
Ips checkpoint что это
Обновлено: 07.07.2024
Мы долго размышляли над тем, стоит ли писать данную статью, т.к. в ней нет ничего нового, чего нельзя было бы найти в сети Интернет. Однако, несмотря на такое обилие информации при работе с клиентами и партнерами мы довольно часто слышим одни и те же вопросы. Поэтому было решено написать некое введение в мир технологий Check Point и раскрыть суть архитектуры их решений. И все это в рамках одного “небольшого” поста, так сказать быстрый экскурс. Причем мы постараемся не вдаваться в маркетинговые войны, т.к. мы не вендор, а просто системный интегратор (хоть мы и очень любим Check Point) и просто рассмотрим основные моменты без их сравнения с другими производителями (таких как Palo Alto, Cisco, Fortinet и т.д.). Статья получилась довольно объемной, зато отсекает большую часть вопросов на этапе ознакомления с Check Point. Если вам это интересно, то добро пожаловать под кат…
UTM/NGFW
Начиная разговор о Check Point первое с чего стоить начать, так это с объяснения, что такое UTM, NGFW и чем они отличаются. Сделаем мы это весьма лаконично, дабы пост не получился слишком большим (возможно в будущем мы рассмотрим этот вопрос немного подробнее)
UTM — Unified Threat Management
Если коротко, то суть UTM — консолидация нескольких средств защиты в одном решении. Т.е. все в одной коробке или некий all inclusive. Что понимается под “несколько средств защиты”? Самый распространенный вариант это: Межсетевой экран, IPS, Proxy (URL фильтрация), потоковый Antivirus, Anti-Spam, VPN и так далее. Все это объединяется в рамках одного UTM решения, что проще с точки зрения интеграции, настройки, администрирования и мониторинга, а это в свою очередь положительно сказывается на общей защищенности сети. Когда UTM решения только появились, то их рассматривали исключительно для небольших компаний, т.к. UTM не справлялись с большими объемами трафика. Это было по двум причинам:
- Способ обработки пакетов. Первые версии UTM решений обрабатывали пакеты последовательно, каждым “модулем”. Пример: сначала пакет обрабатывается межсетевым экраном, затем IPS, потом его проверяет Антивирус и так далее. Естественно такой механизм вносил серьезные задержки в трафик и сильно расходовал ресурсы системы (процессор, память).
- Слабое “железо”. Как было сказано выше, последовательная обработка пакетов сильно отъедала ресурсы и “железо” тех времен (1995-2005) просто не справлялось с большим трафиком.
Но прогресс не стоит на месте. С тех пор значительно увеличились аппаратные мощности, а обработка пакетов изменилась (надо признать, что далеко не у всех вендоров) и стала позволять практически одновременный анализ сразу в нескольких модулях (МЭ, IPS, AntiVirus и т.д.). Современные UTM решения могут “переваривать” десятки и даже сотни гигабит в режиме глубокого анализа, что дает возможность использовать их в сегменте крупного бизнеса или даже датацентов.
Ниже представлен знаменитый магический квадрант Гартнера для UTM решений за август 2016 года:
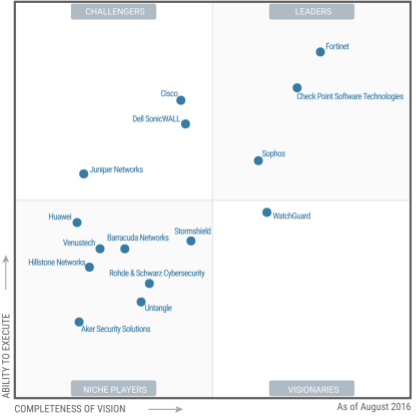
Не буду сильно комментировать данную картинку, просто скажу, что в верхнем правом углу находятся лидеры.
NGFW — Next Generation Firewall
Магический квадрант Гартнера для NGFW за май 2016:
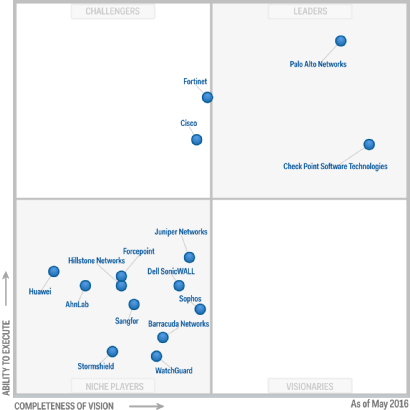
UTM vs NGFW
Очень частый вопрос, что же лучше? Однозначного ответа тут нет и быть не может. Особенно если учитывать тот факт, что почти все современные UTM решения содержат функционал NGFW и большинство NGFW содержат функции присущие UTM (Antivirus, VPN, Anti-Bot и т.д.). Как всегда “дьявол кроется в мелочах”, поэтому в первую очередь нужно решить, что нужно конкретно Вам, определиться с бюджетом. На основе этих решений можно выбрать несколько вариантов. И все нужно однозначно тестировать, не веря маркетинговым материалам.
Мы в свою очередь в рамках нескольких статей попытаемся рассказать про Check Point, как его можно попробовать и что в принципе можно попробовать (практически весь функционал).
Три сущности Check Point
При работе с Check Point вы обязательно столкнетесь с тремя составляющими этого продукта:
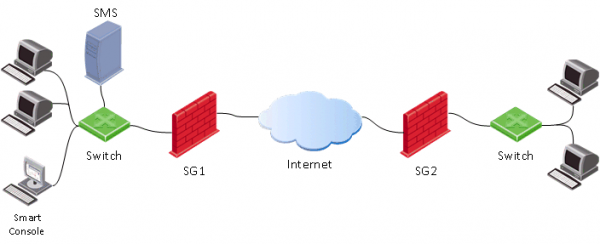
- Security Gateway (SG) — собственно сам шлюз безопасности, который как правило ставится на периметр сети и выполняет функции межсетевого экрана, потокового антивируса, антибота, IPS и т.д.
- Security Management Server (SMS) — сервер управления шлюзами. Практически все настройки на шлюзе (SG) выполняются с помощью данного сервера. SMS также может выступать в качестве Лог-сервера и обрабатывать их встроенной системой анализа и корреляции событий — Smart Event (подобие SIEM для Check Point), но об этом чуть позже. SMS используется для централизованного управления несколькими шлюзами (кол-во шлюзов зависит от модели SMS, либо от лицензии), однако вы обязаны его использовать, даже если у вас всего один шлюз. Тут следует отметить, что Check Point одни из первых стали применять подобную централизованную систему управления, которая уже много лет подряд признается “золотым стандартом” по отчетам компании Gartner. Есть даже шутка: “Если у бы Cisco была нормальная система управления, то Check Point бы никогда не появился”.
- Smart Console — клиентская консоль для подключения к серверу управления (SMS). Как правило устанавливается на компьютер администратора. Через эту консоль осуществляются все изменения на сервере управления, а уже после этого можно применить настройки к шлюзам безопасности (Install Policy).
Операционная система Check Point
Говоря об операционной системе Check Point можно вспомнить сразу три: IPSO, SPLAT и GAIA.
- IPSO — операционная система компании Ipsilon Networks, которая принадлежала компании Nokia. В 2009 года Check Point купила этот бизнес. Больше не развивается.
- SPLAT — собственная разработка Check Point, основана на ядре RedHat. Больше не развивается.
- Gaia — актуальная операционная система от Check Point, которая появилась в результате слияния IPSO и SPLAT, вобрав в себя все самое лучшее. Появилась в 2012 году и продолжает активно развиваться.
Говоря о Gaia следует сказать, что на текущий момент самая распространенная версия это R77.30. Относительно недавно появилась версия R80, которая существенно отличается от предыдущей (как в плане функциональности, так и управления). Теме их отличий мы посвятим отдельный пост. Еще один важный момент — на текущий момент сертификат ФСТЭК имеет только версия R77.10 и идет сертификация версии R77.30.
Варианты исполнения (Check Point Appliance, Virtual machine, OpenSerever)
Здесь нет ничего удивительного, как и многие вендоры Check Point имеет несколько вариантов продукта:
-
Appliance — программно-аппаратное устройство, т.е. своя “железка”. Моделей очень много, которые отличаются по производительности, функционалу и исполнению (есть варианты для промышленных сетей).
Варианты внедрения (Distributed или Standalone)
Чуть выше мы уже обсудили что такое шлюз (SG) и сервер управления (SMS). Теперь обсудим варианты их внедрения. Есть два основных способа:
-
Standalone (SG+SMS) — вариант, когда и шлюз и сервер управления устанавливаются в рамках одного устройства (или виртуальной машины).

Такой вариант подходит когда у вас всего один шлюз, который слабо нагружен пользовательским трафиком. Этот вариант наиболее экономичен, т.к. нет необходимости покупать сервер управления (SMS). Однако при серьезной нагрузке шлюза вы можете получить “тормозящую” систему управления. Поэтому перед выбором Standalone решения лучше всего проконсультироваться или даже протестировать данный вариант.
Как я уже говорил чуть выше, у Check Point есть собственная SIEM система — Smart Event. Использовать ее вы сможете только в случае Distributed установки.
Режимы работы (Bridge, Routed)
Шлюз безопасности (SG) может работать в двух основных режимах:
- Routed — самый распространенный вариант. В этом случае шлюз используется как L3 устройство и маршрутизирует трафик через себя, т.е. Check Point является шлюзом по умолчанию для защищаемой сети.
- Bridge — прозрачный режим. В этом случае шлюз устанавливается как обычный “мост” и пропускает через себя трафик на втором уровне (OSI). Такой вариант обычно применяется, когда нет возможности (или желания) изменить уже существующую инфраструктуру. Вам практически не придется менять топологию сети и не надо задумываться о смене IP — адресации.
Хотелось бы отметить, что в Bridge режиме есть некоторые ограничения по функционалу, поэтому мы как интегратор советуем всем своим клиентам использовать именно Routed режим, конечно если это возможно.
Программные блейды (Check Point Software Blades)
Мы добрались чуть ли не до самой главной темы Check Point, которая вызывает больше всего вопросов у клиентов. Что такое эти “программные блейды”? Под блейдами подразумеваются определенные функции Check Point.

Данные функции могут включаться или выключаться в зависимости от нужд. При этом есть блейды которые активируются исключительно на шлюзе (Network Security) и только на сервере управления (Management). На картинках ниже приведены примеры для обоих случаев:
1) Для Network Security (функционал шлюза)
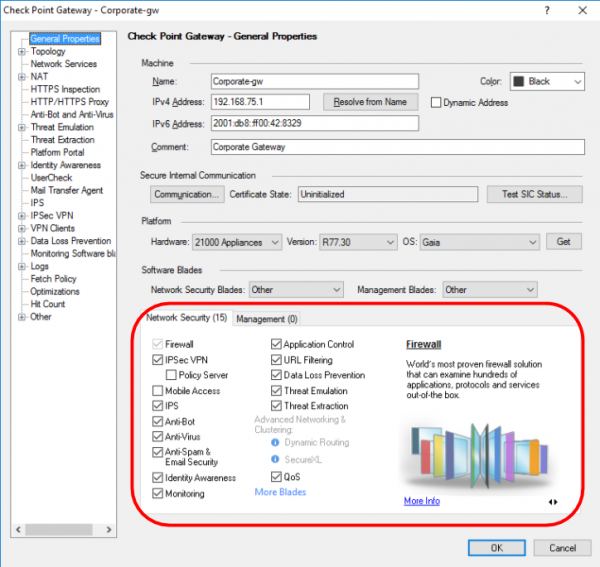
Опишем вкратце, т.к. каждый блейд заслуживает отдельной статьи.
Буквально через несколько статей мы подробно рассмотрим блейды Threat Emulation и Threat Extraction, уверен что будет интересно.
2) Для Management (функционал сервера управления)
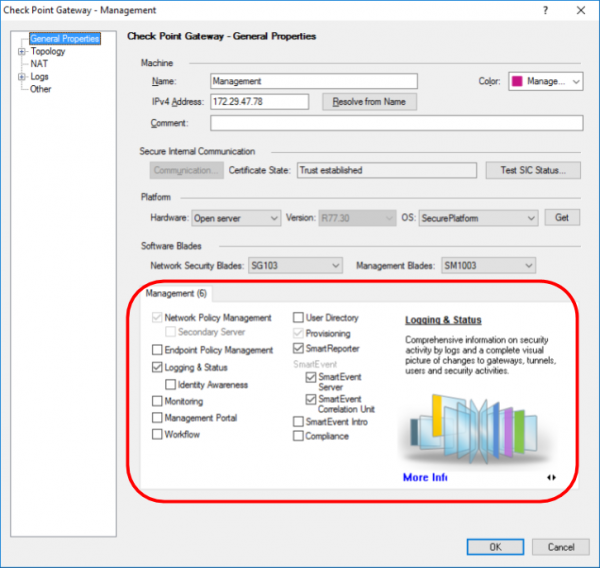
Мы не будем сейчас подробно рассматривать вопросы лицензирования, дабы не раздувать статью и не запутать читателя. Скорее всего мы вынесем это в отдельный пост.
Архитектура блейдов позволяет использовать только действительно нужные функции, что сказывается на бюджете решения и общей производительности устройства. Логично, что чем больше блейдов вы активируете, тем меньше трафика можно “прогнать”. Именно поэтому к каждой модели Check Point прилагается следующая таблица производительности (для примера взяли характеристики модели 5400):

Как видите здесь приводятся две категории тестов: на синтетическом трафике и на реальном — смешанном. Вообще говоря, Check Point просто вынужден публиковать синтетические тесты, т.к. некоторые вендоры используют подобные тесты как эталонные, не исследуя производительность своих решений на реальном трафике (либо намеренно скрывают подобные данные ввиду их неудовлетворительности).
В каждом типе теста можно заметить несколько вариантов:
- тест только для Firewall;
- тест Firewall+IPS;
- тест Firewall+IPS+NGFW (Application control);
- тест Firewall+Application Control+URL Filtering+IPS+Antivirus+Anti-Bot+SandBlast (песочница)
Внимательно смотрите на эти параметры при выборе своего решения, либо обратитесь за консультацией .
Думаю на этом можно закончить вводную статью, посвященную технологиям Check Point. Далее мы рассмотрим, как можно протестировать Check Point и как бороться с современными угрозами информационной безопасности (вирусы, фишинг, шифровальщики, zero-day).
P.S. Важный момент. Несмотря на зарубежное (израильское) происхождение, решение имеет сертификацию в РФ в надзорных органах, что автоматом легализует их наличие в гос.учреждениях (комментарий by Denyemall ).

Несмотря на обилие информации в сети Интернет, мы довольно часто сталкиваемся с одними и теми же вопросами от наших клиентов и партнеров. Поэтому мы решили написать статью-введение в мир технологий Check Point, раскрыть суть его архитектуре и в целом провести для вас быстрый экскурс. Если это актуальная тема для вас, продолжайте читать.
UTM/NGFW
Итак, говоря о Check Point, стоит разобраться, что такое UTM и NGFW и в чем их различия.
UTM — Unified Threat Management
UTM представляет собой консолидацию нескольких средств защиты в одном решении. Проще говоря, это своего рода all inclusive. Что включают в себя эти "несколько средств защиты"? Как правило, это: межсетевой экран, IPS, Proxy (URL фильтрация), потоковый Antivirus, Anti-Spam, VPN и так далее. Все эти элементы объединены в одном UTM решении, что упрощает процесс интеграции, настройки, администрирования и мониторинга, а это в свою очередь положительно влияет на общую защищенность сети.
Изначально UTM решения рассматривались исключительно для небольших компаний, т.к. не справлялись с большими объемами трафика.
Это происходило по следующим причинам:
- Способ обработки пакетов. В первых версиях UTM решений была последовательная обработка. Пример: сначала пакет обрабатывается межсетевым экраном, затем IPS, потом его проверяет Антивирус и так далее. Причиной серьезных задержек в трафике и высокий расход ресурсов системы (процессор, память) было использование такого механизма.
- Слабое "железо". "Железо" тех времен (1995-2005) не справлялось с большим трафиком, особенно с учетом того, что последовательная обработка пакетов сильно отъедала ресурсы.

NGFW — Next Generation Firewall

UTM vs NGFW
Один из самых часто задаваемых вопросов – что лучше, UTM или NGFW?
С учетом того, что почти все современные UTM решения содержат функционал NGFW, а большинство NGFW содержат функции присущие UTM (Antivirus, VPN, Anti-Bot и т.д.), нельзя дать однозначный ответ. Поэтому необходимо определить, что необходимо именно Вам, а также каков Ваш бюджет. На основе этого можно выбрать несколько вариантов и, невзирая на маркетинговые войны, всё необходимо тестировать.
В рамках серии статей мы расскажем про Check Point, как его можно попробовать и что именно можно попробовать (практически весь функционал).

Три сущности Check Point
Check Point имеет три основные составляющие:
- Security Gateway (SG) — шлюз безопасности, который обычно ставится на периметр сети и выполняет функции межсетевого экрана, потокового антивируса, антибота, IPS и т.д.
- Security Management Server (SMS) — сервер управления шлюзами. С помощью данного сервера выполняются практически все настройки на шлюзе (SG). В качестве Лог-сервера может выступать SMS, способный обрабатывать их встроенной системой анализа и корреляции событий — Smart Event (подобие SIEM для Check Point). SMS используется для централизованного управления несколькими шлюзами (кол-во определяется моделью (лицензией) SMS), тем не менее, Вы обязаны использовать его, даже если у вас всего один шлюз. Подобную централизованную систему управления, признанную "золотым стандартом" (по отчетам компании Gartner), Check Point стали применять одни из первых. Есть даже шутка: "Если у бы Cisco была нормальная система управления, то Check Point бы никогда не появился".
- Smart Console — клиентская консоль для подключения к серверу управления (SMS). Все изменения на сервере и применение настроек к шлюзам безопасности (Install Policy) осуществляются через данную консоль. Консоль, как правило, устанавливается на компьютер администратора.
Операционная система Check Point
Говоря об операционной системе Check Point можно обозначить три аспекта: IPSO, SPLAT и GAIA.
- IPSO — операционная система компании Ipsilon Networks, которая принадлежала компании Nokia. В 2009 года Check Point купила этот бизнес. Больше не развивается.
- SPLAT — основанная на ядре RedHat собственная разработка Check Point. Больше не развивается.
- Gaia — актуальная операционная система от Check Point, появившаяся в результате слияния IPSO и SPLAT. Появилась в 2012 году и продолжает активно развиваться.
Варианты исполнения (Check Point Appliance, Virtual machine, OpenSerever)
Как и многие вендоры Check Point имеет несколько вариантов исполнения продукта:
- Appliance — программно-аппаратное устройство ("железка"). Многообразие моделей различных по производительности, функционалу и исполнению (есть варианты для промышленных сетей).
- Virtual Machine — виртуальная машина Check Point с ОС Gaia. Поддерживаются гипервизоры ESXi, Hyper-V, KVM, лицензируются по количеству ядер процессора.
- OpenServer — установка Gaia непосредственно на сервер в качестве основной операционной системы (так называемый "Bare metal"). Поддерживается только определенное "железо". По этому «железу» есть определенные рекомендации, которые необходимо соблюдать, чтобы избежать проблем с драйверами и чтобы тех. поддержка не отказала Вам в обслуживании.

Варианты внедрения (Distributed или Standalone)
Ранее мы обсудили, что такое шлюз (SG) и сервер управления (SMS). Теперь разберем варианты их внедрения. Существует два основных способа:
1. Standalone (SG+SMS) — вариант, при котором шлюз и сервер управления устанавливаются в рамках одного устройства (или виртуальной машины). Этот способ актуален, если у Вас всего один шлюз, который слабо нагружен пользовательским трафиком. Такой вариант наиболее экономичен, т.к. нет необходимости покупать сервер управления (SMS). Однако при серьезной нагрузке шлюза Вы можете получить "тормозящую" систему управления. Поэтому перед выбором Standalone решения лучше всего проконсультироваться или даже протестировать данный вариант.
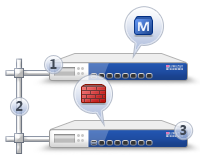
2. Distributed — отдельная установка сервера управления отдельно от шлюза. Данный вариант оптимален в плане удобства и производительности, используется в случае необходимости управления сразу несколькими шлюзами (например, центральным и филиальными). Для реализации такого варианта требуется покупка сервера управления (SMS), который также может быть в виде appliance (железки) или виртуальной машины.
Собственную SIEM систему Check Point — Smart Event – можно использовать только в случае Distributed установки.

Введение
Курс содержит теоретическую и практическую части, где подробно рассмотрены важные настройки шлюзов Check Point (версия Gaia R80.10). В большинстве уроков для проверки защищенности будет использоваться дистрибутив Kali-Linux для имитации различных сценариев атаки. В целом, этот курс предназначен не только для владельцев Check Point. Он будет интересен всем, кто обеспокоен качеством защищенности периметра сети. В итоге получится чек-лист по необходимым проверкам и инструкция, как эти проверки провести. Для удобства пользователей курс разбит на 7 частей.
Этот видеокурс подготовлен специалистами компании TS Solution при участии Алексея Белоглазова, руководителя направления по защите от киберугроз, Check Point Software Technologies в России и СНГ.
Урок 1. Человеческий фактор в информационной безопасности
Этот урок — введение в тематику всего курса. Главный тезис этой части: «Уровень защищенности вашей компании в большей степени зависит от ваших специалистов». На уроке рассмотрен рейтинг современных NGFW и схема сетевого окружения, в котором предполагается тестировать настройки безопасности.
Рисунок 1. Схема для тестирования Check Point Gateway R80.10

Урок 3. Content Awareness. Управление контентом по типам данных
Блейд Content Awareness появился только в версии Gaia R80.10, и многие владельцы Check Point до сих пор его игнорируют. А зря: эта функция позволяет блокировать скачивание и отправку для определенных категорий файлов (архивы, документы, видео, изображения и т. д.). К примеру, можно запретить пользователям скачивать любые исполняемые файлы (exe, msi, bat, скрипты и т.д.) или запретить выгружать в интернет любые документы (pdf, doc, xls). В процессе урока станет понятно, как это позволит улучшить защиту вашей сети и как поможет сэкономить ресурсы вашего шлюза.
Урок 4. Антивирус. Тонкая настройка
Практически каждый NGFW содержит в себе потоковый антивирус. И абсолютно все используют эту функцию на периметре сети. Однако мало кто задумывается о тонкостях настроек антивируса. В этом уроке рассказывается, как обойти антивирус с дефолтными настройками с помощью дистрибутива Kali-Linux. Затем на примере Check Point показано, как усилить защиту с помощью «правильных» настроек антивируса. И полученный результат снова протестирован в связке с Kali-Linux.
Урок 5. Системы предотвращения вторжений (IPS). Теория
Тема защиты от вторжений получилась весьма обширной, поэтому была разбита на две части. В этом уроке затронута история становления IPS, перечислены самые распространенные мифы вокруг IPS. Главный тезис: «IPS — важная и эффективная система защиты вашей сети. Как же правильно ее настроить?»
Урок 6. Системы предотвращения вторжений (IPS). Практика
В практической части урока с помощью Kali-Linux можно наглядно убедиться, что дефолтные настройки IPS не отвечают современным требованиям безопасности. Мы рассмотрим особенности «тюнинга» IPS для улучшения защиты и экономии ресурсов шлюза. Здесь также будет продемонстрирована эффективность IPS в обнаружении файлов, содержащих эксплойты.
Урок 7. SandBlast. Защита от таргетированных атак при помощи песочницы
В ходе этого урока будут подведены итоги пройденного материала. Станет очевидно, как можно сократить площадь атаки, используя традиционные функции NGFW. Пользователь сможет на примере убедиться, что для современной защиты этого недостаточно, и здесь опять же поможет Kali-Linux и VirusTotal. За пару минут создадим вирус, который не детектируется большинством антивирусов и таким образом подойдем к теме таргетированных атак и защите от них при помощи песочниц (sandbox). Главный тезис урока: «Песочница — обязательный элемент современной и комплексной защиты сети».
Выводы
Этот видеокурс наверняка будет полезен тем, кто хочет получить максимум от имеющихся средств защиты. Однако охватить абсолютно все аспекты построения эффективной сетевой защиты в рамках небольшого видеокурса крайне трудно. Разработчики видеокурса готовы проконсультировать вас и ответить на любые возникшие вопросы:
Рассказываем, что нужно учесть в настройках сети, виртуализации и самих Check Point'ов, чтобы все работало.

Многие клиенты, арендующие у нас облачные ресурсы, используют виртуальные Check Point’ы. С их помощью клиенты решают различные задачи: кто-то контролирует выход серверного сегмента в Интернет или же публикует свои сервисы за нашим оборудованием. Кому-то необходимо прогонять весь трафик через IPS blade, а кому-то хватает Check Point в роли VPN-шлюза для доступа к внутренним ресурсам в ЦОДе из филиалов. Есть и те, кому нужно защитить свою инфраструктуру в облаке для прохождения аттестации по ФЗ-152, но об этом я расскажу как-нибудь отдельно.
По долгу службы я занимаюсь поддержкой и администрированием Check Point'ов. Сегодня расскажу, что нужно учесть при разворачивании кластера из Check Point'ов в виртуальной среде. Затрону моменты уровня виртуализации, сети, настроек самого Check Point'а и мониторинга.
Не обещаю открыть Америку – многое есть в рекомендациях и best practices вендора. Но их же никто не читает), поэтому погнали.
Режим работы кластера
У нас Check Point'ы живут в кластерах. Самая частая инсталляция – кластер из двух нод в режиме active-standby. Если с active-нодой что-то случается, она становится неактивной, и в работу включается standby-нода. Переключение на «запасную» ноду обычно происходит из-за проблем в синхронизации между участниками кластера, состоянии интерфейсов, установленной политики безопасности, просто из-за сильной нагрузки на оборудование.
В кластере из двух нод мы не используем режим active-active.
При падении одной из нод выжившая нода может просто не выдержать двойной нагрузки, и тогда мы потеряем все. Если очень хочется active-active, то в кластере должно быть минимум 3 ноды.
Настройки сети и виртуализации

Описание проблемы с Cisco Nexus и ее решения на портале вендора
На уровне виртуализации также разрешаем прохождение multicast-трафика. Если multicast запрещен для синхронизации кластера (CCP), то используем broadcast.
В консоли Check Point'а c помощью команды cphaprob -a if можно посмотреть настройки CPP и его режим работы (multicast или broadcast). Чтобы изменить режим работы, используем команду cphaconf set_ccp broadcast.

Ноды кластера должны находиться на разных ESXi-хостах. Тут все понятно: при падении физического хоста вторая нода продолжает работать. Этого можно достичь с помощью DRS anti-affinity rules.
Размеры виртуальной машины, на которой будет работать Check Point. Рекомендации вендора – 2 vCPU и 6 ГБ, но это для минимальной конфигурации, например, если у вас работает firewall с минимальной пропускной способностью. По нашему опыту внедрений, при использовании нескольких программных блейдов желательно использовать как минимум 4 vCPU, 8 GB RAM.
На ноду мы выделяем в среднем 150 ГБ диска. При развертывании виртуального Check Point диск разбивается на партиции, и мы можем регулировать, какое пространство выделить под System Swap, System Root, Logs, Backup and Upgrade.
При увеличении System Root партицию Backup and Upgrade также нужно увеличить, чтобы соблюсти пропорцию между ними. Если пропорция не соблюдается, то очередной бэкап может не уместиться диске.
Настроено 100% резервирование ресурсов для Check Point при миграции между ESXi-хостами. Рекомендуем зарезервировать 100 % ресурсов, чтобы виртуальная машина, на который развернут Check Point, не конкурировала за ресурсы с другими ВМ на хосте.
Прочее. У нас используется версия Check Point'а R77.30. Для нее рекомендуется использовать RedHat Enterprise Linux version 5 (64-bit) в качестве гостевой ОС на виртуальной машине. Из сетевых драйверов – VMXNET3 или Intel E1000.
Настройки Check Point’a
На шлюзах и сервере управления установлены последние обновления Check Point. Проверяем наличие обновлений через CPUSE.

С помощью Verifier проверяем, что пакет обновлений, который мы собираемся установить, не конфликтует с системой.


Verifier, конечно, штука хорошая, но есть нюансы. Некоторые обновления несовместимы с add-on, но этих конфликтов Verifier не покажет и позволит обновиться. В конце обновления у вас появится ошибка, и только из нее вы узнаете, что мешает обновлению. Например, такая ситуация возникла с пакетом обновлений MABDA_001 (Mobile Access Blade Deployment Agent), которая решает проблему с запуском Java Plugin в браузерах отличных от IE.
Настроено ежедневное автоматическое обновление сигнатур для IPS и других программных блейдов. Check Point выпускает сигнатуры, с помощью которых можно детектировать или блокировать новые уязвимости. Уязвимости автоматически присваивается уровень критичности. В соответствии с этим уровнем и выставленным фильтром система принимает решение о том, детектировать или блокировать сигнатуру. Тут важно не переусердствовать с фильтрами, периодически проверять и вносить корректировки, чтобы не блокировался легитимный трафик.

Профиль IPS, где выбираем действие по отношению к сигнатуре в соответствии с ее параметрами

Настройки политики для данного профиля IPS в соответствии с параметрами сигнатур: уровень критичности, влияние на производительность и пр.
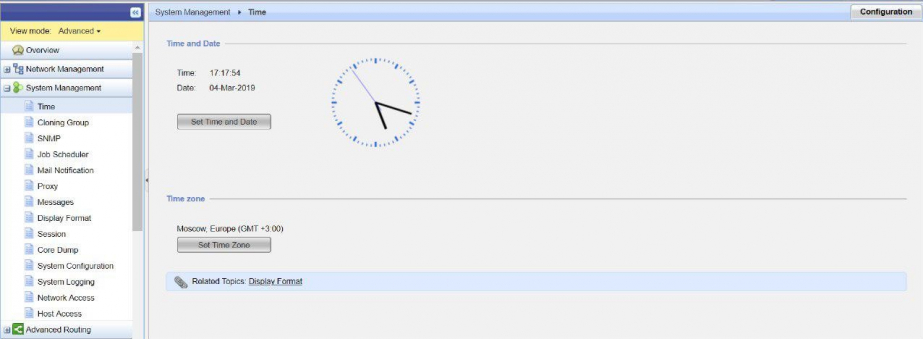
На оборудовании Check Point настроен протокол синхронизации времени NTP. По рекомендациям, Check Point следует использовать внешний NTP-сервер для синхронизации времени на оборудовании. Сделать это можно через веб-портал gaia.
Неточно выставленное время может привести к рассинхронизации кластера. Если время будет неправильным, то крайне неудобно искать интересующую нас запись в логах. Каждая запись в журналах событий маркируется так называемым timestamp.

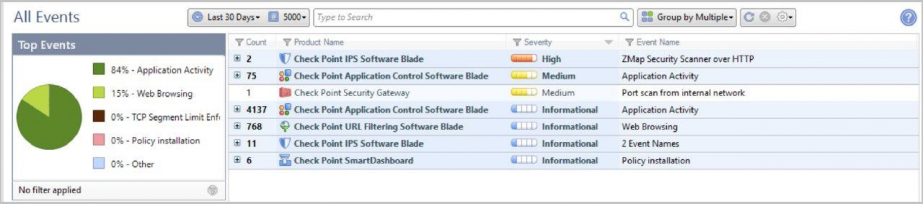
Настроен Smart Event для оповещения о срабатываниях IPS, App Control, Anti-Bot и т. д. Это отдельный модуль со своей лицензией. Если он у вас есть, то с его помощью удобно визуализировать информацию о работе всех программных блейдов и устройств. Например, атаки, количество срабатываний IPS, уровень критичности угроз, какие запрещенные приложения используют пользователи и пр.


Это статистика за 30 дней по количеству сигнатур и степени их критичности
Более подробная информация по детектированным сигнатурам на каждом программном блейде
Мониторинг
Важно отслеживать как минимум следующие параметры:
- состояние кластера;
- доступность компонент Check Point'а;
- загрузку процессора;
- оставшееся место на диске;
- свободную память.
У Check Point'а есть отдельный программный блейд – Smart Monitoring (отдельная лицензия). В нем можно дополнительно следить за доступностью компонент Check Point'а, нагрузками на отдельные блейды, статусами лицензий.


График по нагрузке на Chek Point. Всплеск – это заказчик отправлял push-уведомления 800 тыс. клиентам

График по нагрузке на блейд Firewall в той же ситуации
Мониторинг можно настроить и через сторонние сервисы. У нас, например, также используется Nagios, где мы мониторим:
- сетевую доступность оборудования;
- доступность кластерного адреса;
- загрузку CPU по ядрам. При загрузке более 70% приходит оповещение на почту. Такая высокая загрузка может говорить о специфическом трафике (vpn, например). Если это часто повторяется, то, возможно, не хватает ресурсов и стоит расширить пул.
- свободную оперативную память. Если остается меньше 80%, то мы об этом узнаем.
- загрузка диска по определенным партициям, например var/log. Если она скоро забьется, то надо расширять.
- Split Brain (на уровне кластера). Отслеживаем состояние, когда обе ноды становятся активными и между ними пропадает синхронизация.
- High availability mode – отслеживаем, что кластер работает в режиме active-standby. Смотрим на состояния нод – active, standby, down.

Параметры мониторинга в Nagios
Также стоит мониторить состояние физических серверов, на которых развернуты ESXi-хосты.
Резервное копирование
Сам вендор рекомендует делать снепшот сразу после инсталляции обновления (Hotfixies).
В зависимости от частоты изменений настраивается полный бэкап раз в неделю или месяц. В нашей практике мы делаем ежедневное инкрементное копирование файлов Check Point и полный бэкап раз в неделю.
На этом все. Это были самые базовые моменты, которые нужно учесть при развертывании виртуальных Check Point’ов. Но даже выполнение этого минимума поможет избежать проблем с их работой.
Читайте также: