
Как проверить гипотезу в экселе
Обновлено: 06.07.2024
В этой статье описана функция ДОВЕРИТ в Microsoft Office Excel 2003 и Microsoft Office Excel 2007, а также сравнивает результаты функции для Excel 2003 и Excel 2007 с результатами функции ДОВЕРИТ в более ранних версиях Excel.
Значение доверительных интервалов часто неправильно интерпретировано, и мы стараемся предоставить объяснение допустимой и недопустимой выписки, которые могут быть сделаны после определения доверительного значения на основе данных.
Дополнительные сведения
Функция ДОВЕРИТ(альфа; сигма, n) возвращает значение, которое можно использовать для построения доверительный интервал для многая населения. Доверительный интервал — это диапазон значений, вы центр на основе известного значения выборки. Предполагается, что результаты наблюдений в выборке взяты из нормального распределения с известным стандартным отклонением, сигмой, а количество наблюдений в выборке — n.
Синтаксис
Параметры: альфа — вероятность и 0 < альфа < 1. Сигма — это положительное число, а n — положительное integer, соответствующее размеру выборки.
Обычно альфа — это небольшая вероятность, например 0,05.
Пример использования
Предположим, что оценки коэффициента аналитики следуют за обычным распределением со стандартным отклонением 15. Вы тестировали IQ-тест для 50 учащихся в вашем учебном замещаемом учебном замещаке и получили пример средней 105. Необходимо вычислить доверительный интервал в 95 % для математических вычислений. Доверительный интервал 95 % или 0,95 соответствует альфа = 1 – 0,95 = 0,05.
Чтобы проиллюстрировать функцию ДОВЕРИТ, создайте пустой Excel, скопируйте таблицу ниже и выберите ячейку A1 на Excel листе. В меню Правка выберите команду Вставить.
Примечание: В Excel 2007 нажмите кнопку Вировать в группе Буфер обмена на вкладке Главная.
Элементы в таблице ниже заполняют ячейки A1:B7 на вашем компьютере.
После вжатия этой таблицы на новый Excel нажмите кнопку Параметры вжатия и выберите пункт Найти формат назначения.
Вы можете выбрать в меню Формат пункт Столбец, а затем выбрать пункт Авто подбор по столбцу.
Примечание: В Excel 2007 г. с выбранным диапазоном ячеек нажмите кнопку Формат в группе Ячейки на вкладке Главная, а затем выберите Авто ширина столбца.
Ячейка A6 отображает значение ДОВЕРИТ. Ячейка A7 имеет то же значение, так как звонок на значение ДОВЕРИТ(альфа; сигма, n) возвращает результат вычисления:
NORMSINV(1 – alpha/2) * sigma / SQRT(n)
Непосредственно в доверии не внося изменений, но в Microsoft Excel 2002 г. была улучшена норм.В.ВОСЬМ, а затем в Excel 2002 и Excel 2007 г. были внесены дополнительные улучшения. Поэтому в этих более поздних версиях стандарта ДОВЕРИТ могут возвращаться другие (и улучшенные Excel) результаты, так как доверит их на основе нормСИНВ.
Это не означает, что в более ранних версиях Excel доверие к доверию. Неточности в нормОЛИНВ обычно связаны со значениями аргумента, близкими к 0 или очень близко к 1. На практике альфа обычно имеет 0,05, 0,01 или, возможно, 0,001. Значения альфа-значения должны быть намного меньше, чем это, например 0,0000001, прежде чем ошибки округления в НОРМСИНВ, скорее всего, будут заметили.
Примечание: В этой статье на сайте НОРМ.В.ВН можно узнать о различиях в вычислениях в нормСИНХНОВ.
Для получения дополнительных сведений щелкните номер следующей статьи, чтобы просмотреть статью в базе знаний Майкрософт:
826772 Excel статистические функции: НОРМСИНВ
Интерпретация результатов проверки доверия
Файл Excel справки для confidence был перезаписан в Excel 2003 и Excel 2007, так как все более ранние версии файла справки вводили в заблуждение при интерпретации результатов. В примере говорится: "Предположим, что в нашем примере из 50 сотрудников в пути средняя продолжительность поездки на работу составляет 30 минут со стандартным отклонением в 2,5. Мы можем быть уверены в том, что значение "0,692951" находится в интервале 30 +/- 0,692951", где значение 0,692951 — это значение, возвращаемого значением ДОВЕРИТ(0,05, 2,5, 50).
В этом же примере в заключение говорится, что средняя продолжительность поездки на работу равна 30 ± 0,692951 минуты или от 29,3 до 30,7 минуты. Это также утверждение о том, что численность населения находится в интервале [30 –0,692951, 30 + 0,692951] с вероятностью 0,95.
Перед проведением эксперимента, который дает данные в данном примере, статистический статистик (в отличие от байеса) не может делать никаких заявлений о распределении вероятности распределения по численности населения. Вместо этого статистический статистик в классической версии имеет дело с проверкой гипотез.
Например, классическому статистику может потребоваться провести двухбоговую проверку гипотезы на основе гипотезы на основе гипотезы о нормальном распределении с известным стандартным отклонением (например, 2,5), заранее выбранным значением μ0 и предопределенным уровнем значимости (например, 0,05). Результат проверки будет основан на значении наблюдаемого значения выборки (например, 30), а гипотеза null о том, что это μ0, будет отклонена на уровне значимости 0,05, если наблюдаемое значение имеет значение слишком далеко от μ0 в любом направлении. Если гипотеза NULL отклонена, то интерпретация состоит в том, что выборка означает, что выборка означает, что гораздо больше μ0 может возникнуть менее 5 % времени при позиции, что μ0 — это истинное подмногление численности населения. После проведения этого теста статистический статистик по-прежнему не может сделать никаких заявлений о распределении вероятностей для распределения по численности населения.
С другой стороны, байесский статистический статистик начинается с предполагается распределение вероятности для распределения по численности населения (априори), собирает экспериментальные признаки так же, как и статистический статистик, и использует его для изменения его распределения вероятности для многубного распределения по численности населения и тем самым получения задняя часть распределения. Excel не предусмотрены статистические функции, которые помогли бы байесам в этом случае. Excel статистические функции классической статистики.
Доверительный интервал связан с проверкой гипотез. Учитывая экспериментальные признаки, доверительный интервал делает краткое утверждение о значениях среднего среднего гипотезы μ0, которое позволит принять нулевую гипотезу о том, что это μ0, и значения μ0, которые подавят отклонение гипотезы null о том, что это значение имеет значение μ0. Статистический статистик не может сделать ни одного заявления о вероятности того, что оно попадает в определенный интервал, так как он никогда не делает предопределенные предположения относительно этого распределения вероятности, и такие предположения потребуются, если они будут использовать экспериментальные признаки для их изменения.
Изучение связи между проверками гипотез и доверитными интервалами с помощью примера в начале этого раздела. Связь между доверим и НОРМСИНХОV, которая была заверяема в последнем разделе, имеется:
CONFIDENCE(0.05, 2.5, 50) = NORMSINV(1 – 0.05/2) * 2.5 / SQRT(50) = 0.692951
Так как выборка имеет 30-е, доверительный интервал составляет 30 +/- 0,692951.
Теперь рассмотрим двухбудную проверку гипотезы с уровнем значимости 0,05, как описано выше, в котором предполагается нормальное распределение со стандартным отклонением 2,5, выборку размером 50 и определенным гипотезой о среднего распределения ( μ0). Если это истинное решение по численности населения, то выборка будет взята из нормального распределения со стандартным отклонением μ0 и стандартным отклонением 2,5/SQRT(50). Это распределение симметрично о μ0, и вы хотите отклонить гипотезу null, если abS(выборка μ0) > некого конечного значения. Конечное значение будет таким, что если μ0 — это истинное значение по численности населения, значение выборки — μ0 больше, чем это обрезка, или значение μ0 — выборочная величина выше, чем это обрезка будет возникать с вероятностью 0,05/2. Это вырезание
NORMSINV(1 – 0.05/2) * 2.5/SQRT(50) = CONFIDENCE(0.05, 2.5, 50) = 0. 692951
Отклонить нулевую гипотезу (о численности населения = μ0), если одно из следующих заявлений истинно:
выборка "mean" — μ0 > 0. 692951
0 — пример > 0. 692951
Так как в нашем примере примере выборка " = 30", эти две выписки становятся следующими:
30 - μ0 > 0. 692951
μ0 –30 > 0. 692951
При переописи слева отображается только μ0, что приводит к следующим утверждениям:
μ0 < 30-0. 692951
μ0 > 30 + 0. 692951
Это точно те значения μ0, которые не находятся в доверительный интервал [30 – 0,692951, 30 + 0,692951]. Поэтому доверительный интервал [30 –0,692951, 30 + 0,692951] содержит значения μ0, где null-гипотеза о том, что это μ0, не будет отклонена с учетом примеров признаков. Для значений μ0 вне этого интервала гипотеза null о том, что это μ0, будет отклонена с учетом примеров признаков.
Выводы
Неточности в более ранних версиях Excel обычно возникают при очень небольших или очень больших значениях p в нормУРОВН(p). Доверит оценивается с помощью вызовов НОРМ.СТ.ВВ(p), поэтому точность НОРМСИНВ является потенциальной проблемой для пользователей ДОВЕРИТ. Однако значения p, которые используются на практике, вряд ли являются достаточно крайними, чтобы вызывать существенные ошибки округленного округления в нормУРОВН, и производительность доверит пользователям любой версии Excel.
В большинстве статей основное внимание уделялось анализу результатов проверки доверить. Другими словами, мы спросили: "В чем смысл доверительный интервал?" Доверительный интервал часто неправильно понимается. К сожалению, Excel этой теме были Excel справки во всех версиях Excel 2003. Улучшен Excel 2003.
п.12 . Решение прикладных задач средствами EXCEL .
Процедуры описательной статистики . Параметрический критерий Стьюдента
В Excel для построения выборочных функций распределения используются специальная функция ЧАСТОТА и процедура пакета анализа ГИСТОГРАММА.
1. Функция ЧАСТОТА вычисляет частоты появления случайной величины в интервалах значений и выводит их как массив цифр. Функция задается в качестве формулы массива.
2. Процедура ГИСТОГРАММА используется для вычисления выборочных и интегральных частот попадания данных в указанные интервалы значений. Процедура выводит результаты в виде таблицы и гистограммы.
В мастере функций Excel имеется также ряд специальных функций, предназначенных для вычисления выборочных характеристик. Прежде всего, это функции, характеризующие «центр» распределения.
•Функция СРЗНАЧ вычисляет среднее арифметическое из нескольких массивов (аргументов) чисел. Аргументы число 1, число 2,… — это от 1 до 30 массивов, для которых вычисляется среднее. Например, если ячейки А1-А7 содержат числа 10, 14, 5, 6, 10, 12 и 13, то средним арифметическим СРЗНАЧ ( А1-А7 ) является 10.
• Например, СРГАРМ(10;14;5;6;10;12;13) равняется 8,317.
•Функция МЕДИАНА позволяет получать медиану заданной выборки. Медиана — это элемент выборки, число элементов выборки со значениями больше которого и меньше которого равно. Например, МЕДИАНА (10;14;5;6;10;12;13) равняется 10.
•Функция МОДА вычисляет наиболее часто встречающееся значение в выборке. Например, МОДА (10;14;5;6;10;12,13) равняется 10.
К специальным функциям, вычисляющим выборочные характеристики, характеризующие рассеяние вариант, относятся ДИСП, СТАНДОТКЛОН, ПЕРСЕНТИЛЬ.
•Функция ДИСП позволяет оценить дисперсию по выборочным данным. Например, ДИСП(10;14;5;6;10;12;13) равняется 11,667.
•Функция СТАНДОТКЛОН вычисляет стандартное отклонение. Например, СТАНДОТКЛОН(10;14;5;6;10;12;13) равняется 3,416.
•Функция ПЕРСЕНТИЛЬ позволяет получить квантили заданной выборки. Например, если ячейки А1-А7 содержат числа 10, 14, 5, 6, 10, 12 и 13, то квантиль со значением 0,1 является ПЕРСЕНТИЛЬ (А 1-А7;0,1), равная 5,6.
Форму эмпирического распределения позволяют оценить специальные функции:
•Функция ЭКСЦЕСС вычисляет оценку эксцесса по выборочным данным. Например, ЭКСЦЕСС(10;14;5;6;10;12;13) равняется -1,169.
•Функция СКОС позволяет оценить асимметрию выборочного распределения. Например, СКОС(10;14;5;6;10;12;13) равняется -0,527.
В пакете Excel помимо мастера функций имеется набор более мощных инструментов для работы с несколькими выборками и углубленного анализа данных, называемый Пакет анализа, который может быть использован для решения задач статистической обработки выборочных данных.
Для установки раздела «Анализ данных» в пакете Excel сделайте следующее:
•в меню Сервис выберите команду Надстройки;
•в появившемся списке установите флажок Пакет анализа.
В MS Excel для оценки достоверности отличий по критерию Стьюдента используются специальная функция ТТЕСТ и процедуры пакета анализа.
Функция ТТЕСТ (коэффициент Стьюдента) использует следующие параметры: ТТЕСТ (массив 1; массив 2; хвосты; тип). Здесь:
•массив 1 — это первое множество данных;
•массив2 — это второе множество данных;
•хвосты — число хвостов распределения. Обычно число хвостов равно 2;
•тип — это вид используемого t -теста.
Рассмотрим на примере применение ф ункции ТТЕСТ для оценки статистической значимости различий по исследуемому признаку между двумя выборками.
Изучалось различие в показателях интеллекта студентов первого и пятого курсов технического вуза. Для этого случайным образом были отобраны 12 студентов первого курса и 13 студентов 5 курса, у которых интеллект определялся по одной и той же методике. Были получены следующие результаты:
1 группа - первый курс: 111, 104, 107, 90, 101, 107, 106, 107, 95, 106, 105, 115.
2 группа – пятый курс: 113, 107, 123, 122, 117, 112, 105, 108, 111, 114, 102, 104, 108.
Оценить с помощью критерия Стьюдента достоверность различий между группами.
H – различия между группами не достоверны.
H – различия между группами достоверны.
1. Введите данные: откройте новую рабочую таблицу. Введите в ячейку А1 слово 1 группа - первый курс, затем в ячейки А2-А13 введите показатели интеллекта у студентов первой группы. В ячейку В1 введите слово 2 группа- пятый курс, а в В2-В14 введите показатели интеллекта у студентов второй группы.
3. Поскольку величина вероятности случайного появления анализируемых выборок (0,018563) меньше уровня значимости (р = 0,05), то нулевая гипотеза отклоняется. Следовательно, различия между выборками неслучайные, и средние выборок считаются достоверно отличающимися друг от друга. Поэтому на основании применения критерия Стьюдента можно сделать вывод о том, что различия между группами статистически достоверны .
Проверить с помощью критерия Стьюдента гипотезу о том, что в результате тренинга самооценка конформизма участников возросла.
H – различия между показателями до и после тренинга не достоверны.
H – различия между показателями до и после тренинга достоверны.
1. Введите данные: откройте новую рабочую таблицу. Введите в ячейку С1 слово До тренинга, затем в ячейки С2-С9 — соответствующие значения. В ячейку Д1 введите слова После тренинга, а в Д2-Д9 — значения.
3. Поскольку величина вероятности случайного появления анализируемых выборок (0,047945) меньше пятипроцентного уровня значимости (р = 0,05), нулевая гипотеза отклоняется. Следовательно, различия между выборками неслучайные, и средние выборок считаются достоверно отличающимися друг от друга. Поэтому на основании применения критерия Стьюдента можно сделать вывод о том, что различия между показателями до и после тренинга достоверны (р 0,05).
Итак, при использовании t -критерия выделяют два основных случая. В первом случае его применяют для проверки гипотезы о равенстве средних двух независимых, несвязанных выборок (так называемый двухвыборочный t -критерий). При заполнении диалогового окна ТТЕСТ при этом указывается Тип 3. Во втором случае, когда одна и та же группа объектов порождает числовой материал для проверки гипотез о средних, используется так называемый парный t -критерий (при заполнении диалогового окна ТТЕСТ указывается Тип 1).
Проверялась гипотеза о том, что мужчины агрессивнее женщин. По тесту Басса-Дарки опросили 17 мужчин и 20 женщин. Индексы общей агрессивности для каждого из опрошенных приведены в таблице.
26 , 16 , 19 , 14, 24, 15, 25, 11, 22, 20, 17, 10, 5, 9, 5, 8, 6
20, 17, 13, 19, 22, 8, 10, 7, 10, 15, 10, 5, 8, 5, 6, 5, 5, 8, 10, 10
Члены команды спасателей участвовали в тренинге по повышению стрессоустойчивости. В таблице приведены результаты измерения стрессоустойчивости до тренинга (выборка А) и после тренинга (выборка В).
Можно ли утверждать, что после тренинга стрессоустойчивость испытуемых возросла?
1. Определить выборочные оценки числовых характеристик случайной величины.
Для нахождения выборочных оценок скопируем данные задачи в один столбец таблицы MS Excel . Выделите полученный столбец и на панели инструментов щелкните на кнопку Сортировка и фильтр . В появившемся окошке нажмите сортировку от А до Я. В выделенном столбце значения упорядочатся от наименьшего к наибольшему.
Проанализируем данные с помощью описательной статистики. Для этого на вкладке Данные в группе Анализ щелкните на кнопку Анализ данных . Откроется диалоговое окно Анализ данных.
Выберите инструмент Описательная статистика и щелкните на кнопке Ок . Откроется диалоговое окно Описательная статистика.
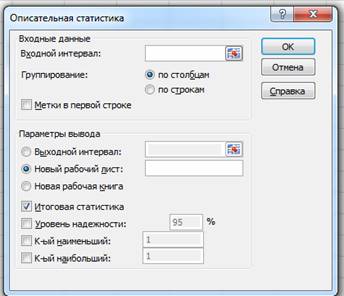
2. Построить вариационный ряд, или ряд распределений и гистограмму для него.
Как видно в итоговой статистике, все возможные значения данного распределения укладываются в интервал 3σ.
Действительно, x =69,43; 3σ=27,3; ( x -3σ; x +3σ) = (41,13; 96,73)
Размах выборки 43,6. Разбиваем данный ряд на 7 интервалов длины 43,6: 7≈6,2.
Составим таблицу ряда распределений:
Чтобы создать диаграмму, выберите нужные данные таблицы (границы интервала и число наблюдений в интервале) и на вкладке Вставка в группе Диаграммы щелкните на типе диаграммы. Появится список доступных подтипов диаграмм. При щелчке на подтипе диаграммы будет создана диаграмма с макетом и цветовой схемой по умолчанию, определенными в теме оформления книги.
3. Определить теоретическую функцию распределения, её параметры. Выполнить сравнительный графический анализ формы эмпирического и теоретического распределений.
Для построения графика теоретической функции распределения построим вспомогательную таблицу:
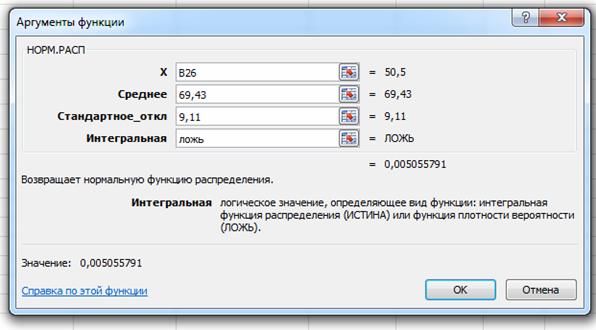
В открывшемся окне в поле X указываем на ячейку со значением середины интервала, в поле Среднее указываем среднее значение, полученное в первом пункте работы с помощью описательной статистики, в поле Стандартное_откл – стандартное отклонение, найденное также с помощью описательной статистики. В поле Интегральная – ЛОЖЬ, так как ищем функцию плотности вероятности и нажимаем ОК.
Теоретическая вероятность вычисляется по формуле:
В таблице 2 выделяем последний столбец и строим график теоретической вероятности. Для этого на вкладке Вставка в группе График щелкните на типе графика. Появится список доступных подтипов графиков. При щелчке на подтипе графика будет создан график с макетом и цветовой схемой по умолчанию, определенными в теме оформления книги.
Изначально на горизонтальной оси обозначены номера интервалов. Правой кнопкой мыши щелкаем на эту ось и нажимаем на Выбрать данные . Меняем подпись горизонтальной оси, указывая первый столбец таблицы 2. Нажимая на график правой кнопкой мыши можно поменять цвет графика.
А теперь выполним сравнительный графический анализ формы эмпирического и теоретического распределений построением графика теоретической вероятности на гистограмме частот.
Для этого построим гистограмму частостей на интервалах. Щелкнем правой кнопкой мыши в поле гистограммы и нажмем на кнопку Выбрать данные . В открывшемся окне в левом столбце Элементы легенды нажмем кнопку Добавить . Откроется окно Изменение ряда . Имя ряда: укажем на ячейку Теоретическая вероятность, значения: выделим соответствующую строку. После нажатия Ок появится гистограмма теоретических вероятностей. Укажем на неё правой кнопкой мыши и выберем Изменить тип диаграммы для ряда, выбрав график. Также поменяем цвет нового графика.
4.Проверка согласованности теоретического и эмпирического распределений.
Схема применения критерия Χ 2 для проверки гипотезы H0 о соответствии эмпирического ряда нормальному закону распределения, сводится к следующему.
1) Определяется мера расхождения эмпирических и теоретических частот Χ 2 по формуле .
Для этого в свободной ячейке нажмем на вкладке Формулы выберем Статистические и, среди них ХИ2.ТЕСТ. Откроется следующее окно:
Я помню, когда я проходил свою первую зарубежную стажировку в CERN в качестве практиканта, большинство людей все еще говорили об открытии бозона Хиггса после подтверждения того, что он соответствует порогу «пять сигм» (что означает наличие p-значения 0,0000003).

Тогда я ничего не знал о p-значении, проверке гипотез или даже статистической значимости.
Я решил загуглить слово — «p-значение», и то, что я нашел в Википедии, заставило меня еще больше запутаться…
При проверке статистических гипотез p-значение или значение вероятности для данной статистической модели — это вероятность того, что при истинности нулевой гипотезы статистическая сводка (например, абсолютное значение выборочной средней разницы между двумя сравниваемыми группами) будет больше или равна фактическим наблюдаемым результатам.
— Wikipedia
Хорошая работа, Википедия.
Ладно. Я не понял, что на самом деле означает р-значение.
Углубившись в область науки о данных, я наконец начал понимать смысл p-значения и то, где его можно использовать как часть инструментов принятия решений в определенных экспериментах.
Поэтому я решил объяснить р-значение в этой статье, а также то, как его можно использовать при проверке гипотез, чтобы дать вам лучшее и интуитивное понимание р-значений.
Также мы не можем пропустить фундаментальное понимание других концепций и определение p-значения, я обещаю, что сделаю это объяснение интуитивно понятным, не подвергая вас всеми техническими терминами, с которыми я столкнулся.
Всего в этой статье четыре раздела, чтобы дать вам полную картину от построения проверки гипотезы до понимания р-значения и использования его в процессе принятия решений. Я настоятельно рекомендую вам пройтись по всем из них, чтобы получить подробное понимание р-значений:
- Проверка гипотезы
- Нормальное распределение
- Что такое P-значение?
- Статистическая значимость
1. Проверка гипотез

Прежде чем мы поговорим о том, что означает р-значение, давайте начнем с разбора проверки гипотез, где р-значение используется для определения статистической значимости наших результатов.
Наша конечная цель — определить статистическую значимость наших результатов.
И статистическая значимость построена на этих 3 простых идеях:
- Проверка гипотезы
- Нормальное распределение
- P-значение
Другими словами, мы создадим утверждение (нулевая гипотеза) и используем пример данных, чтобы проверить, является ли утверждение действительным. Если утверждение не соответствует действительности, мы выберем альтернативную гипотезу. Все очень просто.
Чтобы узнать, является ли утверждение обоснованным или нет, мы будем использовать p-значение для взвешивания силы доказательств, чтобы увидеть, является ли оно статистически значимым. Если доказательства подтверждают альтернативную гипотезу, то мы отвергнем нулевую гипотезу и примем альтернативную гипотезу. Это будет объяснено в следующем разделе.
Давайте воспользуемся примером, чтобы сделать эту концепцию более ясной, и этот пример будет использоваться на протяжении всей этой статьи для других концепций.
Пример. Предположим, что в пиццерии заявлено, что время их доставки составляет в среднем 30 минут или меньше, но вы думаете, что оно больше чем заявленное. Таким образом, вы проводите проверку гипотезы и случайным образом выбираете время доставки для проверки утверждения:
- Нулевая гипотеза — среднее время доставки составляет 30 минут или меньше
- Альтернативная гипотеза — среднее время доставки превышает 30 минут
- Цель здесь состоит в том, чтобы определить, какое утверждение — нулевое или альтернативное — лучше подтверждается данными, полученными из наших выборочных данных.
Одним из распространенных способов проверки гипотез является использование Z-критерия. Здесь мы не будем вдаваться в подробности, так как хотим лучше понять, что происходит на поверхности, прежде чем погрузиться глубже.
2. Нормальное распределение

Нормальное распределение — это функция плотности вероятности, используемая для просмотра распределения данных.
Нормальное распределение имеет два параметра — среднее (μ) и стандартное отклонение, также называемое сигма (σ).
Среднее — это центральная тенденция распределения. Оно определяет местоположение пика для нормальных распределений. Стандартное отклонение — это мера изменчивости. Оно определяет, насколько далеко от среднего значения склонны падать значения.
- 68% данных находятся в пределах 1 стандартного отклонения (σ) от среднего значения (μ)
- 95% данных находятся в пределах 2 стандартных отклонений (σ) от среднего значения (μ)
- 99,7% данных находятся в пределах 3 стандартных отклонений (σ) от среднего значения (μ)
Классно. Теперь вы можете задаться вопросом: «Как нормальное распределение относится к нашей предыдущей проверке гипотез?»
Поскольку мы использовали Z-тест для проверки нашей гипотезы, нам нужно вычислить Z-баллы (которые будут использоваться в нашей тестовой статистике), которые представляют собой число стандартных отклонений от среднего значения точки данных. В нашем случае каждая точка данных — это время доставки пиццы, которое мы получили.
Обратите внимание, что когда мы рассчитали все Z-баллы для каждого времени доставки пиццы и построили стандартную кривую нормального распределения, как показано ниже, единица измерения на оси X изменится с минут на единицу стандартного отклонения, так как мы стандартизировали переменную, вычитая среднее и деля его на стандартное отклонение (см. формулу выше).
Изучение стандартной кривой нормального распределения полезно, потому что мы можем сравнить результаты теста с ”нормальной" популяцией со стандартизированной единицей в стандартном отклонении, особенно когда у нас есть переменная, которая поставляется с различными единицами.

Z-оценка может сказать нам, где лежат общие данные по сравнению со средней популяцией.
Мне нравится, как Уилл Кёрсен выразился: чем выше или ниже Z-показатель, тем менее вероятным будет случайный результат и тем более вероятным будет значимый результат.
Но насколько высокий (или низкий) показатель считается достаточно убедительным, чтобы количественно оценить, насколько значимы наши результаты?
Кульминация
Здесь нам нужен последний элемент для решения головоломки — p-значение, и проверить, являются ли наши результаты статистически значимыми на основе уровня значимости (также известного как альфа), который мы установили перед началом нашего эксперимента.
3. Что такое P-значение?
Наконец… Здесь мы говорим о р-значении!
Все предыдущие объяснения предназначены для того, чтобы подготовить почву и привести нас к этому P-значению. Нам нужен предыдущий контекст и шаги, чтобы понять это таинственное (на самом деле не столь таинственное) р-значение и то, как оно может привести к нашим решениям для проверки гипотезы.
Если вы зашли так далеко, продолжайте читать. Потому что этот раздел — самая захватывающая часть из всех!
Вместо того чтобы объяснять p-значения, используя определение, данное Википедией (извини Википедия), давайте объясним это в нашем контексте — время доставки пиццы!
Напомним, что мы произвольно отобрали некоторые сроки доставки пиццы, и цель состоит в том, чтобы проверить, превышает ли время доставки 30 минут. Если окончательные доказательства подтверждают утверждение пиццерии (среднее время доставки составляет 30 минут или меньше), то мы не будем отвергать нулевую гипотезу. В противном случае мы опровергаем нулевую гипотезу.
Поэтому задача p-значения — ответить на этот вопрос:
Если я живу в мире, где время доставки пиццы составляет 30 минут или меньше (нулевая гипотеза верна), насколько неожиданными являются мои доказательства в реальной жизни?
Р-значение отвечает на этот вопрос числом — вероятностью.
Чем ниже значение p, тем более неожиданными являются доказательства, тем более нелепой выглядит наша нулевая гипотеза.
И что мы делаем, когда чувствуем себя нелепо с нашей нулевой гипотезой? Мы отвергаем ее и выбираем нашу альтернативную гипотезу.
Если р-значение ниже заданного уровня значимости (люди называют его альфа, я называю это порогом нелепости — не спрашивайте, почему, мне просто легче понять), тогда мы отвергаем нулевую гипотезу.
Теперь мы понимаем, что означает p-значение. Давайте применим это в нашем случае.
P-значение в расчете времени доставки пиццы
Теперь, когда мы собрали несколько выборочных данных о времени доставки, мы выполнили расчет и обнаружили, что среднее время доставки больше на 10 минут с p-значением 0,03.
Это означает, что в мире, где время доставки пиццы составляет 30 минут или меньше (нулевая гипотеза верна), есть 3% шанс, что мы увидим, что среднее время доставки, по крайней мере, на 10 минут больше, из-за случайного шума.
Чем меньше p-значение, тем более значимым будет результат, потому что он с меньшей вероятностью будет вызван шумом.
В нашем случае большинство людей неправильно понимают р-значение:
Р-значение 0,03 означает, что есть 3% (вероятность в процентах), что результат обусловлен случайностью — что не соответствует действительности.Люди часто хотят получить определенный ответ (в том числе и я), и именно поэтому я долго путался с интерпретацией p-значений.
Р-значение ничего не *доказывает*. Это просто способ использовать неожиданность в качестве основы для принятия разумного решения.
— Кэсси Козырков
Вот как мы можем использовать p-значение 0,03, чтобы помочь нам принять разумное решение (ВАЖНО):
- Представьте, что мы живем в мире, где среднее время доставки всегда составляет 30 минут или меньше — потому что мы верим в пиццерию (наше первоначальное убеждение)!
- После анализа времени доставки собранных образцов р-значение на 0,03 ниже, чем уровень значимости 0,05 (предположим, что мы установили это значение перед нашим экспериментом), и мы можем сказать, что результат является статистически значимым.
- Поскольку мы всегда верили пиццерии, что она может выполнить свое обещание доставить пиццу за 30 минут или меньше, нам теперь нужно подумать, имеет ли это убеждение смысл, поскольку результат говорит нам о том, что пиццерия не выполняет свое обещание и результат является статистически значимым.
- Так что же нам делать? Сначала мы пытаемся придумать любой возможный способ сделать наше первоначальное убеждение (нулевая гипотеза) верным. Но поскольку пиццерия постепенно получает плохие отзывы от других людей и часто приводит плохие оправдания, которые привели к задержке доставки, даже мы сами чувствуем себя нелепо, чтобы оправдать пиццерию, и, следовательно, мы решаем отвергнуть нулевую гипотезу.
- Наконец, следующее разумное решение — не покупать больше пиццы в этом месте.
По моему мнению, p-значения используются в качестве инструмента для оспаривания нашего первоначального убеждения (нулевая гипотеза), когда результат является статистически значимым. В тот момент, когда мы чувствуем себя нелепо с нашим собственным убеждением (при условии, что р-значение показывает, что результат статистически значим), мы отбрасываем наше первоначальное убеждение (отвергаем нулевую гипотезу) и принимаем разумное решение.
4. Статистическая значимость
Наконец, это последний этап, когда мы собираем все вместе и проверяем, является ли результат статистически значимым.
Недостаточно иметь только р-значение, нам нужно установить порог (уровень значимости — альфа). Альфа всегда должна быть установлена перед экспериментом, чтобы избежать смещения. Если наблюдаемое р-значение ниже, чем альфа, то мы заключаем, что результат является статистически значимым.
Основное правило — установить альфа равным 0,05 или 0,01 (опять же, значение зависит от вашей задачи).
Как упоминалось ранее, предположим, что мы установили альфа равным 0,05, прежде чем мы начали эксперимент, полученный результат является статистически значимым, поскольку р-значение 0,03 ниже, чем альфа.
Для справки ниже приведены основные этапы всего эксперимента:
- Сформулируйте нулевую гипотезу
- Сформулируйте альтернативную гипотезу
- Определите значение альфа для использования
- Найдите Z-показатель, связанный с вашим альфа-уровнем
- Найдите тестовую статистику, используя эту формулу
- Если значение тестовой статистики меньше Z-показателя альфа-уровня (или p-значение меньше альфа-значения), отклоните нулевую гипотезу. В противном случае не отвергайте нулевую гипотезу.
Если вы хотите узнать больше о статистической значимости, не стесняйтесь посмотреть эту статью — Объяснение статистической значимости, написанная Уиллом Керсеном.
Последующие размышления
Здесь много чего нужно переваривать, не так ли?
Я не могу отрицать, что p-значения по своей сути сбивают с толку многих людей, и мне потребовалось довольно много времени, чтобы по-настоящему понять и оценить значение p-значений и то, как они могут быть применены в рамках нашего процесса принятия решений в качестве специалистов по данным.
Но не слишком полагайтесь на p-значения, поскольку они помогают только в небольшой части всего процесса принятия решений.
Я надеюсь, что мое объяснение p-значений стало интуитивно понятным и полезным в вашем понимании того, что в действительности означают p-значения и как их можно использовать при проверке ваших гипотез.
Сам по себе расчет р-значений прост. Трудная часть возникает, когда мы хотим интерпретировать p-значения в проверке гипотез. Надеюсь, что теперь трудная часть станет для вас немного легче.
Если вы хотите узнать больше о статистике, я настоятельно рекомендую вам прочитать эту книгу (которую я сейчас читаю!) — Практическая статистика для специалистов по данным, специально написанная для data scientists, чтобы разобраться с фундаментальными концепциями статистики.

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
Читайте также: