
Как посмотреть температуру сервера в vmware
Обновлено: 06.07.2024
Недавно мы писали о распределении виртуальных ресурсов.
Мы теоретически рассчитали параметры Shares, Reservation и Limit.
Теперь самое время проверить, насколько корректно расставлены значения и как наши расчеты повлияли на производительность ВМ и узлов ESX.
Даже небольшой просчет в изменении параметров одной ВМ может привести к снижению производительности и даже отказу узла ESX. Вот почему важно постоянно держать под контролем производительность виртуальной среды.
Нам необходимо анализировать все параметры производительности ВМ и ESX-хостов и получать полную картину, необходимую для оптимизации и подстройки параметров виртуальной среды.
Помочь нам в этом могут системы управления и мониторинга.
Мы постарались классифицировать средства мониторинга и управления виртуальными средами и вывести общие рекомендации (рецепты) для управления виртуальной средой. Ниже мы представили подробные описания продуктов:
Почему работать лучше с нами?
Работаем без посредников , напрямую с VMware, Veeam;
Содержание:
Продукты мониторинга
| Название продукта | Плюсы | Минусы | Что можно увидеть с помощью этого инструмента | Насколько он пригоден для анализа, и как этот анализ провести |
|---|---|---|---|---|
| Management Assistant | Ведет автоматизированный мониторинг сети. | Изначально работает автоматизировано только с 1 хостом, для того чтобы велись логи всех хостов, придется писать многочисленные скрипты. | Поскольку vMA является средством сбора статистики, на выходе мы получаем .csv файл с многочисленными данными о сервере ESX и ВМ на нем. | vMa плохо пригоден для анализа, поскольку анализ должен осуществляться вручную с помощью Excel, Perfmon, Esxplot. |
| Veeam One | Обладает функцией мониторинга, составление технических и бизнес-отчетов. Лицензируется по процессорам, поэтому в случае использовании “легких” ВМ, будет выигрывать по цене. Удобный и простой в управлении. Присутствует поддержка на русском языке. Широко известен в России. | Лицензируется на процессор, в случае использовании “тяжелых” ВМ, будет значительно дороже других продуктов, которые лицензируются по кол-ву элементов мониторинга. Не поддерживает физическую инфраструктуру. Нет поддержки приложений. | Работает с виртуализацией от компании VMware, предоставляет метрики на основе собственного сбора информации о производительности системы и позволяет получить информацию, как для технических специалистов, так и для людей, принимающих решения. | Позволяет анализировать наиболее важные параметры. Не загружает пользователя ненужной информацией и настройками. |
| SpiceWorks | Бесплатный. Позволяет мониторить приложения. | Работает с виртуальной средой лишь косвенными методами. Мониторинг ВМ ведется из гостевой ОС. В результате отображает только параметры, характерные для физической среды. Заключения о работе гипервизора и ВМ можно сделать, только сравнивая параметры VSphere/VCenter с параметрами SpiceWorks. | Можно увидеть характеристики физической инфраструктуры, а также много рекламы. | Продукт создан для мониторинга физической среды. Средства анализа виртуальной инфраструктуры не развиты. Возможно в дальнейших версиях. |
| Orion VSP (SolarWinds) | Совместно с Orion NPM мониторит физическую среду. Совместно с продуктом Orion APM может мониторить приложения (Exchange, AD, SQL и т.д.). Есть лицензия на неограниченное количество элементов мониторинга. Поддержка Community. | Отсутствие поддержки на русском языке, нет представительства в России. Мониторинг приложений и физической среды осуществляется отдельными продуктами. | Отчеты мониторинга и анализа для виртуальной инфраструктуры (и ESX, и ВМ), для мониторинга физических серверов или приложений необходимо приобрести отдельные продукты. Характеристики и работа приложений. Характеристики и работы физических серверов. | В автоматическом режиме анализирует виртуальную инфраструктуру (а также физическую инфраструктуру и приложения), гибкая настройка получения предупреждений. Есть функция сканирования сервера VCenter и получения информации обо всей инфраструктуре для простоты добавления ESX хостов. |
| Whats Virtual (IpSwitch) | Встроенные средства мониторинга и анализа приложений, графическая информация предоставляется в режиме реального времени. Поддержка Community. Совместно с WhatsUpGold возможно мониторить физическую среду.Мониторинг распределенной инфраструктуры с минимально используемой полосой пропускания. | Не работает со службой Active Directory. Отсутствие поддержки на русском языке. Мониторинг физической среды осуществляется отдельным продуктом. | Выдает информацию по ВМ, ESX хостам, приложениям, а также имеет более 200 готовых шаблонов отчетов. Графики, информация на которых выдается в режиме реального времени. | Получает данные с VCenter сервер. С помощью графиков, изменяющихся в режиме реального времени, упрощается мониторинг и анализ инфраструктуры. |
| Zenoss Virtualization Monitoring | Автоматический поиск (Auto discovery) всех объектов мониторинга. Графическое представление систем мониторинга с точки зрения бизнеса. Мониторинг облачной структуры. 3D представление центра обработки данных. Не требует установки агентов на каждую из ВМ. Мониторинг приложений уже включен в продукт. Для мониторинга физической среды можно использовать Server Monitoring. | Не рассчитан на малые и средние предприятия, минимальный пакет для мониторинга – 200 объектов (ВМ, ESX хосты, приложения). Отсутствие поддержки на русском языке, нет представительства в России. Мониторинг физической среды осуществляется отдельным продуктом. | Карты, отображающие в режиме реального времени все филиалы компании и их статус. Бизнес информацию. Создание планов серверной, показывает сервера и их статус. Характеристики и работа приложений. Характеристики и работы физических серверов. | Технология авто обнаружения позволяет добавить объекты в систему мониторинга автоматически. Самостоятельно классифицирует объекты и строит их топологию. |
| VMware Vcenter Operations Enterprise | Присваивает каждому объекту рейтинг производительности. Интегрируется в VSphere Client. Создает отчеты по производительности, а также предлагает решения для проблемных объектов. Не требуется установки агентов на каждую из ВМ. Есть представительство в России. Предлагает значения параметров для Limits и Reservations. Производит мониторинг AD. Специально разработан для мониторинга виртуальной среды. | Кроме AD, не мониторит приложения. Нет мониторинга физической среды. | На основании рейтинга производительности каждому объекту соответствует цвет от зеленого (объект в порядке) до красного (объект требует срочного вмешательства). Также можно увидеть предложения по устранению проблем с объектами. | Упрощает мониторинг и анализ приложений, поскольку все действия будут происходить в централизованном интерфейсе (VSphere Client). Поскольку ставится плагином, нет необходимости “объяснять” ему нашу инфраструктуру, сканирует систему и находит ВМ и хосты автоматически. |
Описание продуктов
WhatsUpGold
Очень неудобное управление, так как вначале все настройки необходимо производить в 3 разных интерфейсах, а также использовать кучу всплывающих окон.
Все настройки для мониторинга производятся в отдельном интерфейсе, в то время как сам мониторинг производится в веб-браузере.

На следующем слайде показан интерфейс просмотра всей нашей инфраструктуры.
Также минусом это продукта является настройка параметров мониторинга.
Во-первых, необходимо выдать каждому объекту мониторинга (vCenter, VMs, ESX) учетные данные для доступа к гипервизору, операционным системам и прочим объектам управления, если таковые имеются (SSH, Telnet, SMNP, ADO и т.д.).
Во-вторых, каждому объекту мониторинга необходимо выставить параметры, которые он будет мониторить, то есть если нам необходимо следить за используемой памятью самой ВМ, это одно, а если необходимо просматривать используемую память каким-то приложением, следует выставить дополнительные параметры.
С одной стороны, это долго и сложно, с другой, после настойки системы (пару дней), мы получим полноценный продукт, мониторящий именно те параметры, какие нам нужны.
Например, на следующих двух слайдах показано использование памяти сервером VCenter и ESX соответственно.


На следующем слайде показаны службы управлением Reporting (создание отчетов и предоставление их в виде .html файлов).

Основными плюсами стоит выделить следующее:
Встроенный интерфейс управления VSphere, то есть отпадает нужда использовать VSphere Client, все инструменты в одном интерфейсе WhatsUpGold; Инструмент использования подключения по RDP-протоколу; Возможность подключения к Telnet, Task Manager прямо из продукта WhatsUpGold;Ну и в конце недостаток, который был замечен в нашей лаборатории: в веб-интерфейсе – самый медленный продукт, некоторые страницы (учитывая, что все продукты тестировались локально) открывались около 5-10 секунд.
Orion
Очень быстро устанавливается и настраивается.
После загрузки установщика, прошло около 10 минут, прежде чем мы смогли начать мониторить нашу инфраструктуру (у WhatsUpGold это заняло около часа).
В отличие от WhatsUpGold этот продукт без установки Orion APM не мониторит параметры “внутри” ВМ (производительность ОС, приложений), поэтому не нужно определять ему параметры для мониторинга.
Всё происходит автоматически, нужно лишь показать сервер VCenter (для WhatsUpGold нужно показать VCenter, далее настроить все учетные данные).
На следующих двух слайдах показано, как Orion отображает виртуальную среду и производительность сервера ESX для RAM.


Orion также имеет обширное кол-во шаблонов для отсылки отчетов как по почте, так и на принтер.

Разобраться в Orion гораздо проще, на всё уйдет не больше часу, в то время как в WhatsUpGold за это время вы не разберете и трети интерфейса.
С другой стороны, WhatsUpGold сразу предлагает обширный перечень услуг, в то время как Orion делится на Profiles (отдельные продукты для Storages, Virtual, Backup), поэтому выбирать вам.
vCenter Operations
В отличие от двух предыдущих продуктов VCenter Operations (VCOp) ставится как ova файл, с уже настроенным сервером, остается настроить его в плагинах VSphere Client. Помимо всего, VCOp имеет поддержку веб-интерфейса.
На следующих слайдах мы видим:



Своей технологии отчетности VCenter в комплектации Standard не имеет, но это ему и не нужно, прекрасный интерфейс встроен в сам VCenter Server, с помощью которого мы можем получать отчеты так, как мы их настроим.

Основным недостатком является то, что внутрь ВМ он в любой комплектации “смотреть”не умеет , то есть не будет производить мониторинг приложений операционной системы (исключение составляет служба AD).
Так как имеет свой собственный интерфейс, а точнее интерфейс vSphere Client, работает быстрее всех, то есть, нет задержек переключения между страницами. Подробнее об этом продукте можно посмотреть в обзоре VCenter Operations.
Veeam One
В отличие от всех предыдущих продуктов Veeam Monitor, а именно этот продукт занимается мониторингом и анализом сетевых ресурсов, управляется из-под собственного интерфейса, поэтому на всех компьютерах для мониторинга необходимо устанавливать Veeam Monitor Client.
Главный экран мониторинга (Dashboard) представляет собой процентное отображение параметров хостов в VCenter.

Основные графики и даже интерфейс очень схожи с интерфейсом в vSphere Client.

Но также присутствует более удобный централизованный вид просмотра и ряд метрик, не входящих в интерфейс vSphere Client.


Служба отчетов так же предоставляет передачу информации по e-mail, а также с помощью программы Reporter Viewer возможно создание удобных .xls файлов. В остальном, за отчеты отвечает отдельный продукт Veeam Reporter, также входящий в пакет Veeam One.

В отличие от других продуктов, возможно собирать новую информацию кнопкой Refresh не только по расписанию обновления, но и тогда, когда это будет нужно. Еще стоит отметить, что Veeam Monitor также как и WhatsUpGold умеет отображать дерево запущенных процессов в ВМ.
Репутация: 43
Cтаршой
лазил по интернету так и нечего не нашол

Репутация: 898
Старожил
Репутация: 43
Cтаршой
та нет))
да и сервер, это громко сказано))
блин может сразу переходить на что то другое, esxi начал напрягать. все бы ничего, но температуру хотелось бы увидеть
Репутация: 898
Старожил
та нет))
да и сервер, это громко сказано))
блин может сразу переходить на что то другое, esxi начал напрягать. все бы ничего, но температуру хотелось бы увидеть
Infrastructure Client
Раздел Configuration>Health Status
Репутация: 43
Cтаршой
раздел такой есть. но температуру не показывает
Репутация: 2927
ultra active user
вся проблема в том что это esxi
раздел такой есть. но температуру не показывает
Дык может не показывает потому "что да и сервер, это громко сказано))"
Есть там всё. В hardware status
Репутация: 139
Cтаршой
ESXi на линуксе же
ssh и man sensors
Дык может не показывает потому "что да и сервер, это громко сказано))"
Есть там всё. В hardware status
прикольно, у меня 4-й ESX и нету этой вкладки.
Репутация: 2927
ultra active user
Там всё и так есть, без особого шаманства
ЗЫ. Там хоть и шляпа, но обрезанная до жути. Набор команд минимальный. Всё под виртуализацию точено.
Репутация: 43
Cтаршой
Репутация: 2927
ultra active user
Репутация: 43
Cтаршой
» Нажмите, чтобы показать спойлер - нажмите опять, чтобы скрыть. «
Репутация: 2927
ultra active user
Выдели то, что у тебя 192.168.*.* - будет тебе то, что ты хотел.
Репутация: 43
Cтаршой
или я туплю где то.
везде уже перекликал)
Репутация: 2927
ultra active user
Или у тебя сервер эту информацию не выдаёт
Шо тебе сказать? Если эти данные критичны, а они таки критичны, ищи встраиваемую панель с термодатчиками. Что-то из такого и разбрасывай датчики на процессоры и часть платы с дросселями.
Репутация: 3001
Кошки-это хорошо
Репутация: 1097
Праведник

Всем привет сегодня я хочу затронуть тему, в которой мы рассмотрим мониторинг vmware, а конкретно ресурсов, кто их кушает и сколько, как посмотреть потребление ресурсов за месяц, были ли пики или наоборот полный простой. Тема очень актуальная, так как подразумевает правильную утилизацию ресурсов компании, и это очень правильно для бизнеса.
Для чего нужен мониторинг vmware
Самое основное назначение в мониторинге производительности хоста и виртуальных машин vmware, является рациональное использование ресурсов. В реалиях России, особенно в IT компаниях, которые предоставляют сервис или пишут свой софт, стоит огромная проблема, а именно разработчики толком не могут, сказать, сколько их сервису нужно ресурсов, сейчас или через пол года, на что приложение больше рассчитывает на операции чтения или записи, так как от этого зависит и структура дисковой подсистемы. Как следствие в более 70 процентов случаев, серверные мощности просто отданы за зря, хотя могли бы приносить пользу, для бизнеса.
Инструменты мониторинга vmware
Конечно вы можете поставить такие программные комплексы как Zabbix, полезно будет когда у вас в инфраструктуре очень много хостов виртуализации и виртуальных машин, если их не очень большое количество, то достаточно и штатных, встроенных средств в Vmware ESXi 5.5 и vCenter 5.5.
И так приступаем к практике, первым мы будем мониторить сам хост ESXi, для этого выбираем нужный сервер и переходим на вкладку Performance. По умолчанию у вас будет пункт Overview, с суммарной информацией, что происходит, в виде графиков, можно выбрать период, за который вам нужно отобразить графики (Time Range)
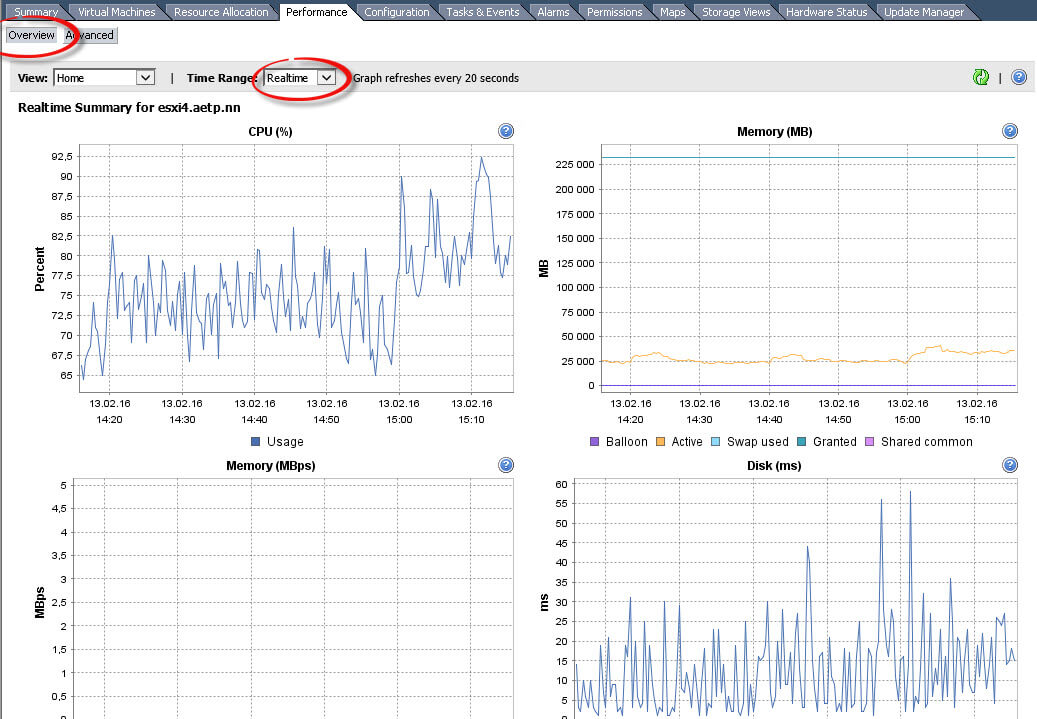
В итоге я отобразил данные за месяц, по всему хосту, в принципе удобно, но не понятно, что именно потребляет ресурсы, хочется какой то конкретики и для этого есть вкладка Advanced
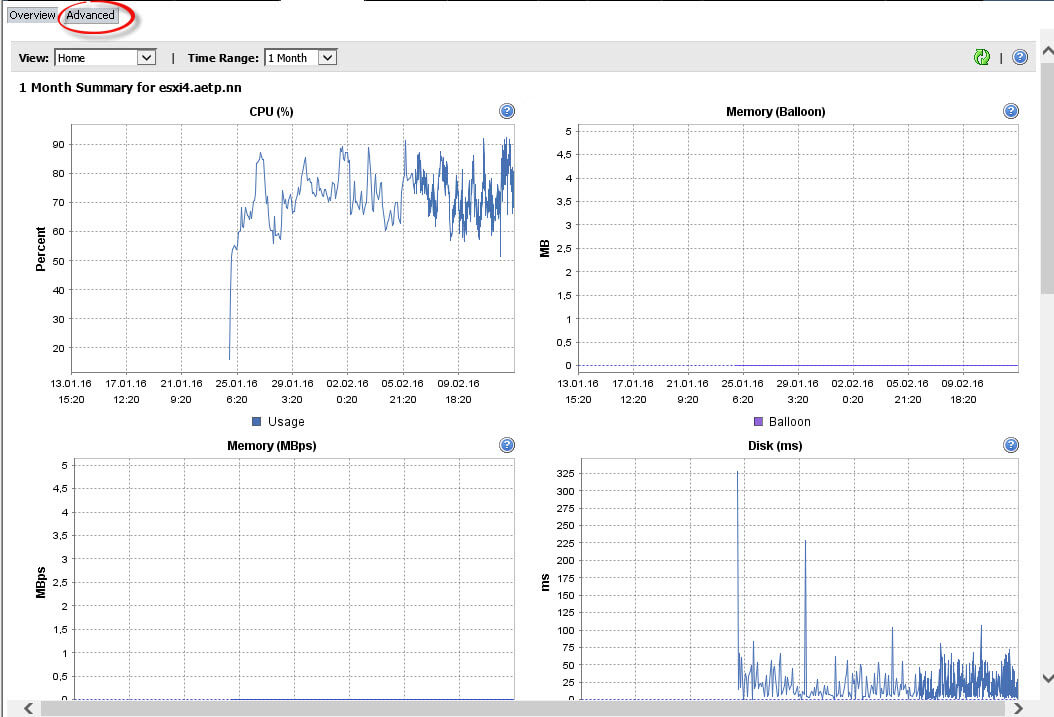
Вот так выглядит вкладка Advanced, тут уже более детально можно смотреть потребление ресурсов.
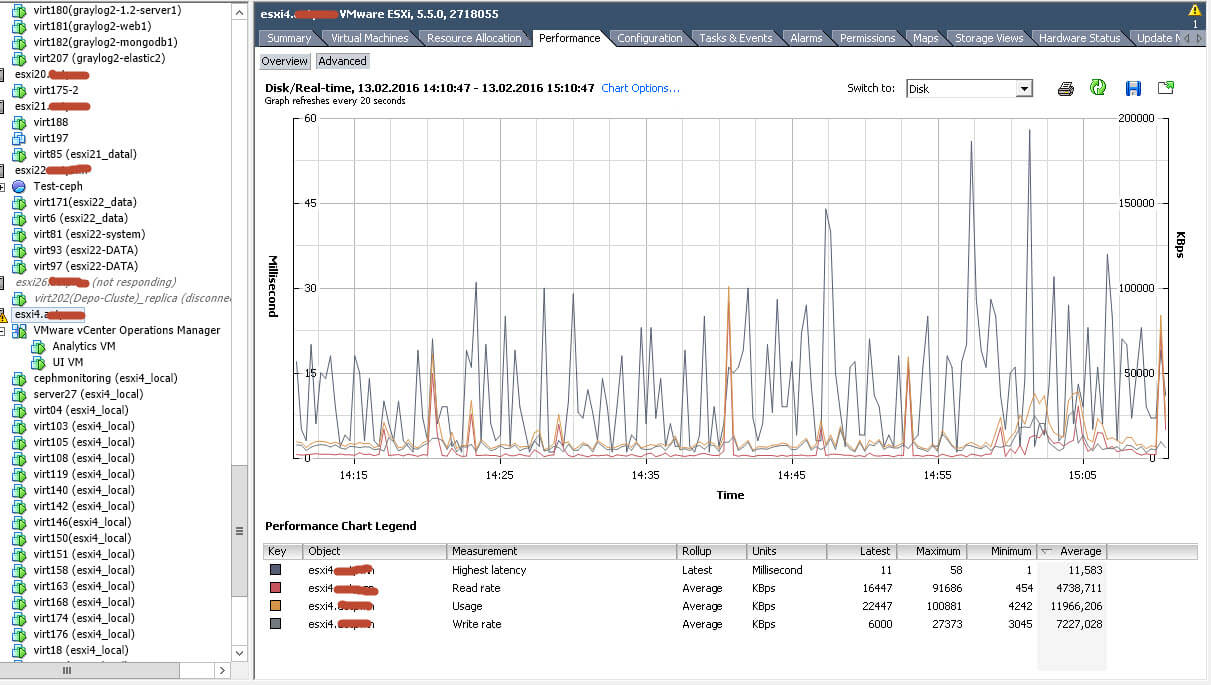
На вкладке Switch to, вы сможете выбрать предмет исследования, будут доступны вот такие пункты
- Disk > латенция и скорость чтения/записи на диск
- Memory > использование памяти
- Network > использование сети
- Power > использование электричества, то же есть
- Storage Adapted > использование дисковых адатеров
- Storage path > можно посмотреть пропускную загрузку при наличии нескольких путей.
- System > загрузка системы
- Virtual flash > если есть ssd кэширование
При желании вы можете сохранить в виде картинки любой график.
Я для примера выбрал мониторинг оперативной памяти, на графике показано, сколько выделено, сколько потребляется в процентах и в мегабайтах, очень удобно. Что означает каждый вид памяти в ESXI читайте по ссылке.
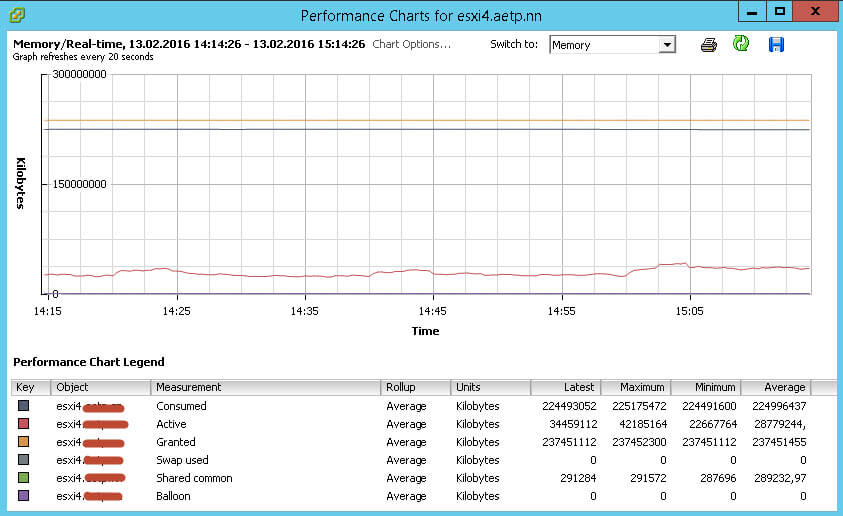
Можно на графике выделить любой пункт, для примера я выбрал Active, то есть активную память и шкала на графике с данным пунктом под светилась и стала выделяться на фоне других.

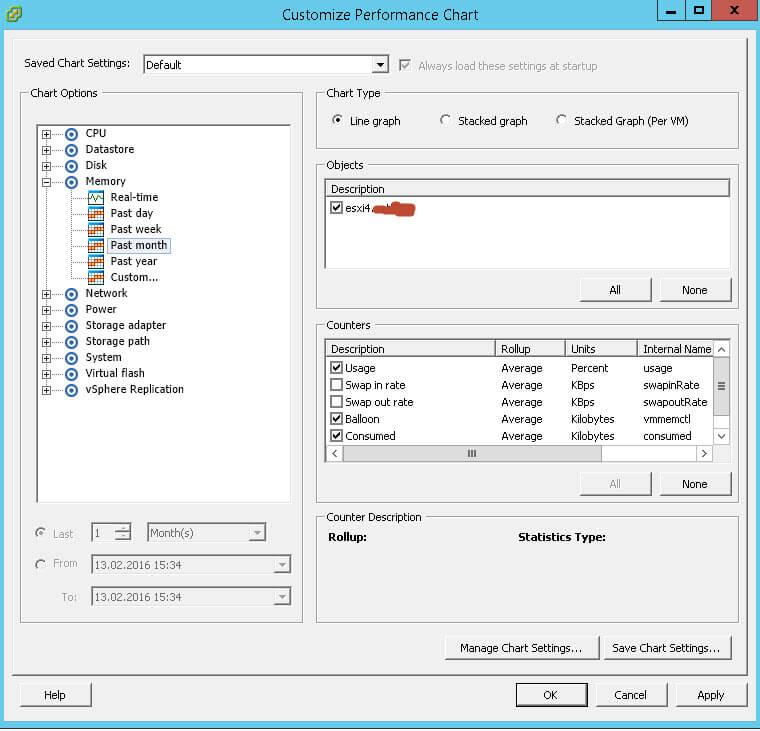
Теперь давайте посмотрим данные за более длительные периоды, для этого жмем Chart Options

С левой стороны нажимаем Past month, то есть за последний месяц, будут выведены данные по мониторингу esxi, в поле Counters, выбираем нужные значения, советую всегда включать там поле usage (используется), жмем ок.
В итоге вы получаете график за месяц по интересующему вас виду ресурсов.
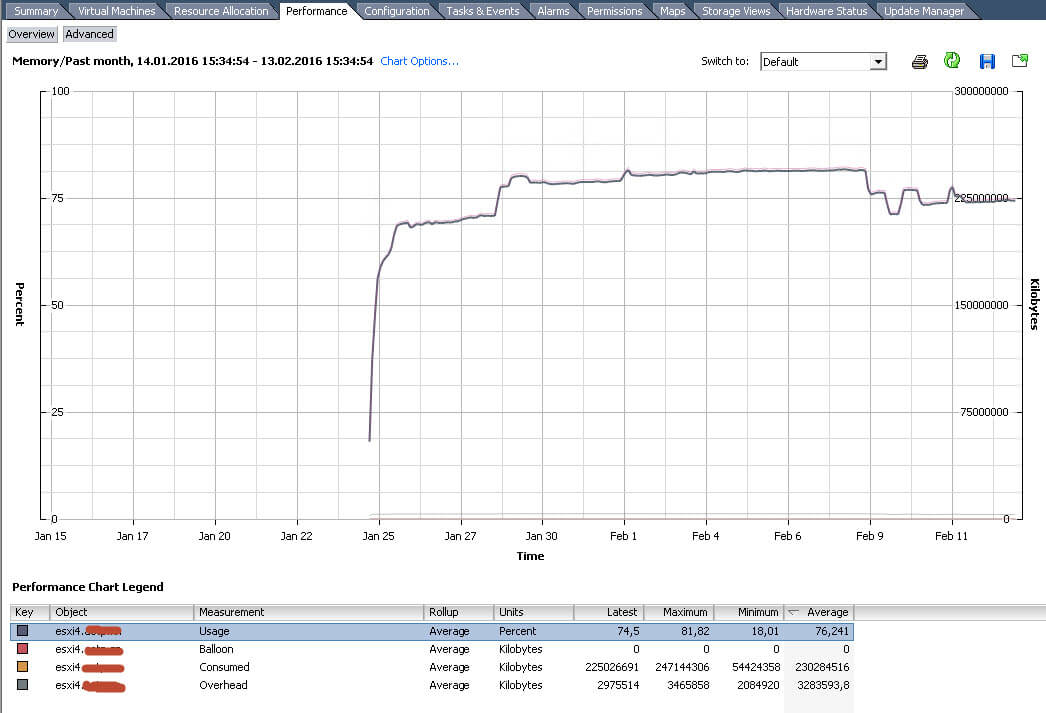
Снова заходим в настройки графика, и обратите внимание, что есть еще два вида отображения
- Stacked graph > закрашенный график для хоста
- Stacked graph (Per VM) > закрашенный график для виртуальной машины
В поле Counters, при Stacked graph, можно выбрать только одно значение.
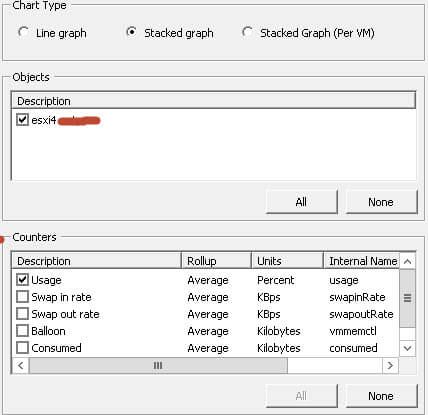
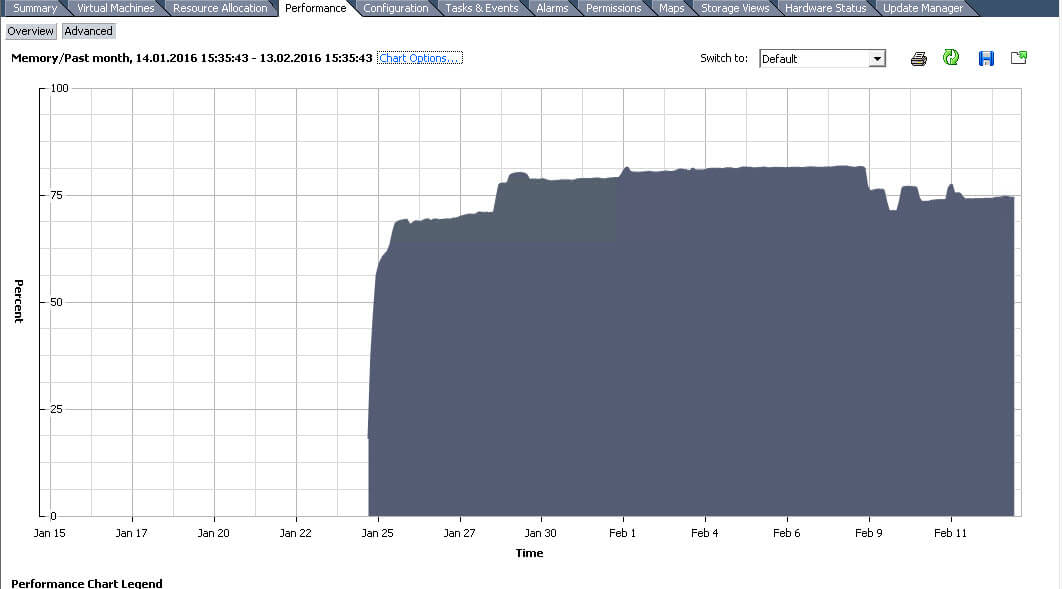
На выходе картинка теперь будет такая.
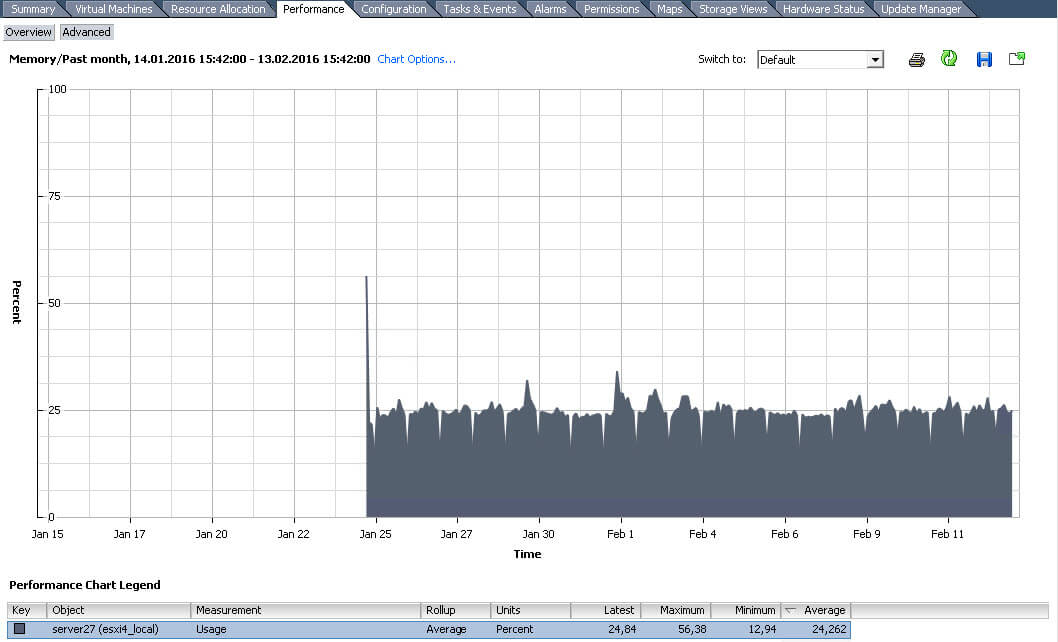
Теперь поставим Stacked graph (Per VM), в моем примере это будет виртуальная машина server27 и смотреть я буду использование памяти.

получилось вот так вот, выбирайте кому, что нагляднее.
Мониторинг vmware с vCenter Operations manager
Ранее я рассказывал как установить vcenter operations manager, советую посмотреть. Отмечу, что это огромный комплекс для мониторинга всей виртуальной инфраструктуры ESXI. Чем хорошо vcenter operations manager встраивается прямо в vCenter, в виде Solutions and Application расширения.
Зайдя в него вы получите вот такой Dashboard, в котором вы увидите, общее состояние инфраструктуры.

Выбираем нужный ESXi 5.5 хост, и смотрим так же его Dashboard, видно эффективность и возможные риски. Все значки кликабельные, это означает, что вас сразу перекинет на пункт, который за это отвечает.
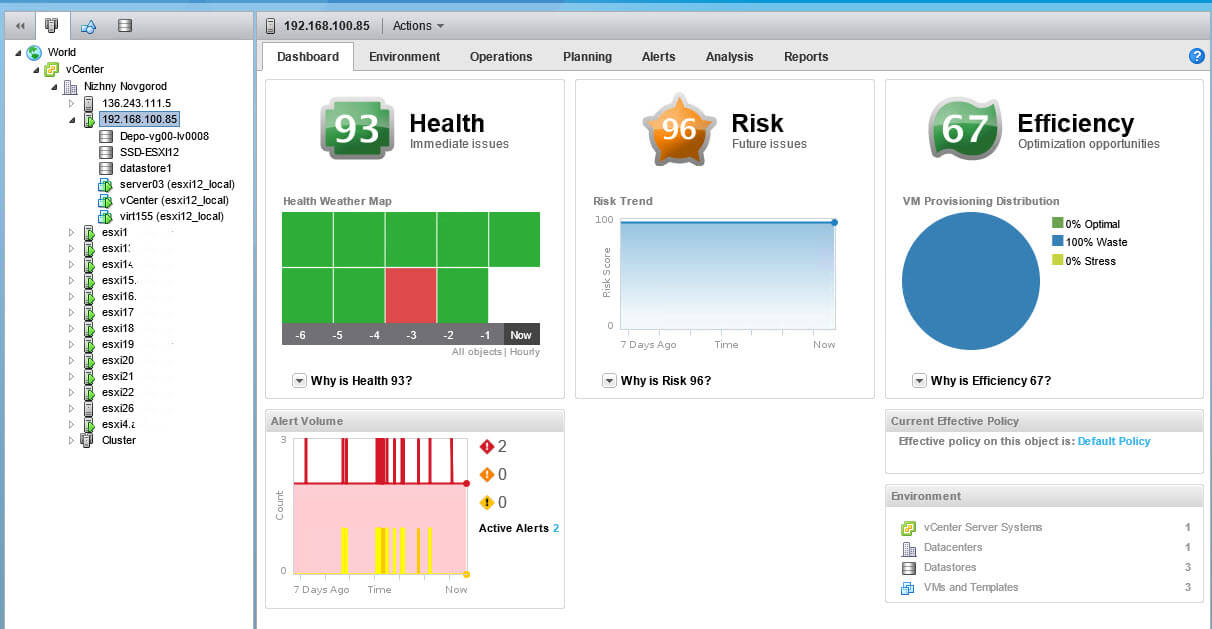
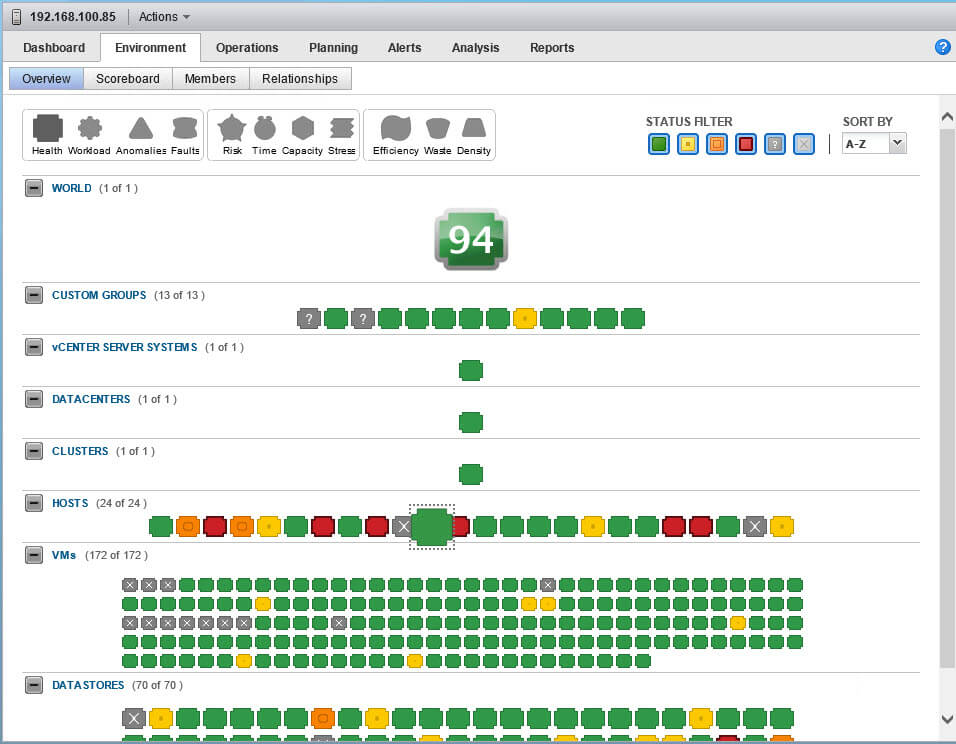
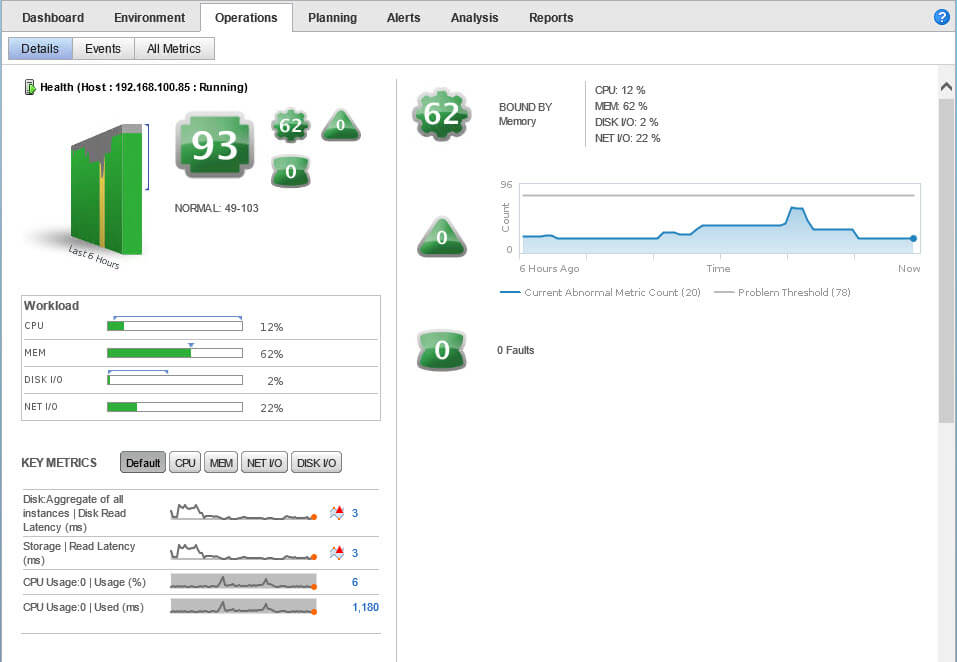
самая полезная это вкладка Environment. Перейдем в нее, а далее в пункт Overview, тут вам покажут, здоровье хоста и различные пункты, связывающие его с инфраструктурой vCneter.
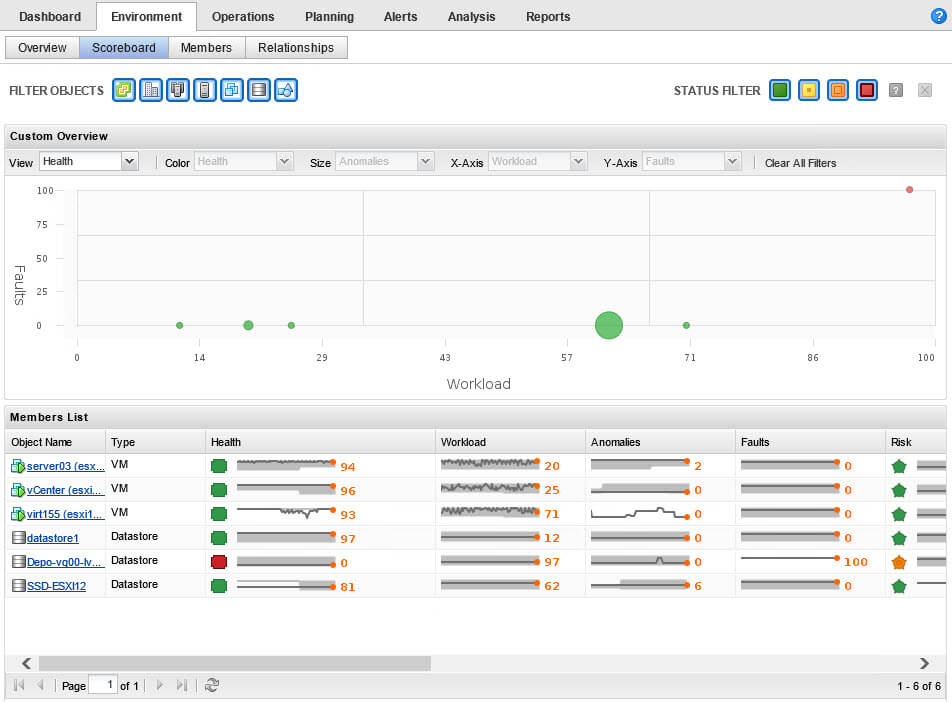
Далее идем на кладку Scoreboard, которая покажет беглый анализ загрузки и здоровья, по всем сущностям данного хоста.
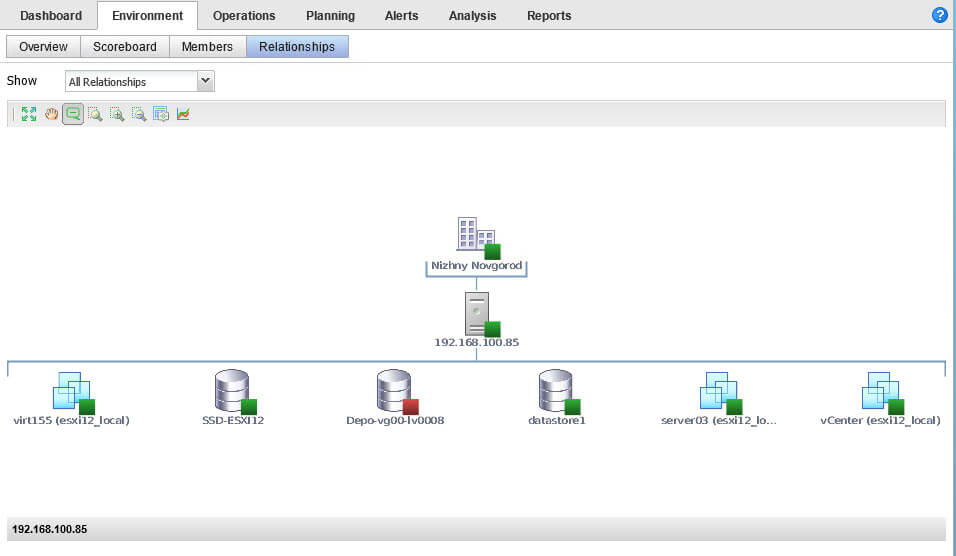
Вкладка Relationships, покажет карту расположения хоста с виртуальными машинами, работающими на нем.
И самый десер, это вкладка Operations, он осуществляет самый подробный мониторинг vmware, CPU, ОЗУ, iops, вплоть для любого датастора или виртуалки.
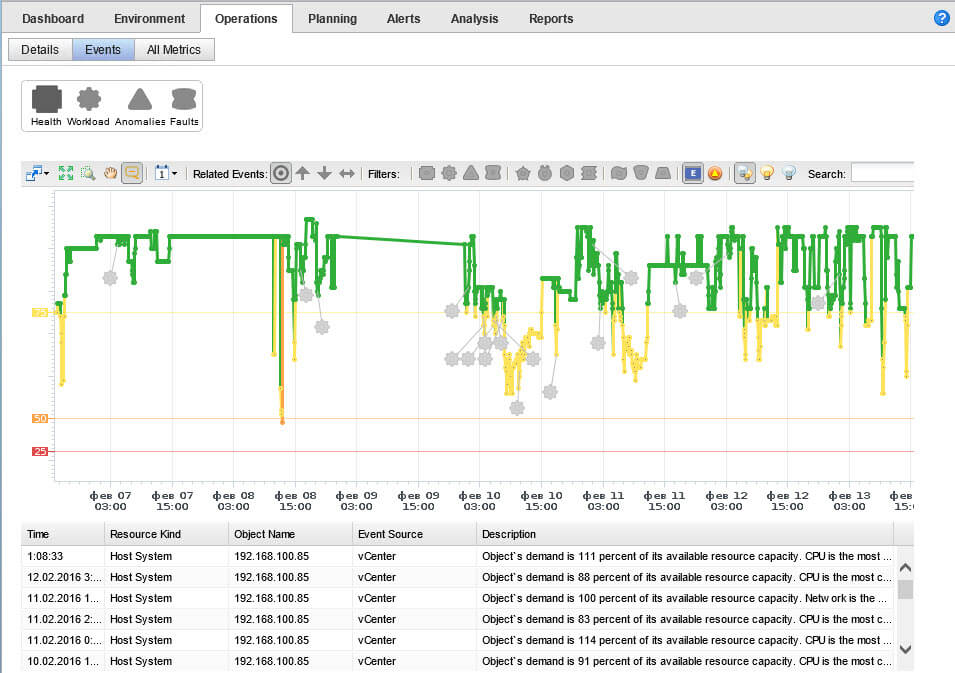
наглядная вкладка ошибок и предупреждений.
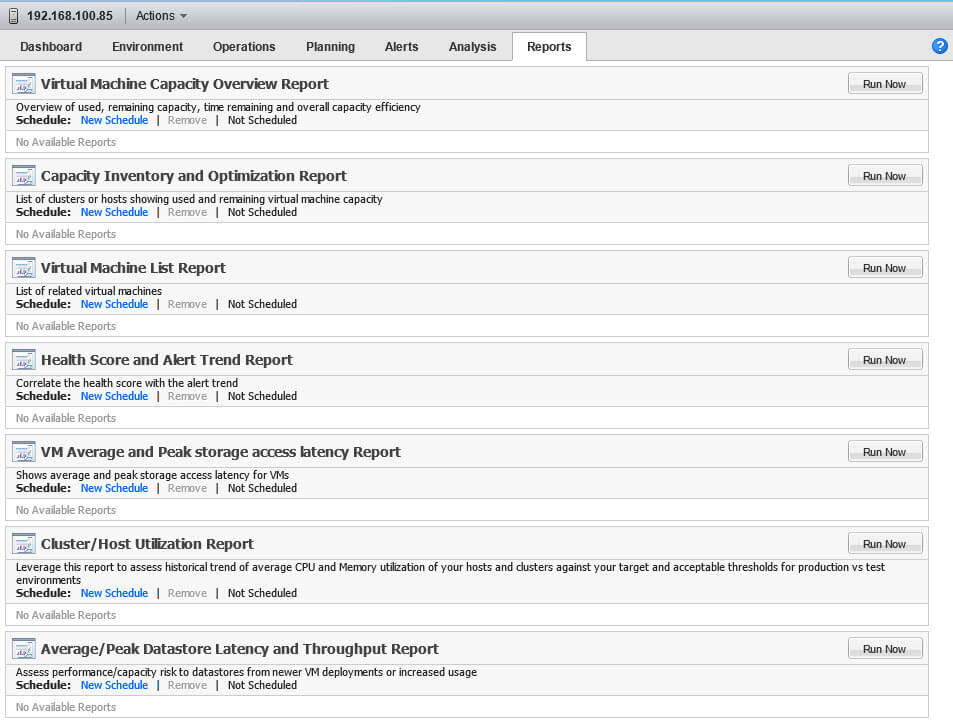
При желании вы можете автоматизировать получение отчетов, по данному серверу.
Как видите, производить мониторинг ESXI очень просто, есть как встроенные средства так и сторонние, но главное, чтобы вы его делали.
Рассказываем, что и почему "тормозит" и как сделать так, чтобы не "тормозило".

Если вы администрируете виртуальную инфраструктуру на базе VMware vSphere (или любого другого стека технологий), то наверняка часто слышите от пользователей жалобы: "Виртуальная машина работает медленно!". В этом цикле статей разберу метрики производительности и расскажу, что и почему "тормозит" и как сделать так, чтобы не "тормозило".
Буду рассматривать следующие аспекты производительности виртуальных машин:
Для анализа производительности нам понадобятся:
Ниже в статье расскажу немного про ESXTOP и приведу несколько полезных ссылок на документацию и статьи по теме.
Немного теории

Диаграмма состояний процесса в ESXi. Источник
В ESXi за работу каждого vCPU (ядра виртуальной машины) отвечает отдельный процесс – world в терминологии VMware. Также есть служебные процессы, но с точки зрения анализа производительности ВМ они менее интересны.
Процесс в ESXi может находиться в одном из четырех состояний:
- Run – процесс выполняет какую-то полезную работу.
- Wait – процесс не выполняет никакой работы (idle) либо ждет ввода/вывода.
- Co-stop – состояние, которое возникает в многоядерных виртуальных машинах. Оно возникает, когда планировщик CPU гипервизора (ESXi CPU Scheduler) не может запланировать одновременное исполнение на физических ядрах сервера всех активных ядер виртуальной машины. В физическом мире все ядра процессора работают параллельно, гостевая ОС внутри ВМ рассчитывает на аналогичное поведение, поэтому гипервизору приходится замедлять ядра ВМ, у которых есть возможность закончить такт быстрее. В современных версиях ESXi планировщик CPU использует механизм, который называется relaxed co-scheduling: гипервизор считает разрыв между самым "быстрым" и самым “медленным" ядром виртуальной машины (skew). Если разрыв превышает определенный порог, "быстрое" ядро переходит в состояние co-stop. Если ядра ВМ проводят много времени в этом состоянии, это может вызвать проблемы с производительностью.
- Ready – процесс переходит в данное состояние, когда у гипервизора нет возможности выделить ресурсы для его исполнения. Высокие значения ready могут вызвать проблемы с производительностью ВМ.
Основные счетчики производительности CPU виртуальной машины
CPU Usage, %. Показывает процент использования CPU за заданный период.

Как анализировать? Если ВМ стабильно использует CPU на 90% или есть пики до 100%, то у нас проблемы. Проблемы могут выражаться не только в "медленной" работе приложения внутри ВМ, но и в недоступности ВМ по сети. Если система мониторинга показывает, что ВМ периодически отваливается, обратите внимание на пики на графике CPU Usage.
Есть стандартный Аlarm, который показывает загрузку CPU виртуальной машины:

Что делать? Если у ВМ постоянно зашкаливает CPU Usage, то можно задуматься об увеличении количества vCPU (к сожалению, это не всегда помогает) или переносе ВМ на сервер с более производительными процессорами.
CPU Usage in Mhz
В графиках на vCenter Usage в % можно посмотреть только по всей виртуальной машине, графиков по отдельным ядрам нет (в Esxtop значения в % по ядрам есть).
По каждому ядру можно посмотреть Usage in MHz.
Как анализировать? Бывает, что приложение не оптимизировано под многоядерную архитектуру: использует на 100% только одно ядро, а остальные простаивают без нагрузки. Например, при дефолтных настройках бэкапа MS SQL запускает процесс только на одном ядре. В итоге резервное копирование тормозит не из-за медленной скорости дисков (именно на это изначально пожаловался пользователь), а из-за того, что не справляется процессор. Проблема была решена изменением параметров: резервное копирование стало запускаться параллельно в несколько файлов (соответственно, в несколько процессов).

Пример неравномерной нагрузки ядер
Также бывает ситуация (как на графике выше), когда ядра нагружены неравномерно и на некоторых из них есть пики в 100%. Как и при загрузке только одного ядра, alarm по CPU Usage не сработает (он по всей ВМ), но проблемы с производительностью будут.
Что делать? Если ПО в виртуальной машине нагружает ядра неравномерно (использует только одно ядро или часть ядер), нет смысла увеличивать их количество. В таком случае лучше переместить ВМ на сервер с более производительными процессорами.
Также можно попробовать проверить настройки энергопотребления в BIOS сервера. Многие администраторы включают в BIOS режим High Performance и тем самым отключают технологии энергосбережения C-states и P-states. В современных процессорах Intel используется технология Turbo Boost, которая увеличивает частоту отдельных ядер процессора за счет других ядер. Но она работает только при включенных технологиях энергосбережения. Если мы их отключаем, то процессор не может уменьшить энергопотребление ядер, которые не нагружены.
VMware рекомендует не отключать технологии энергосбережения на серверах, а выбирать режимы, которые максимально отдают управление энергопотреблением гипервизору. При этом в настройках энергопотребления гипервизора нужно выбрать High Performance.
Если у вас в инфраструктуре отдельные ВМ (или ядра ВМ) требуют повышенную частоту CPU, корректная настройка энергопотребления может значительно улучшить их производительность.

CPU Ready (Readiness)
Если ядро ВМ (vCPU) находится в состоянии Ready, оно не выполняет полезную работу. Такое состояние возникает, когда гипервизор не находит свободное физическое ядро, на которое можно назначить процесс vCPU виртуальной машины.
Как анализировать? Обычно если ядра виртуальной машины находятся в состоянии Ready больше 10% времени, то вы заметите проблемы с производительностью. Проще говоря, больше 10% времени ВМ ждет доступности физических ресурсов.
В vCenter можно посмотреть 2 счетчика, связанных с CPU Ready:
Значения обоих счетчиков можно посмотреть как по всей ВМ, так и по отдельным ядрам.
Readiness показывает значение сразу в процентах, но только в Real-time (данные за последний час, интервал измерений 20 секунд). Этот счетчик лучше использовать только для поиска проблем "по горячим следам".
Значения счетчика Ready можно посмотреть также в исторической перспективе. Это полезно, если нужно установить закономерности и для более глубокого анализа проблемы. Например, если у виртуальной машины начинаются проблемы с производительностью в какое-то определенное время, можно сопоставить интервалы повешенного значения CPU Ready с общей нагрузкой на сервер, где данная ВМ работает, и принять меры по снижению нагрузки (если DRS не справился).
Ready в отличие от Readiness показывается не в процентах, а миллисекундах. Это счетчик типа Summation, то есть он показывает, сколько времени за период измерения ядро ВМ находилось в состоянии Ready. Перевести данное значение в проценты можно по несложной формуле:
(CPU ready summation value / (chart default update interval in seconds * 1000)) * 100 = CPU ready %
Например, для ВМ на графике ниже пиковое значение Ready на всю виртуальную машину получится следующим:

При подсчете значения Ready в процентах стоит обращать внимание на два момента:
- Значение Ready по всей ВМ – это сумма Ready по ядрам.
- Интервал измерения. Для Real-time – это 20 секунд, а, например, на дневных графиках – это 300 секунд.
При активном траблшутинге эти простые моменты можно легко упустить и потратить ценное время на решение несуществующих проблем.
Рассчитаем Ready на основе данных из графика ниже. (324474/(20*1000))*100 = 1622% на всю ВМ. Если смотреть по ядрам получится уже не так страшно: 1622/64 = 25% на ядро. В данном случае обнаружить подвох довольно просто: значение Ready нереалистичное. Но если речь идет о 10–20% на всю ВМ с несколькими ядрами, то по каждому ядру значение может быть в пределах нормы.

Что делать? Высокое значение Ready говорит о том, что серверу не хватает ресурсов процессора для нормальной работы виртуальных машин. В такой ситуации остается только уменьшить переподписку по процессору (vCPU:pCPU). Очевидно, этого можно добиться, уменьшив параметры существующих ВМ или путем миграции части ВМ на другие серверы.
Co-stop
Как анализировать? Данный счетчик также имеет тип Summation и переводится в проценты аналогично Ready:
(CPU co-stop summation value / (<chart default update interval in seconds> * 1000)) * 100 = CPU co-stop %
Здесь также нужно обращать внимание на количество ядер на ВМ и на интервал измерения.
В состоянии Costop ядро таже не выполняет полезную работу. При правильном подборе размера ВМ и нормальной нагрузке на сервер счетчик со-stop должен быть близок к нулю.

В данном случае нагрузка явно ненормальная :)
Также co-stop вырастет, если для активных ядер одной ВМ используются треды на одном физическом ядре сервера со включенным hyper-treading. Такая ситуация может возникнуть, например, если у ВМ больше ядер, чем физически есть на сервере, где она работает, или если для ВМ включена настройка "preferHT". Про эту настройку можно прочитать здесь.
Чтобы избежать проблем с производительностью ВМ из-за высокого Co-stop, выбирайте размер ВМ в соответствии с рекомендациями производителя ПО, которое работает на этой ВМ, и с возможностями физического сервера, где работает ВМ.
Не добавляйте ядра про запас, это может вызвать проблемы с производительностью не только самой ВМ, но и ее соседей по серверу.
Другие полезные метрики CPU
Run – сколько времени (мс) за период измерения vCPU находился в состоянии RUN, то есть собственно выполнял полезную работу.
Idle – сколько времени (мс) за период измерения vCPU находился в состоянии бездействия. Высокие значения Idle – это не проблема, просто vCPU было "нечего делать".
Wait – сколько времени (мс) за период измерения vCPU находился в состоянии Wait. Так как в данный счетчик включается IDLE, высокие значения Wait также не говорят о наличии проблемы. А вот если при высоком Wait IDLE низкий, значит ВМ ждала завершения операций ввода/вывода, а это, в свою очередь, может говорить о наличии проблемы с производительностью жесткого диска или каких-либо виртуальных устройств ВМ.
Max limited – сколько времени (мс) за период измерения vCPU находился в состоянии Ready из-за установленного лимита по ресурсам. Если производительность необъяснимо низкая, то полезно проверить значение данного счетчика и лимит по CPU в настройках ВМ. У ВМ действительно могут оказаться выставлены лимиты, о которых вы не знаете. Например, так происходит, когда ВМ была склонирована из шаблона, на котором был установлен лимит по CPU.
Swap wait – сколько времени за период измерения vCPU ждал операции с VMkernel Swap. Если значения данного счетчика выше нуля, то у ВМ точно есть проблемы с производительностью. Подробнее про SWAP поговорим в статье про счетчики оперативной памяти.
ESXTOP
Если счетчики производительности в vCenter хороши для анализа исторических данных, то оперативный анализ проблемы лучше производить в ESXTOP. Здесь все значения представлены в готовом виде (не нужно ничего переводить), а минимальный период измерения 2 секунды.
Экран ESXTOP по CPU вызывается клавишей "c" и выглядит следующим образом:

Для удобства можно оставить только процессы виртуальных машин, нажав Shift-V.
Чтобы посмотреть метрики по отдельным ядрам ВМ, нажмите "e" и вбейте GID интересующей ВМ (30919 на скриншоте ниже):

Кратко пройдусь по столбцам, которые представлены по умолчанию. Дополнительные столбцы можно добавить, нажав "f".
NWLD (Number of Worlds) – количество процессов в группе. Чтобы раскрыть группу и увидеть метрики для каждого процесса (например, для каждого ядра многоядерной ВМ), нажмите “e”. Если в группе больше одного процесса, то значения метрик для группы равны сумме метрик для отдельных процессов.
%USED – сколько циклов CPU сервера использует процесс или группа процессов.
%RUN – сколько времени за период измерения процесс находился в состоянии RUN, т.е. выполнял полезную работу. Отличается от %USED тем, что не учитывает hyper-threading, frequency scaling и время, затраченное на системные задачи (%SYS).
%SYS – время, затраченное на системные задачи, например: обработку прерываний, ввода/вывода, работу сети и пр. Значение может быть высоким, если на ВМ большой ввод/вывод.
%OVRLP – сколько времени физическое ядро, на котором выполняется процесс ВМ, потратило на задачи других процессов.
Данные метрики соотносятся между собой следующим образом:
%USED = %RUN + %SYS - %OVRLP.
Обычно метрика %USED является более информативной.
%WAIT – сколько времени за период измерения процесс находился в состоянии Wait. Включает IDLE.
%IDLE – cколько времени за период измерения процесс находился в состоянии IDLE.
%SWPWT – сколько времени за период измерения vCPU ждал операции с VMkernel Swap.
%VMWAIT – сколько времени за период измерения vCPU находилось в состояния ожидания события (обычно ввода/вывода). Аналогичного счетчика нет в vCenter. Высокие значения говорят о проблемах с вводом/выводом на ВМ.
%WAIT = %VMWAIT + %IDLE + %SWPWT.
Если ВМ не использует VMkernel Swap, то при анализе проблем с производительностью целесообразно смотреть на %VMWAIT, так как данная метрика не учитывает время, когда ВМ ничего не делала (%IDLE).
%RDY – cколько времени за период измерения процесс находился в состоянии Ready.
%CSTP – cколько времени за период измерения процесс находился в состоянии Co-stop.
%MLMTD – сколько времени за период измерения vCPU находился в состоянии Ready из-за установленного лимита по ресурсам.
%WAIT + %RDY + %CSTP + %RUN = 100% – ядро ВМ все время находится в каком-то из этих четырех состояний.
CPU на гипервизоре
В vCenter есть также счетчики производительности CPU для гипервизора, но они не представляют из себя ничего интересного – это просто сумма счетчиков по всем ВМ на сервере.
Удобнее всего смотреть состояние CPU на сервере на вкладке Summary:

Для сервера, как и для виртуальной машины, есть стандартный Alarm:

При высокой нагрузке на CPU сервера у ВМ, работающих на нем, начинаются проблемы с производительностью.
В ESXTOP данные о загрузке CPU сервера представлены в верхней части экрана. Помимо стандартного CPU load, который малоинформативен для гипервизоров, есть еще три метрики:
CORE UTIL(%) – загрузка ядра физического сервера. Данный счетчик показывает, сколько времени за период измерения ядро выполняло работу.
PCPU UTIL(%) – если включен hyper-threading, то на каждое физическое ядро приходится два потока (PCPU). Данная метрика показывает, сколько времени каждый поток выполнял работу.
PCPU USED(%) – то же, что PCPU UTIL(%), но учитывает frequency scaling (либо снижение частоты ядра в целях энергосбережения, либо повышение частоты ядра за счет технологии Turbo Boost) и hyper-threading.
PCPU_USED% = PCPU_UTIL% * эффективную частоту ядра / номинальную частоту ядра.

На этом скриншоте для некоторых ядер из-за работы Turbo Boost’а значение USED больше 100%, так как частота ядра выше номинальной
Пара слов о том, как учитывается hyper-threading. Если процессы исполняются 100% времени на обоих потоках физического ядра сервера, при этом ядро работает на номинальной частоте, то:
- CORE UTIL для ядра будет 100%,
- PCPU UTIL для обоих потоков будет 100%,
- PCPU USED для обоих потоков будет 50%.
Если оба потока не работали 100% времени за период измерения, то в те периоды, когда потоки работали параллельно, PCPU USED для ядер делится пополам.
В ESXTOP также есть экран с параметрами энергопотребления CPU сервера. Здесь можно посмотреть, используются ли сервером технологии энергосбережения: C-states и P-states. Вызывается клавишей "p":

Стандартные проблемы производительности CPU
Напоследок пробегусь по типичным причинам возникновения проблем с производительностью CPU ВМ и дам короткие советы их решению:
На этом про CPU у меня все. Задавайте вопросы. В следующей части расскажу про оперативную память.
Читайте также: