
Как в тесте дарбина уотсона найти dl и du в экселе
Обновлено: 06.07.2024
( n-число наблюдений, p- число объясняющих переменных).
| n | p=1 dL dU | P=2 dL dU | p=3 dL dU | p=4 dL dU |
| 1.08 1.36 | 0.95 1.54 | 0.82 1.75 | 0.69 1.97 | |
| 1.10 1.37 | 0.98 1.54 | 0.86 1.73 | 0.74 1.93 | |
| 1.13 1.38 | 1.02 1.54 | 0.90 1.71 | 1.78 1.90 | |
| 1.16 1.39 | 1.05 1.53 | 0.93 1.69 | 1.82 1.87 | |
| 1.18 1.40 | 1.08 1.53 | 0.97 1.68 | 0.85 1.85 | |
| 1.20 1.41 | 1.10 1.54 | 1.00 1.68 | 0.90 1.83 | |
| 1.22 1.42 | 1.13 1.54 | 1.03 1.67 | 0.93 1.81 | |
| 1.24 1.43 | 1.15 1.54 | 1.05 1.66 | 0.96 1.80 | |
| 1.26 1.44 | 1.17 1.54 | 1.08 1.66 | 0.99 1.79 | |
| 1.27 1.45 | 1.19 1.55 | 1.10 1.66 | 1.01 1.78 | |
| 1.29 1.45 | 1.21 1.55 | 1.12 1.66 | 1.04 1.77 | |
| 1.30 1.46 | 1.22 1.55 | 1.14 1.65 | 1.06 1.76 | |
| 1.32 1.47 | 1.24 1.56 | 1.16 1.65 | 1.08 1.76 | |
| 1.33 1.48 | 1.26 1.56 | 1.18 1.65 | 1.10 1.75 | |
| 1.34 1.48 | 1.27 1.56 | 1.20 1.65 | 1.12 1.74 | |
| 1.35 1.49 | 1.28 1.57 | 1.21 1.65 | 1.14 1.74 | |
| 1.36 1.50 | 1.30 1.57 | 1.23 1.65 | 1.16 1.74 | |
| 1.37 1.50 | 1.31 1.57 | 1.34 1.65 | 1.18 1.73 | |
| 1.38 1.51 | 1.32 1.58 | 1.26 1.65 | 1.19 1.73 | |
| 1.39 1.51 | 1.33 1.58 | 1.27 1.65 | 1.21 1.73 | |
| 1.40 1.52 | 1.34 1.58 | 1.28 1.65 | 1.22 1.73 | |
| 1.41 1.52 | 1.35 1.59 | 1.29 1.65 | 1.24 1.73 |
Таблица П.А.2Значения статистик dL и dU критерия Дарбина –Уотсона
при уровне значимости a= 0,01
( n-число наблюдений, p- число объясняющих переменных)
| n | p=1 dL dU | p=2 dL dU | p=3 dL dU | p=4 dL dU |
| 0,81 1,07 | 0,70 1,25 | 0,59 1,46 | 0,49 1,70 | |
| 0,84 1,09 | 0,74 1,25 | 0,63 1,44 | 0,534 1,66 | |
| 0,87 1,10 | 0,77 1,25 | 0,67 1,43 | 0,57 1,63 | |
| 0,90 1,12 | 0,80 1,26 | 0,71 1,42 | 0,61 1,60 | |
| 0,93 1,13 | 0,83 1,26 | 0,74 1,41 | 0,65 1,58 | |
| 0,95 1,15 | 0,86 1,27 | 0,77 1,41 | 0,68 1,57 | |
| 0,97 1,16 | 0,89 1,27 | 0,80 1,41 | 0,72 1,55 | |
| 1,00 1,17 | 0,91 1,28 | 0,83 1,40 | 0,75 1,54 | |
| 1,02 1,19 | 0,94 1,29 | 0,86 1,40 | 0,77 1,53 | |
| 1,04 1,20 | 0,96 1,30 | 0,88 1,41 | 0,80 1,53 | |
| 1,05 1,21 | 0,98 1,30 | 0,90 1,41 | 0,83 1,52 | |
| 1,07 1,22 | 1,00 1,31 | 0,93 1,41 | 0,85 1,52 | |
| 1,09 1,23 | 1,02 1,32 | 0,95 1,41 | 0,88 1,51 | |
| 1,10 1,24 | 1,04 1,32 | 0,95 1,41 | 0,90 1,51 | |
| 1,12 1,25 | 1,05 1,33 | 0,99 1,42 | 0,92 1,51 | |
| 1,13 1,26 | 1,07 1,34 | 1,01 1,42 | 0,94 1,51 | |
| 1,15 1,27 | 1,08 1,34 | 1,02 1,42 | 0,96 1,51 | |
| 1,16 1,28 | 1,10 1,35 | 1,04 1,43 | 0,98 1,51 | |
| 1,17 1,29 | 1,11 1,36 | 1,05 1,43 | 1,00 1,51 | |
| 1,18 1,30 | 1,13 1,36 | 1,07 1,43 | 1,01 1,51 | |
| 1,19 1,31 | 1,14 1,37 | 1,08 1,44 | 1,03 1,51 | |
| 1,21 1,32 | 1,15 1,38 | 1,10 1,44 | 1,04 1,51 |
Приложение Б. Исследование уравнений регрессии
С помощью пакетов прикладных программ Excel
Общие сведения
Исследование линейного уравнение регрессии с помощью ППП Excel возможно с использованием встроенной статистической функции ЛИНЕЙН, либо с помощью инструмента анализа данных РЕГРЕССИЯ. Рассмотрим каждый из этих вариантов.
1.1. Введите исходные данные или откройте существующий файл, содержащий анализируемые данные.
1.2. Выделите область пустых ячеек 5×2 (5 строк и 2 столбца) для вывода результатов регрессионной статистики (или область 1×2 –для получения только оценок коэффициентов регрессии).
1.3. Активизируйте Мастер функций, в окне Категория выберите Статистические, в окне Функция – Линейн.
1.4. Заполните аргументы функции:
Известные значения y- диапазон, содержащий данные зависимой переменной Y;
Известные значения x- диапазон, содержащий данные независимой переменной X;
Константа – логическое значение, которое указывает на наличие или отсутствие свободного члена в уравнении регрессии. Если Константа=1, то свободный член a в уравнении регрессии рассчитывается обычным образом; если Константа=0, то свободный член равен нулю, a =0.
Статистика – логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика=1, то выводится дополнительная информация; если Статистика=0, то выводятся только оценки параметров уравнения.
1.5. После заполнения аргументов в левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нужно нажать на клавишу «F2», а затем на комбинацию клавиш «CTRL»+«SHIFT»+«ENTER». Дополнительная регрессионная статистика будет выводиться в следующем порядке:
2. С помощью инструмента анализа данных Регрессия,помимо результатов регрессионной статистики, можно выполнить дисперсионный анализ, построить доверительные интервалы для параметров уравнения регрессии, можно получить остатки, графики остатков и графики подбора линии регрессии. Последовательность подключения и работы с инструментом анализа данных следующая:
2.1. Для подключения пакета анализа данных в главном меню последовательно выберите Сервис/Надстройки. Установите флажок у надстройки Пакет анализа.
2.2 В главном меню выберите Сервис/Анализ данных/Регрессия.
2.3. Заполните диалоговое окно ввода данных и параметров вывода.
Выходной интервал Y - здесь требуется задать состоящий из одного столбца диапазон анализируемых зависимых данных.
Уровень надежности - по умолчанию, применяется уровень 95%. Установить флажок, если нужно включить в выходной диапазон дополнительный уровень, а в поле (рядом) ввести уровень надежности, который будет использован дополнительно к применяемому.
Константа – ноль – этот флажок необходимо пометить только в том случае, если нужно получить уравнение без свободного члена, чтобы линия регрессии прошла через начало координат.В целях исключения ошибок спецификациимодели линейной регрессиирекомендуется не активизировать этот флажок и всегда рассчитывать значение константы; в дальнейшем, если это значение окажется незначимым, им можно пренебречь.
Выходной диапазон - здесь требуется определить левую верхнюю ячейку выходного диапазона. Необходимо минимум семь столбцов для итогового диапазона, который будет включать в себя: результаты дисперсионного анализа, коэффициенты регрессии, стандартную погрешность вычисления Y, среднеквадратичные отклонения, число наблюдений, стандартные погрешности для коэффициентов. В случае сложной задачи, где требуется получить большое число результатов исследования уравнений, лучше воспользоваться возможностью размещения каждого из них на новом рабочем листе.
Новый лист - здесь требуется установить переключатель для открытия нового листа в книге под результаты анализа, начиная с ячейки А1. Можно ввести имя нового листа в поле напротив переключателя.
Остатки- установкой этого флажка заказывается включение остатков в выходной диапазон. Для получения максимума информации в ходе исследования рекомендуется активизировать этот и все описанные ниже флажки диалогового окна.
График остатков - чтобы построить диаграмму остатков для каждой независимой переменной, нужно установить этот флажок.
График подбора - это важнейший график, а точнее серия графиков, показывающих насколько хорошо теоретическая линия регрессии (т.е. предсказания) подобрана к наблюдаемым данным.
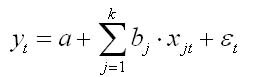
где k — число независимых переменных модели регрессии.
Для каждого момента времени t = 1 : n значение определяется по формуле
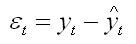
Изучая последовательность остатков как временной ряд в дисциплине эконометрика, можно построить график их зависимости от времени. В соответствии с предпосылками метода наименьших квадратов остатки должны быть случайными (а). Однако при моделировании временных рядов иногда встречается ситуация, когда остатки содержат тенденцию (б и в) или циклические колебания (г). Это говорит о том, что каждое следующее значение остатков зависит от предыдущих. В этом случае имеется автокорреляция остатков.
.jpg)
Причины автокорреляции остатков
Автокорреляция остатков может возникать по несколькими причинами:
Во-первых, иногда автокорреляция связана с исходными данными и вызвана наличием ошибок измерения в значениях Y.
Во-вторых, иногда причину автокорреляции остатков следует искать в формулировке модели. В модель может быть не включен фактор, оказывающий существенное воздействие на результат, но влияние которого отражается в остатках, вследствие чего последние могут оказаться автокоррелированными. Зачастую этим фактором является фактор времени t.
Иногда, в качестве существенных факторов могут выступать лаговые значения переменных, включенных в модель. Либо в модели не учтено несколько второстепенных факторов, совместное влияние которых на результат существенно ввиду совпадения тенденций их изменения или циклических колебаний.
Методы определения автокорреляции остатков
Первый метод — это построение графика зависимостей остатков от времени и визуальное определение наличия автокорреляции остатков.
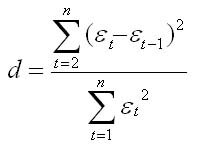
Коэффициент автокорреляции первого порядка определяется по формуле
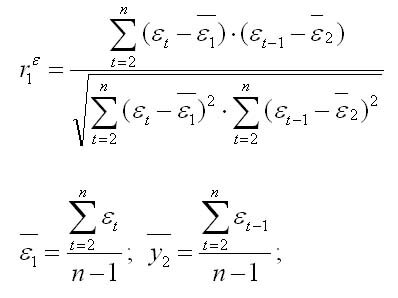
Соотношение между критерием Дарбина — Уотсона и коэффициентом автокорреляции остатков (r1) первого порядка определяется зависимостью
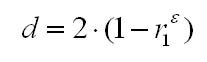
Т.е. если в остатках существует полная положительная автокорреляция r1 = 1, а d = 0, Если в остатках полная отрицательная автокорреляция, то r1 = — 1, d = 4. Если автокорреляция остатков отсутствует, то r1 = 0, d = 2. Следовательно,
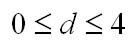
Алгоритм выявления автокорреляции остатков по критерию Дарбина — Уотсона
Выдвигается гипотеза об отсутствии автокорреляции остатков. Альтернативные гипотеэы о наличии положительной или отрицательной автокорреляции в остатках. Затем по таблицам определяются критические значения критерия Дарбина — Уотсона dL и du для заданного числа наблюдений и числа независимых переменных модели при уровня значимости а (обычно 0,95). По этим значениям промежуток [0;4] разбивают на пять отрезков.

Источник: Эконометрика: Учебник / Под ред. И.И. Елисеевой. – М: Финансы и статистика, 2002. – 344 с.
4.4. Автокорреляция возмущений: определение, диагностика и процедуры устранения
Рассмотрим линейную регрессию
где Xt=[xt1, xt2. xtk] T . Будем считать, что индекс t у переменных модели означает, что их значения (регрессанда и регрессоров) изменяются во времени: yt и xtp, - значения переменных в момент времени t (t=1,2,…,n, p=1,2,…,k) то есть модель строится не по пространственной выборке, а по временной, и, чтобы подчеркнуть это, при описании временных выборок мы используем индекс t. Таким образом, уравнение ( 4.29 ) описывает временной ряд зависимой переменной. Для оценки параметров модели временного ряда ( 4.29 ) в условиях предпосылок классической регрессии можно использовать обычный МНК. Однако при моделировании временных рядов часто возникает проблема автокорреляции возмущений . Суть ее заключается в том, что возмущение (случайная составляющая) модели ut в момент времени t зависит от возмущений в предыдущие моменты наблюдений. Автокоррелированность возмущений можно учесть с помощью так называемых моделей авторегрессии . Простейшей из таких моделей является модель авторегрессионного процесса первого порядка (процесс авторегрессии первого порядка). Такой процесс описывается следующим уравнением
где - последовательность некоррелированных случайных величин с характеристиками: математическим ожиданием , и постоянной дисперсией . Начальное значение u0 имеет нулевое математическое ожидание и не зависит от (t=1,2,…,n). Параметр называется коэффициентом авторегресcии , для него должно выполнятся ограничение , которое является необходимым условием стационарности процесса.
Рассмотрим некоторые простейшие свойства процесса авторегрессии. Применяя к обеим частям уравнения ( 4.30 ) операцию математического ожидания и учитывая, что для начального значения , получим для любого t=1,2,…,n. Далее, поскольку , а случайные величины незавимы, то для всех p=1,2,…,t-1, в силу рекуррентной зависимости ( 4.30 ) ( задание : покажите, что это действительно так). Учитывая это, получим выражение для дисперсии
Таким образом, как следует из полученного выражения ( 4.31 ), в общем случае дисперсия процесса авторегрессии зависит от времени (случайное возмущение гетероскедастично). Однако, если начальное значение u0 случайного члена имеет дисперсию
то и для любого t дисперсия случайного члена также равна
и не зависит от времени - случайная составляющая гомоскедастична. Покажем это. Для t = 1 с учетом ( 4.32 ), ( 4.31 ) имеем
Аналогично можно показать, что и для последующих t=2,3,…,n, выполнено соотношение ( 4.34 ), если при каждом t в качестве начального значения регрессии брать ее значение на предыдущем шаге ut-1 (здесь, по существу, используется простейшая схема доказательства по индукции).
Определим элементы ковариационной матрицы вектора возмущений. Умножим левую и правую части уравнения ( 4.30 ) на ut-1 и к получившемуся выражению применим операцию математического ожидания. Получим
поскольку . Аналогично получим
В общем случае точно также можно показать, что
Таким образом, ковариационная матрица имеет следующий вид
Эта матрица отличается от диагональной, поэтому для оценивания модели с автокорреляцией возмущений необходимо использовать обобщенный метод наименьших квадратов. Очевидно, что элементы матрицы легко вычисляются, если известен авторегрессионный параметр . Из выражения ( 4.35 ) легко установить смысл параметра - он равен коэффициенту корреляции между соседними ошибками. Действительно, из ( 4.35 ) получаем, что
Выражение ( 4.36 ) совпадает с определением коэффициента корреляции. В социально-экономических исследованиях этот параметр должен быть оценен на основе эмпирических данных, после проведения теста на автокорреляцию.
Для моделирования авторегрессионной зависимости между наблюдениями можно использовать авторегрессионные процессы и более высоких порядков. Модели таких процессов будут рассмотрены в следующей главе, посвященной анализу временных рядов.
Процедура тестирования на автокорреляцию: тест Дарбина - Уотсона
Существует множество различных тестов для диагностики автокорреляции. Одим из наиболее известных и достаточно просто реализуемых на практике является тест Дарбина-Уотсона (кратко - d -тест). С помощью этого теста проверяется пара гипотез: гипотеза - автокорреляция отсутствует, против альтернативы - возмущения автокоррелированы (или в двух других версиях: - существует положительная корреляция, - существует отрицательная корреляция).
При этом важно иметь ввиду что:
1). При нулевой гипотезе предполагается, что исследуемый процесс описывается классической моделью линейной регрессии, то есть выполнены все предпосылки классической модели (см. п. 3.1 ).
2). Тест не проверяет, действительно ли автокорреляция имеет вид авторегрессии первого порядка (а не описывается другими возможными формами автокорреляционных зависимостей), вид авторегрессионной зависимости постулируется, а проверяется только наличие или отсутствие автокорреляции первого порядка.
Тест Дарбина - Уотсона основан на d - статистике (критерии) Дарбина-Уотсона, которая вычисляется по формуле
Здесь et - остатки регрессионного уравнения. Для их вычисления уравнение оценивается с помощью обычного метода наименьших квадратов. Можно установить зависимость между d - статистикой и выборочным коэффициентом корреляции между соседними ошибками et и et-1. Напомним, что выборочный коэффициент корреляции имеет вид
где выборочная ковариация и дисперсия равны
Для выборки достаточно большого размера можно записать приближенное соотношение
учитывая которое, выборочный коэффициент корреляции ( 4.38 ) можно представить так
Критерий ( 4.37 ) можно записать в виде
Последнее слагаемое в полученном выражении близко к нулю и им можно пренебречь (при достаточно большом n). Тогда окончательно (учитывая ( 4.39 )) получаем
Содержательная интерпретация статистики Дарбина - Уотсона
Опираясь на выражение ( 4.40 ), можно дать следующую содержательную интерпретацию статистики Дарбина-Уотсона. Если между соседними ошибками модели существует положительная корреляция , то величина . При высокой положительной корреляции коэффициент корреляции r будет близок к единице, а d - статистика - к нулю. При отрицательной корреляции значение , а поскольку , то для d - статистики выполняются неравенства .
Распределение d - статистики зависит от следующих величин:
1) от длины наблюдаемого ряда n;
2) от количества регрессоров k;
3) от конкретных наблюдаемых в данной реализации числовых значений регрессоров, то есть от матрицы X.
Последнее обстоятельство делает невозможным прямое построение d - теста, так как для этого потребовалось бы при каждом его применении заново составлять таблицу критических значений d - критерия для соответствующей матрицы X.
К счастью, оказалось (Дарбин и Уотсон это доказали), что существуют две границы, которые определяют области принятия или отклонения гипотез относительно автокорреляции и зависят только от n, k и уровня значимости, но не зависят от конкретных наблюдений регрессоров. Для этих границ можно рассчитать табличные значения. Недостатком d - теста является существование зоны неопределенности, при попадании в которую d - статистики невозможно принять однозначного решения.
При применении d - теста можно руководствоваться следующим эвристическим правилом: если значение d - статистики близко к двум, то автокорреляция возмущений первого порядка несущественна; чем ближе значение d к нулю, тем больше положительная автокорреляция; чем ближе значение d к четырем, тем больше отрицательная автокорреляция.
Порядок применения d - теста
1) . Вычисляем значение d - статистики по формуле ( 4.40 ).
2) . Определяем табличные значения нижней границы dL и верхней dU для заданного уровня значимости и конкретных n и k.
3) . Принимаем решение в соответствии со следующими правилами:
а) . если , то существует положительная корреляция, гипотеза H0 отвергается;
б) . если , то существует отрицательная корреляция, гипотеза H0 отвергается;
в) . если , то корреляция отсутствует, гипотеза H0 не отвергается;
г) . области неопределенности:
4) . Интерпретируем результаты тестирования.
Следует помнить, что корректное применение d - теста требует выполнения предпосылки о некоррелированности регрессоров и возмущений модели. Поэтому его нельзя применять, если, например, в модели присутствуют лаговые (запаздывающие) значения регрессанда в качестве регрессоров (подобные модели часто используются для описания авторегрессионных временных рядов, см. гл. 5 ).
Наличие зон неопределенности существенно снижает эффективность практического использования d - теста. Ошибочное принятие гипотезы H0 приводит к существенному искажению результатов и потере свойств оценок. В тоже время, отклонение нулевой гипотезы, хотя она и верна, приведет лишь к необходимости проведения незначительных дополнительных вычислений, связанных с оценкой параметра авторегрессии и корректировкой модели на авторегрессию. Поэтому, что бы уменьшить вероятность ошибочного решения - принятия гипотезы H0 , когда она неверна, рекомендуется в областях неопределенности нулевую гипотезу отклонять.
В таблице 4.2 приведены данные о годовых доходностях акций компаний A и B (источник: Л.О. Бабешко, 2001, с. 63, [ 4 ]).
Используя данные таблицы 4.2 построим линейную регрессионную модель для изучения влияния изменения доходности акций компании - лидера B на доходность акций компании A и исследуем остатки полученной модели на автокорреляцию, применяя процедуру Дарбина - Уотсона. Спецификация модели имеет вид
где yt - доходность акций компании A, xt - доходность акций компании B. Применение метода наименьших квадратов для оценки коэффициентов модели позволяет получить следующую эмпирическую функцию регрессии:
Прогноз значений зависимой переменной и вычисленные остатки регрессии приведены в таблице 4.3 На рис. 4.13 , 4.14 даны графики прогноза и остатков.
Рис. 4.13. Линия регрессии (4.41)
Рис. 4.14. График остатков
Статистика Дарбина - Уотсона вычисляется по формуле ( 4.40 ):
Для количества наблюдений n = 15, количества регрессоров k = 2 и уровня значимости , нижняя и верхняя границы критического значения статистики Дарбина - Уотсона равны: . Вычисленное для построенной регрессии значение d - статистики меньше нижней границы критического значения статистики, что говорит о наличии положительной автокорреляции остатков.
Определите для данной модели коэффициент детерминации, стандартные отклонения и доверительные интервалы для коэффициентов.
Оценка авторегрессионного параметра и процедуры устранения автокорреляции
Предположим сначала, что значение параметра авторегрессии известно. Для того, чтобы провести коррекцию модели на автокорреляцию, необходимо преобразовать исходную модель так, чтобы в преобразованной модели возмущения были некоррелированы. Такое преобразование легко построить и суть его состоит в следующем. Вычтем почленно из уравнения регрессии ( 4.29 ) (при t=2,3,…,n) уравнение
Учитывая уравнение авторегрессии ( 4.30 ), получим
При t = 1 обе части уравнения ( 4.29 ) умножим на множитель :
Введем новые переменные:
Тогда уравнение преобразованной модели можно записать в виде
где вектор , матрица , вектор возмущений , матрица преобразования имеет следующую структуру
В преобразованной модели ( 4.44 ) возмущения удовлетворяют свойству гомоскедастичности. Действительно, компоненты вектора возмущений имеют одинаковые дисперсии, равные и некоррелированы между собой.
При практической реализации описанного метода, для простоты часто ограничиваются только преобразованием вида ( 4.43 ), опуская первое наблюдение ( 4.42 ).
К сожалению, при построении эконометрических моделей реальных социально-экономических процессов параметр авторегрессии, как правило, неизвестен и подлежит оцениванию. Существует множество различных процедур оценивания регрессионных моделей с одновременным оцениванием параметра авторегрессии возмущений. Рассмотрим некоторые из них.
Итерационная процедура Кохрейна-Оркатта
При подтверждении гипотезы о существовании автокорреляции первого порядка, процедура оценивания параметров регрессии с использованием преобразованной модели может быть проведена по следующей итерационной схеме.
1) Оцениваем обычным методом наименьших квадратов вектор коэффициентов исходной (не преобразованной) модели по формуле ( 3.15 ). Вычисляем вектор остатков e.
3) Строим преобразованную модель, используя вместо параметра его оценку r ( 4.45 ). К преобразованной модели применяем метод наименьших квадратов (обычный) и находим оценку b вектора коэффициентов .
4) Вычисляем новый вектор остатков e = y - Xb. Повторяем процедуру, начиная с пункта 2). Итерационный процесс заканчивается, когда два последовательных значения оценок r параметра мало отличаются друг от друга (находятся друг от друга в пределах заданной точности). Иногда ограничиваются единственной итерацией.
Для вычисления оценки r можно использовать соотношение ( 4.40 ), из которого получаем: , при этом d - статистика вычисляется по формуле ( 4.37 ).
Итерационная процедура Хилдрета-Лу
1) Выбираем последовательно значения коэффициента из интервала его изменения (-1, 1), с некоторым шагом h (то есть очередное значение получается путем прибавления к предыдущему значению параметра величины h).
2) Для каждого значения оцениваем преобразованную модель ( 4.44 ). Вычисляем сумму квадратов остатков. Выбираем то значение параметра , для которого эта сумма минимальна.
Данную процедуру можно проводить в несколько этапов - сначала определить "грубое" значение , реализовав процедуру с большим шагом h. Затем повторить процедуру в окрестности этого значения , уменьшив шаг h.
Преобразованную модель ( 4.44 ) можно записать в виде
К данной модели, очевидно, можно применить обычный МНК, рассматривая наблюдения yt-1 как регрессоры, а - как оцениваемый параметр (возмущения модели гомоскедастичны). Оценив ее параметры, легко получить оценки параметров исходной модели. Недостатком этого метода является то, что количество оцениваемых параметров в преобразованной модели ( 4.46 ) существенно возрастает по сравнению с исходной моделью. Действительно, в качестве оцениваемых параметров модель ( 4.46 ) содержит k - 1 параметр , j=2,3,…,k, исходной модели, k-1 параметр вида , параметр вида и параметр . При малом количестве наблюдений этот подход не применяется.
По таблице Значения d-критерия Дарбина – Уотсона определим, что d1= 1,08 и d2= 1,36
Т.е. наше d=2,213699 ? (1.08;1,36), следовательно нужна дополнительная проверка, найдем d’=4-d=4-2,213699=1,786301, т.е d’ ? (1,36;2)
не выпол-ся доп. Прове-ка выпол-ся d’=4-d

следовательно, свойство независимости уровней ряда остатков выполняются, остатки независимы.
Для проверки нормального распределения остатков вычислим R/S – статистику
еmax- максимальный уровень ряда остатков,
еmin- минимальный уровень ряда остатков,
S- среднеквадратичное отклонение.
еmax=2,2333333 используем Excel fx/статистическая/МАКС),
еmin=-2,466666667 используем Excel fx/статистическая/МИН),
Se=1,444200224 1-я таблица Итогов регрессии строка «стандартная ошибка»
Следовательно, R/S=2,2333333 - (-2,466666667)/ 1,444200224=3,254396
Критический интервал (2,7;3,7), т.е R/S=3,254396 ? (2,7;3,7), свойство нормального распределения остатков выполняется.
Подводя итоги проверки можно сделать вывод, что модель ведет себя адекватно.
Для оценки точности модели вычислим среднюю относительную ошибку аппроксимации Еотн = |e(t)/Y(t)|*100% по полученным значениям определить среднее значение (fx/математическая/СРЗНАЧ)
Eотн ср =8,853564 – хороший уровень точности модели
Для вычисления точечного прогноза в построенную модель подставим соответствующие значения t=10 и t=11:
Ожидаемый спрос на кредитные ресурсы финансовой компании на 10 неделю должен составить около 28,16666667 млн. руб., а на 11 неделю около 30,86666667 млн. руб.
При уровне значимости L=30%, доверительная вероятность равна 70%, а критерий Стьюдента при к=n-2=9-2=7, равен
Se=1,444200224 1-я таблица Итогов регрессии строка «стандартная ошибка»,
t’ср = 5(fx/математическая/СРЗНАЧ)- средний уровень по рассматриваемому моменту времени,
Ширину доверительного интервала вычислим по формуле:
Спрос на кредитные ресурсы финансовой компании на 10 неделю в пределах от 26,16888 млн. руб. до 30,16445 млн. руб., а на 11 неделю от 28,75241 млн. руб. до 32,98093 млн. руб.
Читайте также: