
Как найти js файл на сайте
Обновлено: 06.07.2024
Всё нижеописанное уже так или иначе общеизвестно и опубликовано. Поскольку я ни разу не знаток javascript, данная заметка не претендует на "статью" и носит скорее антисклерозный характер. Основная задача - парсинг сайтов (кто о чём, а я всё о том же), а значит, получение исходного текста страницы.
Во втором случае на форме размещается реквизит типа "Строка" неограниченной длины, с видом "Поле HTML документа", и ему присваивается локальный или сетевой URL. В момент присвоения начинается загрузка документа. Здесь и далее документ определяется как
Окончание загрузки правильнее всего определять по совокупности двух факторов: возникновения события ЭУ 1С "ДокументСформирован" и по выставлении свойства "readyState", равному "complete". Замечено, что, несмотря на теорию, в текущих релизах эти события не синонимичны; полагаю, потому, что событие 1С срабатывает при "interactive", когда уже загружена страница и построено DOM-дерево, но картинки и айфреймы ещё догружаются (т.е. вызвано не Load, а DOMContentLoaded). Либо, возможны новые изменения-догрузки сразу после первой загрузки. Разумно делать обработчик ожидания с выключением в момент полной загрузки.
Мы можем оперировать DOM-моделью документа, методами документа и его элементов. Проверено, что все методы HTML5 работают корректно, с двумя скверными особенностями - они далеко не всегда вызывают ошибки (так, "removeAttribute" при указании несуществующего атрибута никак не ругается) и "пустое" значение js не синонимично пустому в 1С (так, правильнее проверять не "ЗначениеЗаполнено(хтмл)", а "ТипЗнч(хтмл)=Тип("Неопределено") и т.д.)
Мы не можем работать с глобальными переменными - они не сохраняются между сеансами обращения к документу. Т.е. в некоем контексте, в т.ч. контексте документа в целом, можно объявить переменную, и в рамках фрагмента кода js она будет, но следующее обращение столкнётся даже не с пустой переменной, а с её отсутствием.
Не рекомендую ни в каком месте js-кода использовать this - оно или пусто, или некорректно. Возможно, это исправят в других релизах, но надёжнее указывать полный путь к объекту. Если объект создан динамически, тоже пишите его явно.
Вместо "parentWindow" используем "DefaultView", хорошо известное как Document.Window, и можем вызывать скрипты страницы. Также, можем добавлять собственные скрипты (что мне представляется более верным и менее травматичным для документа, нежели подвешивание кусков кода на события и вызов этих событий, как предложено в статье 2016 года). Делается это так:
Можно вносить не в скрипты head'a, а в конец body. Документ уже загрузился, всякие асинхроны своё отрабатывают без учёта наших скриптов, Defer всё равно ни на что не влияет. Перезагрузка страницы при этом не происходит, designMode="on" включать не обязательно. Но важно учитывать, что, если текст скрипта не обёрнут в функцию, то он выполнился сразу в момент срабатывания appendChild, поэтому советую в скрипты класть именованные функции js или осознанно применять эту фичу. А вообще рез=Элементы.ПолеХТМЛ.Документ.DefaultView.Math1(100,50); // и получим 150
Это удобнее, чем присваивать результаты неким свойствам неких объектов и вычитывать их оттуда, или ловить в параметрах событий через createEventObject() и брать из Event.data. Кроме того, не все типы данных могут пережить это преобразование (так, для ArrayBuffer или Blob у меня не сработало, да и про объекты js есть сомнения). А так мы имеем прямое обращение к функции js из языка 1С. Для входных параметров ограничений или искажений экспериментально не обнаружено.
Замечу, что можно многократно добавлять функцию с тем же именем, js просто перезаписывает её код поверх старого (и, кстати, известная разница между "a=func1 и a=func1()" наблюдается и в 1С). Также замечу, что можно добавить одним куском кода в один скрипт сразу несколько функций. Если скрипт добавлен, а обращение по имени вызывает ошибку (1С пишет, что метод не найден), значит, где-то в коде js ошибка, он не скомпилировался и не добавился - так можно себя проверять "на лету".
Задействовать Eval мне не удалось - ошибки не происходит, но и ничего не делает.
Теперь переходим к решению заявленной задачи.
1. Можно обратиться к свойству outerHTML:
Но нам-то надо получить вообще всё, все объявления.
2. Можно использовать Node.js - сильно могучую штуковину, имеющую возможности различной сериализации и выгрузки, которую, однако, надо инсталлировать; потому отпадает. Тем, кто соберётся: обязательно всюду, где только можно, явно указывайте всякие encoding и charset по Документ.inputEncoding, взятому из документа, иначе жесть.
3. webBrowser.DocumentText неприменимо, т.к. нет такого ЭУ - webBrowser (если, конечно, не мучиться долго и старательно с обёртками и актив-иксинами), и опять же, он не кроссплатформенный. Можно, конечно, сделать com-объект MSIE.Application и дёргать его, но зачем.
Но капризничает, если неправильно написан адрес в части префиксов, доменов, протоколов; и любит, чтоб сайт был по возможности статичным, чей хтмл известен уже прямо целиком, что в наше время редкость.
5. Можно использовать (и мне понравился этот способ) объект XMLSerializer. Это часть современной js, и у неё есть метод сериализации всея документа в строку:
В этом случае будет возвращено всё, включая декларацию <!DOCTYPE html>, хтмл с его объявлениями пространств имён, скриптами и т.д., словом, то, что надо. Кодировка UTF-8, и, судя по утверждениям гуру с хабра, с кодировкой он не лажает. Правда, немного жаль, что для этого же сериализатора метод serializeToStream, описанный здесь, более не работает. Кстати, теперь у нас есть возможность обработать двоичный поток, и можно было бы сделать нечто такое:
но увы, это уже не поддерживается.
Таким образом, синхронное получение исходного текста документа загруженной страницы html это:
Добавляем скрипт с этой функцией. Вызываем:
Наблюдаем свежедобавленный скрипт среди прочих в head.
Вот, собственно, и всё. В прежние времена писали ОболочкаХТМЛ.ПолучитьТекст() и были счастливы, но прогресс не стоит)
. и я грустно пошёл переделывать свои старые публикации под новую механику. Потому что беда общая. Буде кто готов сию пещерную дикость развить и дополнить, всецело приветствую.
Иногда при заходе на сайт может возникнуть потребность посмотреть какой JavaScript-код подключен на странице. Это может понадобится в различных ситуациях, например, необходимо разобраться как работает тот или иной функционал на рассматриваемом сайте.
JavaScript-код может быть внедрен прямо в исходный код страницы сайта, тогда проблем с получением такого кода не возникнет. Но зачастую в добавок к такому коду подключаются и сторонние файлы с кодом, тогда отыскать участок кода, отвечающего за конкретный функционал сложнее. В таком случае необходимо проанализировать, какие файлы подключены на страницу.
Процедура получения кода JavaScript обычно сводится к следующему:
- открыть исходный код страницы сайта и обратить внимание на подключение скриптов. Обычно скрипты подключаются либо в верхней части страницы, либо внизу – делается это при помощи тега script;
- скопировать адрес, указанный в атрибуте src тега script;
- адреса обычно указываются относительные, поэтому далее необходимо подставить в начало к полученному адресу скрипта домен рассматриваемого сайта;
- после этого достаточно подготовленный адрес вставить в строку адреса браузера в новой вкладке, в результате на странице будет выведен весь код из файла;
- скопировать код и вставить в редактор с подсветкой синтаксиса.
Данную процедуру можно повторить для каждого подключенного файла, использовав поиск по исходному коду, достаточно указать ключевое слово script.
Когда исходный код получен, можно сделать анализ кода JavaScript:
- необходимо навести курсор на исследуемый элемент и открыть консоль разработчика при помощи контекстного меню над этим элементом. В консоли следует обратить внимание, какие классы или идентификаторы прописаны у элемента. Получив ключевые слова, можно переходить к следующему пункту;
- воспользоваться поиском в редакторе с полученным исходным кодом для нахождения нужного участка кода по извлеченным ключевым словам;
- когда совпадения найдены, можно приступить к изучению участка кода.
При помощи указанной методики, можно получить JavaScript-код практически любой страницы сайта, после чего выполнить комплексный анализ JavaScript-кода. В некоторых случаях анализ кода может быть усложнен, так как может быть применена защита JavaScript-кода, но зачастую такой код никак не защищен.
Осваивайте профессию, начните зарабатывать, а платите через год!

Курсы Python Акция! Бесплатно!

Станьте хакером на Python за 3 дня

Веб-вёрстка. CSS, HTML и JavaScript


Курс Bootstrap 4

Станьте веб-разработчиком с нуля
В этой главе мы займемся размещением сценариев в HTML-документе, чтобы иметь возможность использовать их для оперативной модификации HTML-документа. Для вставки JavaScript-кoдa в НТМL-страницу обычно используют элемент <script> .
Первая программа
Чтобы ваша первая пpoгpaммa (или сценарий) JavaScript запустилась, ее нужно внедрить в НТМL-документ.
Сценарии внедряются в HTML-документ различными стандартными способами:
- поместить код непосредственно в атрибут события HTML-элемента;
- поместить код между открывающим и закрывающим тегами <script> ;
- поместить все ваши скрипты во внешний файл (с расширением .js), а затем связать его с документом HTML.
JavaScript в элементе script
Самый простой способ внедрения JavaScript в HTML-документ – использование тега <script> . Теги <script> часто помещают в элемент <head> , и ранее этот способ считался чуть ли не обязательным. Однако в наши дни теги <script> используются как в элементе <head> , так и в теле веб-страниц.
Таким образом, на одной веб-странице могут располагаться сразу несколько сценариев. В какой последовательности браузер будет выполнять эти сценарии? Как правило, выполнение сценариев браузерами происходит по мере их загрузки. Браузер читает HTML-документ сверху вниз и, когда он встречает тег <script> , рассматривает текст программы как сценарий и выполняет его. Остальной контент страницы не загружается и не отображается, пока не будет выполнен весь код в элементе <script> .
Обратите внимание: мы указали атрибут language тега <script> , указывающий язык программирования, на котором написан сценарий. Значение атрибута language по умолчанию – JavaScript, поэтому, если вы используете скрипты на языке JavaScript, то вы можете не указывать атрибут language .
JavaScript в атрибутах событий HTML-элементов
Вышеприведенный сценарий был выполнен при открытии страницы и вывел строку: «Привет, мир!». Однако не всегда нужно, чтобы выполнение сценария начиналось сразу при открытии страницы. Чаще всего требуется, чтобы программа запускалась при определенном событии, например при нажатии какой-то кнопки.
В следующем примере функция JavaScript помещается в раздел <head> HTML-документа. Вот пример HTML-элемента <button> с атрибутом события, обеспечивающим реакцию на щелчки мышью. При нажатии кнопки генерируется событие onclick.
Внешний JavaScript
Если JavaScript-кода много – его выносят в отдельный файл, который, как правило, имеет расширение .js .
Чтобы включить в HTML-документ JavaScript-кoд из внешнего файла, нужно использовать атрибут src (source) тега <script> . Его значением должен быть URL-aдpec файла, в котором содержится JS-код:
В этом примере указан абсолютный путь к файлу с именем script.js, содержащему скрипт (из корня сайта). Сам файл должен содержать только JavaScript-кoд, который иначе располагался бы между тегами <script> и </script> .
По аналогии с элементом <img> атрибуту src элемента <script> можно назначить полный URL-aдpec, не относящийся к домену текущей НТМL-страницы:
На заметку: Подробнее о путях файлов читайте в разделе «Абсолютные и относительные ссылки».
Чтобы подключить несколько скриптов, используйте несколько тегов:
Примечание: Элемент <script> с атрибутом src не может содержать дополнительный JаvаSсriрt-код между тегами <script> и </script> , хотя внешний сценарий выполняется, встроенный код игнорируется.
Независимо от того, как JS-код включается в НТМL-документ, элементы <script> интерпретируются браузером в том порядке, в котором они расположены в HTML-документе. Сначала интерпретируется код первого элемента <script> , затем браузер приступает ко второму элементу <script> и т. д.
Внешние скрипты практичны, когда один и тот же код используется во многих разных веб-страницах. Браузер скачает js-файл один раз и в дальнейшем будет брать его из своего кеша, благодаря чему один и тот же скрипт, содержащий, к примеру, библиотеку функций, может использоваться на разных страницах без полной перезагрузки с сервера. Кроме этого, благодаря внешним скриптам, упрощается сопровождение кода, поскольку вносить изменения или исправлять ошибки приходится только в одном месте.
Примечание: Во внешние файлы копируется только JavaScript-код без указания открывающего и закрывающего тегов <script> и </script> .
Расположение тегов <script>
Вы уже знаете, что браузер читает HTML-документ сверху вниз и, начинает отображать страницу, показывая часть документа до тега <script> . Встретив тег <script> , переключается в JavaScript-режим и выполняет сценарий. Закончив выполнение, возвращается обратно в HTML-режим и отображает оставшуюся часть документа.
Если на странице используется много скриптов JavaScript, то могут возникнуть длительные задержки при загрузке, в течение которых пользователь видит пустое окно браузера. Поэтому считается хорошей практикой все ссылки нa javaScript-cцeнapии указывать после контента страницы перед закрывающим тегом <body> :
Такое расположение сценариев позволяет браузеру загружать страницу быстрее, так как сначала загрузится контент страницы, а потом будет загружаться код сценария.
Для пользователей это предпочтительнее, потому что страница полностью визуализируется в браузере до обработки JavaScript-кoдa.
Отложенные и асинхронные сценарии
Как отмечалось ранее, по умолчанию файлы JavaScript-кода прерывают синтаксический анализ (парсинг) HTML-документа до тех пор, пока скрипт не будет загружен и выполнен, тем самым увеличивая промежуток времени до первой отрисовки страницы.
Возьмём пример, в котором элемент <script> расположен где-то в середине страницы:
В этом примере, пока пока браузер не загрузит и не выполнит script.js, он не покажет часть страницы под ним. Такое поведение браузера называется «синхронным» и может доставить проблемы, если мы загружаем несколько JavaScript-файлов на странице, так как это увеличивает время её отрисовки.
А что, если HTML-документ на самом деле не зависит от этих JS-файлов, а разработчик желает контролировать то, как внешние файлы загружаются и выполняются?
Кардинально решить проблему загрузки скриптов помогут атрибуты async и defer элемента <script> .
Атрибут async
Async используется для того, чтобы указать браузеру, что скрипт может быть выполнен «асинхронно».
При обнаружении тега <script async src="https://wm-school.ru/js/"> браузер не останавливает обработку HTML-документа для загрузки и выполнения скрипта, выполнение может произойти после того, как скрипт будет получен параллельно с разбором документа. Когда скрипт будет загружен – он выполнится.
Для сценариев с атрибутом async не гарантируется выполнение скриптов в порядке их добавления, например:
В примере второй скрипт может быть выполнен перед первым, поэтому важно, чтобы между этими сценариями не было зависимостей.
Примечание: Атрибут async используется, если нужно разрешить браузеру продолжить загрузку страницы, не дожидаясь завершения загрузки и выполнения сценария.
Атрибут defer
Атрибут defer откладывает выполнение скрипта до тех пор, пока вся HTML-страница не будет загружена полностью.
Как и при асинхронной загрузке скриптов — JS-файл может быть загружен, в то время как HTML-документ ещё грузится. Однако, даже если скрипт будет полностью загружен ещё до того, как браузер закончит обработку страницы, он не будет выполнен до тех пор, пока HTML-документ не обработается до конца.
Несмотря на то, что в приведенном примере теги <script defer src="https://wm-school.ru/js/"> включены в элемент <head> HTML-документа, выполнение сценариев не начнется, пока браузер не дойдет до закрывающего тега </html> .
Кроме того, в отличие от async , относительный порядок выполнения скриптов с атрибутом defer будет сохранён.
Применение атрибута defer бывает полезным, когда в коде скрипта предусматривается работа с HTML-документом, и разработчик должен быть уверен, что страница полностью получена.
Примечание: Атрибуты async и defer поддерживаются только для внешних файлов сценариев, т.е. работают только при наличии атрибута src .
Итоги
- JavaScript можно добавить в HTML-документ с помощью элемента <script> двумя способами:
- Определить встроенный сценарий, который располагается непосредственно между парой тегов <script> и </script> .
- Подключить внешний файл с JavaScript-кодом через <script src="https://wm-school.ru/js/%D0%BF%D1%83%D1%82%D1%8C"></script> .
Задачи
Всплывающее окно
Перед вами простой HTML-документ. Разместите в теле НТМL-страницы сценарий, выводящий всплывающее окно с надписью: "Привет, javascript!"
Исследование различных веб-технологий, математических алгоритмов и проектирование веб-приложений.
Рубрики
Комменты
Каждый уважающий себя бот должен уметь извлекать любую информацию с сайта, например ссылки, заголовки, любой текст, номера телефонов, адреса электронной почты, картинки. В этом уроке мы рассмотрим несколько методов сбора данных на странице при помощи iMacros и Javascript.
Исходный код страницы
Пример:
![schema]()
DOM (Document Object Model) – объектная модель страницы
Основным инструментом работы и динамических изменений на странице является DOM (Document Object Model) – объектная модель, используемая для XML/HTML-документов. Согласно DOM-модели, документ является иерархией, деревом. Каждый HTML-тег образует узел дерева с типом «элемент». Вложенные в него теги становятся дочерними узлами. Для представления текста создаются узлы с типом «текст».
DOM – это представление страницы в виде дерева объектов, доступное для чтения и изменения через JavaScript.
При чтении неверного HTML браузер автоматически корректирует его для показа и при построении DOM. В частности, всегда будет верхний тег <html> . Даже если в тексте нет – в DOM он будет, браузер создаст его самостоятельно. То же самое касается и тега <body> . Например, если файл состоит из одного слова "Test" , то браузер автоматически обернёт его в <html> и <body> .
При генерации DOM браузер самостоятельно обрабатывает ошибки в документе, закрывает теги и делает все, чтобы корректно отобразить документ.
Методы извлечения информации из тегов средствами iMacros
![]()
Давайте приступим, я рекомендую вам сразу открыть эту ссылку в Firefox. Поскольку вам предстоит писать много кода, рекомендую первым делом поставить себе какой-нибудь редактор, например весьма распространенный Notepad++ или же мой любимый и в сто раз более удобный Sublime Text 3, я писал о плагинах для него и режиме Vim для быстрого и мощного редактирования.
Мы получим вот такой скрипт(Current.iim):
Давайте переделаем его в JS.
Создайте новый файл, например test.js. Допустим, нам необходимо получить содержимое тега "<H1>" . Переделаем макрос на js и извлечем из него содержимое тега "<H1>" .Результат(test.js):
Методы извлечения информации из тегов средствами Javascript
Код на JS(test.js):
Здесь мы использовали поиск элемента по тегу. На самом деле, метод querySelector принимает в качестве параметра любое выражение в формате css-правила. Еще важно знать, что querySelector возвращает только первый элемент из DOM-дерева, который совпал. Чтобы получить все элементы, подходящие под указанное правило, используйте querySelectorAll .
Приведу несколько примеров:
Давайте выведем все ссылки в консоль.
Тут мы видим набор элементов, а если быть точнее, то коллекцию узлов DOM-дерева. Квадратные скобки могут натолкнуть на мысль о том, что это обычный массив, но это не совсем так. Мы не сможем для такой коллекции использовать стандартные методы массива, такие, как .map(), .filter() и крайне удобный .forEach() . Поэтому для перебора и обработки элементов такой коллекции мы будем использовать классический цикл for .
В коллекции 6 элементов, вы можете нажать на любой и тогда откроется инспектор DOM-дерева и вы увидите элемент, на который нажали.
![iMacros js тестовая страница]()
Хоть это и неполноценный массив, но нам все равно доступно свойство length . Давайте посчитаем количество ссылок в коллекции и выведем для каждой ссылки заголовок и адрес, куда она ссылается. В JS есть несколько вариантов реализации циклов, мы пока используем самый простой for .
Выводим все ссылки на странице и информацию о них:
Этот код покажет в консоли количество найденных элементов и выведет информацию о каждой ссылке на странице. Это базовый пример, позже вы научитесь создавать, изменять, фильтровать массивы полученной информации, сохранять в каком угодно виде и разумеется считывать из файлов и использовать данные в своих программах.
Помимо получения значений аттрибутов при помощи метода getAttribute() , текста внутри тега при помощи innerHTML, мы можем делать разные другие вещи. Чтобы посмотреть доступные методы, вы можете поискать в документации по JS, или воспользоваться автокомплитом из консоли, попробуйте вручную ввести window.document.querySelectorAll("a")[0]. или window.document.querySelector("a"). , что будет равнозначно, и после ввода точки появится список поддерживаемых методов и свойств, более подробно о каждом свойстве или методе вы легко найдете в гугле. Подобным образом вы сможете исследовать методы и свойства любого объекта.
И еще, вы можете указывать несколько селекторов через запятую, например window.document.querySelectorAll("a, .styled")![imacros css selector]()
Также, для мощного поиска по тексту веб-страницы, можно использовать регулярные выражения, инструмент невиданной силы и мощи, который заслуживает отдельной книги страниц на 600, о нем я расскажу в следующих уроках.
Необходимые условия: Основы JavaScript (см. первые шаги, структурные элементы, объекты JavaScript), основы клиентских API Задача: Узнать, как извлекать данные с сервера и использовать их для обновления содержимого веб-страницы. В чем проблема?
Первоначальная загрузка страницы в Интернете была простой - вы отправляли запрос на сервер web-сайта, и если всё работает, как и должно, то вся необходимая информация о странице будет загружена и отображена на вашем компьютере.
![A basic representation of a web site architecture]()
Проблема с этой моделью заключается в том, что всякий раз, когда вы хотите обновить любую часть страницы, например, чтобы отобразить новый набор продуктов или загрузить новую страницу, вам нужно снова загрузить всю страницу. Это очень расточительно и приводит к плохому пользовательскому опыту, особенно по мере того, как страницы становятся все более сложными.
Появление Ajax
Это привело к созданию технологий, позволяющих веб-страницам запрашивать небольшие фрагменты данных (например, HTML, XML, JSON или обычный текст) и отображать их только при необходимости, помогая решать проблему, описанную выше.
![A simple modern architecture for web sites]()
Модель Ajax предполагает использование веб-API в качестве прокси для более разумного запроса данных, а не просто для того, чтобы браузер перезагружал всю страницу. Давайте подумаем о значении этого:
- Перейдите на один из ваших любимых сайтов, богатых информацией, таких как Amazon, YouTube, CNN и т.д., и загрузите его.
- Теперь найдите что-нибудь, например, новый продукт. Основной контент изменится, но большая часть информации, подобной заголовку, нижнему колонтитулу, навигационному меню и т. д., останется неизменной.
Это действительно хорошо, потому что:
- Обновления страницы намного быстрее, и вам не нужно ждать перезагрузки страницы, а это означает, что сайт работает быстрее и воспринимается более отзывчивым.
- Меньше данных загружается при каждом обновлении, что означает меньшее потребление пропускной способности. Это не может быть такой большой проблемой на рабочем столе в широкополосном подключении, но это серьёзная проблема на мобильных устройствах и в развивающихся странах, которые не имеют повсеместного быстрого интернет-сервиса.
Чтобы ускорить работу, некоторые сайты также сохраняют необходимые файлы и данные на компьютере пользователя при первом обращении к сайту, а это означает, что при последующих посещениях они используют локальные версии вместо загрузки свежих копий, как при первой загрузке страницы. Содержимое загружается с сервера только при его обновлении.
![A basic web app data flow architecture]()
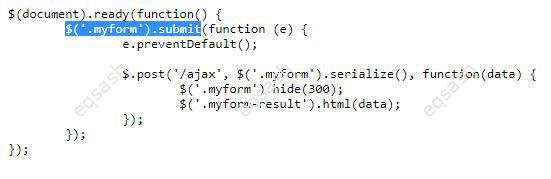
Основной запрос Ajax
Этот набор файлов будет действовать как наша поддельная база данных; в реальном приложении мы с большей вероятностью будем использовать серверный язык, такой как PHP, Python или Node, чтобы запрашивать наши данные из базы данных. Здесь, однако, мы хотим сохранить его простым и сосредоточиться на стороне клиента.
Чтобы начать этот пример, создайте локальную копию ajax-start.html и четырёх текстовых файлов - verse1.txt, verse2.txt, verse3.txt и verse4.txt - в новом каталоге на вашем компьютере. В этом примере мы загрузим другое стихотворение (который вы вполне можете распознать) через XHR, когда он будет выбран в выпадающем меню.
Внутри элемента <script> добавьте следующий код. В нем хранится ссылка на элементы <select> и <pre> в переменных и определяется onchange обработчика событий, так что, когда значение select изменяется, его значение передаётся вызываемой функции updateDisplay() в качестве параметра.
Давайте определим нашу функцию updateDisplay() . Прежде всего, поставьте следующее ниже своего предыдущего блока кода - это пустая оболочка функции:
Мы начнём нашу функцию с создания относительного URL-адреса, указывающего на текстовый файл, который мы хотим загрузить и который понадобится нам позже. Значение элемента <select> в любой момент совпадает с текстом внутри выбранного <option> (если вы не укажете другое значение в атрибуте value) - например, «Verse 1». Соответствующий текстовый файл стиха является «verse1.txt» и находится в том же каталоге, что и файл HTML, поэтому будет использоваться только имя файла.
Тем не менее, веб-серверы, как правило, чувствительны к регистру, и имя файла не имеет символа "пробела". Чтобы преобразовать «Verse 1» в «verse1.txt», нам нужно преобразовать V в нижний регистр, удалить пробел и добавить .txt в конец. Это можно сделать с помощью replace () , toLowerCase () и простой конкатенации строк. Добавьте следующие строки внутри функции updateDisplay() :
Затем мы зададим тип ожидаемого ответа, который определяется как свойство responseType - как text . Здесь это не является абсолютно необходимым - XHR возвращает текст по умолчанию - но это хорошая идея, чтобы привыкнуть к настройке этого, если вы хотите получить другие типы данных в будущем. Добавьте следующее:
Получение ресурса из сети - это asynchronous операция, означающая, что вам нужно дождаться завершения этой операции (например, ресурс возвращается из сети), прежде чем вы сможете сделать что-либо с этим ответом, иначе будет выброшена ошибка. XHR позволяет вам обрабатывать это, используя обработчик события onload - он запускается при возникновении события load (en-US) (когда ответ вернулся). Когда это произойдёт, данные ответа будут доступны в свойстве response (ответ) объекта запроса XHR.
Добавьте следующее ниже вашего последнего дополнения. Вы увидите, что внутри обработчика события onload мы устанавливаем textContent poemDisplay (элемент <pre> ) в значение request. response .
Вышеприведённая конфигурация запроса XHR фактически не будет выполняться до тех пор, пока мы не вызовем метод send() . Добавьте следующее ниже вашего предыдущего дополнения для вызова функции:
Обслуживание вашего примера с сервера
Некоторые браузеры (включая Chrome) не будут запускать запросы XHR, если вы просто запускаете пример из локального файла. Это связано с ограничениями безопасности (для получения дополнительной информации о безопасности в Интернете, ознакомьтесь с Website security).
Чтобы обойти это, нам нужно протестировать пример, запустив его через локальный веб-сервер. Чтобы узнать, как это сделать, прочитайте Как настроить локальный тестовый сервер?
Fetch
Давайте преобразуем последний пример, чтобы использовать Fetch!
Сделайте копию своего предыдущего готового каталога примеров. (Если вы не работали над предыдущим упражнением, создайте новый каталог и внутри него создайте копии xhr-basic.html и четырёх текстовых файлов — verse1.txt, verse2.txt, verse3.txt и verse4.txt.)
Внутри функции updateDisplay() найдите код XHR:
Замените весь XHR-код следующим:
Загрузите пример в свой браузер (запустите его через веб-сервер), и он должен работать так же, как и версия XHR, при условии, что вы используете современный браузер.
Итак, что происходит в коде Fetch?
Прежде всего, мы вызываем метод fetch() , передавая ему URL-адрес ресурса, который мы хотим получить. Это современный эквивалент request.open() в XHR, плюс вам не нужен эквивалент .send() .
После этого вы можете увидеть метод .then() , прикреплённый в конец fetch() - этот метод является частью Promises - современная функция JavaScript для выполнения асинхронных операций. fetch() возвращает промис, который разрешает ответ, отправленный обратно с сервера, - мы используем .then() для запуска некоторого последующего кода после того, как промис будет разрешено, что является функцией, которую мы определили внутри неё. Это эквивалент обработчика события onload в XHR-версии.
Эта функция автоматически передаёт ответ от сервера в качестве параметра, когда обещает fetch() . Внутри функции мы берём ответ и запускаем его метод text() (en-US) , который в основном возвращает ответ как необработанный текст. Это эквивалент request.responseType = 'text' в версии XHR.
Вы увидите, что text() также возвращает промис, поэтому мы привязываем к нему другой .then() , внутри которого мы определяем функцию для получения необработанного текста, который выполняет text() .
Внутри функции внутреннего промиса мы делаем то же самое, что и в версии XHR, - устанавливаем текстовое содержимое <pre> в текстовое значение.
Помимо промисов
Промисы немного запутывают первый раз, когда вы их встречаете, но не беспокойтесь об этом слишком долго. Через некоторое время вы привыкнете к ним, особенно, когда вы узнаете больше о современных JavaScript-API. Большинство из них в большей степени основаны на промисах.
Давайте посмотрим на структуру промисов сверху, чтобы увидеть, можем ли мы ещё немного понять это:
Фактически, функция, переданная в then() , представляет собой кусок кода, который не запускается немедленно - вместо этого он будет работать в какой-то момент в будущем, когда ответ будет возвращён. Обратите внимание, что вы также можете сохранить своё промис в переменной и цепочку .then() вместо этого. Ниже код будет делать то же самое:
Но имеет смысл называть параметр тем, что описывает его содержимое!
Теперь давайте сосредоточимся только на функции:
Объект ответа имеет метод text() (en-US) , который берёт необработанные данные, содержащиеся в теле ответа, и превращает его в обычный текст, который является форматом, который мы хотим в нем А также возвращает промис (который разрешает полученную текстовую строку), поэтому здесь мы используем другой .then() , внутри которого мы определяем другую функцию, которая диктует что мы хотим сделать с этой текстовой строкой. Мы просто устанавливаем свойство textContent элемента <pre> нашего стихотворения равным текстовой строке, так что это получается довольно просто.
Также стоит отметить, что вы можете напрямую связывать несколько блоков промисов ( .then() , но есть и другие типы) на конце друг друга, передавая результат каждого блока следующему блоку по мере продвижения по цепочке , Это делает промисы очень мощными.
Следующий блок делает то же самое, что и наш оригинальный пример, но написан в другом стиле:
Многие разработчики любят этот стиль больше, поскольку он более плоский и, возможно, легче читать для более длинных цепочек промисов - каждое последующее промис приходит после предыдущего, а не внутри предыдущего (что может стать громоздким). Единственное отличие состоит в том, что мы должны были включить оператор return перед response.text() , чтобы заставить его передать результат в следующую ссылку в цепочке.
Какой механизм следует использовать?
Это действительно зависит от того, над каким проектом вы работаете. XHR существует уже давно и имеет отличную кросс-браузерную поддержку. Fetch and Promises, с другой стороны, являются более поздним дополнением к веб-платформе, хотя они хорошо поддерживаются в браузере, за исключением Internet Explorer и Safari (которые на момент написания Fetch были доступны в своём предварительный просмотр технологии).
Если вам необходимо поддерживать старые браузеры, тогда может быть предпочтительным решение XHR. Если, однако, вы работаете над более прогрессивным проектом и не так обеспокоены старыми браузерами, то Fetch может быть хорошим выбором.
Вам действительно нужно учиться - Fetch станет более популярным, так как Internet Explorer отказывается от использования (IE больше не разрабатывается, в пользу нового браузера Microsoft Edge), но вам может понадобиться XHR ещё некоторое время.
Более сложный пример
Чтобы завершить статью, мы рассмотрим несколько более сложный пример, который показывает более интересные применения Fetch. Мы создали образец сайта под названием The Can Store - это вымышленный супермаркет, который продаёт только консервы. Вы можете найти этот пример в прямом эфире на GitHub и посмотреть исходный код.
![A fake ecommerce site showing search options in the left hand column, and product search results in the right hand column.]()
По умолчанию на сайте отображаются все продукты, но вы можете использовать элементы управления формы в столбце слева, чтобы отфильтровать их по категориям, поисковому запросу или и тому и другому.
Существует довольно много сложного кода, который включает фильтрацию продуктов по категориям и поисковым запросам, манипулирование строками, чтобы данные отображались правильно в пользовательском интерфейсе и т.д. Мы не будем обсуждать все это в статье, но вы можете найти обширные комментарии в коде (см. can-script.js).
Однако мы объясним код Fetch.
Первый блок, который использует Fetch, можно найти в начале JavaScript:
Это похоже на то, что мы видели раньше, за исключением того, что второй промис находится в условном выражении. В этом случае мы проверяем, был ли возвращённый ответ успешным - свойство response.ok (en-US) содержит логическое значение, которое true , если ответ был в порядке (например, 200 meaning "OK") или false , если он не увенчался успехом.
Если ответ был успешным, мы выполняем второй промис - на этот раз мы используем json() (en-US) , а не text() (en-US) , так как мы хотим вернуть наш ответ как структурированные данные JSON, а не обычный текст.
Вы можете проверить сам случай отказа:
Второй блок Fetch можно найти внутри функции fetchBlob() :
Это работает во многом так же, как и предыдущий, за исключением того, что вместо использования json() (en-US) мы используем blob() (en-US) - в этом случае мы хотим вернуть наш ответ в виде файла изображения, а формат данных, который мы используем для этого - Blob - этот термин является аббревиатурой от« Binary Large Object »и может в основном использоваться для представляют собой большие файловые объекты, такие как изображения или видеофайлы.
После того как мы успешно получили наш blob, мы создаём URL-адрес объекта, используя createObjectURL() . Это возвращает временный внутренний URL-адрес, указывающий на объект, указанный в браузере. Они не очень читаемы, но вы можете видеть, как выглядит, открывая приложение Can Store, Ctrl-/щёлкнуть правой кнопкой мыши по изображению и выбрать опцию «Просмотр изображения» (которая может немного отличаться в зависимости от того, какой браузер вы ). URL-адрес объекта будет отображаться внутри адресной строки и должен выглядеть примерно так:
Вызов: XHR версия the Can Store
Мы хотели бы, чтобы вы решили преобразовать версию приложения Fetch для использования XHR в качестве полезной части практики. Возьмите копию ZIP файла и попробуйте изменить JavaScript, если это необходимо.
Некоторые полезные советы:
Примечание: Если у вас есть проблемы с этим, не стесняйтесь сравнить свой код с готовой версией на GitHub (см. исходник здесь, а также см. это в действии).
Резюме
Это завершает нашу статью по извлечению данных с сервера. К этому моменту вы должны иметь представление о том, как начать работать как с XHR, так и с Fetch.
Смотрите также
Однако в этой статье обсуждается много разных тем, которые только поцарапали поверхность. Для получения более подробной информации по этим темам, попробуйте следующие статьи:
Читайте также:







