
Как достать текст из кэша
Обновлено: 04.07.2024
Приветствую!
В процессе открытия и просмотра сайтов, браузером автоматически сохраняются файлы, которые являются элементами просматриваемых страниц. Это могут быть графические элементы, аудио и видео, таблицы стилей,js файлы, html файлы и так далее.
Все эти файлы сохраняются в кэше браузера, и впоследствии используются для ускорения формирования и отображения страниц сайтов. Принцип работы кэша весьма прост – если тот или иной элемент страницы открываемого сайта сохранён локально, то браузер использует его при формировании страницы, а не запрашивает вновь с Интернет-а. Естественно, извлечение файла из кэша происходит несоизмеримо быстрее, нежели если бы происходила загрузка оного из сети.
Зная данное обстоятельство, пользователи прибегают к извлечению этих сохранённых файлов. К примеру, это может понадобиться, дабы выяснить, какие сайты просматривались и какой непосредственно контент там отображался. Это можно определить по сохранённым графическим элементам (картинкам, фотографиям) с просматриваемых сайтов, что были сохранены в кэше браузера.
Проблема заключается лишь в том, что в браузере Google Chrome и основанных на его «базе» (Яндекс Браузер, Opera и так далее), к файлам кэша напрямую не обратиться. Точнее, если открыть папку с кэшем, то непосредственно сохранённых файлов вы не обнаружите, а увидите лишь файлы с порядковыми номерами. Но вопрос с доступом к кэшу в браузере решаем, о чём и будет поведано в данном материале.
Инструкция по просмотру и извлечению (копированию, сохранению) файлов кэша в Google Chrome, Opera, Яндекс браузер и т.д.
Для решения поставленной задачи мы воспользуемся миниатюрной утилитой под названием «ChromeCacheView», которая работает без установи и имеет поддержку русского языка интерфейса (языковой файл скачивается отдельно и копируется в папку, где находится и сама утилита).
-
Зайдя на официальный сайт утилиты, скачайте архив с ней и распакуйте в заранее созданную дня неё папку. Запустите находящийся исполняемый файл программы. Будет открыто основное окно утилиты.

Программа попытается обнаружить папку с кэшем браузера и отобразит сохранённые в нём файлы. Если этого не произошло или у вас в системе установлено несколько браузеров (или используется портативный вариант браузера), то в верхнем меню выберите пункт Файл -> Выбрать папку с кешем.

Там будут доступны варианты быстрого переключения расположения путей для браузеров Opera, Vivaldi, Яндекс Браузер, Google Chrome. Если в вашем случае путь будет отличаться, то существует возможность ручного выбора папки кэша.

Делается это просто: выделите файлы, которые должны быть извлечены, а после нажмите в верхнем меню пункт Файл -> Копировать выбранные файлы кэша в… и укажите папку, куда они должны быть скопированы.
Воспользовавшись столь простым решением, вы с лёгкостью сможете просмотреть и скопировать файлы из кэша браузера Google Chrome, а также других браузеров, основанных на коде Chromium.
Мы рады, что смогли помочь Вам в решении поставленной задачи или проблемы.В свою очередь, Вы тоже можете нам очень помочь.
Просто поделитесь статьей в социальных сетях и мессенджерах с друзьями.
Поделившись результатами труда автора, вы окажете неоценимую помощь как ему самому, так и сайту в целом. Спасибо!
Требуется, конечно, более качественный сервис, поэтому, кроме описания нынешней скромной функциональности (вероятность найти в Гугл-кеше и на нескольких сайтах-копировщиках), поднимем в статье краудсорсинговые вопросы — чтобы «всем миром» задачу порешать и прийти к качественному решению, тем более, что решение видится близким для тех, кто имеет сервис копирования контента. Но давайте обо всём по порядку, рассмотрим все предложенные на данный момент решения.
Кеш Гугла
1) они просто не успевают мгновенно и многократно копировать появившиеся ссылки. Хотя надо отдать должное, что к популярным сайтам обращение у них частое, и за 2 и более часов они кешируют новые страницы. Каждый в своё время.
2) далее, возникает такая смешная особенность, что они могут чуть позже закешировать пустую страницу, говорящую о том, что «доступ закрыт».
3) поэтому результат кеширования — как повезёт. Можно обойти все такие кеширующие ссылки, если очень надо, но и оттуда информацию стоит скопировать себе, потому что вскоре может пропасть или замениться «более актуальной» бессмысленной копией пустой страницы.
Кеш Яндекса
Нет прямой ссылки, поэтому нужно просить (самое простое) пользователя нажать на ссылку «копия» на странице поиска, на которой будет одна эта статья (если её Яндекс вообще успел увидеть).
Как показывает опыт, статья, повисевшая пару часов и закрытая автором, довольно успешно сохраняется в кешах поисковиков. Впоследствии, скорее всего, довольно быстро заменится на пустую. Всё это, конечно, не устроит пользователей веба, который по определению должен хранить попавшую в него информацию.
Yahoo Pipes
Многочисленные клонировщики
Все из них болеют тем, что не дают ссылки на статью по её номеру, не приводят полный текст статьи, а некоторые вообще ограничиваются «захабренным» или «настолько ленивы», что копируют редко (к примеру, раз в день), что актуально не всегда. Однако, если хотя бы один автор копировщика подкрутит движок на сохранение полноценного и актуального контента, он окажет неоценимую услугу интернету, и его сервис займёт главное место в скрипте HabrAjax.
Из живых я нашёл пока что 4, некоторые давно существовавшие (itgator) на данный момент не работали. В общем, пока что они почти бесполезны, потому что заставляют искать статью по названию или ключевым словам, а не по адресу, по которому пользователь пришёл на закрытую страницу (а по словам отлично ищет Яндекс и не только по одному их сайту). Приведены в скрипте для какой-нибудь полезной информации.
Задача
Перед сообществом стоит задача, не утруждая организаторов сайта, довести продукт до качественного, не теряющего информацию ресурса. Для этого, как правильно заметили в комментариях к опросу, нужен архиватор актуальных полноценных статей (и комментариев к ним заодно).
В настоящее время неполное решение её, как описано выше, выглядит так:
Если искать в Яндексе, то подобранный адрес выведет единственную ссылку (или ничего):
Нажав ссылку «копия», увидим (если повезёт) сохранённую копию (страница выбрана исключительно для актуального на данный момент примера):
В Гугле несколько проще — сразу попадаем на копию, если тоже повезёт, и Гугл успел сохранить именно то, что нам надо, а не дубль отсутствующей страницы.

Забавно, что скрипт теперь предлагает «выбор альтернативных сервисов» и в этом случае («профилактические работы»):
Жду предложений по добавлению сервисов и копировщиков (или хотя бы проектов) (для неавторизованных — на почту spmbt0 на известном гуглоресурсе, далее выберем удобный формат).
Добавил ссылки мейла и ВК в обновление скрипта (habrAjax) (0.861), теперь там — на 2 строчки больше.


Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
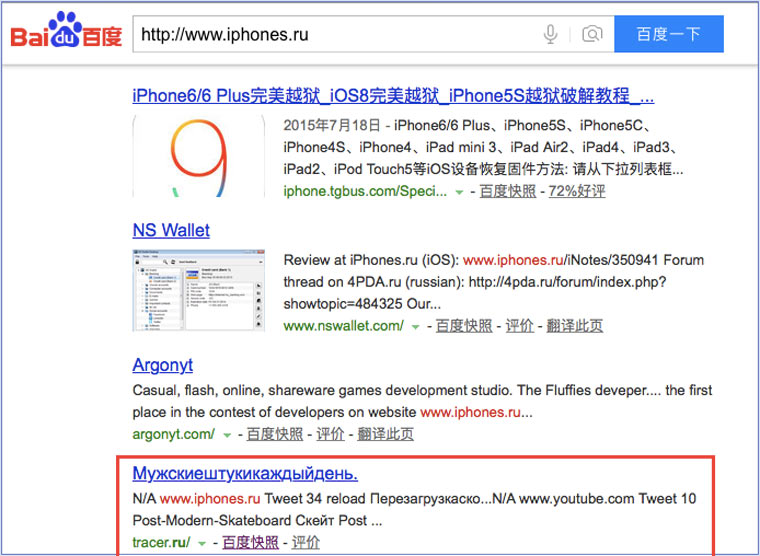
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
6. Archive.is, для собственного кэша
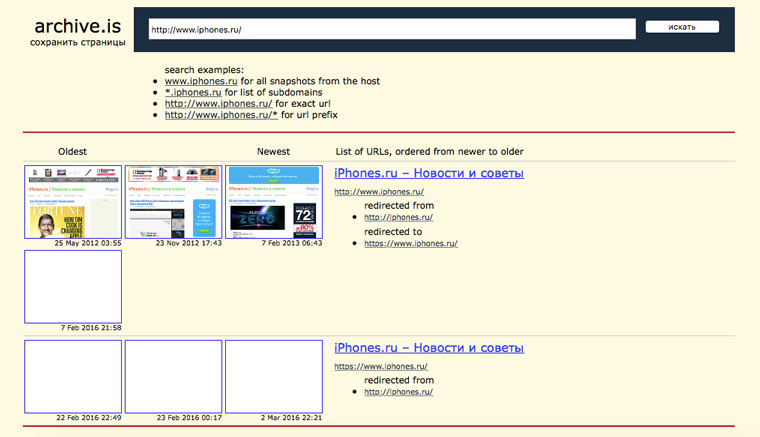
7. Кэши других поисковиков, мало ли
8. Кэш браузера, когда ничего не помогает
Safari
Ищем файлы в папке
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
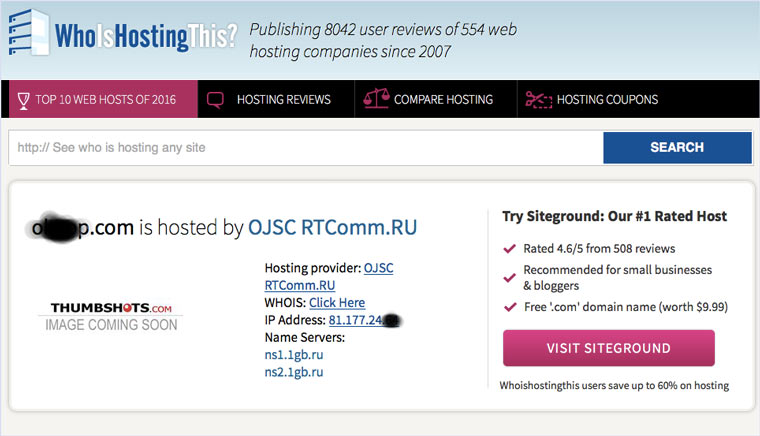
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
(25 голосов, общий рейтинг: 4.80 из 5)

БЕЗ скриптов, макросов, регулярных выражений и командной строки.
Эта статья пригодится студентам, которые хотят скачать все картинки с сайта разом, чтобы потом одним движением вставить их в Power Point и сразу получить готовую презентацию. Владельцам электронных библиотек, которые собирают новые книги по ресурсам конкурентов. Просто людям, которые хотят сохранить интересный сайт/страницу в соцсети, опасаясь, что те могут скоро исчезнуть, а также менеджерам, собирающим базы контактов для рассылок.
Есть три основные цели извлечения/сохранения данных с сайта на свой компьютер:
- Чтобы не пропали;
- Чтобы использовать чужие картинки, видео, музыку, книги в своих проектах (от школьной презентации до полноценного веб-сайта);
- Чтобы искать на сайте информацию средствами Spotlight, когда Google не справляется (к примеру поиск изображений по exif-данным или музыки по исполнителю).
Ситуации, когда неожиданно понадобится автоматизированно сохранить какую-ту информацию с сайта, могут случиться с каждым и надо быть к ним готовым. Если вы умеете писать скрипты для работы с утилитами wget/curl, то можете смело закрывать эту статью. А если нет, то сейчас вы узнаете о самых простых приемах сохранения/извлечения данных с сайтов.
1. Скачиваем сайт целиком для просмотра оффлайн
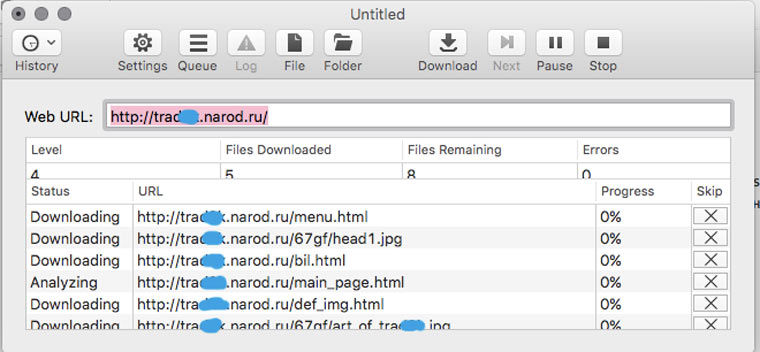
В OS X это можно сделать с помощью приложения HTTrack Website Copier, которая настраивается схожим образом.
Пользоваться Site Sucker очень просто. Открываем программу, выбираем пункт меню File -> New, указываем URL сайта, нажимаем кнопку Download и дожидаемся окончания скачивания.
2. Прикидываем сколько на сайте страниц
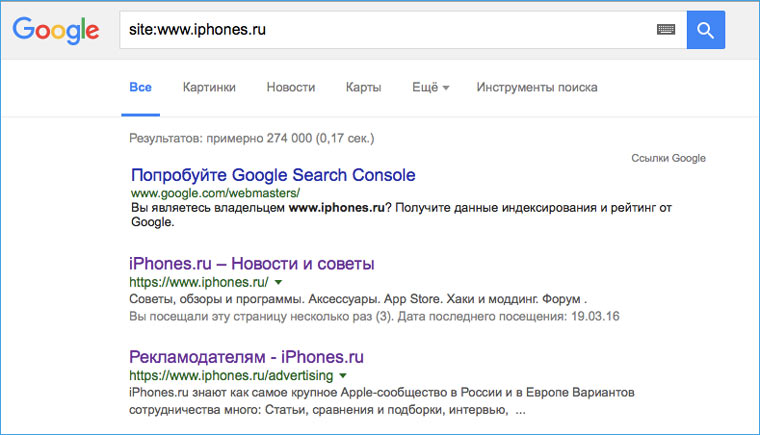
Перед тем как браться за скачивание сайта, необходимо приблизительно оценить его размер (не затянется ли процесс на долгие часы). Это можно сделать с помощью Google. Открываем поисковик и набираем команду site: адрес искомого сайта. После этого нам будет известно количество проиндексированных страниц. Эта цифра не соответствуют точному количеству страниц сайта, но она указывает на его порядок (сотни? тысячи? сотни тысяч?).
3. Устанавливаем ограничения на скачивание страниц сайта
![]()
Если вы обнаружили, что на сайте тысячи страниц, то можно ограничить число уровней глубины скачивания. К примеру, скачивать только те страницы, на которые есть ссылка с главной (уровень 2). Также можно ограничить размер загружаемых файлов, на случай, если владелец хранит на своем ресурсе tiff-файлы по 200 Мб и дистрибутивы Linux (и такое случается).
Сделать это можно в Settings -> Limits.
4. Скачиваем с сайта файлы определенного типа
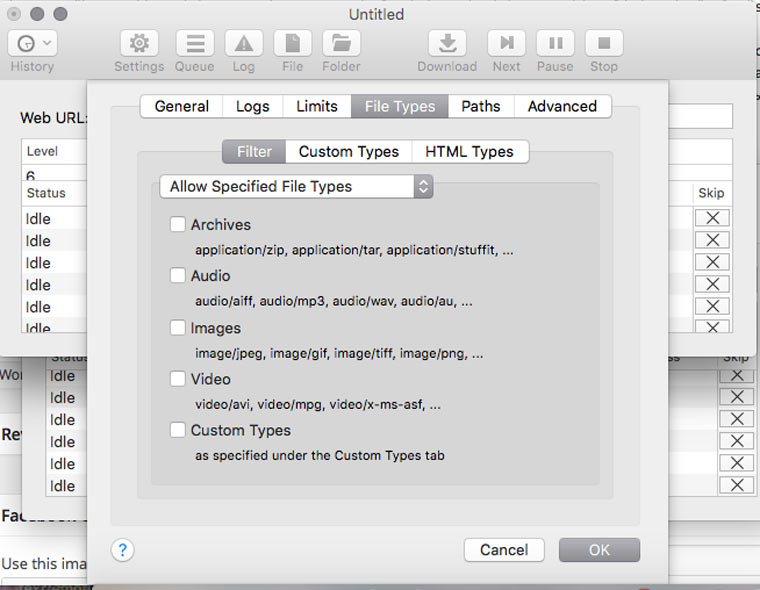
В Settings -> File Types -> Filters можно указать какие типы файлов разрешено скачивать, либо какие типы файлов запрещено скачивать (Allow Specified Filetypes/Disallow Specifies Filetypes). Таким образом можно извлечь все картинки с сайта (либо наоборот игнорировать их, чтобы места на диске не занимали), а также видео, аудио, архивы и десятки других типов файлов (они доступны в блоке Custom Types) от документов MS Word до скриптов на Perl.
5. Скачиваем только определенные папки
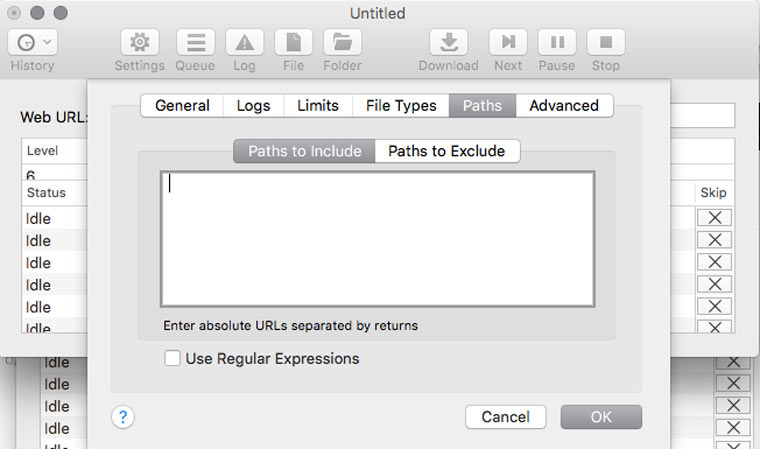
Если на сайте есть книги, чертежи, карты и прочие уникальные и полезные материалы, то они, как правило, лежат в отдельном каталоге (его можно отследить через адресную строку браузера) и можно настроить SiteSucker так, чтобы скачивать только его. Это делается в Settings -> Paths -> Paths to Include. А если вы хотите наоборот, запретить скачивание каких-то папок, то их адреса надо указать в блоке Paths to Exclude
6. Решаем вопрос с кодировкой
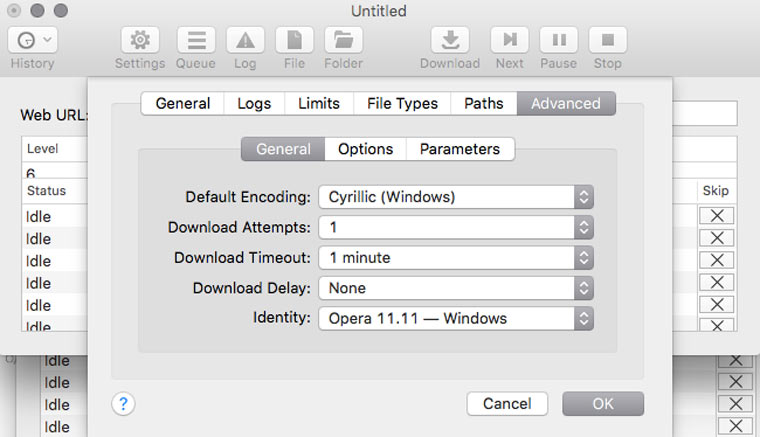
Если вы обнаружили, что скачанные страницы вместо текста содержат кракозябры, там можно попробовать решить эту проблему, поменяв кодировку в Settings -> Advanced -> General. Если неполадки возникли с русским сайтом, то скорее всего нужно указать кодировку Cyrillic Windows. Если это не сработает, то попробуйте найти искомую кодировку с помощью декодера Лебедева (в него надо вставлять текст с отображающихся криво веб-страниц).
7. Делаем снимок веб-страницы
Это может пригодиться для сравнения разных версий дизайна сайта, запечатления на память длинных эпичных перепалок в комментариях или в качестве альтернативы способу сохранения сайтов, описанного в предыдущих шести пунктах.
8. Сохраняем картинки только с определенной страницы
9. Извлекаем HEX-коды цветов с веб-сайта
10. Извлекаем из текста адреса электронной почты
11. Извлекаем из текста номера телефонов
А если надо отфильтровать в тексте заголовки, даты и прочую информацию, то к вам на помощь придут регулярные выражения и Sublime Text.
(2 голосов, общий рейтинг: 4.50 из 5)
Читайте также: