
Извлечь информацию из html файла
Обновлено: 07.07.2024
Я хотел бы извлечь текст из HTML-файла с помощью Python. Я хочу получить тот же результат, что и при копировании текста из браузера и вставке его в блокнот.
Я хотел бы что-то более надежное, чем использование регулярных выражений, которые могут не работать на плохо сформированном HTML. Я видел, как многие люди рекомендуют красивый суп, но у меня было несколько проблем с его использованием. Во-первых, он взял нежелательный текст, такой как источник JavaScript. Кроме того, он не интерпретировал объекты HTML. Например, я ожидал бы, что " in HTML source будет преобразован в Апостроф в тексте, как если бы я вставил содержимое браузера в блокнот.
обновление html2text выглядит многообещающе. Он правильно обрабатывает HTML-объекты и игнорирует JavaScript. Однако это не совсем простой текст; он создает уценку, которая затем должна быть превращена в обычный текст. В нем нет примеров или документации, но код выглядит чистым.
- отфильтровать HTML-теги и разрешить объекты в python
- преобразование объектов XML / HTML в строку Unicode в Python
html2text Это программа Python, которая делает довольно хорошую работу в этом.
лучший кусок кода, который я нашел для извлечения текста без получения javascript или не хотел вещей:
вам просто нужно установить BeautifulSoup перед :
Примечание: NTLK больше не поддерживает clean_html функции
оригинальный ответ ниже и альтернатива в разделах комментариев.
Я потратил свои 4-5 часов, исправляя проблемы с html2text. К счастью, я мог столкнуться с НЛТК.
Это работает волшебно.
сегодня я столкнулся с той же проблемой. Я написал очень простой парсер HTML, чтобы очистить входящее содержимое от всех наценок, возвращая оставшийся текст с минимальным форматированием.
вот версия ответа xperroni, которая немного более полная. Он пропускает разделы сценария и стиля и переводит charrefs (например, ') и HTML-объекты (например, &).
Он также включает в себя тривиальный преобразователь простого текста в html.
вы также можете использовать метод html2text в библиотеке stripogram.
для установки stripogram запустите sudo easy_install stripogram
существует библиотека шаблонов для интеллектуального анализа данных.
вы даже можете решить, какие теги сохранять:
PyParsing делает большую работу. Pyparsing wiki был убит, поэтому вот еще одно место, где есть примеры использования PyParsing (пример ссылки). Одна из причин, по которой он потратил немного времени на pyparsing, заключается в том, что он также написал очень краткое, очень хорошо организованное руководство O'Reilly Short Cut, которое также является недорогим.
обновление
основываясь на комментарии Фрейзера, вот более элегантное решение:
таким образом, вы можете сделать что-то вроде:
вместо модуля HTMLParser проверьте htmllib. Он имеет аналогичный интерфейс, но делает больше работы для вас. (Он довольно древний, поэтому это не очень помогает с точки зрения избавления от javascript и css. Вы можете создать производный класс, но и добавить методы с именами, такими как start_script и end_style (см. документы python для деталей), но это трудно сделать надежно для искаженного html.) Во всяком случае, вот что-то простое, что печатает простой текст на консоль
Если вам нужно больше скорости и меньше точности, то вы можете использовать raw lxml.
установить html2text используя
красивый суп преобразует HTML-объекты. Это, вероятно, ваш лучший выбор, учитывая, что HTML часто глючит и заполнен проблемами кодирования unicode и html. Это код, который я использую для преобразования html в необработанный текст:
Я рекомендую пакет Python под названием goose-extractor Гусь попытается извлечь следующую информацию:
основной текст статьи Основное изображение статьи Любые фильмы Youtube/Vimeo, встроенные в статью метаописание Мета теги
другой вариант-запустить html через текстовый веб-браузер и сбросить его. Например (с помощью Lynx):
Это можно сделать в скрипте python следующим образом:
Он не даст вам точно только текст из HTML-файла, но в зависимости от вашего варианта использования он может быть предпочтительнее вывода html2text.
другое решение, отличное от python: Libre Office:
причина, по которой я предпочитаю этот вариант другим альтернативам, заключается в том, что каждый HTML-абзац преобразуется в одну текстовую строку (без разрывов строк), что я и искал. Другие методы требуют последующей обработки. Lynx производит хороший результат, но не совсем то, что я искал. Кроме того, Libre Office можно использовать для конвертации из любых форматов.
Если у вас уже есть HTML-файлы, загруженные вами можете сделать что-то вроде этого:
Он даже имеет несколько функций НЛП для обобщения тем статей:
этот код находит все части html_text, начинающиеся с " " и заменяют все найденные пустой строкой
@peyotil's ответ, используя BeautifulSoup и устраняя стиль и содержание сценария не работал для меня. Я попробовал использовать decompose вместо extract но это все равно не сработало. Поэтому я создал свой собственный, который также форматирует текст с помощью <p> теги и заменяет <a> теги со ссылкой href. Также справляется со ссылками внутри текста. Доступно по адресу в этом суть С встроенным тестовым документом.
Вам требуется открыть и скопировать код HTML-документа или web-сайта? Если да, то этот онлайн-сервис поможет вам сделать это быстро и легко. Вам не придётся устанавливать программы на компьютер, ноутбук или приложения на телефон. Копировать код веб-страницы вы сможете с помощью обычного браузера и на любом мобильном. HTML-файлы открываются, как на iPhone, так и на смартфонах с операционной системой Android. Открывать консоль или настройки браузера, устанавливать дополнительные расширения больше не нужно. Сохранить код вы сможете по ссылке на интернет-ресурс.
Сервис для копирования HTML-файла сайта
Если вам требуется скопировать HTML-документ сайта из интернета, то данный сервис и онлайн-поиском кода поможет вам в этом. Здесь вы сможете осуществить копирование кода без установки специальных программ и приложений. Сохранить HTML-код можно будет, как на компьютере или на ноутбуке, так и на любом смартфоне.

Больше нет необходимости открывать настройки браузера и консоль интернет-навигатора. Осуществить копирование содержимого HTML-документа, понравившегося вам веб-ресурса, вы сможете по ссылке на страницу. При этом не важно какой интернет-источник, это может быть как обычный сайт, так и защищенный.
Стоит заметить, что операционная система на вашем ПК также не имеет значения. Это могут быть такие ОС, как Windows, Linux или Mac OS для MacBook. Воспользуйтесь онлайн-парсером HTML-файла , чтобы в потом сохранить его содержимое, например, в Ворде, блокноте или в обычном текстовом документе.
Скопируйте HTML-документ по ссылке на сайт
Скачайте HTML-код необходимого вам веб-ресурса быстро, бесплатно и легко. Для того чтобы получить содержимое web-документа выполните следующие действия. Сначала из адресной строки браузера скопируйте веб-ссылку на страницу сайта. Далее вставьте её в поле ниже и запустите процесс копирования.
Не обновляйте и не покидайте страницу! Идет сканирование содержимого web-ресурса. Возможно ссылка указана не верно, а может что-то пошло не так. Повторите сканирование или обратитесь за помощью к специалисту!Выделите и скопируйте содержимое
В результате сканирования найден HTML-код, который вы можете выделить и сохранить на компьютере или телефоне. Внимательно ознакомьтесь с найденными данными, пролистав содержимое окна ниже.
Как открыть и скопировать HTML-код страницы

Копируем ссылку на страницу web-сайта
Итак, первое, что вам потребуется сделать перед тем, как вы скопируете HTML-код - это открыть веб-страницу ресурса. Для этой цели вам подойдет любой гаджет с браузером. Этим устройством может быть, как компьютер, так и мобильный телефон, разницы нет. Как только страница будет загружена, обратите внимание на адресную строку вверху интернет-навигатора. Здесь располагается уникальная ссылка, которую вам нужно будет выделить и скопировать.

Сканируем содержимое HTML-документа
Следующим этапом, после того, как вы скопируете web-адрес, будет сканирование интернет-ресурса с помощью web-сканера кода . Для того чтобы получить содержимое HTML-документа, вставьте скопированную ссылку в поле для веб-адреса и запустите процесс копирования, нажав на кнопку «Скопировать». В результате этих действий начнётся выгрузка содержимого HTML-файла. Процедура парсинга страницы не займёт у вас много времени.

Выделяем и сохраняем код веб-ресурса
По завершению процесса извлечение данных вы увидите специальное окно, в котором будет отображаться содержимое web-источника. Вам предстоит выполнить заключительное действие - копировать HTML-код. Для этого выделите необходимые вам строчки кода и скопируйте их. Далее вам останется всего лишь сохранить информацию у себя на устройстве. Для этой цели вам подойдет Word, блокнот или любой другой текстовый редактор.
Самые популярные вопросы
Скопировать HTML-код сайта можно будет бесплатно?
Как копировать содержимое HTML-файла на компьютер?
Если вам требуется осуществить копирование кода интернет-ресурса на ПК или ноутбук, то для начала вам необходимо будет открыть интересующий сайт в браузере. Далее скопируйте ссылку из адресной строки интернет-навигатора и воспользуйтесь данным сервисом. После того, как вы получите желаемый HTML-код, сохраните его в текстовом файле. Для этого отлично подойдет Ворд, блокнот или любой другой текстовый редактор. Кстати, стоит заметить, что не важно какая у вас операционная система, это может быть Windows, Linux или Mac OS от Apple.
Требуется сохранить web-документ на телефон. Как это сделать?
Процесс сохранения HTML-данных на смартфонах и планшетах в точности повторяет процедуру копирования на ПК. Для открытия и копирования кода веб-ресурса вам всего лишь нужен браузер и данный онлайн-сервис. Для начала скопируйте электронный адрес web-страницы, а затем воспользуйтесь HTML-парсером сайта . В результате парсинга данных вам будет доступно содержание HTML-документа, которое вы позже сможете сохранить в блокноте или любом другом текстовом документе.
Как скачать код веб-страницы на Айфоне и Андроиде?
Абсолютно неважно каким мобильным устройством вы пользуетесь для того, чтобы открыть HTML-файл сайта. Это может быть iPhone от Apple или любой гаджед на базе операционной системы Android. Для того чтобы сохранить код web-страницы, достаточно будет на вашем смартфоне или планшете открыть обычный браузер. При этом не потребуется устанавливать дополнительные расширения и плагины для него. Просто запустите интернет-навигатор и воспользуйтесь данным сервисом.
Необходимо ли устанавливать программы и приложения, чтобы выгрузить код?
Нет. Вам не потребуется ставить дополнительные программы и свой компьютер и приложения на мобильный. Всё что вам потребуется для того чтобы получить код web-страницы - это стандартный интернет-навигатор, который есть на каждом мобильном устройстве. Откройте понравившийся сайт и воспользуйтесь HTML-парсингом кода . В результате вы сможете получить, необходимые вам данные, и скопировать их себе на PC или смарфон.
Нужно устанавливать расширения для браузера, чтобы открыть HTML-файл?
Нет. Никакие расширения для web-браузера вам не потребуются. Для того чтобы получить содержимое HTML-документа любого сайта, вам достаточно иметь под рукой обычный интернет-навигатор, без предустановленных плагинов. Следуйте инструкции, указанной выше, и вы сможете открыть код нужного вам web-ресурса и скопировать его строчки себе на жесткий диск или флешку.
Как можно получить код страницы по ссылке на web-сайт?
Для того чтобы открыть HTML-код по ссылке вам достаточно скопировать url-адрес страницы и воспользоваться web-сканером сайта . Следуйте простой инструкции, которая есть на этой странице и вы сможете посмотреть содержимое, интересующего вас веб-ресурса. Вначале вам потребуется запустить парсинг интернет-источника, а затем скопировать полученные данные на компьютер или мобильное устройство.
Как сохранить содержимое HTML-документа в Word?
Если вам требуется выгрузить данные HTML-страницы в Word или любой другой текстовый редактор, то в этой процедуре нет ничего сложного. Достаточно лишь ознакомиться с руководством по копированию кода, которое указано выше, а потом сделать всё как в инструкции. Весь процесс сохранения состоит из трёх простых операций. Вначале вам нужно будет скопировать урл-адрес интересующего вас веб-ресурса. Затем запустить сканирование web-страницы. А после парсинга скопировать данные в буфер обмена, после чего вставить их в текстовом файле. Такую процедуру вы можете произвести, как на ПК, так и на любом мобильном. Сохранить полученный HTML-код можно будет не только в Ворде, но и, к примеру, в блокноте.

В статье рассматривается реализация разбора структурированных текстов на примере анализа HTML-страниц средствами PHP
Разбор структурированного текста может быть осуществлен с помощью регулярных выражений или программных библиотек, предназначенных для восстановления его древовидной структуры. Но регулярные выражения для сложных текстов теряют наглядность, их становится трудно воспринимать и отлаживать. Построение структурного дерева текста требует больших затрат памяти и является излишним для многих практических задач.
При извлечении информации из HTML-страниц реальных интернет-сайтов можно столкнуться с ошибками верстки, которые не критичны для отображения этих страниц в браузере, но приводят к неожиданным эффектам при построении структурного дерева документа. Веб-мастера могут вносить на сайт незначительные изменения, помещать сведения в дополнительные контейнеры или, наоборот, уменьшать степень вложенности текстов. Желательно минимизировать влияние таких преобразований структуры документов на работу программы-анализатора, извлекающей информацию с сайта.
| Продемонстрируем извлечение информации из HTML-файла комбинированным способом |
В этой статье будет продемонстрировано, что построение собственного анализатора позволяет записать решение задачи анализа в императивных терминах, сохраняя при этом контроль над количеством используемых ресурсов – вычислительной мощности и оперативной памяти.
В общем виде анализатор текста должен состоять из трех модулей [1]:
- Лексический анализатор. На вход лексического анализатора подается исходный текст в виде последовательности символов – букв, цифр, скобок и знаков препинания. На выход лексического анализатора выдается последовательность лексем – слов, чисел, строк.
- Синтаксический анализатор. Принимает последовательность лексем от лексического анализатора, проверяет на соответствие формальным правилам и составляет на их основе таблицы идентификаторов и констант.
- Семантический анализатор использует результаты работы лексического и синтаксического анализаторов для окончательного решения задачи анализа текста, представляет собранную информацию в удобной для дальнейшего использования форме.
При разработке анализатора HTML-документов постараемся воспроизвести эту эталонную систему.
Определение элементов структуры текста
Начнем с лексического анализа. При его выполнении исходный текст последовательно просматривается от начала к концу с попутным выделением структурных элементов. В ходе анализа HTML-текста основной задачей является определение в нем тегов – участков текста, заключенных между угловыми скобками «<» (знак меньше) и «>» (знак больше). В свою очередь, теги состоят из имени (слова, следующего сразу за знаком «<») и атрибутов, которые тоже могут иметь значения.
Например, в программе анализатора часто встречается такой код:
- Пропустить символы-разделители «\040\t\r\n» (пробел, табуляция, возврат каретки и перевод строки) и записать новую позицию в переменную P1.
- Если символ в позиции P1 – цифра, то обнаружено число. Для его выделения нужно пропустить цифровые символы «0. 9» и записать новую позицию в переменную P2.
- Если символ в позиции P1 – буква, то обнаружен идентификатор. Для его выделения нужно пропустить алфавитно-цифровые символы «0..9A. Za. z» и записать новую позицию в переменную P2.
- Если символ в позиции P1 – открывающая кавычка, то обнаружено начало строки. Для нахождения позиции конца строки нужно пропустить все символы до тех пор, пока не встретится закрывающая кавычка. Позицию конца строки нужно записать в переменную P2, а значение переменной P1 увеличить на единицу, чтобы оно указывало на начало строки, а не на открывающую кавычку.
Такой подход к анализу текста очень экономичен в плане расхода памяти. Для хранения информации об элементах текста достаточно двух числовых переменных P1 и P2, в которые записываются позиции начала элемента и символа, следующего за его концом. Значение элемента хранится неявно в анализируемом тексте и при необходимости может быть легко получено из него как подстрока [P1:P2-1]. При этом легко вычисляется длина элемента L = P2 – P1, и она может быть оценена до обработки значения элемента. Например, можно сразу сообщить об ошибке, если длина элемента превышает допустимую.
Обобщая описанную схему, в процессе лексического анализа можно обнаружить регулярное выполнение двух действий (см. рис. 1):
- поиск в тексте позиции определенного символа, который служит признаком начала синтаксической конструкции или является символом-ограничителем;
- пропуск символов из заданного набора (символов-разделителей или алфавитно-цифровых символов для записи идентификаторов) до тех пор, пока не встретится «посторонний» символ.
Рисунок 1. Шаги лексического анализа тега HTML. Зеленая стрелка – переход к следующему символу, голубая стрелка – пропуск символов из набора, оранжевая – поиск символа из набора
Поэтому в основу разрабатываемого лексического анализатора были положены две взаимно дополняющие функции: SkipOver (…, набор_символов) и SkipTo (…, набор_символов). Первая служит для пропуска любых символов, не входящих в указанный набор, и возврата позиции символа, который в этот набор входит. Вторая функция выполняет поиск позиции символа, который совпадает с одним из символов указанного набора. Исходный текст на языке PHP этих функций приведен в файле iaparse r.php .
Особенностью интерпретируемых языков программирования, к каковым относится PHP, является то, что время работы участков кода сильно зависит от баланса между использованием в них встроенных функций языка и языковых конструкций. Поскольку встроенные функции являются скомпилированными блоками машинного кода, то они выполняются существенно быстрее, чем эквивалентные им конструкции, записанные операторами языка. Например, поиск символа C в строке S, записанный с помощью встроенной функции strpos ():
будет выполнен значительно быстрее, нежели реализованный средствами PHP:
Хотя на компилируемых языках оба варианта отработали бы примерно за одинаковое время. Так происходит потому, что конструкции языка PHP не выполняются процессором напрямую, а проходят через интерпретатор, который на каждой итерации цикла осуществляет вызов машинных микроподпрограмм для выполнения своих операторов. Затраты на организацию множественных вызовов могут привести к катастрофическому падению производительности.
Для повышения эффективности в реализациях часто вызываемых функций SkipOver () и SkipTo () включен «защитный код», имеющий вид:
Он обеспечивает определение длины обрабатываемой строки через вызов встроенной функции strlen (), только если ее значение не было передано через необязательный параметр $l. В противном случае сразу используется предоставленное значение.
Несмотря на то что исходные тексты функций SkipOver () и SkipTo () отличаются единственным символом (в первой содержится выражение с неравенством «!==», а во второй – с равенством «==»), что позволяет объединить их в одну функцию Skip () с дополнительным параметром, задающим специфику поведения, было решено это не делать для сохранения наглядности разрабатываемых с их использованием программ.
К сожалению, разработчики интерпретаторов не посчитали нужным включить в стандартную библиотеку функции для упрощения лексического анализа. И если в PHP5 появляется функция strpbrk (), которая подходит для решения первой задачи, то для пропуска разделителей по-прежнему придется написать ресурсозатратный код на PHP.
Еще один момент, на который следует обратить внимание для повышения эффективности программы, – это передача параметров в функцию. Если функция вызывается многократно для обработки большого объема текста, как например это происходит с функциями SkipOver () и SkipTo (), то передача в нее этого текста должна осуществляться по ссылке, а не по значению.
Для передачи параметра по ссылке в языке программирования PHP в заголовке объявления функции нужно предварить название параметра символом «&» (амперсанд). Если забыть это сделать, то при каждом вызове функции будет осуществляться копирование передаваемого значения (в нашем случае – всего обрабатываемого текста), что увеличит затраты и времени, и памяти.
Разбор HTML-документов
Функции, предназначенные для разбора текстов на языке HTML, собраны в файле iahtm l.php . Их ядром является функция iaFindTagOneOf ($p, &$s, $tags), которая осуществляет поиск в тексте $s начиная с позиции $p одного из тегов, заданных параметром $tags.
Если нужно найти какой-то конкретный тег, например «p» или «div», то искомое значение передается как строка. Если же требуется обнаружить один из нескольких тегов, например любой из набора «h1», «h2», «h3», «h4», «h5», «h6», то список тегов нужно передать как массив: array (‘h1’, ‘h2’, ‘h3’, ‘h4’, ‘h5’, ‘h6’). В представленной реализации функции регистр тегов имеет значение, как это регламентировано спецификацией языка XML, поэтому для поиска в «произвольном» HTML в список нужно включить и теги в верхнем регистре: «H1», «H2», «H3», «H4», «H5», «H6».
В результате своей работы функция iaFindTagOneOf () возвращает либо значение FALSE, означающее, что поиск завершился неудачей, либо ассоциативный массив такой структуры:
Для удобства практического использования результат работы функции iaFindTagOneOf () может напрямую передаваться ей же в качестве первого аргумента. В этом случае поиск очередного тега будет продолжен с позиции, следующей за найденным тегом.
Искомые теги задаются своими именами. После реализации функции iaFindTagOneOf () оказалось, что ее можно использовать для поиска как открывающего, так и закрывающего тега. В последнем случае достаточно перед именем тега поставить символ «/» (наклонную черту). Тогда код для поиска тегов, ограничивающих HTML-элемент «div», будет выглядеть как:
Остальные функции, содержащиеся в модуле, имеют вспомогательное назначение. Так, iaFindTagAny ($p, &$s) ищет в тексте $s начиная с позиции $p любой тег HTML. С ее помощью «центральная» функция iaFindTagOneOf () получает очередной тег, после чего проверяет его имя на соответствие списку, переданному в параметре $tags.
Результат работы функции $tag = iaFindTagOneOf () может быть использован в вызывающей программе напрямую, но во многих случаях синтаксические конструкции доступа к ассоциативному массиву выглядят громоздко. Поэтому в комплект включены функции обработки этого результата:
- iaFoundTagPos (&$tag) – возвращает номер позиции тега $tag в обрабатываемой строке;
- iaFoundTagAfterPos (&$tag) – возвращает номер позиции, следующей за тегом $tag;
- iaFoundTagAttr (&$tag, $attr) – позволяет получить значение атрибута $attr тега $tag (если атрибут отсутствует, то возвращается FALSE);
- iaFoundElementContent (&$s, &$tagb, &$tage) – возвращает содержимое элемента, заключенное между тегами $tagb и $tage.
Таким образом, функции из файла iahtm l.php помогают произвести синтаксический анализ HTML-кода.
Демонстрация извлечения информации из HTML-страницы
В качестве примера использования описанных в статье функций рассмотрим извлечение информации из новостной ленты главной страницы сайта журнала «Системный администратор» (см. рис. 2).
Рисунок 2. Так выглядит лента новостей сайта журнала «Системный администратор» в браузере
Прежде всего найдем в HTML-коде страницы по строке «Поздравляем с наступающим Новым годом» интересующий нас участок и попробуем выявить в нем какие-нибудь характерные особенности.
Рисунок 3. HTML-код начала ленты новостей на сайте журнала «Системный администратор». Подчеркнуты характерные участки, которые используются в качестве ориентиров при обработке текста
О кодировании текстов
При обработке текстов нельзя игнорировать кодировку, в которой они представлены. Актуальные в настоящее время кодировки можно разделить на два класса: многобайтовые (UTF-8, UTF-16, UTF-32), представляющие полное множество символов UNICODE, и однобайтовые (ASCII, КОИ-8, CP866, Windows-1251), в которых представлены подмножества из 256 выбранных символов.
В общем случае для обработки текстов, представленных в многобайтовых кодировках, нужно использовать специальные функции языка программирования, учитывающие их особенность. Очевидно, что даже длина строки в многобайтовой кодировке будет отличаться от значения, которое вернет «обычная» функция, подсчитывающая количество байтов.
В языке программирования PHP функции для обработки текстов в многобайтовых кодировках начинаются с префикса «mb_»: mb_strlen (), mb_strpos (), mb_strstr () и т.д. Они выполняются несколько медленнее своих однобайтовых аналогов, потому что для правильной работы им нужно выполнять фоновый анализ встречающихся символов. Впрочем, в интерпретируемых языках программирования этим замедлением можно смело пренебречь.
В подпрограммах, описанных в этой статье, используются обычные однобайтовые функции. Такое решение принято по той причине, что в подавляющем большинстве случаев структура анализируемых текстов (документов HTML и XML, новостных лент RSS, информационных хранилищ JSON) определяется фразами из символов, входящих в подмножество первых 127 символов кодовой таблицы ASCII. А завоевавшая широкое распространение кодировка UTF-8 использует в своей основе префиксное кодирование [2], благодаря которому между кодами первых 127 символов кодировок ASCII и UTF-8 установлено взаимно однозначное соответствие. Многобайтовые символы UNICODE в кодировке UTF-8 содержат в своей записи только байты со значениями от 127 до 255.
Описанные в статье подпрограммы можно смело использовать для обработки текстов в однобайтовых кодировках и кодировке UTF-8. Они будут корректно определять структурные элементы текста, записанные младшими 127 символами, не затрагивая его информационное наполнение, которое в свою очередь может быть произвольным.
Мы продемонстрировали извлечение информации из HTML-файла комбинированным способом, который включает:
- прямой поиск начала интересующего участка HTML-кода с помощью стандартной функции PHP strpos ();
- последующий сбор данных путем анализа структуры HTML-кода с помощью разработанных для этой цели функций лексического и синтаксического анализа текста.
Такой подход позволяет сочетать быструю локализацию области поиска благодаря однократному вызову встроенной функции и гибкость при выполнении анализа текста специально разработанными на языке PHP для этой цели средствами. В большинстве случаев он не имеет недостатков по сравнению с построением структурного дерева HTML-документа. А кроме того не требует установки сторонних библиотек и при необходимости может быть дополнен средствами работы с регулярными выражениями.
Задача извлечения информации из HTML-страницы, рассмотренная в этой статье, гораздо проще проекта разработки компилятора для какого-нибудь языка программирования. Но следование общим принципам построения анализатора позволило сделать программу обозримой и легко адаптируемой к возможным изменениям в дизайне анализируемого сайта. Разработанные вспомогательные функции можно применять для анализа текстов на других похожих языках – XML, RSS, JSON.
Включение в стандартную библиотеку интерпретируемых языков программирования функций SkipOver (текст, набор_символов [,начальная_позиция]) и SkipTo (текст, набор_символов [,начальная_позиция]) позволило бы существенно повысить эффективность реализаций на этих языках программ для обработки текстовой информации.
Если необходимые вам данные разбросаны по разным HTML-страницам для их извлечения применяется скрапинг. Вы создаете код для автоматического посещения определенного перечня страниц, получения конкретного контента с этих страниц и сохранения его в базе данных или в текстовом файле. [1]
Скажем, вы хотите скачать данные по температуре за прошедший год, но у вас не получается найти источник, который предоставил бы вам все сведения за нужный отрезок времени или по нужному городу. К счастью, сайт Weather Underground предоставляет исторические данные о погоде. И плохая новость: на одной странице сведения можно получить только за один день (рис. 1).

Рис. 1. Температура в Москве по данным Weather Underground; чтобы увеличить картинку, кликните на ней правой кнопкой мыши и выберите опцию Открыть картинку в новой вкладке
Проходим по меню More –> Historical Weather и выбираем определенную дату (рис. 2).

Рис. 2. Окно поиска архивных данных о погоде
Нажмите Submit, откроется другая страница, где вам будут представлены подробные данные о погоде в выбранный вами день (рис. 3).

Рис. 3. Подробные сведения о погоде в выбранный день
Допустим вас интересует максимальная температура. Вы могли бы посетить 365 страниц и собрать требуемые данные. Но процесс можно ускорить с помощью кода. Для этого обратитесь к языку программирования Python и к библиотеке под названием BeautifulSoup, созданной Леонардом Ричардсоном.
> python setup.py install
Создайте файл в текстовом редакторе (например, в блокноте) и сохраните его как get-weather-data.py. Теперь вы можете заняться написанием кода. Загрузите страницу, на которой представлены исторические сведения о погоде (как на рис. 3). URL страницы с информаций о погоде в Москве за 1 января 2015 выглядит так (чтобы разместить столь длинную строку мне пришлось разбить ее несколькими пробелами):
Если в этом адресе вы удалите все, что следует за .html, страница будет по-прежнему загружаться, так что избавьтесь от этих лишних символов:
В URL дата указана как /2015/1/1. Чтобы загрузить страницу со сведениями о 2 января 2015 г. без использования выпадающего меню, просто измените параметр даты так, чтобы URL выглядел следующим образом:
Теперь загрузите страницу с помощью Python, используя функцию urlopen, хранящуюся в модуле urllib.request библиотеки urllib. Для начала импортируйте эту функцию в программу:
from urllib.request import urlopen
Чтобы загрузить страницу с данными о погоде за 1 января, введите код:
page = urllib.urlopen( " www.wunderground.com/history/airport/UUEE/2015/1/2/DailyHistory.html " )
Таким образом вы загрузите весь HTML-файл, на который указывает URL в переменной страница. Следующим шагом будет извлечение интересующего вас значения максимальной температуры из этого HTML. Beautiful Soup сделает выполнение данной задачи намного проще. Вслед за urllib импортируйте Beautiful Soup:
from bs4 import BeautifulSoup
Используйте функцию BeautifuLSoup, чтобы прочитать страницу, и произвести ее анализ.
Эта строчка кода прочитывает HTML, который представляет по сути одну длинную строку, а затем сохраняет элементы страницы, такие как заголовок или изображения, в удобном для работы виде. Например, если вы хотите найти все изображения на странице, вы можете использовать код:
images = soup.findAll( ' img ' )
В результате вы получите перечень всех изображений на странице Weather Underground, отображаемых с помощью HTML-тега <img />. Вам нужно первое изображение на странице? Введите:
Хотите второе изображение? Измените ноль на единицу. Если вам нужно значение src в первом теге <img />, тогда используйте:
src = first_image[ ' src ' ]
Ладно, вас ведь не интересуют изображения. Вы просто хотите извлечь максимальную температуру в Москве 1 января 2015 года. Чтобы найти ее, нужно потрудиться чуть подольше, но метод применяется все тот же. Вам нужно выяснить, что вставить в findAll(), а потому просмотрите исходный HTML. Это легко сделать в веб-браузере. В Google Chrome, например, кликните на странице правой кнопкой мыши и выберите Просмотреть код. Появится окно с HTML-кодом (рис. 4).

Рис. 4. Исходный HTML-код страницы Weather Underground
Прокрутите вниз до того места, где показана максимальная температура, или воспользуйтесь функцией поиска в браузере. Строка замыкается тегом <span> с классом wx-value. Это и есть ваш ключ. Вы теперь можете найти все элементы на странице с классом wx-value.
Как и в предыдущем примере, это дает вам в руки перечень всех случаев употребления wx-value. Вас интересует второй из них, который вы найдете с помощью строчки:
Вуаля! Вы впервые в жизни извлекли нужное вам значение из HTML-кода веб-страницы. Следующий шаг — проанализировать все страницы за 2015 год и извлечь из них необходимые данные. Для этого вернитесь к первоначальному URL:
Помните, как вы вручную изменили адрес, чтобы получить сведения о той дате, которая вас интересовала? Приведенный выше код относится к 1 января 2015 года. Если вам нужна страница за 2 января 2015 года, просто измените ту часть URL, в которой указана дата, на соответствующую. Чтобы получить данные за все дни 2015 года, загрузите все месяцы (с 1-го по 12-й), а затем загрузите каждый день каждого месяца. Ниже представлен весь скрипт с комментариями. Сохраните его в вашем файле get-weather-data-full.py.
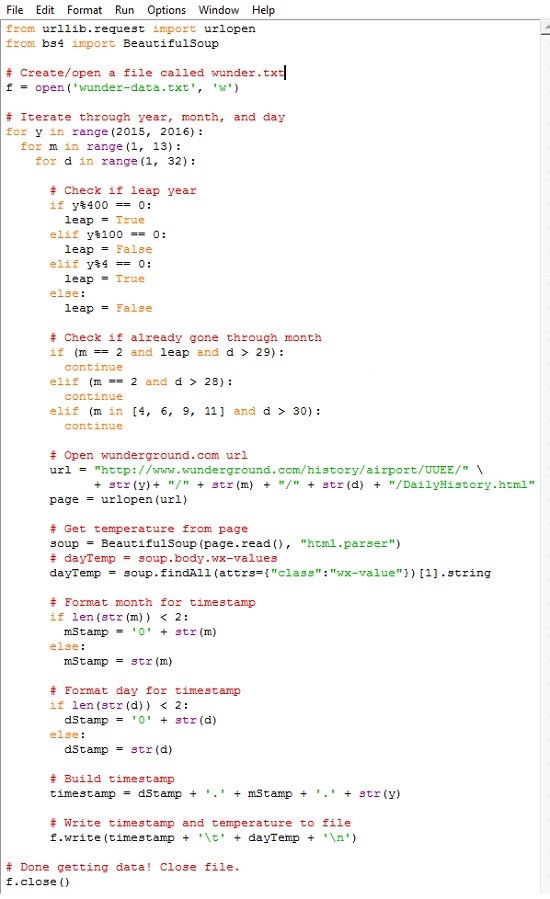
Вы наверняка узнали первые две строчки кода, с помощью которых вы импортировали необходимые библиотеки, — urllib и BeautifulSoup. Далее создается текстовый файл под названием wunder-data.txt с правами на запись, используя метод open(). Все данные, которые вы извлечете, будут сохраняться в этом текстовом файле, расположенном в той же папке, куда вы сохранили свой скрипт.
С помощью следующего блока, используя циклы for, компьютеру отдается команда просмотреть каждый год, месяц и день. Функция range() генерирует последовательность чисел, используемых для итераций цикла. Эта функция генерирует последовательность, начинающуюся с нуля и кончающуюся числом в скобках, не включая его. Поэтому, если вы укажите:
for y in range(2015):
Внешний цикл for проверяет, является ли год високосным. Число, обозначающее месяц, указывается в переменной m. Следующий цикл сообщает компьютеру, что надо посетить каждый день каждого месяца. Каждый отдельный день месяца указывается в переменной d.
Обратите внимание на то, что для повторения операции по дням используется range(1, 32). Это означает, что повтор будет производиться для каждого числа, начиная с 1 и по 31 (последнее значение не включается). Однако не в каждом месяце в году есть 31 день. В феврале их 28; в апреле, июне, сентябре и ноябре — по 30. Температурных показателей за 31 апреля нет, потому что такого дня не существует. Обратите внимание на то, о каком месяце идет речь, и действуйте сообразно этому. Если текущий месяц — февраль, и число больше 28, прервитесь и переходите к следующему месяцу.
Следующие строчки кода вы использовали для извлечения данных из одной конкретной страницы сайта Weather Underground. Отличие состоит в переменной месяца и дня в URL. Ее просто нужно менять для каждого дня, а не оставлять статичной — все прочее тут без изменений. Загрузите страницу, используя библиотеку urllib, произведите анализ контента с помощью Beautiful Soup, а затем извлеките максимальную температуру, с помощью второго появления класса wx-values.
Прогон займет некоторое время, так что наберитесь терпения. По сути, в процессе выполнения программы ваш компьютер загрузит по очереди 365 страниц – по одной на каждый день 2015 года. Когда выполнение скрипта завершится, у вас в рабочем каталоге появится файл под названием wunder-data.txt (рис. 5). Откройте его, и там вы найдете нужные вам данные в формате с разделителями табуляцией. В первой колонке вы увидите дату, во второй – температуру.

Рис. 5. Извлеченные данные в файле с разделителем табуляцией
Обратите также внимание, что, если вы будете запрашивать данные по будущему периоду (дата еще не наступила), то получите некорректный ответ. Запрос найдет второе вхождение тега с классом wx-value, но оно не будет соответствовать максимальной температуре выбранного дня (рис. 6).

Рис. 6. Для будущего периода второй тег класса wx-value не соответствует максимальной температуре выбранного дня
Любопытна история написания этой заметки. Мой друг несколько лет назад подарил мне книгу Нейтана Яу Искусство визуализации в бизнесе. Поскольку меня интересует обработка и представление информации, книга мне показалась любопытной, и я начал ее читать. Но… буквально с первых страниц автор уводит с проторенных дорожек. Критикуя Excel за его недостаточную мощь и гибкость, автор предлагает использовать программную обработку на основе языка Python. Тогда мне это показалось слишком сложным.
Но около месяца назад я вновь вернулся к книге Нейтана Яу. И теперь использование Python меня не отпугнуло. Я решил написать конспект книги, а, чтобы не перегружать его, специфические темы опубликовать отдельно. Первая из таких заметок перед вами. Надо сказать, что далась она непросто.
Для начала, код Нейтана Яу не запустился. Проблемы подстерегали практически на каждом шагу. Выяснилось, что код написан для Python 2, а последняя версия – это Python 3.5. Изучение Интернета подсказало, что язык был существенно переработан при переходе с версии 2 на 3. Мне показалось странным, потчевать читателей устаревшим кодом. Поэтому я установил последнюю из доступных на данный момент версий Python 3.5.1.
Чтобы попытаться самому переписать код, или хотя бы более грамотно задавать вопросы на форумах, я прочитал книгу Майк МакГрат. Программирование на Python для начинающих. Книга мне понравилась. Очень хорошо структурирована, сопровождается файлами с примерами. То, что надо! Она мне здорово помогла.
Следующая проблема была с запуском модуля BeautifulSoup. После импорта внутрь кода Python модуль не был виден. Я менял папки, запускал скрипт setup.py, ничего не помогало. Интенсивный поиск в Интернете натолкнул меня на только что вышедшую в издательстве ДМК Пресс книгу Райана Митчелла Скрапинг вебсайтов с помощью Python. Оцените, книга вышла 30 апреля 2016 г.! Здесь я почерпнул знания о библиотеке urllib, и о том, как установить модуль BeautifulSoup под Python 3. Критически важным было выполнить в командной строке
> python setup.py install
Эта команда конвертирует код модуля BeautifulSoup, адаптируя его к версии Python 3.
Далее оказалось, что с момента написания Нейтаном Яу своей книги на сайте Weather Underground произошли изменения в стилевом оформлении CSS. Поменялось имя тега, используемого для представления значения температуры: с nobr на wx-value.
И наконец, с переходом на версию Python 3, наверное, поменялся синтаксис извлечения значения из тега. У Нейтана Яу было:
Т.е., [ ].span.string следовало заменить на [ ].string. Я нигде не мог найти подсказки, что же следует изменить в первоначальном коде, чтобы извлечь не весь тег
а только его значение
Обращение на форум python.su не помогло. Я применил метод научного тыка, и после нескольких попыток получил то, что нужно.
Успехов вам в освоении языка Python!
[1] Заметка написана на основе материалов книги Нейтан Яу. Искусство визуализации в бизнесе. – М.: Манн, Иванов и Фербер, 2013. – С. 44–53.
Читайте также: