
Как посмотреть партиции таблицы oracle
Обновлено: 03.07.2024
Как лучше всего партиционировать существующую таблицу, которая уже содержит большой объем данных ?
1) Создать новую партиционированную таблицу и залить данные из старой
CREATE TABLE . PARTITION BY (RANGE).
INSERT INTO . SELECT * FROM not_partitioned_table;
или
INSERT /*+ append */INTO . SELECT * FROM not_partitioned_table;
2) Создать новую партиционированную таблицу из старой таблицы
CREATE TABLE partitioned_table
PARTITION BY (RANGE) .
AS SELECT * FROM not_partitioned_table;
3) С помощью EXCHANGE PARTITION
ALTER TABLE partitioned_table
EXCHANGE PARTITION calls_01012008
WITH TABLE not_partitioned_table;
4) С помощью пакета DBMS_REDEFITION
Во всех вышеперечисленных вариантах партиционирования существующей таблицы для активной системы по любому понадобится даунтайм таблицы, кроме 4 пункта(использование DBMS_REDEFINITION).
Теперь, попробую более подробно описать каждый из вариантов.
Скажем, у нас есть партиционированная таблица NOT_PARTITIONED_TABLE, в которой хранятся данные о звонках.В итоге, у нас есть непартиционированная таблица NOT_PARTITIONED_TABLE с 1 миллионом записей о звонках с 1 по 7 января 2008 года:Наша цель: партиционировать эту таблицу с наименьшим даунтаймом таблицы.
Вариант 1: Создать новую партиционированную таблицу и залить данные из старой
План действий такой:
- Создаем новую партиционированную таблицу
- Можно заблокировать непартиционированной таблицу, чтоб никто не смог изменить данные во время заливки
- Заливаем данные из непартиционированной таблицу
- Удаляем непартиционированную таблицу
- Переименовываем новую партиционированную таблицуПеред заливкой заблокируем таблицу в режиме EXCLUSIVE командой LOCK TABLE, чтоб пока мы заливаем данные, никто не смог изменить данные в них или добавить новые.Теперь зальем данные командой INSERT. Сперва посмотрим заливку обычным INSERTом:Заливка 1 миллиона записей длилась почти 8 минут. Инсерт сгенерил 35 909 076 байт redo - это почти равно размеру непартиционированной таблицы, таблица весит 33 554 432 байт.Теперь попробуем залить те же данные прямым инсертом (direct path insert), командой INSERT /*+ APPEND */.
Direct Path Insert отличается от обычного инсерта тем, что вставка происходит:
1) в обход буферного кеша
2) новые блоки добавляются за отметкой HWM
То есть новые блоки данных подготавливаются в pga сессии и в обход буферного кеша добавляются ЗА отметкой HWM , если даже до отметки HWM есть свободное место для данных. Как объясняет Том Кайт, неправильно считать, что при таком инсерте (direct path insert) вообще не генерится redo. Redo по-любому генерится, но совсем малюсенький по сравнению с обычным инсертом, что существенно увеличивает скорость заливки.
После таких заливок следует сделать полный бэкап базы на всякий случай.Заливка "инсерт аппендом" закончилась за 3 минуты (почти в 3 раза быстрей обычного инсерта), и сгенерил 343352 байтов redo (почти в 100 раз меньше чем при обычном инсерте).
В три раза быстрей чем обычный инсерт, но как можно еще как-то ускорить заливку? Есть один способ: можно заранее выделить необходимый объем экстентов партициям , чтоб во время заливки на это не тратилось время.После предварительного выделения эктентов партициям, инсерт аппенд отработал всего за 5 секунд. А обычный инсерт отработал за 11 секунд:Для ускорения заливки и уменьшения даунтайма таблицы, можно заранее выделить необходимые эктенты партициям, чтоб во времы заливки на эту рекурсивную операцию не тратилось время.
Теперь осталось удалить старую таблицу и переименовать партиционированную таблицу.Можно и партиции переименовать (но их можно было бы создать с нужным именем изначально):
В следующие варианты - в следующем выпуске новостей.

В этой части статьи рассматриваются особенности создания секционированных таблиц, в следующей речь пойдет об особенностях перевода существующих больших несекционированчых таблиц в секционированные таблицы, а также особенности секционирования индексов и работа с секциями.
Задачи, решаемые секционированием
Прежде чем приступить к секционированию, надо четко определить задачи, которые предполагается решить
- Первой и наиболее часто решаемой задачей при секционировании является повышение производительности работы SQL-запросов и DML-операций по модификации строк таблицы. Это достигается за счет того, что поиск и модификация строк в таблице идут не по всей таблице, а только в ее части (в одной или нескольких секциях). Кроме того, разбиение таблицы на секции позволяет увеличит скорость обработки таблицы за счет использования параллелизма.
- Вторая задача, которая нашла широкое применение в нашей организации, - это быстрое удаление значительного числа строк в больших таблицах за счет выполнения операции truncate секций. Другим широким применением секционирования является освобождение табличного пространства, занимаемого таблицей, после удаления строк из таблицы командой delete. Использование команд Shrink (сжатие таблицы) или Move (перемещение в табличное пространство) для освобождения табличного пространства в большой несекционированной таблице может занимать значительное время. В секционированных таблицах выполнение таких команд в пределах секции будет выполниться существенно быстрее.
- Третьей задачей секционирования является разбиение большой таблицы на оперативную и архивную части. Особенно это эффективно, если оперативная часть в виде секции интенсивно пополняется и модифицируется, а архивная часть (секции) менее подвержена изменениям, и существенно реже из нее извлекается информация. Строки таблицы из оперативной секции со временем могут быть переведены в архивные секции, при этом архивные секции могут периодически очищаться.
- Четвертой задачей является существенное снижение конкуренции за строки и индексы таблицы, в том числе уменьшения вероятности блокировок. Так в результате секционирования одной из таблиц по HASH-методу полностью была решена задача множественных блокировок, возникающих в таблице.
- Пятой задачей является обеспечение устойчивости функционирования таблиц. Поскольку секция - это поименованный самостоятельный фрагмент памяти на дисках, то при возникновении проблем в одних секциях другие продолжают успешно функционировать. Устойчивости функционирования способствует также хранение секций в различных табличных пространствах и на различных физических носителях. Это особенно важно для таблиц, которые обеспечивают работу множества других таблиц (например. справочники, к которым идет интенсивное обращение). Кроме того, секционирование позволяет осуществлять независимое копирование и резервирование секций, оперативное восстановление секций, а также возможности более быстрой и более частой перестройки индексов наиболее активной секции, не затрагивая индексы пассивных секций.
Ключ секционирования
Следующим важным шагом в создании секционированной таблицы является определение ключа секционирования. В качестве ключа секционирования может выступить столбец или несколько столбцов, относительно значений которых будет делаться разнесение таблицы на секции. К потенциальным столбцам для создания ключа секционирования относятся столбцы типа date (например, столбец created - дата создания строки или updated - дата изменения строки) для секционирования по методам Range и List . Столбцы типа number с высокой степенью уникальности значений хорошо подходят для секционирования по методам Range и Hash . Столбцы, имеющие список фиксированных значений, подходят для секционирования по списку List .
В Oracle 11g появилась возможность в качестве ключа секционирования использовать виртуальный столбец (virtual column), построенный на функции к реальному столбцу таблицы. Виртуальный столбец в действительности не хранится в таблице, а каждый раз вычисляется при обращении к нему во время ввода данных в таблицу. Для создания виртуального столбца используется фраза generated always as. после которой идет функция, выполняемая над реальным столбцом таблицы, а далее идет обязательная фраза virtual. Например, PARTID generated always AS (to_char(UPDATED,'MM')) virtual . Возможен вариант создания виртуального столбца более короткой фразой PARTID AS (to_char(UPDATED,'MM')) .
Увидеть, какой столбец в таблице виртуальный позволяет запрос:
Замечание. При вводе данных в таблицу с виртуальным столбцом следует указать в insert и values перечень столбцов, иначе будет ошибка ORA-00947: not enough value .
Методы секционирования таблиц
Секционирование повышает эффективность работы с таблицами и индексами
Выбранный ключ секционирования, как правило, определяет методы секционирования. В настоящее время имеются следующие методы секционирования таблиц:
- Range -секционирование по диапазону ключа,
- List - секционирование по списку ключа.
- Hash - хеш-секционирование,
- составное секционирование.
- интервальное секционирование.
- ссылочное секционирование,
- системное секционирование
Последние три появились в Oracle 11g. вместе с тем последние два у нас пока не нашли большого применения.
Секционирование методом Range по диапазону ключа
В практике секционирования по методу Range используем два вида секционирования: по диапазону дат и по диапазону значений.
Секционирование методом Range по диапазону дат
При секционировании этим методом нами используются секционирование по дням, месяцам и по годам. Секционирование этим методом покажем на примере таблицы HISTLG в схеме AIF. Ключом секционирования выступает столбец updated (дата корректировки строки), при этом секции создаются с шагом секций в один месяц. Команда создания секционированной таблицы create имеет вид:
В команде CREATE указаны табличное пространство TABLESPACE HSTDATA, в котором будет находиться таблица, метод секционирования и ключ секционирования PARTITION BY RANGE (UPDATED) , имена секций и максимальное значение диапазона ключевого столбца этой секции. Например, первая секция PARTITION PARTMM_2015_01 VALUES LESS THAN TO_DATE('01.01.20157DD.MM.YYYY') говорит о том, что все значения столбца update меньше 01.01.2015 попадут в первую секцию, а значения update меньше 01.02.2015 попадут во вторую секцию и т.д. В таблице создана последняя секция PARTITION PARTMM_MAX VALUES LESS THAN (MAXVALUE) , позволяющая при превышении значения ключа значения диапазона предпоследней секции размещать строки таблицы в эту последнюю секцию (это подстраховка на случай, если забыли создать новую секцию). Фраза COMPRESS определяет, что первая секция будет сжата.
Следует обратить особое внимание на последнюю фразу ENABLE ROW MOVEMENT , которая позволяет переходить строкам таблицы из секции в секцию. В отсутствии этой фразы Oracle выдаст ошибку. Переход строк по секциям может происходить автоматически при изменении значения ключа (например, столбец updated в результате операции update изменит значение на то. при котором он должен уже принадлежать другой секции) или может происходить специально, например, для перевода строк из оперативной секции в архивную секцию путем изменения значения ключевого столбца. Если не указали эту фразу при создании таблицы, то, чтобы избежать ошибки, следует выполнить команду ALTER TABLE ИМЯ ТАБЛИЦЫ ENABLE ROW MOVEMENT .
Увидеть секции таблицы можно по запросу:
А содержимое секции по запросу:
Секционирование методом RANG по диапазону значений
Секционирование по диапазону значений похоже на секционирование по диапазону дат, только вместо ключа по дате используется ключ по столбцу, принимающему числовое значение (желательно имеющее равномерное распределение по всему диапазону значений). Для этого хорошо подходит столбец с уникальным значением. Рассмотрим на примере той же таблицы AIF.HISTLG, секционированной выше по диапазону дат. В качестве ключа секционирования используется столбец ISN с уникальными значениями. Команда создания таблицы имеет вид:
где PARTITION BY RANGE (ISN) говорит о секционировании no RANGE при ключе секционирования ISN, интервал создания секции через 1000 значений.
Создание новой секции в секционированной таблице по методу Range
Каждый раз при создании секционированной таблицы возникает непростой вопрос: как создавать новые секции. До Oracle 11g было три варианта создания новой секции.
Первый вариант - это в команде create таблицы вручную создается множество секций (например, на несколько лет вперед). Однако, как показала практика, этот метод приводит к тому, что через несколько лет о том, что таблица была секционирована, могут забыть. Когда об этом вспоминают, то оказывается, что информация длительное время пишется в одну и ту же последнюю секцию THAN (MAXVALUE) . В результате секционированная таблица практически превратилась в обычную таблицу. В этой ситуации надо либо снова создавать новую секционированную таблицу, либо по команде Split разбивают последнюю секцию на несколько секций. Например, для таблицы AIF.HISTLG (секционированной по дате) команда Split по созданию новой секции PARTMM_2016_01 на основе расщепления последней PARTMM.MAX секции имеет вид:
Фраза UPDATE GLOBAL INDEXES обеспечивает исправность индексов после команды Split.
Второй вариант - создать процедуру, которая автоматически образует новую секцию. Такая универсальная процедура для секционирования по дням и месяцам была нами разработана. Данная процедура запускается Job Sheduler ежедневно для секционирования по дням или ежемесячно для секционирования по месяцам.
Данные процедуры успешно работают уже несколько лет, своевременно создавая новые секции. Основой процедуры являются представление ALL_TAB_PARTITIONS ДЛЯ поиска последней секции таблицы и команда Split для расщепления этой секции по команде ALTER , указанной выше.
Третий вариант (разработан нашими специалистами и успешно применяется в течение несколько лет) - это создание секционированной таблицы с секциями, используемыми по циклу. Под секционированием таблиц по циклу понимаются секционирование, выполненное в соответствии с двумя правилами. Первое правило - таблица должна содержать фиксированное количество секций, равное либо максимальному числу дней в месяце (31 секция), либо максимальному число дней в году (366 секций), либо числу месяцев в году (12 секций). Второе правило: данные в одну и ту же секцию попадают с определенной периодичностью (цикличностью).
Например, в следующем году информация за январь пишется снова в ту же секцию января, что и в прошедшем году. При этом секции чистятся от прошлогодней информации. Преимущество этого метода в том, что не надо создавать новые секции.
В Oracle 11g появилась новая замечательная возможность автоматического создания секций с использованием при создании таблицы фразы INTERVAL (такой подход называется интервальное секционирование Interval Partitioning). Тогда при создании секций методом Range по интервалу дат с использованием фразы Interval команда создания секционированной таблицы примет вид:
где фраза INTERVAL (INTERVAL '1' MONTH) указывает, что секции будут автоматически создаваться каждый месяц (та же фраза может иметь вид INTERVAL (NUMTOYMINTERVAL (1. 'MONTH') . Для секционирования по дням используется фраза INTERVAL (INTERVAL '1' DAY) , а по годам - INTERVAL (INTERVAL '1' YEAR) . При автоматическом создании секций методом Range по интервалу значений с использованием фразы Interval команда создания таблицы примет вид:
где фраза INTERVAL(1000) задает режим автоматического создания секции через 1000 значений ISN.
Следует учесть, что новые секции создаются в процессе ввода данных. Следует также иметь в виду, что имя новой автоматически создаваемой секции будет иметь вид SYS_PNNNNN, например, SYS_P28981. При этом при интервальном секционировании не нужно создавать последнюю секцию VALUES LESS THAN (MAXVALUE) . иначе появится ошибка ORA-14761.
Таким образом, в Oracle 11g у команды create создания секционированной таблицы существенно меньшее число строк, а о создании новой секции своевременно позаботится Oracle.
Секционирование по списку ключей LIST
Секционирование по списку применяется, если есть возможность указать конкретный перечень дискретных значений столбца, по которому происходит разбиение на секции. При секционировании по LIST в команде create указываются метод секционирования LIST (PARTITION BY LIST) , ключ секционирования и имена секций, в которых указывается одно или несколько дискретных значений.
В качестве примера проведем секционирование таблицы AIF.AGREEM. используя в качестве ключа виртуальный столбец partid. При каждом вводе строки в таблицу в виртуальном столбце формируется числовой номер месяца по функции to_number(to_char(updated,'MM')) . Таблицу разбиваем на 12 секций, кроме того, используем подход секционирования по циклу, когда в следующем году строки января вводятся в ту же секцию января, а перед этим секция за январь чистится от старых данных по delete или по truncate. Команда создания секции примет вид:
Вместо виртуального столбца может быть введен реальный столбец partid (тип number) , заполняемый при вводе строки в таблицу. Указанный выше вариант эффективно использовался в таблицах как с 366 секциями, так и с 12 с очисткой последних по truncate, поскольку информация в таблицах хранится меньше года. Достоинство этого подхода в том, что создавать новые секции не приходится, а табличное пространство старых секций ежемесячно быстро освобождается по truncate .
Замечание. Если необходимо очистить табличное пространство секции, то используются либо команды сжатия SHRINK , либо MOVE (перемещения в табличное пространство):
Другие стандартные варианты секционирования по методу LIST изложены в различных источниках.
Хеш-секционирование HASH
Как правило, если не получается секционировать по диапазону RANGE или LIST , то применяется хешсекционирование, основанное на хеш-функции. В этом случае строки таблицы равномерно распределяются между секциями на основании внутренних алгоритмов хеширования Oracle. При этом чем уникальнее значения столбца в таблице, по которому идет секционирование, тем лучше будет распределение данных по разделам. Первичный ключ или уникальный столбец (столбцы) является самым хорошим хеш- ключом. Oracle рекомендует число секций N как степень 2, т.е. N=2,4,8,16,32 и т.д. При этом добавление или удаление какой-то хеш-секции вызывает перезапись всех данных в другие секции. Рассмотрим HASH секционирование на примере индексноорганизованной таблицы LISTIN. Целью HASH секционирования таблицы было добиться существенного снижение числа блокировок, возникающих в этой таблице. Эта цель была успешно реализована за счет секционирования таблицы по 16 секциям (фраза PARTITIONS 16 ), где ключом секционирования выступал столбец TASKISN. Команда создания таблицы имеет вид:
Следует заметить, что если в качестве ключа секционирования используется столбец, в котором имеем очень неравномерное распределение значения столбца (малая уникальность), то применение хеш-секционирования не целесообразно. При этом число секций не имеет особого значения, поскольку все значения ключевого столбца «свалятся» в одну-две секции.
Замечание. Увидеть размер секций в mb по всем указанным выше методам можно по запросу:
Составное секционирование
При составном секционировании внутри секции создаются подсекции Однако в версиях до Oracle 11g смешанное секционирование разрешалось только по RANGE методу для секции и методам HASH или LIST для подсекции. В Oracle 11g варианты методов секций-подсекций были существенно расширены, и в настоящее время можно осуществлять составное секционирование в следующих комбинациях: Range-Range, Range-Hash , Range-List, List-Range, List-Hash или Ust-List. Надо отметить, что при составном секционировании данные физически хранятся в подсекциях, а секции высту-пают только в роли логических контейнеров.
Рассмотрим смешанное секционирование на примере таблицы платежей AIF.PAY_ORD_RECORD с делением таблицы на секции по методу RANGE , а на подсекции по методу LIST . Ключом секционирования по секциям выступает столбец PAY_DATA (тип date), а ключом секционирования подсекции выступает столбец STATUS (тип number), принимающий три значения: 0. 1,2. Команда создания секционированной таблицы в Oracle 11g с секционированием по месяцам примет вид:
где разбиение по секциям задает фраза PARTITION BY RANGE (PAY_DATA) , а по подсекциям фраза SUBPARTITION BY LIST (STATUS) . Далее идет список подсекций со своими значениями: STATUS_0 VALUES (0) . STATUSJ VALUES (1) . STATUSJ? VALUES (2) . Для каждой подсекции может быть задано свое табличное пространства, которое может отличаться от табличного пространства таблицы HSTDATA. С гомощью предложения SUBPARTITION TEMPLATE один и тот же набор подсекций будет автоматически использоваться во всех секциях. Однако создание подсекций можно сделать вручную, указав все подсекции для каждого секции. Просмотреть созданные подсекции по имени таблицы можно по запросу:
Системное секционирование (system partitioning)
Появилось в Oracle 11 g и применяется, как правило, для таблиц, которые не могут быть секционированы никакими другими методами. В этом методе Oracle сам управляет, какую строку таблицы в какую секцию помещать. Для этого метода необходимо просто написать название секций, например, секции Р1, Р2, РЗ:
Увидеть разбиение таблицы на секции можно по запросу:
Увидеть метод секционирования, что он именно SYSTEM , можно по запросу:
Следует заметить, что для правильного ввода данных в таблицу надо, помимо имени таблицы, указать еще имя сегмента, иначе будет ошибка ORA-14701 . Тоже для ускоренной выборки данных по запросу следует указать имя сегмента.
Замечание. В таблице подвергнуться секционированию может не только сама таблица, но и индексы таблицы. В силу объемности и важности материала о секционировании индексов пойдет речь во второй части. Там же будет рассказано об особенностях перехода от несекционированных больших по объему таблиц к секционированным таблицам, в том числе о возникающих в этих случаях особенностях поведения индексов, триггеров, синонимов и т.д. этих таблиц.

В Oracle Database 11g выбор способа секционирования теперь практически не ограничен.
"Разделяй и властвуй" ("Divide and conquer") — этот фигуральный принцип никогда не был проиллюстрирован лучше, чем в возможностях секционирования в Oracle Database. Начиная с версии 8, таблицу или индекс можно разделить на несколько секций, которые затем поместить в различные табличные пространства. Таблица по-прежнему является логической сущностью, в то время как отдельные секции хранятся как отдельные сегменты, что позволяет легко манипулировать данными.
В версии 11 такие новшества, как: ссылочное секционирование (reference partitioning), интервальное секционирование (interval partitioning), секционирование по виртуальным столбцам (partitioning virtual columns) и расширенное смешанное секционирование (extended composite partitioning), дают безграничные возможности проектирования и обеспечения управления секциями.
Расширенное смешанное секционирование (Extended Composite Partitioning)
При смешанном секционировании — эта схема известна с Oracle8i Database — можно создавать подсекции секций, позволяя ещё больше измельчать таблицу. Однако в этой версии можно было создавать подсекции таблиц с диапазонными секциями только хэш-методом. В Oracle9i смешанное секционирование было расширено включением диапазон-списка подсекций.
Эти схемы удовлетворяет большинству случаев, но не всем. Допустим, например, есть таблица SALES, у которой много столбцов, включая два специальных - кандидатов для секционирования:
Пользователи запрашивают данные таблицы, отбирая их по обоим столбцам на равенство, и требования к архивированию также основаны на этих двух столбцах. Когда вы постигните принципы секционирования, то поймёте, что эти столбцы являются хорошими кандидатами на ключи секционирования.
В Oracle Database 11g можно решить проблему очень легко. Эта версия не ограничена смешанным секционированием по схеме диапазон-хэш или диапазон-список. Напротив, выбор совершенно неограничен, вы можете создавать смешанные секции в любых комбинациях.
В этом примере можно выбрать LIST-секционирование таблицы по product_code, так как этот столбец имеет более дискретные значения, а затем создать подсекции по state_code также по списку. Приведенный ниже код примера показывает, как это сделать:
Варианты не ограничиваются теми, что здесь показаны. Можно также создать смешанные секции LIST-RANGE. Предположим, что в примере выше код продукта не дискретный, а выбирается из некоего диапазона. Вы можете создать секции по списку по столбцу state_code, а затем подсекции по product_code. Ниже приведен код, который демонстрирует это.
Можно создать смешанные подсекции типа диапазон-диапазон, которые будут очень полезны, когда имеются два поля-даты. Рассмотрим, например, таблицу для системы обработки продаж, в которой есть дата транзакции и дата доставки. Можно создать секции по диапазону одной даты и также подсекции по диапазону другой. Эта схема позволяет выполнять резервное копирование, архивирование и очистку, основываясь на этих датах.
Как итог, в Oracle Database 11g можно создавать следующие типы смешанных секций:
- Диапазон-диапазон (Range-range)
- Диапазон-хэш (Range-hash)
- Диапазон-список (Range-list)
- Список-диапазон (List-range)
- Список-хэш (List-hash)
- Список-список (List-list)
Ссылочное секционирование (Reference Partitioning)
Вот типичная проблема в проектировании схем секционирования: не все таблицы имеют одни и те же столбцы, которые нам нужны для секционирования. Предположим, вы создаёте систему продаж с двумя простыми таблицами sales и customers:
Таблица sales создана, как показано ниже. Это подчинённая таблица для таблицы customers.
В идеале надо бы секционировать таблицу sales так же, как таблицу customers: секции по списку значений столбца rating. Однако возникает серьёзная проблема: в таблице sales нет столбца rating! И как же секционировать её по несуществующему столбцу? В Oracle Database 11g можно использовать новую возможность Reference Partitioning (Ссылочное секционирование). Вот пример, показывающий, как применить эту возможность к таблице sales:
create table sales ( sales_id number primary key, cust_id number not null, sales_amt number, constraint fk_sales_01 foreign key (cust_id) references customers ) partition by reference (fk_sales_01);
В этом случае создаются секции, идентичные таблице-мастеру, то есть customers. Заметьте, что столбца rating по прежнему нет, хотя таблица секционирована именно по этому столбцу. В выражении partition by reference (fk_sales_01) указано название внешнего ключа в описании секции. Oracle Database 11g показывает, что секционирование выполнено по схеме мастер-таблицы (parent table) — в данном случае, customers. Заметьте, что ограничение целостности по столбцу cust_id — NOT NULL; это требование к ссылочному секционированию.
Проверим границы секций таблицы sales:
Значение high value пусто, а это означает, что границы наследуются из мастер-таблицы. Секции имеют такие же названия, как и у мастер-таблицы. Тип секционирования можно проверить, выполнив запрос по представлению user_part_tables. Специальный столбец ref_ptn_constraint_name показывает название ограничения целостности для внешнего ключа.
Применение ссылочных секций весьма полезно, когда нужно секционировать подчинённую таблицу так же, как мастер-таблицу, но в подчинённой таблице нет тех же столбцов, и вы не хотите создавать их исключительно ради секционирования. В этом случае нет необходимости явно объявлять длинное выражение для секционирования каждой подчинённой таблицы.
Интервальное секционирование (Interval Partitioning)
Интервальное секционирование позволяет создавать секции, основанные на диапазонах значений столбца-ключа секционирования. Вот пример таблицы с интервальным секционированием:
Очевидно, что перед тем, как вставлять запись, необходимо добавить секцию за март 2007. Однако часто это легче сказать, чем сделать. Иногда нет возможности предусмотреть создание множества секций заранее, и некоторые из них могут возвращать эту ошибку.
Не проще ли будет, если бы Oracle как-нибудь автоматически распознавал необходимость новых секций и создавал их? Oracle Database 11g это умеет делать для механизма Interval Partitioning (интервального секционирования). В примере ниже определяются не секции и их границы, а только интервал, который определяет границы каждой секции. Вот демонстрационный пример такого интервального секционирования:
Заметьте, что интервал следует за интервалом. Это из инструкции Oracle по созданию интервалов для каждого месяца. Создаётся также начальная секция p0701 для января 2007. Теперь предположим, что вставляется запись за июнь 2007:
Oracle не возвращает ошибку; наоборот, он успешно выполняет предложение. И где же тогда находится вставленная запись? Секция p0701 не может содержать такую запись, а секция за июнь 2007 не описывалась. Однако проверим секции таблицы ещё раз:
Заметьте, что секция SYS_P1 с верхним значением 1 июля 2007 будет накапливать данные до конца июня. Эта секция создана динамически Oracle и имеет имя, сгенерированное системой.
Теперь предположим, что вводится значение меньше максимального, например 1 мая 2007. Оно идеально соответствует его собственной секции, так как секционный интервал — это месяц.
Заметьте, что новая секция SYS_P42 имеет верхнюю границу 1 июня — такая секция может содержать данные за май 2006. Эта секция создана делением секции SYS_P41 (за июнь). Таким образом, Oracle автоматически создаёт и управляет секциями, когда описана схема интервального секционирования. Если секции необходимо создавать в отдельных табличных пространствах, следует использовать выражение store in:
тогда секции сохраняются в табличных пространствах TS1, TS2 и TS3 по очереди по кругу.
Как разработчик приложения может обратиться к какой-либо секции? Один из известных способов — по названию — может быть невозможным и даже часто приводящим к ошибкам, как вы знаете. Для обеспечения доступа к некоторой секции Oracle Database 11g предлагает новый синтаксис запросов:
Заметьте, что новое выражение for (значение) позволяет напрямую ссылаться на секции без явного обращения по их точному названию. Если необходимо очистить или удалить секцию, можно использовать этот дополнительный синтаксис.
Когда таблица создана так, как показано выше, столбец PARTITIONING_TYPE представления DBA_PART_TABLES показывает значение INTERVAL.
Системное секционирование (System Partitioning)
Хотя Oracle предполагает, что лишь немногие будут использовать на практике эту возможность, я хочу описать её, потому что очень уж она хороша.
Это редкое, но не невообразимое применение: представьте, что у вас есть таблица, которая не может быть секционирована никаким логическим путём. В итоге – огромная монолитная таблица, которая озадачивает такими проблемами, как необходимость расширенного индексирования и других операций.
Поэтому разработчики могут принять следующее решение: они обещают, что если как-нибудь таблицу можно будет секционировать, то они по-умному создадут секции. А пока приложение само управляет, какую запись в какую секцию помещать. Администратору базы данных необходимо просто описать секции. Например:
Заметьте, что не описано ни ключей секционирования, ни границ. Поэтому таблица физически разделена на два сегмента, хотя это целая логическая таблица. Когда описан такой метод, база данных создаёт два табличных сегмента вместо одной монолитной таблицы. Это можно проверить:
Когда создается локальный индекс, он секционируется таким же способом.
Тип секционирования можно проверить по user_part_tables:
Результат показывает SYSTEM, что, конечно же, обозначает системное секционирование. Отметим то обстоятельство, что столбец high_value имеет значение NULL для таблиц такого типа.
А вот интересный вопрос: если нет ключа или схемы секционирования таких, как диапазон, список или хэш, то как Oracle узнает, в какую секцию поместить входящую запись?
Ответ: Oracle этого не делает. Вот пример того, что происходит, если необходимо вставить запись в таблицу:
Границы секций неизвестны, поэтому приложение должно обеспечить эту информацию, используя секция-подобный синтаксис при вставке данных. Предложение необходимо переписать:
При удалении не обязательно использовать этот синтаксис — но помните, границы секций отсутствуют. Поэтому при выполнении предложения типа:
Oracle должен просканировать все секции, чтобы увидеть, где расположена строка. Чтобы этого избежать, следует написать так:
Также выполняются и изменение данных. Такой способ ограничивает перечень секций, по которым выполняется поиск.
Системные секции имеют гигантские преимущества, когда таблица не может быть секционирована никаким логическим путём. Они позволяют использовать преимущества секционирования, позволяя освободить разработчиков от решения, в какую секцию помещать запись.
Табличное пространство транспортируется с одной секцией
В ранних версиях Oracle Database появилась возможность перемещать табличное пространство, а потом подключать его к различным базам данных или к той же самой. Процесс заключается в копировании файлов данных, поскольку это самый быстрый способ перемещения данных между базами данных. Однако до настоящего времени не было возможности перемещать табличное пространство с одиночной секцией, а затем подключать его обратно. В Oracle Database 11g это можно.
Предположим, что есть таблица SALES5 с секциями CT, NY и т.д.
Теперь необходимо переместить секцию CT с помощью команды, показанной ниже:
Теперь можно взять два файла — p_ct.dmp и ts1_01.dmp — и в другой системе попытаться подключить их к базе данных. Для изучения давайте попробуем подключить их к той же самой базе данных. Сначала нужно удалить таблицу, а затем табличное пространство ts1.
Теперь подключим табличное пространство к базе данных. В этом месте, однако, возникает небольшая проблема: таблица sales5 больше не существует, а экспортирована была только одна её секция (ct), а не вся таблица. И как же теперь импортировать эту секцию несуществующей таблицы? В Oracle Database 11g имеется новая опция утилиты командной строки Data Pump Import с называнием partition_options, которая делает это возможным. Если указать значение departition, то Data Pump создаст новую таблицу из экспортированной секции. По ходу дела он "удаляет" секции, поэтому и называется соответственно десекционированием. Давайте посмотрим, как этот прием работает.
Это SQL-предложение создаёт таблицу sales5_ct, которая ни что иное, как секция ct таблицы SALES5, экспортированной ранее в транспортируемом табличным пространстве. Название таблицы, как можно видеть, — это комбинация названий таблицы и секции. Наличие соответствующего сегмента можно увидеть в представлении DBA_SEGMENTS.
Возможность транспортирования табличных пространств с одиночной секцией можно использовать для подключения таблицы к другой базе данных. После подключения можно выполнить операцию обмена секциями, чтобы преобразовать её в секцию какой-либо таблицы.
Секционирование по виртуальным столбцам (Partitioning on Virtual Columns)
Давайте рассмотрим другую распространённую проблему. В таблице sales есть следующие столбцы:
Предположим необходимо секционировать эту таблицу по такой схеме, которая позволяет очищать и архивировать секции в зависимости от количества продаж. Есть четыре категории продаж:
Эту таблицу необходимо секционировать по столбцу sale_category, но вот проблема: столбца sale_category нет. Он в основном зависит от столбца sale_amt. И как же можно секционировать эту таблицу?
В ранних версиях Oracle нужно было добавить в таблицу столбец sale_category и использовать триггер для заполнения столбца, используя логику, показанную в таблице. Однако наличие этого нового столбца повлияет на производительность вследствие работы триггера.
В Oracle Database 11g новая возможность Virtual Columns (виртуальные столбцы) позволяет создать столбец, который не хранится в таблице, а вычисляется во время работы. По этому столбцу можно также выполнять секционирование. Использование этой возможности слегка «покачает» секционирование этой таблицы.
Теперь при попытке вставить записи получаем:
Каждая запись помещена в соответствующую секцию.
Секционирование по виртуальным столбцам позволяет создавать секции, которые имеют смысл в бизнесе, даже если самого столбца не существует. Здесь использовалось очень простое вычисление по виртуальному столбцу, однако оно может быть настолько сложным, насколько вам понадобится. В таких случаях секционирование по виртуальным столбцам становится ещё более полезным.
Советчик по вопросам секционирования (Partition Advisor)
Надо полагать, что больше всего споров при проектировании секционирования возникает при выборе схемы секционирования и столбца (-ов) секционирования. Пусть эта задача лучше достанется бывалым профессионалам, занимающимся всесторонним анализом рабочей нагрузки, но даже они могут сделать это не правильно. Вы в Oracle Database 11g же получите помощь от нового советчика Partition Advisor (советчик по вопросам секционирования), который анализирует данные и методы доступа применительно к предполагаемым схемам секционирования. Об этом инструменте можно больше прочитать в руководстве по его инсталляции.
Заключение
- Ссылочное секционирование позволяет синхронно разделать на секции связанные таблицы одной базы данных, даже если столбцов нет в подчинённых таблицах.
- Интервальное секционирование реализовано так, как было весьма желательно в действиях «сделал-и-забыл» (fire-and-forget) — описывается интервал, и Oracle в дальнейшем берёт на себя заботу по поддержке.
- Расширения смешанного секционирования до диапазон-диапазон (range-range), список-диапазон (list-range), список-хэш (list-hash) и список-список (list-list) демонстрируют новые возможности большей свободы выбора секционирования и управления им.
- Data Pump теперь позволяет перемещать и подключать одиночную секцию таблицы; возможность, которая очень полезна в архивировании и хранении.
- Наконец, можно спроектировать наилучшую из возможных стратегий секционирования, которая отражает бизнес-потоки путём секционирования по виртуальным столбцам.
Стратегия "Разделяй и властвуй" ("Divide and conquer") никогда не предполагает много вариантов выбора. Но представьте их себе как набор блестящих ножей для разделки тушки индейки на лучшие части!
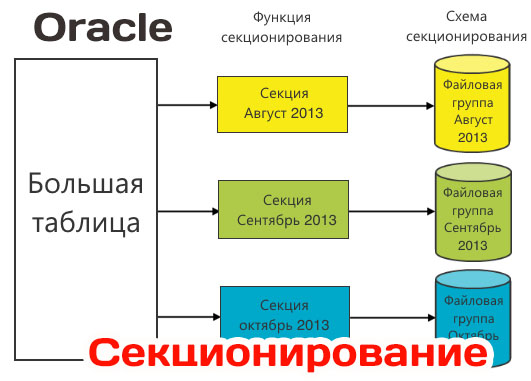
разделение таблицы или индекса на несколько логически связанных частей , фрагментов, секций с неким общим признаком.
Допустим , то есть у нас есть таблицы начислений , мы разбиваем эту таблицу на множество секций , например по начислениям за каждый месяц
Кому и зачем это нужно? Вопрос с секционированием таблиц, тесно связан с другим важным вопросом , вопросом масштабируемости проекта.
С помощью фрагментации появляется возможность управления фрагментами(секциями) в больших таблицах, то есть часть не нужных нам данных в текущий момент можно перенести на сторонний носитель.
Оставить для работы , для оптимального доступа к данным, только лишь необходимые нам в сейчас секции таблицы.
Так же очень часто возникает необходимость быстрого построения индекса по заданному фрагменту , а не по всей таблице , для решения данных задач в Oracle используется фрагментация.
Итак, для демонстрации перечисленных возможностей фрагментации подготовим небольшой тестовый пример
Для выполнения данного примера нам потребуется войти под пользователем с правами администратора .
Создадим три независимых табличных пространства, они нам понадобятся для демонстрационных примеров
Фрагментация таблиц
В Oracle используется три типа фрагментации(партицирования) для таблиц - это:
Фрагментация по диапазону значений
Данные относящиеся таблицы , где значения в заданных колонках относятся к некоторому диапазону распределяются по соответствующим фрагментам(секциям) таблицы
Например все проводки с 2001-2002 года , помещаются в первую секцию , за 2002-2003 во второй и так далее.
Фрагментация по списку значений
Фрагмент(секция) определяется по элементу списка , такой способ фрагментации идеально подходит , когда в заданной колонке используется ограниченное число значений.
Фрагментация с использованием хэш функции
По данным заданных столбцов таблицы , Oracle вычисляет значение специальной хэш функции на основании которого определяет в какой именно фрагмент таблицы поместить заданную запись
Совмещенный тип фрагментации
Или тип фрагментации совмещающий в себе фрагментацию с использованием хэш функции и фрагментации по диапазону значений
Синтаксис
Создания и фрагментации таблиц используется дополнительная синтаксическая конструкция в команде CREATE ТABLE – PATITION BY
Обычный синтаксис для создания ферментированной таблицы выглядит следующим образом
Специфика использования оператора SELECT для выбора данных из фрагментированных таблиц
С помощью оператора SELECT есть возможность выбирать как все данные из фрагментированной таблицы, так и
использовать SELECT для выбора данных из заданного фрагмента таблицы.
данный запрос выведет данные из фрагмента таблицы pt_3
Фрагментация по диапазону значений
Создадим таблицу проводок с фрагментацией по диапазону значений
Заполним таблицу проводок значениями
Выберем данные из таблицы
Следующий пример демонстрирует разбиение на фрагменты таблицу в зависимости года к которой принадлежит проводка
Следующий пример иллюстрирует использование фрагментации таблицы в зависимости от числового значения
Фрагментация с использованием списка значений
Создание таблицы
Фрагментация с использованием хэш-функции
Создадим таблицу проводок с фрагментацией по хэш функции
Заполним ее данными
Выберем данные из таблицы
А так же выполним оператор select для каждого из фрагментов(секций) таблицы
Смешанный тип фрагментации
Смешанный тип фрагментации предусматривает как ферментацию по диапазону значений так и дополнительную фрагментацию по хэш функции или фрагментацию по списку значений
Заполним таблицу pro_range_hash
Управление данными во фрагментах таблицы
Попробуем внести данные в таблицу ,которые не подходят по условиям ни в один из фрагментов(секций)
Сервер выведет ошибку
Ora-144000. Вставленный ключ секции не соответствует ни одной секции.
Изменим данные таким образом чтобы изменилась принадлежность записей к фрагменту
Получим ошибку обновление ключа секции прведет к ее изменению.
Как же сделать возможным перенос строк?
Для этого необходимо включить для выбранной таблицы опцию row movemen t
Выполним скрипт
выполним наш update повторно
на этот раз ошибок не было. Обновление строк в таблице прошло успешно.
А собственно ,зачем это все было необходимо? Как это применить?
У вас есть три табличных пространства, нам в данный момент нужна только оперативная информация по документам типа RR из таблицы pro_list в табличном пространстве номер TBLSP2 .
Отключим остальные табличные пространства и перенесем их на архивный диск.
Выполним запрос по таблице pro_list
Получим системную ошибку о том, что сегмент не может быть прочитан
Скорректируем запрос так как нам нужны только документы RR
Таким образом, применяя фрагментацию в больших таблицах с несколькими миллионами записей , всегда есть возможность освободить часть дискового пространстве и перенести неиспользуемые данные на архивный носитель
Читайте также: