вопрос как их найти и удалить вручную.
Finikiez- Mark as New
- Bookmark
- Subscribe
- Mute
- Email to a Friend
Теперь все понятно.
У вас кончилось место на датасторе из-за того, что используются тонкие диски у виртуальных машин. Соответственно если вы просуммируете сконфигурированный объем всех виртуальных дисков всех виртуальных машин на этом датасторе, вы должны получить цифру больше, чем 1,95 Тб, которые у вас есть.
Соответственно у вас просто кто-то начал расти в объеме и занял все доступное пространство. При этом гостевые операционные системы считают, что у них еще место есть.
Когда вы удаляете данные в гостевой ОС в ESXi 5.5 в тонком виртуальном диске, автоматически свободное пространство в VMFS датастор не возвращается.
Вам нужно в случае ОС Windows вычистить место с помощью команды sdelete и дальше с помощью команды vmkfstools "сжать" виртуальный диск.
В ESXi 6.0 и 6.5 есть значительные улучшения в работе UNMAP и большинство операций, при соблюдении определенных условий, выполняется автоматически.
Как выглядит предупреждение Datastore usage on disk


Варианты решения проблемы
Данное уведомление очень полезное, так как системный администратор будет в курсе, что у него заканчивается место, хотя уверен, что он об этом узнает из другой системы мониторинга, например, Zabbix. Но если у вас ситуация как у меня, когда на датасторе полно место и вы не хотите, чтобы предупреждение мозолило вам глаза, то у вас два варианта, точнее три:
- Освободить свободное место на нужном датасторе ESXI хоста, не всегда представляется возможным
- Полностью отключить оповещение, не самый лучший вариант
- Отредактировать настройки, и изменить значения срабатывания тригера, наш выбор


Щелкните по ним и измените значения на свои.


Запросим текущее состояние политики с помощью команды:

Посмотреть все политики оповещения связанные с датастором, можно вот так:

Hi Guys,
I have a VMware cluster (3 ESXi Servers) and a vSAN configured using all the storage among these servers.
When I go to the vSAN Datastore summary usging the vSphere client it shows 8TB of free space.
But 2 events are happening that got me worried:
Why are these events popping up if according to the system I still have 8TB of free space?
How can I fix this issue?, preferable keeping all the space I have reserved for Virtual Disks on my VMs.
Background
I was doing an upgrade from 4.0 to 4.1 this week on a two node cluster. This cluster is owned by an SMB and its a fully contained VMware setup, basically it has two DL380 G6 servers each with 8 – 146GB 10k SAS drives, dual Nehalem processors, and 24GB of ram. We have HP’s P4000 VSA software installed on each node to form a redundant two node SAN, so each server has all 8 drives in a RAID5 and a single VMware VMFS volume on them. Inside of that volume we have a single virtual machine (the VSA) and it consumes about 90% of the space in that datastore. Inside of the VSA is where all of the production VM’s live, but the problem is that the local datastores are in an alarm state because they are above the threshold set at the vcenter level. I suppose I could just change that threshold to like 98% or something and the alarms would go away, but that wouldn’t let us much time to react if the VSA volume ever got full. So the better solution would be to somehow ignore alarms on local datastores but still keep the alarms for shared datastores. Below is what the problem looks like… Local datastores are in an alarm state… but the “real” data which is in “VM Storage Repository” is not full yet.
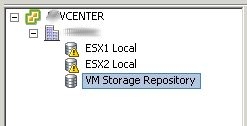
Solution
After doing a little research I was able to come by one other blog post that used this same method on ESX to fix the errors on the service console volume, but I could not find anything related to local and VSA shared volumes. The process is the same for both though, so I figured I would share.
The first step is to log into vcenter (or esxi, whichever your using) and goto the Datastore Inventory tab. Next create two folders, one for local datastores and another for shared. Then drag your local datastores to the local folder and your shared datastores to the shared folder.
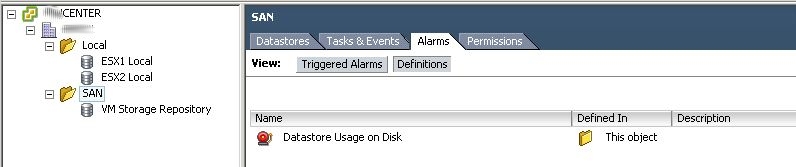
Note that the pictures shows how it will look after we delete some alarms and recreate them.
After putting your datastores in the proper folders click on the vcenter, or esxi object (whichever is the top level) and go to the alarms tab (you will need to click on the Definitions button as well. Find the ‘Datastore usage on disk’ alarm and go into it and take some screen shots of how it is setup, we will use these later to recreate the alrm, then delete it. (Or at least disable it) Then go down to the shared datastore folder that you created, and then into the alarms tab again (then click Definitions). In here we will want to recreate a ‘Datastore Usage on Disk’ alarm so that we still get alarms for our shared storage. Right click and Add new. and then refer to the screenshots you took in order to create it properly. Just for reference here is what it looks like inside of the alarm definition:
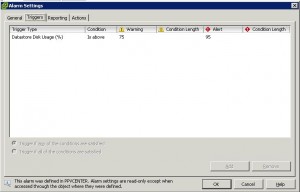
Now you should have something that looks like the last screen shot… you will have a ‘Datastore Usage on Disk’ alarm that has been created in “This object” and your local datastores are no longer monitored. If you wanted to you could create a disk usage alarm for the local folder and set its thresholds much higher just to be safe.
Datastore usage on disk, сам LUN имеет размеры 4 ТБ и на нем было свободно более 800 гигабайт. Данное оповещение сообщает, что у меня начинает заканчиваться свободное место на дисковом массиве, но в виду того, что свободно 800 гигабайт, это оповещение мне кажется лишним. Я вам покажу, как его поправит
Как выглядит предупреждение Datastore usage on disk
What Is DataStore.edb
To fix the high disk usage issue, it’s necessary to figure out what is DataStore.edb. DataStore.edb is a kind of Windows log file that’s located under the software distribution folder. This file is used to keep the history of all Windows updates.
That means the DataStore.edb log file will grow in disk size with every Windows Update check. So, you may find the system spends much time reading and writing to the DataStore.edb file, which slow down your PC considerably. When checking Windows update, you may find the svchost.exe process is using large disk resources to read Windows.edb file in Task Manager.
Increase Datastore Disk Space Capacity
For some storage model there is a features that it is possible to extend more space to the datastore. So, we can increasing disk space on the datastore.
Environment
PlateSpin Migrate and PlateSpin Protect used with ESX target server.
Situation
The CreateVM_Task submitted to the VMware ESX server failed: Insufficient disk space on datastore
The CreateVM_Task submitted to the VMware ESX server failed: A general system error occurred: The file is too big for the filesystem
The above error will occur if any of the following is true:
- There is not enough disk space on the target host to create the .vmdk file
- The block size of the VMFS partition needs to be increased to support the desired size of the .vmdk
Варианты решения проблемы
Данное уведомление очень полезное, так как системный администратор будет в курсе, что у него заканчивается место, хотя уверен, что он об этом узнает из другой системы мониторинга, например, Zabbix. Но если у вас ситуация как у меня, когда на датасторе полно место и вы не хотите, чтобы предупреждение мозолило вам глаза, то у вас два варианта, точнее три:
- Освободить свободное место на нужном датасторе ESXI хоста, не всегда представляется возможным
- Полностью отключить оповещение, не самый лучший вариант
- Отредактировать настройки, и изменить значения срабатывания тригера, наш выбор
Щелкните по ним и измените значения на свои.
Запросим текущее состояние политики с помощью команды:
Посмотреть все политики оповещения связанные с датастором, можно вот так:
Background
I was doing an upgrade from 4.0 to 4.1 this week on a two node cluster. This cluster is owned by an SMB and its a fully contained VMware setup, basically it has two DL380 G6 servers each with 8 – 146GB 10k SAS drives, dual Nehalem processors, and 24GB of ram. We have HP’s P4000 VSA software installed on each node to form a redundant two node SAN, so each server has all 8 drives in a RAID5 and a single VMware VMFS volume on them. Inside of that volume we have a single virtual machine (the VSA) and it consumes about 90% of the space in that datastore. Inside of the VSA is where all of the production VM’s live, but the problem is that the local datastores are in an alarm state because they are above the threshold set at the vcenter level. I suppose I could just change that threshold to like 98% or something and the alarms would go away, but that wouldn’t let us much time to react if the VSA volume ever got full. So the better solution would be to somehow ignore alarms on local datastores but still keep the alarms for shared datastores. Below is what the problem looks like… Local datastores are in an alarm state… but the “real” data which is in “VM Storage Repository” is not full yet.
Читайте также: