
Как остановить процессы в кэше
Обновлено: 03.07.2024
Многие пользователи часто думают, что со временем их смартфон просто испортился и поэтому перестал держать заряд, начал медленнее работать и чаще зависать. Конечно, небольшой износ у смартфонов действительно есть, но он не оказывает такого влияния, как сам пользователь. Особенно это относится к устройствам на Android. Именно они с годами обрастают фоновыми приложениями, расширениями и прочей чешуей, которая оказывает куда большее влияние на гаджет, чем просто старение плат.
Видео
Когда чистить кэш
Чистить его каждый день или раз в неделю не надо. Во-первых, это энергозатратно и долго. Во-вторых, кэш все равно начнет сразу же собираться заново. В-третьих, это будет тормозить работу приложений.
Нужно найти баланс, когда вы точно будете понимать, что медленная работа смартфона в целом — избыток кэша, а не что-то еще. Чистить кэш стоит раз в 3-6 месяцев, не чаще, и нужно быть готовым к тому, что пару дней приложения будут работать дольше. Все же вы сбросите всю информацию, которая их ускоряла, нужно время, чтобы восстановить ее. Так вы освежите устройство, избавитесь от лишнего и соберете только то, что нужно.
Расположение и использование
Временные файлы находятся в специальных папках на устройстве или карте памяти. Полностью удалять их нельзя, поскольку сотрутся важные для нормальной работы смартфона объекты. Располагаются временные файлы в папке data и obb. В первой они имеют вид файлов, а во второй – архивов. При установке каждое приложение создает папку с таким же названием и наполняет ее временными файлами, которые увеличивают скорость загрузки уже просмотренных страниц.

Ограничьте фоновые процессы
Большинство Android-приложений при закрытии продолжают работать в фоновом режиме, потребляя энергию и системные ресурсы. Вы можете ограничить число программ, способных работать в фоне. Делается это в меню разработчика, которое по умолчанию скрыто от пользователя.
- Для того, чтобы активировать меню разработчика, зайдите в настройки, выберите пункт «Об устройстве», и пролистайте вниз до пункта «Номер сборки». Теперь быстро нажмите семь раз подряд на этот пункт.

- После этого в настройках появится раздел «Параметры разработчика». Откройте его. Найдите пункт «Ограничить фоновые процессы», и установите значение «не более 3 процессов».
Как убрать ненужные фоновые процессы
Итак, самый простой способ – это ограничение фоновых процессов через настройки вашего девайса. Это делается в разделе настроек «Для разработчиков». Но просто так вы ее не отыщете.

Чтобы раздел «Для разработчиков» стал видным, необходимо проследовать во вкладку «О телефоне», после чего несколько раз нажать на «Номер сборки» или «Версия прошивки»
После того, как раздел появился, переходим к выполнению пошаговой инструкции:
- Посещаем вкладку «Для разработчиков».
- Ищем строку «Лимит фоновых процессов (или служб)», нажимаем на нее.
- Во всплывающем окне выставляем ограничение. Как показывает практика, для корректной работы смартфона требуется поставить отметку не меньше двух фоновых процессов. Запретив все фоновые процессы, вы рискуете получить множество ошибок вместо ускорения работы гаджета.
- Сворачиваем настройки для сохранения изменений.
Кэширование и окончательная согласованность
Чтобы шаблон "Отдельно от кэша" работал, экземпляр приложения, который заполняет кэш, должен иметь доступ к самым актуальным и согласованным данным. В системе, которая реализует окончательную согласованность (реплицируемое хранилище данных), это может быть не так.
Один экземпляр приложения может изменить элемент данных и сделать кэшированную версию этого элемента недействительной. Другой экземпляр приложения может попытаться прочитать этот элемент из кэша, что приведет к промаху кэша, поэтому он считает данные из хранилища данных и добавит их в кэш. Тем не менее, если хранилище данных не было полностью синхронизировано с другими репликами, экземпляр приложения может считать данные и заполнить кэш старым значением.
Защита кэшированных данных
Независимо от используемой службы кэша следует рассмотреть вопрос защиты данных, хранящихся в кэше, от несанкционированного доступа. Существуют две основные проблемы.
- Конфиденциальность данных в кэше.
- Конфиденциальность данных в процессе их передачи между кэшем и приложением, в котором используется этот кэш.
Для защиты данных в кэше служба кэша может реализовать механизм проверки подлинности, который требует от приложений указывать следующие моменты:
- какие удостоверения могут обращаться к данным в кэше;
- какие операции (чтение и запись) разрешено выполнять этим удостоверениям.
Чтобы снизить издержки, связанные с чтением и записью данных, после того как удостоверению был предоставлен доступ к записи или чтению в кэш, удостоверение может использовать любые данные в кэше.
Если требуется ограничить доступ к подмножествам кэшированных данных, можно сделать следующее:
- Разбить кэш на секции (с помощью различных серверов кэширования) и предоставить доступ удостоверениям только к тем секциям, которые они должны использовать.
- Зашифровать данные в каждом подмножестве с помощью различных ключей и предоставить ключи шифрования только тем удостоверениям, которые должны иметь доступ к каждому подмножеству. Клиентское приложение по-прежнему сможет получить все данные в кэше, но при этом расшифровать только те данные, для которых имеются ключи.
Способы очистки
На смартфонах с версией Android 8.0 Oreo и выше нет функции очистки кэша, разработчики решили удалить эту возможность. В таких устройствах система автоматически управляет данными. Когда у какого-то приложения превышена установленная квота, то стирается промежуточный буфер. Пользователи могут не беспокоиться об этом вопросе.
В остальных случаях придется выполнять очистку вручную или с помощью профильной программы.
Ручная очистка
Дать универсальную инструкцию не получится, поскольку особенности настроек зависят от версии операционной системы. Мы расскажем про общие правила, которые стоит соблюдать:

- Зайдите в настройки и найдите раздел «Хранилище». В нем предоставляется информация о том, сколько памяти занято и чем именно.
- Перейдите в раздел с приложениями, отсортируйте их по размеру.
- Зайдите внутрь самых тяжелых, найдите кнопку «Очистить кэш».
Clean Master
Если вы не хотите заходить в каждое приложение, то можно воспользоваться специальной программой, которая выполняет комплексную очистку. Алгоритм действий:
- Скачайте Clean Master в Плей Маркете.
- Откройте программу и перейдите в раздел «Мусор».
- Приложение начнет анализировать информацию и искать доступные для удаления файлы. Дождитесь завершения процесса.
- На экране появится общий размер файлов доступных для удаления. Проследите, чтобы напротив строки «Ненужный кэш» стояла галочка.
- Нажмите зеленую кнопку внизу экрана, начнется очистка.
Приложение работает бесплатно, но при этом его функционал ограничен. В платной версии есть возможности для оптимизации основных процессов, охлаждения смартфона, анализа всех приложений и того, как они влияют на устройство.
Есть и другие аналоги, которые справляются со своей задачей. Например, OneBooster, Avast Cleanup, AVG Cleaner, SD Maid. Они имеют схожий функционал и минимальные отличия. Все устанавливаются бесплатно, поэтому можно протестировать несколько приложений и понаблюдать за тем, как работает устройство, после чего сделать выбор.

У всех подобных приложений есть минус – использование системных ресурсов. Поэтому, несмотря на то, что они ускоряют некоторые процессы и выполняют комплексные действия, замедление устройства тоже происходит.
Очистка кэша и данных на Android-устройствах
Часто мы называем очистку данных и кэша одним и тем же, но это два разных действия.
Данные — то, что вы сами осознанно сохранили. Это могут быть видео, музыка, карты или что-то еще, но суть именно в том, что вы сами это сохранили. Если вы очистите только кэш — приложение будет выглядеть, как сразу после установки, но с сохраненными данными. Если вы удалите и эту информацию — приложение будет абсолютно пустым, собирать данные придется заново.
Опасно ли останавливать фоновые процессы Android
В системе есть ”защита от дурака” и остановить что-то, что действительно может привести к критической ошибке, скорее всего, не получится, но испытывать судьбу не стоит.
Чтобы остановить процесс, надо будет открыть выбранное приложение и нажать ”остановить”. Все просто.
7 крутых виджетов для Android, которые я советую попробовать
Если вы сомневаетесь или просто не хотите останавливать процессы из этого меню, можно зайти в другое место. Откройте ”Настройка”, далее ”Приложения”, после этого откройте список приложений и нажмите в правом верхнем углу значок с тремя точками. Там выберите ”Показать системные процессы”.
На смартфоне изначально установлено не так много приложений, поэтому устройство работает довольно-таки быстро. Но со временем, когда сторонних программ появляется немного больше, может быть заметна нехватка оперативной памяти. Например, когда вы только свернули запущенную утилиту, а при повторном открытии она уже перезагрузилась. Причина подобной проблемы – слишком большое количество фоновых процессов. Вы даже можете не знать, сколько приложений на самом деле незаметно работают и расходуют ресурсы смартфона. Ну что же, давайте разбираться, что такое кэшированный фоновый процесс в Андроиде и как закрыть постоянно работающие программы.
Что такое кэшированный фоновый процесс?
Как известно, определенные данные приложений могут сохраняться в кэше. Если мы будем рассматривать какую-то социальную сеть, то сюда относятся фотографии и различные иконки. При повторном открытии программы конкретные элементы будут загружаться автоматически, так как они уже были заранее сохранены в кэше. Благодаря этому интерфейс работает быстрее, а нагрузка на компоненты смартфона снижается.
Как отключить фоновые процессы?
Проще всего ограничить фоновые процессы через настройки смартфона, а точнее – скрытый раздел «Для разработчиков». Для того, чтобы эта вкладка стала заметной, необходимо перейти в меню «О телефоне», а затем несколько раз нажать по пункту «Версия прошивки» или «Номер сборки». Раздел появился? Отлично, значит теперь переходим к пошаговой инструкции:
- Заходим во вкладку «Для разработчиков».
- Находим пункт «Лимит фоновых процессов» или «Лимит фоновых служб» и нажимаем по нему.
- В выпадающем меню выставляем нужное ограничение. Как правило, для корректной работы устройства желательно выбирать не менее двух фоновых процессов. Если вы вообще запретите любые службы в фоне, то это может привести только к сбоям и ошибкам, но никак не к ускорению смартфона.
- Для сохранения изменений сворачиваем настройки.
Ещё вы можете пойти другим путем, ограничив работу конкретных фоновых приложений. Чтобы узнать, какие это программы, в разделе «Для разработчиков» откройте вкладку «Статистика процессов». Вы можете остановить практически любой сторонний софт, и это никак не отразится на работе смартфона. Вот, кстати, пошаговая инструкция:
- Переходим в настройки.
- Открываем вкладку «Приложения».
- Переходим на страницу с конкретной программой, деятельность которой нужно ограничить.
- В нижней части экрана выбираем «Закрыть» или «Остановить».
- Просматриваем возможные последствия, а затем подтверждаем действия, выбрав «Ок».
В принципе, на современных телефонах с достаточным объемом оперативной памяти ограничивать фоновые процессы смысла нет. Особого прироста производительности вы не заметите.
Итак, мы рассмотрели, что такое кэшированный фоновый процесс в Андроиде и как отключить постоянно работающие приложения. Если остались вопросы или замечания, то обязательно пишите об этом в комментариях!
У большинства людей в наше время имеется невероятно удобный и практичный гаджет. Речь идет, конечно же, о смартфоне. Он не занимает много места, способен поместиться в кармане или миниатюрной сумочке, но при этом выполняет роль настоящего персонального компьютера.
В первое время после покупки девайса, он работает хорошо и быстро. Дело в том, что изначально на смартфоне установлено минимум приложений.
С течением времени телефон «обрастает» сторонними программами и это иногда приводит к сильной загруженности оперативной памяти
И, как следствие, к замедлению работы аппарата. Почему так происходит и как с этим бороться – сегодня и поговорим.
Всему виной большое количество фоновых процессов
Если на смартфоне установлено слишком много приложений, это может существенно тормозить его работу.
Иногда случается так, что когда вы сворачиваете запущенную утилиту, а потом раскрываете ее – приложение перезапускается. Причина такого положения дел, скорее всего, кроется в наличии слишком большого количества фоновых процессов. Остановив некоторые из них, вы сможете ускорить работу своего девайса.
Юрий Петренко, IT-специалист

Самое время разобраться в том, что такое кэшированный фоновый процесс в Андроиде, и как с ним бороться – как закрыть все время работающие и отнимающие ресурсы смартфона программы.
Что собой представляет кэшированный фоновый процесс
Те, кто хотя бы немного интересуется данной темой, знают, что некоторые данные приложений могут храниться в так называемом кэше. К примеру, если речь идет о социальных сетях, то там будут сохраняться фотографии и всевозможные иконки.
Когда программа будет запущена повторно, некоторые элементы загрузятся в автоматическом режиме. А все потому, что ранее они уже были сохранены в кэше.

Благодаря вышеуказанной «функции», страницы грузятся быстрее, а нагрузка на компоненты гаджета заметно снижаются

Следует помнить, что принудительное завершение некоторых процессов может привести к появлению нежелательных ошибок
В то же время в фоновом режиме могут быть запущены и многие ненужные программы, которые лишь отнимают ресурсы смартфона.
Теперь давайте разберемся, каким образом мы можем убрать некоторые процессы из фона без вреда для нашего гаджета.
Как убрать ненужные фоновые процессы
Итак, самый простой способ – это ограничение фоновых процессов через настройки вашего девайса. Это делается в разделе настроек «Для разработчиков». Но просто так вы ее не отыщете.
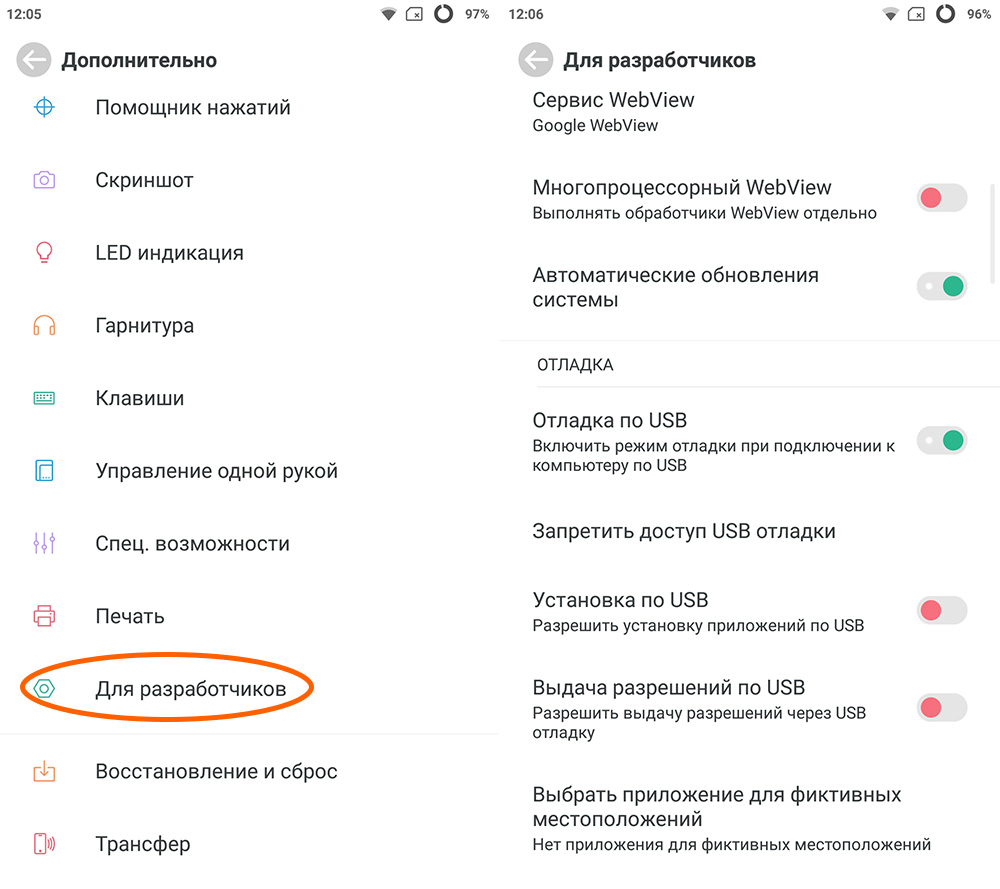
Чтобы раздел «Для разработчиков» стал видным, необходимо проследовать во вкладку «О телефоне», после чего несколько раз нажать на «Номер сборки» или «Версия прошивки»
После того, как раздел появился, переходим к выполнению пошаговой инструкции:
- Посещаем вкладку «Для разработчиков».
- Ищем строку «Лимит фоновых процессов (или служб)», нажимаем на нее.
- Во всплывающем окне выставляем ограничение. Как показывает практика, для корректной работы смартфона требуется поставить отметку не меньше двух фоновых процессов. Запретив все фоновые процессы, вы рискуете получить множество ошибок вместо ускорения работы гаджета.
- Сворачиваем настройки для сохранения изменений.
Запрещаем фоновую работу конкретных приложений
Также мы можем ограничить фоновое функционирование каких-то конкретных программ. Идем в «Настройки», открываем «Приложения», находим требуемое приложение, внизу выбирает «Остановить». Подтверждаем кнопочкой «Ок».
Меня зовут Виктор Пряжников, я работаю в SRV-команде Badoo. Наша команда занимается разработкой и поддержкой внутреннего API для наших клиентов со стороны сервера, и кэширование данных — это то, с чем мы сталкиваемся каждый день.
Существует мнение, что в программировании есть только две по-настоящему сложные задачи: придумывание названий и инвалидация кэша. Я не буду спорить с тем, что инвалидация — это сложно, но мне кажется, что кэширование — довольно хитрая вещь даже без учёта инвалидации. Есть много вещей, о которых следует подумать, прежде чем начинать использовать кэш. В этой статье я попробую сформулировать некоторые проблемы, с которыми можно столкнуться при работе с кэшем в большой системе.

Я расскажу о проблемах разделения кэшируемых данных между серверами, параллельных обновлениях данных, «холодном старте» и работе системы со сбоями. Также я опишу возможные способы решения этих проблем и приведу ссылки на материалы, где эти темы освещены более подробно. Я не буду рассказывать, что такое кэш в принципе и касаться деталей реализации конкретных систем.
При работе я исхожу из того, что рассматриваемая система состоит из приложения, базы данных и кэша для данных. Вместо базы данных может использоваться любой другой источник (например, какой-то микросервис или внешний API).
Деление данных между кэширующими серверами
Если вы хотите использовать кэширование в достаточно большой системе, нужно позаботиться о том, чтобы можно было поделить кэшируемые данные между доступными серверами. Это необходимо по нескольким причинам:
- данных может быть очень много, и они физически не поместятся в память одного сервера;
- данные могут запрашиваться очень часто, и один сервер не в состоянии обработать все эти запросы;
- вы хотите сделать кэширование более надёжным. Если у вас только один кэширующий сервер, то при его падении вся система останется без кэша, что может резко увеличить нагрузку на базу данных.
Есть разные алгоритмы для реализации этого. Самый простой — вычисление номера сервера как остатка от целочисленного деления численного представления ключа (например, CRC32) на количество кэширующих серверов:
Такой алгоритм называется хешированием по модулю (англ. modulo hashing). CRC32 здесь использован в качестве примера. Вместо него можно взять любую другую хеширующую функцию, из результатов которой можно получить число, большее или равное количеству серверов, с более-менее равномерно распределённым результатом.
Этот способ легко понять и реализовать, он достаточно равномерно распределяет данные между серверами, но у него есть серьёзный недостаток: при изменении количества серверов (из-за технических проблем или при добавлении новых) значительная часть кэша теряется, поскольку для ключей меняется остаток от деления.
Я написал небольшой скрипт, который продемонстрирует эту проблему.
В нём генерируется 1 млн уникальных ключей, распределённых по пяти серверам с помощью хеширования по модулю и CRC32. Я эмулирую выход из строя одного из серверов и перераспределение данных по четырём оставшимся.
В результате этого «сбоя» примерно 80% ключей изменят своё местоположение, то есть окажутся недоступными для последующего чтения:
Total keys count: 1000000
Shards count range: 4, 5
| ShardsBefore | ShardsAfter | LostKeysPercent | LostKeys |
|---|---|---|---|
| 5 | 4 | 80.03% | 800345 |
Самое неприятное тут то, что 80% — это далеко не предел. С увеличением количества серверов процент потери кэша будет расти и дальше. Единственное исключение — это кратные изменения (с двух до четырёх, с девяти до трёх и т. п.), при которых потери будут меньше обычного, но в любом случае не менее половины от имеющегося кэша:

Я выложил на GitHub скрипт, с помощью которого я собрал данные, а также ipynb-файл, рисующий данную таблицу, и файлы с данными.
Для решения этой проблемы есть другой алгоритм разбивки — согласованное хеширование (англ. consistent hashing). Основная идея этого механизма очень простая: здесь добавляется дополнительное отображение ключей на слоты, количество которых заметно превышает количество серверов (их могут быть тысячи и даже больше). Сами слоты, в свою очередь, каким-то образом распределяются по серверам.
При изменении количества серверов количество слотов не меняется, но меняется распределение слотов между этими серверами:
- если один из серверов выходит из строя, то все слоты, которые к нему относились, распределяются между оставшимися;
- если добавляется новый сервер, то ему передаётся часть слотов от уже имеющихся серверов.

На картинке начального разбиения все слоты одного сервера расположены подряд, но в реальности это не обязательное условие — они могут быть расположены как угодно.
Основное преимущество этого способа перед предыдущим заключается в том, что здесь каждому серверу соответствует не одно значение, а целый диапазон, и при изменении количества серверов между ними перераспределяется гораздо меньшая часть ключей ( k / N , где k — общее количество ключей, а N — количество серверов).
Если вернуться к сценарию, который я использовал для демонстрации недостатка хеширования по модулю, то при той же ситуации с падением одного из пяти серверов (с одинаковым весом) и перераспределением ключей с него между оставшимися мы потерям не 80% кэша, а только 20%. Если считать, что изначально все данные находятся в кэше и все они будут запрошены, то эта разница означает, что при согласованном хешировании мы получим в четыре раза меньше запросов к базе данных.
Код, реализующий этот алгоритм, будет сложнее, чем код предыдущего, поэтому я не буду его приводить в статье. При желании его легко можно найти — на GitHub есть rendezvous hashing), но они гораздо менее распространены.
Вне зависимости от выбранного алгоритма выбор сервера на основе хеша ключа может работать плохо. Обычно в кэше находится не набор однотипных данных, а большое количество разнородных: кэшированные значения занимают разное место в памяти, запрашиваются с разной частотой, имеют разное время генерации, разную частоту обновлений и разное время жизни. При использовании хеширования вы не можете управлять тем, куда именно попадёт ключ, и в результате может получиться «перекос» как в объёме хранимых данных, так и в количестве запросов к ним, из-за чего поведение разных кэширующих серверов будет сильно различаться.
Чтобы решить эту проблему, необходимо «размазать» ключи так, чтобы разнородные данные были распределены между серверами более-менее однородно. Для этого для выбора сервера нужно использовать не ключ, а какой-то другой параметр, к которому нужно будет применить один из описанных подходов. Нельзя сказать, что это будет за параметр, поскольку это зависит от вашей модели данных.
В нашем случае почти все кэшируемые данные относятся к одному пользователю, поэтому мы используем User ID в качестве параметра шардирования данных в кэше. Благодаря этому у нас получается распределить данные более-менее равномерно. Кроме того, мы получаем бонус — возможность использования multi_get для загрузки сразу нескольких разных ключей с информацией о юзере (что мы используем в предзагрузке часто используемых данных для текущего пользователя). Если бы положение каждого ключа определялось динамически, то невозможно было бы использовать multi_get при таком сценарии, так как не было бы гарантии, что все запрашиваемые ключи относятся к одному серверу.
Параллельные запросы на обновление данных
Посмотрите на такой простой кусочек кода:
Что произойдёт при отсутствии запрашиваемых данных в кэше? Судя по коду, должен запуститься механизм, который достанет эти данные. Если код выполняется только в один поток, то всё будет хорошо: данные будут загружены, помещены в кэш и при следующем запросе взяты уже оттуда. А вот при работе в несколько параллельных потоков всё будет иначе: загрузка данных будет происходить не один раз, а несколько.
Выглядеть это будет примерно так:

На момент начала обработки запроса в процессе №2 данных в кэше ещё нет, но они уже читаются из базы данных в процессе №1. В этом примере проблема не такая существенная, ведь запроса всего два, но их может быть гораздо больше.
Количество параллельных загрузок зависит от количества параллельных пользователей и времени, которое требуется на загрузку необходимых данных.
Предположим, у вас есть какой-то функционал, использующий кэш с нагрузкой 200 запросов в секунду. Если на на загрузку данных нужно 50 мс, то за это время вы получите 50 / (1000 / 200) = 10 запросов.
То есть при отсутствии кэша один процесс начнёт загружать данные, и за время загрузки придут ещё девять запросов, которые не увидят данные в кэше и тоже станут их загружать.
Эта проблема называется cache stampede (русского аналога этого термина я не нашёл, дословно это можно перевести как «паническое бегство кэша», и картинка в начале статьи показывает пример этого действия в дикой природе), hit miss storm («шторм непопаданий в кэш») или dog-pile effect («эффект собачьей стаи»). Есть несколько способов её решения:
Блокировка перед началом выполнения операции пересчёта/ загрузки данных
Суть этого метода состоит в том, что при отсутствии данных в кэше процесс, который хочет их загрузить, должен захватить лок, который не даст сделать то же самое другим параллельно выполняющимся процессам. В случае memcached простейший способ блокировки — добавление ключа в тот же кэширующий сервер, в котором должны храниться сами закэшированные данные.
При этом варианте данные обновляются только в одном процессе, но нужно решить, что делать с процессами, которые попали в ситуацию с отсутствующим кэшем, но не смогли получить блокировку. Они могут отдавать ошибку или какое-то значение по умолчанию, ждать какое-то время, после чего пытаться получить данные ещё раз.
Кроме того, нужно тщательно выбирать время самой блокировки — его гарантированно должно хватить на то, чтобы загрузить данные из источника и положить в кэш. Если не хватит, то повторную загрузку данных может начать другой параллельный процесс. С другой стороны, если этот временной промежуток будет слишком большим и процесс, получивший блокировку, умрёт, не записав данные в кэш и не освободив блокировку, то другие процессы также не смогут получить эти данные до окончания времени блокировки.
Вынос обновлений в фон
Основная идея этого способа — разделение по разным процессам чтения данных из кэша и записи в него. В онлайн-процессах происходит только чтение данных из кэша, но не их загрузка, которая идёт только в отдельном фоновом процессе. Данный вариант делает невозможными параллельные обновления данных.
Этот способ требует дополнительных «расходов» на создание и мониторинг отдельного скрипта, пишущего данные в кэш, и синхронизации времени жизни записанного кэша и времени следующего запуска обновляющего его скрипта.
Этот вариант мы в Badoo используем, например, для счётчика общего количества пользователей, про который ещё пойдёт речь дальше.
Вероятностные методы обновления
Суть этих методов заключается в том, что данные в кэше обновляются не только при отсутствии, но и с какой-то вероятностью при их наличии. Это позволит обновлять их до того, как закэшированные данные «протухнут» и потребуются сразу всем процессам.
Для корректной работы такого механизма нужно, чтобы в начале срока жизни закэшированных данных вероятность пересчёта была небольшой, но постепенно увеличивалась. Добиться этого можно с помощью алгоритма XFetch, который использует экспоненциальное распределение. Его реализация выглядит примерно так:
В данном примере $ttl — это время жизни значения в кэше, $delta — время, которое потребовалось для генерации кэшируемого значения, $expiry — время, до которого значение в кэше будет валидным, $beta — параметр настройки алгоритма, изменяя который, можно влиять на вероятность пересчёта (чем он больше, тем более вероятен пересчёт при каждом запросе). Подробное описание этого алгоритма можно прочитать в white paper «Optimal Probabilistic Cache Stampede Prevention», ссылку на который вы найдёте в конце этого раздела.
Нужно понимать, что при использовании подобных вероятностных механизмов вы не исключаете параллельные обновления, а только снижаете их вероятность. Чтобы исключить их, можно «скрестить» несколько способов сразу (например, добавив блокировку перед обновлением).
«Холодный» старт и «прогревание» кэша
Нужно отметить, что проблема массового обновления данных из-за их отсутствия в кэше может быть вызвана не только большим количеством обновлений одного и того же ключа, но и большим количеством одновременных обновлений разных ключей. Например, такое может произойти, когда вы выкатываете новый «популярный» функционал с применением кэширования и фиксированным сроком жизни кэша.
В этом случае сразу после выкатки данные начнут загружаться (первое проявление проблемы), после чего попадут в кэш — и какое-то время всё будет хорошо, а после истечения срока жизни кэша все данные снова начнут загружаться и создавать повышенную нагрузку на базу данных.
От такой проблемы нельзя полностью избавиться, но можно «размазать» загрузки данных по времени, исключив тем самым резкое количество параллельных запросов к базе. Добиться этого можно несколькими способами:
- плавным включением нового функционала. Для этого необходим механизм, который позволит это сделать. Простейший вариант реализации — выкатывать новый функционал включённым на небольшую часть пользователей и постепенно её увеличивать. При таком сценарии не должно быть сразу большого вала обновлений, так как сначала функционал будет доступен только части пользователей, а по мере её увеличения кэш уже будет «прогрет».
- разным временем жизни разных элементов набора данных. Данный механизм можно использовать, только если система в состоянии выдержать пик, который наступит при выкатке всего функционала. Его особенность заключается в том, что при записи данных в кэш у каждого элемента будет своё время жизни, и благодаря этому вал обновлений сгладится гораздо быстрее за счёт распределения последующих обновления во времени. Простейший способ реализовать такой механизм — умножить время жизни кэша на какой-то случайный множитель:
Если по какой-то причине не хочется использовать случайное число, можно заменить его псевдослучайным значением, полученным с помощью хеш-функции на базе каких-нибудь данных (например, User ID).
Пример
Я написал небольшой скрипт, который эмулирует ситуацию «непрогретого» кэша.
В нём я воспроизвожу ситуацию, при которой пользователь при запросе загружает данные о себе (если их нет в кэше). Конечно, пример синтетический, но даже на нём можно увидеть разницу в поведении системы.
Вот как выглядит график количества hit miss-ов в ситуации с фиксированным (fixed_cache_misses_count) и различным (random_cache_misses_count) сроками жизни кэша:

Видно, что в начале работы в обоих случаях пики нагрузки очень заметны, но при использовании псевдослучайного времени жизни они сглаживаются гораздо быстрее.
«Горячие» ключи
Данные в кэше разнородные, некоторые из них могут запрашиваться очень часто. В этом случае проблемы могут создавать даже не параллельные обновления, а само количество чтений. Примером подобного ключа у нас является счётчик общего количества пользователей:

Этот счётчик — один из самых популярных ключей, и при использовании обычного подхода все запросы к нему будут идти на один сервер (поскольку это всего один ключ, а не множество однотипных), поведение которого может измениться и замедлить работу с другими ключами, хранящимися там же.

Чтобы решить эту проблему, нужно писать данные не в один кэширующий сервер, а сразу в несколько. В этом случае мы кратно снизим количество чтений этого ключа, но усложним его обновления и код выбора сервера — ведь нам нужно будет использовать отдельный механизм.
Мы в Badoo решаем эту проблему тем, что пишем данные во все кэширующие серверы сразу. Благодаря этому при чтении мы можем использовать общий механизм выбора сервера — в коде можно использовать обычный механизм шардирования по User ID, и при чтении не нужно ничего знать про специфику этого «горячего» ключа. В нашем случае это работает, поскольку у нас сравнительно немного серверов (примерно десять на площадку).
Если бы кэширующих серверов было намного больше, то этот способ мог бы быть не самым удобным — просто нет смысла дублировать сотни раз одни и те же данные. В таком случае можно было бы дублировать ключ не на все серверы, а только на их часть, но такой вариант требует чуть больше усилий.
Если вы используете определение сервера по ключу кэша, то можно добавить к нему ограниченное количество псевдослучайных значений (сделав из total_users_count что-то вроде t otal_users_count_1 , total_users_count_2 и т. д.). Подобный подход используется, например, в Etsy.
Если вы используете явные указания параметра шардирования, то просто передавайте туда разные псевдослучайные значения.
Главная проблема с обоими способами — убедиться, что разные значения действительно попадают на разные кэширующие серверы.
Сбои в работе
Система не может быть надёжной на 100%, поэтому нужно предусмотреть, как она будет вести себя при сбоях. Сбои могут быть как в работе самого кэша, так и в работе базы данных.
При сбоях в работе базы данных и отсутствии кэша мы можем попасть в ситуацию cache stampede, про которую я тоже уже рассказывал раньше. Выйти из неё можно уже описанными способами, а можно записать в кэш заведомо некорректное значение с небольшим сроком жизни. В этом случае система сможет определить, что источник недоступен, и на какое-то время перестанет пытаться запрашивать данные.

Всем привет Поговорим о том, как отключить кэширование в Windows, а также напишу минусы его и плюсы. Значит что вообще такое это кэширование виндовское и для чего оно нужно? Значит оно как бы ускоряет комп в целом, ну думаю вы и так знаете. Но вот в чем прикол, мне кажется, что это кэширование не совсем так работает, как о нем пишут в интернетах..
Дело в том, что это кэширование файлов приводит к тому, что все последующие обращения к одному и тому же файлу происходят намного быстрее. Но кэширование работает именно на уровне файлов, это стоит учесть, ибо например утилита PrimoCache (которой кстати я давно уже пользуюсь, она позволяет создать кэш из ОЗУ для жесткого диска), так она кэширует как бы не файлы, а блоки файловой системы. Как по мне, то эффективность кэширования блоков куда выше, чем файлов.
Но как бы там не было, отключать кэширование я все равно не советую, потому что так бы сказать это базовое кэширование и оно очень необходимо. Мы не знаем эффект от него, не видим просто потому, что оно по умолчанию уже включено. Даже в Windows XP по умолчанию включено это кэширование. Вот если бы винда устанавливалась с отключенным кэшированием, то потом, после некоторого времени, если бы вы включили кэширование, то вы стопудово заметили бы ускорение работы системы
Я писал, что виндовское кэширование не до конца изучено, ну или о нем просто мало есть инфы. Что я это имел ввиду? По моим наблюдениям, виндовское кэширование это нечто большее чем просто кэширование файлов. После включения кэширования его я не замечаю взрыв производительности, нет, такого нет, но то что оболочка работает быстрее, это факт. То что программы чуть быстрее открываются и закрываются, это тоже факт. Мелкие файлы также легче копировать. Загрузка рабочего стола со всеми процессами, прогами которые стоят в автозагрузке, то все это происходит немного быстрее при включенном виндовском кэшировании. Почему так, я не знаю. Но уверен, что кэширование нужно не только для файлов! Возможно что кэшируются данные, с которыми работают те или иные программы, кэшируются вызовы команд, библиотеки, ну и все остальное такое эдакое. Вы уж извините, может я и бред написал, но я вот так думаю.
Поэтому даже используя утилиту PrimoCache, я все равно не отключаю виндовское кэширование. И вам советую. Правда есть разговоры в интернетах, что в Windows 7 такое кэширование потребляет много оперативы и потом назад эту память не отдает. Ну, честно вот скажу, никогда ничего подобного у меня не было, и очень странно, ведь я с компьютером почти не расстаюсь..
Ну так вот, теперь по поводу настроек. В винде есть два вида кэширования, это кэширование дисков и кэширование файловой системы. Или это одно и тоже, я честно говоря не знаю, но вроде бы это разные настройки. То есть чтобы полностью включить или отключить кэширование в Windows, нужно пройтись по этим обоим настройкам.
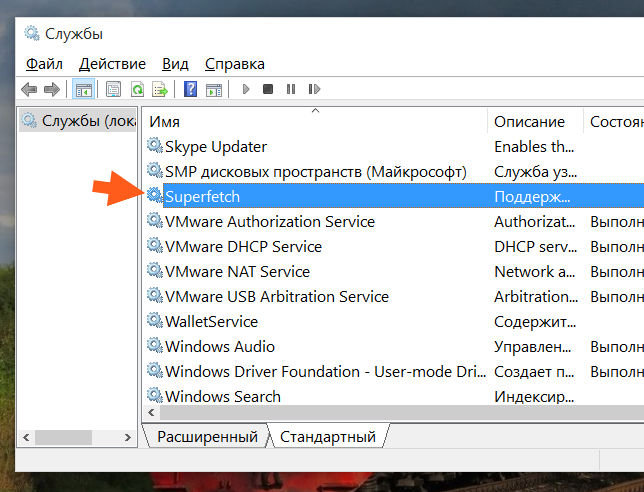
Итак, первая настройка, это служба SuperFetch. Именно эта служба и обеспечивает кэширование файловой системы в виндовс. Я лично ее не отключал, вернее я пробовал ее отключить, но пришел к выводу, что лучше ее оставить включенной. Вы тоже можете провести эксперимент: отключите службу и поработайте за компом несколько недель, а потом ее включите и сравните работу. Может вы заметите разницу, а может быть и не заметите. Кому как, но если комп работает быстрее и без службы SuperFetch, то думаю что нет смысла вам ее включить. В принципе все логично..
Я сейчас покажу как отключить SuperFetch в Windows 10, но также само все можно сделать и в Windows 7. Можно ли отключить в Vista, я, честно говоря не знаю.. Но думаю что можно.. Ну так вот, открываете диспетчер задач и там идете на вкладку Службы, где нажимаете кнопку Открыть службы:

Теперь тут находим службу SuperFetch (кстати она еще называется SysMain, так что теперь знайте что это за служба) и нажимаем по ней два раза:
Потом появится вот такое небольшое окошко свойств:

Как видите, в поле Описание тут сказано кратко, что поддерживает и улучшает производительность системы. Ну, в принципе, как я уже писал, то так оно и есть. Теперь, чтобы отключить эту службу, вам нужно там где Тип запуска, то там выбрать Отключена. И потом еще нажать кнопку Остановить, ну чтобы работа службы прекратилась. Ну а чтобы включить ее обратно, то нужно все вернуть как было
Это была первая настройка. А вот вторая настройка, это я имею ввиду кэширования дисков в Windows и вот как это кэширование отключить. Открываете окно Мой компьютер, в Windows 10 вы можете сразу его и не открыть, ну мало ли, поэтому на всякий случай я покажу команду, при помощи которой можно открыть это окно. Просто зажимаете Win + R и пишите туда такое как:

Теперь нажимаете правой кнопкой по любому диску или разделу и выбираете там Свойства:

Откроется окошко свойств, тут вам нужно перейти на вкладку Оборудование, где у вас будут все диски, вот эта вкладка:

А внизу там есть еще кнопочока Свойства. Так вот, вам нужно выбрать диск, и потом нажать эту кнопку, чтобы открыть уже свойства устройства, ну то есть диска. В общем выбираем диск и нажимаем кнопку Свойства:

Дальше нажимаем кнопку Изменить параметры:

И вот теперь, на вкладке Политика будут две галочки, вот они:

Как видите, они у меня поставлены, если вам нужно максимально отключить виндовское кэширование, то помимо отключения службы SuperFetch, снимите и тут галочки. Но учтите, что после этих отключений, ну я имею ввиду и SuperFetch и вот это кэширование записей, очистка буфера, то после всего этого у вас винда может начать работать немного медленнее. А если у вас SSD, то может быть и не будет разницы, но если не будет разницы, то в этом в кэшировании точно нет смысла! Но это вам нет, а вот вашему SSD (если у вас именно он), то польза может и будет, ибо с включенным кэшированием обращений к SSD-диску возможно что будет меньше. Вот такие вот дела ребята, так что учитывайте все моменты при отключении кэширования..
ЗАБЫЛ КОЕ ЧТО! Я вот показал как отключить кэширование дисков, да? Ну так вот, это нужно сделать для каждого диска! То есть там в окошке выбираете диск и потом нажимаете кнопку Свойства, и потом уже отключаете кэширование. ВОТ ТАК нужно сделать с каждым диском, для каждого диска нажать кнопку Свойства, ну, думаю все понятно
Что еще сказать про кэширование? Даже не знаю.. Ну то что отключать его я не советую, это я уже написал, однако решение все равно за вами, кому-то легче с ним, а у кого-то оно вызывает только глюки. Ведь для кэширования нужна оперативка, правда Microsoft утверждает, что при необходимости, оперативка будет освобождена под нужды какой-то проги. Но как уже убедились юзеры Windows 7, это не всегда происходит именно так, хотя у меня все было нормально. Часто юзеры писали, что какая-то программа сообщает, что ей не хватает оперативки, когда ее в теории должно быть полно. А оказывается, что вся она ушла под кэширование и возвращаться не собирается. Вот такие пироги..
Итак, давайте подведем выводы. Какие плюсы у отключения кэширования?
- Потребление оперативной памяти самой Windows должно снизится.
- Работающих служб станет на одну меньше, конечно это плюс сомнительный, но чем меньше работающих служб, тем быстрее работает сама Windows.
- Меньше шансов, что ценная информация пропадет. В теории данные должны записываться сразу на диск, без буферной зоны в виде кэша. Ну это не то чтобы в теории, это так и должно быть.
Как видим плюсы есть, но огромных все таки нет, разве что Windows будет потреблять меньше оперативки. Но и тут прикол, некоторые юзеры писали, что даже при отключении кэширования, винда все равно продолжала кушать оперативку под какой-то кэш. Правда дело было в Windows 7.
Ну а какие минусы отключения виндовского кэширования?
- Некоторые программы могут работать медленнее. Копирование файлов, установка и запуск программ, закрытие программ, все эти процессы могут происходить немного медленнее. Однако это я имею ввиду если у вас жесткий диск (HDD), если же твердотельный накопитель (SSD), то никакого замедления быть не должно.
- Увеличится обращение к диску. В случае с жестким диском это проявляется как периодическое подтормаживание, а в случае с SSD это просто увеличит количество записи/чтения данных (что не так уж и полезно для SSD).
- После отключения кэширования, свободная оперативная память будет простаивать, то есть пользы от нее никакой не будет. С другой стороны доступный обьем ОЗУ будет полностью в распоряжении запущенных программ.
Вот такие дела, я не знаю что написать по поводу особых плюсов или особых минусов в кэшировании. Тут каждый выбирает сам. То что система с включенным кэшированием работает быстрее, то в этом я сам лично убедился. Если отключить кэширование, то становится больше оперативы, я это тоже заметил. Поэтому вывод можно сделать один: я показал как отключить кэширование, вам осталось просто провести эксперимент и понять, что лучше, без кэширования или с ним. Рекомендую эксперимент вести не один день, а где-то неделю, или даже две, чтобы окончательно закрыть для себя вопрос, ну как-то так..
В общем на этом все, извините если что не так, но надеюсь что все вам тут было понятно. Удачи вам в жизни и всего хорошего
Читайте также: