
Из перечисленного достоинством полностью ассоциативный кэш памяти является
Обновлено: 04.07.2024
Вы здесь: Главная Память. Нижний уровень КЭШ-память Ассоциативная память
Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Ассоциативная память
Ассоциативная память
В ассоциативной памяти элементы выбираются не по адресу, а по содержимому. Поясним последнее понятие более подробно. Для памяти с адресной организацией было введено понятие минимальной адресуемой единицы (МАЕ) как порции данных, имеющей индивидуальный адрес. Введем аналогичное понятие для ассоциативной памяти, и будем эту минимальную единицу хранения в ассоциативной памяти называть строкой ассоциативной памяти (СтрАП). Каждая СтрАП содержит два поля: поле тега (англ. tag — ярлык, этикетка, признак) и поле данных. Запрос на чтение к ассоциативной памяти словами можно выразить следующим образом: выбрать строку (строки), у которой (у которых) тег равен заданному значению.
Особо отметим, что при таком запросе возможен один из трех результатов:
- имеется в точности одна строка с заданным тегом;
- имеется несколько строк с заданным тегом;
- нет ни одной строки с заданным тегом.
Поиск записи по признаку — это действие, типичное для обращений к базам данных, и поиск в базе зачастую чвляется ассоциативным поиском. Для выполнения такого поиска следует просмотреть все записи и сравнить заданный тег с тегом каждой записи. Это можно сделать и при использовании для хранения записей обычной адресуемой памяти (и понятно, что это потребует достаточно много времени — пропорционально количеству хранимых записей!). Об ассоциативной памяти говорят тогда, когда ассоциативная выборка данных из памяти поддержана аппаратно. При записи в ассоциативную память элемент данных помещается в СтрАП вместе с присущим этому элементу тегом. Для этого можно использовать любую свободную СтрАП. Рассмотрим разновидности структурной организации КЭШ-памяти или способы отображения оперативной памяти на КЭШ.
Полностью ассоциативный КЭШ
Схема полностью ассоциативного КЭШа представлена на рисунке (см. рисунок ниже).
Опишем алгоритм работы системы с КЭШ-памятью. В начале работы КЭШ-память пуста. При выполнении первой же команды во время выборки ее код, а также еще несколько соседних байтов программного кода, — будут перенесены (медленно) в одну из строк КЭШа, и одновременно старшая часть адреса будет записана в соответствующий тег. Так происходит заполнение КЭШ-строки.
Если следующие выборки возможны из этого участка, они будут сделаны уже из КЭШа (быстро) — "КЭШ-попадание". Если же окажется, что нужного элемента в КЭШе нет, — "КЭШ-промахом". В этом случае обращение происходит к ОЗУ (медленно), и при этом одновременно заполняется очередная КЭШ-строка.
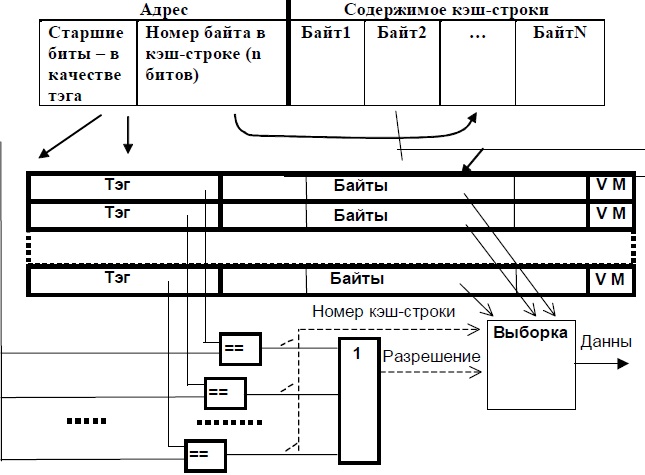
Схема полностью ассоциативной КЭШ-памяти
Обращение к КЭШу происходит следующим образом. После формирования исполнительного адреса его старшие биты, образующие тег, аппаратно (быстро) и одновременно сравниваются с тегами всех КЭШ-строк. При этом возможны только две ситуации из трех, перечисленных ранее: либо все сравнения дадут отрицательный результат (КЭШ-промах), либо положительный результат сравнения будет зафиксирован в точности для одной строки (КЭШ-попадание).
При считывании, если зафиксировано КЭШ-попадание, младшие разряды адреса определяют позицию в КЭШ-строке, начиная с которой следует выбирать байты, а тип операции определяет количество байтов. Очевидно, что если длина элемента данных превышает один байт, то возможны ситуации, когда этот элемент (частями) расположен в двух (или более) разных КЭШ-строках, тогда время на выборку такого элемента увеличится. Противодействовать этому можно, выравнивая операнды и команды по границам КЭШ-строк, что и учитывают при разработке оптимизирующих трансляторов или при ручной оптимизации кода.
Если произошел КЭШ-промах, а в КЭШе нет свободных строк, необходимо заменить одну строку КЭШа на другую строку.
Основная цель стратегии замещения — удерживать в КЭШ-памяти строки, к которым наиболее вероятны обращения в ближайшем будущем, и заменять строки, доступ к которым произойдет в более отдаленном времени или вообще не случится. Очевидно, что оптимальным будет алгоритм, который замещает ту строку, обращение к которой в будущем произойдет позже, чем к любой другой строке-КЭШ.
К сожалению, такое предсказание практически нереализуемо, и приходится привлекать алгоритмы, уступающие оптимальному. Вне зависимости от используемого алгоритма замещения, для достижения высокой скорости он должен быть реализован аппаратными средствами.
Среди множества возможных алгоритмов замещения наиболее распространенными являются четыре, рассматриваемые в порядке уменьшения их относительной эффективности. Любой из них может быть применен в полностью ассоциативном КЭШ.
Наиболее эффективным является алгоритм замещения на основе наиболее давнего использования ( LRU — Least Recently Used ), при котором замещается та строка КЭШ-памяти, к которой дольше всего не было обращения. Проводившиеся исследования показали, что алгоритм LRU, который "смотрит" назад, работает достаточно хорошо в сравнении с оптимальным алгоритмом, "смотрящим" вперед.
Наиболее известны два способа аппаратурной реализации этого алгоритма. В первом из них с каждой строкой КЭШ-памяти ассоциируют счетчик. К содержимому всех счетчиков через определенные интервалы времени добавляется единица. При обращении к строке ее счетчик обнуляется. Таким образом, наибольшее число будет в счетчике той строки, к которой дольше всего не было обращений и эта строка — первый кандидат на замещение.
Второй способ реализуется с помощью очереди, куда в порядке заполнения строк КЭШ-памяти заносятся ссылки на эти строки. При каждом обращении к строке ссылка на нее перемещается в конец очереди. В итоге первой в очереди каждый раз оказывается ссылка на строку, к которой дольше всего не было обращений. Именно эта строка прежде всего и заменяется.
Другой возможный алгоритм замещения — алгоритм, работающий по принципу "первый вошел, первый вышел" ( FIFO — First In First Out ). Здесь заменяется строка, дольше всего находившаяся в КЭШ-памяти. Алгоритм легко реализуется с помощью рассмотренной ранее очереди, с той лишь разницей, что после обращения к строке положение соответствующей ссылки в очереди не меняется.
Еще один алгоритм — замена наименее часто использовавшейся строки (LFU — Least Frequently Used). Заменяется та строка в КЭШ-памяти, к которой было меньше всего обращений. Принцип можно воплотить на практике, связав каждую строку со счетчиком обращений, к содержимому которого после каждого обращения добавляется единица. Главным претендентом на замещение является строка, счетчик которой содержит наименьшее число.
Простейший алгоритм — произвольный выбор строки для замены. Замещаемая строка выбирается случайным образом. Реализовано это может быть, например, с помощью счетчика, содержимое которого увеличивается на единицу с каждым тактовым импульсом, вне зависимости от того, имело место попадание или промах. Значение в счетчике определяет заменяемую строку.
Кроме тега и байтов данных в КЭШ-строке могут содержаться дополнительные служебные поля, среди которых в первую очередь следует отметить бит достоверности V (от valid — действительный имеющий силу) и бит модификации M (от modify — изменять, модифицировать). При заполнении очередной КЭШ-строки V устанавливается в состояние "достоверно", а M — в состояние "не модифицировано". В случае, если в ходе выполнения программы содержимое данной строки было изменено, переключается бит M, сигнализируя о том, что при замене данной строки ее содержимое следует переписать в ОЗУ. Если по каким-либо причинам произошло изменение копии элемента данной строки, хранимого в другом месте (например в ОЗУ), переключается бит V. При обращении к такой строке будет зафиксирован КЭШ-промах (несмотря на то, что тег совпадает), и обращение произойдет к основному ОЗУ. Кроме того, служебное поле может содержать биты, поддерживающие алгоритм LRU.
Оценка объема оборудования
Типовой объем КЭШ-памяти в современной системе — 8…1024 кбайт, а длина КЭШ-строки 4…32 байт. Дальнейшая оценка делается для значений объема КЭШа 256 кбайт и длины строки 32 байт, что характерно для систем с процессорами Pentium и PentiumPro. Длина тега при этом равна 27 бит, а количество строк в КЭШе составит 256К/ 32=8192. Именно столько цифровых компараторов 27 битных кодов потребуется для реализации вышеописанной структуры.
Приблизительная оценка затрат оборудования для построения цифрового компаратора дает значение 10 транз/бит, а общее количество транзисторов только в блоке компараторов будет равно:
10*27*8192 = 2 211 840,
что приблизительно в полтора раза меньше общего количества транзисторов на кристалле Pentium. Таким образом, ясно, что описанная структура полностью ассоциативной КЭШ-памяти ( ассоциативная память ) реализуема только при малом количестве строк в КЭШе, т.е. при малом объеме КЭШа (практически не более 32…64 строк). КЭШ большего объема строят по другой структуре.
Из перечисленного важнейшими особенностями языка VHDL являются 1) понятие параллелизма выполнения действий 2) понятие наследования свойств объектов 3) использование рекурсивных функций 4) введение физического типа данных
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного введение специализированных аппаратных ядер в FPGA и CPLD 1) уменьшает стоимость микросхемы 2) сокращает площадь кристалла при реализации сложных функций 3) увеличивает универсальность микросхем 4) ведет к достижению максимального быстродействия
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного второй байт команды микропроцессора К1821 может содержать 1) сведения о способе адресации 2) адрес ВУ 3) старший полуадрес операнда 4) непосредственный операнд
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного входные буферы ПЛМ выполняют действия 1) соединяют выход любого логического элемента со входами других 2) преобразуют однофазные входные сигналы в парафазные 3) формируют сигналы необходимой мощности для питания матрицы элементов И 4) осуществляют динамическую реконфигурацию
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного выходные буферы ПЛМ выполняют действия 1) осуществляют инвертирование выходных сигналов 2) обеспечивают необходимую нагрузочную способность выходов 3) формируют сигналы необходимой мощности для питания матрицы элементов И 4) разрешают или запрещают выход ПЛМ на внешние шины
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного дешифратор команд в МП Л1839ВМ1 выполняет следующие функции 1) формирование адресов команд и операндов 2) хранение адресов, операндов и результатов выполнения операций на регистрах 3) формирование начального адреса микропрограммы обработки команды 4) управление по выделению из программы смещений адресации и констант
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного для борьбы с помехами, возникающими из-за наличия токовых импульсов, используют: 1) "хорошую землю" 2) фильтрацию напряжений питания 3) коаксиальные кабели, витые пары 4) экранирование устройства
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного для исключения возможных сбоев в работе цифрового устройства из-за явлений риска используют: 1) введение избыточных элементов 2) запрещение восприятия сигналов комбинационной схемы элементами памяти на время переходных процессов 3) фильтрацию напряжений питания 4) введение RC-цепей
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного для реализации задержек на практике используют: 1) цепочки логических элементов 2) RC-цепочки 3) LC-цепочки 4) оптопары
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного достоинствами динамических ЗУ являются 1) высокое быстродействие 2) отсутствие необходимости регенерации 3) большая информационная емкость 4) невысокая стоимость
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного достоинствами ЗУ с электрическим стиранием информации по сравнению с ЗУ с УФ-стиранием являются 1) возможность стирания информации индивидуально для каждого адреса 2) высокий уровень интеграции 3) низкая стоимость 4) большое число возможных циклов перепрограммирования
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного достоинствами ЗУ типа PROM являются 1) простота программирования пользователем 2) невысокая стоимость 3) высокий уровень интеграции 4) коэффициент программируемости, близкий к единице
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного достоинствами статических ЗУ являются 1) высокое быстродействие 2) отсутствие необходимости регенерации 3) большая информационная емкость 4) невысокая стоимость
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного достоинствами файловой Флэш-памяти по сравнению с твердыми дисками являются 1) высокая информационная емкость 2) низкая стоимость 3) низкая потребляемая мощность 4) высокое быстродействие при чтении данных
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного достоинством полностью ассоциативной кэш-памяти является 1) простота организации 2) функциональная гибкость 3) бесконфликтность адресов 4) малый размер тега
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного информационный буфер позволяет 1) повысить независимость устройств, участвующих в обмене 2) хранить копии информации, используемой в текущих операциях обмена 3) согласовать скорости передачи и приема данных 4) работать в режиме непосредственного обмена с процессором
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного использование ПЗУ для замены комбинационных схем имеет недостатки 1) высокая чувствительность к моменту изменения входных сигналов 2) необходимость использования выходных резисторов в некоторых случаях 3) простота изменения логики работы схемы 4) простота проектируемого устройства
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного к однократно программируемым СБИС ПЛ относятся 1) с перемычками типа antifuse 2) с триггерной памятью конфигурации 3) с УФ-стиранием 4) EPROM-OTP
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного к релаксационным генераторам, вырабатывающим электрические колебания, близкие по форме к прямоугольным, относятся: 1) мультивибраторы 2) блокинг-генераторы 3) одновибраторы 4) элементы задержки
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного к репрограммируемым СБИС ПЛ относятся 1) с перемычками типа antifuse 2) с триггерной памятью конфигурации 3) с УФ-стиранием 4) EPROM-OTP
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного каждая логическая микросхема обязательно имеет выводы для: 1) сигнала перевода в третье состояние 2) питания 3) выходных сигналов 4) синхронизации
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного контроллер ПДП при блочных передачах выполняет действия 1) преобразование данных из потоковой формы в параллельную 2) выдача сигнала подтверждения прерывания 3) прием сведений об области памяти, отведенной для блока данных 4) генерация адресов для ЗУ и сигналов управления для ЗУ и ВУ
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного контроллер прерываний выполняет действия 1) сохраняет текущее состояние регистров микропроцессора в стеке 2) выдает запрос прерывания INT для микропроцессора 3) определяет, какой из незамаскированных запросов имеет наивысший приоритет 4) вызывает подпрограмму обработки прерывания
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного на сумматорах, входящих в состав сумматора с условным переносом, производится суммирование: 1) младших полей операндов при единичном значении сигнала переноса из старшего сумматора 2) полученного значения суммы операндов и предыдущего значения суммы 3) старших полей операндов при единичном значении сигнала переноса из младшего сумматора 4) старших полей операндов при нулевом значении сигнала переноса из младшего сумматора
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного одновибратор может применяться для: 1) формирования сигнала огибающей последовательности входных импульсов 2) изменения амплитуды входного импульса 3) формирования выходных импульсов заданной длительности с высокой точностью 4) изменения длительности входного импульса
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного операционный блок в МП Л1839ВМ1 выполняет следующие функции 1) формирование адресов команд и операндов 2) хранение адресов, операндов и результатов выполнения операций на регистрах 3) формирование начального адреса микропрограммы обработки команды 4) управление по выделению из программы смещений адресации и констант
Тема/шкала: 1219.Зач.01;ТБПД.01;1 - Тестовая база по дисциплине - Схемотехника ЭВМ (для специалистов)
Из перечисленного операцию монтажной логики можно получить, если разрешить активную работу элементов и соединить параллельно выходы: 1) логические 2) с третьим состоянием 3) с открытым коллектором 4) с открытым эмиттером
За счет чего же мы наблюдаем постоянный рост производительности однопоточных программ? В данный момент мы находимся на той ступени развития микропроцессорных технологий, когда прирост скорости работы однопоточных приложений зависит только от памяти. Количество ядер растет, но частота зафиксировалась в пределах 4 ГГц и не дает прироста производительности.
Скорость и частота работы памяти — это то основное за счет чего мы получаем «свой кусок бесплатного торта» (ссылка). Именно поэтому важно использовать память, настолько эффективно, насколько мы можем это делать, а тем более такую быструю как кэш. Для оптимизации программы под конкретный компьютер, полезно знать характеристики кэш-памяти процессора: количество уровней, размер, длину строки. Особенно это важно в высокопроизводительном коде — ядра систем, математические библиотеки.
Как же определить характеристики кэша автоматический? (естественно cpuinfo распарсить не считается, хотя-бы потому-что в конечном итоге мы бы хотели получить алгоритм, который можно без труда реализовать в других ОС. Удобно, не правда ли? ) Именно этим мы сейчас и займемся.
Немного теории
В данный момент существуют и широко используются три разновидности кэш-памяти: кэш с прямым отображением, ассоциативный кэш и множественно-ассоциативный кэш.
Кэш с прямым отображением (direct mapping cache)
— данная строка ОЗУ может быть отображена в единственную строку кэша, но в каждую строку кэша может быть отображено много возможных строк ОЗУ.

Ассоциативный кэш (fully associative cache)
— любая строка ОЗУ может быть отображена в любую строку кэша.

Множественно-ассоциативный кэш
— кэш-память делится на несколько «банков», каждый из которых функционирует как кэш с прямым отображением, таким образом строка ОЗУ может быть отображена не в единственную возможную запись кэша (как было бы в случае прямого отображения), а в один из нескольких банков; выбор банка осуществляется на основе LRU или иного механизма для каждой размещаемой в кэше строки.

LRU — вытеснение самой «долго не использованной» строки, кэш памяти.
Чтобы определить количество уровней кэша нужно рассмотреть порядок обращений к памяти, на котором будет четко виден переход. Разные уровни кэша отличаются прежде всего скоростью отклика памяти. В случае «кэш-промаха» для кэша L1 будет произведен поиск данных в следующих уровнях памяти, при этом если размер данных больше L1 и меньше L2 — то скоростью отклика памяти будет скорость отклика L2. Предыдущее утверждение так же верно в общем случаи.
Ясно что нужно подобрать тест на котором, мы будем четко видеть кэш промахи и протестировать его на различных размерах данных.
Зная логику множественно-ассоциативных кэшей, работающих по алгоритму LRU не трудно придумать алгоритм на котором кэш «валится», ничего хитрого — проход по строке. Критерием эффективности будем считать время одного обращения к памяти. Естественно нужно последовательно обращаться ко всем элементам строки, повторяя многократно для усреднения результата. К примеру возможны случаи, когда строка умещается в кэше но для первого прохода мы грузим строку из оперативной памяти и потому получаем совсем неадекватное время.
Хочется увидеть что-то подобное ступенькам, проходя по строкам разной длины. Для определения характера ступенек рассмотрим пример прохода по строке для прямого и ассоциативного кэша, случай с множественно-ассоциативным кэшем будет среднем между кэшем с прямым отображением и ассоциативным кэшем.
Как только размер данных превышает размер кэш-памяти,
полностью ассоциативный кэш «промахивается» при каждом обращении к памяти.

Рассмотрим разные размеры строк. — показывает максимальное количество промахов, которое потратит процессор для доступа к элементам массива при следующем проходе по строке.

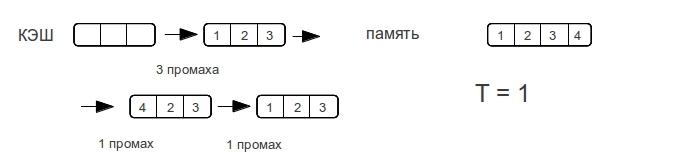
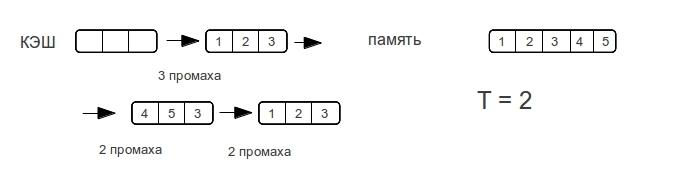
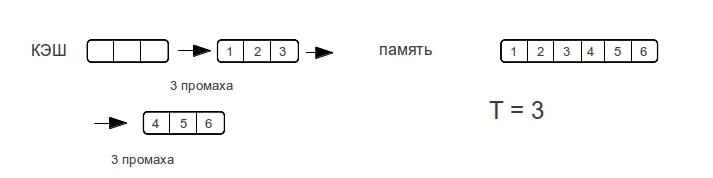
Как видно время доступа к памяти возрастает не резко, а по мере увеличения объема данных. Как только размер данных превысит размер кэша, то промахи будут при каждом обращении к памяти.
Потому у ассоциативного кэша ступенька будет вертикальной, а у прямого — плавно возрастать вплоть до двойного размера кэша. Множественно ассоциативный кэш будет средним случаем, «бугорком», хотя бы потому, что время-доступа не может быть лучше прямого.
Если-же говорить о памяти — то самая быстрая это кэш, следом идет оперативная, самая медленная это swap, про него мы в дальнейшем говорить не будем. В свою очередь у разных уровней кэша (как правило сегодня процессоры имеют 2-3 уровня кэша) разная скорость отклика памяти: чем больше уровень, тем меньше скорость отклика. И поэтому, если строка помещается в первый уровень кэша, (который кстати полностью ассоциативный) время отклика будет меньше, чем у строки значительно превышающей размеры кэша первого уровня. По-этому на графике времени отклика памяти от размеров строки будет несколько плато — плато* отклика памяти, и плато вызванные различными уровнями кэша.
Приступим к реализации
Для реализации будем использовать Си (ANSI C99).
Быстро написан код, обычный проход по строкам разной длины, меньше 10мб, выполняющийся многократно. (Будем приводить небольшие куски программы, несущие смысловую нагрузку).

Очевидно что это может происходить по двум причинам: либо в процессоре нет кэш памяти, либо процессор так хорошо угадывает обращения к памяти. Поскольку первый вариант ближе к фантастике причина всему хорошее предсказание обращений.
Дело в том, что сегодня далеко не топовые процессоры, помимо принципа пространственной локальности, предсказывают также и арифметическую прогрессию в порядке обращения к памяти. Поэтому нужно рандомизовать обращения к памяти.
Длина рандомизованного массива должна быть сопоставимой с длиной основной строки, чтобы избавиться от большой гранулярности обращений, так же длина массива не должна быть степенью двойки, из-за этого происходили «наложения» — следствием чего могут — быть выбросы. Лучше всего задать гранулярность константно, в том числе, если гранулярность простое число, то можно избежать эффектов наложений. А длина рандомиованого массива — функция от длинны строки.
После чего мы удивили столь долгожданную «картинку», о которой говорили в начале.


Программа разбита на 2 части — тест и обработка данных. Написать скрипт в 3 строки для запуска или 2 раза запустить ручками решайте сами.
Листинг файла size.с Linux
Листинг файла size.с Windows
В общем- то думаю все понятно, но хотелось бы оговорить несколько моментов.
Массив A объявлен как volatile — эта директива гарантирует нам что к массиву A всегда будут обращения, то-есть их не «вырежут» ни оптимизатор, ни компилятор. Так-же стоит оговорить то что вся вычислительная нагрузка выполняется до замера времени, что позволяет нам, уменьшить фоновое влияние.
Файл переведен в ассемблер на Ubuntu 12.04 и компилятором gcc 4.6 — циклы сохраняются.
Обработка данных
Для обработки данных логично использовать производные. И несмотря на то что с повышением порядка дифференцирования шумы возрастают, будет использована вторая производная и её свойства. Как бы не была зашумлена вторая производная, нас интересует лишь знак второй производной.
Находим все точки, в которых вторая производная больше нуля (с некоторой погрешностью потому-что вторая производная, помимо того что считается численно, — сильно зашумлена ). Задаем функцию зависимости знака второй производной функции от размера кэша. Функция принимает значение 1 в точках, где знак второй производной больше нуля, и ноль, если знак второй производной меньше или равен нулю.
Точки «взлетов» — начало каждой ступеньки. Также перед обработкой данных нужно убрать одиночные выбросы, которые не меняют смысловой нагрузки данных, но создают ощутимый шум.
Листинг файла data_pr.с
Тесты
CPU/ОС/версия ядра/компилятор/ключи компиляции — будут указаны для каждого теста.
Intel Pentium CPU P6100 @2.00GHz / Ubuntu 12.04 / 3.2.0-27-generic / gcc -Wall -O3 size.c -lrt
Давайте поговорим о «граблях»
Грабля обнаружилась при обработке данных на серверном процессоре Intel Xeon 2.4/L2 = 512 кб/Windows Server 2008

Проблема заключается в маленьком количестве точек, попадающих на интервал выхода на плато, — соответственно, скачок второй производной незаметен и принимается за шум.
Можно решить эту проблему методом наименьших квадратов, либо прогонять тесты в по ходу определения зон плато.
Ассоциат-я кэш-память. В этом случае информация поступившая из процессора или переносимая из ОП может расположится в любой строке кэш. Адрес рассматривается контролером кэш, состоящим из двух групп бит: младшие биты и смещение.
В соответствии с адресом выставленном процессором, контролер кэш осуществляет параллельный ассоциативный поиск во всех строках кэш. В качестве ассоциативного признака используются старшие биты адреса, которые сравниваются с тегами строк.
Если в кэш имеется строка, удовлетворяющая ассоциативному признаку, из той строки процессору предаются байты, начина яс номера, определяемого смещением.
Достоинством ассоциативной кэш является то, что инф-я может располагаться в любой строке. Недостатком является большие аппаратные затраты для параллельного поиска во всех строках кэш.
Наборно-ассоциативная кэш-память. В этом случае все строки кэш разделяются на группы (наборы). В представленных наборах осуществляется ассоциативный поиск. А инф-ция о ноборе задается в коде адреса
В этом случае контролер кэш по мере набора определяет группу строк, в которой осуществляется параллельный ассоциативный поиск, если требу-я ин-цмя имеется в наборе. В соответствии со смещением осуществляется пересылка ин-ции из строки в процессор.
В современных ЭВМ наиболее часто используется кэш-память с двумя и четырьмя наборами.
В системах с КЭШ - памятью нужно учитывать, что в ЭВМ хранится одновременно две копии инф. с одинаковыми адресами - одна в КЭШ, другая в ОП. При модификации данных они прежде всего заносятся в КЭШ. Может возникнуть ситуация, когда в КЭШ и ОП по одному и тому же адресу будут храниться различные данные. Для недопущения ситуации, когда в процессе исполнения программы могут быть использованы старые данные, что приведет к ошибке, сущ. спец. способы обновления КЭШ - памяти.
Системы со сквозной записью - в этом случае модифицированные данные заносятся в КЭШ и сразу же перезаписываются в ОП. Это исключает появление различных копий в ОП и КЭШ. Недостатком этого способа обновления явл. частое обр. к ОП, что снижает производительность системы.
Система со сквозной записью и буферизацией - в этом случае модиф. данные задерживаются в КЭШ (спец. буфере перед записью их в ОП). Это дает возможность проц. приступить к выполнению след. команды не дожидаясь, пока данные будут переписаны из КЭШ в ОП. В этом случае увеличение произв. обеспечивается, если при выполнении след. команды имеет место КЭШ - попадание. В рассматриваемом случае (как и в предыдущем) модифиц. данные, хранящ. в КЭШ могут быть исп. каким - либо устр-вом ЭВМ только после перезаписи их в ОП. Обычно КЭШ имеет только1 буфер.
Повторная запись - в этом случае в тэге КЭШ - памяти исп. дополнительный бит изменения. Этот бит устанавливается в 1, если в данную строку КЭШ занесены модиф. данные, кот. ещё не перезаписаны в ОП. При обращении к строке КЭШ контроллер кэш проверяет бит изменения, если в нем 1 перед занесением в эту строку новых данных контроллер перезаписывает их в ОП, после этого записывает новые, если бит изменения 0, в строку кэш сразу же записываются новые данные без перенесения строки в ОП.
Читайте также: