
Как сохранить файл csv из jupiter notebook
Обновлено: 02.07.2024
Ну что, начинаю тут вещать и собирать свои лайфхаки. Без них бы я не разобралась в том, что знаю сейчас.
В Jupyter’е есть как минимум с десяток классных функций упрощающих жизнь всем, для примера возьму импорт и экспорт датафреймов:
pd.read_csv(filename) | Загрузить CSV file
pd.read_table(filename) | Из текстового файла с разделителями (например, TSV)
pd.read_excel(filename) | Загрузить Excel file
pd.read_sql(query, connection_object) | Загрузка из таблицы / базы данных SQL
pd.read_json(json_string) | Чтение из строки, URL или файла в формате JSON
pd.read_html(url) | Разбирает html URL, строку или файл и извлекает таблицы в список датафреймов
pd.read_clipboard() | Берет содержимое вашего буфера обмена и передает его в read_table()
pd.DataFrame(dict) | Словарь, ключи для имен столбцов, значения для данных в виде списков
df.to_csv(filename) | Записать в CSV file
df.to_excel(filename) | Записать в Excel file
df.to_sql(table_name, connection_object) | Записать в SQL table
df.to_json(filename) | Записать в JSON format
Сегодня расскажу немножко про боль при сохранении cvs в excel, ключевое почему не срабатывает просто сухое to_excel() - нужно сначала записать данные в эксель, а после сохранять.
Например у вас загружен в Jupyter csv с помощью pd.read_csv(filename)
Ниже будет перевод материала из вот этой статьи на медиуме, спасибо @Stephen Fordham.
У Стивена очень подробно все описано, даже с примером как в файл сохранить несколько датафреймов в разные вкладки. Я же представлю скрин того, как сохранить один датафрейм.

Опишу то что мы видим, чтобы использовать Pandas для записи объектов Dataframe в Excel, необходимо установить 2 библиотеки. Это библиотеки xlrd и openpyxl соответственно. Для удобства эти библиотеки можно установить, не выходя из Jupyter Notebook, просто добавив к команде префикс ! подписать с последующей установкой pip . Когда эта ячейка будет выполнена, вывод будет либо «Требование уже выполнено», либо установка будет выполнена автоматически.
Далее все проще, как пишет Стивен в своей публикации — От Pandas Dataframe к Excel за 3 шага

If you need to keep the Jupyter Notebook output data for some reason and download it as a file csv/zip(for larger files)/.ipynb(all cells) on your local machine then you have several options depending on the server and configuration. If tried to investigate all possible ways - the result is in this post:
Download the whole notebook
This is useful when you want to download the whole notebook with all cells, outputs and states. Sometimes the files are too big and this method is not convenient or you may need only a specific output file. In this case you can check the next section.
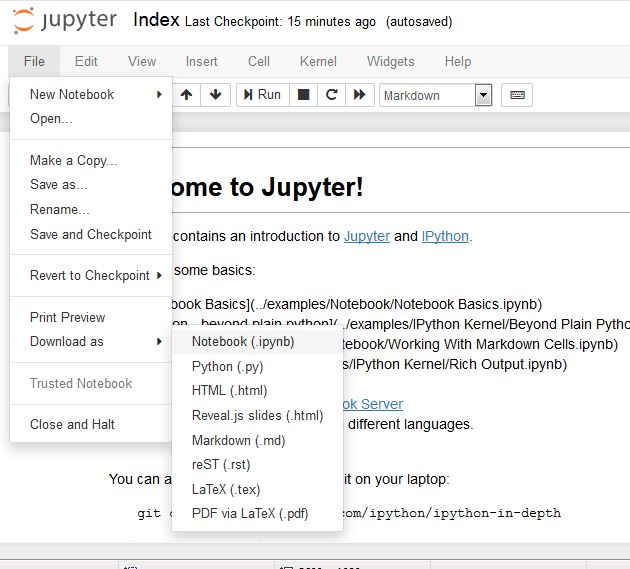
For Jupyter notebook you can download the notebooks as .ipynb then you can:
- Open your notebook in Jupyter
- Click File
- Download as
- Choose format:
- Notebook (.ipynb)
- Python (.py)
- HTML (.html)
- Markdown (.md)
- LaTeX (.tex)
- PDF via LaTeX (.pdf)
![jupyter_download]()
Python 3 Download CSV from an Jupyter Notebook
This is an update for Python 3. If you need to download a file:
- title = "Download CSV file" - is the name which is going to be shown in the browser as download link
- filename = "data.csv" - this is the name for the downloaded file
- file = '/tmp/report/stats/hours.txt' - this is the absolute location of the file which you want to download (from the server)
You can download text and CSV files.
If you like to check the files on the server than you can use jupyter magics like:
Create and download CSV/zip file
In this section you will see how to create a single output file in Jupyter and download the file as CSV or zip depending on the size. Note that some browsers will work only with small sized dataframes. For example Chrome's max data URI size is 2MB. In this case, this is after Base64 encoding.
For the simple and small data frame which can be download as CSV file you can use:
This will not work for larger dataframes. In this case you can zip your file and download it as a zip. This ensures working with a large DataFrame without the need of server configurations or additional setup. This is the example which allows you creating csv or zip file with Jupyter/iPython Notebook:
the usage(in the cell) for csv and zip is:
Direct download with FileLinks('/path/to/')
Assuming that you have the files stored on the server and proper configuration to download files then you can use this python code in order to get any file from the server. If the configuration is not correct you will be redirected to wrong address and the file will be unavailable for download:
Using extension to download folders
In order to enable it:
- install it by:
- enable it by:
- You can test that you have a new button next to the apply button which is downloading the folder content as an archive.
Download files with Linux command
Another option for downloading information from your jupyter server if the files are stored on the server is by linux commands like:
![]()
Рассмотрим три библиотеки по работе с геоданными: gmaps, ipyleaflet и более продвинутую по сравнению с предыдущими – folium. Забегая вперед, скажем, что лучше использовать folium, так как в ней удобнее строить интерактивные карты и работать со слоями. В конце статьи вы найдете ссылки на блокноты с кодом.
Установка Jupyter
Установим блокноты Jupyter следующей командой:
Запустим блокноты Jupyter:
1. Библиотека gmaps
Начнем с простого – библиотеки gmaps. Для работы с ней нужен API-ключ. Как его получить читайте на сайте Google Maps Platform.
Помимо gmaps нам понадобятся инструменты интерактивного управления ipywidgets , widgetsnbextension и библиотека для обработки и анализа данных pandas . Они устанавливаются как через консоль ( pip install ), так и прямо из блокнота через восклицательный знак ( !pip install ):
Активируем виджеты следующими командами:
1.1. Карта точек WiFi
Рис. 1. Карта с маркерами точек WiFi (gmaps)![Рис. 1. Карта с маркерами точек WiFi (gmaps)]()
За основу возьмем датасет, размещенный на портале открытых данных Москвы, в котором содержится информация о 2.8 тыс. бесплатных точек Wi-Fi. На каждой 1001-й строчке датасета дублируются названия столбцов. Во избежание ошибок при обработке набора данных, удалим эти строчки из таблицы. Очищенный массив доступен в репозитории на Гитхабе.
Какую информацию возьмем из датасета? Нам нужны координаты ( Latitude_WGS84 , Longitude_WGS84 ), адрес ( Location ) и количество точек доступа ( NumberOfAccessPoints ).
Cоздадим список wifi_points , состоящий из словарей, в каждом из которых хранится вышеперечисленная информация о каждой точке. Затем создадим отдельный список marker_coordinates с координатами и переведем элементы списка из типа строка str в тип вещественное число float , потому что координаты – это число, а не строчка.
sep – разделитель между столбцами.
encoding – кодировка файла.info_box_template – формирует HTML-форму с описанием точки Wi-Fi.
<dl> – создает контейнер.
<dt> – заголовок.
<dd> – описание.marker_info – список, содержащий форматированные строчки с описанием точек Wi-Fi: адрес точки ( Location ) и количество работающих точек Wi-Fi ( NumberOfAccessPoints ).
marker_layer – создает слой маркеров с соответствующими координатами.
Если при запуске блокнота выскочила ошибка Figure(layout=FigureLayout(height='420px')) , то перезапустите блокнот, но не через панель управления блокнотом ( Kernel → Restart ), а через консоль.
fig = gmaps.figure() – инициирует создание карты.
fig.add_layer(marker_layer ) – добавляет слой с маркерами на карту.
fig – запускает карту.2. Библиотека ipyleaflet
ipyleaflet – интерактивная библиотека виджетов, основанная ipywidgets. Библиотека использует карты OpenStreetMap.
Установим библиотеки pandas, ipyleaflet и ipywidgets:
2.1. Карта точек WiFi
Рис. 2. Карта с маркерами точек WiFi (ipyleaflet)![Рис. 2. Карта с маркерами точек WiFi (ipyleaflet)]()
Создадим карту с точками Wi-Fi, но уже с помощью библиотеки ipyleaflet. Воспользуемся датасетом из раздела про gmaps:
markers – список из координат маркеров.
locations_info – список из адресов и количества точек Wi-Fi.
for i in range(len(markers)) – каждый из элементов на карте представляет из себя слой, поэтому напишем цикл создающий нужное количество слоев. Один слой – один маркер.
m – отрисовывает карту с маркерами.
Если виджеты не отображаются, перезапустите блокноты Jupyter через консоль.2.2. Маршрут марафона
Рис. 3. Маршрут 5 км московского марафона (ipyleaflet)![Рис. 3. Маршрут 5 км московского марафона (ipyleaflet)]()
Построим маршрут 5 км московского марафона: импортируем из библиотеки ipyleaflet модуль «Муравьиный путь» AntPath и добавим маркеры Старт и Финиш! .
marathon_path – координаты марафона.
start_marker и finish_marker – координаты маркеров Старт и Финиш! соответственно.
start.value и finish.value – описания маркеров старта и финиша, которые появятся во всплывающем окне при клике на маркер.
zoom_slider – ползунок масштаба.
color – цвет линии.
pulse_color – цвет бегущих муравьев.
2.3. Маршрут марафона с иконками AwesomeIcon
Рис. 4. Маршрут марафона с иконками AwesomeIcon (ipyleaflet)![Рис. 4. Маршрут марафона с иконками AwesomeIcon (ipyleaflet)]()
Заменим стандартные иконки маркеров на иконки из каталога AwesomeIcon:
start_icon и finish_icon – содержат элементы из библиотеки AwesomeIcon.
marker_color – цвет маркера.
icon_color – цвет иконки.
2.4. Маршрут марафона с собственными иконками
Рис. 5. Маршрут марафона с собственными иконками (ipyleaflet)![Рис. 5. Маршрут марафона с собственными иконками (ipyleaflet)]()
Добавим собственные иконки с помощью модуля Icon :
Импортируем из библиотеки ipyleaflet модуль Icon , чтобы использовать собственные иконки.
icon_url – ссылка на иконку.
icon_size=[x, y] – задает размеры иконки: x – длина, y – высота.
2.5. Карта 85 субъектов РФ
Рис. 6. Карта 85 субъектов РФ (ipyleaflet)![Рис. 6. Карта 85 субъектов РФ (ipyleaflet)]()
Создадим карту с 85 субъектами РФ. Координаты границ субъектов возьмем из json-файла. Данные актуальны на 2015 год и в них есть дефект с Чукотским Автономным округом, но для нашей задачи – демонстрации возможностей библиотеки – этого вполне достаточно. Очищенная версия лежит в репозитории.
load_data – функция, которая записывает файл с данным в локальное хранилище.
random_color – функция, генерирующая случайные цвета для субъектов РФ.
style и hover_style – задают графическое отображение субъекта по умолчанию и при наведении на него курсора мыши.
2.6. Интерактивная карта РФ (по клику)
Рис. 7. Интерактивная карта 85 субъектов РФ (ipyleaflet)![Рис. 7. Интерактивная карта 85 субъектов РФ (ipyleaflet)]()
Сделаем карту интерактивной: при клике на субъект под картой появится название центрального города субъекта:
handle_click – функция, которая принимает именованные аргументы.
['name'] – имя субъекта.
geo_json.on_click(handle_click) – подключает к карте событие (вывод на экран) при клике на субъект.
2.7. Больше интерактива
Рис. 8. Интерактивная карта 85 субъектов РФ (ipyleaflet)![Рис. 8. Интерактивная карта 85 субъектов РФ (ipyleaflet)]()
Теперь, с помощью функции handle_hover сделаем так, чтобы название центрального города субъекта появлялось при наведении курсора мыши на субъект:
handle_hover – функция, принимающая именованные аргументы.
geo_json.on_click(handle_hover) – подключает к карте событие при наведении на субъект.
2.8. Хороплет-карта США по COVID-19
Рис. 9. Хороплет-карта карта США по COVID-19 (ipyleaflet)![Рис. 9. Хороплет-карта карта США по COVID-19 (ipyleaflet)]()
Построим хороплет-карту (фоновая картограмма) штатов США по COVID-19. На хороплет-карте цветом с различной степенью насыщенности отображается интенсивность какого-либо показателя. Данные по заболеваемости возьмем из репозитория университета Джона Хопкинса, а координаты границ штатов с сайта библиотеки ipyleaflet . Слегка изменим csv-файл, добавив в него второй столбец State с почтовыми сокращениями штатов США (Alabama – AL и так далее), чтобы была связь со вторым ключом ( id ) для каждого штата из json-файла. Также удалим несколько штатов из csv-файла, границы которых отсутствуют в json-файле.
geo_json_data – загрузка json-файла с координатами границ штатов.
сonfirmed – загрузка csv-файла с данными по заболеваемости.
confirmed = dict. – создает словарь с ключем Почтовое название штата и значением Количество подтвержденных случаев заражения .
geo_data – координаты границ штатов.
choro_data – хороплет-данные, количество заболевших в каждом штате.
colormap – цвет из палитры ColorBrewer.
3. Библиотека folium
Теперь воспользуемся библиотекой folium, которая также работает на картах OpenStreetMap, но обладает большими возможностями по сравнению с ipyleaflet.
3.1. Установка folium
Установим folium следующей командой:
3.2. Два слоя на одной карте
Рис. 10. Хороплет-карта США по COVID-19 (folium). Два слоя на одной карте.![Рис. 10. Хороплет-карта США по COVID-19 (folium). Два слоя на одной карте.]()
Построим карту по COVID-19 в США с двумя слоями: количество заболевших в каждом штате и летальность.
columns – столбцы, которые используются для построения карты.
key – ключ, используемый для построения карты. По умолчанию id .
name – название карты.
fill_color – цвет из палитры ColorBrewer. Если данных в столбце нет ( NaN ), то цвет будет серый.
legend_name – описание под шкалой.
show – определяет, показывать ли слой при загрузке карты. По умолчанию значение True .
![Рис. 11. Хороплет-карта США по COVID-19 (folium). Два слоя на одной карте.]()
Рис. 11. Хороплет-карта США по COVID-19 (folium). Два слоя на одной карте.
3.3. Добавляем интерактив: всплывающий текст
Рис. 12. Интерактивная хороплет-карта США по COVID-19 (folium)![Рис. 12. Интерактивная хороплет-карта США по COVID-19 (folium)]()
Сделаем так, чтобы при наведении курсора мыши на штат всплывало название штата:
covid_map.geojson.add_child. – добавляет всплывающее окошко с названием штата.
3.4. Две карты в одном окне
Рис. 13. Две карты в одном окне (folium).![Рис. 13. Две карты в одном окне (folium).]()
Создадим две карты в одном окне с помощью плагина DualMap . Для этого добавим к основной карте m дочерние карты m1 и m2 через запись m.m1 и m.m2 соответственно:
folium.TileLayer(" ") – добавляет на карту картографический слой. В нашем случае: openstreetmap, Stamen Terrain и cartodbpositron.
m.m1 и m.m2 – создает две карты: первая карта (слева) и вторая карта (справа).
.add_to(m) , .add_to(m.m1) , .add_to(m.m2) – добавляют маркеры на обе карты, только на первую карту и только на вторую соответственно.
3.5. Группируем маркеры
Рис. 14. Группируем маркеры в (folium)![Рис. 14. Группируем маркеры в (folium)]()
Создадим группы маркеров с возможностью включения и отключения их видимости:
plugins.FeatureGroupSubGroup(figure, "name") – создает группы маркеров с именем name .
m.add_child(group1) – добавляет группы маркеров на карту.
folium.Marker([59.93863, 30.31413]).add_to(group1) – добавляет маркер в группу.
Мы проделали большую работу и познакомились с тремя географическими библиотеками: gmaps, ipyleaflet и folium. С их помощью научились:
![]()
Jupyter Notebook — важный инструмент для специалиста по науке о данных. С его помощью можно выполнять базовые задачи, такие как очистка данных, визуализация, создание моделей машинного обучения и многие другие. В Jupyter Notebook можно использовать Python и R (в зависимости от ядра), сохранять результаты выполнения кода в ячейках и делиться ими с другими людьми.
В Python можно группировать данные и создавать сводные таблицы с помощью встроенных функций из библиотеки pandas.
Классический способ создания сводных таблиц — с помощью старого доброго метода pivot_table. Как и у большинства методов Python, его синтаксис прост и удобен для чтения.
Однак о чем сложнее логика слоя сводной таблицы, тем больше времени потребуется для ее написания. Более того, результирующая сводная таблица всегда является статической, а не интерактивной. При каждой смене расположения данных в сводной сетке, необходимо переписывать код. Возможно, вам не придется вносить много изменений, однако это время можно было бы потратить на то, чтобы лучше разобраться в данных.
Мы будем работать в JupyterLab — пользовательском интерфейсе для Jupyter Notebooks, в котором можно найти все элементы классического Jupyter, такие как ноутбуки и файловый браузер. Помимо этого, JupyterLab предлагает более расширенную функциональность: возможность устанавливать расширения, разворачивать, сворачивать и перетаскивать ячейки, а также предоставляет функцию автозаполнения вкладок.
Запускаем JupyterLab. Для начала импортируем необходимые библиотеки Python: pandas, JSON и модуль display из IPython. Во всех этих библиотеках встроен дистрибутив Anaconda, однако, если вы не работаете с ним, то установите эти библиотеки глобально или в виртуальной среде.
-
— неотъемлемый инструмент для работы со структурами данных в Python. — API для интерактивных и параллельных вычислений в Python. display — это его модуль, представляющий собой API для инструментов отображения в IPython.
- Библиотека json предоставляет API для кодирования и декодирования JSON. Если вы уже работали с модулями marshal или pickle , то знакомы с этим API.
















Для визуализации данных мы будем использовать библиотеку JavaScript Flexmonster Pivot Table & Charts.
Для демонстрации воспользуемся набором данных “Цены на авокадо” из Kaggle. Это легкий набор, содержащий разумное количество полей. Вы можете выбрать любой понравившийся вам набор данных.
▶ Загрузите данные. С помощью pandas прочитайте данные CSV на фрейме данных. Удалите “Unnamed: 0” — столбец индекса, который часто появляется при чтении файлов CSV.
▶ Вызовите метод to_json() на фрейме данных, чтобы преобразовать его в строку JSON и сохранить в переменную json_data .
Параметр orient определяет ожидаемый формат строки JSON. Устанавливаем его в значение records. Это значение переводит объект в структуру, подобную списку: [, … , ]. Именно с этим форматом работает Flexmonster.
▶ Теперь создадим экземпляр Flexmonster с помощью вложенного словаря. Здесь нужно указать все необходимые параметры инициализации и передать декодированные данные компоненту. Для декодирования JSON воспользуемся методом json.loads() .
Как видите, мы сразу устанавливаем срез, опции и форматы. Если пропустить этот шаг, то в сводной таблице отобразится срез по умолчанию.
▶ Теперь преобразуем объект Python в JSON с помощью json.dumps() :
▶ Следующий шаг — определение функции, которая отображает сводную таблицу непосредственно в ячейку. Для этого определяем многострочную строку и передаем ее в импортированную функцию HTML:
▶ И, наконец, передаем JSON в функцию рендеринга и вызываем ее:
На странице отображается интерактивная сводная таблица. Набор данных готов к работе: вы можете переупорядочить поля в сетке, изменять агрегаты, настраивать фильтрацию и сортировку, форматировать значения и многое другое для создания уникального отчета. Более того, если вы пропустите способ отображения записей в фрейме данных, то сможете переключиться из сводного режима в плоское представление. Таким образом, можно увидеть данные в исходном виде, но с интерактивной функциональностью.
Сводная таблица выглядит следующим образом:
Вы также можете применить условное форматирование, чтобы сосредоточиться на самых важных значениях.
Теперь немного усложним логику, добавив больше элементов в ноутбук. Две сводные диаграммы сделают визуализацию данных более универсальной. Для этого определяем дополнительную функцию, которая принимает несколько компонентов JSON и отображает их на странице. Ее логика выглядит так же, как и логика одной сводной таблицы. Компоненты сводных диаграмм определяются так же, как компоненты сводных таблиц.
В срезах отчетов для сводных диаграмм можно установить фильтры Top X для ограничения количества категорий, отображаемых в диаграммах, чтобы сделать их более аккуратными и компактными.
Интерактивная панель индикаторов в Jupyter Notebook готова к работе!
Мы рассмотрели новый способ манипулирования и представления данных в Jupyter Notebook с помощью Python и библиотеки визуализации данных JavaScript. Как вы могли заметить, настройка не требует много кода и времени.
Выполнив ее однажды, вы сможете исследовать данные в привычном рабочем пространстве.
Этот подход освобождает вас от переписывания фрагментов кода при каждой необходимости взглянуть на данные под новым углом, а также прекрасно сочетается с главной идеей Jupyter Notebooks — сделать визуализацию и анализ данных интерактивными и гибкими.
Полную версию кода можно найти на GitHub. 👈
Краткий список основных функций, с помощью которых можно улучшить отчеты:
В большинстве случаев реальные данные неаккуратны и непоследовательны: поля могут быть названы с использованием разных случаев, непонятных сокращений и т. д. Для уточнения можно воспользоваться отображением (mapping) — свойством отчета, которое устанавливает конфигурации представлений, применяемых к источнику данных. Еще одним преимуществом этой функциональности форматирования является явная настройка типов данных. С ее помощью можно указать компоненту способ обработки полей, что повлияет на выбор агрегатов, доступных для иерархий полей.
В примере GitHub показано, как определить объект mapping и установить его в сводную таблицу.
Сводная таблица содержит методы и события JavaScript API. Вы можете настроить сохранение отчетов в различных форматах локально или в удаленных точках, таких как серверы, с помощью метода exportTo .
Читайте также: