
К какому слою относится модуль управления памятью
Обновлено: 05.07.2024
SDRAM: Определение
Микросхемы SDRAM: Физическая организация и принцип работы
Важно заметить, что с динамической матрицей памяти связан особый буфер статической природы, именуемый «усилителем уровня» (SenseAmp), размер которого равен размеру одной строки, необходимый для осуществления операций чтения и регенерации данных, содержащихся в ячейках памяти. Поскольку последние физически представляют собой конденсаторы, разряжающиеся при совершении каждой операции чтения, усилитель уровня обязан восстановить данные, хранящиеся в ячейке, после завершения цикла доступа (более подробно участие усилителя уровня в цикле чтения данных из микросхемы памяти рассмотрено ниже).
Кроме того, поскольку конденсаторы со временем теряют свой заряд (независимо от операций чтения), для предотвращения потери данных необходимо периодически обновлять содержимое ячеек. В современных типах памяти, которые поддерживают режимы автоматической регенерации (в «пробужденном» состоянии) и саморегенерации (в «спящем» состоянии), обычно это является задачей внутреннего контроллера регенерации, расположенного непосредственно в микросхеме памяти.
Схема обращения к ячейке памяти в самом общем случае может быть представлена следующим образом:
В современных микросхемах SDRAM схема обращения к ячейкам памяти выглядит аналогично. Далее, в связи с обсуждением задержек при доступе в память (таймингов памяти), мы рассмотрим ее более подробно.
Микросхемы SDRAM: Логическая организация
Модули SDRAM: Организация
Модули памяти: Микросхема SPD
Тайминги памяти
Схема доступа к данным микросхемы SDRAM
1. Активизация строки
Повторная активизация какой-либо другой строки того же банка не может быть осуществлена до тех пор, пока предыдущая строка этого банка остается открытой (т.к. усилитель уровня, содержащий буфер данных размером в одну строку банка и описанный в разделе «Микросхемы SDRAM: Физическая организация и принцип работы», является общим для всех строк данного банка микросхемы SDRAM). Таким образом, минимальный промежуток времени между активизацией двух различных строк одного и того же банка определяется минимальным временем цикла строки (Row Cycle Time, tRC).
2. Чтение/запись данных
Возвращаясь к чтению данных, заметим, что существует две разновидности команды чтения. Первая из них является «обычным» чтением (READ), вторая называется «чтением с автоматической подзарядкой» (Read with Auto-Precharge, «RD+AP»). Последняя отличается тем, что после завершения пакетной передачи данных по шине данных микросхемы автоматически будет подана команда подзарядки строки (PRECHARGE), тогда как в первом случае выбранная строка микросхемы памяти останется «открытой» для осуществления дальнейших операций.
3. Подзарядка строки
Соотношения между таймингами
В заключение этой части, посвященной задержкам при доступе к данным, рассмотрим основные соотношения между важнейшими параметрами таймингов на примере более простых операций чтения данных. Как мы рассмотрели выше, в самом простейшем и самом общем случае — для пакетного считывания заданного количества данных (2, 4 или 8 элементов) необходимо осуществить следующие операции:
1) активизировать строку в банке памяти с помощью команды ACTIVATE;
2) подать команду чтения данных READ;
3) считать данные, поступающие на внешнюю шину данных микросхемы;
4) закрыть строку с помощью команды подзарядки строки PRECHARGE (как вариант, это делается автоматически, если на втором шаге использовать команду «RD+AP»).
Наконец, промежуток времени между четвертой операцией и последующим повтором первой операции цикла составляет «время подзарядки строки» (tRP).
В то же время, минимальному времени активности строки (от подачи команды ACTIVATE до подачи команды PRECHARGE, tRAS), по его определению, как раз отвечает промежуток времени между началом первой и началом четвертой операции. Отсюда вытекает первое важное соотношение между таймингами памяти:
Под архитектурой операционной системы понимают структурную и функциональную организацию ОС на основе некоторой совокупности программных модулей. В состав ОС входят исполняемые и объектные модули стандартных для данной ОС форматов, программные модули специального формата (например, загрузчик ОС, драйверы ввода-вывода ), конфигурационные файлы, файлы документации, модули справочной системы и т.д.
На архитектуру ранних операционных систем обращалось мало внимания: во-первых, ни у кого не было опыта в разработке больших программных систем, а во-вторых, проблема взаимозависимости и взаимодействия модулей недооценивалась. В подобных монолитных ОС почти все процедуры могли вызывать одна другую. Такое отсутствие структуры было несовместимо с расширением операционных систем. Первая версия ОС OS/360 была создана коллективом из 5000 человек за 5 лет и содержала более 1 млн строк кода. Разработанная несколько позже операционная система Mastics содержала к 1975 году уже 20 млн строк [17]. Стало ясно, что разработка таких систем должна вестись на основе модульного программирования.
Большинство современных ОС представляют собой хорошо структурированные модульные системы, способные к развитию, расширению и переносу на новые платформы. Какой-либо единой унифицированной архитектуры ОС не существует, но известны универсальные подходы к структурированию ОС. Принципиально важными универсальными подходами к разработке архитектуры ОС являются [5, 10, 13, 17]:
- модульная организация;
- функциональная избыточность;
- функциональная избирательность;
- параметрическая универсальность;
- концепция многоуровневой иерархической вычислительной системы, по которой ОС представляется многослойной структурой;
- разделение модулей на две группы по функциям: ядро – модули, выполняющие основные функции ОС, и модули, выполняющие вспомогательные функции ОС;
- разделение модулей ОС на две группы по размещению в памяти вычислительной системы: резидентные, постоянно находящиеся в оперативной памяти, и транзитные, загружаемые в оперативную память только на время выполнения своих функций;
- реализация двух режимов работы вычислительной системы: привилегированного режима (режима ядра – Kernel mode ), или режима супервизора ( supervisor mode ), и пользовательского режима ( user mode ), или режима задачи (task mode);
- ограничение функций ядра (а следовательно, и количества модулей ядра) до минимального количества необходимых самых важных функций.
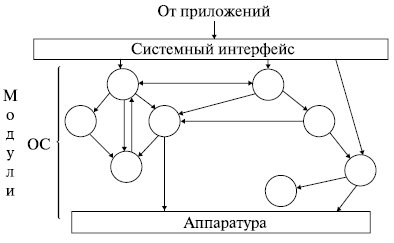
Первые ОС разрабатывались как монолитные системы без четко выраженной структуры (рис. 1.2).
Для построения монолитной системы необходимо скомпилировать все отдельные процедуры, а затем связать их вместе в единый объектный файл с помощью компоновщика (примерами могут служить ранние версии ядра UNIX или Novell NetWare). Каждая процедура видит любую другую процедуру (в отличие от структуры, содержащей модули, в которой большая часть информации является локальной для модуля, и процедуры модуля можно вызвать только через специально определенные точки входа).
Однако даже такие монолитные системы могут быть немного структурированными. При обращении к системным вызовам, поддерживаемым ОС, параметры помещаются в строго определенные места, такие как регистры или стек , а затем выполняется специальная команда прерывания, известная как вызов ядра или вызов супервизора. Эта команда переключает машину из режима пользователя в режим ядра, называемый также режимом супервизора, и передает управление ОС. Затем ОС проверяет параметры вызова, для того чтобы определить, какой системный вызов должен быть выполнен. После этого ОС индексирует таблицу, содержащую ссылки на процедуры, и вызывает соответствующую процедуру.
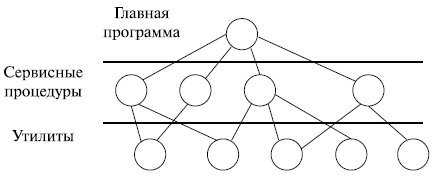
Такая организация ОС предполагает следующую структуру [13]:
- главная программа, которая вызывает требуемые сервисные процедуры;
- набор сервисных процедур, реализующих системные вызовы;
- набор утилит, обслуживающих сервисные процедуры.
В этой модели для каждого системного вызова имеется одна сервисная процедура. Утилиты выполняют функции, которые нужны нескольким сервисным процедурам. Это деление процедур на три слоя показано на рис. 1.3.
Классической считается архитектура ОС, основанная на концепции иерархической многоуровневой машины, привилегированном ядре и пользовательском режиме работы транзитных модулей. Модули ядра выполняют базовые функции ОС: управление процессами , памятью, устройствами ввода-вывода и т.п. Ядро составляет сердцевину ОС, без которой она является полностью неработоспособной и не может выполнить ни одну из своих функций. В ядре решаются внутрисистемные задачи организации вычислительного процесса, недоступные для приложения.
Особый класс функций ядра служит для поддержки приложений, создавая для них так называемую прикладную программную среду. Приложения могут обращаться к ядру с запросами – системными вызовами – для выполнения тех или иных действий, например, открытие и чтение файла , получение системного времени, вывода информации на дисплей и т.д. Функции ядра, которые могут вызываться приложениями, образуют интерфейс прикладного программирования – API ( Application Programming Interface ).
Для обеспечения высокой скорости работы ОС модули ядра ( по крайней мере, большая их часть) являются резидентными и работают в привилегированном режиме ( Kernel mode ). Этот режим, во-первых, должен обезопасить работу самой ОС от вмешательства приложений, и, во-вторых, должен обеспечить возможность работы модулей ядра с полным набором машинных инструкций, позволяющих собственно ядру выполнять управление ресурсами компьютера, в частности, переключение процессора с задачи на задачу, управлением устройствами ввода-вывода, распределением и защитой памяти и др.
Остальные модули ОС выполняют не столь важные функции, как ядро , и являются транзитными. Например, это могут быть программы архивирования данных, дефрагментации диска , сжатия дисков, очистки дисков и т.п.
Вспомогательные модули обычно подразделяются на группы:
- утилиты – программы, выполняющие отдельные задачи управления и сопровождения вычислительной системы;
- системные обрабатывающие программы – текстовые и графические редакторы (Paint, Imaging в Windows 2000), компиляторы и др.;
- программы предоставления пользователю дополнительных услуг (специальный вариант пользовательского интерфейса, калькулятор, игры, средства мультимедиа Windows 2000);
- библиотеки процедур различного назначения, упрощения разработки приложений, например, библиотека функций ввода-вывода, библиотека математических функций и т.п.
Эти модули ОС оформляются как обычные приложения, обращаются к функциям ядра посредством системных вызовов и выполняются в пользовательском режиме ( user mode ). В этом режиме запрещается выполнение некоторых команд, которые связаны с функциями ядра ОС ( управление ресурсами , распределение и защита памяти и т.п.).
В концепции многоуровневой (многослойной) иерархической машины структура ОС также представляется рядом слоев. При такой организации каждый слой обслуживает вышележащий слой, выполняя для него некоторый набор функций, которые образуют межслойный интерфейс . На основе этих функций следующий верхний по иерархии слой строит свои функции – более сложные и более мощные и т.д. Такая организация системы существенно упрощает ее разработку, т.к. позволяет сначала "сверху вниз" определить функции слоев и межслойные интерфейсы, а при детальной реализации, двигаясь "снизу вверх", – наращивать мощность функции слоев. Кроме того, модули каждого слоя можно изменять без необходимости изменений в других слоях (но не меняя межслойных интерфейсов!).
Многослойная структура ядра ОС может быть представлена, например, вариантом, показанным на рис. 1.4.
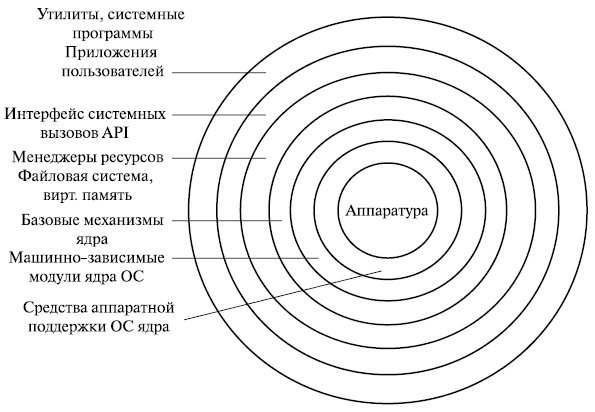
В данной схеме выделены следующие слои.
- Средства аппаратной поддержки ОС. Значительная часть функций ОС может выполняться аппаратными средствами [10]. Чисто программные ОС сейчас не существуют. Как правило, в современных системах всегда есть средства аппаратной поддержки ОС, которые прямо участвуют в организации вычислительных процессов. К ним относятся: система прерываний, средства поддержки привилегированного режима, средства поддержки виртуальной памяти, системный таймер , средства переключения контекстов процессов (информация о состоянии процесса в момент его приостановки), средства защиты памяти и др.
- Машинно-зависимые модули ОС. Этот слой образует модули, в которых отражается специфика аппаратной платформы компьютера. Назначение этого слоя – "экранирование" вышележащих слоев ОС от особенностей аппаратуры (например, Windows 2000 – это слой HAL (Hardware Abstraction Layer ), уровень аппаратных абстракций).
- Базовые механизмы ядра. Этот слой модулей выполняет наиболее примитивные операции ядра: программное переключение контекстов процессов , диспетчерскую прерываний, перемещение страниц между основной памятью и диском и т.п. Модули этого слоя не принимают решений о распределении ресурсов, а только обрабатывают решения, принятые модулями вышележащих уровней. Поэтому их часто называют исполнительными механизмами для модулей верхних слоев ОС.
- Менеджеры ресурсов. Модули этого слоя выполняют стратегические задачи по управлению ресурсами вычислительной системы. Это менеджеры (диспетчеры) процессов ввода-вывода, оперативной памяти и файловой системы. Каждый менеджер ведет учет свободных и используемых ресурсов и планирует их распределение в соответствии запросами приложений.
- Интерфейс системных вызовов. Это верхний слой ядра ОС, взаимодействующий с приложениями и системными утилитами , он образует прикладной программный интерфейс ОС. Функции API, обслуживающие системные вызовы, предоставляют доступ к ресурсам системы в удобной компактной форме, без указания деталей их физического расположения.
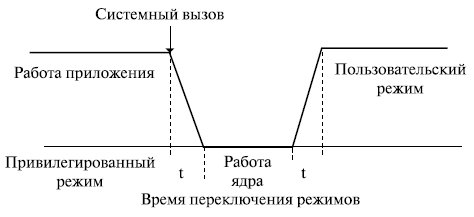
Повышение устойчивости ОС обеспечивается переходом ядра в привилегированный режим. При этом происходит некоторое замедление выполнения системных вызовов. Системный вызов привилегированного ядра инициирует переключение процессора из пользовательского режима в привилегированный, а при возврате к приложению – обратное переключение. За счет этого возникает дополнительная задержка в обработке системного вызова (рис. 1.5). Однако такое решение стало классическим и используется во многих ОС ( UNIX , VAX , VMS , IBM OS/390, OS/2 и др.).
Многослойная классическая многоуровневая архитектура ОС не лишена своих проблем. Дело в том, что значительные изменения одного из уровней могут иметь трудно предвидимое влияние на смежные уровни. Кроме того, многочисленные взаимодействия между соседними уровнями усложняют обеспечение безопасности. Поэтому, как альтернатива классическому варианту архитектуры ОС, часто используется микроядерная архитектура ОС.
Суть этой архитектуры состоит в следующем. В привилегированном режиме остается работать только очень небольшая часть ОС, называемая микроядром. Микроядро защищено от остальных частей ОС и приложений. В его состав входят машинно-зависимые модули, а также модули, выполняющие базовые механизмы обычного ядра. Все остальные более высокоуровневые функции ядра оформляются как модули, работающие в пользовательском режиме. Так, менеджеры ресурсов , являющиеся неотъемлемой частью обычного ядра, становятся "периферийными" модулями, работающими в пользовательском режиме. Таким образом, в архитектуре с микроядром традиционное расположение уровней по вертикали заменяется горизонтальным. Это можно представить, как показано на рис. 1.6.

Схематично механизм обращений к функциям ОС, оформленным в виде серверов, выглядит, как показано на рис. 1.7.
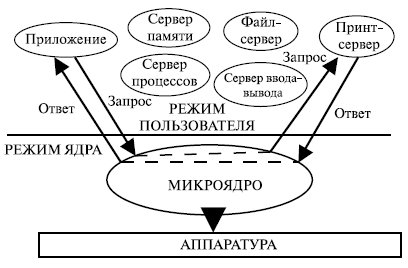
Схема смены режимов при выполнении системного вызова в ОС с микроядерной архитектурой выглядит, как показано на рис. 1.8. Из рисунка ясно, что выполнение системного вызова сопровождается четырьмя переключениями режимов (4 t), в то время как в классической архитектуре – двумя. Следовательно, производительность ОС с микроядерной архитектурой при прочих равных условиях будет ниже, чем у ОС с классическим ядром.
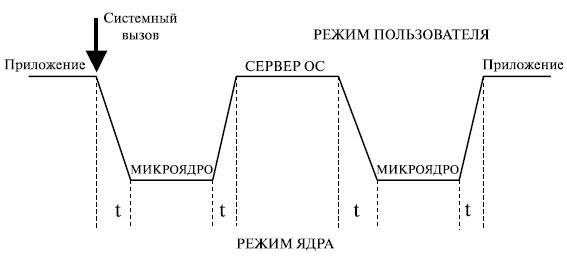
Рис. 1.8. Обработка системного вызова в микроядерной архитектуре
В то же время признаны следующие достоинства микроядерной архитектуры [17]:
- единообразные интерфейсы;
- простота расширяемости;
- высокая гибкость;
- возможность переносимости;
- высокая надежность;
- поддержка распределенных систем;
- поддержка объектно-ориентированных ОС.
По многим источникам вопрос масштабов потери производительности в микроядерных ОС является спорным. Многое зависит от размеров и функциональных возможностей микроядра. Избирательное увеличение функциональности микроядра приводит к снижению количества переключений между режимами системы, а также переключений адресных пространств процессов.
Может быть, это покажется парадоксальным, но есть и такой подход к микроядерной ОС, как уменьшение микроядра.
Для возможности представления о размерах микроядер операционных систем в ряде источников [17] приводятся такие данные:
Предыдущая статья цикла " Микроконтроллеры для начитающих. Часть 4. Очень кратко о микропрограммах " была факультативной. Однако, теперь мы еще на шаг приблизимся к практическому использованию микроконтроллеров. Пусть и упрощенно, схематически, но мы теперь представляем, как устроен процессор микроконтроллера. Пришло время подключать его к остальным узлам управляющей микроЭВМ микроконтроллера.
При слове архитектура большинство людей вспоминает о дворцах и зданиях, строительстве, возникает ассоциация со словом зодчий. Это правильно, но термин архитектура применим не только к строительству. Фактически, архитектура обозначает основные принципы использованные при проектировании и создании чего-либо.
Применительно к ЭВМ, под архитектурой обычно называют совокупность основных принципов, идей, подходов, методов, которые использовались при ее проектировании. Чаще всего входит в понятие архитектура ЭВМ входят:
- Организация памяти. Это количество различных типов памяти, их организация, способы подключения к процессору, особенности работы памяти.
- Система команд. Обратите внимание, я не сказал набор команд, я сказал система команд. В наборе команд ЭВМ(точнее, процессора) некоторые команды могут отсутствовать, могут включаться дополнительные команды, но подход к формированию системы команд остается неизменным. Набор команд это подмножество системы команд. Сюда входит адресность команд (количество операндов), режимы адресации операндов, тонкости выполнения (количество циклов, возможно, переменное), типы выполняемых операций, возможность расширения.
- Подсистема ввода-вывода. Способы подключения и адресации внешних (периферийных). Сюда же относится и наличие (и организация) канала прямого доступа к памяти ЭВМ.
- Возможность построения многопроцессорных комплексов. Одновременная работа нескольких процессоров в составе ЭВМ далеко не так проста, как может показаться. Причем и с точки зрения программиста.
- Механические параметры. Да, как ни странным это кажется. Наверное все знают платы расширения устанавливаемые в настольные ПК или в гнезда PCMCIA. Были и определенные требования к размерам ТЭЗ (типовой элемент замены), так назывались платы устанавливаемые в стойки больших ЭВМ (ЕС, СМ). Механические параметры далеко не всегда входят в понятие архитектуры, но иногда такое встречается.
Подробно архитектуру рассматривать мы не будем, для наших целей в этом нет смысла. Но некоторые аспекты для нас очень важны. И начнем мы с архитектуры памяти, точнее, с того, как память подключается к процессору (или наоборот).
"Чистые архитектуры" идеального мира
Наиболее известны две архитектуры подключения памяти к процессору. Первая, знакомая всем по IBM PC совместимым ЭВМ (точнее, микропроцессорам 80x86), архитектура фон Неймана . Вторая, менее известная, но более важная для нас, как станет видно в дальнейшем, Гарвардская архитектура .
Наиболее известные архитектуры ЭВМ с точки зрения организации памяти. Наиболее известные архитектуры ЭВМ с точки зрения организации памяти.Как видно, основное различие здесь в использовании памяти.
Архитектура фон Неймана
Хранит и программу, и данные, в единой памяти. Это выглядит привлекательно, так как позволяет эффективно использовать память небольшого объема. У нас небольшая программа, которая обрабатывает большие объемы данных? Нет никаких проблем, главное, что бы суммарный размер программы и данных мог поместиться в память. Большая программа требующая мало данных? Тоже все просто.
Кроме того, мы можем заполнить область памяти данными и потом передать ей управление. Или использовать коды команд как данные, возможно, изменяя их.
Архитектура фон Неймана вполне естественна для универсальных ЭВМ, ведь в этом случае неизвестно, что именно потребуется программе и какое будет соотношение объема кода программы и данных. Мы можем легко загрузить новую программу и данные в память и начать выполнение.
Однако, и минусов хватает. Самый большой плюс, лежащий в основе архитектуры, является и самым большим минусом. Представьте, что по какой то причине программа записала часть данных в область команд. Это приведет к неработоспособности программы, если управление будет передано этой измененной области. Или к остановке ЭВМ (когда то давно это называлось АВОСТ - аварийный останов).
Второй, менее очевидный минус, невозможность одновременного считывания очередной команды и операнда, или считывания команды и записи результата. Доступ к памяти может быть только последовательным.
Гарвардская архитектура
Используется разная память для программ и данных. Здесь у нас нет опасности исказить команды программы ошибкой с записью данных. И мы можем считывать очередную команду и записывать результат или считывать операнд одновременно, так как у нас разные блоки памяти. Минусы исчезли? Не совсем.
Теперь мы не можем передать управление области данных или использовать команды как данные. То есть, мы не можем изменять саму программу. Но это иногда все таки требуется. Теперь мы должны по отдельности загружать в области памяти коды команд и данные перед началом выполнения программы. Для универсальных ЭВМ эта архитектура менее удобна, чем архитектура фон Неймана. Зато для микроконтроллеров она подходит хорошо. Ведь программа в микроконтроллер обычно загружается если не однократно, то надолго и изменять ее не требуется. А отдельная область данных позволяет повысить надежность работы и уменьшить объем ОЗУ (оперативная память зачастую дороже). Теперь стало немного понятнее, почему я сказал, что Гарвардская архитектура для более важна, мы же говорим как раз о микроконтроллерах.
При этом довольно неприятным минусом, пусть и не критичным, является снижение гибкости в использовании памяти. Представьте, что нам не хватает, совсем чуть чуть, памяти данных, но есть свободная память команд. Мы никак не можем решить проблему, так как память программ под хранение данных использовать нельзя. И наоборот.
Суровый реальный мир и компромиссы
Реальные ЭВМ не используют в чистом виде ни одну из описанных выше архитектур. Хотя существовали и ЭВМ полностью им соответствующие. Архитектура реальных ЭВМ это некий компромисс. Но прежде чем двигаться дальше нам нужно кратко остановиться на понятии адресного пространства.
Адресное пространство
Под адресным пространством мы будем понимать логически единую совокупность адресуемых ячеек памяти . Звучит туманно? Не волнуйтесь, сейчас все станет понятно. Давайте начнем разбираться с более знакомой всем универсальной ЭВМ (в виде ПК, например).
Из каких областей памяти обычно состоит программа? Во первых, собственно код (команды) программы. Во вторых, область данных. Причем можно выделить область инициализированных данных, которые получают определенные значения перед началом выполнения программы, и не инициализированных данных, значения которых не определены до момента явного присвоения. В третьих, область стека, где хранятся адреса возвратов из подпрограмм и временные данные. В четвертых, динамически выделяемая область памяти.
Совокупность этих областей памяти программы, или задачи, называется адресным пространством задачи. Выглядит это, примерно, так
Пример упрощенного представления об адресном пространстве программы. Иллюстрация моя Пример упрощенного представления об адресном пространстве программы. Иллюстрация мояДля процессоров 80х86 области памяти обычно называют сегментами. В рамках своего адресного пространства программа может как угодно распоряжаться памятью. Но выход за пределы адресного пространства запрещен (обычно, операционной системой). Видно, что адресное пространство задачи занимает часть, в общем случае, все имеющейся памяти ЭВМ.
Совокупность сегментов, показанных на иллюстрации выше, логически единая , так все эти области памяти относятся к одной и той же программе. Причем не требуется, в общем случае, такого смежного размещения областей памяти программы в физической памяти ЭВМ. Может быть, например, такое расположение
Пример отображения адресного пространства задачи на физическую память ЭВМ. Серым цветом отмечены не используемые области памяти. Иллюстрация моя Пример отображения адресного пространства задачи на физическую память ЭВМ. Серым цветом отмечены не используемые области памяти. Иллюстрация мояТакое отображение выполняется аппаратно специальными блоками управления памятью, которые могут входить как в состав процессора, так и в состав памяти. При этом адреса памяти используемые в программе называют логическими, а адреса физической памяти ЭВМ физическими. Я не буду углубляться в тему преобразования адресов и управления памятью, это очень обширная и интересная тема, но нам достаточно такого упрощенного представления.
Команды и данные не обязательно занимают все доступное адресное пространство программы. Если реальная потребность программы меньше, чем ей выделено памяти, то часть адресов остается неиспользованной. Доступное адресное пространство задачи может быть меньше, чем ее потребности в памяти. В этом случае приходится использовать методы организации виртуальной памяти, если это возможно. Виртуальную память я так же не буду рассматривать.
Адресные пространства могут полностью изолированными, могут частично перекрываться, могут полностью совпадать, одно из пространств может быть подмножеством другого. С точки зрения математики можно рассматривать адресные пространства как некий вид множеств (множества ячеек памяти) с почти всеми применимыми к множествам операциями.
В рамках приведенного ранее примера с адресным пространством задачи можно показать пример частичного перекрытия
Пример перекрывающихся адресных пространств. Иллюстрация моя Пример перекрывающихся адресных пространств. Иллюстрация мояНо какое это отношение имеет к микроконтроллерам? Самое прямое! И сейчас это станет видно.
Адресные пространства ЭВМ
Да, именно так. Микроконтроллер включает в себя управляющую ЭВМ, как мы уже видели ранее. Какие области памяти могут быть в ЭВМ? Вспомним наши "чистые архитектуры". Область команд программы и область данных . Но это не все, есть еще область стека , которая может оказаться не такой простой, и область ввода-вывода .
Почему ввод-вывод относится к памяти? Все просто. Мы должны как то адресовать устройства ввода-вывода, управлять ими, передавать им данные и получать ответы. Внешние устройства обычно представлены набором управляющих регистров, каждый из которых имеет определенный адрес. Вероятно, некоторым из вас знакомы команды IN и OUT , которые иногда используются для доступа к таким регистрам. Адреса в командах IN и OUT как раз и относятся к области ввода-вывода.
Еще я назову область специальных регистров процессора , о которой вспоминают не часто. Специальные регистры процессора могут иметь свои адреса, а могут и не иметь.
Таким образом, у нас есть пять областей памяти, каждая из которых может иметь собственные адреса, свой размер, и является логически единой(по смыслу). Другими словами, у нас есть пять адресных пространств.
В общем случае мы не можем сказать, что именно хранится в ячейке с некоторым адресом, если не указано, к какому адресному пространству она относится. Например, ячейка с адресом 10 может хранить команду, если она в адресном пространстве команд (программ), или являться, например, регистром управления внешнего устройства, если она в адресном пространстве ввода-вывода, или быть просто некоторой переменной, если она в адресном пространстве данных.
Если еще раз вспомнить "чистые архитектуры", то станет видно, что в архитектуре фон Неймана адресные пространства программ и данных полностью совпадают. А в Гарвардской архитектуре они полностью изолированы.
А вот со стеком все немного интереснее. Стек хранит адреса возвратов и временные данные. С архитектурой фон Неймана все понятно, там адресные пространства совпадают. А как быть с Гарвардской? Мы не можем поместить стек в память программ, так он может содержать и данные. А в микроконтроллерах память программ еще и обычно представлена ПЗУ. Мы не можем поместить стек в память данных, так это позволит изменять адреса возвратов, которые относятся к памяти программ.
Мы можем решить проблемы поместив стек в специальную, изолированную, область памяти. Или сделать два различных стека, один для адресов возвратов, второй для временных данных. Теперь понятно, почему я выделил стек как отдельную область памяти, отдельное адресное пространство?
Но вернемся к нашей теме. Даже в Гарвардской архитектуре иногда требуется доступ к памяти программ, как к данным. Это можно сделать несколькими способами, я кратко расскажу о двух.
Пример организации доступа к памяти программ как к внешнему устройству. Иллюстрация моя Пример организации доступа к памяти программ как к внешнему устройству. Иллюстрация мояПроще всего добавить в ЭВМ (или процессор) специальный блок, через который и будет осуществляться доступ к памяти программ, как к данным. С большой долей вероятности, этот блок позволит достаточно легко читать память программ, а вот запись будет или сложнее, или не будет доступна совсем. С точки зрения чистоты архитектуры это решение ничего не нарушает, адресные пространства по прежнему изолированы, а дополнительный блок является обычным внешним устройством. При этом доступ к памяти программ будет медленнее, чем к памяти данных. И потребует больших усилий при программировании.
А вот второй способ гораздо хитрее и, на первый взгляд, нарушает все различия между архитектурами. Мы можем построить виртуальное адресное пространство, которое и будет использовать процессор, и которое будет являться объединением адресных пространств данных и программ. Вот так
Пример объединения адресных пространств программ и данных в единое виртуальное адресное пространство. Иллюстрация моя Пример объединения адресных пространств программ и данных в единое виртуальное адресное пространство. Иллюстрация мояОбратите внимание, здесь нет принципиальных схемотехнических отличий от первого варианта, где мы работали с памятью программ как с внешним устройством. У нас лишь добавился дешифратор, который маскирует особенности памяти программ с точки зрения программиста. Доступ от этого не становится быстрее, но вот использовать его в программе проще. Самое виртуальное адресное пространство теперь выглядит примерно так
Пример единого виртуального адресного пространства программ и данных. Иллюстрация моя Пример единого виртуального адресного пространства программ и данных. Иллюстрация мояКто то может сказать, а чем это вообще отличается от архитектуры фон Неймана? А действительно, чем? Особенно с учетом того, что я сказал, что адресное пространство не обязательно должно отображаться на непрерывные области физической памяти.
Все просто, на самом деле. В архитектуре фон Неймана у нас адресные пространства программ и данных полностью совпадают. Фактически, там можно говорить о едином адресном пространстве программ/данных. В данном же случае, у нас адресные пространства программ и данных по прежнему изолированны, а виртуальное пространство строится как их объединение, но без нарушения изоляции.
Таким образом, для Гарвардской архитектуры мы можем строить виртуальные адресные пространства по разному комбинируя отдельные адресные пространства не нарушая их изолированности. А можно и включать одно пространство в другое, без изоляции. Например, мы можем включить адресное пространство регистров процессора в адресное пространство данных. Так сделано, например, в микроконтроллерах PIC Microchip и AVR Atmel. При этом туда же входит и адресное пространство ввода-вывода (для Atmel это не совсем так, но разница нам сейчас не принципиальна). Подробнее обо всем этом поговорим в следующих статьях.
Остается кратко упомянуть, как можно обеспечить изоляцию адресных пространств программ и данных для архитектуры фон Неймана. Тут тоже используются отдельные блоки управления памятью. Поскольку эта темя далеко от микроконтроллеров особенно углубляться в нее не буду. Скажу лишь, что обычно используется запрет передачи управления на области памяти, которые должны считаться памятью данных. При этом можно и читать, и записывать эти области, а вот передавать управление туда нельзя. И, разумеется, никто не отменял включения защиты от записи в определенные области памяти.
Архитектура и адресные пространства микроконтроллеров
Ну вот мы и добрались до микроконтроллеров. Путь был длинным и не простым, зато сейчас будет гораздо легче.
При этом доступ к памяти программ как к данным имеют далеко не все микроконтроллеры. В некоторых случаях такой доступ организован как к внешнему устройству, в некоторых моделях через виртуальное адресное пространство. При этом, через виртуальное адресное пространство не всегда можно производить запись в память программ, даже используя специальные методы доступа.
В большинстве микроконтроллеров адресное пространство регистров процессора объединено (включено) в адресное пространство данных. Так же, во многих контроллерах с отдельным адресным пространством ввода-вывода оно частично, или полностью, может включаться в пространство данных. Более подробно я это буду рассматривать когда доберемся до организации памяти (не архитектуры).
Некоторые микроконтроллеры позволяют организовывать виртуальное адресное пространство. Как это выглядит для микроконтроллеров PIC Microchip можно посмотреть в статье, ссылку на которую я давал выше. А вот для STM8 я приведу упрощенный вид виртуального адресного пространства
Это самая важная функция операционной системы, которая управляет основной памятью. Это помогает процессам перемещаться вперед и назад между основной памятью и исполнительным диском. Это помогает ОС отслеживать каждую область памяти, независимо от того, выделена она для какого-либо процесса или остается свободной.
Из этого руководства по операционной системе вы узнаете:
Зачем использовать управление памятью?
Вот причины использования управления памятью:
- Это позволяет вам проверить, сколько памяти должно быть выделено процессам, которые решают, какой процессор должен получить память в какое время.
- Отслеживает всякий раз, когда инвентарь становится свободным или нераспределенным. По нему будет обновляться статус.
- Он выделяет пространство для подпрограмм приложения.
- Также убедитесь, что эти приложения не мешают друг другу.
- Помогает защитить разные процессы друг от друга
- Он помещает программы в память, чтобы память использовалась в полной мере.
Методы управления памятью
Вот некоторые наиболее важные методы управления памятью:
Одно смежное распределение
Это самый простой метод управления памятью. В этом методе все типы памяти компьютера, за исключением небольшой части, зарезервированной для ОС, доступны для одного приложения. Например, операционная система MS-DOS выделяет память таким образом. Встроенная система также работает в одном приложении.
Разделенное Распределение
Он делит первичную память на различные разделы памяти, которые в основном являются смежными областями памяти. Каждый раздел хранит всю информацию для конкретной задачи или работы. Этот метод состоит из выделения раздела для задания при его запуске и нераспределения при его завершении.
Управление постраничной памятью
Этот метод делит основную память компьютера на блоки фиксированного размера, известные как фреймы страниц. Этот аппаратный блок управления памятью отображает страницы в кадры, которые должны быть распределены на основе страниц.
Управление сегментированной памятью
Сегменты нуждаются в аппаратной поддержке в виде таблицы сегментов. Он содержит физический адрес раздела в памяти, размер и другие данные, такие как биты защиты доступа и статус.
Что такое обмен?

Преимущества обмена
Вот основные преимущества / плюсы обмена:
- Он предлагает более высокую степень мультипрограммирования.
- Позволяет динамическое перемещение. Например, если используется привязка адреса во время выполнения, то процессы можно менять в разных местах. Иначе в случае привязки времени компиляции и загрузки процессы должны быть перемещены в одно и то же место.
- Это помогает лучше использовать память.
- Минимальная потеря процессорного времени при завершении, поэтому его можно легко применить к методу планирования на основе приоритетов для повышения его производительности.
Что такое распределение памяти?
Здесь основная память делится на два типа разделов
Распределение разделов
Ниже приведены различные схемы распределения разделов:
- Первая подгонка: при этой подгонке выделяется раздел, который является первым достаточным блоком с начала основной памяти.
- Best Fit: Распределяет процесс по разделу, который является первым наименьшим разделом среди свободных разделов.
- Наихудшая подгонка: он распределяет процесс по разделу, который является самым большим достаточным свободно доступным разделом в основной памяти.
- Следующая подгонка: в большинстве случаев она похожа на первую подгонку, но эта подгонка ищет первый достаточный раздел из последней точки размещения.
Что такое пейджинг?
Что такое фрагментация?
Процессы сохраняются и удаляются из памяти, что создает свободное место в памяти, которое слишком мало для использования другими процессами.
После этого процесс, который не может быть выделен для блоков памяти, поскольку его небольшой размер и блоки памяти всегда остаются неиспользованными, называется фрагментацией. Этот тип проблемы возникает во время системы динамического выделения памяти, когда свободных блоков достаточно мало, поэтому она не может выполнить любой запрос.
Два типа методов фрагментации:
- Внешняя фрагментация
- Внутренняя фрагментация
- Внешнюю фрагментацию можно уменьшить, переставив содержимое памяти, чтобы разместить всю свободную память вместе в одном блоке.
- Внутренняя фрагментация может быть уменьшена путем назначения наименьшего раздела, который все еще достаточно хорош для выполнения всего процесса.
Что такое сегментация?
Метод сегментации работает почти так же, как пейджинг. Единственное различие между ними состоит в том, что сегменты имеют переменную длину, тогда как в методе подкачки страницы всегда имеют фиксированный размер.
Программный сегмент включает в себя основную функцию программы, структуры данных, служебные функции и т. Д. ОС поддерживает таблицу сегментной карты для всех процессов. Он также включает в себя список свободных блоков памяти, а также его размер, номера сегментов и места в памяти в основной или виртуальной памяти.
Что такое динамическая загрузка?
Что такое динамическое связывание?
Читайте также: