
Как создать tmx файл
Обновлено: 05.07.2024
В данном видео объясняется, как при помощи OmegaT создать память переводов, которая содержит сегменты из отдельных исходных файлов или сегменты, сохраненные в определенный промежуток времени.
Экспорт TMX-памяти для отдельных файлов
Эта функция полезна, когда вам нужно выполнить контроль качества перевода в отдельной QA-программе (например, Verifika) для одного или нескольких файлов, а не всей памяти проекта (находится в файле project_save.tmx или же в трех TMX-файлах в корне проекта, созданных по нажатии Ctrl+D).
Большой плюс этого скрипта заключается в том, что в отличие от файла project_save.tmx, где все сегменты идут в алфавитном порядке, в TMX-файлах, созданных скриптом, сегменты идут в их естественном порядке (так же как они представлены в исходном файле и OmegaT). Это упрощает контроль качества, поскольку вы можете видеть контекст. И если вы сравниваете TMX-файлы до и после редактирования, то сравнение получается более наглядным по той же причине.
Экспорт TMX-файлов для конкретных промежутков времени
Под временным промежутком я понимаю период времени с момента начала изменения сегментов в проекте до настоящего момента. Возможны по крайней мере две ситуации, когда нужен такой экспорт:
- Вы работаете над проектом с большим количеством 100%-ных совпадений, которые не требуется проверять. Если после перевода нового текста нужно выполнить контроль качества этих новых переводов в отдельной QA-программе, вам потребуется TMX-память, включающая только эти сегменты.
- Вы завершили проект, но потом потребовалось внести в него дополнительные правки. Вы потратили на них три часа и теперь хотите выполнить контроль качества в отношении только тех сегментов, которые отредактировали за эти три часа, чтобы убедиться в том, что не допустили новых ошибок. Для этого потребуется TMX-файл, содержащий только те сегменты, которые вы изменили за этот период.
Вы можете создать TMX-файлы для этих целей следующим образом:
Здесь нельзя не поблагодарить в очередной раз Коса Иванцова за разработку этих незаменимых скриптов.
Если этот блог вам как-то помог, поделитесь ссылкой на этот пост на своем сайте или на странице в социальной сети.
Выберите File - Export в TRADOS Workbench (не изменяйте настройки, если Вы желаете включить все единицы перевода) и нажмите кнопку OK . В следующем окне выберите TMX (*. tmx ) в качестве файла экспорта, дайте файлу название и определите для него позицию по своему усмотрению.

Wordfast => TMX
Откройте в Wordfast память переводов, которую Вы желаете экспортировать в формат TMX .

Убедитесь, что Вы выбрали TMX в Export TM и нажмите кнопку Export TM .
ВАЖНЫЙ ШАГ, СВЯЗАННЫЙ С ОПЦИЯМИ СОХРАНЕНИЯ В MS WORD
Если не сделать этого, в большинстве случаев все единицы перевода с ä или ö не будут отображаться корректно и не смогут использоваться в других приложениях.
DejaVu X => TMX
Откройте DejaVu X и память переводов, которую Вы желаете экспортировать в формат TMX .


Выберите TMX в окне Specify Data Format .

Выберите папку/диск и название для памяти переводов TMX .

В окне Specify Languages выберите все языки, которые Вы желаете включить в экспортируемый TMX формат памяти переводов.

В окне Filtering conditions Вы можете выбрать критерии для единиц перевода, включённых в память, но Вы не должны устанавливать никаких условий при экспорте всех единиц перевода.

В окне TMX Options определите набор символов (предлагаемая по умолчанию UTF -8 подойдёт) и хотите ли Вы включить в память дополнительную информацию. Если Вы желаете экспортировать только переводы, снимите все галочки ниже Extra Information .

Мастер сообщит Вам результаты экспорта в последнем окне.
Transit XV => TMX
В Transit XV откройте проект, в котором Вы использовали память, которую желаете конвертировать в формат TMX .



Дайте памяти название и определите её расположение по своему усмотрению.

В Project target languages определите языки, которые Вы желаете включить в память TMX .
Запустите преобразование, выбрав Start export .
SDLX 2003 => TMX

Выберите TM - Export a Translation Memory или нажмите клавиши Ctrl + E.


Найдите и откройте память переводов, которую Вы желаете экспортировать в формат TMX , нажмите кнопку Open .

Выбранная память перевода появляется в поле. Убедитесь, что выбор корректен и продолжите, нажав кнопку Next .


Выберите TMX format file для опции Export to и нажмите кнопку Next . Выберите All Languages или выберите языки из раскрывающихся списков Source- и Target , нажмите кнопку Next .

Выберите No filter to be applied (если Вы не желаете исключать единицы перевода из памяти).


Выберите папку / диск, где Вы желаете создать память TMX , определите для памяти название и нажмите кнопку Save .

Запустите преобразование в формат TMX нажав кнопку Finish .
TMX => TRADOS
Выберите File - Import . Выберите Large import file и как Вы хотите передать существующие единицы перевода (по умолчанию - Merge ).

Выберите файл TMX и нажмите кнопку Open . Если Вы не можете найти файл, проверьте, чтобы в Files of type было выбрано TMX (*. tmx )

TMX => Wordfast
Откройте файл TMX как память Wordfast выбрав Select TM . При запросе сохраните его в формате Unicode или Text Only .

TMX => Deja Vu X
Запустите DejaVu X и откройте память переводов, куда Вы желаете импортировать единицы перевода, или создайте новую память.


Выберите TMX в окне Specify Data Format и нажмите кнопку Next .



Проверьте в окне Specify Language Conversion корректность маркировки всех языков. Продолжите, нажав кнопку Next .

Импортируйте единицы перевода, нажав кнопку Finish . Мастер отображает число импортированных единиц перевода.
TMX => Transit XV
В Transit XV импортируйте памяти TMX , определённые как Reference Material .


Полученный сегментированный файл может быть оставлен пустым.
Запустите преобразование, выбрав Start import .

Окно Import progress отобразит текст Completed successfully.
Перейдите на Project settings - Reference material.


TMX => SDLX

Выберите Import a Translation Memory или нажмите Ctrl + I.

Нажмите Open an Existing Translation Memory , если у Вас имеется память, в которую Вы желаете импортировать единицы перевода из памяти в формате TMX , или используйте Create New Translation Memory , чтобы создать новую память.

Если Вы создаёте новую память переводов, определите для неё название и разместите её на диске по своему усмотрению.

После выбора памяти для импорта единиц перевода, продолжите, нажав кнопку Next .

Выберите TMX format file для опции Export from и нажмите кнопку Next .



Выберите требуемые файлы TMX и нажмите кнопку Open .

После выбора всех файлов памяти для импорта нажмите кнопку OK .


Выберите, желаете ли Вы Overwrite the existing translation segments найденные в памяти или Add a new segment to the Translation Memory в случае если обнаружена существующая единица перевода.
Начните импорт единиц перевода, нажав кнопку Finish .

Память будет открыта в SDL Maintain и Вы сможете проверить, все ли единицы перевода импортированы корректно.
В проектах ОмегаТ файлы памяти перевода, т. е. файлы с расширением «tmx», могут храниться в пяти разных местах.
Папка «omegat» содержит файл project_save.tmx и, возможно, некоторое количество его резервных копий. Файл project_save.tmx содержит все сегменты, которые были сохранены в памяти программы с момента начала проекта. Этот файл всегда присутствует во всех проектах. Его содержимое всегда отсортировано по исходным сегментам в алфавитном порядке.
main project folder
Главный каталог проекта содержит три TMX-файла: имя_проекта-omegat.tmx , имя_проекта-level1.tmx и имя_проекта-level2.tmx .
Файл «level1» содержит только текстовую информацию.
Файл «level2» инкапсулирует специфические теги ОмегаТ в стандартные теги TMX, чтобы этот файл можно было использовать (со всей информацией о форматировании) в любом переводческом ПО, которое поддерживает TMX 2 уровня, или в самой ОмегаТ .
Файл omegat включает специфические теги форматирования ОмегаТ , так что его можно использовать в других проектах ОмегаТ .
Эти файлы представляют собой копии project_save.tmx , т. е. главной памяти переводов проекта, за исключением ничейных сегментов. Им специально присвоены разные имена, чтобы всегда можно было понять, что находится в данном, конкретном файле. Это может быть полезно, например, когда TMX-файл находится в подкаталоге «tm» другого проекта.
Каталог «/tm/» может содержать любое количество справочных TMX-файлов. Эти файлы могут быть в любом из трёх описанных выше вариантах. Заметьте, что другие системы автоматизированного перевода могут также производить экспорт (и импорт) TMX-файлов во всех вариантах. Лучше всего, конечно, использовать TMX-файлы со специфичными для ОмегаТ тегами (см. выше), чтобы сохранить информацию о внутреннем форматировании сегментов.
Содержимое файлов памяти переводов из каталога «tm» используется при поиске нечётких совпадений в переводимом тексте. Любые хранящиеся в этих файлах сегменты, достаточно схожие с сегментами переводимого текста, будут показываться в области просмотра нечётких совпадений.
Если какой-либо из хранящихся в справочных TMX-файлах сегментов полностью совпадёт с текущим переводимым сегментом, поведение ОмегаТ будет зависеть от настроек, заданных в диалоговом окне «Параметры → Параметры редактирования. » . Например (если заданы настройки по умолчанию), перевод из справочной памяти переводов может быть принят, и вставлен как перевод сегмента с префиксом [нечёткое совпадение] , так что в дальнейшем переводчик сможет легко найти подобные сегменты и проверить их (см. раздел Параметры редактирования) .
Иногда файлы памяти переводов из папки tm содержат сегменты с одинаковым исходным текстом, но разными переводами. ОмегаТ считывает TMX-файлы в алфавитном порядке, строка за строкой. Соответственно, последний из сегментов с одинаковым исходным текстом будет иметь преимущество (примечание: хотя, конечно же, подобного рода ситуации следует избегать).
Заметьте, что TMX-файлы в каталоге «tm» могут быть сжаты утилитой gzip.
Если заранее известно, что хранящиеся в TMX-файле переводы корректны (полностью подходят для текущего проекта), можно поместить TMX-файл в подкаталог tm/auto , что позволит избежать необходимости удалять подстроку [нечёткое совпадение] из множества автоматически вставленных переводов. Это позволит легко создать предварительный перевод исходного текста: все исходные сегменты, для которых в файлах из папки «auto» найдутся точные совпадения, будут переведены без какого-либо участия со стороны пользователя.
Иногда требуется отделить высококачественные файлы памяти переводов от менее надёжных (например, относящихся к другой тематике или ещё не отредактированных). Для памяти переводов, хранящейся в подкаталогах «penalty-xxx» (где «xxx» это число от 0 до 100), будет автоматически занижаться процент совпадений, в соответствии с названием каталога, например, точные совпадения из памяти переводов, хранящейся в каталоге «penalty-30», будут помечаться как семидесятипроцентные. Это относится и к остальным совпадениям: сегменты с 75, 80 и 90 процентами совпадений будут отмечаться как имеющие 45, 50 и 60 %.
Также можно указать ОмегаТ создать дополнительный TMX-файл (в формате *-omegat-* ) со всеми сегментами проекта. См. ниже подраздел о памяти псевдо-переводов.
Помните, что файлы памяти переводов загружаются в память при открытии проекта. Резервное копирование памяти переводов проекта происходит регулярно (см. следующий раздел), также файл project_save.tmx сохраняется/обновляется при каждой загрузке и закрытии проекта. Это означает, например, что если вы добавите в проект новый справочный TMX-файл, то будет достаточно перезагрузить проект, все ваши переводы будут сохранены.
Расположение различных файлов памяти перевода для текущего проекта задаётся пользователем (см. окно Проект > Свойства…).
В зависимости от потребностей, можно применять различные стратегии перевода, например:
несколько проектов со схожей тематикой: используйте единый каталог для всех проектов, заменяйте только каталоги исходных и переведённых файлов (исходные файлы в «source/order1», переведённые файлы в «target/order1» и т. д.). Заметьте, что переводы сегментов из файлов в каталоге «order1», которые отсутствуют в «order2» или других работах, будут помечаться как «ничейные», что, однако, никак не помешает использовать их как источник нечётких совпадений.
несколько переводчиков, работающих над одним проектом: разделите каталог исходных файлов на «source/Mihail», «source/Viacheslav»… и назначьте их членам команды (Михаилу, Вячеславу и т. д.). Они могут создать собственные проекты и предоставить project_save.tmx по окончанию проекта, или после перевода определённого количества текстов. Затем, файлы project_save.tmx собираются вместе и анализируются, например, чтобы исключить несоответствия в терминологии. Создаётся новая версия главного TMX-файла, который либо помещается в каталог tm/auto каждого члена команды, либо служит заменой их файлов project_save.tmx . Команда может использовать общий каталог переведённых файлов. Это позволяет, например, в любой момент убедиться, что перевод всего проекта корректен.
Резервное копирование TMX-файлов
По мере перевода ваших фалов, ОмегаТ сохраняет память переводов в файле project_save.tmx , находящемся в подкаталоге omegat .
Кроме того, ОмегаТ сохраняет резервные копии памяти переводов в файлах project_save.tmx.ГГГММДДЧЧНН.bak в той же папке при каждом открытии или перезагрузке проекта. ГГГГ — это год (4 цифры), ММ — это месяц, ДД — это число, а ЧЧ и НН — это часы и минуты, прошедшие с момента сохранения предыдущей резервной копии.
Если вам кажется, что вы потеряли свой перевод, сделайте следующее:
Переименуйте файл project_save.tmx (например, в project_save.tmx.temporary )
Выберите резервную копию, которая скорее всего содержит нужные вам данные, например, самую последнюю, или последнюю копию за вчерашний день.
Переименуйте его в project_save.tmx
TMX-файлы и язык
Файлы TMX содержат единицы перевода, которые состоят из определённого количества эквивалентных сегментов на разных языках. Единица перевода состоит из, как минимум, двух вариантов единицы перевода (translation unit variant, TUV). Любой из них можно использовать и как оригинал, и как перевод.
Языки перевода и оригинала определяются из настроек проекта. Таким образом, ОмегаТ находит варианты единиц перевода соответствующие языковым кодам проекта и рассматривает их как сегменты оригинала и перевода. ОмегаТ распознаёт языковые коды в двух форматах:
двух-буквенные коды (например, JA для японского), или
двух- или трёх-буквенные коды, за которыми идёт двух-буквенный код страны (например, EN-US, см Приложение A, Языки - список кодов ISO 639 неполный список кодов языков).
Если языковые коды проекта и файла TMX полностью совпадают, сегменты загружаются в память. Если совпадает только язык, но не страна, сегменты всё равно загружаются в память. Если не совпадает ни один код, сегменты не загружаются.
В общем случае TMX-файлы могут содержать единицы перевода на разных языках. Если в памяти переводов для текущего сегмента нет совпадений на языке перевода, будут показаны все остальные совпадения, вне зависимости от языка. Например, если в проекте производится перевод с немецкого на французский, перевод текущего сегмента с немецкого на английский может всё равно оказаться полезным.
Ничейные сегменты
Файл project_save.tmx содержит все сегменты, которые были переведены с момента начала проекта. После изменения правил сегментации или удаления файлов из каталога «source» некоторые совпадения могут отображаться в области просмотра как «ничейные» : такие совпадения соответствуют сегментам, которых больше нет в исходных документах, эти сегменты были переведены и сохранены в памяти до своего удаления.
Повторное использование памяти переводов
Изначально, сразу после создания проекта, главный файл памяти переводов, project_save.tmx , пуст. По мере перевода этот TMX-файл будет наполняться. Для ускорения этого процесса можно использовать уже имеющиеся переводы. Если текущий сегмент уже был переведён ранее и переведён хорошо, переводить его заново нет никакой необходимости. Также, сегменты из памяти перевода могут использоваться как образцы специфического стиля, типичный пример — международные документы, публикуемые Европейским Союзом.
При создании переведённых документов память переводов проекта также сохраняется в виде трёх файлов в главной папке проекта (см. выше). Эти три TMX-файла ( «-omegat.tmx» , «-level1.tmx» и «-level2.tmx» ) можно рассматривать как «память переводов на экспорт», то есть, как экспортированную двуязычную сводку вашего проекта.
Если вы пожелаете повторно использовать память переводов из предыдущего проекта (например, потому что новый проект похож на предыдущий или использует терминологию, которая была задействована раньше), то вы можете подключить эту память переводов как «внешнюю» по отношению к вашему новому проекту. В этом случае поместите файлы памяти переводов, которые вы хотите использовать, в каталоги /tm или /tm /auto вашего нового проекта. Файлы из каталога «tm» будут использоваться для поиска нечётких совпадений, а файлы каталога «/tm/auto» — для создания предварительного перевода вашего проекта.
По умолчанию, каталог «/tm» находится в главном каталоге проекта (например, /MyProject/tm ), но, при желании, в диалоговом окне свойств проекта вы можете задать и другое расположение. Это полезно, если вы часто используете файлы памяти переводов, созданные раннее, например, потому что они относятся к одной теме или к одному клиенту. В таком случае, может быть полезно прибегнуть к такой процедуре:
Создайте каталог (репозиторий, хранилище) в удобном месте на вашем жёстком диске. Он будет использоваться для конкретного клиента или конкретной тематики.
После окончания работы над проектом, скопируйте один из трёх «экспортных» файлов памяти переводов из главного каталога проекта в каталог-репозиторий.
Когда вы начинаете работу над новым проектом для того же клиента или по той же тематике, выберите пункт меню «Проект > Свойства. » и в появившемся диалоговом окне в качестве папки памяти переводов укажите каталог-репозиторий.
Имейте в виду, что все TMX-файлы в репозитории «/tm» обрабатываются во время запуска программы, поэтому если вы поместите туда все имеющиеся у вас TMX-файлы, то можете несколько замедлить работу ОмегаТ. Возможно, часть этих файлов можно будет удалить, после того, как их содержимое перейдёт в project-save.tmx вашего текущего проекта.
Импорт и экспорт памяти переводов
ОмегаТ поддерживает импорт файлов TMX версий 1.1—1.4b (уровней 1 и 2). Это позволяет ОмегаТ использовать память переводов, созданную другими программами. Однако, импорт TMX-файлов 2 уровня (которые содержат не только перевод, но и форматирование) поддерживается не полностью. ОмегаТ может импортировать TMX-файлы второго уровня и использовать содержащуюся в них текстовую информацию, но качество нечётких совпадений будет несколько ниже.
ОмегаТ использует очень жёсткие правила обработки файлов памяти переводов (файлов TMX). Если в таком файле обнаружится ошибка, ОмегаТ укажет её расположение в некорректном файле.
ОмегаТ экспортирует TMX-файлы версии 1.4 (1 и 2 уровня). На самом деле, экспорт 2 уровня не совсем соответствует стандарту, но достаточен для того, чтобы эти файлы давали корректные совпадения в программах, поддерживающих TMX 2 уровня. Если вам нужна только текстовая информация (без форматирования), используйте созданный ОмегаТ файл 1 уровня.
Создание отдельной памяти переводов для некоторых документов
Если вы хотите поделиться памятью переводов, за исключением сегментов из некоторых документов, или содержащей сегменты только определённых документов, передача всего файла ИмяПроекта-omegat.tmx вам не подойдёт. Ниже описан один из способов решить эту проблему, не единственный, но достаточно простой и надёжный.
Создайте новый проект с нужной парой языков и подходящим именем, помните, что это имя унаследуют и создаваемые TMX-файлы.
Скопируйте документы, для которых хотите создать файл памяти переводов, в каталог «source» нового проекта.
Скопируйте память переводов этих документов из предыдущих проектов в каталог tm/auto .
Откройте созданный проект. Нажмите CTRL+T , чтобы проверить теги и CTRL+U , чтобы убедиться, что все сегменты имеют перевод. Если никаких проблем не обнаружено, нажмите CTRL+D , чтобы создать переведённые документы, и проверьте их содержимое.
Закройте проект. Теперь TMX-файлы в главном каталоге проекта содержат память перевода нужных вам файлов и только их. Сделайте резервную копию этих файлов.
Чтобы избежать путаницы, удалите новый проект или переместите его в архив.
Использование общей памяти переводов
Если над проектом работает команда переводчиков, вместо обмена локальными копиями памяти переводов удобнее использовать один общий файл памяти.
ОмегаТ умеет работать с SVN и Git, двумя наиболее популярными свободными системами управления версиями. Система управления версиями может синхронизировать общий каталог проекта между всей командой переводчиков, включая подкаталог «source» и файл с настройками проекта. Более подробная информация представлена в соответствующем разделе.
Использование TMX-файлов с другими языковыми парами
Предположим, вы перевели проект, например, с нидерландского на русский. Затем вам потребовалось перевести это проект на китайский, но переводчица, знающая китайский, совсем не понимает нидерландский, однако хорошо говорит по-русски. В этом случае память переводов NL-RU может быть использована как для создания перевода NL-ZH.
Для этого нужно скопировать созданную память NL-RU в подкаталог «tm» и переименовать файл в «ZN-CN.tmx», чтобы подчеркнуть язык перевода проекта. Переводчик будет видеть английские переводы сегментов на нидерландском языке и сможет использовать их для создания перевода на китайский.
Важно: вспомогательный TMX-файл должен быть переименован в «XX_YY.tmx», где «XX_YY» — это код целевого языка проекта, например, «ZH_CN.tmx» в примере выше. Конечно же, исходные языки проекта и TMX-файла должны быть одинаковыми (в нашем примере это NL). Заметьте, что для одной языковой пары можно подключить только один TMX-файл, так что если вам нужно использовать несколько файлов памяти переводов, их следует объединить в один файл «XX_YY.tmx».
Исходные документы с уже имеющимися переводами
Файлы некоторых форматов, например, PO и TTX, являются двуязычными, т. е. одновременно содержат и исходные сегменты, и память переводов. В этих случаях существующий перевод, хранящийся в исходном файле, автоматически копируется в project_save.tmx . Если не найдено других точных совпадений, он становится переводом по умолчанию, в противном случае он рассматривается как один из возможных вариантов перевода. Таким образом, полученный результат зависит от порядка загрузки исходных сегментов.
Все переводы из исходных документов показываются не только в области нечётких совпадений, но и в области комментариев. В случае с PO-файлами процент совпадения альтернативных вариантов перевода занижается на 20 %, т. е. для точных совпадений он будет составлять лишь 80 %. Рядом с исходным сегментом будет отображаться строка «[Нечёткое совпадение]».
При загрузке TTX-файлов сегменты, перевод которых совпадает с оригиналом, будут включены в проект, если в окне «Параметры → Параметры редактирования…» установлен соответствующий флажок. Так как это может вас запутать, возможно, флажок стоит снять.
Память псевдо-перевода
Примечание
Этот раздел предназначен для опытных пользователей!
Иногда перед собственно переводом, может понадобиться предварительная обработка сегментов, вне ОмегаТ. Например, вы можете захотеть создать псевдо-перевод, чтобы как-нибудь с ним поэкспериментировать. ОмегаТ позволяет создать дополнительный TMX-файл, который содержит все сегменты проекта. Переводы в этом файле либо:
будут копировать оригинал (поведение по умолчанию)
Вы можете указать для этого файла любое имя. Память псевдо-перевода создаётся следующей командой (в командной строке):
java -jar omegat.jar --pseudotranslatetmx=<имяфайла> [pseudotranslatetype=[equal|empty]]
Замените <имяфайла> на конкретное имя файла, который вы хотите создать. Имя может быть абсолютным или относительным к текущему каталогу (каталогу, из которого запускается ОмегаТ ). Второй аргумент ( --pseudotranslatetype ) не обязателен. Он может принимать значения equal (поведение по умолчанию, перевод копирует оригинал) или empty (сегмент перевода будет пустым). В дальнейшем вы можете обрабатывать созданный TMX-файл при помощи любой доступной вам программы. Чтобы повторно использовать его в ОмегаТ , переименуйте файл в project_save.tmx и поместите в папку omegat вашего проекта.
Обновление файлов памяти переводов
Ранние версии ОмегаТ умели производить сегментацию исходных файлов только по абзацам и непоследовательно нумеровали теги форматирования в файлах HTML и Open Document. ОмегаТ может определять и исправлять такие TMX-файлы «на лету», что позволяет улучшить качество нечётких совпадений и более эффективно использовать существующие переводы, тем самым освобождая переводчика от лишней работы.
ET TMX Editor — Программное решение для просмотра и редактирования переводческой базы данных TranslationMemory.
Доступ к решению осуществляется здесь.
Текущая версия работает по следующим параметрам:
- • Языковые пары: любые
- • Доступный формат обрабатываемых файлов: .tmx
- • Возможный размер обрабатываемого файла: до 20 Мб *
* Необходимо обработать файлы большего размера? Вы можете воспользоваться решением ET TMX Processor.
Посмотреть видео-инструкцию вы можете по ссылке
Приступаем к работе!
Шаг 1: До начала работы следует ознакомиться с предварительной информацией нажав кнопку "Как начать работать"
(Рис. №1.)
Чтобы скрыть информацию снова нажмите на кнопку "Как начать работать".


Шаг 2: Заполнение проекта (поля под " * " обязательны для заполнения):
А) Введите название проекта,
Б) загрузите файл .tmx с локального диска
(Рис. №2.)
Шаг 3: Дополнительные параметры:
Если вы хотите, чтобы файл в проекте отображался без сегментов, которые не содержат текст (только цифры, знаки препинания и т.п.), поставьте галочку " Не обрабатывать сегменты, не содержащие буквенные символы ".
(Рис. №3.)

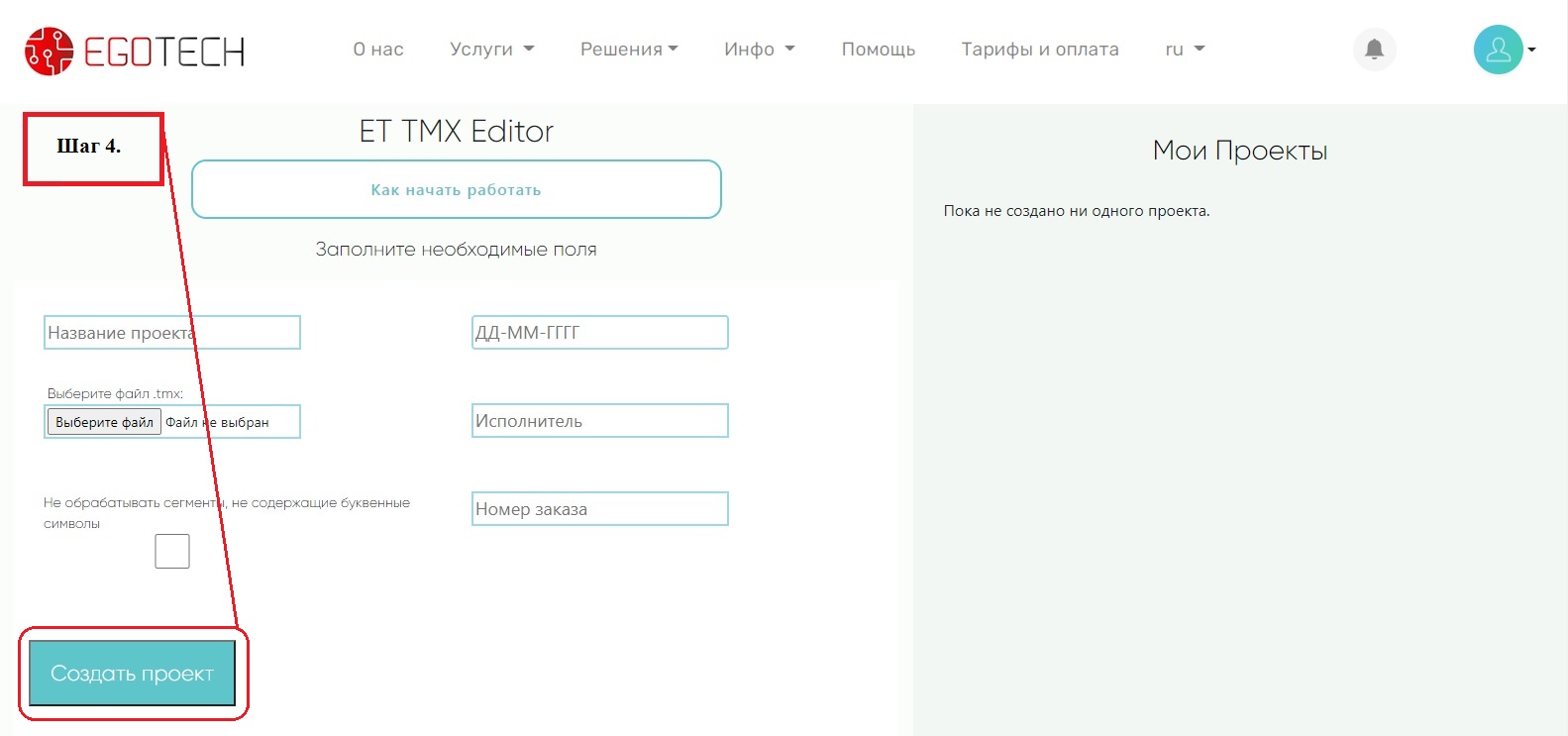
Шаг 4: Создание проекта:
Шаг 5:
Убедитесь, что проект отобразился в поле "Мои проекты" справа. (Рис. №5.)
Созданный проект также отобразится в Вашем Личном кабинете во вкладке "Мои проекты".


Шаг 6: Запуск проекта:
Кликните "Открыть" у выбранного проекта и нажмите кнопку "Запустить" (Рис. №6) .
Среднее время обработки файла - 5-15 c.
Шаг 7: Работа с результатом обработки ET TMX Editor.
Результаты обработки отображаются в визуальном редакторе под строкой меню.

Редактирование данных:
Если вы хотите удалить сегмент, поставьте галочку слева от него и нажмите кнопку "Удалить выдленные".
Поиск:
Для поиска по тексту файла введите слово для поиска в окно и нажмите кнопку "Найти"
Шаг 8: Сохранение и выгрузка данных.
Кнопка "Сохранить" позволяет перезаписать загруженный файл с внесенными изменениями .
Записанный файл сохраняется в проекте документа, Вы можете вернуться к нему, когда необходимо.
Кнопка "Сохранить и выгрузить" позволяет выгрузить данные в формате .tmx.
(Рис. №9.) .
Кнопка "Проекты" позволят перейти к списку созданных проектов. Кнопка "На главную" позволяет вернуться на главную страницу сайта.

Работа с проектом.
А) Открыть или Удалить проект вы можете со страницы компонента ET TMX Editor в поле " Мои проекты " . (Рис. №10.) .
Также попасть на страницу компонента ET TMX Editor вы можете из вкладки " Мои проекты " в вашем профиле, для этого нажмите кнопку " Карандаш " . Вы можете удалить проект, нажав кнопку " Корзина " . (Рис. №11.) .
Читайте также: