
Как создать файл robots txt для bitrix
Обновлено: 06.07.2024
Данный набор правил запрещает индексировать всякие служебные папки движка, админку, загрузки, модули, результаты поиска, сравнение, персональный раздел, авторизацию, статистику хоста, десктопное приложение, аяксы, тестовые разделы, ошибку 404, т.е. всякий ненужный в результатах поиска мусор.
Запрещает индексировать дубли страниц index.php , index1.php , index2.php и т.д.
Запрещает индексировать по умолчанию все параметры типа: ?PAGEN_1 , ?sort=asc&order=desc
Разрешаем индексировать в публичной, доступной всем части сайта: компоненты, шаблоны, изображения, кэш, css, js и т.д.
Тут обратите внимание, выше папки /bitrix/ + /local/ полностью запрещено индексировать, но правилами ниже по коду можно переопределять или дополнять разрешения, т.к. в них есть как служебные, так и публичные данные, необходимые и поисковиками и пользователям.
Здесь аналогично, выше папка /upload/ полностью запрещена для индексации, а ниже по коду открываем для робота отдельные, необходимые папки, это изображения главного модуля, модуля инфоблоки, медиабиблиотека и динамический ресайз превьюшек.
Данные параметры вопросов и отзывов относятся к моим решениям, они лишь для примера, в каком месте нужно добавлять параметры для индексации своего проекта, их лучше удалить.
Обратите внимание, выше мы закрывали все параметры директивой Disallow: /*?* в этом месте добавляйте только необходимые параметры, которые должны быть разрешены для индексации, все остальные параметры необходимо закрывать, это все мусор, который замедляет индексацию, лишние итерации поисковика и нагрузка на сайт, вплоть до падения сервера.
Это разрешает индексировать все публичные css и js, это важно при проверке проекта на Удобство просмотра на мобильных устройствах или в Google PageSpeed Insights может всплыть закрытый стиль, из-за которого у проекта могут быть проблемы.
Здесь указываем путь к карте сайта проекта, обратите внимание, нужно отступить одну строку.
Постраничная навигация/пагинация
Очень спорный момент, вы часто можете встретить правила типа:
Данные правила запрещают индексировать постраничку, это правильно, но если у сайта есть карта sitemap.xml , если карты сайта нет, то постраничка должна быть открыта для индексирования, иначе робот может не найти другие страницы, что в постраничке окажутся на 2-й и далее страницах, а при наличии карты сайта все будет проиндексировано.
Порядок в коде
Еще хочу сказать, как например мне удобно ориентироваться в карте и копировать ее из проекта в проект, ежегодно что-то добавлять в нужное место, не копаясь в сотнях строк непонятных правил.
1-й пример, все запрещающие правила для проекта я добавляю выше строки Disallow: /bitrix/
2-й пример: все разрешающие правила для параметров проекта я добавляю внизу перед Allow: /*.css
Два параметра для вопросов и отзывов у себя можете удалить, две строчки, я пока еще с ними экспериментирую, их и не так много, парочка параметров обычно максимум набирается.
Советы
Все закрытые, системные, административные скрипты и папки закрывайте формой входа на сайт, правила в файле robots.txt все равно не запрещают роботу ходить по сайту и сканировать все что доступно по ссылке, просканирует и загрузит в базу вообще все, хоть всю админку, а в результатах поиска будет показывать что в robots.txt разрешено показывать, но может и всплыть когда-нибудь дамп вашей базы или файл сброса пароля админа ✌😊
Закрывайте от индексации все порты на сервере, все ссылки, которыми мы в Яндекс.Почте обмениваемся, индексируются поисковиком, стоило один раз скинуть клиенту лично на почту ссылку с портом, как через неделю весь сайт на порту был проиндексирован, а исходный сайт был исключен из результатов поиска, как дубль.

Важно передать поисковикам актуальную информацию о страницах, которые закрыты от индексации, о главном зеркале и карте сайта (sitemap.xml). Для этого в корне сайта создается файл robots.tx и заполняется директивами.
Рассмотрим как в самом общем случае в битриксе создать файл robots.txt.

Первое, переходим на страницу Рабочий стол -> Маркетинг -> Поисковая оптимизация -> Настройка robots.txt
Второе, указываем основные правила.
На первой строчке видим User-agent: * , это означает, что директивы указаны для всех роботов всех поисковых систем.
Закрываем от индексации страницу авторизации, личного кабинета и другие директории и страницы, которые не должны попасть в результаты поиска.
Для того, чтобы закрыть директорию пишем правило:
Четвертое, в директиве Sitemap прописываем ссылку к файлк sitemap.xml.
В целом, это все что требуется, для того, чтобы передать файл в вебмастера Яндекса и Google.
- YandexBot — основной индексирующий
- YandexDirect — скачивает информацию о контенте сайтов-партнеров Рекламной сети, чтобы уточнить их тематику для подбора релевантной рекламы
- YandexMedia — робот, индексирующий мультимедийные данные
- YandexImages — индексатор Яндекс.Картинок
- YandexBlogs поиска по блогам — робот, индексирующий посты и комментарии
- YandexNews — робот Яндекс.Новостей
- YandexMetrika — робот Яндекс.Метрики
- YandexMarket — робот Яндекс.Маркета
Например, вам не нужно индексировать картинки, находящиеся в папке /include/, но вы хотите, чтобы статьи из этого раздела индексировались. Для этого, следует закрыть директивой Disallow папку /include/ для робота YandexImages.
Robots.txt для сайта – это индексный текстовый файл в кодировке UTF-8.
Индексным его назвали потому, что в нем прописываются рекомендации для поисковых роботов – какие страницы нужно просканировать, а какие не нужно.
Если кодировка файла отличается от UTF-8, то поисковые роботы могут неправильно воспринимать находящуюся в нем информацию.
Где находится robots.txt на сайте?
Директивы файла robots txt для сайта
Обязательными составляющими файла robots.txt для сайта являются правило Disallow и инструкция User-agent. Есть и второстепенные правила.
Правило Disallow
Disallow – это правило, с помощью которого поисковому роботу сообщается информация о том, какие страницы сканировать нет смысла. И сразу же несколько конкретных примеров применения этого правила:
Пример 1 - разрешено индексировать весь сайт:

Пример 2 - полностью запретить индексацию сайта:

Продвижение сайтов в таком случае будет бесполезно. Применение этого примера актуально в том случае, если сайт «закрыт» на доработку (например, неправильно функционирует). В этом случае сайту в поисковой выдаче не место, поэтому его нужно через файл robots txt закрыть от индексации. Разумеется, после того, как сайт будет доработан, запрет на индексирование надо снять, но об этом забывают.
Пример 3 – запрещено сканирование всех документов, находящихся в папке /papka/:

Пример 4 – запретить индексацию страницы с конкретным URL:

Пример 5 – запрещено индексировать конкретный файл (в данном случае – изображение):

Пример 6 – как в robots txt закрыть от индексации файлы конкретного расширения (в данном случае - .jpg):

Звездочка перед .jpg$ сообщает, что имя файла может быть любым, а знак $ сообщает о конце строки. Т.е. такая «маска» запрещает сканирование вообще всех GIF-файлов.
Правило Allow в robots txt
Правило Allow все делает с точностью до наоборот – разрешает индексирование файла/папки/страницы.
И сразу же конкретный пример:

Мы с вами уже знаем, что с помощью директивы Disallow: / мы можем закрыть сайт от индексации robots txt. В то же время у нас есть правило Allow: /catalog, которое разрешает сканирование папки /catalog. Поэтому комбинацию этих двух правил поисковые роботы будут воспринимать как «запрещено сканировать сайт, за исключением папки /catalog»
Сортировка правил и директив Allow и Disallow производится по возрастанию длины префикса URL и применяется последовательно. Если для одной и той же страницы подходит несколько правил, то робот выбирает последнее подходящее из списка.
Рассмотрим 2 ситуации с двумя правилами, которые противоречат друг другу - одно правило запрещает индексировать папки /content, а другое – разрешает.
В данном случае будет приоритетнее директива Allow, т.к. оно находится ниже по списку:

А вот здесь приоритетным является директива Disallow по тем же причинам (ниже по списку):

User-agent в robots txt
User-agent — правило, являющееся «обращением» к поисковому роботу, мол, «список рекомендаций специально для вас» (к слову, списков в robots.txt может быть несколько – для разных поисковых роботов от Google и Яндекс).
Например, в данном случае мы говорим «Эй, Googlebot, иди сюда, тут для тебя специально подготовленный список рекомендаций», а он такой «ОК, специально для меня – значит специально для меня» и другие списки сканировать не будет.
Правильный robots txt для Google (Googlebot)

Примерно та же история и с поисковым ботом Яндекса. Забегая вперед, список рекомендаций для Яндекса почти в 100% случаев немного отличается от списка для других поисковых роботов (чем – расскажем чуть позже). Но суть та же: «Эй, Яндекс, для тебя отдельный список» - «ОК, сейчас изучим его».

И последний вариант – рекомендации для всех поисковых роботов (кроме тех, у которых отдельные списки). Через «звездочку» было решено сделать по одной простой причине – чтоб не перечислять «поименно» все 300 с чем-то роботов.

Т.е. если в одном и том же robots.txt есть 3 списка с User-agent: *, User-agent: Googlebot и User-agent: Yandex, это значит, первый является «одним для всех», за исключением Googlebot и Яндекс, т.к. для них есть «личные» списки.
Sitemap
Т.е. каждый раз поисковый робот будет просматривать карту сайта на предмет появления новых адресов, а затем переходить по ним для дальнейшего сканирования, дабы освежить информацию о сайте в базах данных поисковой системы.
Правило Sitemap должно быть вписано в Robots.txt следующим образом:

Директива Host
Межсекционная директива Host в файле robots.txt так же является обязательной. Она необходима для поискового робота Яндекса - сообщает ему, какое из зеркал сайта нужно учитывать при индексировании. Именно поэтому для Яндекса формируется отдельный список правил, т.к. Google и остальные поисковые системы директиву Host не понимают. Поэтому если у вашего сайта есть копии или же сайт может открываться под разными URL адресами, то добавьте директиву host в файл robots txt, чтобы страницы сайта правильно индексировались.

«Зеркалом сайта» принято называть либо точную, либо почти точную «копию» сайта, которая доступна по другому адресу.
Адрес основного зеркала обязательно должно быть указано следующим образом:

Crawl delay
В отличие от предыдущих, параметр Crawl-delay уже не является обязательным. Основная его задача – подсказать поисковому роботу, в течение скольких секунд будут грузиться страницы. Обычно применяется в том случае, если Вы используете слабые сервера. Актуален только для Яндекса.

Clean param
С помощью директивы Clean-param можно бороться с get-параметрами, чтобы не происходило дублирование контента, т.к. один и тот же контент бывает доступен по разным динамическим ссылкам (это те, которые со знаками вопроса). Динамические ссылки могут генерироваться сайтом в том случае, когда используются различные сортировки, применяются идентификаторы сессий и т.д.
Например, один и тот же контент может быть доступен по трем адресам:
В таком случае директива Clean-param оформляется вот так:

Т.е. после двоеточия прописывается атрибут ref, указывающий на источник ссылки, и только потом указывается ее «хвост» (в данном случае - /catalog/get_phone.ua).
Самые частые вопросы
Как в robots.txt запретить индексацию?
Для этих целей придумано правило Disallow: т.е. копируем ссылку на документ/файл, который нужно закрыть от индексации, вставляем ее после двоеточия:
Ну а если требуется закрыть от индексирования все файлы с определенным расширением, то правила будут выглядеть следующим образом:
Как в robots.txt указать главное зеркало?
Однако, следует помнить, директива Host является рекомендацией, а не правилом. Т.е. не исключено, что в Host будет указан один домен, а Яндекс посчитает за основное зеркало другой, если у него в панели вебмастера введены соответствующие настройки.
Простейший пример правильного robots.txt
В таком виде файл robots.txt можно разместить практически на любом сайте (с мельчайшими корректировками).

Давайте теперь разберем, что тут есть.
- Здесь 2 списка правил – один «персонально» для Яндекса, другой – для всех остальных поисковых роботов.
- Правило Disallow: пустое, а значит никаких запретов на сканирование нет.
- В списке для Яндекса присутствует директива Host с указанием основного зеркала, а также, ссылка на карту сайта.
НО… Это НЕ значит, что нужно оформлять robots.txt именно так. Правила должны быть прописаны строго индивидуально для каждого сайта. Например, нет смысла индексировать «технические» страницы (страницы ввода логина-пароля, либо тестовые страницы, на которых отрабатывается новый дизайн сайта, и т.д.). Правила, кстати, зависят еще и от используемой CMS.
Закрытый от индексации сайт – как выглядит robots.txt?
Даем сразу же готовый код, который позволит запретить индексацию сайта независимо от CMS:


Наиболее частые ошибки в robots.txt
Специально для Вас мы приготовили подборку самых распространенных ошибок, допускаемых в robots.txt. Почти все эти ошибки объединяет одно – они допускаются по невнимательности.
1. Перепутанные инструкции:


2. В один Disallow вставляется куча папок:

В такой записи робот может запутаться. Какую папку нельзя индексировать? Первую? Последнюю? Или все? Или как? Или что? Одна папка = одно правило Disallow и никак иначе.

3. Название файла допускается только одно - robots.txt, причем все буквы маленькие. Имена Robots.txt, ROBOTS.TXT и т.п. не допускаются.
4. Правило User-agent запрещено оставлять пустым. Либо указываем имя поискового робота (например, для Яндекса), либо ставим звездочку (для всех остальных).
5. Мусор в файле (лишние слэши, звездочки и т.д.).
6. Добавление в файл полных адресов скрываемых страниц, причем иногда даже без правила Disallow.
Онлайн-проверка файла robots.txt
Существует несколько способов проверки файла robots.txt на соответствие общепринятому в интернете стандарту.
Способ 1. Зарегистрироваться в панелях веб-мастера Яндекс и Google. Единственный минус – придется покопаться, чтоб разобраться с функционалом. Далее вносятся рекомендованные изменения и готовый файл закачивается на хостинг.
Способ 2. Воспользоваться онлайн-сервисами:



Итак, robots.txt сформирован. Осталось только проверить его на ошибки. Лучше всего использовать для этого инструменты, предлагаемые самими поисковыми системами.
Google Вебмастерс (Search Console Google): заходим в аккаунт, если в нем сайт не подтвержден – подтверждаем, далее переходим на Сканирование -> Инструмент проверки файла robots.txt.

- моментально обнаружить все ошибки и потенциально возможные проблемы,
- сразу же «на месте» внести поправки и проверить на ошибки еще раз (чтоб не перезагружать файл на сайт по 20 раз)
- проверить правильность запретов и разрешений индексирования страниц.

Является аналогом предыдущего, за исключением:
- авторизация не обязательна;
- подтверждение прав на сайт не обязательно;
- доступна массовая проверка страниц на доступность;
- можно убедиться, что все правила правильно восприняты Яндексом.
Готовые решения для самых популярных CMS
Правильный robots.txt для Wordpress
Давайте разберем код файла robots txt для WordPress CMS:
Здесь мы указываем, что все правила актуальны для всех поисковых роботов (за исключением тех, для кого составлены «персональные» списки). Если список составляется для какого-то конкретного робота, то * меняется на имя робота:
Здесь мы осознанно даем добро на индексирование ссылок, в которых содержится /uploads. В данном случае это правило является обязательным, т.к. в движке WordPress есть директория /wp-content/uploads (в которой вполне могут содержаться картинки, либо другой «открытый» контент), индексирование которой запрещено правилом Disallow: /wp-. Поэтому с помощью Allow: */uploads мы делаем исключение из правила Disallow: /wp-.
В остальном просто идут запреты на индексирование:
Disallow: /cgi-bin – запрет на индексирование скриптов
Disallow: /feed – запрет на сканирование RSS-фида
Disallow: /trackback – запрет сканирования уведомлений
Disallow: ?s= или Disallow: *?s= - запрет на индексирование страниц внутреннего поиска сайта
Disallow: */page/ - запрет индексирования всех видов пагинации
Где находится robots txt WordPress вы все наверное знаете - так как и в другие CMS, данный файл должен находится в корневом каталоге сайта.
Содержание:
Самый простой Robots.txt
Самый простой robots.txt , который всем поисковым системам, разрешает всё индексировать, выглядит вот так:
Если у директивы Disallow не стоит наклонный слеш в конце, то разрешены все страницы для индексации.
Такая директива полностью запрещает сайт к индексации:
В справке Яндекса написано, что его поисковые роботы обрабатывают User-agent: * , но если присутствует User-agent: Yandex , User-agent: * игнорируется.
Директивы Disallow и Allow
Существуют две основные директивы:
Пример: На блоге мы запретили индексировать папку /wp-content/ где находятся файлы плагинов, шаблон и.т.п. Но так же там находятся изображения, которые должны быть проиндексированы ПС, для участия в поиске по картинкам. Для этого надо использовать такую схему:
Порядок использования директив имеет значение для Яндекса, если они распространяются на одни страницы или папки. Если вы укажите вот так:
User-agent : *Disallow : /wp-content/
Allow : /wp-content/uploads/
Изображения не будут загружаться роботом Яндекса с каталога /uploads/ , потому что исполняется первая директива, которая запрещает весь доступ к папке wp-content .
Google относится проще и выполняет все директивы файла robots.txt, вне зависимости от их расположения.
Так же, не стоит забывать, что директивы со слешем и без, выполняют разную роль:
Регулярные выражения в robots.txt
Поддерживается два символа, это:
Пример:
Disallow: /about* запретит доступ ко всем страницам, которые содержат about, в принципе и без звёздочки такая директива будет так же работать. Но в некоторых случаях это выражение не заменимо. Например, в одной категории имеются страницы с .html на конце и без, чтобы закрыть от индексации все страницы которые содержат html, прописываем вот такую директиву:
Ещё пример по аналогии:
Все страницы будут закрыты, кроме страниц которые заканчиваются на .html
Пример:
Директива Sitemap
В этой директиве указывается путь к Карте сайта, в таком виде:
Директива Host
Указывается в таком виде:
Пример robots.txt для Битрикс
Пример robots.txt для WordPress
После того, когда были добавлены все нужные директивы, которые описаны выше. Вы должны получить примерно вот такой файл robots:
Это так сказать базовый вариант robots.txt для wordpress. Здесь присутствует два User-agent-a – один для всех и второй для Яндекса, где указывается директива Host .
Мета-теги robots
Существует возможность закрыть от индексации страницу или сайт не только файлом robots.txt, это можно сделать при помощи мета-тега.
Прописывать его надо в теге и этот мета тег запретит индексировать сайт. В WordPress существуют плагины, которые позволяют выставлять такие мета теги, например – Platinum Seo Pack . С помощью него можно закрыть от индексации любую страницу, он использует мета-теги.
Директива Crawl-delay
С помощью этой директивы можно задать время, на которое должен прерываться поисковый бот, между скачиванием страниц сайта.
Таймаут между загрузкой двух страниц будет равен 5 секундам. Чтобы уменьшить нагрузку на сервер, обычно выставляют 15-20 секунд. Это директива нужны для больших, часто обновляемых сайтов, на которых поисковые боты просто «живут».
Для обычных сайтов/блогов эта директива не нужна, но можно таким образом ограничить поведение других не актуальных поисковых роботов (Rambler, Yahoo, Bing) и.т.п. Ведь они тоже заходят на сайт и индексируют его, создавая тем самым нагрузку на сервер.
Проверить robots.txt
Чтобы проверить robots.txt для Google, надо зайти в панель вебмастер:
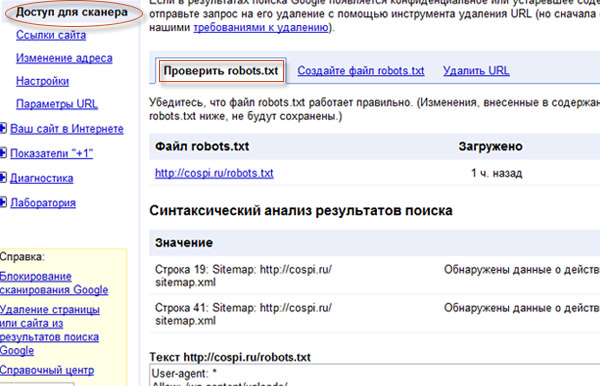
Тут вы сможете проверять все директивы на работоспособность и экспериментировать с ними.
Проверить robots.txt для Яндекса можно тоже в его Панели Вебмастер, перейдя вот по этой
ссылки.
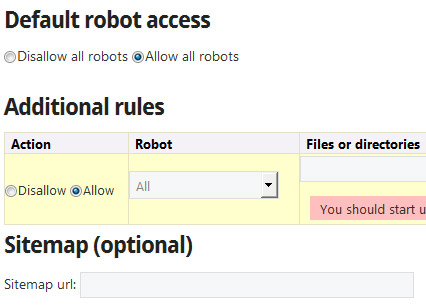
Так же существуют сервисы генераторы robots.txt, которые помогут вас сделать базовые настройки, вот некоторые из них:
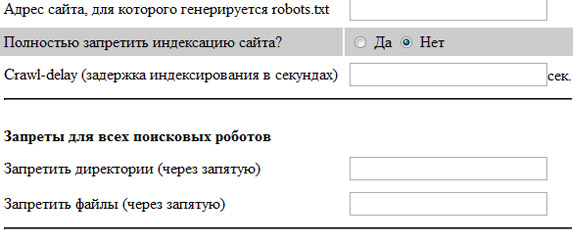
На этом всё, спасибо за внимание и не забываем подписываться на обновление блога
Читайте также: