
Как хранить файлы на сервере
Обновлено: 06.07.2024
Размер: 18,4 Мб.
Длительность: 14 мин. 45 сек.
Сегодня у нас на повестке дня вопрос хранения файлов, которые есть у вас на сайте.
Я хочу рассказать вам о некоторых из способов, которые можно использовать для этих целей.
Вообще почему этот вопрос актуален? Ведь, казалось бы - храни себе все необходимые файлы на сервере хостера - и все будет ок.
Это так, но только с рядом оговорок:
1. Как правило, хостеры не выдают изначально большого пространства под ваши проекты.
2. Вы можете перейти на более дорогой тарифный план, и вам прибавят места, которые вы можете использовать.
Но здесь тоже есть свой минус. Скажем, ваш сайт не требователен именно к вычислительным ресурсам хостинга, т.е. его посещает не такая уж и толпа людей.
Поэтому выходит так, что вы получаете дополнительное место под файлы, однако ежемесячно переплачиваете за потенциально доступные вам вычислительные ресурсы, которые вам точно не пригодятся.
3. И, наконец, не все хостеры адекватно относятся к генерации вами достаточно большого объема трафика. Поэтому, если ваши файлы будут скачивать слишком уж активно, вас могут попросту отключить, т.к. вы создаете чрезмерную нагрузку на сервер.
Учитывая все эти моменты, стоит серьезно задуматься о том, где хранить ваши файлы, особенно, если их много, и скачивают их часто.
Краткий обзор урока (все подробности смотрите в видео):
Начнем с, наверное, самого известного решения, которое, увы, уже почти ушло в прошлое.
Это сервис Яндекс.Файлы, т.е. знаменитый Народ. Я сам пользуюсь этим сервисом до сих пор, хотя сейчас он как таковой уже упразднен и Яндекс предлагает использовать вместо него свой более новый сервис Яндекс.Диск.
Те файлы, которые были закачаны еще на Народ, успешно там хранятся, однако, я подозреваю, что Яндекс все настойчивее будет переводить всех именно на Яндекс.Диск, т.к. им очень накладно хранить огромные объемы информации бесплатно.
Вместо безлимитного народа на Яндекс.Диске вам выделяется не очень-то много места под файлы (10 Гб. по умолчанию).
При этом у вас на компьютере будет папка, с которой будет совершаться синхронизация, т.е. то, что вы положите в эту папку, будет закачано на Яндекс.Диск, и наоборот - то, что вы закачаете через веб-интерфейс на Яндекс.Диск, будет сохранено на ваш компьютер.
Вы можете создавать свою структуру папок и файлов так, как вам будет удобно. Также есть возможность делать файлы личными и публичными. Личные доступны только вам, публичные же могут скачать любые люди, которые имеют ссылку на этот файл.
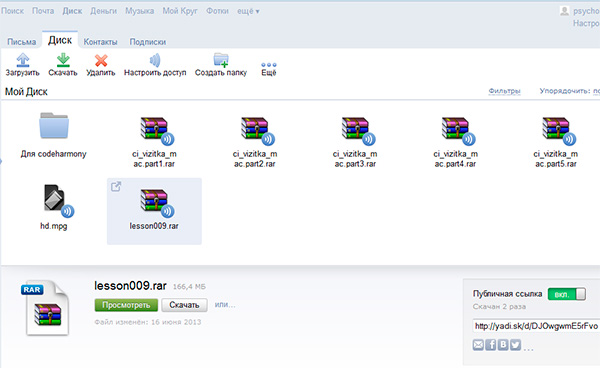
Несомненное достоинство сервиса - его бесплатность, поэтому для хранения относительно небольших объемов информации он подходит очень хорошо. Сейчас я использую его для хранения части архивов с видеоуроками, которые публикую на сайте.
Однако, наряду с достоинствами, у Яндекс.Файлов есть и свои недостатки. Я бы назвал два основных:
1. Нет возможности использовать этот сервис как классический хостинг.
Что я имею в виду? Вот смотрите, когда вы закачали файл (скажем, какое-то изображение) себе на хостинг, то в коде страницы вы указываете адрес до этого изображения в атрибуте src, в результате чего изображение выводится на экран в браузере.
Здесь это невозможно. Все, что вы можете - это дать другим людям возможность скачать это изображение - использовать его как иллюстрацию в статье не получится.
2. Второй недостаток - это имиджевая составляющая.
Понятно, что если вы раздаете со своего сайта какие-то файлы и уроки бесплатно, то Яндекс.Диск - прекрасное решение. Но если вы что-то продаете, например, обучающие видеокурсы и т.п. вещи, которые много весят, то было бы не очень профессионально давать человеку ссылки на скачивание, ведущие на Яндекс.Диск.
Ваш покупатель, скорее всего, ожидает получить ссылки в вашем домене, либо ссылки, которые выдают факт того, что файлы хранятся на каком-то специальном сервере. Яндекс.Диск выглядел бы здесь не очень уместно.
Какие альтернативы есть у этого сервиса?
Сразу скажу, что здесь не будет подробного обзора сервисов, я расскажу еще о двух решениях, которыми пользовался и продолжаю пользоваться сейчас.
Amazon Simple Storage Service (Amazon S3) — онлайновая веб-служба, предлагаемая Amazon Web Services, предоставляющая возможность для хранения и получения любого объёма данных, в любое время из любой точки сети, так называемый файловый хостинг.
Я пользуюсь этим сервисом уже более полутора лет, хотя в настоящее время использую его в качестве резерва на случай возникновения проблем с другим сервисом, о котором я расскажу чуть позже.
Зарегистрировавшись в этом сервисе, вы получаете возможность создавать свою структуру папок и хранить в них неограниченное количество файлов. Идея похожа на Яндекс.Диск.
Точно так же, как и там, вы можете разрешать или запрещать доступ к файлам, однако возможностей здесь больше.
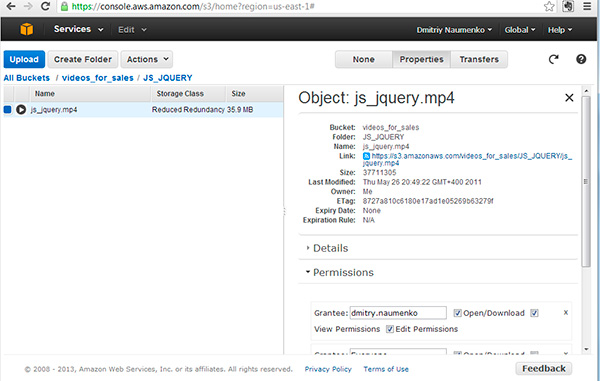
Из минусов для русскоговорящего пользователя я бы отметил то, что интерфейс полностью английский, и изменить язык возможности нет.
Второй момент - это то, что для пользования им вам понадобится завести долларовую карточку, с которой Amazon будет ежемесячно списывать плату за пользование услугами Amazon S3.
И, наконец, не самые низкие цены. Поскольку сервис рассчитан, в первую очередь, на страны Запада, стоимость их услуг находится на соответствующем уровне.
Конечно, хранить там небольшие объемы информации, которые скачиваются не очень часто, вполне можно, однако не очень рекомендовал бы вам хранить там много больших файлов, которые скачиваются часто - в этом случае ежемесячный чек может быть вполне ощутимым.
Я пользуюсь им уже более полугода и очень доволен как качеством самих услуг, так и уровнем технической поддержки.
Они предлагают очень широкий спектр услуг, однако я на данный момент использую только "Облачное хранилище".
Принцип использования все тот же. Вы создаете нужные вам папки (здесь они называются контейнерами) и помещаете в них файлы, которые должны быть доступны для скачивания.
Вы можете загружать новые файлы как через веб-интерфейс, так и по протоколу FTP, используя одну из специальных программ, которые будут вам предложены.
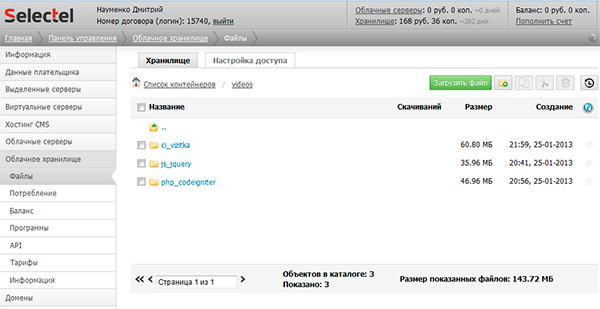
К плюсам данного решения можно отнести следующие моменты:
1. Все на русском языке, удобно и понятно;
2. Привычные способы оплаты (от электронных денег и до банковских карт);
3. Отличная техническая поддержка (реагирует в течение 15-20 минут);
4. Приятные цены.
Т.е. если в Яндекс.Диске нет возможности добавить изображение и вывести его на экран браузера, то здесь у вас такая возможность есть.
Когда это может пригодиться?
Это может быть актуально, если вы ожидаете приток на ваш сайт большого количества людей одновременно.
В этом случае вы можете разместить все медиа-файлы (изображения, анимацию, видео и др.) на серверах Selectel, а в коде веб-страницы просто указывать пути до этих файлов.
Так вы можете разгрузить ресурсы своего хостинга и предотвратить его падение при большом наплыве посетителей.
Разумеется, этот подход отлично работает, если нет других ограничивающих факторов, скажем, ограничения по количеству одновременных подключений к базе данных. Т.е. наиболее актуален такой подход при работе с высоконагруженными страницами со статической информацией.
Ну что ж, вот в общем-то все, что я хотел вам рассказать по данному вопросу, по данным сервисам. Я надеюсь, что этот небольшой обзор был для вас полезен, если перед вами уже встал вопрос о хранении файлов сайта.
Если же пока он не актуален, это может произойти уже в самом ближайшем будущем, и на этот случай у вас уже есть полезная информация.
На этом я заканчиваю, спасибо вам за внимание!
Если краткий текстовый обзор вам не до конца понятен, то изучите полную версию урока в видеоформате на этой странице выше.
С уважением, Дмитрий Науменко.
P.S. Занимаетесь веб-разработкой? Присмотритесь к премиум-урокам по различным аспектам сайтостроения, а также к бесплатному курсу по созданию своей CMS-системы на PHP с нуля. Все это поможет вам быстрее и проще освоить веб-технологии: начиная с HTML и CSS и заканчивая JavaScript, PHP и SQL.
Понравился материал и хотите отблагодарить?
Просто поделитесь с друзьями и коллегами!
Первоначально данная статья была размещена на Хабре, но по комментариям в нее были внесены некоторые дополнения, развивающие и объясняющие идеи, изложенные в статье.
За последнее время мне пришлось активно работать с сайтами, которые большие объемы информации хранят в файловой системе. Это разнообразные сайты фото и файловых хостингов, а также сайты с загрузкой видео контента, некоторые сайты проектировались и программировались мной с нуля, некоторые переписывались, дописывались или "приводились в порядок".
Должен отметить, что хранение файлов в файловой системе является для многих программистов областью, которая проходит мимо их внимания.
Для начала дам небольшой обзор распространенных ошибок:
1. файл храниться в файловой системе под кириллическим названием. Собственно, происходит следующее: пользователь загружает файл под именем, скажем, "безымянный-1.jpg", программист с тем же именем запихивает его в каталог, в котором хранятся файлы. Надеюсь, не нужно объяснять какие проблемы это за собой может повлечь?
2. файл храниться под тем же названием, под которым он был загружен пользователем, но символы не входящие в латинский алфавит транслитерированы. Уже лучше, но все равно данный способ вызывает множество проблем, например, пользователи очень любят грузить файлы с одинаковыми названиями))) И дело не в том, что они такие злые, например мой фотоаппарат после каждой очистки карты памяти начинает нумерацию фотографий с 00001.
И третья самая распространенная ошибка:
3. Хранение в директории количества файлов превышающих возможности файловой системы. Рассмотрим эту ситуацию на конкретном примере, переписывал я как-то файловый хостинг, большой, на момент переписывания объем информации вплотную приближался к четырем терабайтам, и это притом, что 80 процентов файлов были картинками. Все файлы на диске (дисков было 4 каждый по терабайту) случайным образом раскидывались по двум десяткам директорий, и так до заполнения диска, потом программа переходила на следующий диск. В результате для того что бы открыть директорию вебсерверу требовалось около трех секунд. Согласитесь, это катастрофически много. В каждой директории на диске находилось около двадцати тысяч файлов.
Проанализировав несколько таких ситуаций, я попробовал создать способ хранения файлов, который бы удовлетворял следующим условиям:
1. директория не должна «тормозить», то есть в одной директории не должно храниться более 1000 файлов или каталогов (число взято с запасом). По данному пункту напомню, что каталог файловой системы, можно рассматривать как файл со списком файлов, которые находятся в этом каталоге. Имея полный путь к файлу, мы должны просмотреть последовательно несколько файлов «каталогов», для того, что бы в последнем найти физический адрес (первый кластер нужного нам файла). Естественно, чем больше в каждом каталоге файлов и вложенных каталогов, тем больше времени занимает данная операция. Идеально, что бы весь список файлов содержащихся в одном каталоге, помещался в одном кластере на диске, что бы головка винчестера могла прочитать данный «файл-каталог» в «одно касание».
2. Имена файлов не должны повторяться. Наверное, данный пункт даже расшифровывать не нужно - одинаковые имена совсем не говорят об одинаковом содержимом и наоборот.
3. Желательно не хранить две копии одного файла. Это не является большой проблемой, если мы храним картинки (хотя как сказать… пара тысяч повторяющихся картинок в хорошем качестве и пяти гигабайт как не бывало). Но при хранении на диске чего то более серьезного по объему повторяющиеся файлы уже являются большой проблемой (например, три четыре одинаковых дистрибутива линукса.
После некоторых раздумий, я пришел к следующей схеме, которой и хочу поделиться с коллегами программистами.
Начну с последнего требования не хранить две копии файла. Для определения целостности файла давно и вполне успешно используется md5 хеш для php, эта задача решается функцией md5_file(filename), которая вычисляет MD5 хэш файла, имя которого задано аргументом filename используя алгоритм MD5 RSA Data Security, Inc. и возвращает этот хэш. Хэш представляет собой 32-значное шестнадцатеричное число.
Если два файла одинаковы у них и хеш будет одинаков, если разные - то разный. Сейчас в меня «полетят камни» сопровождающиеся рассуждениями о коллизиях и ненадежности md5. Отвечу по порядку md5 не надежна? Но мы же не ставим задачу обмануть «вероятного противника»! Мы просто получаем уникальный идентификатор файла и все. А по поводу коллизий. я не настаиваю на повторении моего метода один в один, используйте другую функцию. Только задумайтесь, два в двести пятьдесят шестой степени это - очень много! Если мне говорят, про возможность возникновения коллизий, я прошу человека привести пример двух строк или двух файлов, md5 хеш, которых одинаков. пока еще мне не было приведено такой пары так, что возможность является чисто теоретической. Однако в комментариях на хабре мне привели две строки, которые дают одинаковый md 5 хеш, что же один вариант возникновения коллизий теперь известен. Однако не предполагаю, что на практике это имеет действительно большое значение.
В качестве примера приведу обе строки:
d131dd02c5e6eec4693d9a0698aff95c2fcab58712467eab4004583eb8fb7f8955ad340609f4b30283e488832571415a
085125e8f7cdc99fd91dbdf280373c5bd8823e3156348f5bae6dacd436c919c6dd53e2b487da03fd02396306d248cda0
e99f33420f577ee8ce54b67080a80d1ec69821bcb6a8839396f9652b6ff72a70
d131dd02c5e6eec4693d9a0698aff95c2fcab5 O 712467eab4004583eb8fb7f8955ad340609f4b30283e4888325f1415a0 85125e8f7cdc99fd91dbd7280373c5bd8823e3156348f5bae6dacd436c919c6dd53e23487da03fd02396306d248cda0e9
9f33420f577ee8ce54b67080280d1ec69821bcb6a8839396f965ab6ff72a70
Каждый из этих блоков даёт MD5-хеш, равный 79054025255fb1a26e4bc422aef54eb4 .
Пункт второй – «имена файлов не должны повторяться, напрямую вытекает из третьего. Если в качестве имени файла на диске мы используем строку его md 5 хеша, то имена файлов не повторяются (реальные имена файлов (те, которые загрузил пользователь), мы можем хранить в базе данных). В случае загрузки пользователями двух одинаковых файлов, мы получаем у них одинаковые имена. И первое - файлы не будут дублированы, второе - мы не беспокоимся по поводу имен в директориях.
Теперь чуть более сложно, по поводу хранения файлов на диске. Я создаю структуру вложенных каталогов, опираясь на имена файлов. Здесь тоже полный простор для фантазии. Я ни в коем случае не призываю слепо копировать мой способ. Обычно я делаю два, три уровня вложенности каталогов. Первый уровень - это первые две буквы названия файла (не забыли, название файла это его md 5 хеш!);второй уровень это третья и четвертая буквы…
Каждый уровень вложенности дает мне * на 256 каталогов.
То есть, если в один каталог я могу загрузить не более 1000 файлов, то при одном уровне вложенности я могу безопасно разместить на диске 256 000 файлов; при двух уровнях вложенности – 65 536 000; при трех – 16 777 216 000 и так далее. Длинна строки md 5 хеша позволяет нам сделать 16 уровней вложенности в каталогах. На мой взгляд, этого хватит для обеспечения работы самых емких дисков. Хотя, исходя из практика, обычно, и трех уровней хватает «за глаза» для проектов любой сложности.
И напоследок. В тех же комментариях на хабре мне прозрачно намекнули, что я «лью воду из пустого в порожнее», так как данные вещи всем и хорошо известны. Что же возможно это и так. На «моем счету» около 20 крупных переписанных или дописанных проектов, и я нигде не встречал подобной системы хранения файлов. Максимум на что хватало фантазии разработчиков, это именовать каталоги по дате, а в внутри них уже файлы по порядковому номеру. Это было на сайте одного интернет издания… издание на протяжении пяти лет (до попадания ко мне в руки) каждый день публиковало статьи и соответственно через пять лет количество каталогов содержащих файлы выросло до полутора тысяч. То есть вплотную приблизилось к границе, за которой начинается «торможение» по файловой системе. Как правило программисты торопятся сдать проект, не задумываясь о тех объемах информации, которые будут находится на сайте через год два или десять лет.

Мы работаем с большими объемами медиа данных: видео, рендеры, фото, иллюстрации. Чтобы обеспечивать коллективную работу, нам нужен постоянный общий доступ ко всем этим файлам.
В какой-то момент нам перестало хватать собственного сервера, и мы начали искать облачное хранилище, удовлетворяющее нашим запросам.
Мы сравним популярные облачные хранилища для бизнеса: Google Drive, DropBox, Citrix ShareFile и Microsoft OneDrive.
Наши требования к облачному хранилищу:
- Безлимитный объем данных — у нас много данных, в среднем около 10ТБ. Не хочется постоянно думать сколько нужно докупить места в этом месяце и почему вдруг кончилась квота.
- Версионность файлов и логирование — git приучил нас, что все изменения можно видеть и откатить. Поэтому и с файлами должны быть точно так же: любое изменение, удаление должно быть обратимо и легко контролироваться.
- Права доступа — никаких больше общих папок доступных всем. Каждый сотрудник должен иметь свою область видимости.
- Upload без регистрации — клиенты не должны больше искать файлообменники, чтобы прислать нам тяжелый файл. Файлы должны сразу загружаться в наше хранилище без промежуточных сервисов.
Как это было раньше

Когда данных было поменьше, а облачных сервисов (за разумные деньги) не было, нам приходилось держать здоровенный сервер с хрустящими жесткими дисками в RAID массиве. Доступ к нему происходил через SMB. За ним нужно было постоянно присматривать, менять жесткие диски, бекапить. Раз в месяц у него что-то происходило: то скорость записи/чтения резко падала, то какая-то папка или файл становились недоступны из-за недопустимых символов в названии и т.д.
Когда сотрудников стало больше, они начали работать удаленно, да и еще и с разных операционных систем: Windows, macOS. Для доступа к серверу пришлось развернуть VPN, который обеспечивал хоть и медленный, но доступ к файлам. В какой-то момент стало понятно, что этот подход устарел и мы стали искать ему замену.
Объем хранилища и цены
Мы храним большие объемы данных, около 10ТБ в среднем. Во время активной работы эта цифра может увеличиваться в несколько раз. Проекты приходится хранит еще несколько месяцев после сдачи клиенту, а то и вечно. Поэтому для нам нужно безлимитное хранилище, чтобы каждый месяц не думать сколько нужно докупить гигабайтов.
Количество сотрудников варьируется в пределах десяти, поэтому для удобства мы будем считать стоимость тарифов на 10 сотрудников.
| Citrix ShareFile | Dropbox | Google Drive | Microsoft OneDrive | |
|---|---|---|---|---|
| Объем | Не ограничен | Не ограничен | Не ограничен | Не ограничен |
| Цена за 10 пользователей в месяц | 150$ | 200$ | 100$ | 125$ |
У большинства сервисов такой ценник только при оплате на год вперед, и при оплате помесячно цена выше на 20-40%. Это нужно учитывать.
Скрытые ограничения
Обычно, если что-то указано как безлимитное, нужно искать мелкий серый текст в условиях. У каждого сервиса есть свои особенности, которые можно не разглядеть с первого взгляда. У некоторых они настолько странные, что делают их полностью бесполезными для нашей задачи.
- Dropbox — максимальный объем загружаемого файла 50ГБ
- Citrix ShareFile — максимальный объем загружаемого файла — 100ГБ. Не очень много, но терпимо.
- Google Drive — У Google Drive максимальный размер файла 5ТБ!
Для каждого аккаунта или общего диска максимальный размер отдельного файла, который можно загрузить или синхронизировать, составляет 5 ТБ. Максимальный объем файлов, которые можно загрузить за один день, составляет 750 ГБ
Microsoft OneDrive

В бизнес тарифах Microsoft OneDrive максимальный размер файла ограничен 15ГБ. Это просто какое-то недоразумение! Во времена, когда даже бюджетные камеры снимают видео с битрейтом 200Mbit/s и легко генерируют файлы размером сотни гигабайт. Это ограничение делает сервис OneDrive полностью бесполезным для нас.
Выборочная синхронизация
Бухгалтеру Светлане не нужно на компьютере 2ТБ видео с которыми работает видеограф Андрей. Для этого система должна иметь функцию выборочной синхронизации, то есть пользователь должен вручную отметить какие файлы ему нужны локально на компьютере, а какие только по запросу. Все четыре сервиса поддерживают эту функцию. Однако приложение Google Drive позволяет отметить только папки в корне диска, то есть нельзя включить синхронизацию только для Бухгалтерия --> Отчеты --> 2018, можно только для всей папки Бухгалтерия.
Права доступа
Разные сотрудники должны иметь доступ только к определенным папкам и файлам. Система должна сохранять подробный журнал изменений прав доступа и обращений к файлам. Все четыре системы имеют такой функционал. У Citrix ShareFile и DropBox можно включить уведомления в случае доступа к определенным файлам и папкам. Это может быть полезно для файлов с особо охраняемой информацией. Например, можно установить алерт на доступ к файлам клиентбанка и некоторым документам, и быть в курсе, что кто-то в нерабочее время вдруг обратился к этим файлам.
Версионность

Теперь мы можем мгновенно обратится к любой версии файла. Особенно приятно, что видно каким пользователем были сделаны изменения. Это исключает ситуации, когда можно сказать "это не я, оно уже так было".

Список изменений файла в ShareFile с указанием даты и аккаунта который вносил изменения.
Запрос файлов и анонимная загрузка

Раньше нам приходилось создавать временный аккаунт на FTP сервере и выдавать его клиенту. Попутно долго объясняя, как настроить FTP клиент, как восстановить закачку после обрыва и так далее. Сейчас же можно просто нажать «запросить файлы» на любой папке, и сервис создаст анонимную ссылку, по которой можно залить файлы через браузер. При этом разрешена только загрузка, нельзя увидеть, что уже находится в папке или как-то просматривать на сервере. Это избавляет от необходимости создавать временные учетные записи для клиентов и следить за их удалением. Эту функцию поддерживают только ShareFile и Dropbox.
Доступ по WebDAV и FTP
В некоторых случаях установка стороннего ПО на компьютер не желательна или невозможна, например на корпоративных системах. У ShareFile есть доступ по (S)FTP и WebDAV. Google Drive имеет сторонние программы для доступа к диску по WebDAV, но все они требуют передачи доступа к аккаунту третьим лицам. Dropbox не имеет поддержки сторонних протоколов, доступ возможен только через клиент.
Клиенты для этих протоколов встроены в большинство операционных систем. Правда клиент macOS почему-то часто монтирует WebDAV в режиме read only.

Хранилище Citrix ShareFile можно подключить по WebDAV без установки стороннего софта
Интересует вопрос, как на сегодняшний момент лучше хранить файлы на сервере?
Знаю, что есть 2 основных способа хранения - напрямую в БД (что на выходе не очень производительно) и хранение файлов на сервере, а в БД хранить путь до файла. В связи с этим вопрос:
1) как все таки оптимально хранить файлы?
2) если предполагается, что файлов будет очень много, как их правильно хранить? (отдельный сервер или прямо там же, где и сам сайт или же выгоднее будет положиться на облачный сервис хранения)
3) если на сайте понадобятся изображения разных размеров (допустим уменьшенная версия аватара пользователя), то как лучше это изображение хранить? (при загрузке пользователем изображения сохранять изображение и кучу его обрезанных версий для разных случаев или же хранить одно обрезанное до определенного размера изображение, а в нужных местах, где нужна "версия поменьше" сжимать его средствами CSS? Насколько затратны эти способы?)
4) касательно способа хранения "файлы - на сервере/пути - в БД" - что делать при случае, когда каким-нибудь образом запись в БД с путем до файла пропадет, а файл на сервере останется (и наоборот, файл пропадет, а запись в бд будет)?
1) как все таки оптимально хранить файлы?
Если файлы небольшого размера и их количество невелико, то можно и в БД. Плюсы: бэкап всегда сохраняет файлы и бд, можно применять каскадные операции. Минусы: БД становится большого размера. Бэкап и восстановление могут длиться часами
если предполагается, что файлов будет очень много, как их правильно хранить?
Зависит от типа и частоты операций, которые вы будете с ними проделывать. Если большую часть операций составляет чтение, то можно и на cdn или отдельном сервере. Опять же можно начать с хранения в директории на том же сервере, при увеличении размера примонтировать в эту директорию отдельный диск, по мере роста можно воспользоваться сетевыми хранилищами с доступом по iSCSI, NFS и т.д.
Если файлов много, следует учитывать, что файловые системы имеют ограничение на количество файлов в одном каталоге. Поэтому стоит продумать структуру подкаталогов.
3) если на сайте понадобятся изображения разных размеров
Если позволяет место, то лучше оставлять оригинал. Тогда, при смене дизайна оффлайн-скриптом на сервере вы сможете перегенерировать нужные вам размеры, или "переналожить" водяной знак с новым дизайном. Некоторые используют "ленивый" ресайз. Постоянно хранятся оригиналы, нужные размеры генерируются при первом доступе к сущности и сохраняются во временный каталог, далее используются уже измененные файлы. При отсутствии активности измененные размеры чистятся по крону
что делать при случае, когда каким-нибудь образом запись в БД с путем до файла пропадет, а файл на сервере останется
тут уж ничего особо не сделаешь. Только устраивать периодическую синхронизацию, с перебором файлов и проверкой наличия записи в БД
Система хранения данных - это программно-аппаратное решение для надежного и безопасного хранения данных, а также предоставления гарантированного доступа к ним.
Так, под надежностью подразумевается обеспечение сохранности данных, хранящихся в системе. Такой комплекс мер, как резервное копирование, объединение накопителей в RAID массивы с последующим дублированием информации способны обеспечить хотя бы минимальный уровень надежности при относительно низких затратах. При этом также должна обеспечиваться доступность, т. е. возможность беспрепятственной и непрерывной работы с информацией для санкционированных пользователей. В зависимости от уровня привилегий самих пользователей, система предоставляет разрешение для выполнения операций чтения, записи, перезаписи, удаления и так далее.
Безопасность является, пожалуй, наиболее масштабным, важным и труднореализуемым аспектом системы хранения данных. Объясняется это тем, что требуется обеспечить комплекс мер, направленный на сведение риска доступа злоумышленников к данным к минимуму. Реализовать это можно использованием защиты данных как на этапе передачи, так и на этапе хранения. Также важно учитывать возможность самих пользователей неумышленно нанести вред не только своим, но и данным других пользователей.
ТОПОЛОГИИ ПОСТРОЕНИЯ СИСТЕМ ХРАНЕНИЯ ДАННЫХ
Большинство функции, которые выполняют системы хранения данных, на сегодняшний день, не привязаны к конкретной технологии подключения. Описанные ниже методы используется при построении различных систем хранения данных. При построении системы хранения данных, необходимо четко продумывать архитектуру решения, и исходя из поставленных задач учитывать достоинства и недостатки, присущие конкретной технологии в конкретной ситуации. В большинстве случаев применяется один из трех видов систем хранения данных:
DAS (Direct-attached storage) - система хранения данных с прямым подключением (рисунок ниже). Устройство хранения (обычно жесткий диск) подключается непосредственно к компьютеру через соответствующий контроллер. Отличительным признаком DAS является отсутствие какого-либо сетевого интерфейса между устройством хранения информации и вычислительной машиной. Система DAS предоставляет коллективный доступ к устройствам хранения, однако для это в системе должно быть несколько интерфейсов параллельного доступа.
Главным и существенным недостатком DAS систем является невозможность организовать доступ к хранящимся данным другим серверам. Он был частично устранен в технологиях, описанных ниже, но каждая из них привносит свой новый список проблем в организацию хранения данных.
NAS (Network-attached storage) - это система, которая предоставляет доступ к дисковому пространству по локальной сети (рисунок выше). Архитектурно, в системе NAS промежуточным звеном между дисковым хранилищем и серверами является NAS-узел. С технической точки зрения, это обычный компьютер, часто поставляемый с довольно специфической операционной системой для экономии вычислительных ресурсов и концентрации на своих приоритетных задачах: работы с дисковым пространством и сетью.
Дисковое пространство системы NAS обычно состоит из нескольких устройств хранения, объединенных в RAID - технологии объединения физических дисковых устройств в логический модуль, для повышения отказоустойчивости и производительности. Вариантов объединения довольно много, но чаще всего на практике используются RAID 5 и RAID 6 [3], в которых данные и контрольные суммы записываются на все диски одновременно, что позволяет вести параллельные операции записи и чтения.
Главными преимуществами системы NAS можно назвать:
- Масштабируемость - увеличение дискового пространства достигается за счет добавления новых устройств хранения в уже существующий кластер и не требует переконфигурации сервера;
- Легкость доступа к дисковому пространству - для получения доступа не нужно иметь каких-либо специальных устройств, так как все взаимодействие между системой NAS и пользователями происходит через сеть.
SAN (Storage area network) - система, образующая собственную дисковую сеть (рисунок ниже). Важным отличием является то, что с точки зрения пользователя, подключенные таким образом SAN-устройства являются обычными локальными дисками. Отсюда и вытекают основные преимущества системы SAN:
- Возможность использовать блочные методы хранения - базы данных, почтовые данные,
- Быстрый доступ к данным - достигается за счет использования соответствующих протоколов.
СИСТЕМЫ РЕЗЕРВНОГО КОПИРОВАНИЯ ДАННЫХ
Резервное копирование - процесс создания копии информации на носителе, предназначенном для восстановления данных в случае их повреждения или утраты. Существует несколько основных видов резервного копирования:
- Полное резервное копирование;
- Дифференциальное резервное копирование;
- Инкрементное резервное копирование.
Рассмотрим их подробнее.
Полное резервное копирование. При его применении осуществляется копирование всей информации, включая системные и пользовательские данные, конфигурационные файлы и так далее (рисунок ниже).
Дифференциальное резервное копирование. При его применении сначала делается полное резервное копирование, а впоследствии каждый файл, который был изменен с момента первого полного резервного копирования, копируется каждый раз заново. На рисунке ниже представлена схема, поясняющая работу дифференциального резервного копирования.
Инкрементное резервное копирование. При его использовании сначала делается полное резервное копирование, затем каждый файл, который был изменен с момента последнего резервного копирования, копируется каждый раз заново (рисунок ниже).
К системам резервного копирования данных выдвигаются следующие требования:
- Надежность - обеспечивается использованием отказоустойчивого оборудования для хранения данных, дублированием информации на нескольких независимых устройствах, а также своевременным восстановлением утерянной информации в случае повреждения или утери;
- Кроссплатформенность - серверная часть системы резервного копирования данных должна работать одинаково с клиентскими приложениями на различных аппаратно-программных платформах;
- Автоматизация - сведение участие человека в процессе резервного копирования к минимуму.
ОБЗОР МЕТОДОВ ЗАЩИТЫ ДАННЫХ
Криптография - совокупность методов и средств, позволяющих преобразовывать данные для защиты посредством соответствующих алгоритмов.
Шифрование - обратимое преобразование информации в целях ее сокрытия от неавторизованных лиц. Признаком авторизации является наличие соответствующего ключа или набора ключей, которыми информация шифруется и дешифруется. Криптографические алгоритмы можно разделить на две группы:
- Симметричное шифрование;
- Асимметричное шифрование.
Под симметричным шифрованием понимаются такие алгоритмы, при использовании которых информация шифруется и дешифруется одним и тем же ключом. Схема работы таких систем представлена на рисунке ниже.
Главным проблемным местом данной схемы является способ распределения ключа. Чтобы собеседник смог расшифровать полученные данные, он должен знать ключ, которым данные шифровались . Так, при реализации подобной системы становится необходимым учитывать безопасность распределения ключевой информации для того, чтобы на допустить перехвата ключа шифрования.
К преимуществам симметричных криптосистем можно отнести:
- Высокая скорость работы за счет, как правило, меньшего числа математических операций и более простых вычислений;
- Меньшее потребление вычислительной мощности, в сравнении с асимметричными криптосистемами;
- Достижение сопоставимой криптостойкости при меньшей длине ключа, относительно асимметричных алгоритмов.
Под асимметричным шифрованием понимаются алгоритмы, при использовании которых информация шифруется и дешифруется разными, но математически связанными ключами - открытым и секретным соответственно. Открытый ключ может находится в публичном доступе и при шифровании им информации всегда можно получить исходные данные путем применения секретного ключа. Секретный ключ, необходимый для дешифрования информации, известен только его владельцу и вся ответственность за его сохранность кладется именно на него. Структурная схема работы асимметричных криптосистем представлена на рисунке ниже.
Ассиметричные криптосистемы архитектурно решают проблему распределения ключей по незащищенным каналам связи. Так, если злоумышленник перехватит ключ, применяемый при симметричном шифровании, он получит доступ ко всей информации. Такая ситуация исключена при использовании асимметричных алгоритмов, так как по каналу связи передается лишь открытый ключ, который в свою очередь не используется при дешифровании данных.
Другим местом применения асимметричных криптосистем является создание электронной подписи, позволяющая подтвердить авторство на какой-либо электронный ресурс.
Достоинства асимметричных алгоритмов:
- Отсутствует необходимость передачи закрытого ключа по незащищенного каналу связи, что исключает возможность дешифровки передаваемых данных третьими лицами,
- В отличии от симметричных криптосистем, в которых ключи шифрования рекомендуется генерировать каждый раз при новой передаче, в асимметричной их можно не менять продолжительное время.
ПОДВЕДЁМ ИТОГИ
При проектировании таких систем крайне важно изначально понимать какой должен получиться результат, и исходя из потребностей тщательно продумывать физическую топологию сети хранения, систему защиты данных и программную архитектуру решения. Также необходимо обеспечить резервное копирование данных для своевременного восстановления в случае частичной или полной утери информации. Выбор технологий на каждом последующем этапе проектирования, зачастую, зависит от принятых ранее решений, поэтому корректировка разработанной системы в таких случаях, нередко, затруднительна, а часто даже может быть невозможно.
Читайте также: