
Как узнать кодировку файла в архиве
Обновлено: 14.05.2024
каков наилучший способ программно определить правильную кодировку кодировки inputstream/файла ?
Я попытался использовать следующее:
но в файле, который, как я знаю, кодируется ISO8859_1, приведенный выше код дает ASCII, что неверно и не позволяет мне правильно отображать содержимое файл в консоль.
вы не можете определить кодировку произвольного потока байтов. Такова природа кодировок. Кодировка означает сопоставление между значением байта и его представлением. Таким образом, каждая кодировка "может" быть правильной.
на getEncoding () метод вернет кодировку, которая была настроена (прочитайте JavaDoc) для потока. Он не угадает кодировку для вас.
некоторые потоки сообщают вам, какая кодировка использовалась для их создания: XML, HTML. Но не произвольный поток байтов.
в любом случае, вы можете попытаться угадать кодировку самостоятельно, если вам нужно. Каждый язык имеет общую частоту для каждого символа. В английском языке char e появляется очень часто, но ê будет появляться очень редко. В потоке ISO-8859-1 обычно нет символов 0x00. Но в потоке UTF-16 Их много.
или: вы можете спросить пользователя. Я уже видел приложения, которые представляют вам фрагмент файла в разных кодировках и спрашивают вас чтобы выбрать "правильный".
вот мои любимые:
можно, конечно,проверка файл для определенной кодировки по декодирования С CharsetDecoder и следить за" неправильным вводом "или" неприменимыми символами " ошибок. Конечно, это только говорит вам, если кодировка неверна; он не говорит вам, если это правильно. Для этого вам нужна основа сравнения для оценки декодированных результатов, например, знаете ли вы заранее, ограничены ли символы некоторым подмножеством или текст придерживается какой строгий формат? Суть в том, что обнаружение кодировок-это догадки без каких-либо гарантий.
Я не тестировал его широко, но, похоже, он работает.
Не забудьте поставить все попытки поймать нужно это.
Я надеюсь, что это работает для вас.
какую библиотеку использовать?
на момент написания этой книги они представляют собой три библиотеки, которые появляются:
Я не включаю Apache Any23 потому что он использует ICU4j 3.4 под капотом.
Как сказать, какой из них обнаружил право charset (или так близко, как возможно)?
невозможно подтвердить кодировку, обнаруженную каждой из вышеперечисленных библиотек. Тем не менее, можно спросить их по очереди и набрать возвращенный ответ.
Как забить возвращенный ответ?
каждому ответу может быть присвоена одна точка. Чем больше точек имеет ответ, тем больше уверенности имеет обнаруженная кодировка. Это простой метод подсчета очков. Вы можете разработать другие.
есть ли пример кода?
здесь полный фрагмент, реализующий стратегию, описанную в предыдущих строках.
улучшения: The guessEncoding метод полностью считывает inputstream. Для больших inputstreams это может быть проблемой. Все эти библиотеки будут читать весь inputstream. Это потребует больших затрат времени на обнаружение кодировки.
можно ограничить начальную загрузку данных несколькими байтами и выполнить обнаружение кодировки на этих нескольких байтах только.
Если вы не знаете кодировку данных, это не так легко определить, но вы могли бы попробовать использовать библиотека, чтобы угадать это. Кроме того, есть аналогичный вопрос.
насколько я знаю, в этом контексте нет общей библиотеки, подходящей для всех типов проблем. Таким образом, для каждой задачи вы должны протестировать существующие библиотеки и выбрать лучшую, которая удовлетворяет ограничениям вашей проблемы, но часто ни одна из них не подходит. В этих случаях вы можете написать свой собственный детектор кодирования! Как я уже писал .
Я написал инструмент meta java для обнаружения кодировки кодировок HTML веб-страниц, используя IBM ICU4j и Mozilla JCharDet в качестве встроенные компоненты. здесь вы можете найти мой инструмент, пожалуйста, прочитайте раздел README, прежде чем что-либо еще. Также, вы можете найти некоторые основные понятия этой проблемы в моем статьи и в его ссылках.
ниже я предоставил некоторые полезные комментарии, которые я испытал в своей работе:
- обнаружение кодировки не является надежным процессом, потому что он по существу основан на статистических данных, и то, что на самом деле происходит, гадание не определения
- icu4j является основным инструментом в этом контексте IBM, imho
- оба TikaEncodingDetector и Lucene-ICU4j используют icu4j, и их точность не имела значимого отличия от того, что icu4j в моих тестах (не более %1, Как я помню)
- icu4j гораздо более общий, чем jchardet, icu4j просто немного смещен к кодировкам семейства IBM, в то время как jchardet сильно смещен к utf-8
- из-за широкое использование UTF-8 в HTML-мире; jchardet-лучший выбор, чем icu4j в целом, но не лучший выбор!
- icu4j отлично подходит для восточноазиатских кодировок, таких как EUC-KR, EUC-JP, SHIFT_JIS, BIG5 и семейные кодировки GB
- как icu4j, так и jchardet-Это фиаско в работе с HTML-страницами с кодировками Windows-1251 и Windows-1256. Windows-1251 aka cp1251 широко используется для кириллических языков, таких как русский и Windows-1256 aka cp1256 is широко используется для арабского
- почти все инструменты обнаружения кодирования используют статистические методы, поэтому точность вывода сильно зависит от размера и содержимого ввода
- некоторые кодировки по существу одинаковы только с частичными различиями, поэтому в некоторых случаях угаданная или обнаруженная кодировка может быть ложной, но в то же время истинной! Что касается Windows-1252 и ISO-8859-1. (см. последний абзац в разделе 5.2 бумага)
для файлов ISO8859_1 существует не простой способ отличить их от ASCII. Для Unicode файлов, однако, как правило, можно обнаружить это на основе первых нескольких байтов файла.
UTF-8 и UTF-16 файлы включают в себя Метка Порядка Байтов (BOM) в самом начале файла. BOM-это пространство с нулевой шириной.
к сожалению, по историческим причинам, Java не обнаруживает это автоматически. Такие программы, как Notepad, проверят спецификацию и используйте соответствующую кодировку. Используя unix или Cygwin, вы можете проверить спецификацию с помощью команды file. Например:
для Java я предлагаю вам проверить этот код, который обнаружит общие форматы файлов и выберет правильную кодировку: Как прочитать файл и автоматически указать правильную кодировку
Как получить кодировку символов текстового файла в Java [версия UTF-8, улучшенная версия]
1. Распознать кодировку символов:
1. Кодировка String в Java по умолчанию - UTF-8, которую можно получить с помощью следующего оператора: Charset.defaultCharset();
2. По умолчанию в Windows используется кодировка текстовых файлов ANSI, для китайских операционных систем - GBK. Например, если мы используем программу «Блокнот» для создания нового текстового документа, кодировка символов по умолчанию - ANSI.
3. Для текстовых текстовых документов предусмотрены четыре варианта кодирования: ANSI, Unicode (включая Unicode Big Endian и Unicode Little Endian), UTF-8, UTF-16.
4. Поэтому, когда мы читаем txt-файл, мы иногда можем не знать его формат кодирования, поэтому нам нужно использовать программу для динамического определения кодировки txt-файла.
- ANSI: нет определения формата, GBK или GB2312 для китайских операционных систем
- UTF-8: первые три байта: 0xE59B9E (UTF-8), 0xEFBBBF (UTF-8 с спецификацией)
- UTF-16: первые два байта: 0xFEFF
- Unicode: первые два байта: 0xFFFE
Например, если документ Unicode начинается с 0xFFFE, используйте программу, чтобы вынуть первые несколько байтов и оценить.
5. Соответствие между кодировкой Java и кодировкой текста:
UTF-8 содержит две спецификации:
Нужно судить о первых трех байтах:
Первые три байта: 0xE59B9E
Первые три байта: 0xEFBBBF
Юникод содержит две спецификации:
1、UCS2 Little Endian
2、UCS2 Big Endian
Java читает текстовый файл. Если формат кодирования не совпадает, появятся искаженные символы. Поэтому вам необходимо установить правильную кодировку символов при чтении текстовых файлов. Формат кодирования текстового документа записывается в заголовке файла. Формат кодирования файла необходимо проанализировать в программе. После получения формата кодирования файл не будет искажен при чтении файла в этом формате.
Бывают случаи, когда требуется узнать кодировку текстового файла. Это нужно для того, чтобы более эффективно с ним работать или перекодировать. Ведь иногда при открытии некоторых файлов на экране появляются непонятные символы. Поэтому чтобы нормально открывать такие файлы, нужно знать их кодировку.
- Как узнать кодировку файла
- Как определить кодировку файла
- Как определить кодировку текстового файла
- Компьютер, программа Штирлиц, доступ в интернет
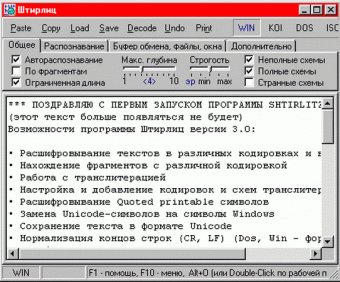
Очень удобным приложением для определения кодировки файла является программа Штирлиц. Приложение расшифровывает различные тексты, независимо от того, с помощью какой кодировки они были написаны. Скачайте и установите программу на компьютер.
После установки внимательно изучите панель инструментов программы. Если у вас есть текст, который вам нужно открыть и узнать его кодировку, нажмите на строку «Файл». Затем выберите компонент «Открыть». Появится список всех файлов на вашем компьютере. Найдите файл, который нужно декодировать или узнать его кодировку. Если файл в окне не отображается, в строке «Тип файлов» замените «Текстовые файлы» на «Все файлы». После того как найдете нужный файл, нажмите «Открыть». Файл откроется в окне программы. Тип кодировки файла должен отображаться в окне программы.
На верхней панели инструментов есть функция «Декодировать файл». В случае необходимости можете ею воспользоваться. Также справа в окне программы имеется панель инструментов, где можно выбрать различные варианты кодировки файла.
Чтобы прочитать текст неизвестной вам кодировки, из списка файлов выберите нужный файл. Затем на панели инструментов выберите строку «Декодировать», после чего программа начнет процесс декодирования файла. После окончания этого процесса декодированный текст будет доступен в новом окне.
Помимо этого можно совершать различные вариации работы с текстом. В верхнем окне программы можете выбрать тип и размер шрифта, воспользоваться различными командами для коррекции. Также можно преобразовать HTML в форматный текст или в обычный текст.
в нашем приложении, мы получаем текстовые файлы ( .txt , .csv , etc.) из различных источников. При чтении эти файлы иногда содержат мусор, потому что файлы, созданные в другой / неизвестной кодовой странице.
есть ли способ (автоматически) определить кодировку текстового файла?
на detectEncodingFromByteOrderMarks на StreamReader конструктор, работает на UTF8 и другие отмеченные unicode файлы, но я ищу способ обнаружения кодовых страниц, таких как ibm850 , windows1252 .
Спасибо за ваши ответы, это то, что я сделал.
файлы, которые мы получаем от конечных пользователей, они не имеют понятия о кодовых страниц. Получатели также являются конечными пользователями, теперь это то, что они знают о кодовых страницах: кодовые страницы существуют и раздражают.
устранение:
- откройте полученный файл в блокноте, посмотрите на искаженный фрагмент текста. Если кого-то зовут Франсуа или что-то вроде того, с вашим человеком интеллект вы можете догадаться об этом.
- я создал небольшое приложение, которое пользователь может использовать для открытия файла, и введите текст, который пользователь знает, что он появится в файле, когда используется правильная кодовая страница.
- цикл через все кодовые страницы и отображать те, которые дают решение с предоставленным пользователем текстом.
- если появляется несколько кодовых страниц, попросите пользователя указать больше текста.
вы не можете обнаружить кодовую страницу, вам нужно сказать это. Вы можете анализировать байты и угадывать их, но это может дать некоторые странные (иногда забавные) результаты. Я не могу найти его сейчас, но я уверен, что блокнот можно обмануть, показывая английский текст на китайском языке.
В Частности Джоэл говорит:
Если вы хотите обнаружить кодировки без UTF (т. е. без BOM), вы в основном занимаетесь эвристикой и статистическим анализом текста. Возможно, вы захотите взглянуть на Mozilla paper об универсальном обнаружении кодировок (та же ссылка, с лучшим форматированием через Wayback Machine).
Читайте также: