
Как сделать запрос sql oracle
Обновлено: 03.07.2024
SQL (Structured Query Language) — это язык структурированных запросов. Он позволяет читать, записывать, удалять, сортировать и фильтровать информацию в базе данных.
В SQL используется немного слов. Он напоминает человеческий язык и поэтому его легко изучить. С его помощью можно работать с реляционными базами данных: пользователь отправляет SQL-запрос к базе данных через систему управления базами данных (СУБД). Последняя обрабатывает запрос и отправляет полученные данные пользователю.
Структура SQL-запроса
Запрос на выборку данных выглядит вот так:
Рассмотрим подробнее, как производится выборка.
SELECT и FROM
SELECT и FROM — обязательные ключевые слова в этом запросе. С их помощью можно указать, откуда и какие данные можно выбрать:
- К примеру, выбрать фамилии сотрудников из таблицы Employees:
- Получить только фамилию и размер зарплаты из этой же таблицы:
Обратите внимание: имена столбцов указываются через запятую.
Для выборки всех столбцов применяется групповой символ «*». При его использовании столбцы будут возвращены, но иногда порядок может не соблюдаться.
Групповой символ упрощает запрос, но при этом снижает производительность. Поэтому лучше использовать его в редких случаях.
WHERE
Обычно нам нужна определенная информация из таблицы. Но как ее быстро найти? WHERE помогает извлечь информацию, отфильтровав ее по одному или нескольким условиям. Это очень удобно!
С WHERE применяются такие операции:
Некоторые из операций приведены в нескольких вариантах, потому что в разных СУБД они указываются по-разному. Чтобы узнать, какие операции используются в вашей СУБД — смотрите ее документацию.
Если требуется указать значение строки , заключите его в апострофы:
Фильтр по нескольким условиям
Данные можно фильтровать не только по одному, а и по нескольким условиям и значениям. Для этого используются операторы IN, NOT IN, AND, OR.
- Отфильтровать по нескольким значениям с дополнительными условиями:
В результате этого запроса будут выбраны все сотрудники из подразделений ИТ и маркетинга.
- Отфильтровать по нескольким значениям с исключением:
Будут выбраны все сотрудники, кроме тех, кто работает в подразделениях ИТ и маркетинга.
- Выбрать сотрудников из ИТ-подразделения с зарплатой свыше 1000:
- Выбрать сотрудников из ИТ-подразделения или с зарплатой свыше 1000:
GROUP BY
С помощью необязательного предложения GROUP BY создаются группы данных. Это удобно для получения итоговых значений. Например, нужно узнать, сколько человек работает в отделе продаж. Инструкция может выглядеть так:
Этот код возвращает названия подразделений и количество работников в каждом из них. Количество сотрудников помещается в столбец с псевдонимом cnt, который мы задали с помощью ключевого слова AS.
Предложение GROUP BY указывается после WHERE и перед ORDER BY.
В GROUP BY можно указать столько столбцов, сколько нужно. В результате группы вкладываются друг в друга.
При вложении данные будут суммироваться для последней заданной группы, а не для отдельно для каждого столбца.
В предложении GROUP BY можно указать только столбцы выборки или выражения. В нем не указывается функция группирования и не применяются псевдонимы.
Если в столбце, по которому производится группирование, встречается одна или несколько строк со значением NULL, они выделяются в отдельную группу.
HAVING
С помощью предложения GROUP BY можно также указывать, какие группы включить в результат, а какие — исключить из него. Для этого используется предложение HAVING. Оно очень напоминает WHERE, но фильтрует не строки, а группы.
Этот код похож на предыдущий, но возвращает только те группы, в которых найдены три или больше сотрудников. Фильтрация выполняется по итоговому значению группы. Этим HAVING отличается от WHERE, которое фильтрует по значениям строк.
Эти предложения можно использовать вместе. Например, можно узнать, сколько сотрудников в подразделениях со штатом более трех человек, получают более 1000:
Сначала выбираются все строки, где в столбце salary содержатся значения больше 1000. А затем выбираются только те группы, в которых не меньше трех записей.
ORDER BY
Предложение ORDER BY используется для сортировки результатов запроса. В нем указываются имена столбцов, по которым нужна сортировка.
Давайте отсортируем список фамилий сотрудников:
В предложении ORDER BY можно указывать и те столбцы, которые не выбраны в операторе SELECT:
Так список фамилий сотрудников будет отсортирован по размеру зарплаты.
Сортировку можно выполнять и по нескольким столбцам. Для этого имена столбцов указывают через запятую:
Так мы увидим список сотрудников, который сначала отсортирован по фамилии, а затем — по имени.
Вместо имен столбцов можно указать их порядковые номера в операторе SELECT:
Этот код также возвращает список сотрудников с сортировкой по фамилии, а затем — по имени.
Сортировка по убыванию
В предыдущих примерах мы сортировали по возрастанию (это делается по умолчанию). Но можно сортировать и по убыванию. Для этого укажем слово DESC:
Так мы отсортируем список с именами и фамилиями в обратном алфавитном порядке.
Если обратная сортировка выполняется по нескольким столбцам, укажите ключевое слово DESC после каждого из них.
Слово DESC — это сокращение от слова DESCENDING. В запросах можно использовать как полную, так и сокращенную форму. Для сортировки в порядке возрастания тоже существует ключевое слово. Его полная форма — ASCENDING, а сокращенная — ASC. Поскольку по умолчанию выполняется сортировка по возрастанию, то это слово не указывают.
Объединение таблиц
Иногда нам нужны данные из нескольких таблиц. Рассмотрим пример:
Этот код возвратит имена и фамилии сотрудников из таблицы Employees и номера заказов из таблицы Orders, которые выполнены соответствующими сотрудниками. В предложении WHERE имена столбцов указаны с именами соответствующих таблиц. Это необходимо, чтобы СУБД могла различать столбцы employee_id из разных таблиц.
Такое объединение называется внутренним. Для него можно использовать специальный синтаксис с ключевым словом INNER JOIN. Приведенный ниже код выдаст те же результаты, что и предыдущий фрагмент:
Вместо предложения WHERE используется предложение ON, синтаксис которого совпадает с синтаксисом WHERE.
Число объединяемых таблиц в SQL не ограничено, но может ограничиваться в разных СУБД. Обратите внимание: чем больше таблиц объединяется, тем ниже производительность. Поэтому не рекомендуем объединять таблицы без особой необходимости.
Вместо заключения
SQL — простой для освоения и при этом мощный язык. Он появился в 1970-х и до сих пор используется, хотя наряду с ним появляются новые похожие языки. Этот язык используется различными СУБД: MySQL, SQLite, Oracle Database, Microsoft Access, Microsoft SQL Server, dBASE, IBM DB2.
Сегодня SQL — не просто язык формирования запросов. С его помощью можно упорядочивать и изменять данные, делать выборки, управлять доступом к ним, совместно использовать информацию и обеспечивать ее целостность. Пользуйтесь!
Highload нужны авторы технических текстов. Вы наш человек, если разбираетесь в разработке, знаете языки программирования и умеете просто писать о сложном!
Откликнуться на вакансию можно здесь .
Что такое индексы в Mysql и как их использовать для оптимизации запросов
Основные понятия о шардинге и репликации
Примеры ad-hoc запросов и технологии для их исполнения
Настройка Master-Master репликации на MySQL за 6 шагов
Как создать и использовать составной индекс в Mysql
Анализ медленных запросов (профилирование) в MySQL с помощью Percona Toolkit
Основное средство для получения информации из базы данных — это запросы, то есть команда SELECT . Базовые возможности этой команды будут рассмотрены в этом разделе, другие, более сложные возможности — в следующих разделах. В каждом разделе будут указываться отличия по сравнению с аналогичными возможностями в Microsoft SQL Server .
Поскольку во всех главных базах данных поддерживается стандарт ANSI SQL , то базовые возможности и в Oracle , и в других базах данных ( Microsoft SQL Server , IBM DB 2, Informix , Sybase , Microsoft Access ) будут схожи. Отличия — в частностях, которые стандарт SQL не определяет, но которые довольно существенны, и которые могут привести к сложностям для пользователей, которые привыкли создавать запросы к другим базам данных.
Базовый синтаксис команды SELECT в Oracle выглядит следующим образом:
SELECT [ DISTINCT ] список_столбцов FROM источник WHERE фильтр ORDER BY выражение_сортировки
Приведем пример такого запроса :
SELECT employee_id, first_name, last_name, hire_date FROM hr.employees WHERE hire_date < '01.01.2000' ORDER BY last_name
Как мы видим, пока в запросе не используются специальные возможности, он выглядит абсолютно стандартным и полностью идентичен аналогичным запросам, например, в SQL Server . Если нам нужно выбрать все столбцы из базы данных или представления, мы можем указать вместо списка столбцов звездочку:
SELECT * FROM hr.employees WHERE hire_date < '01.01.2000' ORDER BY last_name
Выводимое имя столбца можно поменять при помощи псевдонима ( alias ). Для этого достаточно просто написать имя пседвонима сразу после названия столбца или использовать ключевое слово AS (оба синтаксиса полностью равнозначны):
SELECT last_name Фамилия FROM hr.employees
SELECT last_name AS Фамилия FROM hr.employees
Особенно удобно использовать псевдонимы для вычисляемых столбцов, для которых изначально имя не предусмотрено:
SELECT last_name AS Фамилия, salary*12 AS "Зарплата за год" FROM hr.employees
Если в псевдониме используются пробелы или какие-то служебные символы, то такой псевдоним нужно поместить в двойные кавычки.
Отметим и некоторые особенности, связанные со списком столбцов в Oracle . Если в SQL Server "проблемные" имена столбцов (с пробелами и зарезервированными словами) можно было помещать в квадратные скобки (а обычно и в двойные кавычки — в зависимости от настроек сеанса), то в Oracle и тот, и другой вариант вызовет ошибку.
В список столбцов в Oracle можно включать литералы ( literals ). Литералы — это любое строковое значение, дата или число, которое помещается в список столбцов и при этом не является ни названием столбца, ни псевдонимом. Литералы будут повторяться для каждого возвращаемого столбца. Обычно они используются для создания пояснений в возвращаемом наборе результатов:
SELECT last_name AS Фамилия, 'Зарплата за год: ', salary*12 FROM hr.employees
В этом примере 'Зарплата за год: ' — это литерал, который будет выводиться для каждой записи.
Строковые литералы и литералы с датой должны заключаться в одинарные кавычки. Литералы в виде числовых значений в кавычки не помещаются.
Отметим, что литералы часто сливаются в выводимых результатах с возвращаемыми из базы данных значениями при помощи оператора конкатенации (||). Про операторы Oracle будет рассказываться в разделах 2.2, 2.3, 2.4.
При работе с литералами иногда возникает проблема, связанная с тем, что литерал сам по себе может содержать зарезервированный символ, например, одинарные кавычки. Oracle , в отличие, например, от SQL Server , позволяет пользователю самостоятельно определять символ, который будет использоваться в качестве кавычек. Выглядеть такое переопределение может. например, так:
select department _ name , q '[ It ' s assigned manager ID : ]' , manager _ id from departments
Попытка применить обычные одинарные кавычки для литерала приведет к ошибке, поскольку кавычка встречается внутри самого символьного значения литерала. Поэтому в этом примере в качестве кавычек выступают квадратные скобки.
Отметим некоторые особенности применения оператора q ':
- можно использовать как строчную букву q , так и заглавную (Q) ;
- после q должна идти обычная одинарная кавычка. Следующая одинарная кавчка определяет завершение области действия оператора q ;
- сразу после одинарной кавычкой должен идти символ, выбранный пользователем для применения в качестве кавычек. Этот символ может быть любым, за исключением пробела, перевода строки или табуляции (в том числе и одинарная кавычка). Если пользователь выбрал символ (, , ] и >. В других случаях закрытие кавычек производится при помощи того же символа, который использовался для их открытия.
И последний момент, связанный с базовым синтаксисом запросов. По умолчанию запрос возвращает из базы данных все значения, соответствующие параметрам запроса, даже если некоторые из возвращаемых значений будут полностью одинаковыми. Например, запрос
SELECT salary FROM hr . employees
вернет 107 строк, несмотря на то, что значительная часть значений будет повторяться.
Чтобы вернуть только уникальные значения (или наборы значений, если возвращается несколько столбцов), в запросе можно использовать ключевое слово DISTINCT :
SELECT DISTINCT salary FROM hr.employees
Такой запрос вернет уже 57 значений, при этом все значения будут уникальными.
Отличительной особенностью Oracle является то, что вместо DISTINCT можно использовать ключевое слово UNIQUE . SQL Server такого не позволяет.

Каждый сайт в Интернете, любой проект, обрабатывающий значительный объем информации, вынужден хранить эту информацию в тех или иных базах данных (БД). Подавляющее большинство проектов информацию сохраняют в БД реляционного типа, делая записи в различных подобиях таблиц. Как внесение новых записей, так и обращение к имеющимся, осуществляется с благодаря использованию запросов, составляемых конструкциями SQL (structured query language) – непроцедурного декларативного языка структурированных запросов. В нашем случае это подразумевает, что, используя конструкции SQL, мы будем обращаться к БД, сообщая что нужно сделать с данными, но не указывая способ, как именно это нужно сделать.
Фактически, SQL является набором стандартов, для написания запросов к БД. Последняя действующая редакция стандартов языка SQL - ISO/IEC 9075:2016.
Основываясь на указанных стандартах языка SQL, ряд организаций выпустили свои, расширенные версии стандартов указанного языка. Подобные версии иногда называют диалектами SQL.
Варианты спецификаций SQL разрабатываются компаниями и сообществами и служат, соответственно, для работы с разными СУБД (Системами Управления Базами Данных) – системами программ, заточенных под работу с продуктами из своей инфраструктуры.
Наиболее применяемые на сегодня СУБД, использующие свои стандарты (расширения) SQL:


MySQL – СУБД, принадлежащая компании Oracle.
PostgreSQL – свободная СУБД, поддерживаемая и развиваемая сообществом.
Microsoft SQL Server – СУБД, принадлежащая компании Microsoft. Применяет диалект Transact-SQL (T-SQL).
Благодаря тому, что диалекты SQL что создаются, специфицируются и используются разными организациями, имеют как общие черты, так и ряд отличий в возможностях расширений.
Общими чертами диалектов являются основные конструкции, применимые практически без отличий во многих реляционных БД. Основные отличия диалектов состоят в различиях использованных типов данных, количеством, реализацией и детальными возможностями команд. Разные диалекты применяют как разные наборы зарезервированных слов, так и разные наборы команд.
Здесь мы будем рассматривать запросы, применяя конструкции из спецификаций диалекта T-SQL.
Коснемся классификации SQL запросов.
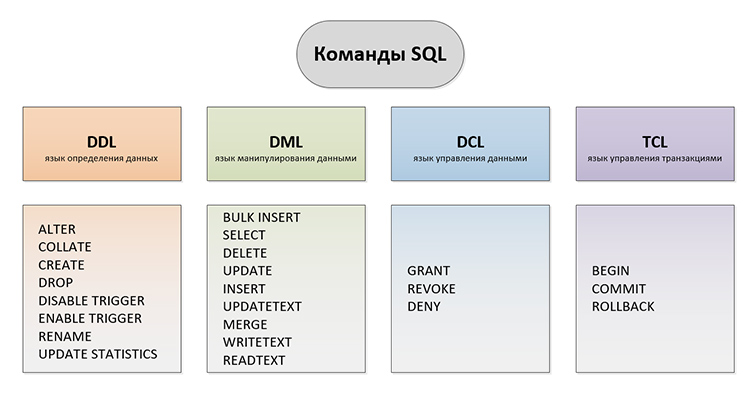
Выделяют такие виды SQL запросов:
DDL (Data Definition Language) - язык определения данных. Задачей DDL запросов является создание БД и описание ее структуры. Запросами такого вида устанавливаются правила того, в каком виде различные данные будут размещаться в БД.
DML (Data Manipulation Language) - язык манипулирования данными. В число запросов этого типа входят различные команды, используя которые непосредственно производятся некоторые манипуляции с данными. DML-запросы нужны для добавления изменений в уже внесенные данные, для получения данных из БД, для их сохранения, для обновления различных записей и для их удаления из БД. В число элементов DML-обращений входит основная часть SQL операторов.
DCL (Data Control Language) - язык управления данными. Включает в себя запросы и команды, касающиеся разрешений, прав и других настроек СУБД.
TCL (Transaction Control Language) - язык управления транзакциями. Конструкции такого типа применяют чтобы управлять изменениями, которые производятся с использованием DML запросов. Конструкции TCL позволяют нам производить объединение DML запросов в наборы транзакций.
Основные типы SQL запросов по их видам:
Ниже мы рассмотрим практические примеры применения SQL запросов для взаимодействия с БД используя запросы двух категорий – DDL и DML.
Тема связана со специальностями:
Создание и настройка базы данных
Нам нужна будет для примеров БД MS SQL Server 2017 и MS SQL Server Management Studio 2017.
Рассмотрим последовательность действий того, как создать SQL запрос. Воспользовавшись Management Studio, для начала создадим новый редактор скриптов. Чтобы это сделать, на стандартной панели инструментов выберем «Создать запрос». Или воспользуемся клавиатурной комбинацией Ctrl+N.
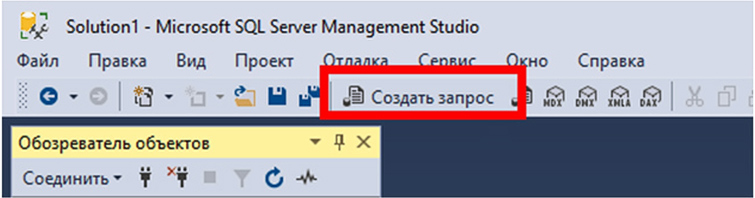
Нажимая кнопку «Создать запрос» в Management Studio, мы открываем тестовый редактор, используя который можно производить написание SQL запросов, сохранять их и запускать.
Используем для начала простые запросы SQL, благодаря которым можно создать и настроить новую БД, чтобы получить возможность в дальнейшем с ней работать.
Создадим новую БД с именем «b_library» для библиотеки книг. Чтобы это делать наберем в редакторе такой SQL запрос:
Далее выделим введенный текст и нажмем F5 или кнопку «Выполнить». У нас создастся БД «b_library».
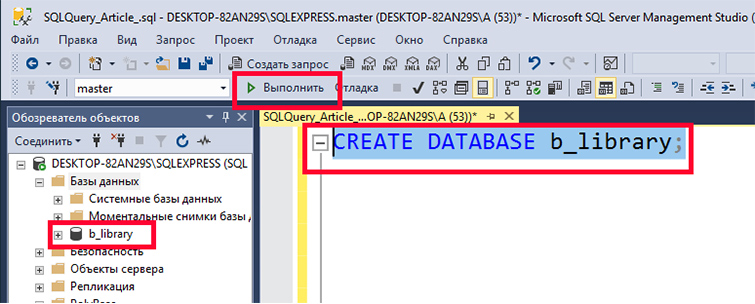
Все дальнейшие манипуляции мы можем провести с этой созданной нами БД. Для этого сначала подключимся к этой базе:
В БД «b_library» создадим таблицу авторов «tAuthors» с такими столбцами: AuthorId, AuthorFirstName, AuthorLastName, AuthorAge:
CREATE TABLE tAuthors (AuthorId INT IDENTITY (1, 1) NOT NULL,
AuthorFirstName NVARCHAR (20) NOT NULL,
AuthorLastName NVARCHAR (20) NOT NULL,
AuthorAge INT NOT NULL
);
Заполним нашу таблицу таким авторами: Александр Пушкин, Сергей Есенин, Джек Лондон, Шота Руставели и Рабиндранат Тагор. Для этого используем такой SQL запрос:
Мы можем посмотреть в «tAuthors» записи, путем отправления в СУБД простого SQL запроса:
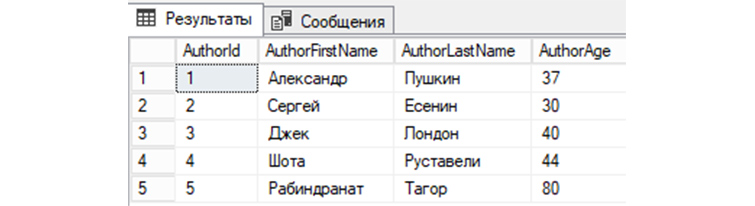
В нашей БД «b_library» мы создали первую таблицу «tAuthors», заполнили «tAuthors» авторами книг и теперь можем рассмотреть различные примеры SQL запросов, которыми мы сможем взаимодействовать с БД.
Примеры простых запросов SQL к базам данных.
Рассмотрим основные запросы SQL.
SELECT
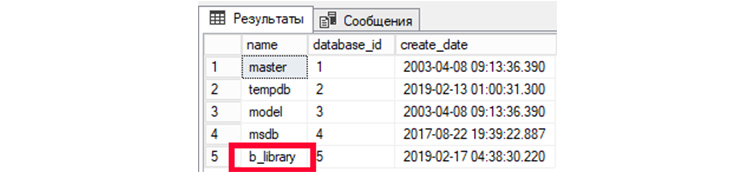
1) Выведем все имеющиеся у нас БД:
SELECT name, database_id, create_dateFROM sys.databases;
2) Выведем все таблицы в созданной нами ранее БД «b_library»:
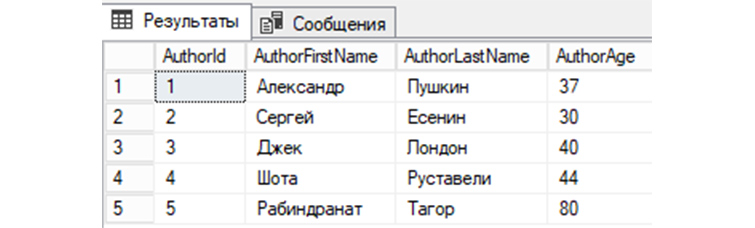
4) Выведем информацию о том, сколько у нас имеется записей строк в «tAuthors»:

5) Выведем из «tAuthors» две записи, начиная с четвертой. Используя ключевое слово OFFSET, пропустим первые три записи, а благодаря использованию ключевого слова FETCH – обозначим выборку только следующих 2 строк (ONLY):
ORDER BY AuthorId
OFFSET 3 ROWS
FETCH NEXT 2 ROWS ONLY;

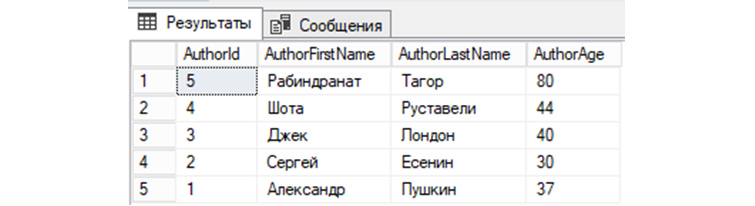
6) Выведем из «tAuthors» все записи с сортировкой в алфавитном порядке по первой букве имени автора:
8) Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:

9) Выберем из «tAuthors» записи, где имя автора AuthorFirstName начинается с «се»:

10) Выберем из «tAuthors» записи, в которых имя автора (AuthorFirstName) заканчивается на «ат»:
Видео курсы по схожей тематике:

SQL Базовый. Разбор ДЗ



11) Сделаем выборку всех строк из «tAuthors», значение AuthorId в которых равняется 2 или 4:

13) Проведем выборку из «tAuthors» по столбцам AuthorFirstName и AuthorLastName:
INSERT
INSERT – это вид запроса SQL, при применении которого СУБД выполняет добавление новых записей в БД.
Добавим в «tAuthors» нового автора – Уильяма Шекспира, 51 год. Соответственно в поле AuthorFirstName добавится Уильям, в AuthorLastName добавится Шекспир, в AuthorAge – 51. В AuthorId, в нашем случае, автоматически добавится значение, инкрементированное от предыдущего на 1.
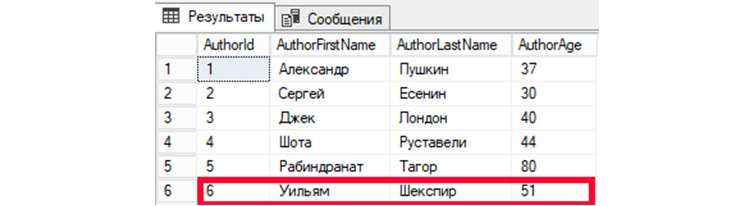
UPDATE
UPDATE – SQL запрос, позволяющий внести изменения или дописывать новую информацию в те записи, которые уже существуют.
Внесем корректировки в шестую запись (AuthorId = 6). Значения изменим для полей имени, фамилии и возраста автора.
Затем, обратимся к БД, чтобы вывести все имеющиеся записи:
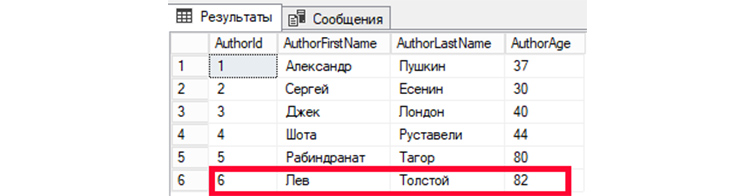
Мы видим изменения информации в записи автора под номером 6.
DELETE
DELETE – SQL запрос, выполняя который в СУБД производится операция удаления определенной строки из таблицы в БД.
Обратимся к «tAuthors» с командой на удаление строки, где AuthorId = 5:
Чтобы увидеть изменения, снова обратимся к базе для вывода всех записей:
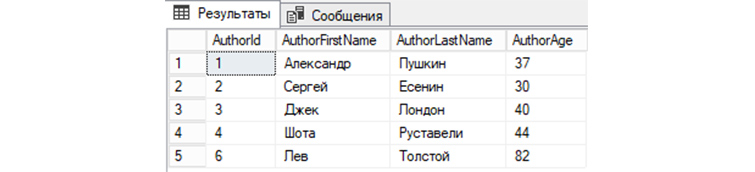
Мы видим, что запись автора под номером 5 теперь отсутствует в «tAuthors» и, соответственно, не выводится с другими записями.
DROP
DROP – ключевое слово в SQL, применяемое для удаления данных с помощью запроса. К примеру удаление некоторой таблицы из БД.
После рассмотрения ряда простых запросов к БД мы можем полностью удалить нашу таблицу «tAuthors» целиком, выполнив простой SQL запрос:
Далее рассмотрим сложные запросы SQL.
Примеры сложных запросов к базе данных MS SQL
Сложные запросы SQL представляют из себя комбинации простых запросов. Выполняясь, простые запросы возвращают сгруппированные в промежуточные таблицы наборы данных. А сложный запрос уже манипулирует данными, полученными благодаря простым «подзапросам».
- Помещением одного запроса в другой. В этом случае внешнее выражение будет называться основным запросом, а вложенное выражение - подзапросом.
- Применение с SQL запросами различных операторов объединения результатов выполнения подзапросов. Такие операторы называют реляционными.
Рассмотрим в SQL примеры сложных запросов.
Воспользуемся нашей предыдущей таблицей «tAuthors» и создадим дополнительно еще одну таблицу с книгами этих авторов – «tBooks». В качестве идентификатора авторов книг используем значение AuthorId из «tAuthors», а название книги - BookTitle.
CREATE TABLE tBooks (BookId INT IDENTITY (1, 1) NOT NULL,
BookTitle NVARCHAR (20) NOT NULL,
Author INT NOT NULL
);
Заполним «tBooks» такими книгами:
1) Сделаем выборку из БД всех книг, у которых имя автора - «Александр»:
2) Сделаем выборку данных из «tBooks» всех книг, авторами которых являются люди, с именами «Александр» или «Сергей»:
3) Сделаем выборку по книгам из таблицы «tBooks», у которых именами авторов являются НЕ «Сергей» и НЕ «Александр»:
Бесплатные вебинары по схожей тематике:

Как стать Full-Stack разработчиком?

Основы реляционных баз данных и языка SQL
4) Возьмем таблицу «tBooks» и сделаем из нее выборку всех книг с указанием как имен, так и фамилий авторов этих книг из «tAuthors»:
SELECT tBooks.BookId, tBooks.BookTitle, tAuthors.AuthorFirstName,tAuthors.AuthorLastName
FROM tBooks
JOIN tAuthors ON tAuthors.AuthorId = tBooks.Author;
Выводы
Мы с вами рассмотрели несколько вариантов простых и сложных SQL запросов. Конечно эту статью не стоит рассматривать ни как учебное пособие, ни как исчерпывающий перечень возможностей запросов в T-SQL, и других диалектах. Скорее ее можно считать примером SQL запросов для начинающих. Однако она может послужить для Вас отправной точкой.
Данные рекомендации взяты мной из руководства Oracle по настройке базы данных, со временем они практически не меняются, посмотреть их можно здесь, это глава 11.5. Ссылка может не работать, все зависит от того, как долго Oracle решит хранить этот фрагмент документации в интернете.
Не используйте SQL-функции в предикатах. Любое выражение в котором используется колонка (expression), например функция, использующая колонку, как аргумент, приведет к тому, что индекс для данной колонки (если он есть) использоваться не будет, даже если это уникальный индекс. Хотя, если для колонки имеется составной индекс (function-based) на основе применяемой в предикате функции, то он может быть использован.
где numexpr выражение числового типа, то Oracle преобразует ваше условие в:
и индекс использован не будет.
Где по числовой колонке numcol построен индекс.
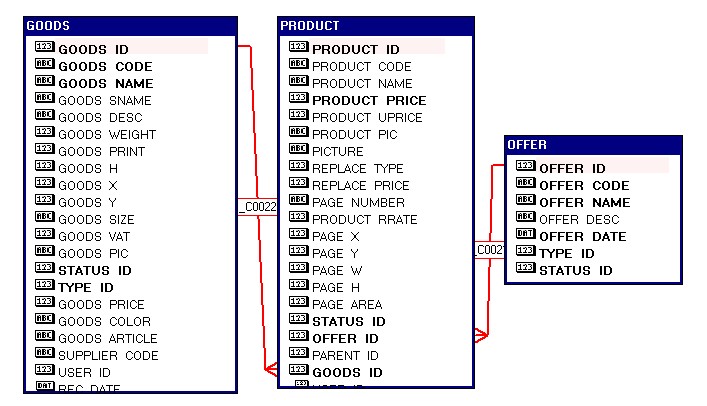
План запроса.
Практически любую задачу по получению каких-либо результатов из базы данных можно решить несколькими способами, т.е. написать несколько разных запросов, которые дадут один и тот же результат. Это, однако не означает, что база данных эти запросы будет выполнять по-разному. Также неверно мнение о том, что структура запроса может повлиять на то, как Oracle будет его выполнять, это касается порядка временных таблиц, JOINS и условий отбора в WHERE. Решение о том, как построить запрос принимает оптимизатор Oracle. Алгоритм получения сервером данных для конкретного запроса называют планом запроса.
Практически все продукты для работы с базой данных Oracle позволяют просмотреть план конкретного запроса. Так как слушатели этих лекций используют PL/SQL Developer, то для получения плана запроса в нем необходимо сделать следующее:
Существует стандартный механизм получения плана запроса. Для этого используется конструкция (команда) EXPLAIN PLAN FOR:
План запроса будет выведен в виде таблицы с одним полем, выглядит он так:
Важно ! Во всех планах запросов, первостепенное значение имеют колонки операций и названия объектов над которыми эти операции производятся. Все остальные колонки имеют оценочный характер, часть из них формируется на основе статистики, которая может устареть или вообще отсутствовать. При анализе плана запроса вы должны представлять объемы записей в таблицах, а также примерный алгоритм соединения таблиц.
В приведенном выше примере показан план запроса, полученный с помощью EXPLAIN PLAN FOR, более наглядную картину дает окно плана запроса в PL/SQL Developer:
План всегда имеет иерархическую структуру. Операция соединения результирующих наборов оперирует парами дочерних операций. Операция получения данных может использовать вспомогательную операцию, такую, например, как сканирование индекса.
Данные результирующих наборов получаются в порядке следования этих наборов в плане запроса. Операция получения данных результирующего набора может состоять из нескольких шагов, которые характеризуются глубиной операции (колонка Depth).
При анализе плана в первую очередь необходимо обращать внимание на способы, с помощью которых получены данные результирующих наборов.
Некоторые термины в плане запроса.
План запроса имеет форму таблицы, один из столбцов которой описывает тип производимых сервером операций. Вот некоторые из них, которые встречаются наиболее часто:
Анализ плана запроса.
При анализе плана запроса вам необходимо примерно представлять объемы записей в таблицах и наличие у них индексов, которые могут пригодиться при фильтрации записей. Для доступа к данным Oracle использует несколько стратегий, какие из них выбраны для каждой из таблиц можно понять из плана запроса. При просмотре плана, вам необходимо решить, правильная ли выбрана стратегия в том или ином случае. Ниже приведены краткие описания способов доступа и механизмов отбора записей при соединениях результирующих наборов.
Full Table Scan (Table Access Full).
Может показаться, что доступ к данным таблицы быстрее осуществлять через индекс, но это не так. Иногда дешевле прочитать всю таблицу целиком, чем прочитать, например, 80% записей таблицы через индекс, так как чтение индекса тоже требует ресурсов. Очень не желательна ситуация, когда эта операция стоит первой в объединении наборов записей и таблица, которая читается полностью, большая. Еще хуже ситуация с большой таблицей на второй позиции в объединении, это означает, что она также будет прочитана полностью, как минимум, один раз, а если объединение производится через NESTED LOOPS, то таблица будет читаться несколько раз, поэтому запрос будет работать очень долго.
Nested Loops.
Такое соединение может использоваться оптимизатором, когда небольшой основной набор записей (стоит первым в плане запроса) объединяется с помощью условия, позволяющего эффективно выбрать записи из второго набора. Важным условием успешного использования такого соединения является наличие связи между основным и второстепенным набором записей. Если такой связи нет, то для каждой записи в первом наборе, из второго набора будут извлекаться одни и те же записи, что может привести к значительному увеличению времени запроса. Если вы видите, что в плане запроса применен NESTED LOOPS, а соединяемые наборы не удовлетворяют этому условию, то налицо ошибка.
Hash Joins.
Используется при соединении больших наборов данных. Оптимизатор использует наименьший из наборов данных для построения в памяти хэш-таблицы по ключу соединения. Затем он сканирует большую таблицу, используя хэш-таблицу для нахождения записей, которые удовлетворяют условию объединения.
Оптимизатор использует HASH JOIN, если наборы данных соединяются с помощью операторов и ключевых слов эквивалентности (=, AND) и если присутствует одно из условий:
■ Необходимо соединить наборы данных большого объема.
■ Большая часть небольшого набора данных должна быть использована в соединении.
Sort Merge Join.
Данное соединение может быть применено для независимых наборов данных. Обычно Oracle выбирает такую стратегию, если наборы данных уже отсортированы ранее, и если дальнейшая сортировка результата соединения не требуется. Обычно это имеет место для наборов, которые соединяются с помощью операторов , >=. Для этого типа соединения нет понятия главного и вспомогательного набора данных, сначала оба набора сортируются по общему ключу, а затем сливаются в одно целое. Если какой-то из наборов уже отсортирован, то повторная сортировка для него не производится.
Cartesian Joins.
Это соединение используется, когда одна и более таблиц не имеют никаких условий соединения с какой-либо другой таблицей в запросе. В этом случае произойдет объединение каждой записи из одного набора данных с каждой записью в другом. Такое соединение может быть выбрано между двумя небольшими таблицами, а в дальнейшем этот набор данных будет соединен с другой большой таблицей. Наличие такого соединения может обозначать присутствие серьезных проблем в запросе, особенно, если соединяемые таблицы по MERGE JOIN CARTESIAN. В этом случае, возможно, упущены дополнительные условия соединения наборов данных.
Хинты.
Использование хинтов.
Хинт ставится после ключевого слова, которое определяет некую цельную конструкцию запроса, в данном разделе речь пойдет о хинтах в запросах к данным, т.е. тех, которые оформляются оператором SELECT и ключевых словах, используемых в сочетании с ним. Хинт указывается в закрытом комментарии после оператора:
В данном примере используется хинт RULE.
FIRST_ROWS.
Данный хинт дает указание оптимизатору выбрать такой план запроса при котором первые записи результатов будут получены максиально быстрым способом. Хорош при отладке запроса, чтобы убедиться, что выдается то, что необходимо. Если предполагается, что запрос вернет много записей, то при использовании такого хинта он может работать дольше.
ORDERED / LEADING.
При использовании этого хинта оптимизатор соединяет наборы данных в том порядке, в каком они следуют после оператора FROM. Вот пример разных последовательностей:
Порядок наборов данных необходимо выбирать аккуратно, чтобы соединяемые объекты имели какое-то условие связи в WHERE или после ключевого слова ON. Например в приведенном выше примере 4 версия списка во FROM приведет к перемножению таблиц GOODS и OFFER, так как они не связаны друг с другом условиями.
Данный хинт часто бывает полезен, если статистика по таблицам не собрана, план запроса не верный, и вам точно известно, как должны соединяться таблицы. При использовании данного хинта старайтесь выстроить порядок соединения так, чтобы тяжесть обработки данных следовала в сторону увеличения, т.е. сначала соедините наборы поменьше или с хорошими условиями отбора, чтобы результат их соединения был наименьшим по количеству записей, затем подключайте наборы данных большего размера.
Более удобен в использовании хинт LEADING. Он позволяет соединить наборы данных в порядке перечисления их (или их алиасов) в списке аргументов хинта:
Порядок связи в этом примере будет такой: product -> offer -> goods. Использование этого хинта предпочтительнее при отладке, если список наборов данных большой.
MATERIALIZE.
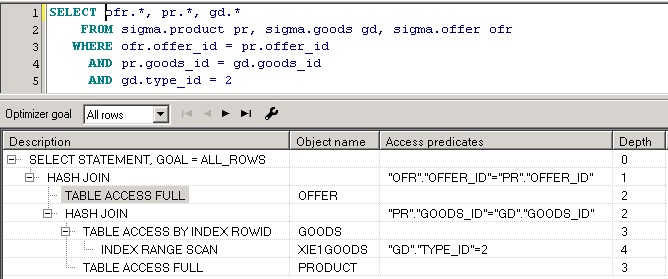
Дает указание оптимизатору построить временную таблицу (материализовать результаты) для запроса, к которому этот хинт применяется, работает только в конструкции WITH. Очень полезен при обработке больших объемов данных, так как позволяет разбить запрос на части, в этом случае улучшается читабельность запроса, а также может быть получен правильный план. Пример использования:
План запроса выглядит так:
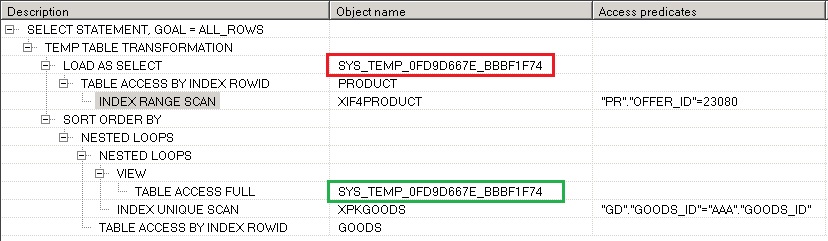
Красным цветом помечена таблица при ее создании, зеленым ее использование в соединении.
INDEX.
Дает указание оптимизатору использовать индекс при чтении данных из таблицы. Полезен тем, что может предотвратить чтение всего содержимого таблицы, если вы считаете, что этого делать не нужно. Пример использования:
Этот хинт сработает в том случае, если у таблицы есть указываемый индекс, и его можно использовать на основе одного или нескольких условий при получении данных таблицы. В приведенном примере в составе индекса есть поле OFFER_ID на второй позиции и он может быть использован, план запроса выглядит в этом случае так:

Комбинации хинтов.
Использование комбинации хинтов допустимо. Нужный эффект можно получить, если хинты в одном запросе не протеворечат друг другу. При записи хинты разделяются пробелами:
В данном примере используется хинт для установки порядка соединения наборов данных и способа доступа к таблице, противоречия в их использовании нет.
Читайте также: