
Как располагается массив в памяти компьютера
Обновлено: 04.07.2024
Продолжаем разговор об основах построения вычислительной техники. На этот раз рассмотрим массивы. Это структура в памяти компьютера в виде элементов, расположенных друг за другом. В классическом понимании эти элементы однотипные. В отдельных технологиях элементы могут быть разных типов, но это уже совсем другая история. Массивы это чрезвычайно часто используемая абстракция. С помощью них организуются вычисления при обработке практически любых данных. Это голос, изображения, видео и разные поля величин в многомерных координатных пространствах.
На сегодня у нас задача сложения всех элементов массива. Какие частные вопросы мы рассмотрим:
- технические подробности доступа к элементам массива в памяти компьютера,
- продолжим освоение циклических конструкций языка си,
- вызов функций.
Процессор с регистровым файлом.
Схема простейшего процессора из прошлых статей слишком примитивна для освещения поставленных вопросов. Немного доработаем ее до представленной схемы.
В основном, нам тут покажется знакомыми многие детали.
Никуда не исчез регистр счетчика инструкций, он же регистр указателя инструкции PC .
Как и раньше он занимается изъятием из памяти очередной инструкции из памяти.
Помогает ему в этом сумматор текущего адреса инструкции с единицей.
Выбранная инструкция поступает в регистр команды на временное хранение.
Как можно заметить, теперь нет отдельной памяти для программ и для данных. Есть одна общая память. Поэтому доступ за инструкцией и за данными осуществляется по очереди. Пока происходит выборка данных инструкция хранится в своем регистре и через дешифратор команд управляет всеми потоками данных в процессоре. Теперь рассмотрим одну важную конструкцию. Это пара регистров R1 и R2 . Их выходы подключаются к арифметико-логическому устройству , служащему не просто для арифметических операций, а для вычисления адреса, где хранятся данные.
Рассмотрим расположение массива в памяти. Самый первый элемент массива программисты называют нулевым элементом и на это есть причины технического характера. Для доступа к элементам массива в один из регистров, называемый базой, заносится адрес нулевого элемента. Тогда второй регистр будет хранить индекс элемента и в совокупности это будет весьма удобной схемой. На рисунке регистр R1 указывает на ячейку 2 . Регистр R2 хранит число 3, которое является индексом элемента 6 . Мы получили к нему доступ, хотя полный адрес числа 6 нам совершенно не интересен. Если в R2 поместить ноль, то получим доступ к нулевому элементу массива. Хоть абстракции и позволяют программистам не заботиться о таких технических вопросах, но по видимому понятие нулевого элемента прижилось надежно.Итак, база и индекс позволяют организовать удобный доступ к элементам массива. В языках Си и С++ синтаксически определено, что имя массива является указателем на нулевой элемент. Также индекс массива, указывающийся в квадратных скобках может быть вычисляемой величиной в процессе работы программы.

- тип структуры;
- адрес начала массива;
- тип элемента (длина элемента массива);
- нижняя граница индекса;
- верхняя граница индекса.

Существуют различные варианты использования динамической памяти. 2.6. Строки с объявленным максимальным размером. Списковое представление строк Строка — это линейно упорядоченная последовательность символов, принадлежащих конечному множеству символов, называемому алфавитом.
- их длина, как правило, переменна, хотя алфавит фиксирован;
- обычно обращение к символам строки идет с какого-нибудь одного конца последовательности, т.е важна упорядоченность этой последовательности, а не ее индексация; в связи с этим свойством строки часто называют также цепочками;
- чаще всего целью доступа к строке является не отдельный ее элемент (хотя это тоже не исключается), а некоторая цепочка символов в строке.
В зависимости от особенности задачи, свойств применяемого алфавита и представляемого им языка и свойств носителей информации могут применяться различные способы кодирования символов. В современных вычислительных системах общепринятой является кодировка всего множества символов на разрядной сетке фиксированного размера (в 1 байт).
Хотя строки являются полустатическими структурами данных, в тех или иных конкретных задачах изменчивость строк может варьироваться от полного ее отсутствия до практически неограниченных возможностей изменения. Ориентация на ту или иную степень изменчивости строк определяет и физическое представление их в памяти и особенности выполнения операций над ними. В большинстве языков программирования (Си, Паскаль и др.) строки представляются именно как полустатические структуры.
В зависимости от ориентации языка программирования средства работы со строками занимают в языке более или менее значительное место.
В Паскале длина строки может меняться от 0 до n. Основные операции над строками реализованы как простые операции или встроенные функции. Возможны также библиотеки, обеспечивающие расширенный набор строковых операций.
- определение длины строки;
- присваивание строк;
- конкатенация (сцепление) строк;
- выделение подстроки;
- поиск вхождения.
Операция сравнения строк имеет тот же смысл, что и для других типов данных. Сравнение строк производится по следующим правилам. Сравниваются первые символы двух строк. Если символы не равны, то строка, содержащая символ, место которого в алфавите ближе к началу, считается меньшей. Если символы равны, сравниваются вторые, третьи и т.д. символы. При достижении одного конца одной из строк строка меньшей длины считается меньшей. При равенстве длин строк и попарном равенстве всех символов в них строки считаются равными.
Результатом операции сцепления двух строк является строка, длина которой равна суммарной длине строк-операндов, а значение соответствует значению первого операнда, за которым непосредственно следует значение второго операнда. Операция сцепления дает результат, длина которого в общем случае больше длин операндов. Как и во всех операциях над строками, которые могут увеличивать длину строки (присваивание, сцепление, сложные операции), возможен случай, когда длина результата окажется большей, чем отведенный для него объем памяти. Естественно, эта проблема возникает только в тех языках, где длина строки ограничивается. Возможны три варианта решения этой проблемы, определяемые правилами языка или режимами компиляции:
- никак не контролировать такое превышение, возникновение такой ситуации неминуемо приводит к труднолокализуемой ошибке при выполнении программы;
- завершать программу аварийно с локализацией и диагностикой ошибки;
- ограничивать длину результата в соответствии с объемом отведенной памяти.
- аварийное завершение программы с диагностикой ошибки;
- формирование результата меньшей длины, чем задано, возможно, даже пустой строки.
На основе базовых операций могут быть реализованы и любые другие, даже сложные операции над строками. Например, операция удаления из строки символов с номерами от n1 включительно n2 может быть реализована как последовательность следующих шагов:
- выделение из исходной строки подстроки, начиная с позиции 1, длиной n1 - 1;
- выделение из исходной строки подстроки, начиная с позиции n2 + 1, длиной, равной длине исходной строки минус n2;
- сцепление подстрок, полученных на предыдущих шагах.
Представление строк в памяти зависит от того, насколько изменчивыми являются строки в каждой конкретной задаче, и средства такого представления варьируются от абсолютно статического до динамического. Универсальные языки программирования в основном обеспечивают работу со строками переменной длины, но максимальная длина строки должна быть указана при ее создании. Если программиста не устраивают возможности или эффективность тех средств работы со строками, которые предоставляет ему язык программирования, то он может либо определить свой тип данных "строка" и использовать для его представления средства динамической работы с памятью, либо сменить язык программирования на специально ориентированный на обработку текста, в которых представление строк базируется на динамическом управлении памятью.
Представление строк в виде векторов, принятое в большинстве универсальных языков программирования, позволяет работать со строками, размещенными в статической памяти. Кроме того, векторное представление позволяет легко обращаться к отдельным символам строки, как к элементам вектора, по индексу.
Самым простым способом является представление строки в виде вектора постоянной длины. При этом в памяти отводится фиксированное количество байт, в которые записываются символы строки. Если строка меньше отводимого под нее вектора, то лишние места заполняются пробелами, а если строка выходит за пределы вектора, то лишние (обычно справа строки) символы должны быть отброшены.
Этот и все последующие за ним методы учитывают переменную длину строк. Признак конца строки — это особый символ, принадлежащий алфавиту (таким образом, полезный алфавит оказывается меньше на один символ), и занимает то же количество разрядов, что и все остальные символы. Издержки памяти при этом способе составляют 1 символ на строку.
Счетчик символов — это целое число, и для него отводится достаточное количество битов, чтобы их с избытком хватало для представления длины самой длинной строки,какую только можно представить в данной машине. Обычно для счетчика отводят от 8 до 16 битов. Тогда при таком представлении издержки памяти в расчете на одну строку составляют 1-2 символа. При использовании счетчика символов возможен произвольный доступ к символам в пределах строки, поскольку можно легко проверить, что обращение не выходит за пределы строки. Счетчик размещается в таком месте, где он может быть легко доступен — начале строки или в дескрипторе строки. Максимально возможная длина строки, таким образом, ограничена разрядностью счетчика. В Паскале, например, строка представляется в виде массива символов, индексация в котором начинается с 0, а однобайтный счетчик числа символов в строке является нулевым элементом этого массива. И счетчик символов, и признак конца могут быть доступны для программиста как элементы вектора.
В двух предыдущих вариантах обеспечивалось максимально эффективное расходование памяти (1-2 "лишних" символа на строку), но изменчивость строки обеспечивалась крайне неэффективно. Поскольку вектор — статическая структура, каждое изменение длины строки требует создания нового вектора, пересылки в него неизменяемой части строки и уничтожения старого вектора. Это сводит на нет все преимущества работы со статической памятью. Поэтому наиболее популярным способом представления строк в памяти являются векторы с управляемой длиной.
Память под вектор с управляемой длиной отводится при создании строки. Ее размер и размещение остаются неизменными все время существования строки. В дескрипторе такого вектора-строки может отсутствовать начальный индекс, так как он может быть зафиксирован раз и навсегда установленными соглашениями, но появляется поле текущей длины строки. Размер строки, таким образом, может изменяться от 0 до значения максимального индекса вектора. "Лишняя" часть отводимой памяти может быть заполнена любыми кодами — она не принимается во внимание при оперировании со строкой. Поле конечного индекса может быть использовано для контроля превышения длиной строки объема отведенной памяти.
Хотя такое представление строк не обеспечивает экономии памяти, проектировщики систем программирования, возможно, считают это приемлемой платой за возможность работать с изменчивыми строками в статической памяти.
Списковое представление строк в памяти обеспечивает гибкость в выполнении разнообразных операций над строками (в частности, операций включения и исключения отдельных символов и целых цепочек) и использование системных средств управления памятью при выделении необходимого объема памяти для строки. Однако, при этом возникают дополнительные расходы памяти. Другим недостатком спискового представления строки является то, что логически соседние элементы строки не являются физически соседними в памяти. Это усложняет доступ к группам элементов строки по сравнению с доступом в векторном представлении строки.

В однонаправленном линейном списке каждый символ строки представляется в виде элемента связного списка; элемент содержит код символа и указатель на следующий элемент. Одностороннее сцепление представляет доступ только в одном направлении вдоль строки. На каждый символ строки необходим один указатель, который обычно занимает 2-4 байта.



Многосимвольные группы (звенья) организуются в список, так что каждый элемент списка, кроме последнего, содержит группу элементов строки и указатель следующего элемента списка. Поле указателя последнего элемента списка хранит признак конца — пустой указатель. В процессе обработки строки из любой ее позиции могут быть исключены или в любом месте вставлены элементы, в результате чего звенья могут содержать меньшее число элементов, чем было первоначально. По этой причине необходим специальный символ, который означал бы отсутствие элемента в соответствующей позиции строки.
Представление строки многосимвольными звеньями постоянной длины обеспечивает более эффективное использование памяти, чем символьно-связное. Операции вставки/удаления в ряде случаев могут сводиться к вставке/удалению целых блоков. Однако, при удалении одиночных символов в блоках могут накапливаться пустые символы emp, что может привести даже к худшему использованию памяти, чем в символьно-связном представлении.
В многосимвольных звеньях переменной длины п еременная длина блока дает возможность избавиться от пустых символов и тем самым экономить память для строки. Однако появляется потребность в специальном символе — признаке указателя.
С увеличением длины групп символом, хранящихся в блоках, эффективность использования памяти повышается. Однако негативной характеристикой рассматриваемого метода является усложнение операций по резервированию памяти для элементов списка и возврату освободившихся элементов в общий список доступной памяти.
Такой метод спискового представления строк особенно удобен в задачах редактирования текста, когда большая часть операций приходится на изменение, вставку и удаление целых слов. Поэтому в этих задачах целесообразно список организовать так, чтобы каждый его элемент содержал одно слово текста. Символы пробела между словами в памяти могут не представляться.
Рассмотрим многосимвольные звенья с управляемой длиной. Память выделяется блоками фиксированной длины. В каждом блоке помимо символов строки и указателя на следующий блок содержится номера первого и последнего символов в блоке. При обработке строки в каждом блоке обрабатываются только символы, расположенные между этими номерами. Признак пустого символа не используется: при удалении символа из строки оставшиеся в блоке символы уплотняются и корректируются граничные номера. Вставка символа может быть выполнена за счет имеющегося в блоке свободного места, а при отсутствии такового — выделением нового блока. Хотя операции вставки/удаления требуют пересылки символов, диапазон пересылок ограничивается одним блоком. При каждой операции изменения может быть проанализирована заполненность соседних блоков и два полупустых соседних блока могут быть переформированы в один блок. Для определения конца строки может использоваться как пустой указатель в последнем блоке, так и указатель на последний блок в дескрипторе строки. Последнее может быть весьма полезным при выполнении некоторых операций, например, сцепления. В дескрипторе может храниться также и длина строки: считывать ее из дескриптора удобнее, чем подсчитывать ее перебором всех блоков строки.
За последнюю неделю дважды объяснял людям как организована работа с памятью в х86, с целью чтобы не объяснять в третий раз написал эту статью.
И так, чтобы понять организацию памяти от вас потребуется знания некоторых базовых понятий, таких как регистры, стек и тд. Я по ходу попробую объяснить и это на пальцах, но очень кратко потому что это не тема для этой статьи. Итак начнем.
Как известно программист, когда пишет программы работает не с физическим адресом, а только с логическим. И то если он программирует на ассемблере. В том же Си ячейки памяти от программиста уже скрыты указателями, для его же удобства, но если грубо говорить указатель это другое представление логического адреса памяти, а в Java и указателей нет, совсем плохой язык. Однако грамотному программисту не помешают знания о том как организована память хотя бы на общем уровне. Меня вообще очень огорчают программисты, которые не знают как работает машина, обычно это программисты Java и прочие php-парни, с квалификацией ниже плинтуса.
Так ладно, хватит о печальном, переходим к делу.
Рассмотрим адресное пространство программного режима 32 битного процессора (для 64 бит все по аналогии)
Адресное пространство этого режима будет состоять из 2^32 ячеек памяти пронумерованных от 0 и до 2^32-1.
Программист работает с этой памятью, если ему нужно определить переменную, он просто говорит ячейка памяти с адресом таким-то будет содержать такой-то тип данных, при этом сам програмист может и не знать какой номер у этой ячейки он просто напишет что-то вроде:
int data = 10;
компьютер поймет это так: нужно взять какую-то ячейку с номером стопицот и поместить в нее цело число 10. При том про адрес ячейки 18894 вы и не узнаете, он от вас будет скрыт.
Все бы хорошо, но возникает вопрос, а как компьютер ищет эту ячейку памяти, ведь память у нас может быть разная:
3 уровень кэша
2 уровень кэша
1 уровень кэша
основная память
жесткий диск
Это все разные памяти, но компьютер легко находит в какой из них лежит наша переменная int data.
Этот вопрос решается операционной системой совместно с процессором.
Вся дальнейшая статья будет посвящена разбору этого метода.
Архитектура х86 поддерживает стек.
Стек это непрерывная область оперативной памяти организованная по принципу стопки тарелок, вы не можете брать тарелки из середины стопки, можете только брать верхнюю и класть тарелку вы тоже можете только на верх стопки.
В процессоре для работы со стеком организованны специальные машинные коды, ассемблерные мнемоники которых выглядят так:
push operand
помещает операнд в стек
pop operand
изымает из вершины стека значение и помещает его в свой операнд
Стек в памяти растет сверху вниз, это значит что при добавлении значения в него адрес вершины стека уменьшается, а когда вы извлекаете из него, то адрес вершины стека увеличивается.
Теперь кратко рассмотрим что такое регистры.
Это ячейки памяти в самом процессоре. Это самый быстрый и самый дорогой тип памяти, когда процессор совершает какие-то операции со значением или с памятью, он берет эти значения непосредственно из регистров.
В процессоре есть несколько наборов логик, каждая из которых имеет свои машинные коды и свои наборы регистров.
Basic program registers (Основные программные регистры) Эти регистры используются всеми программами с их помощью выполняется обработка целочисленных данных.
Floating Point Unit registers (FPU) Эти регистры работают с данными представленными в формате с плавающей точкой.
Еще есть MMX и XMM registers эти регистры используются тогда, когда вам надо выполнить одну инструкцию над большим количеством операндов.
Рассмотрим подробнее основные программные регистры. К ним относятся восемь 32 битных регистров общего назначения: EAX, EBX, ECX, EDX, EBP, ESI, EDI, ESP
Для того чтобы поместить в регистр данные, или для того чтобы изъять из регистра в ячейку памяти данные используется команда mov:
mov eax, 10
загружает число 10 в регистр eax.
mov data, ebx
копирует число, содержащееся в регистре ebx в ячейку памяти data.
Регистр ESP содержит адрес вершины стека.
Кроме регистров общего назначения, к основным программным регистрам относят шесть 16битных сегментных регистров: CS, DS, SS, ES, FS, GS, EFLAGS, EIP
EFLAGS показывает биты, так называемые флаги, которые отражают состояние процессора или характеризуют ход выполнения предыдущих команд.
В регистре EIP содержится адрес следующей команды, которая будет выполнятся процессором.
Я не буду расписывать регистры FPU, так как они нам не понадобятся. Итак наше небольшое отступление про регистры и стек закончилось переходим обратно к организации памяти.
Как вы помните целью статьи является рассказ про преобразование логической памяти в физическую, на самом деле есть еще промежуточный этап и полная цепочка выглядит так:
Логический адрес --> Линейный (виртуальный)--> Физический

Все линейное адресное пространство разбито на сегменты. Адресное пространство каждого процесса имеет по крайней мере три сегмента:
Сегмент кода. (содержит команды из нашей программы, которые будут исполнятся.)
Сегмент данных. (Содержит данные, то бишь переменные)
Сегмент стека, про который я писал выше.
Линейный адрес вычисляется по формуле:
линейный адрес=Базовый адрес сегмента(на картинке это начало сегмента) + смещение
Сегмент кода
Базовый адрес сегмента кода берется из регистра CS. Значение смещения для сегмента кода берется из регистра EIP, в котором хранится адрес инструкции, после исполнения которой, значение EIP увеличивается на размер этой команды. Если команда занимает 4 байта, то значение EIP увеличивается на 4 байта и будет указывать уже на следующую инструкцию. Все это делается автоматически без участия программиста.
Сегментов кода может быть несколько в нашей памяти. В нашем случае он один.
Сегмент данных
Данные загружаются в регистры DS, ES, FS, GS
Это значит что сегментов данных может быть до 4х. На нашей картинке он один.
Смещение внутри сегмента данных задается как операнд команды. По дефолту используется сегмент на который указывает регистр DS. Для того чтобы войти в другой сегмент надо это непосредственно указать в команде префикса замены сегмента.
Сегмент стека
Используемый сегмент стека задается значением регистра SS.
Смещение внутри этого сегмента представлено регистром ESP, который указывает на вершину стека, как вы помните.
Сегменты в памяти могут друг друга перекрывать, мало того базовый адрес всех сегментов может совпадать например в нуле. Такой вырожденный случай называется линейным представлением памяти. В современных системах, память как правило так организована.
Теперь рассмотрим определение базовых адресов сегмента, я писал что они содержаться в регистрах SS, DS, CS, но это не совсем так, в них содержится некий 16 битный селектор, который указывает на некий дескриптор сегментов, в котором уже хранится необходимый адрес.
Так выглядит селектор, в тринадцати его битах содержится индекс дескриптора в таблице дескрипторов. Не хитро посчитать будет что 2^13 = 8192 это максимальное количество дескрипторов в таблице.
Вообще дескрипторных таблиц бывает два вида GDT и LDT Первая называется глобальная таблица дескрипторов, она в системе всегда только одна, ее начальный адрес, точнее адрес ее нулевого дескриптора хранится в 48 битном системном регистре GDTR. И с момента старта системы не меняется и в свопе не принимает участия.
А вот значения дескрипторов могут меняться. Если в селекторе бит TI равен нулю, тогда процессор просто идет в GDT ищет по индексу нужный дескриптор с помощью которого осуществляет доступ к этому сегменту.
Пока все просто было, но если TI равен 1 тогда это означает что использоваться будет LDT. Таблиц этих много, но использоваться в данный момент будет та селектор которой загружен в системный регистр LDTR, который в отличии от GDTR может меняться.
Индекс селектора указывает на дескриптор, который указывает уже не на базовый адрес сегмента, а на память в котором хранится локальная таблица дескрипторов, точнее ее нулевой элемент. Ну а дальше все так же как и с GDT. Таким образом во время работы локальные таблицы могут создаваться и уничтожаться по мере необходимости. LDT не могут содержать дескрипторы на другие LDT.
Итак мы знаем как процессор добирается до дескриптора, а что содержится в этом дескрипторе посмотрим на картинке:
Дескрипторы состоит из 8 байт.
Биты с 15-39 и 56-63 содержат линейный базовый адрес описываемым данным дескриптором сегмента. Напомню нашу формулу для нахождения линейного адреса:
линейный адрес = базовый адрес + смещение
[база; база+предел)
В зависимости от 55 G-бита(гранулярити), предел может измеряться в байтах при нулевом значении бита и тогда максимальный предел составит 1 мб, или в значении 1, предел измеряется страницами, каждая из которых равна 4кб. и максимальный размер такого сегмента будет 4Гб.
Для сегмента стека предел будет в интервале:
(база+предел; вершина]
Кстати интересно почему база и предел так рвано располагаются в дескрипторе. Дело в том что процессоры х86 развивались эволюционно и во времена 286х дескрипторы были по 8 бит всего, при этом старшие 2 байта были зарезервированы, ну а в последующих моделях процессоров с увеличением разрядности дескрипторы тоже выросли, но для сохранения обратной совместимости пришлось оставить структуру как есть.
Значение адреса «вершина» зависит от 54го D бита, если он равен 0, тогда вершина равна 0xFFF(64кб-1), если D бит равен 1, тогда вершина равна 0xFFFFFFFF (4Гб-1)
С 41-43 бит кодируется тип сегмента.
000 — сегмент данных, только считывание
001 — сегмент данных, считывание и запись
010 — сегмент стека, только считывание
011 — сегмент стека, считывание и запись
100 — сегмент кода, только выполнение
101- сегмент кода, считывание и выполнение
110 — подчиненный сегмент кода, только выполнение
111 — подчиненный сегмент кода, только выполнение и считывание
44 S бит если равен 1 тогда дескриптор описывает реальный сегмент оперативной памяти, иначе значение S бита равно 0.
Самым важным битом является 47-й P бит присутствия. Если бит равен 1 значит, что сегмент или локальная таблица дескрипторов загружена в оперативку, если этот бит равен 0, тогда это означает что данного сегмента в оперативке нет, он находится на жестком диске, случается прерывание, особый случай работы процессора запускается обработчик особого случая, который загружает нужный сегмент с жесткого диска в память, если P бит равен 0, тогда все поля дескриптора теряют смысл, и становятся свободными для сохранения в них служебной информации. После завершения работы обработчика, P бит устанавливается в значение 1, и производится повторное обращение к дескриптору, сегмент которого находится уже в памяти.
На этом заканчивается преобразование логического адреса в линейный, и я думаю на этом стоит прерваться. В следующий раз я расскажу вторую часть преобразования из линейного в физический.
А так же думаю стоит немного поговорить о передачи аргументов функции, и о размещении переменных в памяти, чтобы была какая-то связь с реальностью, потому размещение переменных в памяти это уже непосредственно, то с чем вам приходится сталкиваться в работе, а не просто какие-то теоретические измышления для системного программиста. Но без понимания, как устроена память невозможно понять как эти самые переменные хранятся в памяти.
В общем надеюсь было интересно и до новых встреч.
Массив — структура, стоявшая у истоков программирования. Но, несмотря на то, что массивам уделяется внимание в каждом курсе уроков по любому языку программирования, от новичков все равно ускользает много важной информации, связанной с логикой взаимодействия с этой структурой.
Цель этого поста — собрать некоторую информацию о массивах, которой когда-то не хватало мне. Пост для новичков.
Что такое массив?
Массив - это структура однотипных данных, расположенная в памяти одним неразрывным блоком.
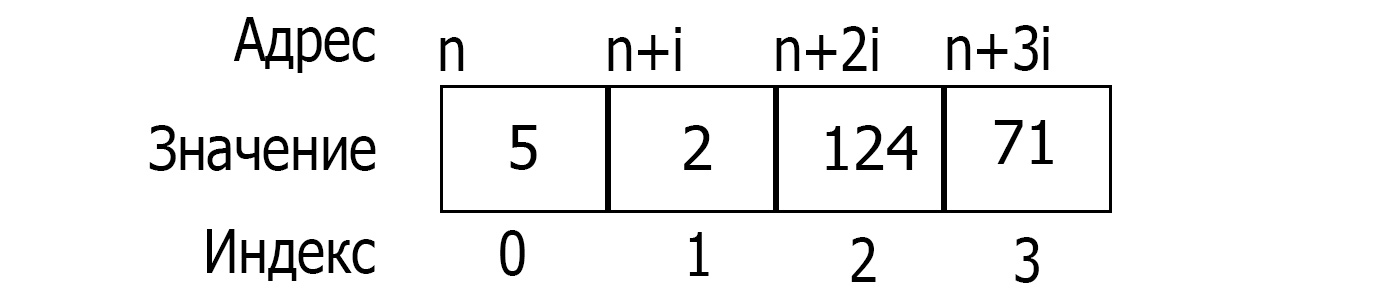
Расположение одномерного массива в памяти
Многомерные массивы хранятся точно также.
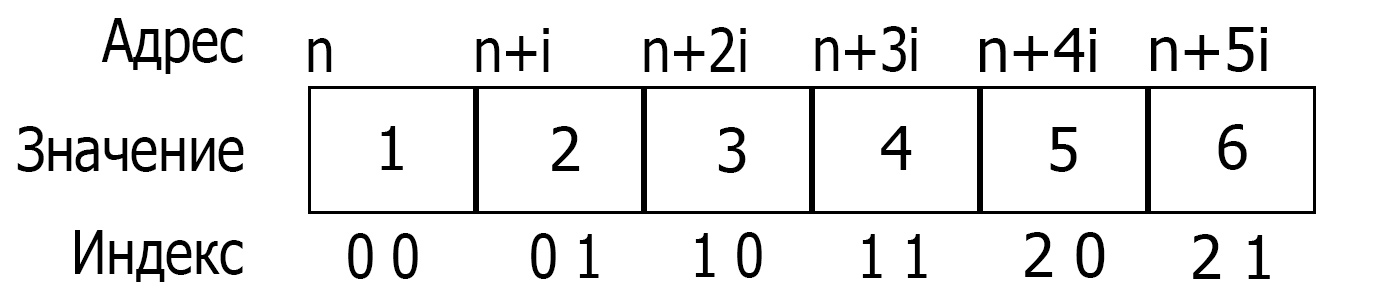
Расположение двухмерного массива в памяти
Знание этого позволяет нам по-другому обращаться к элементам массива. Например, у нас есть двухмерный массив из 9 элементов 3х3. Так что есть, как минимум два способа вывести его правильно:
1-й вариант (Самый простой):
2-й вариант (Посложнее):
Формула для обращения к элементу 2-размерного массива, где width - ширина массива, col - нужный нам столбец, а row - нужная нам строчка:
Зная второй вариант, необязательно пользоваться им постоянно, но все же знать стоит. Например, он может быть полезен, когда нужно избавиться от лишних звездочек от указателей на указатели на указатели.
А вот так можно работать с трехмерным массивом
Этим способом можно обходить трехмерные объекты, например.
Формула доступа к элементам в трехмерном массиве, где height - высота массива, width - ширина массива, depth - глубина элемента(наше новое пространство), col - столбец элемента, а row - строка элемента:
Для получения доступа к элементам массива большей размерности по аналогии в формулу добавляем новые пространства.
Алгоритмы обработки массивов
Я не буду здесь писать про алгоритмы сортировки и алгоритмы поиска, так как найти код для почти любого из этих алгоритмов не составит труда.
Изображения - это целый комплекс из разных заголовков и информации о изображении, и самого изображения хранящемся в виде двухмерного массива.
Обработка изображений хорошо научит работать с двумерными массивами. Вот некоторые алгоритмы, которые пригодились мне для обработки изображений:
1) Зеркальное отражение.
Для того чтобы перевернуть изображение по горизонтали нужно всего лишь читать массив, в котором оно содержится сверху вниз и справа налево.
По такому же принципу выполняется переворот изображения по вертикали.
2) Поворот изображения на 90 градусов.
Для поворота изображения нужно повернуть сам двухмерный массив, а чтобы повернуть массив нужно транспонировать двухмерный массив, а затем зеркально отразить по горизонтали.
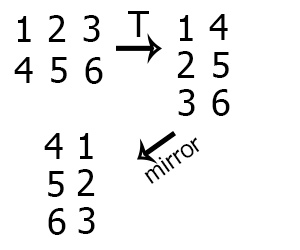
Пошаговое выполнение алгоритма
Такой алгоритм появился, когда я нарисовал график координат c точками.

График, приведший к решению
Хочу обратить ваше внимание, что здесь я применяю другой способ переворота изображения. Вместо выделения памяти под новый массив, здесь просто меняем местами первые и последние элементы.
Примечание: создать массив размерностью высоты и ширины реального изображения на стеке не выйдет. Только на куче с помощью оператора new.
Заключение
Этот небольшой пост не претендует на невероятные открытия мира информатики, но надеюсь успешно поможет немного вникнуть в устройство массивов падаванам мира IT.
Как я сказал в начале, здесь я собрал частичку того, чего не хватало мне при изучении программирования. Как бы эти вещи не казались бесполезными, все студенты университетов, изучающие информационные технологии проходят через это, и не напрасно — это помогает развивать логику и решать более сложные задачи, которые ждут далее. Приведенные выше примеры показывают некоторые важные способы взаимодействия с массивами.
Я надеюсь этот пост будет полезен, и если это будет так, то я напишу продолжение этой темы.
Читайте также: