
Как слить файлы в спсс
Обновлено: 04.07.2024
Войти
Авторизуясь в LiveJournal с помощью стороннего сервиса вы принимаете условия Пользовательского соглашения LiveJournal
9.5.4 SPSS - Копирование таблиц и графиков
В верхнее тематическое оглавление
Тематическое оглавление (Учебно-методическое (что там у компьютера внутри и как с ним бороться))
предыдущее по теме………………………………… следующее по теме
предыдущее по другим темам…………… следующее по другим темам
ММА УЧ(Практический) 9.5.4
Статистический анализ медицинских данных с помощью пакета статистических программ SPSS: описательная статистика
Копирование таблиц и графиков в SPSS
В процессе работы все результаты расчетов добавляются в протокол, открытый в отдельном окне. В принципе этот протокол можно распечатывать, заголовки в нем можно редактировать, а его – сохранять в виде файла (SPSS для этого использует расширение .spo), но в целом он работать с ним очень неудобно. Лучше нужные таблицы и рисунки копировать в другие программы, в том числе в Word или Excel.
Делать это можно при помощи стандартных операций с буфером обмена, хотя и здесь есть некоторые хитрости.
Если таблицу вставить в Word, то она вставится с тем количеством знаков, с которым отображается в выдаче. Если же ее вставить в Excel, то числа в ней будут вставлены с большим количеством знаков после запятой, так как SPSS проводит вычисления со значительно большей точностью, чем это показывается в выдаче. Далее можно уже средствами Excel поменять количество отображаемых знаков и скопировать эту таблицу в Word.
ВНИМАНИЕ! Далее - текст и 2 анимированные картинки суммарным весом 150К
Возможны и некоторые другие различия, в частности, во внешнем виде получаемых таблиц. Особенно это касается более сложных вариантов таблиц с объединенными ячейками, общими заголовками и т.д.
Свои проблемы есть при вставке и рисунков, причем зависит это от версии Word. В буфер обмена рисунки копируются точно так же, через контекстное меню, вызываемого правой кнопкой мыши, но при вставке в Word во многих версиях вставляются со свойством «поверх текста», что потом очень неудобно. Для того чтобы этого избежать, моно вставить рисунок через команду «Правка/Специальная вставка», там его вставлять как рисунок, но сняв опцию «Поверх текста».
Напоследок хочется рассказать о некоторых полезных свойствах программы SPSS, которые существенно облегчат работу с ней.
1. Несколько файлов (баз данных) SPSS можно объединять, добавляя при этом либо новые переменные, либо новых респондентов.
2. Построенные диаграммы можно изменять, дважды щелкнув на них мышью в окне SPSS Viewer. Простые диаграммы, как будет показано в п. 3, содержат лишь базовые возможности форматирования диаграмм (в специальном окне SPSS Chart Editor), тогда как интерактивные диаграммы предоставляют значительный набор средств, аналогичных MS Microsoft Excel.
4. Таблицы в окне SPSS Viewer можно изменять, дважды щелкнув на них мышью. Далее выберите в меню Pivot пункт Pivoting Trays. Откроется дополнительное окно, с помощью которого можно поменять местами столбцы, ряды и уровни таблицы.
5. После создания таблиц линейных или перекрестных распределений на их основе можно строить различные диаграммы. Дважды щелкните на таблице мышью, чтобы открыть ее. Затем выделите требуемые числовые значения (без названий переменных и вариантов ответа) и щелкните правой кнопкой мыши. В появившемся контекстном меню выберите Create Graph и в нем — требуемый тип диаграммы. После этого, например, будет построена интерактивная диаграмма.
7. Часто при работе с SPSS возникает необходимость скопировать результаты работы программы из окна SPSS Viewer в Microsoft Word или Microsoft Excel. Для того чтобы скопировать диаграмму, выделите ее, щелкнув на ней правой кнопкой мыши, и в открывшемся контекстном меню выберите пункт Сору. Таблицы копируются методами, различными для Microsoft Word и Microsoft Excel. Так, чтобы скопировать таблицу в Microsoft Excel, выделите ее правой кнопкой мыши и в открывшемся меню выберите пункт Сору. После этого вставка в Microsoft Excel производится обычным способом. В Microsoft Word вы можете вставить таблицу, во-первых, в виде рисунка (метафайла) — выделите ее при помощи правой кнопки мыши и выберите пункт Copy Objects (при этом таблицу нельзя изменять) — и, во-вторых, в виде собственно таблицы. Однако если вы просто скопируете и вставите ее в Microsoft Word, таблица потеряет оформление и может стать нечитаемой. Мы рекомендуем вставлять таблицу в Microsoft Word, предварительно скопировав ее в Microsoft Excel.
8. В любых диалоговых окнах SPSS, так же как и в окне SPSS Viewer, вы можете получить справку по конкретным элементам (кнопкам, полям, статистикам) — для этого щелкните на них правой кнопкой мыши. Чтобы уточнить смысл какой-либо статистики, представленной в объектах SPSS Viewer, сначала нужно открыть их двойным щелчком мыши, а затем при помощи правой кнопки мыши получить информацию об интересующей статистике.
Мы уже не раз упоминали о слабости графической подсистемы SPSS. В связи с этим исследователи строят диаграммы в MS Excel, копируя их из окна SPSS
Листинг П.1. Скрипт для переноса таблиц из SPSS Viewer в MS Word
 |
Для того чтобы перенести все таблицы из окна SPSS Viewer в MS Excel, нужно ввести между начальной и конечной строками программы в редакторе синтаксиса следующий текст (листинг П.2).
В результате выполнения данной программы будет создана новая рабочая книга MS Excel, в которой на каждой вкладке будет одна таблица из окна SPSS Viewer. Далее можно написать макрос (например, на VBA) для построения диаграмм на основании таблиц, содержащихся в MS Excel.
Для того чтобы протестировать какую-либо переменную на нормальность распределения, перенесите ее из левого списка всех доступных переменных в область для тестируемых переменных Test Variable List. Затем выберите тип распределения, на соответствие которому вы собираетесь проводить тестирование. По умолчанию выбран только тест на нормальное распределение (Normal). Также можно провести тест на распределение Пуассона (Poisson), равномерное (Uniform) и экспоненциальное распределение (Exponential). Как в тесте %2 (см. раздел 4.1), тесты на вид распределения можно проводить асимптотическими методами и точными методами (Exact). Точные методы могут применяться в тех случаях, когда асимптотические методы неприменимы (например, при малых размерах выборки). Мы рекомендуем всегда проверять результаты асимптотических методов при помощи точных. Вывод точных тестов на вид распределения осуществляется при помощи кнопки Exact. Вид соответствующего диалогового окна аналогичен виду окна для теста %2. Напомним, что в нем следует выбрать параметр Monte-Carlo и указать доверительный уровень 95 %.
 |
Рис. П.1. Диалоговое окно One-Sample Kolmogorov-Smirnov Test
 |
Рис. П.2. Таблица One-Sample Kolmogorov-Smirnov Test
В результатах данного теста (окно SPSS Viewer) наше внимание должна привлечь значимость тестовой характеристики: асимптотическая (строка Asymp. Sig. (2-tai-led)) и точная (строка Monte Carlo Sig.). На рис. П.2 представлен общий вид выводимых результатов при тесте на нормальное распределение. Так как нулевая (исходная) гипотеза для тестирования состоит в наличии нормального распределения, вероятность (статистическая значимость) менее 0,05 означает, что исследуемая переменная не подчиняется закону нормального распределения. Таким образом, значимая тестовая величина означает отсутствие, а незначимая — наличие исследуемого распределения.
Работа с данными нескольких файлов одновременно иногда способна сбить с тол-ку даже опытных пользователей. Нередко файлы данных создаются при помощи разного программного обеспечения и имеют разные форматы. Это порождает раз-личные проблемы их совместного использования, из которых мы рассмотрим наи-более типичную: дополнение рабочего файла SPSS содержимым внешнего файла. При этом возможны две ситуации дополнения данных рабочего файла SPSS:
ff из внешнего файла Excel;
ff из внешнего файла SPSS.
Мы рассмотрим оба варианта, но сначала сформулируем общие рекомендации.
ff Если вы намерены добавлять переменные, убедитесь, что порядок следования наблюдений в рабочем и внешнем файлах одинаков.
ff Если вы намерены добавлять объекты, убедитесь, что порядок следования пе-ременных в рабочем и внешнем файлах одинаков.
ff Настройте форматы каждой переменной рабочего файла данных, чтобы они соответствовали данным внешнего файла (если добавляемая переменная со-держит буквенные символы, либо замените буквы числами во внешнем файле, либо поменяйте тип переменной на строковую в рабочем файле).
ff Перед добавлением данных создайте резервную копию рабочего файла, чтобы к ней можно было вернуться в случае неудачного переноса данных.
| Объединение данных разных файлов |

Следует иметь в виду, что чем больше соответствия между структурами рабочего и внешнего файлов, тем меньше вероятность ошибок при слиянии данных.
Если вы выполнили указанные рекомендации, то перенос данных из одного (внеш-него) в другой (рабочий) файл не составит труда.
В Откройте рабочий и внешний файлы с данными.
В Во внешнем файле выделите необходимый для переноса блок данных.
В Скопируйте его в буфер обмена.
В Разверните свернутое окно SPSS с рабочим файлом на вкладке Данные.
В Установите фокус ввода в левую верхнюю ячейку того места, куда вы намере-ваетесь поместить переносимые данные.
В В меню Правка выберите команду Вставка.
После этого таблица редактора данных дополнится новыми данными. Проверьте корректность переноса данных. Если допущена ошибка, в меню Правка рабочего файла выберите команду Отменить. После возврата в исходное состояние проверь-те свои действия и повторите попытку.
Указанная последовательность действий требует большого внимания и определенной сноровки и применима для небольших фрагментов данных. К счастью, существует более надежный способ объединения данных — слияние рабочего и внешнего файлов.
Слияние файлов допустимо, когда и рабочий, и внешний файлы созданы при помо-щи редактора данных SPSS и имеют одинаковые имена переменных (когда мы до-бавляем объекты) или одинаковые число и порядок следования наблюдений (когда мы добавляем переменные). Таким образом, если внешним является файл Excel, то перед слиянием необходимо на его основе создать внешний файл SPSS (см. гла-ву 3). Структура создаваемого файла должна быть максимально согласована со структурой рабочего файла. Для этого, дополнительно к общим рекомендациям, из-ложенным ранее, нужно настроить форматы каждой переменной файлов так, чтобы они были одинаковыми, и проверить идентичность имен переменных файлов.
Хотя эти рекомендации не являются обязательными, все же следует иметь в виду, что чем больше соответствия между структурами файлов, тем меньше вероят-ность возникновения ошибок при слиянии. Особенное внимание следует уделять идентичности имен переменных, их форматам и расположению в файлах данных. Обратите внимание также на то, что при добавлении переменных одинаковый по-рядок следования наблюдений в файлах обязателен.
Добавление наблюдений
После завершения шага 3, описанного ранее в этой главе, у вас уже должен быть открыт файл ex01.sav.
Шаг 4к Для добавления наблюдений в меню Данные выберите команду Слить файлы Добавить наблюдения. На экране появится диалоговое окно, по-казанное на рис. 4.10.
80 Глава 4.Управление данными


Рис. 4.10.Диалоговое окно Добавить наблюдения
C помощью диалогового окна Добавить наблюдения можно выбрать внешний файл данных, предназначенный для слияния с открытым (рабочим) файлом. Если нужный внешний файл есть в списке Открытый набор данных, то для доступа к нему достаточно щелкнуть на его имени.
Предположим, создан файл ex01a.sav, в котором содержатся данные о 10 новых учащихся с теми же переменными, что и файл ex01.sav. В данном случае ex01.sav является рабочим файлом, а ex01a.sav — внешним. Иногда внешний файл распола-гается на внешнем носителе. Как правило, в этом случае проще ввести полный путь к файлу с клавиатуры в формате f:\имя_файла.sav. После задания имени фай-ла щелкните на кнопке Открыть и затем Продолжить.
После того как внешний файл задан, на экране появляется диалоговое окно, пока-занное на рис. 4.11. Как видите, в заголовке окна отображено полное имя внешнего файла.

Рис. 4.11.Диалоговое окно Добавить наблюдения
| Объединение данных разных файлов |
Список Непарные переменные в данном случае пуст (как и следовало ожидать). Если же файлы содержат непарные переменные, все они попадают в этот спи-сок: переменные рабочего файла помечаются знаком * (звездочка), а переменные внешнего файла — знаком + (плюс). После того как вы убедитесь, что структуры рабочего и внешнего файлов совпадают, необходимо проверить на идентичность структуру каждой пары переменных. Перед щелчком на кнопке OK вы можете при необходимости выполнить два дополнительных действия.
ff Если вы не хотите, чтобы какая-либо из парных переменных присутствовала
3 новом файле, выделите ее щелчком в списке Переменные в новом активном наборе данных и перенесите ее в левое окно при помощи кнопки со стрелкой.
ff По умолчанию все непарные переменные исключаются из нового рабочего файла. Если же вы хотите включить какую-либо из непарных переменных
42 рабочий файл, выделите ее в списке Непарные переменные и переместите
43 список Переменные в новом активном наборе данных щелчком на кнопке со стрелкой. Переменная войдет в рабочий файл, а ее отсутствующие значения будут восприниматься как пропущенные.
Шаг 5к Чтобы выполнить слияние файлов ex01.sav и ex01a.sav, в диалого-вом окне, показанном на рис. 4.10, задайте имя файла ex01a.sav. По-том щелкните на кнопке Продолжить и в открывшемся диалоговом окне (см. рис. 4.11) — на кнопке OK.
После выполнения этого шага в редакторе данных оказывается открытым новый рабочий файл с добавленными объектами, которому необходимо дать новое имя
53сохранить. Содержимое старого рабочего файла и внешнего файла при этом останутся прежними.
Добавление переменных
После завершения предыдущей пошаговой процедуры вам необходимо заново от-крыть файл ex01.sav.
Шаг 4л После выполнения шага 3 должно быть открыто окно редактора данных
(ex01.sav - Редактор данных IBM SPSS Statistics).
55 меню Данные окна редактора данных выберите команду Слить файлы Добавить переменные. На экране появится диалоговое окно, показанное ранее на рис. 4.10, только заголовок окна будет другим: Добавить пере-
Слияние с добавлением переменных очень похоже на слияние с добавлением на-блюдений. Начало выполнения обеих пошаговых процедур фактически одинаково: на экране появляется диалоговое окно, в котором вы указываете имя внешнего файла и щелкаете на кнопке Продолжить. При добавлении переменных после этого открывается диалоговое окно, показанное на рис. 4.12. В его заголовке отражено полное имя внешнего файла. Обратите внимание, что для демонстрации данной
82 Глава 4.Управление данными
процедуры мы создали еще один специальный файл ex01b.sav, который содержит переменные идентификационного номера и класса для тех же наблюдений (уча-щихся), что и в файле ex01.sav, а также новую переменную тест6 — результат до-полнительного тестирования.

Рис. 4.12.Диалоговое окно Добавить переменные
Парные переменные попадают в список Исключенные переменные и помечаются символом + (плюс), указывающим на то, что они принадлежат внешнему файлу. Переменные, включенные в новый рабочий файл, перечисляются в списке Новый активный набор данных: переменные старого рабочего файла помечаются символом
57 (звездочка), а новые переменные — символом + (плюс).
Следующим и очень важным действием является задание ключевой переменной. Необходимо, чтобы порядок следования значений в ключевых переменных обоих файлов был одинаковым. В нашем примере в роли ключевой переменной реко-мендуется использовать переменную № (идентификационный номер), поскольку
в значения уникальны для каждого наблюдения. Значения переменной № долж-ны быть упорядочены, например, по возрастанию. После того как вы убедитесь, что в обоих файлах ключевые переменные отсортированы одинаково, установите флажок Сливать по ключу в отсортированных файлах, выделите ключевую пере-менную в списке Исключенные переменные и щелкните сначала на нижней кноп-ке со стрелкой, чтобы перенести ее в поле Переменные-ключи, а потом — на кноп-ке OK.
| Агрегирование данных |
Ниже приведен пример слияния рабочего файла ex01.sav с внешним файлом ex01b. sav, где в качестве ключевой переменной выступает переменная №, упорядоченная по возрастанию.
Шаг 5л В диалоговом окне Добавить переменные, открытом после выполнения шага 4л, выполните следующие действия.
и Задайте имя файла ex01b.sav, а потом щелкните на кнопке Продол-жить. На экране появится диалоговое окно, показанное на рис. 4.12.
и Установите флажок Сливать по ключу в отсортированных файлах,
списке Исключенные переменные щелкните на переменной №, что-бы выделить ее, и щелкните на нижней кнопке со стрелкой. Имя № появится в списке Переменные-ключи.
и Щелкните на кнопке OK.
и На экране появится предупреждение Слияние по ключу будет невоз-можно, если данные не были отсортированы по ключевой переменной
порядке возрастания. Щелкните на кнопке OK.
Если у вас возникнут проблемы при выполнении этого примера, проверьте, дей-ствительно ли переменная № упорядочена по возрастанию в обоих файлах.
После выполнения этого шага в редакторе данных оказывается открытым новый рабочий файл с добавленными объектами, которому необходимо дать новое имя
и сохранить. Содержимое старого рабочего файла и внешнего файла при этом останутся прежними.
Агрегирование данных
Агрегирование данных позволяет создавать такие значения переменных, каждое из которых представляет собой результат объединения группы исходных значений, например среднее. В процессе агрегирования задается группирующая переменная (например, номер респондента), каждое значение которой неоднократно встреча-ется в исходных данных. Затем для каждого значения группирующей переменной вычисляются новые значения агрегируемых переменных исходя из их исходных значений по заданной функции (например, среднее).
и качестве примера будем использовать файл ex021.sav (см. описание в главе 14).
и нем значения переменных НАЧАЛО, СЕРЕДИНА, КОНЕЦ представлены для каждо-го респондента дважды (в две строки), в соответствии с переменной Отсрочка: без отсрочки (0) и с отсрочкой (1). Соответственно, номер каждого респондента (пере-менная N) повторяется дважды. Предположим, исследователь желает агрегиро-вать значения переменных НАЧАЛО, СЕРЕДИНА, КОНЕЦ так, чтобы для респондента с неповторяющимся номером N каждое значение этих переменных представляло собой среднее двух исходных значений (с отсрочкой и без нее).
После выполнения шага 2 на экране должно быть окно редактора данных SPSS.
Шаг 3м
Глава 4.Управление данными
Откройте файл данных, с которым вы намерены работать (в нашем слу-чае — это файл ex021.sav). Если он расположен в текущей папке, то вы-полните следующие действия.
и Выберите в меню Файл команду Открыть Данные или щелкните на кнопке Открыть данные панели инструментов.
и В открывшемся диалоговом окне дважды щелкните на имени ex021. sav или введите его с клавиатуры и щелкните на кнопке OK.
Шаг 4м 1. В меню Данные выберите команду Агрегировать данные, чтобы от-крыть окно, показанное на рис. 4.13.
Поле Группирующая переменная предназначено для помещения переменной, по-вторяющимся значениям которой должна соответствовать группа агрегируемых значений. А переменные, для которых агрегируются значения, переносятся в поле Итоги для переменной(ых). Для нашего примера группирующей переменной высту-пает номер респондента (N), а агрегируемые переменные – НАЧАЛО, СЕРЕДИНА, КОНЕЦ. В связи с тем, что для переменных Инт и Знач значения для повторяю-щихся N идентичны, то результаты агрегирования для них, в случае вычисления среднего, будут равны исходным значениям. Поэтому они тоже могут быть поме-щены в список Итоги для переменной(ых).
Группа переключателей Сохранить управляет судьбой агрегированных перемен-ных. В нашем случае целесообразно создание нового набора данных, который по-сле проверки результата агрегирования может быть сохранен.
Кнопка Функция позволяет задавать другие способы агрегирования, нежели приня-тое по умолчанию вычисление среднего, а кнопка Имя и Метка позволяет задавать имена агрегируемым переменным, иные, чем присваиваемые по умолчанию.
На следующем шаге создадим новый набор данных с именем ex021agg.sav, содер-жащий агрегированные переменные НАЧАЛО, СЕРЕДИНА, КОНЕЦ: каждое новое их значение будет равно среднему двух исходных значений (с отсрочкой и без). Так-же включим в этот набор значения переменных Инт и Знач.
Шаг 5м 1. В окне Агрегировать данные щелкните по переменной N, затем – по кнопке со стрелкой, чтобы перенести ее в поле Группирующая пере-менная.
в Перенесите переменные Инт, Знач, НАЧАЛО, СЕРЕДИНА, КОНЕЦ в поле Итоги для переменной(ых). Для этого нажмите на клавиатуре клави-шу Ctrl и, удерживая ее, щелкните последовательно на именах этих переменных, для их выделения. Затем щелкните на соответствую-щую кнопку со стрелкой.
в В области Сохранить установите переключатель Создать новый набор данных… и задайте его имя ex021agg.
в Для выполнения команды щелкните по кнопке ОК.
| Реструктурирование данных |

Рис. 4.13.Диалоговое окно Агрегирование данных
В результате выполнения последнего шага создан новый набор данных ex021agg. sav, в котором группирующая переменная N содержит неповторяющиеся номера, а каждое значение переменных НАЧАЛО, СЕРЕДИНА и КОНЕЦ представляет собой среднее для двух исходных значений соответствующих переменных (с отсрочкой и без нее). Далее этот набор данных может быть сохранен как новый файл данных.
Основным инструментом анализа и визуализации статистических данных для меня всегда был Excel. Я работаю с ним ежедневно. По нему написал больше всего заметок и прочитал наибольшее число книг. Пожалуй, лучшее сочетание статистики и Excel я нашел в книге Левин. Статистика для менеджеров с использованием Microsoft Excel. Вторым инструментом, к которому я только прикоснулся, был R (см., например, Алексей Шипунов. Наглядная статистика. Используем R!). А недавно прочитал любопытную книгу Нил Дж. Салкинд. Статистика для тех, кто (думает, что) ненавидит статистику. В ней автор все примеры иллюстрирует в программе SPSS. Так что я решил попробовать и этот продукт.
На сайте IBM доступна пробная версия, которая будет работать на вашем ПК 14 дней. Регистрируетесь и скачиваете программу SPSS Statistics. При регистрации запомните пароль. Он вам пригодится для входа в программу. После запуска появляется приветственное окно:
Рис. 1. Приветственное окно SPSS; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Если вы не хотите видеть этот экран каждый раз при запуске SPSS, то в левом нижнем углу окна кликните Не показывать это диалоговое окно в будущем.
Кликните Закрыть в правом нижнем углу экрана. Появится окно Редактор данных. По виду и функционалу Редактор похож на электронную таблицу, как лист Excel.
Рис. 2. Редактор данных
Хотя этого и не видно, когда SPSS открывается в первый раз, но есть еще одно открытое (хотя и неактивное) окно. Это Окно вывода (Viewer). Оно показывает создаваемые вами статистические результаты и графики. Набор данных создается при помощи Редактора данных, а после анализа или построения графиков вы изучаете результаты анализа в Окне вывода.
Рис. 3. Окно вывода
Панель инструментов и строка состояния
Если вы хотите узнать, что делает иконка на панели инструментов, просто наведите на нее указатель мыши. Некоторые кнопки на панели инструментов затенены. Это означает, что они не активны.

Рис. 4. Панель инструментов

Рис. 5. Строка состояния
Использование справки
Справка настолько подробна, что может указать вам путь, даже если вы новичок в работе с программой. Меню Справка содержит 10 разделов.
Рис. 6. Меню справки
Нажмите Темы, и перейдете в браузер на страницу центра знаний IBM на русском языке. Здесь представлена собственно справка, а также Учебное пособие, Разбор конкретных случаев, Инструктор по статистике, Разделы для подключаемых модулей Python и R.
Открытие файла
Вы можете импортировать данные из Excel, или ввести значения в таблицу, после чего сохранить в новом файле SPSS, или открыть готовый файл. В этой заметке мы используем файл Sample Data Set.sav. Пройдите по меню Файл –> Открыть –> Данные. Выберите файл. Данные загрузятся в окно редактора:
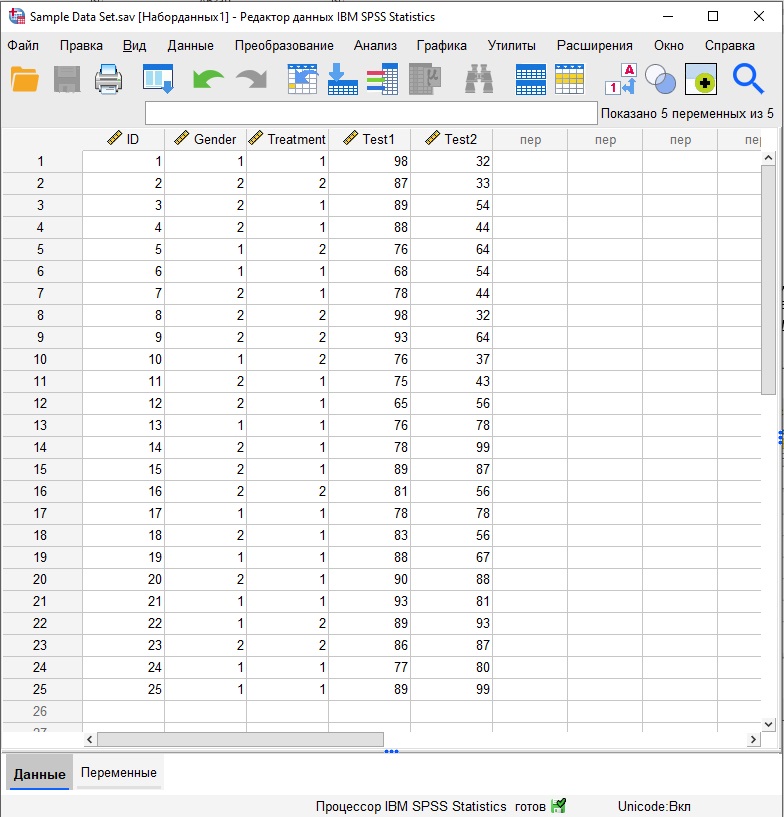
Рис. 7. Данные загружены из файла в окно редактора
Таблица и диаграмма
Допустим, мы хотим посчитать, сколько мужчин и женщин находится в нашей выборке, и вывести результат в виде столбчатой диаграммы. В окне Редактора данных пройдите по меню Анализ –> Описательные статистики –> Частоты. В открывшемся окне Частоты, выберите Gender, нажмите кнопку для переноса переменной в правое окно (или дважды кликните на Gender). Нажмите копку Диаграммы. Выберите Столбчатые. Нажмите Продолжить. Нажмите Ok.
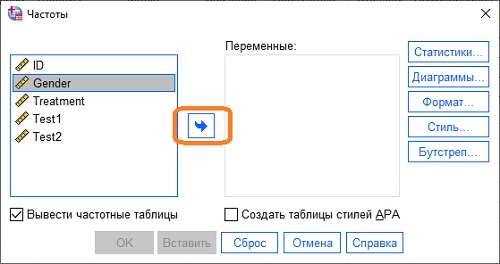
Рис. 8. Выбор переменной для анализа частоты
В окне вывода появится таблица и диаграмма:
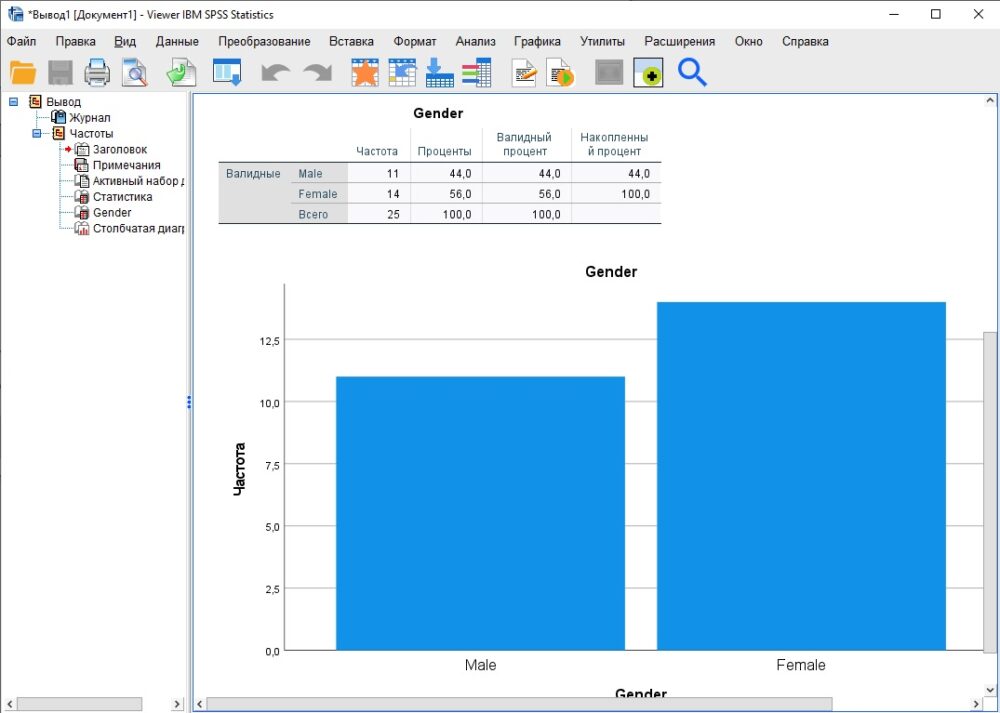
Рис. 9. Таблица и диаграмма в окне вывода
Оценка t-критерия
Давайте проверим, отличаются ли средние значения результатов Test 1 у мужчин и женщин. Этот анализ основан на t-критерии для независимых выборок. В редакторе данных пройдите по меню Анализ –> Сравнение средних –> Т-критерий для независимых выборок. В открывшемся окне переместите переменную Test1 в область Проверяемые параметры, а переменную Gender – в область Группировать по:
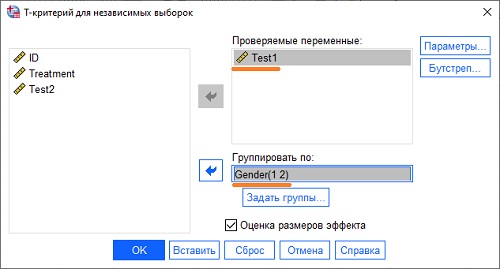
Рис. 10. Настройка расчета t-критерия для независимых выборок
Нажмите Ok. Программа сформирует таблицы проверки по t-критерию, и покажет их в окне вывода:
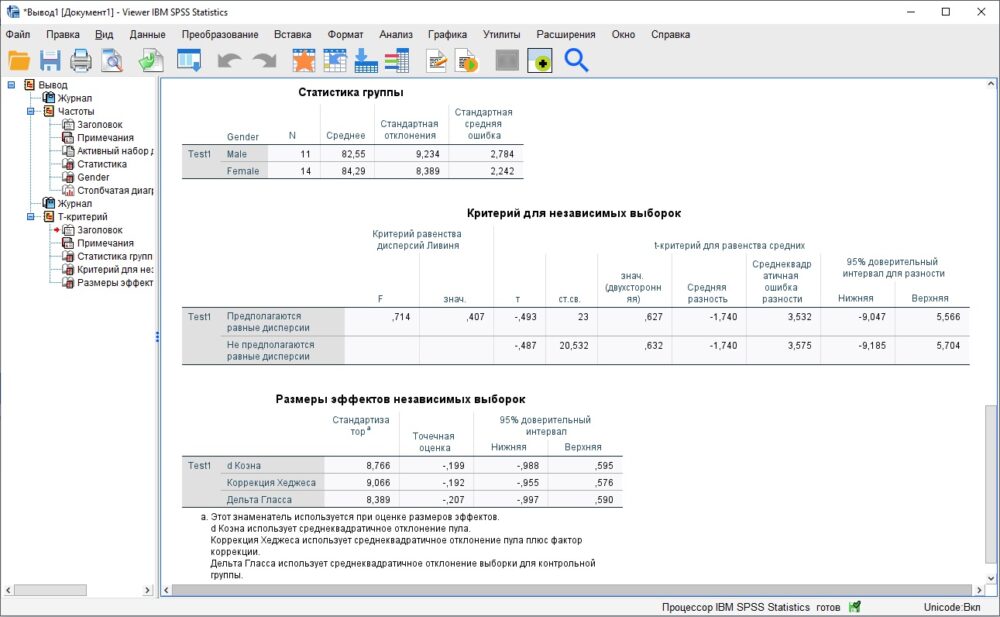
Рис. 11. Результаты проверки t-критерия для независимых выборок
T-тест показал, что различие между мужчинами и женщинами при прохождении Test1 незначимо.
Создание и редактирование файла данных
Давайте создадим набор данных, который только что загрузили из файла Sample Data Set.sav. Сначала определим переменные, а затем введем данные. В окне Редактора данных пройдите по меню Файл –> Создать –> Данные. Откроется новое окно Редактора данных. Обратите внимание, что окно открылось на вкладке Переменные (SPSS подсказывает, что сначала надо заняться ими).
Если вы поместите курсор в первую ячейку в колонке Имя, введёте любое имя и нажмёте Enter, SPSS для всех характеристик переменной автоматически проставит значения по умолчанию (см. строку 1 на рис. ниже).
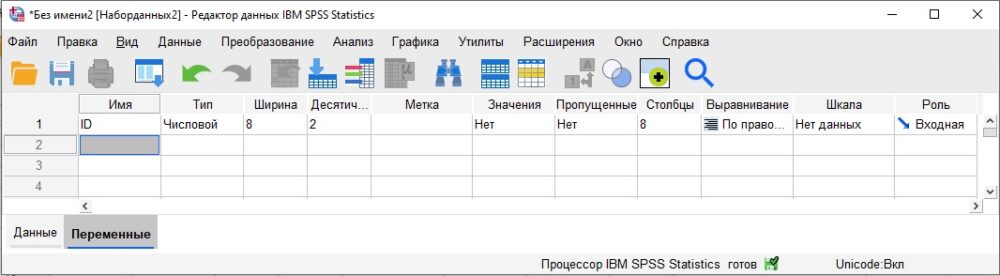
Рис. 12. Параметры по умолчанию
Подробнее о параметрах переменной:
- Имя переменной должно начинаться с буквы, иметь длину не более 64 символов, не содержать пробелы, подробнее см. здесь;
- Тип:
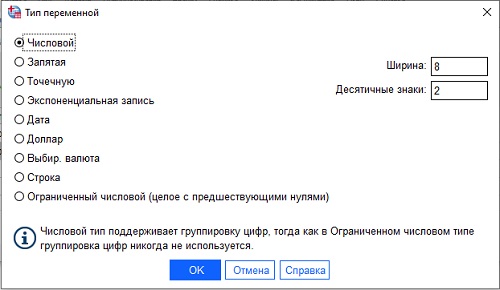
Рис. 13. Типы переменных
- Ширина задает количество символов в столбце, содержащем данную переменную;
- Десятичные определяет количество десятичных знаков;
- Метка задает метку переменной длиной до 256 символов;
- Значения устанавливает соответствие числовых значений и категорий; например, 1 для мужчин и 2 для женщин;
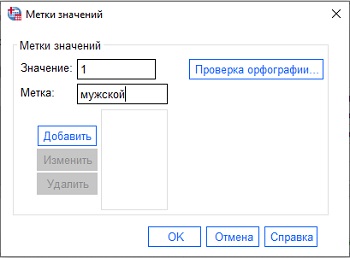
Рис. 14. Введение значений для категорийных переменных
Категорийные переменные в SPSS можно вводить в виде текстовых строк, например, Male и Female, а можно назначить им значения. Когда дело дойдет до анализа, окажется, что очень трудно работать с нечисловыми записями. Но при визуальном просмотре файла, наоборот, имена (метки) нагляднее. Окно Метки значений позволяет вводить в SPSS числа, а выводить на экран метки: и волки сыты, и овцы целы. Чтобы это работало, находясь в Редакторе данных на закладке Данные, перейдите в меню Вид, и поставьте галочку напротив Метки значений.
- Пропущенные – указывает, как обращаться с пропущенными значениями;
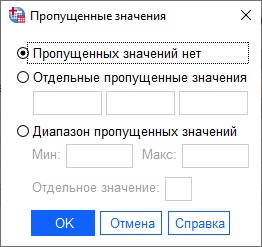
Рис. 15. Управление пропущенными значениями
- Ширина столбца определяет количество символов, выделенное для переменной в окне представления данных;
- Выравнивание – определяет, как будут выровнены данные в ячейке (влево, вправо, по центру);
- Мера – определяет шкалу измерения, которая лучше всего описывает переменную (номинальная, порядковая или интервальная);
- Роль – определяет роль, которую играет переменная в анализе (входная, целевая и т.д.).
Определите следующие переменные:
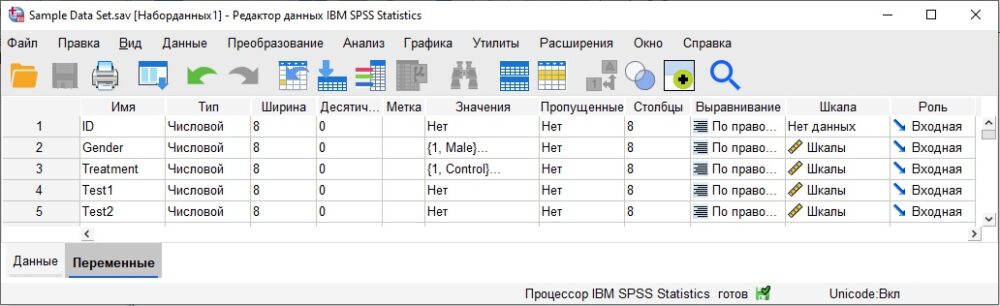
Рис. 16. Пять переменных в окне Редактора данных на закладке Переменные
Теперь вы можете переключиться на вкладку Данные и просто ввести все данные, которые представлены на рис. 7.
Печать из SPSS
Чтобы распечатать весь файл данных или его часть:
- убедитесь, что файл, который вы хотите напечатать, находится в активном окне;
- кликните Файл –> Печать;
- откроется диалоговое окно печати (рис. 17);
- выберите, что вы хотите распечатать: файл целиком или выделенный фрагмент (если предварительно фрагмент не был выбран, эта опция неактивна); нажмите Ok.
Рис. 17. Диалоговое окно печати
Вместо выбора принтера можно задать создание файл *.pdf.
Создание диаграммы в SPSS
Воспользуемся данными из файла Sample Data Set.sav. Откройте файл, на вкладке Данные, кликните меню Графика. Выберите одну из опций: Мастер диаграмм, Панель выбора диаграмм, Устаревшие диалоговые окна. Последняя опция позволяет выбрать один из стандартных типов диаграмм. Первые две опции проведут вас по пути создания диаграммы, наиболее подходящей к выбранным данным.
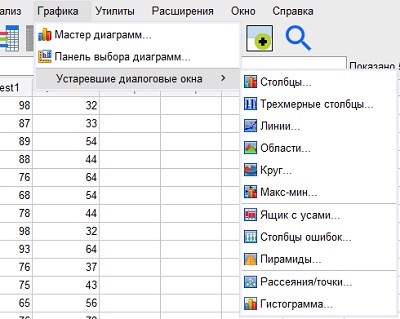
Рис. 18. Типы диаграмм
Выберите Столбцы, откроется диалоговое окно, предлагающее несколько вариантов оформления:

Рис. 19. Виды столбчатой диаграммы
Выберите Простая и Итоги по группам наблюдений. Нажмите Задать. Откроется окно Простые столбцы. Задайте, что будет анализировать диаграмма:
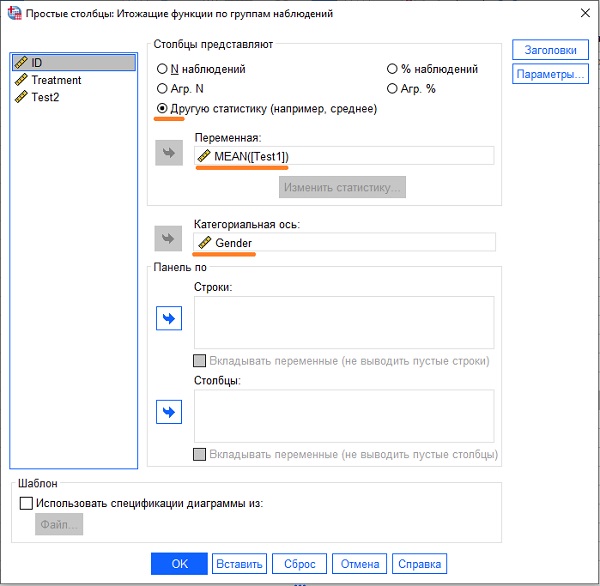
Рис. 20. Параметры аналитики диаграммы
Нажмите Ok. В окне вывода появится диаграмма: среднее значение Test1 раздельно по полу:
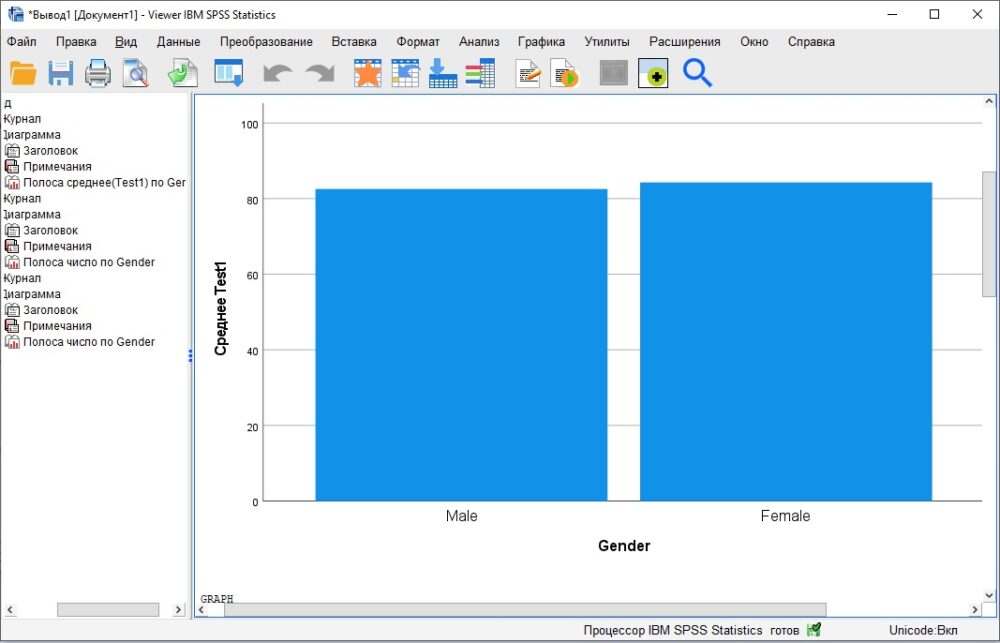
Рис. 21. Средние результаты Теста 1
Сохранение диаграммы
Диаграмма является частью окна вывода. В этом окне сохраняется любой выполняемый вами анализ. Диаграмма не является самостоятельной сущностью, и ее нельзя сохранить в качестве таковой. Для того чтобы сохранить диаграмму, вам нужно сохранить содержимое всего окна вывода. Для этого:
- кликните Файл –> Сохранить;
- задайте имя для окна вывода и папку;
- нажмите Ok; вывод сохранится в файле с расширением *.spo.
Редактирование диаграммы
Для изменения диаграммы используйте Редактор диаграмм. Чтобы вызвать его дважды кликните на диаграмме в окне вывода.
Чтобы добавить заголовок кликните на соответствующей иконке на панели инструментов Редактора диаграмм:
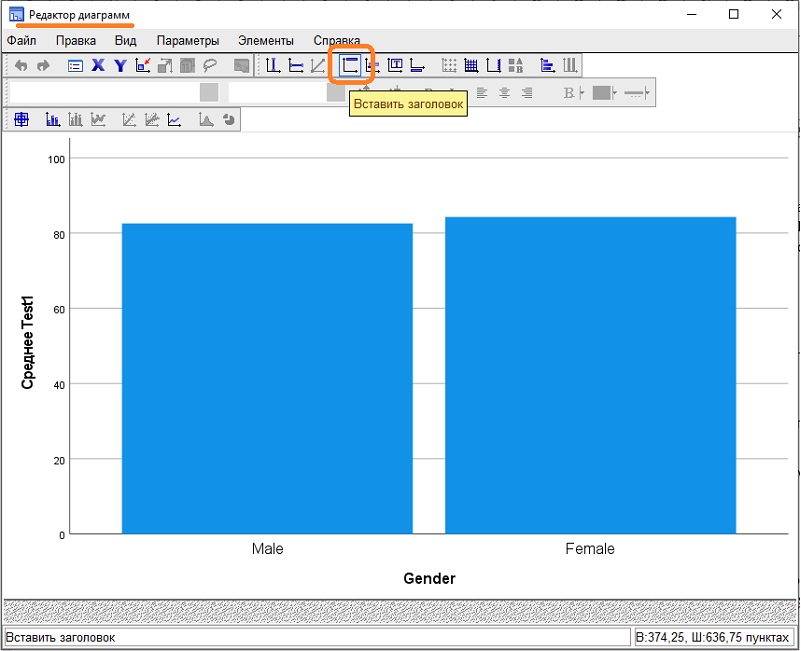
Рис. 22. Кнопка Редактор диаграмм
На диаграмме появится область для ввода заголовка и окно Свойства, где можно выбрать шрифты, границы и заливку. Для добавления подзаголовка (или даже нескольких) кликните на иконке Вставить заголовок повторно.
Для изменения любого элемента дважды щелкните на нем. Можно отдельно щелкнуть на названии оси, подписях и самой оси. В первых двух случаях можно будет отредактировать шрифты и стили оформления, а в последнем – масштаб.
Чтобы выйти из Редактора диаграмм просто кликните на крестике окна или пройдите Файл –> Закрыть.
Описание данных
Частоты и сопряженные таблицы. Частоты подсчитывают количество случаев возникновения определенного значения. Сопряженные таблицы позволяют подсчитать количество случаев возникновения определенного значения с разбивкой по одной или более категориям, например, по полу и возрасту. Для вычисления частот перейдите в окно Редактора данных, кликните Анализ –> Описательные статистики –> Частоты. Откроется диалоговое окно Частоты (см. выше рис. 8). Дважды щелкните мышью по переменным, для которых вы хотите посчитать частоты. В нашем случае это Test 1 и Test 2:
Рис. 23. Диалоговое окно Частоты
Щелкните по кнопке Статистики. Откроется диалоговое окно Частоты: статистики. В разделе Разброс отметьте Стандартное отклонение. В разделе Положение центра распределения отметьте Среднее:
Рис. 24. Диалоговое окно Частоты: Статистики
Нажмите Продолжить, а затем Ok.
В окне вывода появится три таблицы: обобщенная, и подробная для каждой переменной – Test 1 и Test 2:
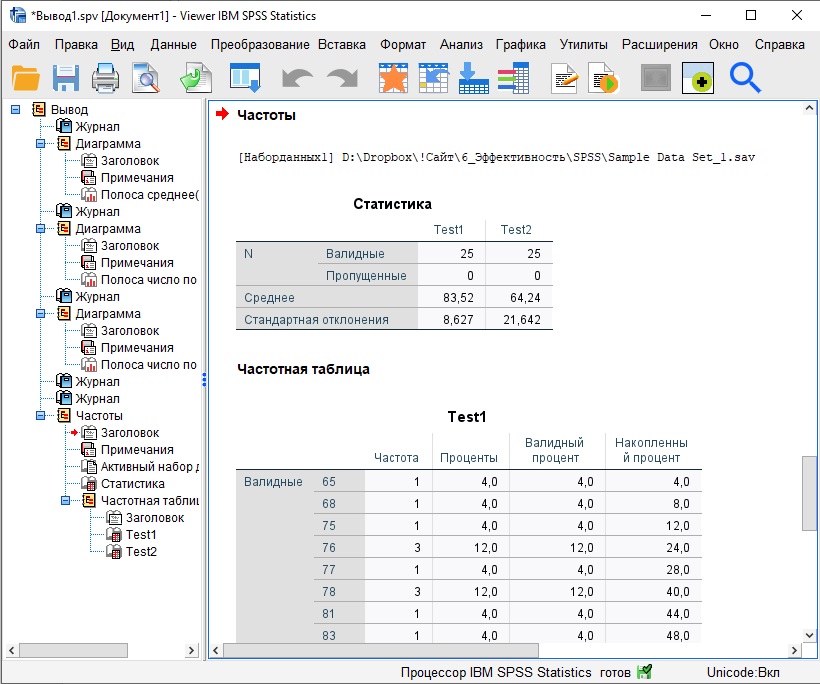
Рис. 25. Обобщенная статистика частот и фрагмент подробной таблицы частот Test 1
Выход из SPSS
Кликните Файл –> Выход. SPSS позаботится о том, чтобы сохранить все не сохраненные ранее или отредактированные окна, а затем закроется.
Только что вы кратко познакомились с SPSS. Однако эти навыки ничего не значат, если вы не понимаете смысла того, что делаете. Так что не восхищайтесь своими или чужими навыками пользования такими программами, как SPSS. Восхищайтесь, когда люди могут рассказать, что означает тот или иной вывод и какой ответ он дает на поставленный вопрос. И особенно восхищайтесь, если вы сами можете это сделать!
1 комментарий для “SPSS Statistics быстрый старт”
Читайте также: