
Как посмотреть файлы сайта
Обновлено: 03.07.2024

Если мошенники просканируют ваш сайт и найдут загруженные файлы, они могут загрузить на ваш сайт вредоносный код. Если на вашем сайте есть скрытые файлы, о которых вы не знаете, вы можете стать легкой добычей киберпреступников. Они могут получить доступ к конфиденциальной информации и использовать ее в незаконных целях.
По этой причине очень важно знать, как найти скрытые файлы на веб-сайтах и в каталогах.
В этой статье мы объясним, как просмотреть список каталогов веб-сайтов с помощью сканера каталогов веб-сайтов. Это простой и бесплатный способ получить полный список скрытых каталогов, которые могут стать уязвимостью для вашего сайта.
Что такое сканер каталогов веб-сайтов?
Как найти скрытые страницы и файлы на сайте?
Что такое каталог веб-сайта? Это основная папка, в которой хранятся все каталоги и файлы сайта. Именно в эту папку загружается архив с файлами сайта и базой данных. Если вы поместите файлы сайта не в ту папку, вместо сайта будет отображаться ошибка 403.
Это помогает профессионально сканировать каталог веб-сайтов. Особенно, когда вы запускаете ориентированные на безопасность тесты и просматриваете каталог веб-сайта, он закрывает некоторые дыры, не закрываемые классическими сканерами веб-уязвимостей. Он ищет определенные веб-объекты, но не ищет уязвимости и не ищет веб-контент, который может быть уязвимым.
Что могут быть «скрытые файлы»?
В общем, эти каталоги могут быть следующими:
- Файлы конфигурации проекта, которые создает IDE (интегрированная среда разработки).
- Конкретные файлы конфигурации и конфигурации для данного проекта или технологии.
Различные типы сканеров каталогов веб-сайтов
Как просмотреть каталог сайта? Сканеры работают по разным принципам. Есть инструменты для сканирования вашего сайта (и это авторизованные инструменты), но есть также хакерские инструменты. С этической точки зрения вы не можете сканировать каталоги других сайтов. Юридически это считается взломом и мошенничеством.
Давайте посмотрим, по какому принципу будут работать различные типы сканеров каталогов.
- Словарный поиск файлов на веб-сайте.
- Сканирование чистым сканером.
- Сканирование с помощью веб-сканера.
- Сканирование с использованием библиотеки запросов Python.
Как видите, существует несколько способов сканирования и поиска скрытых файлов на вашем сайте. Вы можете выбрать наиболее удобный для себя или воспользоваться нашим простым инструментом «Сканер каталогов веб-сайтов». С помощью нашего бесплатного сканера вы легко просмотрите каталог веб-сайта и найдете все скрытые файлы, которые могут стать вашей уязвимостью.
Руководство по эффективному использованию нашего сканера каталогов
Если вы хотите найти скрытые URL страниц на веб-сайте и знаете, как просмотреть список каталогов веб-сайтов, используйте наш инструмент сканирования каталогов веб-сайтов.
Так просто выглядит процесс поиска в каталоге сайта.
Особенности нашего сканера каталогов веб-сайтов
Что ж, давайте кратко рассмотрим основные функции нашего сканера каталогов веб-сайтов.
Как только сканирование остановится, вы увидите оценку своего сайта, количество отсканированных страниц и количество страниц в индексе Google. Например, мы просканировали наш сайт sitechecker.pro. Вы можете увидеть результаты сканирования на скриншоте ниже.

Прокрутив страницу ниже, вы увидите проблемы на уровне сайта. Если на вашем веб-сайте есть скрытые файлы, которые наш инструмент может сканировать, вы также увидите их в этом списке.

Следующей особенностью нашего инструмента является то, что вы можете просматривать ошибки, разделенные на три категории. Это критические ошибки, которые говорят о важности их исправления как можно скорее.


БЕЗ скриптов, макросов, регулярных выражений и командной строки.
Эта статья пригодится студентам, которые хотят скачать все картинки с сайта разом, чтобы потом одним движением вставить их в Power Point и сразу получить готовую презентацию. Владельцам электронных библиотек, которые собирают новые книги по ресурсам конкурентов. Просто людям, которые хотят сохранить интересный сайт/страницу в соцсети, опасаясь, что те могут скоро исчезнуть, а также менеджерам, собирающим базы контактов для рассылок.
Есть три основные цели извлечения/сохранения данных с сайта на свой компьютер:
- Чтобы не пропали;
- Чтобы использовать чужие картинки, видео, музыку, книги в своих проектах (от школьной презентации до полноценного веб-сайта);
- Чтобы искать на сайте информацию средствами Spotlight, когда Google не справляется (к примеру поиск изображений по exif-данным или музыки по исполнителю).
Ситуации, когда неожиданно понадобится автоматизированно сохранить какую-ту информацию с сайта, могут случиться с каждым и надо быть к ним готовым. Если вы умеете писать скрипты для работы с утилитами wget/curl, то можете смело закрывать эту статью. А если нет, то сейчас вы узнаете о самых простых приемах сохранения/извлечения данных с сайтов.
1. Скачиваем сайт целиком для просмотра оффлайн
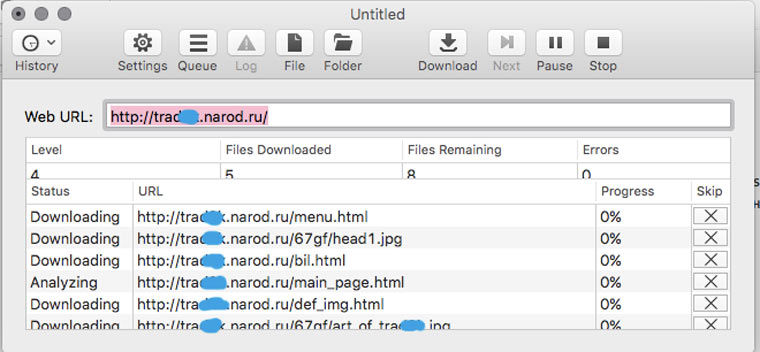
В OS X это можно сделать с помощью приложения HTTrack Website Copier, которая настраивается схожим образом.
Пользоваться Site Sucker очень просто. Открываем программу, выбираем пункт меню File -> New, указываем URL сайта, нажимаем кнопку Download и дожидаемся окончания скачивания.
2. Прикидываем сколько на сайте страниц
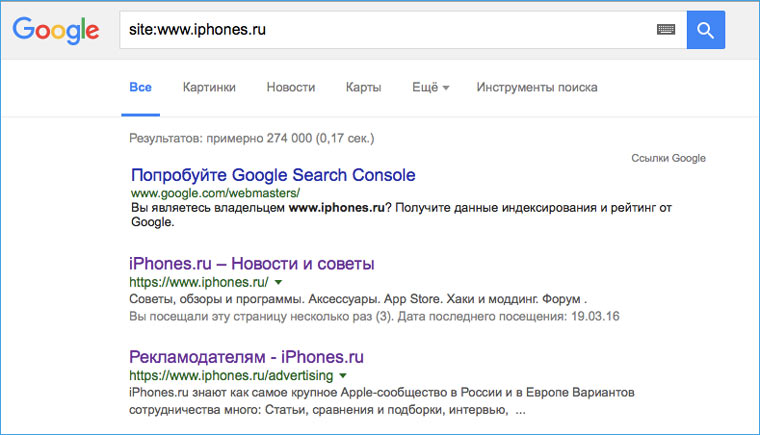
Перед тем как браться за скачивание сайта, необходимо приблизительно оценить его размер (не затянется ли процесс на долгие часы). Это можно сделать с помощью Google. Открываем поисковик и набираем команду site: адрес искомого сайта. После этого нам будет известно количество проиндексированных страниц. Эта цифра не соответствуют точному количеству страниц сайта, но она указывает на его порядок (сотни? тысячи? сотни тысяч?).
3. Устанавливаем ограничения на скачивание страниц сайта
![]()
Если вы обнаружили, что на сайте тысячи страниц, то можно ограничить число уровней глубины скачивания. К примеру, скачивать только те страницы, на которые есть ссылка с главной (уровень 2). Также можно ограничить размер загружаемых файлов, на случай, если владелец хранит на своем ресурсе tiff-файлы по 200 Мб и дистрибутивы Linux (и такое случается).
Сделать это можно в Settings -> Limits.
4. Скачиваем с сайта файлы определенного типа
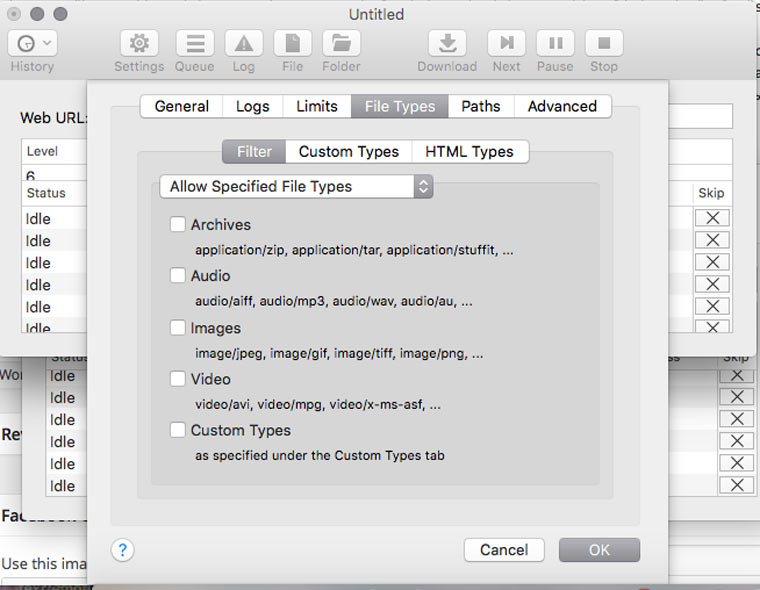
В Settings -> File Types -> Filters можно указать какие типы файлов разрешено скачивать, либо какие типы файлов запрещено скачивать (Allow Specified Filetypes/Disallow Specifies Filetypes). Таким образом можно извлечь все картинки с сайта (либо наоборот игнорировать их, чтобы места на диске не занимали), а также видео, аудио, архивы и десятки других типов файлов (они доступны в блоке Custom Types) от документов MS Word до скриптов на Perl.
5. Скачиваем только определенные папки
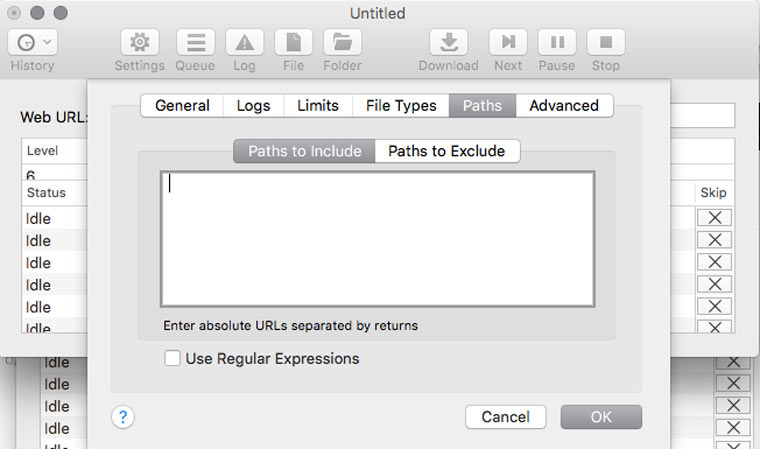
Если на сайте есть книги, чертежи, карты и прочие уникальные и полезные материалы, то они, как правило, лежат в отдельном каталоге (его можно отследить через адресную строку браузера) и можно настроить SiteSucker так, чтобы скачивать только его. Это делается в Settings -> Paths -> Paths to Include. А если вы хотите наоборот, запретить скачивание каких-то папок, то их адреса надо указать в блоке Paths to Exclude
6. Решаем вопрос с кодировкой
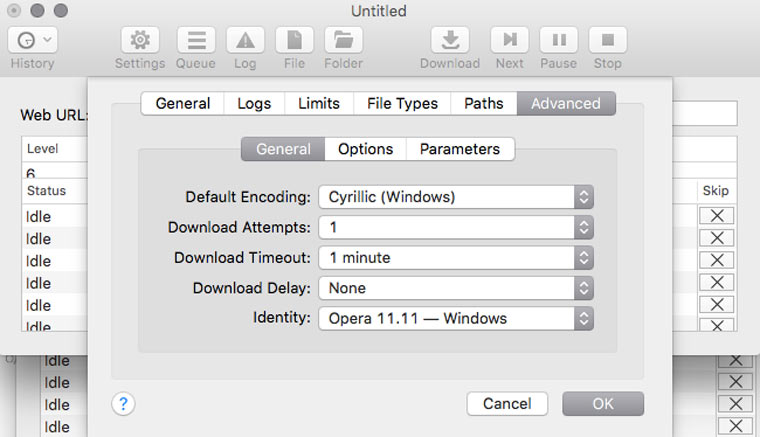
Если вы обнаружили, что скачанные страницы вместо текста содержат кракозябры, там можно попробовать решить эту проблему, поменяв кодировку в Settings -> Advanced -> General. Если неполадки возникли с русским сайтом, то скорее всего нужно указать кодировку Cyrillic Windows. Если это не сработает, то попробуйте найти искомую кодировку с помощью декодера Лебедева (в него надо вставлять текст с отображающихся криво веб-страниц).
7. Делаем снимок веб-страницы
Это может пригодиться для сравнения разных версий дизайна сайта, запечатления на память длинных эпичных перепалок в комментариях или в качестве альтернативы способу сохранения сайтов, описанного в предыдущих шести пунктах.
8. Сохраняем картинки только с определенной страницы
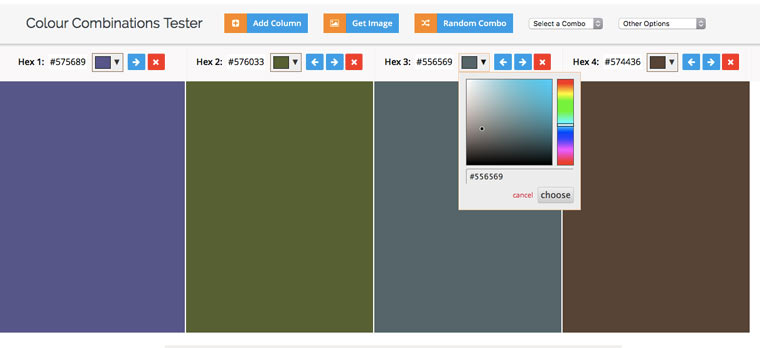
9. Извлекаем HEX-коды цветов с веб-сайта
10. Извлекаем из текста адреса электронной почты
11. Извлекаем из текста номера телефонов
А если надо отфильтровать в тексте заголовки, даты и прочую информацию, то к вам на помощь придут регулярные выражения и Sublime Text.
(2 голосов, общий рейтинг: 4.50 из 5)
Помощь в написании контрольных, курсовых и дипломных работ здесь
Как просмотреть содержимое папки на FTP сервере
Всем доброго дня! Разобрался с подключением к FTP серверу. Подскажите 1) Как просмотреть.

Как просмотреть содержимое директории?
Здравствуйте, подскажите пожалуйста, как в Lazarus просмотреть все файлы, имеющиеся в директории.
Как в отладчике просмотреть содержимое списка?
Python 2.7.2. Имеется скрипт, считывающий данные из внешних файлов и определенным образом их.
Как в VBA просмотреть содержимое папок?
Как в VBA просмотреть содержимое папок, типа dirlistbox есть что-нибудь??
53ifbb, спасибо. Действительно, нашел такую опцию, добавил в .htaccess. Правильно я понимаю, что .htaccess должен лежать в корне сайта? Я помещал его и в mysite, и в www, и в конечную папку "1" (лежит внутри папки www), но листинга папки "1" я так не увидел. При вызове mysite в браузере появляется страничка Index of с единственной папкой "1" (т.к. она лежит внутри www). Но при выборе этой папки по прежнему сразу открывается index.html, который лежит внутри нее, но не содержимое всей папки "1". В чем может быть проблема? Пробовал класть файл в директорию Z:\usr\local\apache\conf - результат тот же.
Conf файл не трогаем. Htaccess лежит допустим в папие "вася" и все правила распространяются на нее и все ко омые в ней. Если в ней лежит папка Петя, а пете еще htacces, то правила из папки вася отменяются и берутся из пети для пети всех кто в пете)))Для листинга на подпапки нужно дописывать All. Про эту диррективк очень много инф в гугл, почитайте получше.
Если в ней лежит папка Петя, а пете еще htacces, то правила из папки вася отменяются и берутся из пети для пети всех кто в пете)))
53ifbb, хорошо. Тогда, что означает этот комментарий из файла .htaccess, который лежит в папке /home/custom:
Добавлено через 1 час 11 минут
И что самое интересное - если я положу файл .htaccess в папку 1, но уберу из этой папки index.html, то кликнув в браузере по этой папке, я получу все файлы, которые в ней лежат, т.е. то, что мне и нужно. Вопрос: чем так мешает в папке 1 index.html?
минус ознаяает запретить, плюс разрешить. Может у вас там еще какие то правила, показывайте тогда все htaccess которые имеете по дереву.
Добавлено через 3 минуты
RamblingBeard, Я не знаю, что у вас после вшего комменария идет, может у вас там список и имеется ввиду отключить что то
Но 24 года назад, лишь в 1996 году Брюстером Кейлом была организована некоммерческая организация Internet Arсhive, собирающая копии веб-сайтов, с 2001 года предоставившая публичный доступ к своей Waybackmachine (накопилось свыше 50 петабайт данных и число перевалило за полтриллиона страниц).
Но, к сожалению, материалы за около 5 лет, когда сайты были, а архива не было, фактически потеряны.
Распадаются страны (например, домен .yu — Югославия), упраздняются организации, прекращают работу сайты, следовательно сведения бесследно исчезают.
Информация — это история и культура.
Например, сайт прекратившей работу компании, создавшей один из первых интернет-браузеров:

Лучшие практики того,
как можно вручную сохранить ценную информацию [почти] навечно (на примере Пикабу).
Чтобы сохранить АДРЕС_СТРАНИЦЫ, нужно прописать:
Чтобы найти АДРЕС_СТРАНИЦЫ потом:
1) Web-страницы публично открытых сайтов (когда waybackmachine срабатывает).
2) Текстовая информация.
А потом дополнительно для спокойствия сохраняем в Waybackmachine.
Обе ссылки можно дать, например, в комментарии.
3.1) Файлы по ссылкам.
Стандартно. Упомянутый Архив Интернета сохраняет файлы, если дать на них прямую ссылку.
В комментариях можно дать ссылку на резервную копию файла.
3.2) Файлы по ссылкам, когда waybackmachine не сработал, ИЛИ же закрытые файлы.
Во-первых, применимо, когда сохранение не проходит из-за настроек сервера.
Во-вторых, применимо, когда у вас есть свой файл, который хочется опубликовать и сделать так, чтобы ссылка на него была доступна в комментариях и в будущем, навсегда.
Последовательность действий моя:
- дополнительно сохраняем полученную ссылку в Waybackmachine;
- в комментариях к странице даём обе ссылки;
- опционно: сохраняем в waybackmachine ещё и статью с комментариями (где будут эти ссылки).
Критерии хостинга: без регистрации, получается прямая ссылка (которая сохранится в Waybackmachine), а бонусом идёт вечное хранение (как утверждается). Но если и не вечное, то зеркало будет в Архиве Интернета.
Если у вас есть подпадающие под эти критерии хостинги — кидайте в комментарии.
4.1) Web-страницы публично открытых сайтов, когда waybackmachine не сработал, ИЛИ же закрытые страницы.
Во-первых, применимо, когда сохранение конкретной страницы не проходит опять-таки из-за настроек сервера (например, сайт подгружает информацию по нажатию мыши).
Во-вторых, применимо, когда есть информация, которая доступна после авторизации, а давать логин-пароль не рационально.
С первым примером всё ясно.
Типичный пример второго — та же Лепра, или страница с закрытого паблика соцсети, или страница с электронной почты. Сделать копию HTML, не давая доступа к учётной записи, чтобы показать, можно.
Доступный аналог (к сожалению, в отличие от исчезнувшего сервиса ссылки не сокращает и хранит информацию у себя не вечно, хотя с первостепенной задачей справляется):
- зайти на сайт, скопировать букмарклет себе в браузер (или быть готовым запустить скрипт, например, через консоль);
- зайти на нужную страницу;
- запустить букмарклет, чтобы осуществить копирование страницы. Учтите, она пропадёт в скором времени!
- дополнительно сохранить её с помощью в waybackmachine навечно;
- в комментарии к странице даём обе ссылки;
- опционно: сохраняем в waybackmachine ещё и статью с комментариями (где будут эти ссылки).
Как подменить:
Типичные примеры спасения файлов, когда ссылка в посте больше не работает, и иное:
1. Пикабу: Векторные дома в изометри, раздаю бесплатно:) (с сайта, указанного в посте, не грузится, но Архив Интернета скопировал).
2. Голосовое управление офисной оргтехникой (по ссылке в посте не грузится, но файл залит на хостинг, а потом сохранён в Архив Интернета).
4. Аналогичный файл javascript сайта-аналога, не был сохранён. А был сохранён позавчера мной, и я был первым. Если что с сайтом случится, файл останется.

Web-технологии
233 поста 4.5K подписчиков
Правила сообщества
1. Не оскорблять других пользователей
2. Не пытаться продвигать свои услуги под видом тематических постов
3. Не заниматься рекламой
4. Никакой табличной верстки
5. Тег сообщества(не обязателен) pikaweb
Ниче не понял. Оставил комент чтоб потом зайти почитать, что умные люди скажут.
Спасибо за пост. А можно сохранить весь сайт целиком с файлами? Например, есть сайт на сервере, по какой - то причине сервер вышел из строя, снэпшота ос нет. Можно сделать полную резервную копию сайта, чтобы потом на заново устаенленной ос на сервере можно было восстановить полноценный рабочий сайт?
Не волнуйтесь, в Америке весь интернет копирует АНБ. Так что всегда можно написать им и восстановить:)
Хм. А как можно вытащить с Wayback Machine сайт, который там уже есть, но целиком, со всем флешем?
Через простое сохранение страницы — не выходит, внутренние элементы флеша не сохраняются. Но в самом архиве всё работает, даже файлы скачать можно.
использую diigo. Умеет сохранять все кешируя
А вдруг кто-нибудь знает, как скопировать и заархивировать свой блог на ЖЖ?
Панические атаки, антидепрессанты и обучение по 16 часов в день. Как я пытаюсь стать программистом

Интернет пестрит рекламными баннерами в духе "Изучи programmingLanguageName (подставьте название любого популярного языка) с нуля за 3 месяца и устройся на работу с зп от 100 000 вечнодеревянных". Предложение, конечно, заманчивое, но вряд ли осуществимое на практике для среднего человека без опыта разработки и не являющегося гением. Попытаюсь рассказать о своём пути в IT.
В апреле мой работодатель решил закрыть бизнес и я оказался на улице. Было принято окончательное решение стать разработчиком. К этому моменту у меня за плечами был опыт изучения JS примерно полгода и примерно месяц изучения React. Я решил, что смогу за пару месяцев подтянуть знания до уровня, позволяющего претендовать на позицию junior frontend-developer. Следующие 2 месяца я начинал занятия в 10-11 часов утра и заканчивал в 2-3 ночи. Без праздников и выходных. Оказалось, что кроме HTML, CSS и JavaScript нужно знать ещё кучу разных технологий и библиотек вроде Redux, Webpack, Material-UI, formik, axios, да тысячи их. Также было сделано открытие: знать синтаксис языка, писать ToDo и решать задачи на codewars !== быть программистом.
В общем, список того, что нужно изучить в процессе только разрастался. Я начал переживать, что ошибся в оценке сроков, нужных для трудоустройства. Деньги заканчивались. Рассылка резюме не давала нужных результатов. Я не получал даже приглашения на интервью. Думаю, что это в совокупности с ещё рядом факторов спровоцировали первую паническую атаку. Букет, состоящий из высокого давления, головокружения, нехватки воздуха и дикого страха смерти прямо здесь и сейчас даёт весьма интересные ощущения. Терапевты из платной и бесплатной клиник поставили диагноз гипертония. На мой вопрос почему у меня развилась гипертония в 27 лет был дан ответ: "Что вы хотите, - возраст. Даже железо стареет". Сначала панические атаки были раз в неделю, спустя некоторое время они стали возникать каждый день. Нормально учиться стало невозможно. В таком состоянии я пробыл около 3 месяцев, пока наконец не попал к неврологу, который выписал антидепрессанты. Я вернулся к учёбе.
На данный момент прошло 1,5 года с момента, как я впервые встретился с HTML. До сих пор не получилось устроиться на работу. Программирование мне очень нравится и, думаю, что я его не брошу, даже если ничего не выйдет с работой. Идея окунуться в омут с головой, не имея солидной финансовой подушки, была весьма авантюрной. О решении не идти на платные курсы, готовящие профессиональных разработчиков за срок от недели до 3 месяцев не жалею, поскольку до сих пор не вижу их преимуществ перед самообучением.

Наглядно про веб-технологии

Перевод, думаю, не нужен :)
Во все тяжкие: Веб-разработчик с нуля. 1 год

"Еще до встречи с Юнаковым он уже жил по правилу: не отступать и не теряться. Не вышло—повтори. Правило, чем-то напоминающее цирковой обычай: не удался прыжок, упал с лошади или с проволоки — повтори, не откладывая в долгий ящик, повтори, преодолевая боль и страх, повторяй до тех пор, пока не добьешься своего, иначе тебе никогда не избавиться от неуверенности в решающий момент. Александр Крон - "Капитан дальнего плавания".
Цель — Senior Frontend Developer.
Язык: JavaScript.
Возраст: 29 лет.
Работа (настоящее время): Trainee Frontend Developer в компании "Корус Консалтинг СНГ".
Локация: г. Санкт-Петербург.
Привет! Пролетел год, с того самого дня, как я твердо решил освоить профессию инженера-программиста (веб-разработчика). И в этом посте мне не хочется рассказывать в привычной мне манере о том, что я сделал за последний месяц и о трудностях с которыми столкнулся. Вкратце, расскажу об этом в конце поста, а сейчас позволю себе кое-что поведать.
Этот год был интересен для меня не столько программированием, сколько открытием для себя новой плоскости, знакомство с людьми, чье мышление и навыки довольно интересны сами по себе.
Каждый человек рожден для того, чтобы развить в себе способность разбираться за короткий промежуток времени и решить задачу в любой сфере, неважно в какой. В истории, примеров людей, реализовавших эту способность, десятки. Современная жизнь требует от человека решение задач в разных плоскостях, но общество заставляет становиться узкоспециализированным специалистом в одной сфере, абсолютно неспособного ни на что, стоит только его вытянуть за пределы его плоскости влияния. И, как вы понимаете, жизнь со всеми ее ситуациями делает и будет продолжать делать это с каждым. Неважно, программист ты или врач, сантехник или менеджер, тебе обязательно придется столкнуться с реалиями жизни и со сферами, которые тебе не знакомы. Поэтому очень важно научиться быстро разбираться в любой сфере и принимать правильные решения.
К чему это я веду? К тому, чтобы глядя на мой пример, вы ни в коем случае, не закрывались в четырех стенах с компьютером в обнимку. Со стороны может показаться, что моя история - это история человека, который решил "жить программированием", что он только и делает, что программирует и больше ему ничего не интересно. Нет, это не так.
Моя жизнь не заканчивается программированием. Для меня программирование сейчас - это лишь сфера, которая мне показалась год назад очень хорошей для того, чтобы освоить определенные навыки и почувствовать под ногами опору в профессиональной сфере. Сейчас она мне кажется до сих пор такой сферой. Получилось ли это? Еще нет, я в начале пути, но определенно кое-какие успехи есть, и чувствую я себя увереннее. И я абсолютный противник такого образа жизни, при котором мышление человека фиксируется на одной плоскости и практически никогда оттуда не смещается. Иногда, да, требуется длительная фокусировка на сфере, но не фиксация.
Что касается программирования - то это обычная профессиональная плоскость, со своими особенностями и определенными требуемыми навыками. Она интересная, как и многие другие сферы, но она не особенная.
Сейчас у меня начался второй месяц стажировки и учебы в компании "Корус Консалтинг СНГ". Могу с уверенностью сказать, что за этот месяц я понял и освоил, с помощью преподавателя, больше, чем за несколько месяцев самостоятельной работы. Это к тому, что если есть возможность учиться у кого-то, кто уже прошел такой же путь - то обязательно делайте это. Еще я понял, что конкретные технологии абсолютно не имеют значения. React, Vue, Angular. это все не важно. Если вы понимаете главные принципы построения программы, принципы взаимодействия ее частей и тот язык на глубоком уровне, на базе которого происходит всё это построение, то вы очень быстро перейдете на любую абстракцию и будете спокойно ее использовать.
Меня недавно спросили -"Как закреплять элементарные основы по JS (if, for, простые функции) на практике? откуда брать задания? с задачами на learn-javascript я более менее справляюсь, но этого мало."
Хочу написать для всех. Задайте себе вопрос: К чему вы идете? Вы хотите научиться решать задачки с Codewars или вы хотите устроиться в компанию и решать коммерческие задачи, тем самым зарабатывая деньги? Если ответ второй, то тогда начните с тестовых заданий в компании (или компанию, если есть такая, в которую вы хотите попасть). И пляшите от тестового задания. Всё, что вам необходимо знать и уметь для решения этой и подобных задач, с полным понимаем, того что вы делаете, и будет тем, куда вам необходимо прикладывать усилия. Про собеседования, на которых вас заставляют решать задачи, абсолютно никак не связанные с будущими задачами на работе - я промолчу.
В связи с этим, я решил помочь таким же как и я и создал базу тестовых заданий для frontend разработчиков. На данный момент она пополняется исключительно теми заданиями, которые присылали мне. По мере возможности, я буду ее пополнять. Я думаю, еще порядка 15-20 заданий, я в ближайшие дни туда выложу. Так же, приветствую пулреквесты. На гитхабе есть подобный репозиторий, но там очень мало тестовых, и в основном задания от крупных компаний. Но ведь больше как раз маленьких компаний, и было бы хорошо +- понимать, какие тестовые могут быть в этой компании и вообще, какие навыки и знания будут требоваться при работе там, с учетом особенности сферы и т.д. С другой стороны это позволит работодателям не расслабляться и постоянно менять тестовые. Дабы действительно брать на работу только тех, кто решил задачу, а не тех, кто скопировал решение из чужого репозитория или канала на ютубе, а потом будет сидеть и тупить на работе.
Что же касается моего развития, то я публично выкладываю материалы, которые я закончил изучать. Можете смело глядеть и подбирать для себя то, что хотите. У меня вкус хороший, надеюсь.
Всем профессионального роста и силы. Не забывайте, что мир сам по себе тайна, которую стоит раскрыть для себя. Не капсулируйте весь мир в одной плоскости!
Читайте также: