
Как в ms sql server формируется размер файла
Обновлено: 05.07.2024
На физическом уровне БД представляется набором файлов операционной системы. Данные и сведения журналов транзакций всегда размещаются в разных файлах. Отдельные файлы используются только одной базой данных. Файловые группы представляют собой именованные коллекции файлов и используются для упрощения размещения данных и выполнения задач администрирования, например резервного копирования и восстановления. Изначально можно указать максимальный размер каждого файла. Если максимальный размер файла не указан, файлы SQL Server могут автоматически увеличиваться в размерах, превосходя первоначально заданные показатели, пока не займут все доступное место на диске.
Базы данных SQL Server содержат файлы трех типов:
Первичные файлы данных. Первичный файл данных является отправной точкой базы данных. Он указывает на остальные файлы базы данных. В каждой базе данных имеется один первичный файл данных. Для имени первичного файла данных рекомендуется исп. расширение MDF.
Вторичные файлы данных. Ко вторичным файлам данных относятся все файлы данных, за исключением первичного файла данных. Базы данных могут вообще не содержать вторичных файлов данных, или содержать один или несколько вторичных файлов данных. Для имени вторичного файла данных рекомендуется использовать расширение NDF.
Файлы журналов. Файлы журналов содержат все сведения журналов, используемые для восстановления базы данных. В каждой базе данных должен быть по меньшей мере один файл журнала, но их может быть и больше. Для имен файлов журналов рекомендуется использовать расширение MDF, NDF и LDF. Однако эти расширения помогают пользователю идентифицировать различные виды файлов и правильно их использовать.
В SQL Server расположение всех файлов базы данных записывается в первичный файл базы данных и в специальную служебную структуру СУБД SQL Server, называемою базой данных master. В большинстве случаев при работе с базой данных компонент СУБД (SQL Server Database Engine) использует сведения о размещении файлов, хранимые в базе данных master. Однако в некоторых случаях (например, при восстановлении базы данных master из копии, при определенным образом проводимым присоединении базы данных) компонент Database Engine использует сведения о расположении файлов из первичного файла, чтобы инициализировать записи о расположении файлов в базе данных master.
Файлы SQL Server имеют два имени:
· logical_file_name — имя, используемое для ссылки на физический файл во всех инструкциях Transact-SQL. Логическое имя файла должно соответствовать правилам для идентификаторов SQL Server и быть уникальным среди логических имен файлов в соответствующей базе данных.
· os_file_name — это имя физического файла, включая путь к каталогу. Оно должно соответствовать правилам для имен файлов операционной системы.
Основной единицей хранилища данных и обмена информацией между внешней и оперативной памятью в SQL Server является страница. Дисковые операции ввода-вывода выполняются на уровне страницы. А именно, SQL Server считывает или записывает целые страницы данных. В SQL Server размер страницы составляет 8 КБ. Это значит, что в одном мегабайте базы данных SQL Server содержится 128 страниц. Каждая страница начинается с 96-байтового заголовка, который используется для хранения системных данных о странице. Эти данные включают номер страницы, тип страницы, объем свободного места на странице и идентификатор единицы распределения объекта, которому принадлежит страница. В файлах данных базы данных SQL Server используется 8 типов страниц (данные с типами данных небольших размеров, данные с типами данных больших размеров, записи индекса, сведения о размещении экстентов, сведения о размещении страниц и доступном на них свободном месте и т. д.).
Для эффективного управления памятью страницы объединяются в экстенты , которые являются основными единицами организации пространства.
Экстент — это коллекция, состоящая из восьми физически непрерывных страниц или 64 Кб; они используются для эффективного управления страницами. Все страницы хранятся в экстентах. Таким образом, в одном мегабайте базы данных SQL Server содержится 16 экстентов.

Опора деревянной одностоечной и способы укрепление угловых опор: Опоры ВЛ - конструкции, предназначенные для поддерживания проводов на необходимой высоте над землей, водой.

Общие условия выбора системы дренажа: Система дренажа выбирается в зависимости от характера защищаемого.

Организация стока поверхностных вод: Наибольшее количество влаги на земном шаре испаряется с поверхности морей и океанов (88‰).
Поперечные профили набережных и береговой полосы: На городских территориях берегоукрепление проектируют с учетом технических и экономических требований, но особое значение придают эстетическим.
В сегодняшней статье я хочу поговорить об очень важной теме SQL Server: как SQL Server обрабатывает файловые группы файлов. Когда вы используете команду CREATE DATABASE для создания простой базы данных, SQL Server создает для вас 2 файла:
- Файл данных (.mdf)
- Файл журнала транзакций (.ldf)
Сам файл данных создается в одной и только одной основной группе файлов. По умолчанию в основной группе файлов SQL Server хранит все данные (пользовательские таблицы, системные таблицы и т. Д.). Для чего нужны дополнительные файлы и файловые группы? Давайте взглянем.
Когда вы создаете дополнительные файловые группы для своих данных, вы можете сохранять в них определяемые вами таблицы и индексы. Это поможет вам во многих отношениях.
- Вы можете сохранить свою основную файловую группу небольшой.
- Вы можете разделить данные на несколько файловых групп (например, вы можете использовать файловые разделы в корпоративной версии).
- Вы можете выполнять операции резервного копирования и восстановления на уровне файловой группы. Это дает вам более точный контроль над стратегиями резервного копирования и восстановления.
- Команду DBCC CHECKDB можно запустить на уровне группы файлов, а не на уровне базы данных.
Как правило, у вас должна быть хотя бы одна группа подчиненных файлов, в которой вы можете хранить создаваемые вами объекты базы данных. Вы не должны хранить другие системные объекты, созданные SQL Server для вас, в основной файловой группе.
Когда вы создаете свою собственную файловую группу, вы также должны поместить в нее хотя бы один файл. Кроме того, в файловую группу можно добавлять дополнительные файлы. Это также улучшит вашу производительность загрузки, потому что SQL Server будет распространять данные по всем файлам, так называемые Алгоритм Round Robin Allocation (Алгоритм Round Robin Allocation). Первые 64 КБ хранятся в первом файле, вторые 64 КБ хранятся во втором файле, а третья область сохраняется в первом файле (в вашей файловой группе, когда у вас есть 2 файла).
Используя этот метод, SQL Server может находиться в буферном пуле Защелка выделяет несколько копий растровых страниц (PFS, GAM, SGAM) и повышает производительность загрузки. Вы также можете использовать этот метод для решения той же проблемы с конфигурацией по умолчанию в TempDb. Кроме того, SQL Server также гарантирует, что все файлы в группе файлов будут заполнены в один и тот же момент времени - с помощью так называемого Алгоритм пропорционального заполнения . Поэтому очень важно, чтобы все ваши файлы в группе файлов имели одинаковый начальный размер и параметры автоматического увеличения. в противном случае Алгоритм распределения циклического планирования не может работать должным образом.
Теперь мы рассмотрим следующий пример, как создать базу данных с несколькими файлами в группе дополнительных файлов. В следующем коде показана команда CREATE DATABASE, которую необходимо использовать для выполнения этой задачи.
После создания базы данных возникает вопрос, как поместить таблицу или индекс в определенную файловую группу? Вы можете использовать ключевое слово ON, чтобы вручную указать группу файлов, как показано в следующем коде:
Другой вариант: вы помечаете определенную группу файлов как группу файлов по умолчанию. Затем SQL Server автоматически создает новый объект базы данных в группе файлов, в которой не указано ключевое слово ON.
Это метод, который я обычно рекомендую, потому что вам больше не нужно думать об этом после создания объектов базы данных. Итак, теперь давайте создадим новую таблицу, которая будет автоматически сохранена в файловой группе FileGroup1.
Теперь проводим простой тест: вставляем в таблицу 40 000 записей. Каждая запись имеет размер 8 КБ. Итак, мы вставили в таблицу 320 МБ данных. Это то, что я только что упомянул Алгоритм распределения расписания опроса будет работать: SQL Server будет распределять данные между 2 файлами: первый файл содержит 160 МБ данных, а второй файл также будет иметь 160 МБ данных.
Затем вы можете проверить его на жестком диске, и вы увидите тот же размер, что и два файла.

Когда вы помещаете эти файлы на разные физические жесткие диски, вы можете получить к ним доступ одновременно. Это сила наличия нескольких файлов в файловой группе.
Вы также можете использовать следующий сценарий для получения информации о файле базы данных.
В сегодняшней статье я показал вам, как несколько групп файлов и несколько файлов в группе файлов упрощают управление вашей базой данных и как использовать несколько файлов в группе файлов. Алгоритм распределения циклического планирования.
Многие администраторы Microsoft SQL Server сталкивались с проблемой значительного увеличения физического размера базы данных и файлов журнала транзакций и, конечно же, им хотелось бы каким-то образом уменьшить этот размер, для того чтобы не предпринимать какие-либо действия, связанные с увеличением свободного пространства на жестком диске. Способ уменьшить физический размер базы данных и файлов журнала транзакций в SQL сервере есть – это сжатие.

Что такое сжатие в Microsoft SQL Server?
Физический размер файлов базы данных со временем растет, это связанно с добавлением данных, но при их удалении физический размер файлов остается неизменным, однако в данных файлах появляется логическое неиспользуемое пространство, которое и можно удалить.
Наибольший эффект от сжатия достигается тогда, когда операция сжатия выполняется после операции удаления таблиц из БД или удаления данных из таблиц.
Следует отличать процедуру сжатия журнала транзакций от процедуры усечения журнала транзакций. Сжатие — это уменьшение физического размера журнала за счет удаления неиспользуемого пространства, а усечение – это освобождение места в логическом журнале для повторного использования (т.е. образуется неиспользуемое пространство) журналом транзакций при этом размер физического файла не уменьшается.
Усечение журнала транзакций происходит автоматически:
- В простой модели восстановления — после достижения контрольной точки, которая может возникнуть, например, после создания BACKUP базы данных, при явном выполнении инструкции CHECKPOINT, или тогда когда размер логического журнала транзакций заполняется на 70 процентов, во всех этих случаях происходит автоматическая очистка неактивной части журнала, т.е. его усечение;
- В модели полного восстановления или в модели восстановления с неполным протоколированием — после создания резервной копии журнала при условии, что с момента создания последней резервной копии журнала была достигнута контрольная точка.
Если Вы используете модель полного восстановления или в модель восстановления с неполным протоколированием и у Вас файлы журнала транзакций слишком велики, то скорей всего Вы достаточно долго не делали BACKUP (резервную копию) журнала транзакций. В данном случае Вам необходимо сделать сначала BACKUP журнала транзакций, а затем выполнить сжатие журнала транзакций, которое мы как раз и рассмотрим чуть ниже.
Также возможно размер файлов журнала транзакций слишком большой (как при простой, так и при полной модели восстановления) за счет задержки процедуры усечения, т.е. размер журнала, состоит в основном из активной части журнала, а активную часть усечь нельзя, поэтому физический размер журнала растет. На задержку процедуры усечения влияют такие факторы как: активные длительные транзакции, некоторые сценарии отображения зеркальных баз данных и журнала транзакций, некоторые сценарии при репликации транзакций и журнала транзакций, а также усечение журнала невозможно во время операций резервного копирования и восстановления данных. В данном случае Вам нужно устранить причины задержки, затем сделать усечение (т.е. например, для полной модели восстановления BACKUP журнала), а затем сжатие до приемлемых размеров.
Обычно если на постоянной основе с определенной периодичностью создаются резервные копии журнала транзакций или базы данных (при простой модели восстановления), файлы журнала транзакций не растут, и не возникает переполнение журнала транзакций.
Как сжать базу данных в MS SQL Server?
Сжать файлы базы данных и журнала транзакций можно и с помощью графического интерфейса Management Studio и с помощью инструкций Transact-SQL: DBCC SHRINKDATABASE и DBCC SHRINKFILE. Также возможно настроить базу данных на автоматическое сжатие путем выставления параметра БД AUTO_SHRINK в значение ON.
Примечание! Сжатие базы данных я буду рассматривать на примере Microsoft SQL Server 2016 Express.
Сжимаем базу данных с помощью среды Management Studio
Запускаем Management Studio и в обозревателе объектов открываем объект «Базы данных». Затем щелкаем правой кнопкой мыши по БД, которую необходимо сжать, далее выбираем «Задачи ->Сжать -> База данных (или Файлы, если, например, нужно сжать только журнал транзакций)». Я для примера выбираю «База данных».
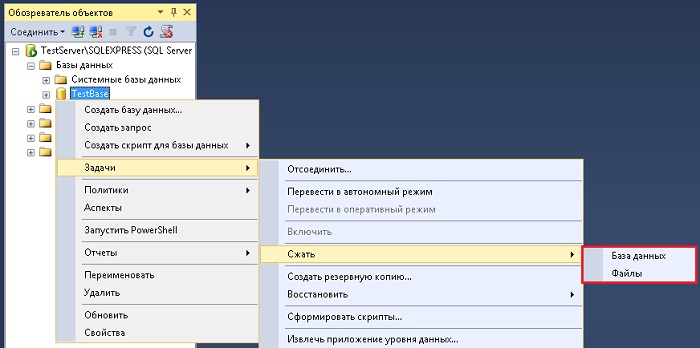
В итоге у Вас откроется окно «Сжатие базы данных», в котором Вы, кстати, можете наблюдать размер базы данных, а также доступное свободное место, которое можно удалить (т.е. сжать). Нажимаем «ОК».
Через некоторое время, в зависимости от размера базы данных, сжатие будет завершено.
Сжимаем базу данных с помощью инструкций SHRINKDATABASE и SHRINKFILE
В MS SQL Server для выполнения сжатия файлов базы данных и журнала транзакций существуют две инструкции SHRINKDATABASE и SHRINKFILE.
- DBCC SHRINKDATABASE – это команда для сжатия базы данных;
- DBCC SHRINKFILE – с помощью данной команды можно выполнить сжатие некоторых файлов базы данных (например, только журнала транзакций).
Для того чтобы выполнить сжатие БД (например, TestBase) точно также как мы это сделали чуть ранее в Management Studio, выполните следующую инструкцию.
SHRINKDATABASE имеет следующие параметры:
Синтаксис SHRINKDATABASE
Для того чтобы сжать только журнал транзакций можно использовать инструкцию SHRINKFILE, например.
В данном случае мы осуществим сжатие файла журнала (TestBase_log – это название файла журнала транзакций), до его начального значения, т.е. до значения по умолчанию. Для того чтобы сжать файл до определенного размера, укажите вторым параметром размер в мегабайтах. Например, следующей инструкцией мы уменьшим размер файла журнала транзакций до 5 мегабайт.
Также необходимо учесть, что если Вы укажете размер меньше того, чем требуется для хранения данных в файле, то файл до этого размера сжат не будет. Например, допустим, если Вы указали 5 мегабайт, а для хранения данных в файле требуется 7 мегабайт, файл будет сжат только до 7 мегабайт.
SHRINKFILE также имеет параметры NOTRUNCATE и TRUNCATEONLY.
Синтаксис SHRINKFILE
Рекомендации и важные моменты при сжатии базы данных
- Операция сжатия базы данных может вызвать фрагментацию индексов и замедлить работу БД. Поэтому слишком часто не рекомендуется выполнять сжатие базы данных;
- Сжимать БД лучше до операции перестроения индексов, т.е. после сжатия запустите процедуру перестроения индексов;
- Параметр базы данных AUTO_SHRINK (автоматическое сжатие) лучше не выставлять в значение ON, а оставлять по умолчанию, т.е. в OFF, если конечно у Вас нет на это достаточно серьезных оснований;
- Инструкция SHRINKDATABASE не позволяет уменьшить размер базы данных до размера, который меньше начального, т.е. минимального. Однако инструкция SHRINKFILE сделать это может (вторым параметром указываем размер меньше минимального). Минимальный размер базы данных — это размер, который указан при создании базы данных или явно установленный операцией изменения размера БД, такой как DBCC SHRINKFILE или ALTER DATABASE. Например, если база данных была создана с размером 10 мегабайт, потом увеличилась до 100 мегабайт, ее можно сжать с помощью SHRINKDATABASE только до начальных 10 мегабайт, даже если все данные были удалены из базы данных;
- Сжимать файлы базы данных и журнала транзакций нельзя, когда идет процесс их резервирования. И наоборот, создавать резервные копии базы и журнала транзакций нельзя пока идет процесс их сжатия;
- Выполнение инструкции DBCC SHRINKDATABASE без указания параметра NOTRUNCATE или TRUNCATEONLY равносильно выполнению инструкции DBCC SHRINKDATABASE с параметром NOTRUNCATE после выполнения инструкции DBCC SHRINKDATABASE с параметром TRUNCATEONLY;
- В процессе сжатия базы данных пользователи могут работать в ней (т.е. переводить БД в однопользовательский режим не нужно);
- В любой момент времени Вы можете прервать процесс выполнения операций SHRINKDATABASE и SHRINKFILE, при этом вся выполненная работа сохраняется;
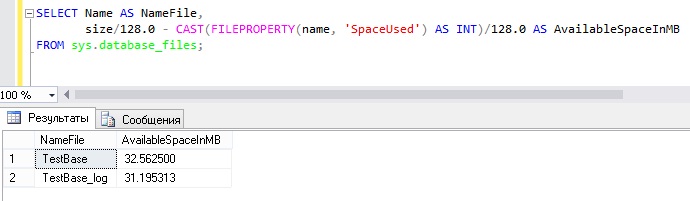
- Перед запуском процедуры сжатия проверьте, есть ли свободное пространство для удаления в файлах базы данных, т.е. можно ли вообще сжать файлы, выполнив следующий запрос (он покажет в мегабайтах, на сколько Вы можете уменьшить файлы БД).
Заметка! Если Вас интересует SQL и T-SQL, рекомендую посмотреть мои видеокурсы по T-SQL, с помощью которых Вы «с нуля» научитесь работать с SQL и программировать с использованием языка T-SQL в Microsoft SQL Server.
Изучить принципы использования файловой структуры при хранении баз данных в MS SQL Server 2000.
Оглавление
Задания
- Изучить типы файлов, которые создаются на сервере в момент создания новой базы данных на сервере MS SQL Server 2000.
- Изучить типы индексных файлов, которые могут создаваться на сервере MS SQL Server 2000. Понять различие кластерного и не кластерного индекса.
- Изучить операторы создания и перестройки индексов.
- Создать требуемые индексы.
- Подготовить отчет о проделанной работе в электронном виде.
1. Системы хранения данных в MS SQL Server 2000
По умолчанию при создании новой базы данных предлагается расположить ее в двух файлах (рис. 1).

В общем случае сложные и большие базы данных в MS SQL Server 2000 могут располагаться более чем в двух файлах. В таких случях эти файлы объединяются в группы.
Все файлы базы данных разделяются на три типа:


В MS SQL Server 2000 предусмотрена врзможность автоматического увеличения размера файлов. Настройка параметров увеличения размера файлов показана на рис. 2 . В нашем случае выбрано не абсолютное увеличение, а процентное: на 10% при исчерпании заданного пространства.
2. Индексные файлы
MS SQL Server 2000 поддерживает три типа индексов:
В операции создания индекса пользователь в явном виде задает тип индекса, который будет создан.
В некластерном индексе значения индексируемых столбцов хранятся в упорядоченном виде, и каждому значению соответствует ссылка на строку исходной таблицы. Таким образом, некластерный индекс фактически соответствует плотному индексу, однако в некластерном индексе индексируемые значения могут повторяться, поэтому он создается не для первичного или возможного ключа, а для произвольного столбца таблицы, по которому необходимо обеспечить наиболее быстрый поиск.
В MS SQL Server при создании некластерного индекса можно явно задать порядок сортировки значений индексируемых столбцов.
Любой индекс создается следующей командой:
CREATE [UNIQUE] [CLUSTERED | NONCLUSTERED]
INDEX_name ON table(column [ASC| DESC] [. n])
[WITH
[PAD_INDEX]
[[,] FILLFACTOR = fillfactor]
[[,] IGNORE_DUP_KEY]
[[,] DROP_EXISTING]
[[,] STATISTICS_NORECOMPUTE]]
[ON filegroup]
[SORT_IN_TEMPDB]
MS SQL Server 2000 позволяет создавать индексы с использованием графического интерфейса в Enterprise Manager. Индексы, как и триггеры, принадлежат в скрытым объектам MS SQL Server 2000. В перечне объектов базы данных они отсутствуют. Действительно, так как индексы строятся к таблицам данных или к представлениям, то интерфейс управления индексами находится в контекстном меню конкретной таблицы, в разделе Все задачи , и называется Manage Indexes (рис. 4).

По умолчанию при создании таблицы создается кластерный индекс для первичного ключа данной таблицы. В каждой подчиненной таблице, кроме кластерного индекса по первичному ключу, создаются некластерные индексы для каждого внешнего ключа (рис. 5).

Характеристики индексов, созданных по умолчанию, можно посмотреть и при необходимости отредактировать, нажав кнопку Edit (рис. 6).

Удаляется индекс следующей командой:
DROP INDEX <имя таблицы>.<имя индекса>
CREATE
INDEX [books_YEAR] ON [dbo].[Books] ([YEARIZD])
В базе данных Master имеется специальная системная таблица sysindexes , в которой хранится описание всех созданных индексов. Для того чтобы удалить индекс, можно использовать следующий скрипт:
IF EXISTS (SELECT name FROM sysindexes
WHERE name = 'books_YEAR')
DROP INDEX books.books_YEAR
3. Дополнительная статистика по индексу
Ниже приведены команды создания дополнительной статистики и ее обновления:
CREATE STATISTICS statistics_name
ON (column [. n])
[WITH
[[FULLSCAN
| SAMPLE number ] [, ]]
[NORECOMPUTE]
]
UPDATE STATISTICS table | view
[index | (statistics_name [. n])]
[WITH
[[FULLSCAN]
| SAMPLE number ]
| RESAMPLE
]
[[, ] [ALL | COLUMNS | INDEX]
[[, ] NORECOMPUTE]
]
Для любого индекса можно посмотреть статистику с помощью следующей команды:
DBCC Show Statistics(<таблица>, <индекс>)
Пример вывода статистики по созданному нами индексу для года издания приведен на рис. 7.

Если вы создавали дополнительную статистику, то ее можно удалить следующей командой:
Читайте также: