
Как создать requirements txt файл python
Обновлено: 05.07.2024
Итак requirements.txt! Это питоновский аналог package.json. если кто знаком с node js.
Эта штука нужна при деплое (заливании проекта на сервер), а также при командной разработке, чтобы одной командой установить все используемые в проекте библиотеки правильных версий.
1) создание виртуального окружения: virtualenv venv
2) активация виртуального окружения:
linux $source venv/bin/activate
3) эти команды нужно выполнить, если не работает pip freeze в пункте 4.
linux: sudo apt-get install python-matplotlib
windows: python -m pip install -U pip setuptools
python -m pip install matplotlib
4) Чтобы сформировать вышеоговренный файл вводим
pip freeze > requirements.txt
5) чтобы установить библиотеки из сформированного файла в пункте 4:
pip install -r requirements.txt для python 2.x
pip3 install -r requirements.txt для python 3.x
Ничего сложного, но надо знать.
Кстати в течение недели, как выложил видео в youtube, был на собеседовании, в котором один из вопросов был, "Что такое виртуальное окружение", а об этом я рассказывал в предыдущем видео и сразу представил это:

Следущий вопрос был как раз про requirements.txt. И тут мне было еще тяжелее сдержать улыбку =) Так что будет полезно.
Видео само собой прикладываю.

Карантин -- самое время подтянуть навыки программирования. Практика программирования с использованием Python, Хирьянов Т.Ф, лекция 9
Вот уже на протяжении нескольких лет Тимофей, преподаватель кафедры информатики МФТИ, выкладывает свои лекции по программированию на своём Youtube канале с открытым доступом.


Разработка системы заметок с нуля. Часть 2: REST API для RESTful API Service + JWT + Swagger
Продолжаем серию материалов про создание системы заметок. В этой части мы спроектируем и разработаем RESTful API Service на Go cо Swagger и авторизацией. Будет много кода, ещё больше рефакторинга и даже немного интеграционных тестов.
В первой части мы спроектировали систему и посмотрели, какие сервисы требуются для построения микросервисной архитектуры.
Подробности в видео и текстовой расшифровке под ним.
Прототипирование
Начнём с макетов интерфейса. Нам нужно понять, какие ручки будут у нашего API и какой состав данных он должен отдавать. Макеты мы будем делать, чтобы понять, какие сущности, поля и эндпоинты нам нужны. Используем для этого онлайн-сервис NinjaMock. Он подходит, если макет надо сделать быстро и без лишних действий.
После входа в приложение пользователь увидит список заметок, который будет выглядеть примерно так:
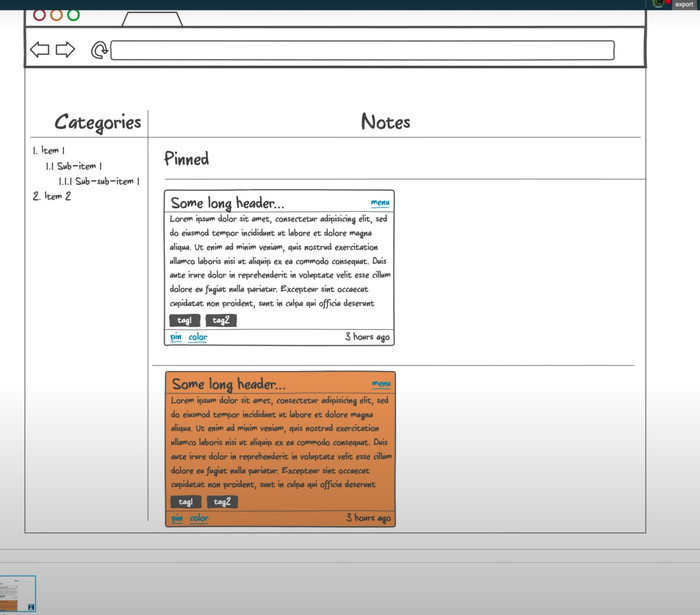
Интерфейс, который будет у нашего веб-приложения:
- Слева — список категорий любой вложенности.
- Справа — список заметок в виде карточек, который делится на два списка: прикреплённые и обычные карточки.
- Каждая карточка состоит из заголовка, который урезается, если он очень длинный.
- Справа указано, сколько секунд/минут/часов/дней назад была создана заметка.
- Тело заголовка — отрендеренный Markdown.
- Панель инструментов. Через неё можно изменить цвет, прикрепить или удалить заметку.
Тут важно отметить, что файлы заметки мы не отображаем и не будем запрашивать у API для списка заметок.
Полная карточка открывается по клику на заметку. Тут можно сразу отобразить полностью длинный заголовок. Высота заметки зависит от количества текста. Для файлов появляется отдельная секция. Мы их будем получать отдельным асинхронным запросом, который не помешает пользователю редактировать заметку. Файлы можно скачать по ссылке, также есть отдельная кнопка на добавление файлов.
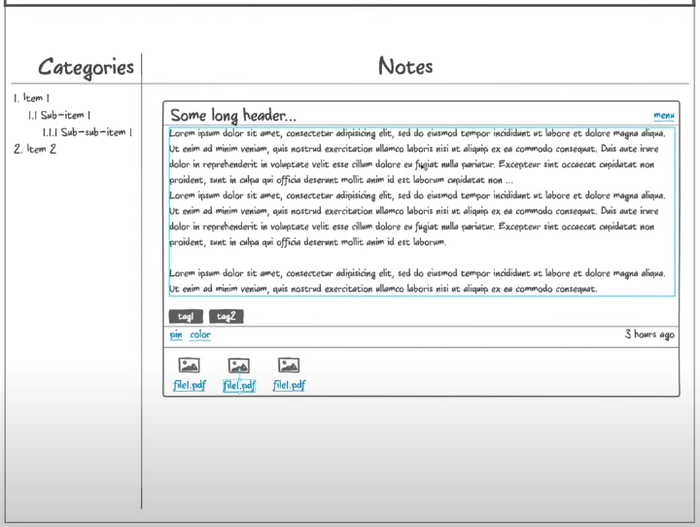
Так будет выглядеть открытая заметка
В ходе прототипирования стало понятно, что в первой части мы забыли добавить еще один микросервис — TagsService. Он будет управлять тегами.
Определение эндпоинтов
Для страниц авторизации и регистрации нам нужны эндпоинты аутентификации и регистрации соответственно. В качестве аутентификации и сессий пользователя мы будем использовать JWT. Что это такое и как работает, разберём чуть позднее. Пока просто запомните эти 3 буквы.
Для страницы списка заметок нам нужны эндпоинты /api/categories для получения древовидного списка категорий и /api/notes?category_id=? для получения списка заметок текущей категории. Перемещаясь по другим категориям, мы будем отдельно запрашивать заметки для выбранной категории, а на фронтенде сделаем кэш на клиенте. В ходе работы с заметками нам нужно уметь создавать новую категорию. Это будет метод POST на URL /api/categories. Также мы будем создавать новый тег при помощи метода POST на URL /api/tags.

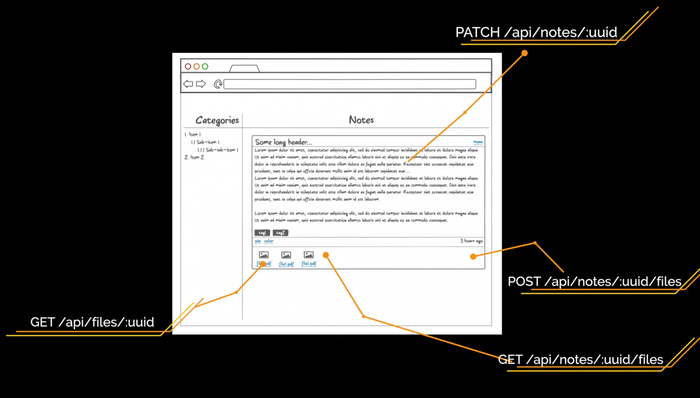
Структура репозитория системы
Ещё немного общей информации. Структура репозитория всей системы будет выглядеть следующим образом:
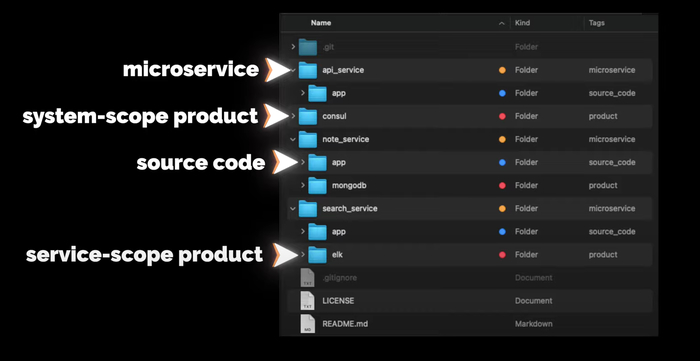
В директории app будет исходный код сервиса (если он будет). На уровне с app будут другие директории других продуктов, которые используются с этим сервисом, например, MongoDB или ELK. Продукты, которые будут использоваться на уровне всей системы, например, Consul, будут в отдельных директориях на уровне с сервисами.
Разработка сервиса
Писать будем на Go
- Идём на официальный сайт.
- Копируем ссылку до архива, скачиваем, проверяем хеш-сумму.
- Распаковываем и добавляем в переменную PATH путь до бинарников Go
- Пишем небольшой тест проверки работоспособности, собираем бинарник и запускаем.
Установка завершена, всё работает
Теперь создаём проект. Структура стандартная:
- build — для сборок,
- cmd — точка входа в приложение,
- internal — внутренняя бизнес-логика приложения,
- pkg — для кода, который можно переиспользовать из проекта в проект.
Я очень люблю логировать ход работы приложения, поэтому перенесу свою обёртку над логером logrus из другого проекта. Основная функция здесь Init, которая создает логер, папку logs и в ней файл all.log со всеми логами. Кроме файла логи будут выводиться в STDOUT. Также в пакете реализована поддержка логирования в разные файлы с разным уровнем логирования, но в текущем проекте мы это использовать не будем.
APIService будет работать на сокете. Создаём роутер, затем файл с сокетом и начинаем его слушать. Также мы хотим перехватывать от системы сигналы завершения работы. Например, если кто-то пошлёт приложению сигнал SIGHUP, приложение должно корректно завершиться, закрыв все текущие соединения и сессии. Хотел перехватывать все сигналы, но линтер предупреждает, что os.Kill и SIGSTOP перехватить не получится, поэтому их удаляем из этого списка.
Теперь давайте добавим сразу стандартный handler для метрик. Я его копирую в директорию pkg, далее добавляю в роутер. Все последующие роутеры будем добавлять так же.
Далее создаём точку входа в приложение. В директории cmd создаём директорию main, а в ней — файл app.go. В нём мы создаём функцию main, в которой инициализируем и создаём логер. Роутер создаём через ключевое слово defer, чтобы метод Init у роутера вызвался только тогда, когда завершится функция main. Таким образом можно выполнять очистку ресурсов, закрытие контекстов и отложенный запуск методов. Запускаем, проверяем логи и сокет, всё работает.
Но для разработки нам нужно запускать приложение на порту, а не на сокете. Поэтому давайте добавим запуск приложения на порту в наш роутер. Определять, как запускать приложение, мы будем с помощью конфига.
Создадим для приложения контекст. Сделаем его синглтоном при помощи механизма sync.Once. Пока что в нём будет только конфиг. Контекст в виде синглтона создаю исключительно в учебных целях, впоследствии он будет выпилен. В большинстве случаев синглтоны — необходимое зло, в нашем проекте они не нужны. Далее создаём конфиг. Это будет YAML-файл, который мы будем парсить в структуру.
В роутере мы вытаскиваем из контекста конфиг и на основании listen.type либо создаем сокет, либо вешаем приложение на порт. Код graceful shutdown выделяем в отдельный пакет и передаём на вход список сигналов и список интерфейсов io.Close, которые надо закрывать. Запускаем приложение и проверяем наш эндпоинт heartbeat. Всё работает. Давайте и конфиг сделаем синглтоном через механизм sync.Once, чтобы потом безболезненно удалить контекст, который создавался в учебных целях.
Теперь переходим к API. Создаём эндпоинты, полученные при анализе прототипов интерфейса. Тут важно отметить, что у нас все данные привязаны к пользователю. На первый взгляд, все ручки должны начинаться с пользователя и его идентификатора /api/users/:uuid. Но у нас будет авторизация, иначе любой пользователь сможет программно запросить заметки любого другого пользователя. Авторизацию можно сделать следующим образом: Basic Auth, Digest Auth, JSON Web Token, сессии и OAuth2. У всех способов есть свои плюсы и минусы. Для этого проекта мы возьмём JSON Web Token.
Работа с JSON Web Token
JSON Web Token (JWT) — это JSON-объект, который определён в открытом стандарте RFC 7519. Он считается одним из безопасных способов передачи информации между двумя участниками. Для его создания необходимо определить заголовок (header) с общей информацией по токену, полезные данные (payload), такие как id пользователя, его роль и т.д., а также подписи (signature).
JWT использует преимущества подхода цифровой подписи JWS (Signature) и кодирования JWE (Encrypting). Подпись не даёт кому-то подделать токен без информации о секретном ключе, а кодирование защищает от прочтения данных третьими лицами. Давайте разберёмся, как они могут нам помочь для аутентификации и авторизации пользователя.
Аутентификация — процедура проверки подлинности. Мы проверяем, есть ли пользователь с полученной связкой логин-пароль в нашей системе.
Авторизация — предоставление пользователю прав на выполнение определённых действий, а также процесс проверки (подтверждения) данных прав при попытке выполнения этих действий.
Другими словами, аутентификация проверяет легальность пользователя. Пользователь становится авторизированным, если может выполнять разрешённые действия.
Важно понимать, что использование JWT не скрывает и не маскирует данные автоматически. Причина использования JWT — проверка, что отправленные данные были действительно отправлены авторизованным источником. Данные внутри JWT закодированы и подписаны, но не зашифрованы. Цель кодирования данных — преобразование структуры. Подписанные данные позволяют получателю данных проверить аутентификацию источника данных.
Реализация JWT в нашем APIService:
- Создаём директории middleware и jwt, а также файл jwt.go.
- Описываем кастомные UserClaims и сам middlware.
- Получаем заголовок Authorization, оттуда берём токен.
- Берём секрет из конфига.
- Создаём верификатор HMAC.
- Парсим и проверяем токен.
- Анмаршалим полученные данные в модель UserClaims.
- Проверяем, что токен валидный на текущий момент.
При любой ошибке отдаём ответ с кодом 401 Unauthorized. Если ошибок не было, в контекст сохраняем ID пользователя в параметр user_id, чтобы во всех хендлерах его можно было получить. Теперь надо этот токен сгенерировать. Это будет делать хендлер авторизации с методом POST и эндпоинтом /api/auth. Он получает входные данные в виде полей username и password, которые мы описываем отдельной структурой user. Здесь также будет взаимодействие с UserService, нам надо там искать пользователя по полученным данным. Если такой пользователь есть, то создаём для него UserClaims, в которых указываем все нужные для нас данные. Определяем время жизни токена при помощи переменной ExpiresAt — берём текущее время и добавляем 15 секунд. Билдим токен и отдаём в виде JSON в параметре token. Клиента к UserService у нас пока нет, поэтому делаем заглушку.
Добавим в хендлер с heartbeat еще один тестовый хендлер, чтобы проверить работу аутентификации. Пишем небольшой тест. Для этого используем инструмент sketch, встроенный в IDE. Делаем POST-запрос на /api/auth, получаем токен и подставляем его в следующий запрос. Получаем ответ от эндпоинта /api/heartbeat, по истечении 5 секунд мы начнём получать ошибку с кодом 401 Unauthorized.
Наш токен действителен очень ограниченное время. Сейчас это 15 секунд, а будет минут 30. Но этого всё равно мало. Когда токен протухнет, пользователю необходимо будет заново авторизовываться в системе. Это сделано для того, чтобы защитить пользовательские данные. Если злоумышленник украдет токен авторизации, который будет действовать очень большой промежуток времени или вообще бессрочно, то это будет провал.
Чтобы этого избежать, прикрутим refresh-токен. Он позволит пересоздать основной токен доступа без запроса данных авторизации пользователя. Такие токены живут очень долго или вообще бессрочно. После того как только старый JWT истекает мы больше не можем обратиться к API. Тогда отправляем refresh-токен. Нам приходит новая пара токена доступа и refresh-токена.
Хранить refresh-токены на сервере мы будем в кэше. В качестве реализации возьмём FreeCache. Я использую свою обёртку над кэшем из другого проекта, которая позволяет заменить реализацию FreeCache на любую другую, так как отдает интерфейс Repository с методами, которые никак не связаны с библиотекой.
Пока рассуждал про кэш, решил зарефакторить существующий код, чтобы было удобней прокидывать объекты без dependency injection и синглтонов. Обернул хендлеры и роутер в структуры. В хендлерах сделал интерфейс с методом Register, которые регистрируют его в роутере. Все объекты теперь инициализируются в main, весь роутер переехал в мейн. Старт приложения выделили в отдельную функцию также в main-файле. Теперь, если хендлеру нужен какой-то объект, я его просто буду добавлять в конструктор структуры хендлера, а инициализировать в main. Плюс появилась возможность прокидывать всем хендлерам свой логер. Это будет удобно когда надо будет добавлять поле trace_id от Zipkin в строчку лога.
Вернемся к refresh_token. Теперь при создании токена доступа создадим refresh_token и отдадим его вместе с основным. Сделаем обработку метода PUT для эндпоинта /api/auth, а в теле запроса будем ожидать параметр refresh_token, чтобы сгенерировать новую пару токена доступа и refresh-токена. Refresh-токен мы кладём в кэш в качестве ключа. Значением будет user_id, чтобы по нему можно было запросить данные пользователя у UserService и сгенерировать новый токен доступа. Refresh-токен одноразовый, поэтому сразу после получения токена из кэша удаляем его.
Описание API
Для описания нашего API будем использовать спецификацию OpenAPI 3.0 и Swagger — YAML-файл, который описывает все схемы данных и все эндпоинты. По нему очень легко ориентироваться, у него приятный интерфейс. Но описывать вручную всё очень муторно, поэтому лучше генерировать его кодом.
- Создаём эндпоинты /api/auth с методами POST и PUT для получения токена по юзернейму и паролю и по Refresh-токену соответственно.
- Добавляем схемы объектов Token и User.
- Создаём эндпоинты /api/users с методом POST для регистрации нового пользователя. Для него создаём схему CreateUser.
У нас есть подсказка в виде Swagger-файла. На его основе создаём все нужные хендлеры. Там, где вызов микросервисов, будем проставлять комментарий с TODO.
Создаём хендлер для категорий, определяем URL в константах. Далее создаём структуры. Опираемся на Swagger-файл, который создали ранее. Далее создаём сам хендлер и реализуем метод Register, который регистрирует его в роутере. Затем создаём методы с логикой работы и сразу пишем тест API на этот метод. Проверяем, находим ошибки в сваггере. Таким образом мы создаём все методы по работе с категориями: получение и создание.
Далее создаём таким же образом хендлер для заметок. Понимаем, что забыли методы частичного обновления и удаления как для заметок, так и для категорий. Дописываем их в Swagger и реализуем методы в коде. Также обязательно тестируем Swagger в онлайн-редакторе.
Здесь надо обратить внимание на то, что методы создания сущности возвращают код ответа 201 и заголовок Location, в котором находится URL для получения сущности. Оттуда можно вытащить идентификатор созданной сущности.
В третьей части мы познакомимся с графовой базой данных Neo4j, а также будем работать над микросервисами CategoryService и APIService.
Обычно для запуска проекта требуется несколько внешних пакетов.
Чтобы каждый раз с болью в сердце не собирать их, список этих пакетов принято поставлять вместе с исходным кодом. Принято селить весь список необходимых пакетов в файле requirements.txt в корне проекта. Формат этого файла простой: по одному пакету на строку.
Заморозка пакетов
У одного пакета обычно много версий. Когда мы просим пип установить пакет, он устанавливает самую свежую из доступных.
Это может привести к проблемам: скажем, проект разрабатывался на версии 1.2. Через полгода потребовалось развернуть его заново, пип установил последнюю версию – 1.5. Эта версия может быть не совместима со старой, тогда код сломается.
Например, такая история была с модулем vk : в версии 1.5 нужно было использовать класс vk.api.APISession , а в версии 2.0 – vk.OAuthAPI . Понятное дело, программа, которая использует не ту версию модуля, ломалась – старого класса-то нет.
Чтобы такого не происходило, пакеты принято замораживать – указывать версию пакета вместе с названием. Пип поддерживает такой синтаксис: модуль==версия .
Вот часть requirements.txt из Девмана:
Получить все версии пакетов, установленных на вашем компьютере, можно командой pip freeze :
Все зависимости заморозить и в requirements.txt
Установка
Все пакеты из requirements.txt можно установить одним махом, пип такое умеет: pip install -r requirements.txt .
Зависимости зависимостей
К сожалению, правильное заполнение requirements.txt не решает все проблемы с зависимостями и версиями.
Дело в том, что у перечисленных в файле зависимостей есть свои зависимости. Например, модуль vk для своей установки требует модуль requests . Пип установит его сам, незаметно для нас.
Проблема в том, что если модуль requests не заморожен в исходниках модуля vk , через полгода всё опять может сломаться: версия vk будет правильная, а requests – нет.
Эта проблема свойственна большим проектам, у которых десятки зависимостей и сотни неявных зависимостей.
Решение этой проблемы рассмотрим в другой раз. Главное – быть начеку.
Попробуйте бесплатные уроки по Python
Получите крутое код-ревью от практикующих программистов с разбором ошибок и рекомендациями, на что обратить внимание — бесплатно.

Поэтому лучшим подходом будет создавать для каждого отдельного проекта свою среду. В этой статье будет рассмотрена библиотека venv для настройки Virtual Environment для Windows.
venv (для Python 3) позволяет управлять отдельными установками пакетов для разных проектов. По сути, venv позволяет вам создавать «виртуальную» изолированную установку Python и устанавливать пакеты в эту виртуальную установку. При переключении проектов вы можете просто создать новую виртуальную среду и не беспокоиться о нарушении работы пакетов, установленных в других средах. При разработке приложений Python всегда рекомендуется использовать виртуальную среду.
Чтобы создать виртуальную среду, перейдите в каталог вашего проекта и запустите venv.
venv создаст виртуальную установку Python в директории env .

Примечание:Вы должны исключить каталог виртуальной среды из своей системы управления версиями с помощью .gitignore .
Активация и деактивация виртуальной среды Python
Далее необходимо активировать виртуальную среду. Для этого необходимо запустить файл .\env\Scripts\activate.bat или .\env\Scripts\Activate.ps1 .
Пока ваша виртуальная среда активирована, pip будет устанавливать пакеты в эту конкретную среду, и вы сможете импортировать и использовать пакеты в своем приложении Python.
Если вы хотите переключить проекты или иным образом покинуть виртуальную среду, просто запустите .\env\Scripts\deactivate.bat .
Установка пакетов в виртуальную среду
Пример:
pip позволяет вам указать, какую версию пакета установить, используя спецификаторы версии . Например, чтобы установить определенную версию requests :
Как сохранить пакеты в файл requirements.txt
Pip может экспортировать список всех установленных пакетов и их версий с помощью freeze команды: pip freeze > requirements.txt .
Будет выведен список спецификаторов пакетов, таких как:
Имейте в виду, что в этом случае в файле requirements.txt будут перечислены все пакеты, которые были установлены в виртуальной среде, независимо от того, откуда они пришли.
Установить пакеты из файла requirements.txt
Как запустить скрипт Python в виртуальной среде. Пример автоматизации с помощью cmd
Для того, чтобы запустить скрипт, достаточно внутри директории с проектом (со средой) запустить команду:
В мои обязанности входит наём Python-разработчиков. Если у заинтересовавшего меня специалиста есть GitHub-аккаунт — я туда загляну. Все так делают. Может быть, вы этого и не знаете, но ваш домашний проект, не набравший ни одной GitHub-звезды, может помочь вам в получении работы.
То же самое относится и к тестовым задачам, выдаваемым кандидатам на должность программиста. Как известно, мы, когда впервые видим человека, формируем первое впечатление о нём за 30 секунд. Это влияет на то, как мы будем, в дальнейшем, оценивать этого человека. Мне кажется несправедливым то, что люди, обладающие привлекательной внешностью, добиваются всего легче, чем все остальные. То же самое применимо и к коду. Некто смотрит на чей-то проект и что-то тут же бросается ему в глаза. Ошмётки старого кода в репозитории — это как крошки хлеба, застрявшие в бороде после завтрака. Они могут напрочь испортить первое впечатление. Может, бороды у вас и нет, но, думаю, вам и так всё ясно.

Обычно легко понять то, что некий код написан новичком. В этом материале я дам вам несколько советов о том, как обыграть кадровиков вроде меня и повысить свои шансы на получение приглашения на собеседование. При этом вас не должна мучить мысль о том, что, применяя эти советы, вы кого-то обманываете. Вы не делаете ничего дурного. Применяя те небольшие улучшения кода, о которых пойдёт речь, вы не только повышаете свои шансы на успешное прохождение собеседования, но и растёте как программист. Не могу сказать, что профессиональному росту способствует упор на заучивание алгоритмов или модулей стандартной библиотеки.
В чём разница между новичком и более опытным разработчиком? Новичок не работал с устаревшими кодовыми базами. Поэтому он не видит ценности в том, чтобы вкладывать время в написание кода, который легко поддерживать. Часто новички работают в одиночку. Они, в результате, не особенно заботятся о читабельности кода.
Ваша цель заключается в том, чтобы показать то, что вас заботит читабельность вашего кода и возможность его поддержки в будущем.
Поговорим о том, как повысить качество ваших Python-проектов. Советы, которыми я хочу поделиться, улучшат ваш код. А если вы не сделаете из них карго-культ, то они ещё и помогут вашему профессиональному росту.
1. Уберите из репозитория ненужные файлы
Откройте страницу своего репозитория на GitHub. Есть ли в нём файлы с расширениями .idea , .vscode , .DS_Store или .pyc ? Попали ли туда файлы из виртуального окружения? Если так — избавьтесь от всего этого и добавьте записи о соответствующих файлах и папках в .gitignore . Выкладывая код на GitHub следует придерживаться правила, в соответствии с которым в репозиторий не должно попадать ничего такого, что создано не владельцем репозитория. Вот хорошее руководство по .gitignore , в котором даётся обзор того, что обычно не стоит включать в репозитории.
▍Примеры
Начальный вариант файла .gitignore для Python-проектов
Следующий текст можно рассматривать в качестве начального варианта содержимого .gitignore . Добавьте такой файл в свой проект в самом начале работы над ним.
Если вам нужен более масштабный пример .gitignore — взгляните на этот файл из коллекции GitHub. Используйте его как источник вдохновения и как базу для вашего .gitignore .
2. Не храните в коде секретные данные
В репозитории не должно быть никаких паролей к базам данных, ключей к внешним API, секретных ключей систем шифрования! Подобные вещи надо хранить в конфигурационных файлах или в переменных окружения. Ещё один вариант — их чтение из защищённого хранилища. А включать их в код — это в высшей степени неправильно. Вот — отличное руководство на тему хранения конфигурационных данных, подготовленное в рамках проекта The Twelve-Factor App (другие материалы этого проекта тоже весьма полезны).
▍Примеры
Неправильно: реквизиты базы данных хранятся в коде
Ниже приведён фрагмент Flask-приложения. Автор хранит реквизиты для доступа к базе данных в коде.
Правильно: реквизиты хранятся в переменных окружения
Перенести реквизиты для доступа к базе данных в переменные окружения совсем несложно:
Теперь нужно, перед запуском приложения, инициализировать переменные окружения:
Правильно: реквизиты хранятся в файле .env
Для того чтобы перед запуском программы не приходилось бы вручную инициализировать переменные окружения, можно пойти дальше. А именно, речь идёт о том, чтобы сохранить эти данные в файле .env . Далее, нужно установить пакет python-dotenv и инициализировать переменные окружения прямо из Python-кода.
Вот как может выглядеть файл .env :
Вот как работать с этим файлом из кода:
И надо не забыть добавить запись об .env в .gitignore . Благодаря этому данный файл не будет случайно выгружен в репозиторий.
3. Добавьте в репозиторий файл README
В проекте, на его верхнем уровне, должен присутствовать файл README , в котором описана цель создания проекта, в котором даются инструкции по установке проекта и по началу работы с ним. Если вы не знаете о том, что писать в таком файле, обратитесь к руководству, размещённому на сайте Make a README.
▍Примеры
Файл README для Python-проекта
Тут приведён пример файла README , созданный в соответствии с рекомендациями вышеупомянутого сайта. Так, здесь есть сведения о проекте, руководство по его установке и использованию. Здесь же присутствует раздел, предназначенный для тех, кто хочет внести вклад в работу над проектом. В файле есть и сведения о лицензии, что очень важно для опенсорсных проектов.
4. Если вы используете сторонние библиотеки — добавьте в репозиторий файл requirements.txt
Если в проекте используются сторонние зависимости, об этом нужно сообщить. Легче всего это сделать, создав файл requirements.txt в корневой директории проекта. В каждой строке этого файла приводятся сведения об одной зависимости. Нужно, кроме того, добавить инструкции по работе с этим файлом в README . Подробности о requirements.txt можно найти в руководстве пользователя по pip .
▍Примеры
Файл requirements.txt для Flask-приложения
Добавление файла requirements.txt в корневую директорию проекта — это самый лёгкий способ отслеживания зависимостей. Можно, помимо сведений о самих зависимостях, дать сведения и об их версиях. Вот пример файла requirements.txt :
Указание более подробных сведений о зависимостях с использованием файла requirements.in
При работе над любым проектом всегда полезно иметь возможность воспроизведения его окружения. В результате, даже если вышла новая версия какой-нибудь библиотеки, можно использовать старую, проверенную в деле версию, работая с ней до тех пор, пока не будет решено перейти на новую. Это называется «фиксацией зависимостей». Легче всего это можно сделать, прибегнув к pip-tools. При таком подходе в вашем распоряжении окажется два файла: requirements.in и requirements.txt . Второй из них при этом вручную не модифицируют, просто добавляя его в репозиторий вместе с requirements.in . Вот как выглядит файл requirements.in :
Для того чтобы на основе этого файла был бы автоматически создан requirements.txt , файл requirements.in компилируют, используя команду pip-compile . Вот как выглядит автоматически сгенерированный файл requirements.txt :
Как видите, готовый файл содержит сведения о точных версиях всех зависимостей.
5. Форматируйте код с помощью black
Неоднородное форматирование кода не помешает ему нормально работать. Но если код хорошо отформатирован — это улучшит его читабельность и упростит его поддержку. Форматирование кода может и должно быть автоматизировано. Если вы пользуетесь VS Code, то можете увидеть рекомендацию по установке black в качестве автоматического средства форматирования исходного кода, написанного на Python. Форматирование кода производится при сохранении файлов. Кроме того, black можно установить самостоятельно и форматировать код, пользуясь средствами командной строки.
▍Примеры
Неправильно: неформатированный код
Код, приведённый ниже, тяжело читать и расширять.
Правильно: тот же самый код, отформатированный с помощью black
Применение black гарантирует то, что переформатированный код будет работать так же, как его исходный вариант. Данный инструмент всего лишь снимает с программиста нагрузку по ручному форматированию кода.
6. Избавьтесь от ненужных команд импорта
Ненужные команды импорта обычно остаются в коде после каких-нибудь экспериментов и после рефакторинга. Если в программе не используется некий модуль, который раньше в ней применялся, не забудьте убрать из кода соответствующую команду импорта. Обычно редакторы подсвечивают неиспользуемые команды импорта, что облегчает их поиск и борьбу с ними.
▍Примеры
Неправильно: наличие в коде ненужных команд импорта
В этом фрагменте кода импортированный модуль os не используется:
Правильно: в коде нет ненужных команд импорта
Вышеприведённый код очень просто привести в приличный вид:
7. Избавьтесь от ненужных переменных
То, о чём говорилось в предыдущем пункте, относится и к неиспользуемым переменным. Они могут попасть в код в те моменты, когда программист создаёт их, думая, что они могут пригодиться в дальнейшем, а потом оказывается, что они не нужны.
▍Примеры
Неправильно: наличие в коде ненужной переменной:
Здесь переменная response не используется:
Правильно: в коде нет ненужных переменных
Тут нет ничего лишнего:
8. Следуйте соглашению по именованию сущностей из PEP 8
Именование сущностей — это как форматирование. Неудачный выбор имён не помешает правильной работе программы, но затруднит работу с кодом. Кроме того, единообразный подход к именованию сущностей снимает с программиста нагрузку, связанную с постоянным выдумыванием имён. Почитать PEP 8 можно здесь.
▍Примеры
Правила именования сущностей из PEP 8
- Имена файлов и директорий записываются в нижнем регистре с использованием символа подчёркивания для разделения слов: lowercase_underscores .
- Так же составляют имена функций и переменных: lowercase_underscores .
- Имена классов записывают с использованием «верблюжьего» стиля: CamelCase .
- Имена констант записываются в верхнем регистре с использованием символа подчёркивания: UPPERCASE_UNDERSCORE .
Пример применения PEP 8
Ниже приведён фрагмент кода, имеющего достаточно сложную структуру, но соответствующего правилам PEP 8. Тут я, чтобы продемонстрировать именование разных сущностей, поместил простую функцию в класс.
9. Проверяйте код с использованием линтера
Линтер анализирует код и ищет в нём ошибки, которые можно обнаружить автоматически. Перед отправкой изменений в репозиторий код всегда полезно проверять с помощью линтера.
Если говорить о линтерах, представленных инструментами командной строки, то в этой сфере я порекомендовал бы flake8. Этот линтер обладает разумными настройками, применяемыми по умолчанию. Обычно ошибки, о которых он сообщает, стоит исправлять. Если вы хотите строже относиться к своему коду — взгляните на pylint. Этот линтер способен выявлять множество ошибок, в число которых входят и те, о которых мы тут не говорим.
▍Примеры
Файл, который нужно почистить
В нижеприведённом коде (файл ping.py ) можно увидеть некоторые проблемы и без применения линтера.
Давайте проанализируем его с помощью flake8 и pylint .
Результаты анализа кода с помощью flake8
Результаты анализа кода с помощью pylint
10. Удалите из кода команды print, используемые при отладке
Отладка кода с использованием команд print , расположенных в его важнейших местах, — это нормально. Но не стоит, решив проблему, коммитить в репозиторий код, содержащий подобные команды.
▍Примеры
Неправильно: отладочные команды print в коде
Автор кода захотел узнать о том, к каким изменениям в файловой системе приведёт работа функции, сохраняющей объект в файл. Команды print , выполняемые до и после вызова тела функции, не решают никаких задач, имеющих отношение к самой функции. После того, как они помогли программисту разобраться в происходящем, их нужно удалить. Иначе они будут просто засорять код.
Правильно: код без ненужных команд print
Если убрать из кода отладочные команды — это уменьшит размер функции и повысит удобство работы с ней. А это всегда хорошо.
11. Не держите в репозитории закомментированный код
Очищайте репозиторий от закомментированных старых версий кода и от закомментированного кода, который был написан для проведения каких-нибудь экспериментов. Если вы когда-нибудь решите вернуться к старой версии программы — это всегда можно сделать с помощью инструментов применяемой вами системы контроля версий. Остатки старого кода сбивают с толку тех, кто читает тексты программ. Такой код создаёт впечатление небрежного отношения к нему его автора.
▍Примеры
Неправильно: ненужные комментарии в коде
Автор экспериментировал, прямо в коде программы, с преобразованием строк. Решено было не включать результаты этих экспериментов в итоговый вариант программы, но, на всякий случай, соответствующий код не удалили полностью, а лишь закомментировали.
Правильно: код, в котором нет ненужных комментариев
Обратите внимание на то, насколько легче читать предыдущий код, из которого убраны ненужные комментарии.
12. Оформляйте скрипты в виде функций
В самом начале работы над программой её код обычно следует за потоком мыслей программиста. Этот код состоит из последовательности инструкций, решающих некую задачу. Выработайте у себя привычку оформлять последовательности инструкций в виде функций. Поступать так стоит с самого начала работы над проектом. Подобные функции нужно вызывать в самом конце программ, защитившись выражением if __name__ == «__main__» . Это поможет вам использовать структурный подход при развитии проекта, извлекая из нужных мест вспомогательные функции. А позже, если надо, это облегчит оформление скриптов в виде модулей.
▍Примеры
Неправильно: скрипт, не оформленный в виде функции
Выполнение кода в этом примере начинается в первой строке и заканчивается в последней. Такой подход оправдан в том случае, если речь идёт о простых скриптах. Но если код скрипта окажется сложнее, воспринять его будет уже не так легко.
Правильно: скрипт, оформленный в виде функции
Поток выполнения программы начинается в последней строке кода — там, где вызывается функция say_hello() . Если речь идёт о том, что в состав функции входит всего пара строк кода, то такой подход может показаться неоправданно усложнённым. Но это, в любом случае, облегчает изменение кода. Например, можно легко, воспользовавшись click, оснастить свою функцию возможностями по приёму параметров из командной строки.
Домашнее задание
Говорят, что мы запоминаем лишь 10% того, что прочли. Это значит, что вы запомните лишь один из 12 данных мной советов. Полагаю, это означает, что вы впустую потратили время, читая эту статью. А я, в таком случае, зря её писал.
Но, к счастью, есть одна хитрость. Известно, что практика позволяет сохранить около 80% знаний. Следовательно — вот вам задание: возьмите один из своих проектов и проанализируйте его с точки зрения моих 12 советов. У того, кто так и сделает, в 8 раз больше шансов профессионально вырасти, чем у того, кто просто прочтёт статью.
Есть ли в ваших Python-проектах недочёты, о которых говорит автор этой статьи?
Читайте также: