Как получить файл базы данных sql server
Обновлено: 13.05.2024
На работе появилась необходимость немного автоматизировать рабочий процесс:
В Excel написан макрос, который анализирует подключенные к нему таблицы с SQL, находит новые нужные записи, обрабатывает их, по внутренним отчётам (другие книги excel), добывает недостающую информацию, и шлёт Email заинтересованным лицам. Прав администратора нет, поэтому сильно ограничены в действиях.
Так столкнулся с проблемой, что часть нужной информации лежит на SQL во полях blob во внутреннем неизвестном формате, и единственным местом, где что-то хоть как-то структурировано: файлик xml, который содержит всю необходимую информацию.
Находится в таблице: EDMsgXML, в которой есть столбцы EnvelopeID, Msg, Zip.
из которых:
EnvelopeID - идентификатор (достаточно легко можно найти, и загнать в переменную)
Msg - искомый файлик XML
Zip - признак архива (в архиве файл или нет).
Собственно вопрос: возможно ли средствами VBA добыть файл с SQL, сохранить на диск и, если нужно разархивировать?
Заранее благодарю за любую помощь
Помощь в написании контрольных, курсовых и дипломных работ здесь

Получить тип столбца из таблицы в SQL Server посредством Linq to SQL
Как получить тип столбца из таблицы в SQL Server посредством Linq to SQL или используя любой.
Получить список таблиц из БД MS SQL Server
Хочу получит список таблиц из БД но не получается. Как правильно делать ?? string connStr =.
получить данные из БД SQL server по значению textbox
Добрый день. Сделал програмулину которая записывает инфу с текстбоксов в бд, все нормально.
Определенный бред удалось получить:
Файлики создает (во вложении пример), разного размера для разных записей (как и должно быть), но, странные какие-то. (может проблема в кодировке?). А может на SQL не в бинарном виде хранится? Как проверить?
Есть мысли у кого-нибудь?
В чем проблема сейчас?
Добавлено через 4 минуты
И вопрос, а есть ли у Вас разрешение на работу с данной таблицей это главный момент всей вашей затеи.
Каждая база данных SQL Server имеет как минимум два рабочих системных файла: файл данных и файл журнала. Файлы данных содержат данные и объекты, такие как таблицы, индексы, хранимые процедуры и представления. Файлы журнала содержат сведения, необходимые для восстановления всех транзакций в базе данных. Файлы данных могут быть объединены в файловые группы для удобства распределения и администрирования.
Файлы базы данных
SQL Server имеют три типа файлов.
| Файл | Описание |
|---|---|
| Первичная | Содержит сведения, необходимые для запуска базы данных, и ссылки на другие файлы в базе данных. В каждой базе данных имеется один первичный файл данных. Для имени первичного файла данных рекомендуется расширение MDF. |
| Вторичная | Необязательные определяемые пользователем файлы данных. Данные могут быть распределены на несколько дисков, в этом случае каждый файл записывается на отдельный диск. Для имени вторичного файла данных рекомендуется расширение NDF. |
| Журнал транзакций | Журнал содержит информацию для восстановления базы данных. Для каждой базы данных должен существовать хотя бы один файл журнала. Для файлов журнала транзакций рекомендуется расширение LDF. |
Например, простая база данных с именем Sales включает один первичный файл, содержащий все данные и объекты, и один файл журнала, содержащий сведения журнала транзакций. Более сложная база данных с именем Orders может содержать один первичный файл и пять вторичных файлов. Данные и объекты внутри базы данных распределяются по всем шести файлам, а четыре файла журнала содержат сведения журнала транзакций.
По умолчанию и данные, и журналы транзакций помещаются на один и тот же диск и имеют один и тот же путь для обработки однодисковых систем. Для производственных сред это может быть неоптимальным решением. Рекомендуется помещать данные и файлы журнала на разные диски.
Логические и физические имена файлов
Файлы SQL Server имеют два типа имен файлов.
logical_file_name: имя, используемое для ссылки на физический файл во всех инструкциях Transact-SQL. Логическое имя файла должно соответствовать правилам для идентификаторов SQL Server и быть уникальным среди логических имен файлов в соответствующей базе данных.
os_file_name: имя физического файла, включающее путь к каталогу. Оно должно соответствовать правилам для имен файлов операционной системы.
Дополнительные сведения об аргументах NAME и FILENAME см. в статье Параметры ALTER DATABASE ((Transact-SQL)) для файлов и файловых групп.
Файлы данных и файлы журналов SQL Server могут использоваться как в файловой системе FAT, так и в системе NTFS. В системах Windows рекомендуется использовать файловую систему NTFS по причинам ее большей безопасности.
Файловые группы, доступные как для чтения, так и для записи, а также файлы журналов не поддерживаются со сжатой файловой системой NTFS. В сжатую файловую систему NTFS разрешено помещать лишь доступные только для чтения базы данных и доступные только для чтения вторичные файловые группы. Для экономии места настоятельно рекомендуется использовать сжатие данных вместо сжатия файловой системы.
Если на одном компьютере запущено несколько экземпляров SQL Server, каждый экземпляр получает отдельный каталог по умолчанию для хранения файлов баз данных, созданных в этом экземпляре. Дополнительные сведения см. в разделе Расположение файлов для экземпляра по умолчанию и именованных экземпляров SQL Server.
Размер файла
Файлы SQL Server могут автоматически увеличиваться в размерах, превосходя первоначально заданные показатели. При определении файла пользователь может указывать требуемый шаг роста. Каждый раз при заполнении файла его размер увеличивается на указанный шаг роста. Если в файловой группе имеется несколько файлов, их автоматический рост начинается лишь по заполнении всех файлов.
Дополнительные сведения о страницах и их типах см. в разделе Руководство по архитектуре страниц и экстентов.
Кроме того, можно указать максимальный размер каждого файла. Если максимальный размер файла не указан, файл может продолжать увеличиваться в размерах, пока не займет все доступное место на диске. Эта функция особенно полезна в случаях, когда SQL Server используется в качестве базы данных, внедренной в приложение, где пользователь не имеет удобного доступа к системному администратору. По мере необходимости пользователь может предоставить файлам возможность увеличиваться в размерах автоматически, тем самым снимая с администратора часть забот по наблюдению за свободным пространством базы данных и по распределению дополнительного пространства вручную.
Дополнительные сведения об управлении файлами журнала транзакций см. в разделе Управление размером файла журнала транзакций.
Файлы моментального снимка базы данных
Вид файла, используемый для хранения копируемых во время записи данных моментального снимка базы данных, зависит от того, создается ли моментальный снимок пользователем или используется внутренними механизмами.
- Данные моментального снимка базы данных, созданного пользователем, хранятся в одном или нескольких разреженных файлах. Технология разреженных файлов является свойством файловой системы NTFS. Изначально разреженный файл не содержит данных пользователя, и место на диске под него не выделяется. Общие сведения об использовании разреженных файлов в моментальных снимках базы данных и о том, как растут моментальные снимки базы данных, см. в разделе Просмотр размера разреженного файла моментального снимка базы данных.
- Моментальные снимки базы данных могут использоваться внутренними механизмами при выполнении определенных команд DBCC. Эти команды включают DBCC CHECKDB, DBCC CHECKTABLE, DBCC CHECKALLOC и DBCC CHECKFILEGROUP. Внутренним моментальным снимком базы данных используются разреженные дополнительные потоки данных исходных файлов базы данных. Подобно разреженным файлам, дополнительные потоки данных являются свойством файловой системы NTFS. Использование разреженных дополнительных потоков данных позволяет связать несколько расположений данных с одним файлом или папкой, не затрагивая при этом размер файла или статистику тома.
Файловые группы
- Эта файловая группа содержит первичный файл данных и все вторичные файлы, не входящие в другие файловые группы.
- Пользовательские файловые группы могут создаваться для удобства администрирования, распределения и размещения данных.
Например, Data1.ndf , Data2.ndf и Data3.ndf могут быть созданы на трех дисках соответственно и отнесены к файловой группе fgroup1 . В этом случае можно создать таблицу на основе файловой группы fgroup1 . Запросы данных из таблицы будут распределены по трем дискам, и это улучшит производительность. Подобного улучшения производительности можно достичь и с помощью одного файла, созданного на чередующемся наборе дискового массива RAID. Тем не менее файлы и файловые группы позволяют без труда добавлять новые файлы на новые диски.
Все файлы данных хранятся в файловых группах, перечисленных в следующей таблице.
| Файловая группа | Описание |
|---|---|
| Первичная | Файловая группа, содержащая первичный файл. Все системные таблицы являются частью первичной файловой группы. |
| Данные, оптимизированные для памяти | В основе оптимизированной для памяти файловой группы лежит файловая группа файлового потока. |
| Файловый поток | |
| Определяемые пользователем маршруты | Любая файловая группа, созданная пользователем при создании или изменении базы данных. |
Файловая группа по умолчанию (первичная)
Если в базе данных создаются объекты без указания файловой группы, к которой они относятся, они назначаются файловой группе по умолчанию. В любом случае только одна файловая группа создается как файловая группа по умолчанию. Файлы в файловой группе по умолчанию должны быть достаточно большими, чтобы вмещать новые объекты, не назначенные другим файловым группам.
Файловая группа PRIMARY является группой по умолчанию, если только она не была изменена инструкцией ALTER DATABASE. Системные объекты и таблицы распределяются внутри первичной файловой группы, а не новой файловой группой по умолчанию.
Файловая группа данных, оптимизированных для памяти
Дополнительные сведения об оптимизированных для памяти файловых группах см. в разделе Оптимизированные для памяти файловые группы.
Файловая группа файлового потока
Дополнительные сведения о файловых группах файлового потока см. в статьях FILESTREAM и Создание базы данных с поддержкой FILESTREAM.
Пример файлов и файловых групп
В следующем примере создается база данных на основе экземпляра SQL Server. База данных содержит первичный файл данных, пользовательскую файловую группу и файл журнала. Первичный файл данных входит в состав первичной файловой группы, а пользовательская файловая группа состоит из двух вторичных файлов данных. Инструкция ALTER DATABASE придает пользовательской файловой группе статус файловой группы по умолчанию. Затем создается таблица, определяющая пользовательскую файловую группу. (В этом примере используется универсальный путь к c:\Program Files\Microsoft SQL Server\MSSQL.1 , чтобы не указывать версию SQL Server.)
Данная иллюстрация обобщает все вышесказанное (кроме данных файлового потока).
Стратегия заполнения файлов и файловых групп
В файловых группах для каждого файла используется стратегия пропорционального заполнения. При записи данных в файловую группу компонент Компонент SQL Server Database Engine записывает в каждый файл количество данных, пропорциональное свободному пространству этого файла, вместо записи всех данных в первый файл до его заполнения. Затем запись производится в следующий файл. Например, если в файле f1 свободно 100 МБ, а в файле f2 — 200 МБ, то в файл f1 записывается одна часть данных, а в файл f2 — две части, и так далее. Таким образом, оба файла будут заполнены примерно в одно и то же время, и достигается простейшее распределение данных между хранилищами.
Например, файловая группа состоит из трех файлов, для всех разрешено автоматическое увеличение. Когда свободное пространство во всех файлах группы закончится, будет расширен только первый файл. Когда заполнится первый файл и в файловую группу снова нельзя будет записывать новые данные, будет расширен второй файл. Когда заполнится второй файл и в файловую группу опять нельзя будет записывать новые данные, будет расширен третий файл. Когда заполнится третий файл и в файловую группу нельзя будет записывать новые данные, будет снова расширен первый файл и т. д.
Правила проектирования файлов и файловых групп
Для файлов и файловых групп действуют следующие правила:
- файл или файловая группа не могут использоваться несколькими базами данных. Например, файлы sales.mdf и sales.ndf, содержащие данные и объекты базы данных sales, не могут использоваться никакой другой базой данных.
- файл может быть элементом только одной файловой группы;
- файлы журнала транзакций не могут входить ни в какие файловые группы.
Рекомендации
Рекомендации при работе с файлами и файловыми группами:
- Для большинства баз данных достаточно использовать один файл данных и один файл журнала транзакций.
- При использовании множества файлов данных создайте вторую файловую группу с дополнительным файлом и сделайте ее файловой группой по умолчанию. Тогда в первичном файле будут храниться только системные таблицы и объекты.
- Чтобы увеличить производительность, по возможности разнесите файлы и файловые группы по нескольким доступным дискам. Объекты, активно конкурирующие за свободное пространство, поместите в разные файловые группы.
- Используйте файловые группы для целенаправленного размещения объектов на конкретных физических дисках.
- Помещайте разные таблицы, использующиеся в одних и тех же запросах с соединениями, в разные файловые группы. Этот этап увеличит производительность, так как для поиска соединяемых данных можно будет использовать параллельный ввод-вывод.
- Часто используемые таблицы и некластеризованные индексы, относящиеся к ним, помещайте в разные файловые группы. Использование разных групп файлов увеличит производительность, так как можно будет использовать параллельный ввод и вывод, если файлы находятся на разных жестких дисках.
- Не помещайте файлы журнала транзакций на тот же физический диск, где находятся другие файлы и файловые группы.
- Если необходимо расширить том или раздел, в котором находятся файлы базы данных, с помощью таких средств, как Diskpart, следует сначала выполнить резервное копирование всех системных и пользовательских баз данных и остановить службы SQL Server. Кроме того, после успешного расширения томов дисков рекомендуется выполнить команду DBCC CHECKDB , чтобы обеспечить физическую целостность всех баз данных в томе.
Дополнительные рекомендации по управлению файлами журнала транзакций см. в разделе Управление размером файла журнала транзакций.
В сегодняшней статье я хочу поговорить об очень важной теме SQL Server: как SQL Server обрабатывает файловые группы файлов. Когда вы используете команду CREATE DATABASE для создания простой базы данных, SQL Server создает для вас 2 файла:
- Файл данных (.mdf)
- Файл журнала транзакций (.ldf)
Сам файл данных создается в одной и только одной основной группе файлов. По умолчанию в основной группе файлов SQL Server хранит все данные (пользовательские таблицы, системные таблицы и т. Д.). Для чего нужны дополнительные файлы и файловые группы? Давайте взглянем.
Когда вы создаете дополнительные файловые группы для своих данных, вы можете сохранять в них определяемые вами таблицы и индексы. Это поможет вам во многих отношениях.
- Вы можете сохранить свою основную файловую группу небольшой.
- Вы можете разделить данные на несколько файловых групп (например, вы можете использовать файловые разделы в корпоративной версии).
- Вы можете выполнять операции резервного копирования и восстановления на уровне файловой группы. Это дает вам более точный контроль над стратегиями резервного копирования и восстановления.
- Команду DBCC CHECKDB можно запустить на уровне группы файлов, а не на уровне базы данных.
Как правило, у вас должна быть хотя бы одна группа подчиненных файлов, в которой вы можете хранить создаваемые вами объекты базы данных. Вы не должны хранить другие системные объекты, созданные SQL Server для вас, в основной файловой группе.
Когда вы создаете свою собственную файловую группу, вы также должны поместить в нее хотя бы один файл. Кроме того, в файловую группу можно добавлять дополнительные файлы. Это также улучшит вашу производительность загрузки, потому что SQL Server будет распространять данные по всем файлам, так называемые Алгоритм Round Robin Allocation (Алгоритм Round Robin Allocation). Первые 64 КБ хранятся в первом файле, вторые 64 КБ хранятся во втором файле, а третья область сохраняется в первом файле (в вашей файловой группе, когда у вас есть 2 файла).
Используя этот метод, SQL Server может находиться в буферном пуле Защелка выделяет несколько копий растровых страниц (PFS, GAM, SGAM) и повышает производительность загрузки. Вы также можете использовать этот метод для решения той же проблемы с конфигурацией по умолчанию в TempDb. Кроме того, SQL Server также гарантирует, что все файлы в группе файлов будут заполнены в один и тот же момент времени - с помощью так называемого Алгоритм пропорционального заполнения . Поэтому очень важно, чтобы все ваши файлы в группе файлов имели одинаковый начальный размер и параметры автоматического увеличения. в противном случае Алгоритм распределения циклического планирования не может работать должным образом.
Теперь мы рассмотрим следующий пример, как создать базу данных с несколькими файлами в группе дополнительных файлов. В следующем коде показана команда CREATE DATABASE, которую необходимо использовать для выполнения этой задачи.
После создания базы данных возникает вопрос, как поместить таблицу или индекс в определенную файловую группу? Вы можете использовать ключевое слово ON, чтобы вручную указать группу файлов, как показано в следующем коде:
Другой вариант: вы помечаете определенную группу файлов как группу файлов по умолчанию. Затем SQL Server автоматически создает новый объект базы данных в группе файлов, в которой не указано ключевое слово ON.
Это метод, который я обычно рекомендую, потому что вам больше не нужно думать об этом после создания объектов базы данных. Итак, теперь давайте создадим новую таблицу, которая будет автоматически сохранена в файловой группе FileGroup1.
Теперь проводим простой тест: вставляем в таблицу 40 000 записей. Каждая запись имеет размер 8 КБ. Итак, мы вставили в таблицу 320 МБ данных. Это то, что я только что упомянул Алгоритм распределения расписания опроса будет работать: SQL Server будет распределять данные между 2 файлами: первый файл содержит 160 МБ данных, а второй файл также будет иметь 160 МБ данных.
Затем вы можете проверить его на жестком диске, и вы увидите тот же размер, что и два файла.

Когда вы помещаете эти файлы на разные физические жесткие диски, вы можете получить к ним доступ одновременно. Это сила наличия нескольких файлов в файловой группе.
Вы также можете использовать следующий сценарий для получения информации о файле базы данных.
В сегодняшней статье я показал вам, как несколько групп файлов и несколько файлов в группе файлов упрощают управление вашей базой данных и как использовать несколько файлов в группе файлов. Алгоритм распределения циклического планирования.
Содержание
- Условие задачи
- Выполнение
- 1. Запуск MS Visual Studio .
- 2. Активировать окно Server Explorer .
- 3. Команда “ Add Connection… ”.
- 4. Окно “ Add Connection ”.
- 5. Создание таблицы Student .
- 6. Создание таблицы Session .
- 7. Редактирование структуры таблиц.
- 8. Установление связей между таблицами.
- 9. Внесение данных в таблицы.
Поиск на других ресурсах:
Условие задачи
Создать базу данных с именем “ Education ”. В базе данных создать две таблицы, которые связаны между собой по некоторому полю.
Структура первой таблицы « Student ».
![09_02_00_002_table01_r]()
Структура второй таблицы “Session”.
![09_02_00_002_table02_r]()
Таблицы должны быть связаны между собой по полю Num_book .
Выполнение
1. Загрузить MS Visual Studio .
2. Активировать окно Server Explorer .
Файл базы данных с расширением “ *.mdf ” относится к серверу реляционных баз данных Microsoft SQL Server . Файл содержит непосредственно базу данных.
При создании “ *.mdf ” файла базы данных также создается файл с расширением “ *.ldf ”, который содержит журнал транзакций.
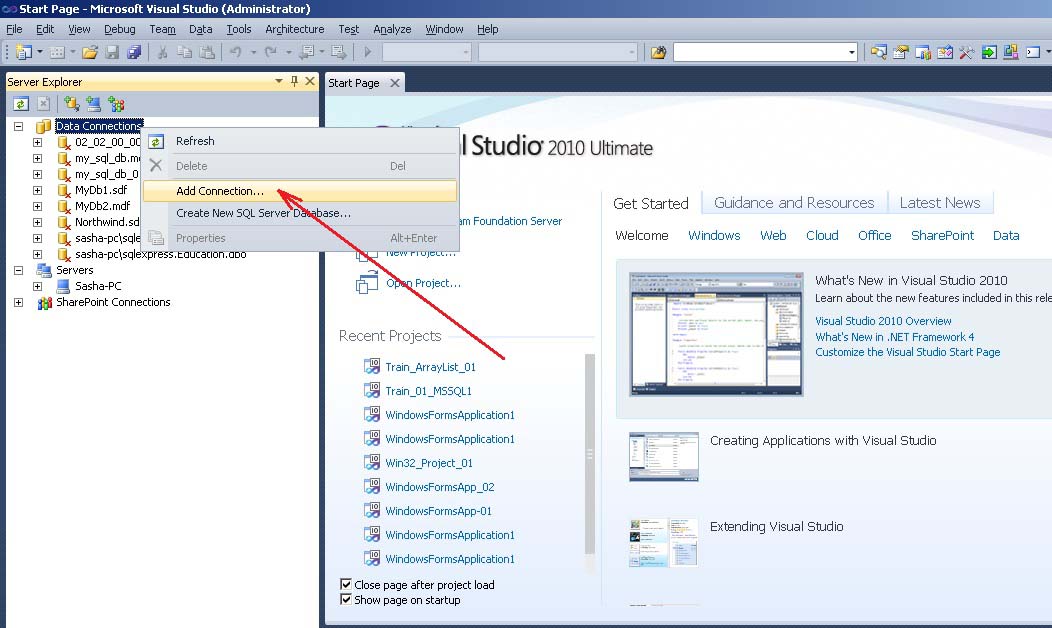
Перед созданием базы данных, нужно активировать утилиту Server Explorer . Для этого, в MS Visual Studio нужно вызвать (рисунок 1)
![Visual Studio команда Server Explorer]()
Рис. 1. Вызов Server Explorer
![Visual Studio команда Add Connection]()
Рис. 2. Вызов команды Add Connection из контекстного меню
![Visual Studio команда “Connect to Database. ”]()
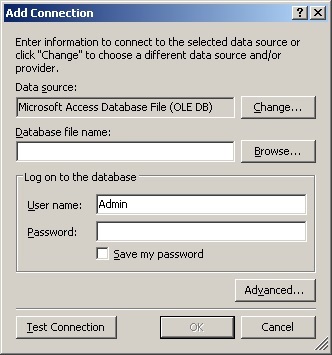
4. Окно “ Add Connection ”.
В результате выполнения предыдущей команды откроется окно “ Add Connection ” (рисунок 4). В этом окне пользователь имеет возможность:
![SQL Server соединение база данных]()
Рис. 4. Окно “ Add Connection ”
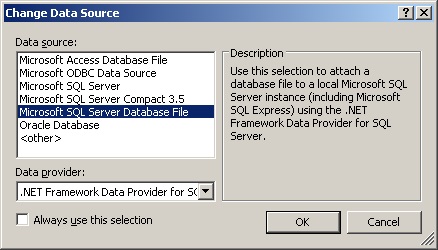
В результате откроется второе окно “ Change Data Source ” (рисунок 5). В этом окне выбирается источник данных и провайдер.
Система MS Visual Studio предлагает следующие виды источников данных:
- база данных Microsoft Access , которая содержится в файле формата “ *.mdb ”;
- база данных, которая поддерживает доступ с помощью драйвера ODBC ;
- база данных типа Microsoft SQL Server , в том числе и локальный сервер SQLEXPRESS ;
- база данных “ Microsoft SQL Server Compact 3.5 ”, которая размещается в файлах с расширением “ *.sdf ”;
- база данных “ Microsoft SQL Server Database File ”, которая содержится в файлах формата “ *.mdf ”;
- база данных Oracle .
Для создания “ *.mdf ” файла базы данных Microsoft SQL Server нужно выбрать источник данных “ Microsoft SQL Server Database File ” как зображено на рисунке 5.
![09_02_00_002_05_]()
Рис. 5. Окно “ Change Data Source ”
В нашем случае нужно ввести название базы данных “ Education ”, как изображено на рисунке 6.
![09_02_00_002_06_]()
Рис. 6. Создание базы данных Education
После подтверждения на “ OK ”, система выведет окно, как изображено на рисунке 7. Предлагается системная папка по умолчанию:
![09_02_00_002_07_]()
Рис. 7. Предложение создать файл “ Education.mdf ”
После подтверждения, база данных Education.mdf будет создана (рисунок 8).
![09_02_00_002_08_]()
Рис. 8. Новосозданная база данных “ Education.mdf ”
5. Создание таблицы Student .
На данный момент база данных Education абсолютно пустая и не содержит никаких объектов (таблиц, сохраненных процедур, представлений и т.д.).
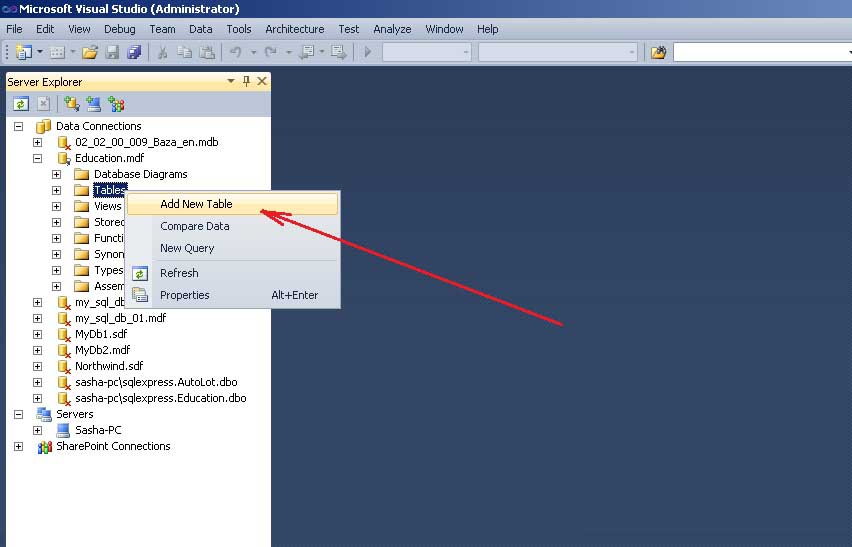
Чтобы создать таблицу, нужно вызвать контекстное меню (клик правой кнопкой мышки) и выбрать команду “ Add New Table ” (рисунок 9).
![09_02_00_002_09_]()
Рис. 9. Команда добавления новой таблицы
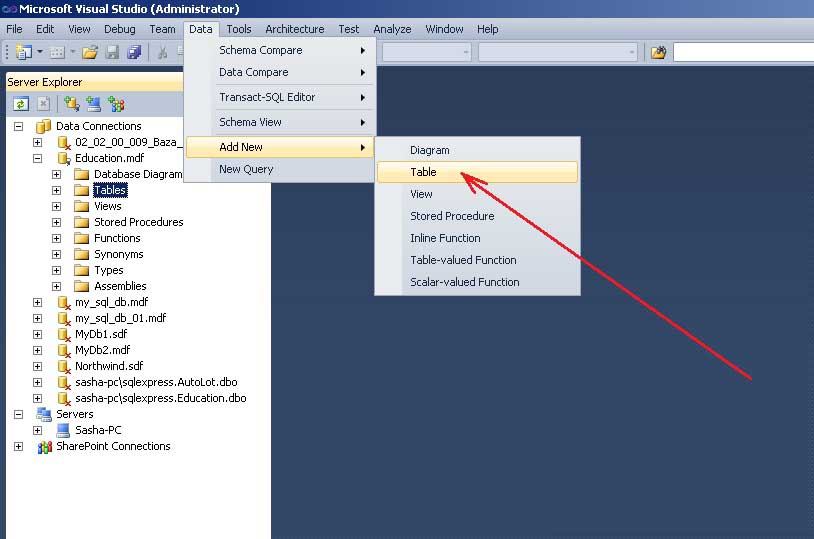
Существует и другой вариант добавления таблицы базы данных с помощью команд меню Data (рисунок 10):
![09_02_00_002_10_]()
Рис. 10. Альтернативный вариант добавления новой таблицы
В результате откроется окно добавления таблицы, которое содержит три столбца (рисунок 11). В первом столбце “ Column Name ” нужно ввести название соответствующего поля таблицы базы данных. Во втором столбце “ Data Type ” нужно ввести тип данных этого поля. В третьем столбце “ Allow Nulls ” указывается опция о возможности отсутствия данных в поле.
![09_02_00_002_11_]()
Рис. 11. Окно создания новой таблицы
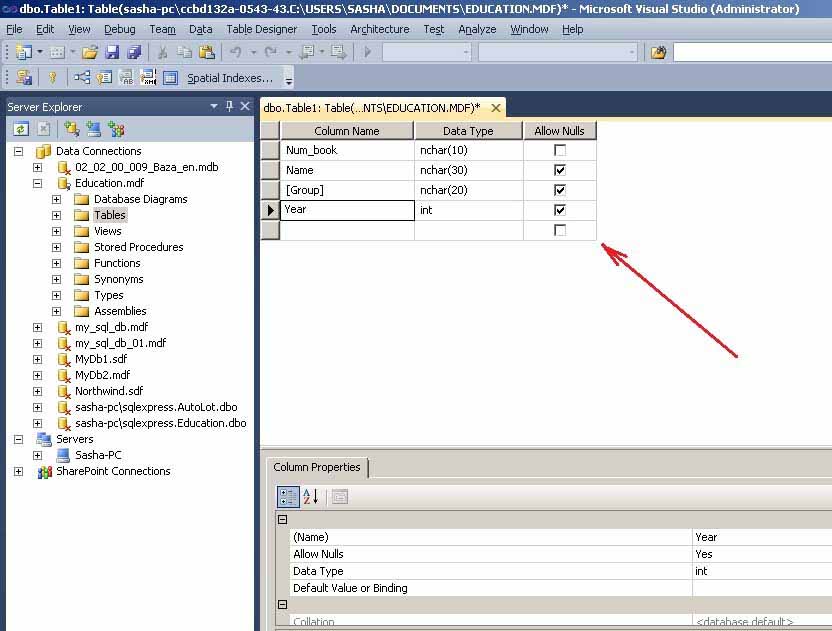
С помощью редактора таблиц нужно сформировать таблицу Student как изображено на рисунке 12. Имя таблицы нужно задать при ее закрытии.
В редакторе таблиц можно задавать свойства полей в окне Column Properties . Для того, чтобы задать длину строки ( nvchar ) в символах, в окне Column Properties есть свойство Length . По умолчанию значения этого свойства равно 10.
![09_02_00_002_12_]()
Рис. 12. Таблица Student
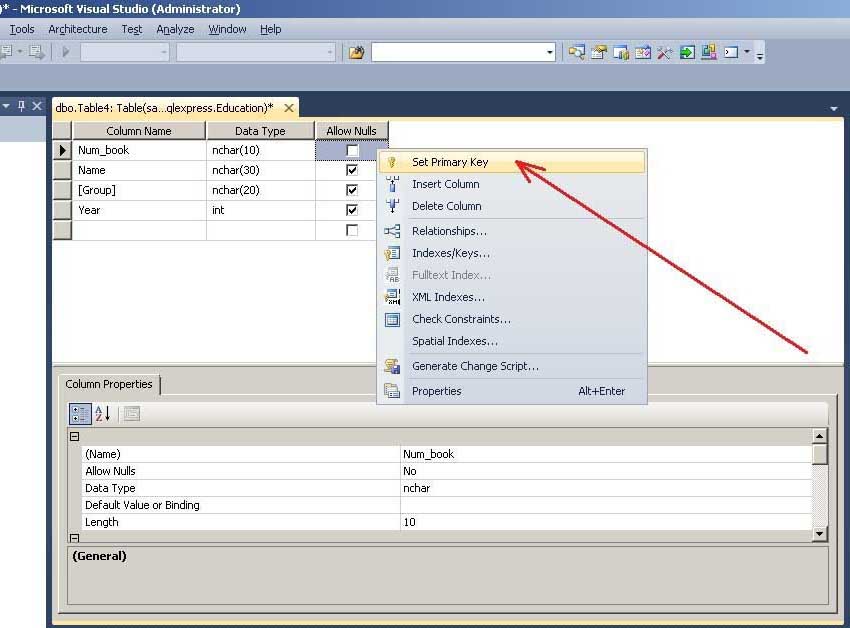
Следующим шагом нужно задать ключевое поле. Это осуществляется вызовом команды “ Set Primary Key ” из контекстного меню поля Num_book (рисунок 13). С помощью ключевого поля будут установлены связи между таблицами. В нашем случае ключевым полем есть номер зачетной книжки.
![09_02_00_002_13_]()
Рис. 13. Задание ключевого поля
После установки первичного ключа окно таблицы будет иметь вид как изображено на рисунке 14.
![]()
Рис. 14. Таблица Student после окончательного формирования
![]()
Рис. 15. Ввод имени таблицы Student
6. Создание таблицы Session .
По образцу создания таблицы Student создается таблица Session .
На рисунке 16 изображен вид таблицы Session после окончательного формирования. Первичный ключ ( Primary Key ) устанавливается в поле Num_book . Имя таблицы задается Session .
![]()
Рис. 16. Таблица Session
После выполненных действий, в окне Server Explorer будут отображаться две таблицы Student и Session .
Таким образом, в базу данных можно добавлять любое количество таблиц.
7. Редактирование структуры таблиц.
Бывают случаи, когда нужно изменить структуру таблицы базы данных.
Для того, чтобы вносить изменения в таблицы базы данных в MS Visual Studio , сначала нужно снять опцию “ Prevent Saving changes that require table re-creation ” как показано на рисунке 17. Иначе, MS Visual Studio будет блокировать внесения изменений в ранее созданную таблицу. Окно Options , показанное на рисунке 17 вызывается из меню Tools в такой последовательности:
![]()
Рис. 17. Опция “ Prevent Saving changes that require table re-creation ”
После настройки можно изменять структуру таблицы. Для этого используется команда “Open Table Definition ” (рисунок 18) из контекстного меню, которая вызывается для выбранной таблицы (правый клик мышкой).
![]()
Рис. 18. Вызов команды “ Open Table Definition ”
Также эта команда размещается в меню Data :
Предварительно таблицу нужно выделить.
8. Установление связей между таблицами.
В соответствии с условием задачи, таблицы связаны между собою по полю Num_book.
Чтобы создать связь между таблицами, сначала нужно (рисунок 19):
- выделить объект Database Diagram ;
- выбрать команду Add New Diagram из контекстного меню (или из меню Data );
- подтвердить создание нового объекта-диаграммы (рисунок 20).
![]()
Рис. 19. Вызов команды добавления новой диаграммы
![]()
В результате откроется окно добавления новой диаграммы Add Table (рисунок 21). В этом окне нужно выбрать последовательно две таблицы Session и Student и нажать кнопку Add.
![]()
Рис. 21. Окно добавления таблиц к диаграмме
В результате будет создан новый объект с двумя таблицами Student и Session (рис. 22).
![]()
Рис. 22. Таблицы Student и Session после добавления их к диаграмме
Чтобы начать устанавливать отношение между таблицами, надо сделать клик на поле Num_book таблицы Student , а потом (не отпуская кнопку мышки) перетянуть его на поле Num_book таблицы Session .
В результате последовательно откроются два окна: Tables and Columns (рис. 23) и Foreign Key Relationship (рис. 24), в которых нужно оставить все как есть и подтвердить свой выбор на OK .
В окне Tables and Columns задается название отношения ( FK_Session_Student ) и названия родительской ( Student ) и дочерней таблиц.
![]()
Рис. 23. Окно Tables and Columns
![]()
Рис. 24. Окно настройки свойств отношения
После выполненных действий будет установлено отношение между таблицами (рисунок 25).
![]()
Рис. 25. Отношение между таблицами Student и Session
Сохранение диаграммы осуществляется точно также как и сохранение таблицы. Имя диаграммы нужно выбрать на свое усмотрение (например Diagram1 ).
После задания имени диаграммы откроется окно Save , в котором нужно подтвердить свой выбор (рисунок 26).
![]()
Рис. 26. Подтверждение сохранения изменений в таблицах
9. Внесение данных в таблицы.
Система Microsoft Visual Studio разрешает непосредственно вносить данные в таблицы базы данных.
Чтобы вызвать режим ввода данных в таблицу Student , нужно вызвать команду Show Table Data из контекстного меню (клик правой кнопкой мышки) или с меню Data (рис. 27).
![]()
Рис. 27. Команда Show Table Data
Откроется окно, в котором нужно ввести входные данные (рис. 28).
![]()
Рис. 28. Ввод данных в таблице Student
После внесения данных в таблицу Student нужно внести данные в таблицу Session .
При внесении данных в поле Num_book таблицы Session нужно вводить точно такие же значения, которые введены в поле Num_book таблицы Student (поскольку эти поля связаны между собой).
Например, если в поле Num_book таблицы Student введены значения “1134”, “1135”, “1221” (см. рис. 28), то следует вводить именно эти значения в поле Num_book таблицы Session . Если попробовать ввести другое значение, система выдаст приблизительно следующее окно (рис. 29).
![]()
Таблица Session с введенными данными изображена на рисунке 30.
![]()
Рис. 30. Таблица Session с введенными данными
Итак, база данных создана. Ввод и обработку данных в таблицах можно реализовать программным путем.
Я хочу импортировать / экспортировать саму базу данных, таблицы, ограничения (внешние ключи и так далее). Я бы предпочел не получать данные с ним, но я могу избавиться от него после, если нет другого способа.
Так. как экспортировать базу данных с помощью MS SQL Server Management Studio ? Как импортировать это?
единственным решением, которое я нашел, был щелчок правой кнопкой мыши по таблицам и" скрипт для создания", но у меня есть что-то вроде 100 таблиц, поэтому я бы предпочел избежать этого.
щелкните правой кнопкой мыши саму базу данных, задачи - > создать скрипты.
затем следуйте указаниям мастера.
для SSMS2008+, если вы хотите также экспортировать данные, на шаге " установить параметры сценариев "выберите кнопку" Дополнительно "и измените" типы данных в сценарий "с" только схема "на" только данные "или"схема и данные".
другое решение - резервное копирование и восстановление базы данных
резервное копирование системной базы данных
чтобы создать резервную копию системной базы данных с помощью Microsoft SQL Server Management Studio Express, выполните следующие действия:
после установки Microsoft SQL Server Management Studio Express запустите приложение для подключения к системной базе данных. Откроется диалоговое окно "подключение к серверу". В поле" имя сервера: "введите имя сервера Webtrends, на котором установлена системная база данных. В поле" аутентификация: "выберите" аутентификация Windows", Если вы вошли в систему Windows использование учетной записи службы Webtrends или учетной записи с правами для внесения изменений в системную базу данных. В противном случае выберите "проверка подлинности SQL Server" в раскрывающемся меню и введите учетные данные учетной записи SQL Server, которая имеет необходимые права. Нажмите "Подключиться", чтобы подключиться к базе данных.
выберите "OK" для завершения процесс резервного копирования.
повторите вышеуказанные шаги для части базы данных" wtMaster".
восстановить системную базу данных
чтобы восстановить системную базу данных с помощью Microsoft SQL Server Management Studio, выполните следующие действия:
после установки Microsoft SQL Server Management Studio запустите приложение для подключения к системной базе данных. Откроется диалоговое окно "подключение к серверу". В поле" тип сервера: "выберите" компонент Database Engine " (по умолчанию). В поле" имя сервера: "выберите" \WTSYSTEMDB", где находится имя сервера Webtrends, на котором расположена база данных. WTSYSTEMDB имя экземпляра базы данных в установке по умолчанию. В поле "аутентификация:" выберите "аутентификация Windows", Если вы вошли в систему Windows с помощью учетной записи службы Webtrends или учетной записи с правами на внесение изменений в системную базу данных. В противном случае выберите "проверка подлинности SQL Server" в раскрывающемся меню и введите учетные данные учетной записи SQL Server, которая имеет необходимые права. Нажмите "Подключиться", чтобы подключиться к базе данных.
развернуть "Базы данных" щелкните правой кнопкой мыши на "wt_sched" и выберите "Удалить" из контекстного меню. Убедитесь, что установлен флажок" удалить данные журнала резервного копирования и восстановления для баз данных".
выберите "OK", чтобы завершить процесс удаления.
повторите вышеуказанные шаги для части базы данных" wtMaster".
повторите шаг 6 для "wtMaster" часть базы данных.
для Microsoft SQL Server Management Studio 2012,2008.. Сначала скопируйте файл базы данных .MDF и файл журнала .ldf & вставить в файл установки sql server в файлы программ - >Microsoft SQL Server - >MSSQL10.SQLEXPRESS - >MSSQL - >ДАННЫЕ. Затем откройте Microsoft Sql Server . Щелкните правой кнопкой мыши на Databases - > Select Attach. выбор.
Я попробовал ответы выше, но скрипт был очень большой и у меня возникли проблемы при импорте данных. В итоге я отсоединил базу данных, а затем скопировал .mdf на мою новую машину, а затем прикрепить его к моей новой версии SQL Server Management Studio.
Примечание: после отсоединения базы данных я нашел этот.файл mdf в этом каталоге:
C:\Program файлы\Microsoft SQL Server\Я хотел поделиться с вами своим решением для экспорта базы данных с Microsoft SQL Server Management Studio.
для экспорта базы данных
копировать вставить этот скрипт
SET @BackupFile = 'D:\database-backup - . бак!--1-->
резервное копирование базы данных [%имя базы данных%]
на диск = @BackupFile
не забудьте заменить %databaseName% именем базы данных, которую вы хотите экспортировать.
отметьте, что этот метод дает более легкий файл, чем из меню.
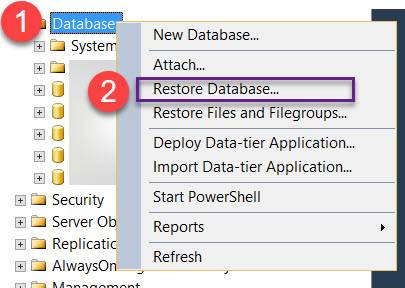
импорт этот файл из SQL Server Management Studio. Не забудьте предварительно удалить базу данных.
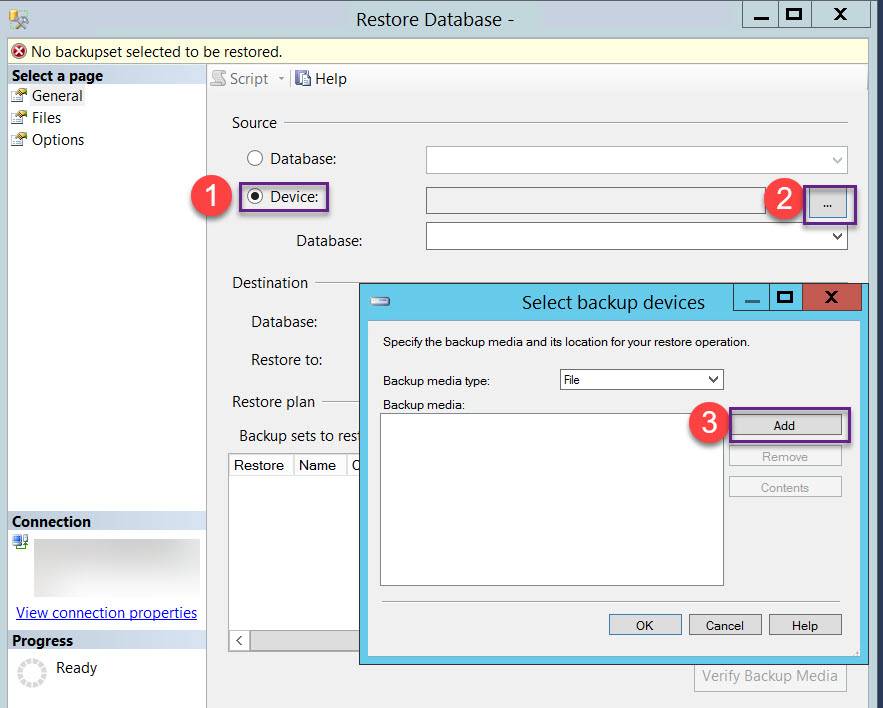
![Click restore database]()
![Add the backup file]()
добавить резервную копию файл
Читайте также: